Nota
L'accesso a questa pagina richiede l'autorizzazione. È possibile provare ad accedere o modificare le directory.
L'accesso a questa pagina richiede l'autorizzazione. È possibile provare a modificare le directory.
Tidyverse è una raccolta di pacchetti R che gli scienziati dei dati usano comunemente nelle analisi quotidiane dei dati. Include pacchetti per l'importazione dei dati (readr), l'effetto di visualizzazione dei dati (ggplot2), la manipolazione dei dati (dplyr, tidyr), la programmazione funzionale (purrr), la creazione di modelli (tidymodels) e così via. I pacchetti in tidyverse sono progettati per essere usati insieme senza problemi e seguono un insieme coerente di principi di progettazione.
Microsoft Fabric distribuisce la versione stabile più recente di tidyverse con ogni pubblicazione di runtime. Importare e iniziare a usare i pacchetti R già conosciuti.
Prerequisiti
Ottenere una sottoscrizione di Microsoft Fabric. In alternativa, iscriversi per ottenere una versione di valutazione di Microsoft Fabric gratuita.
Accedere a Microsoft Fabric.
Utilizzare l'interruttore di esperienza nella parte inferiore sinistra della home page per passare a Fabric.

Aprire o creare un notebook. Per istruzioni, vedere Come usare i notebook di Microsoft Fabric.
Impostare l'opzione del linguaggio su SparkR (R) per modificare il linguaggio primario.
Collegare il notebook a un lakehouse. Sul lato sinistro, selezionare Aggiungi per aggiungere un lakehouse esistente o per crearne uno nuovo.
Caricare tidyverse
# load tidyverse
library(tidyverse)
Importazione dei dati
readr è un pacchetto R che fornisce strumenti per la lettura di file di dati rettangolari, ad esempio CSV, TSV e file a larghezza fissa.
readr fornisce un modo rapido e semplice da usare per leggere file di dati rettangolari, ad esempio fornire funzioni read_csv() e read_tsv() per leggere rispettivamente file CSV e TSV.
Creiamo prima un data.frame R, scriviamolo nel lakehouse usando readr::write_csv() e leggiamolo con readr::read_csv().
Nota
Per accedere ai file Lakehouse usando readr, è necessario usare il percorso del file API. Nell'explorer di Lakehouse, fare clic con il pulsante destro del mouse sul file o sulla cartella a cui si vuole accedere e copiarne il percorso del file API dal menu contestuale.
# create an R data frame
set.seed(1)
stocks <- data.frame(
time = as.Date('2009-01-01') + 0:9,
X = rnorm(10, 20, 1),
Y = rnorm(10, 20, 2),
Z = rnorm(10, 20, 4)
)
stocks
Scriviamo quindi i dati nel lakehouse usando il percorso del file API.
# write data to lakehouse using the File API path
temp_csv_api <- "/lakehouse/default/Files/stocks.csv"
readr::write_csv(stocks,temp_csv_api)
Leggere i dati dal lakehouse.
# read data from lakehouse using the File API path
stocks_readr <- readr::read_csv(temp_csv_api)
# show the content of the R date.frame
head(stocks_readr)
Riordino dei dati
tidyr è un pacchetto R che fornisce strumenti per lavorare con dati disordinati. Le funzioni principali in tidyr sono progettate per permettere di rimodellare i dati in un formato ordinato. I dati ordinati hanno una struttura specifica in cui ogni variabile è una colonna e ogni osservazione è una riga, il che semplifica il lavoro con i dati in R e altri strumenti.
Ad esempio, la funzione gather() in tidyr può essere usata per convertire dati larghi in dati lunghi. Ecco un esempio:
# convert the stock data into longer data
library(tidyr)
stocksL <- gather(data = stocks, key = stock, value = price, X, Y, Z)
stocksL
Programmazione funzionale
purrr è un pacchetto R che migliora il toolkit di programmazione funzionale di R fornendo un insieme completo e coerente di strumenti per lavorare con funzioni e vettori. Il punto di partenza migliore per iniziare a usare purrr è la serie di funzioni map() che consentono di sostituire molti Loop con codice più sintetico e più facile da leggere. Ecco un esempio di come usare map() per applicare una funzione a ogni elemento di un elenco:
# double the stock values using purrr
library(purrr)
stocks_double = map(stocks %>% select_if(is.numeric), ~.x*2)
stocks_double
Manipolazione dei dati
dplyr è un pacchetto R che fornisce un insieme coerente di verbi che consentono di risolvere i problemi di manipolazione dei dati più comuni, ad esempio la selezione di variabili in base ai nomi, la selezione di case in base ai valori, la riduzione di più valori a un singolo riepilogo e la modifica dell'ordine delle righe e così via. Ecco alcuni esempi:
# pick variables based on their names using select()
stocks_value <- stocks %>% select(X:Z)
stocks_value
# pick cases based on their values using filter()
filter(stocks_value, X >20)
# add new variables that are functions of existing variables using mutate()
library(lubridate)
stocks_wday <- stocks %>%
select(time:Z) %>%
mutate(
weekday = wday(time)
)
stocks_wday
# change the ordering of the rows using arrange()
arrange(stocks_wday, weekday)
# reduce multiple values down to a single summary using summarise()
stocks_wday %>%
group_by(weekday) %>%
summarize(meanX = mean(X), n= n())
Effetto di visualizzazione dei dati
ggplot2 è un pacchetto R per la creazione dichiarativa di grafica, basato su La Grammatica della Grafica. Si forniscono i dati, si spiega a ggplot2 come fare a eseguire il mapping delle variabili all'estetica, quali primitive grafiche usare, e il pacchetto si occupa dei dettagli. Di seguito sono riportati alcuni esempi:
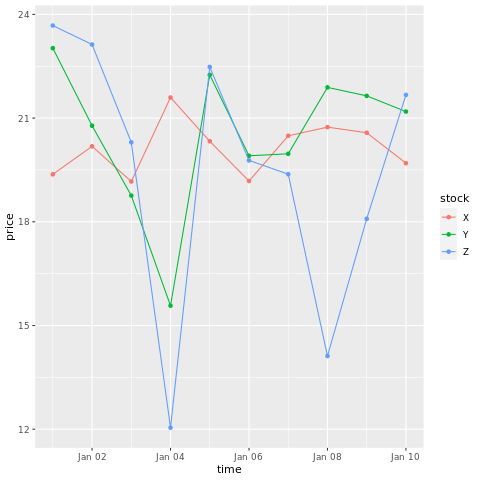
# draw a chart with points and lines all in one
ggplot(stocksL, aes(x=time, y=price, colour = stock)) +
geom_point()+
geom_line()
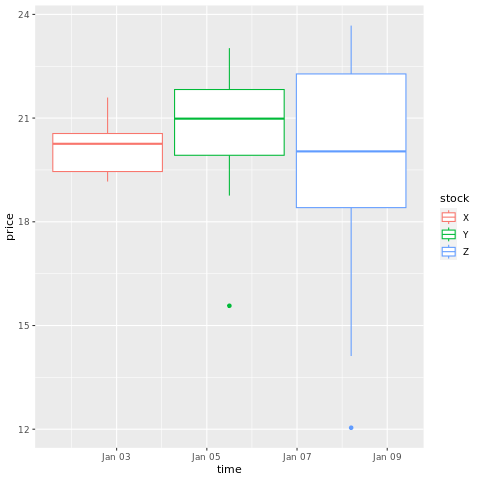
# draw a boxplot
ggplot(stocksL, aes(x=time, y=price, colour = stock)) +
geom_boxplot()
Creazione del modello
Il framework tidymodels è una raccolta di pacchetti per la modellazione e l'apprendimento automatico che usa i principi tidyverse. Include un elenco di pacchetti principali per un'ampia gamma di attività di creazione di modelli, ad esempio rsample per la divisione dei campioni di set di dati di training/test, parsnip per la specifica del modello, recipes per la pre-elaborazione dei dati, workflows per la modellazione dei flussi di lavoro, tune per l'ottimizzazione degli iperparametri, yardstick per la valutazione del modello, broom per l'ordinamento degli output del modello e dials per la gestione dei parametri di ottimizzazione. Per ulteriori informazioni sui pacchetti, visitare il sito Web tidymodels. Di seguito è riportato un esempio di creazione di un modello di regressione lineare per stimare le miglia per gallone (mpg) di un'automobile in base al suo peso (wt):
# look at the relationship between the miles per gallon (mpg) of a car and its weight (wt)
ggplot(mtcars, aes(wt,mpg))+
geom_point()
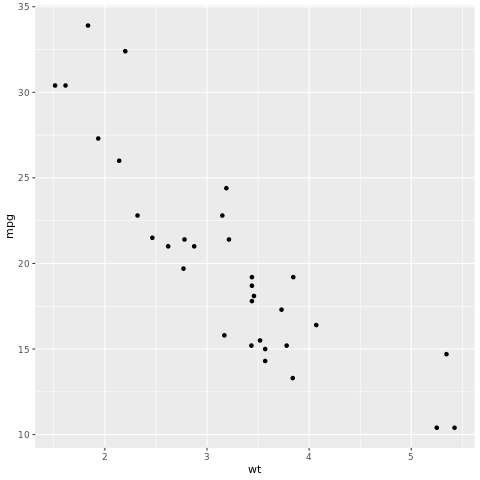
Dal grafico a dispersione, la relazione sembra approssimativamente lineare e la varianza sembra costante. Proveremo ora a modellare questa relazione usando la regressione lineare.
library(tidymodels)
# split test and training dataset
set.seed(123)
split <- initial_split(mtcars, prop = 0.7, strata = "cyl")
train <- training(split)
test <- testing(split)
# config the linear regression model
lm_spec <- linear_reg() %>%
set_engine("lm") %>%
set_mode("regression")
# build the model
lm_fit <- lm_spec %>%
fit(mpg ~ wt, data = train)
tidy(lm_fit)
Applicare il modello di regressione lineare per prevedere il set di dati di test.
# using the lm model to predict on test dataset
predictions <- predict(lm_fit, test)
predictions
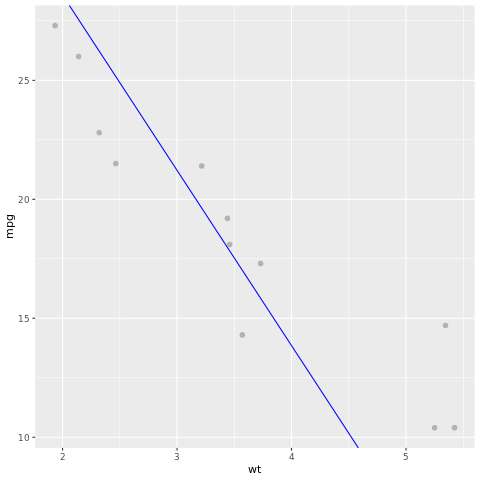
Esaminiamo ora il risultato del modello. È possibile disegnare il modello come grafico a linee e i dati di verità del terreno di test come punti nello stesso grafico. Il modello non presenta problemi.
# draw the model as a line chart and the test data groundtruth as points
lm_aug <- augment(lm_fit, test)
ggplot(lm_aug, aes(x = wt, y = mpg)) +
geom_point(size=2,color="grey70") +
geom_abline(intercept = lm_fit$fit$coefficients[1], slope = lm_fit$fit$coefficients[2], color = "blue")