Nota
L'accesso a questa pagina richiede l'autorizzazione. È possibile provare ad accedere o modificare le directory.
L'accesso a questa pagina richiede l'autorizzazione. È possibile provare a modificare le directory.
Le librerie forniscono codice riutilizzabile che può essere utile includere nei programmi o nei progetti per Microsoft Fabric Spark.
Microsoft Fabric supporta un runtime R con molti dei pacchetti R open source più diffusi, tra cui TidyVerse, preinstallati. All'avvio di un'istanza di Spark, queste librerie vengono incluse automaticamente e rese disponibili per essere usate immediatamente nei notebook o nelle definizioni dei processi Spark.
Potrebbe essere necessario aggiornare le librerie R per vari motivi. Ad esempio se una delle dipendenze principali ha rilasciato una nuova versione o se il team ha creato un pacchetto personalizzato necessario nei cluster Spark.
È possibile includere due tipi di librerie in base allo scenario:
Le librerie di feed fanno riferimento a quelle che risiedono in origini o repository pubblici, ad esempio CRAN o GitHub.
Le librerie personalizzate sono il codice creato dall'utente o dall'organizzazione, .tar.gz può essere gestito tramite i portali di gestione delle librerie.
In Microsoft Fabric sono installati due livelli di pacchetti:
Ambiente: gestire le librerie tramite un ambiente per riutilizzare lo stesso set di librerie in più notebook o processi.
Sessione: un'installazione a livello di sessione crea un ambiente per una sessione di notebook specifica. La modifica delle librerie a livello di sessione non viene mantenuta tra le sessioni.
Riepilogo dei comportamenti correnti di gestione delle librerie R disponibili:
| Tipo di libreria | Installazione dell'ambiente | Installazione a livello di sessione |
|---|---|---|
| Feed R (CRAN) | Non supportato | Supportato |
| Personalizzazione R | Supportato | Supportato |
Prerequisiti
Ottenere una sottoscrizione di Microsoft Fabric. In alternativa, iscriversi per ottenere una versione di valutazione di Microsoft Fabric gratuita.
Accedere a Microsoft Fabric.
Usa l'interruttore esperienza nell'angolo in basso a sinistra della tua home page per passare a Fabric.

Librerie R a livello di sessione
Quando si esegue l'analisi interattiva dei dati o l'apprendimento automatico, è possibile provare pacchetti più recenti oppure potrebbero essere necessari pacchetti attualmente non disponibili nell'area di lavoro. Anziché aggiornare la configurazione dell'area di lavoro, è possibile usare pacchetti con ambito sessione per aggiungere, gestire e aggiornare le dipendenze della sessione.
- Quando si installano librerie con ambito sessione, solo il notebook corrente ha accesso alle librerie specificate.
- Queste librerie non hanno alcun impatto su altre sessioni o processi che usano lo stesso pool di Spark.
- Queste librerie vengono installate sopra il runtime di base e le librerie a livello di pool.
- Le librerie di notebook hanno la precedenza più alta.
- Le librerie R con ambito sessione non vengono mantenute tra le sessioni. Queste librerie vengono installate all'inizio di ogni sessione quando vengono eseguiti i comandi di installazione correlati.
- Le librerie R con ambito sessione vengono installate automaticamente nei nodi driver e di lavoro.
Nota
Questi comandi di gestione delle librerie R vengono disabilitati durante l'esecuzione di processi della pipeline. Se si desidera installare un pacchetto all'interno di una pipeline, è necessario sfruttare le funzionalità di gestione della libreria a livello di area di lavoro.
Installare pacchetti R da CRAN
È possibile installare facilmente una libreria R da CRAN.
# install a package from CRAN
install.packages(c("nycflights13", "Lahman"))
È anche possibile usare snapshot CRAN come repository per assicurarsi di scaricare ogni volta la stessa versione del pacchetto.
# install a package from CRAN snapsho
install.packages("highcharter", repos = "https://cran.microsoft.com/snapshot/2021-07-16/")
Installare pacchetti R usando devtools
La libreria devtools semplifica lo sviluppo di pacchetti per accelerare le attività comuni. Questa libreria viene installata all'interno del runtime predefinito di Microsoft Fabric.
È possibile usare devtools per specificare una versione specifica di una libreria da installare. Queste librerie verngono installate in tutti i nodi all'interno del cluster.
# Install a specific version.
install_version("caesar", version = "1.0.0")
Analogamente, è possibile installare una libreria direttamente da GitHub.
# Install a GitHub library.
install_github("jtilly/matchingR")
Attualmente, all'interno di Microsoft Fabric sono supportate le seguenti funzioni devtools:
| Comando | Descrizione |
|---|---|
| install_github() | Installa un pacchetto R da GitHub |
| install_gitlab() | Installa un pacchetto R da GitLab |
| install_bitbucket() | Installa un pacchetto R da BitBucket |
| install_url() | Installa un pacchetto R da un URL arbitrario |
| install_git() | Installa da un repository Git arbitrario |
| install_local() | Installa da un file locale su disco |
| install_version() | Installa da una versione specifica in CRAN |
Installare librerie personalizzate R
Per usare una libreria personalizzata a livello di sessione, è prima necessario caricarla in un lakehouse collegato.
Aprire il notebook in cui si vuole usare la libreria personalizzata.
Sul lato sinistro, selezionare Aggiungi per aggiungere una lakehouse esistente o crearne uno nuovo.
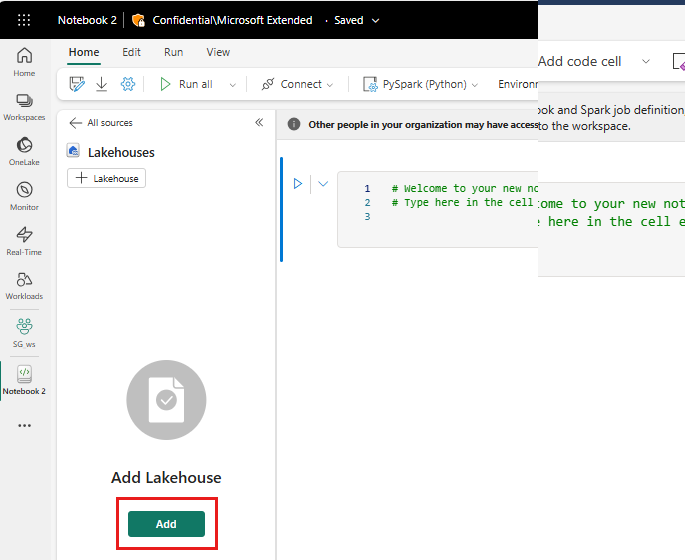
Fare clic con il pulsante destro del mouse o selezionare "..." accanto a File per caricare il file .tar.gz.
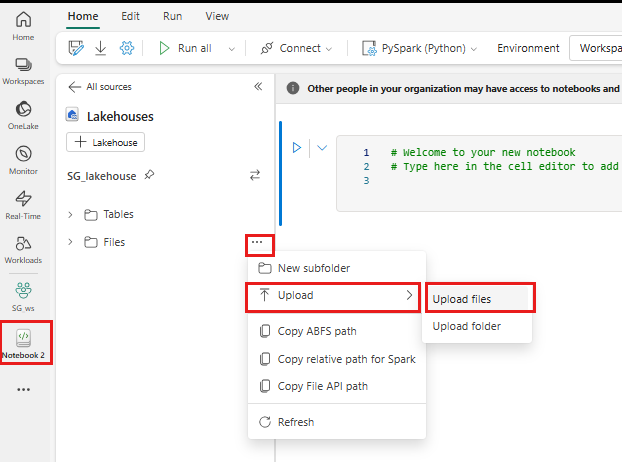
Dopo il caricamento, tornare al notebook. Usare il comando seguente per installare la libreria personalizzata nella sessione:
install.packages("filepath/filename.tar.gz", repos = NULL, type = "source")
Visualizzare le librerie installate
È possibile eseguire query su tutte le librerie installate all'interno della sessione usando il comando library.
# query all the libraries installed in current session
library()
È possibile usare la funzione packageVersion per controllare la versione della libreria:
# check the package version
packageVersion("caesar")
Rimuovere un pacchetto R da una sessione
È possibile usare la funzione detach per rimuovere una libreria dallo spazio dei nomi. Queste librerie rimangono su disco finché non vengono ricaricate.
# detach a library
detach("package: caesar")
Per rimuovere un pacchetto con ambito sessione da un notebook, usare il comando remove.packages(). Questa modifica della libreria non ha alcun impatto su altre sessioni nello stesso cluster. Gli utenti non possono disinstallare o rimuovere librerie integrate del runtime predefinito di Microsoft Fabric.
Nota
Non è possibile rimuovere pacchetti di base come SparkR, SparklyR o R.
remove.packages("caesar")
Librerie R con ambito sessione e SparkR
Le librerie con ambito notebook sono disponibili nei ruoli di lavoro SparkR.
install.packages("stringr")
library(SparkR)
str_length_function <- function(x) {
library(stringr)
str_length(x)
}
docs <- c("Wow, I really like the new light sabers!",
"That book was excellent.",
"R is a fantastic language.",
"The service in this restaurant was miserable.",
"This is neither positive or negative.")
spark.lapply(docs, str_length_function)
Librerie R con ambito sessione e sparklyr
Con spark_apply() in sparklyr, è possibile usare qualsiasi pacchetto R all'interno di Spark. Per impostazione predefinita, in sparklyr::spark_apply() l'argomento packages è impostato su FALSE. Questa operazione copia le librerie nei percorsi libPath correnti ai ruoli di lavoro, consentendo di importarle e usarle nei ruoli di lavoro. Ad esempio, è possibile eseguire quanto segue per generare un messaggio con crittografia caesar con sparklyr::spark_apply():
install.packages("caesar", repos = "https://cran.microsoft.com/snapshot/2021-07-16/")
spark_version <- sparkR.version()
config <- spark_config()
sc <- spark_connect(master = "yarn", version = spark_version, spark_home = "/opt/spark", config = config)
apply_cases <- function(x) {
library(caesar)
caesar("hello world")
}
sdf_len(sc, 5) %>%
spark_apply(apply_cases, packages=FALSE)
Contenuto correlato
Altre informazioni sulle funzionalità R: