Nota
L'accesso a questa pagina richiede l'autorizzazione. È possibile provare ad accedere o modificare le directory.
L'accesso a questa pagina richiede l'autorizzazione. È possibile provare a modificare le directory.
Questa esercitazione presenta un esempio end-to-end di un workflow di Data Science Synapse in "Microsoft Fabric". Lo scenario crea un modello per le raccomandazioni sui libri online.
Segui questi passaggi:
- Caricare dati in un lakehouse
- Eseguire l'analisi esplorativa sui dati
- Eseguire il training del modello e registrarlo con MLflow
- Caricare il modello ed effettuare previsioni
Sono disponibili molti tipi di algoritmi di raccomandazione. Questa esercitazione usa l'algoritmo di fattorizzazione della matrice Alternate Least Squares (ALS). ALS è un algoritmo di filtro collaborativo basato su modello.

ALS tenta di stimare la matrice di classificazioni R come prodotto di due matrici di rango inferiore, U e V. Qui, R = U * Vt. In genere, queste approssimazioni sono denominate matrici di fattori.
L'algoritmo ALS è iterativo. Ogni iterazione contiene una delle costanti delle matrici di fattori, mentre risolve l'altra usando il metodo dei minimi quadrati. Mantiene quindi la costante della matrice di fattori appena risolta mentre risolve l'altra matrice di fattori.

Prerequisiti
Ottenere una sottoscrizione Microsoft Fabric. In alternativa, iscriversi per ottenere una versione di valutazione gratuita Microsoft Fabric.
Accedere a Microsoft Fabric.
Passare a Fabric usando il commutatore dell'esperienza in basso a sinistra della tua home page.

- Se necessario, crea un lakehouse di Microsoft Fabric come descritto in Creare un lakehouse in Microsoft Fabric.
Segui con un blocco per appunti
Scegli una di queste opzioni per seguire in un bloc-notes:
- Aprire ed eseguire il notebook integrato.
- Caricare il notebook da GitHub.
Aprire il notebook predefinito
Il notebook di esempio raccomandazione del libro accompagna questa esercitazione.
Per aprire il notebook di esempio per questa esercitazione, seguire le istruzioni riportate in Preparare il sistema per le esercitazioni sull'analisi scientifica dei dati.
Assicuratevi di collegare un lakehouse al notebook prima di iniziare a eseguire il codice.
Importare il notebook da GitHub
Il notebook AIsample - Book Recommendation.ipynb accompagna questa esercitazione.
Per aprire il notebook di accompagnamento per questa esercitazione, seguire le istruzioni riportate in Preparare il sistema per le esercitazioni di data science per importare il notebook nell'area di lavoro.
Se si preferisce copiare e incollare il codice da questa pagina, è possibile creare un nuovo notebook.
Assicurati di collegare un lakehouse al notebook prima di iniziare a eseguire il codice.
Passaggio 1: caricare i dati
Il set di dati delle raccomandazioni libro in questo scenario è costituito da tre set di dati distinti:
Books.csv: un numero ISBN (International Standard Book Number) identifica ogni libro, con date non valide già rimosse. Il set di dati include anche il titolo, l'autore e publisher. Per un libro con più autori, il file Books.csv elenca solo il primo autore. Gli URL puntano alle risorse del sito Web Amazon per le immagini di copertina, in tre dimensioni.
ISBN Titolo-libro Autore di libri Anno-di-pubblicazione Editore Image-URL-S Image-URL-M Image-URL-l 0195153448 Mitologia classica Mark P. O. Morford 2002 Oxford University Press http://images.amazon.com/images/P/0195153448.01.THUMBZZZ.jpg http://images.amazon.com/images/P/0195153448.01.MZZZZZZZ.jpg http://images.amazon.com/images/P/0195153448.01.LZZZZZZZ.jpg 0002005018 Clara Callan Richard Bruce Wright 2001 HarperFlamingo Canada http://images.amazon.com/images/P/0002005018.01.THUMBZZZ.jpg http://images.amazon.com/images/P/0002005018.01.MZZZZZZZ.jpg http://images.amazon.com/images/P/0002005018.01.LZZZZZZZ.jpg Ratings.csv: le classificazioni per ogni libro sono esplicite (fornite dagli utenti, su scala da 1 a 10) o implicite (osservate senza input dell'utente e indicate da 0).
ID utente ISBN Valutazione libro 276725 034545104X 0 276726 0155061224 5 Users.csv: gli ID utente sono anonimi e mappati a numeri interi. I dati demografici, ad esempio la posizione e l'età, vengono forniti, se disponibili. Se questi dati non sono disponibili, questi valori sono
null.ID utente Luogo Età 1 New York City, New York, USA 2 "stockton california usa" 18.0
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
Definire questi parametri, in modo da poter usare questo notebook con set di dati diversi:
IS_CUSTOM_DATA = False # If True, the dataset has to be uploaded manually
USER_ID_COL = "User-ID" # Must not be '_user_id' for this notebook to run successfully
ITEM_ID_COL = "ISBN" # Must not be '_item_id' for this notebook to run successfully
ITEM_INFO_COL = (
"Book-Title" # Must not be '_item_info' for this notebook to run successfully
)
RATING_COL = (
"Book-Rating" # Must not be '_rating' for this notebook to run successfully
)
IS_SAMPLE = True # If True, use only <SAMPLE_ROWS> rows of data for training; otherwise, use all data
SAMPLE_ROWS = 5000 # If IS_SAMPLE is True, use only this number of rows for training
DATA_FOLDER = "Files/book-recommendation/" # Folder that contains the datasets
ITEMS_FILE = "Books.csv" # File that contains the item information
USERS_FILE = "Users.csv" # File that contains the user information
RATINGS_FILE = "Ratings.csv" # File that contains the rating information
EXPERIMENT_NAME = "aisample-recommendation" # MLflow experiment name
Scaricare e archiviare i dati in un lakehouse
Questo codice scarica il set di dati e quindi lo archivia nel lakehouse.
Importante
Assicurarsi di aggiungere un lakehouse al notebook prima di eseguirlo. In caso contrario, viene visualizzato un errore.
if not IS_CUSTOM_DATA:
# Download data files into a lakehouse if they don't exist
import os, requests
remote_url = "https://synapseaisolutionsa.z13.web.core.windows.net/data/Book-Recommendation-Dataset"
file_list = ["Books.csv", "Ratings.csv", "Users.csv"]
download_path = f"/lakehouse/default/{DATA_FOLDER}/raw"
if not os.path.exists("/lakehouse/default"):
raise FileNotFoundError(
"Default lakehouse not found, please add a lakehouse and restart the session."
)
os.makedirs(download_path, exist_ok=True)
for fname in file_list:
if not os.path.exists(f"{download_path}/{fname}"):
r = requests.get(f"{remote_url}/{fname}", timeout=30)
with open(f"{download_path}/{fname}", "wb") as f:
f.write(r.content)
print("Downloaded demo data files into lakehouse.")
Configurare il rilevamento dell'esperimento di MLflow
Usare questo codice per configurare il rilevamento dell'esperimento MLflow. In questo esempio viene disabilitato il logging automatico. Per altre informazioni, vedere l'articolo Autologging in Microsoft Fabric.
# Set up MLflow for experiment tracking
import mlflow
mlflow.set_experiment(EXPERIMENT_NAME)
mlflow.autolog(disable=True) # Disable MLflow autologging
Leggere i dati dal database di lakehouse
Dopo aver inserito i dati corretti nel Lakehouse, leggi i tre set di dati in DataFrames Spark separati nel notebook. I percorsi di file in questo codice usano i parametri definiti in precedenza.
df_items = (
spark.read.option("header", True)
.option("inferSchema", True)
.csv(f"{DATA_FOLDER}/raw/{ITEMS_FILE}")
.cache()
)
df_ratings = (
spark.read.option("header", True)
.option("inferSchema", True)
.csv(f"{DATA_FOLDER}/raw/{RATINGS_FILE}")
.cache()
)
df_users = (
spark.read.option("header", True)
.option("inferSchema", True)
.csv(f"{DATA_FOLDER}/raw/{USERS_FILE}")
.cache()
)
Passaggio 2: eseguire l'analisi esplorativa dei dati
Visualizzare dati non elaborati
Esplorare i dataframe usando il display comando . Usando questo comando, è possibile visualizzare statistiche di dataframe di alto livello e comprendere in che modo le diverse colonne del set di dati sono correlate tra loro. Prima di esplorare i set di dati, usare questo codice per importare le librerie necessarie:
import pyspark.sql.functions as F
from pyspark.ml.feature import StringIndexer
import matplotlib.pyplot as plt
import seaborn as sns
color = sns.color_palette() # Adjusting plotting style
import pandas as pd # DataFrames
Usare questo codice per esaminare il DataFrame che contiene i dati del libro:
display(df_items, summary=True)
Aggiungere una colonna _item_id per usarla in un secondo momento. Il valore _item_id deve essere un numero intero per i modelli di raccomandazione. Questo codice usa StringIndexer per trasformare ITEM_ID_COL in indici:
df_items = (
StringIndexer(inputCol=ITEM_ID_COL, outputCol="_item_id")
.setHandleInvalid("skip")
.fit(df_items)
.transform(df_items)
.withColumn("_item_id", F.col("_item_id").cast("int"))
)
Visualizzare il DataFrame e verificare se il valore _item_id aumenta in modo monotonico e successivo, come previsto:
display(df_items.sort(F.col("_item_id").desc()))
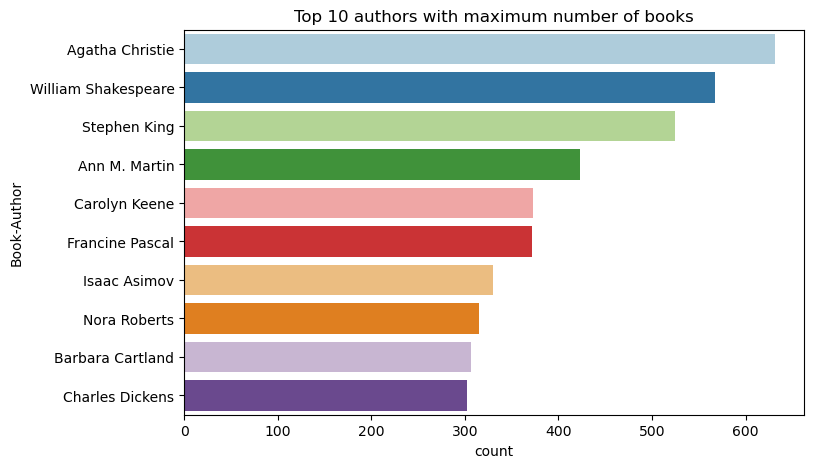
Usare questo codice per tracciare i primi 10 autori, in base al numero di libri scritti, in ordine decrescente. Agatha Christie è l'autore principale con più di 600 libri, seguiti da William Shakespeare.
df_books = df_items.toPandas() # Create a pandas DataFrame from the Spark DataFrame for visualization
plt.figure(figsize=(8,5))
sns.countplot(y="Book-Author",palette = 'Paired', data=df_books,order=df_books['Book-Author'].value_counts().index[0:10])
plt.title("Top 10 authors with maximum number of books")
Visualizzare quindi il DataFrame che contiene i dati utente:
display(df_users, summary=True)
Se una riga contiene un valore mancante User-ID, eliminare tale riga. I valori mancanti in un set di dati personalizzato non causano problemi.
df_users = df_users.dropna(subset=(USER_ID_COL))
display(df_users, summary=True)
Aggiungere una colonna _user_id per usarla in un secondo momento. Per i modelli di raccomandazione, il valore _user_id deve essere un numero intero. Nell'esempio di codice seguente, StringIndexer viene usato per trasformare USER_ID_COL in indici.
Il set di dati dei libri contiene già una colonna di numeri interi User-ID. Tuttavia, l'aggiunta di una colonna _user_id per la compatibilità con set di dati diversi rende questo esempio più affidabile. Usare questo codice per aggiungere la colonna _user_id:
df_users = (
StringIndexer(inputCol=USER_ID_COL, outputCol="_user_id")
.setHandleInvalid("skip")
.fit(df_users)
.transform(df_users)
.withColumn("_user_id", F.col("_user_id").cast("int"))
)
display(df_users.sort(F.col("_user_id").desc()))
Usare questo codice per visualizzare i dati di classificazione:
display(df_ratings, summary=True)
Ottenere le classificazioni distinte e salvarle per usarle in un secondo momento in un elenco denominato ratings:
ratings = [i[0] for i in df_ratings.select(RATING_COL).distinct().collect()]
print(ratings)
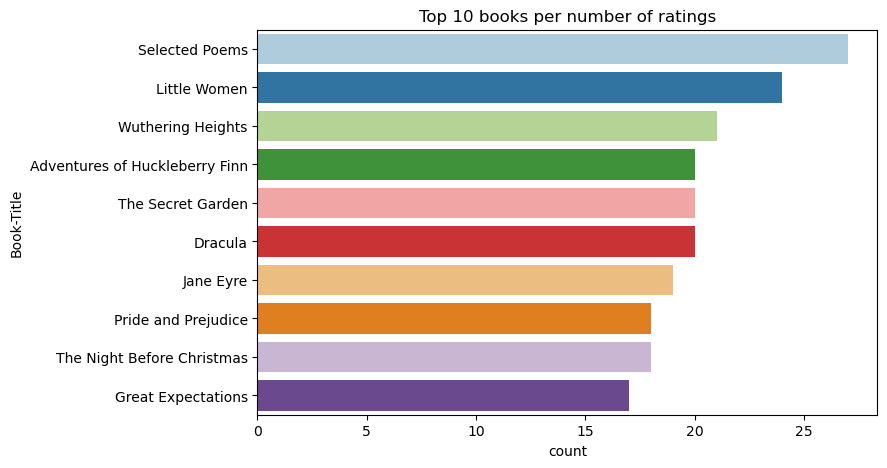
Usare questo codice per visualizzare i primi 10 libri con le classificazioni più alte:
plt.figure(figsize=(8,5))
sns.countplot(y="Book-Title",palette = 'Paired',data= df_books, order=df_books['Book-Title'].value_counts().index[0:10])
plt.title("Top 10 books per number of ratings")
Secondo le classificazioni, Selected Poems è il libro più popolare. Adventures of Huckleberry Finn, The Secret Garden e Dracula hanno la stessa classificazione.
Unire dati
Unire i tre DataFrame in un DataFrame per un'analisi più completa:
df_all = df_ratings.join(df_users, USER_ID_COL, "inner").join(
df_items, ITEM_ID_COL, "inner"
)
df_all_columns = [
c for c in df_all.columns if c not in ["_user_id", "_item_id", RATING_COL]
]
# Reorder the columns to ensure that _user_id, _item_id, and Book-Rating are the first three columns
df_all = (
df_all.select(["_user_id", "_item_id", RATING_COL] + df_all_columns)
.withColumn("id", F.monotonically_increasing_id())
.cache()
)
display(df_all)
Usare questo codice per visualizzare un conteggio di utenti, libri e interazioni distinti:
print(f"Total Users: {df_users.select('_user_id').distinct().count()}")
print(f"Total Items: {df_items.select('_item_id').distinct().count()}")
print(f"Total User-Item Interactions: {df_all.count()}")
Calcolare e tracciare gli elementi più diffusi
Usare questo codice per calcolare e visualizzare i primi 10 libri più diffusi:
# Compute top popular products
df_top_items = (
df_all.groupby(["_item_id"])
.count()
.join(df_items, "_item_id", "inner")
.sort(["count"], ascending=[0])
)
# Find top <topn> popular items
topn = 10
pd_top_items = df_top_items.limit(topn).toPandas()
pd_top_items.head(10)
Suggerimento
Usare il valore <topn> per le sezioni di raccomandazione più diffusi o più acquistati.
# Plot top <topn> items
f, ax = plt.subplots(figsize=(10, 5))
plt.xticks(rotation="vertical")
sns.barplot(y=ITEM_INFO_COL, x="count", data=pd_top_items)
ax.tick_params(axis='x', rotation=45)
plt.xlabel("Number of Ratings for the Item")
plt.show()

Preparare i set di dati di training e di test
La matrice ALS richiede una preparazione dei dati prima del training. Usare questo esempio di codice per preparare i dati. Il codice esegue queste azioni:
- Convertire la colonna del rating al tipo corretto.
- Campiona i dati di addestramento con le valutazioni degli utenti.
- Suddividere i dati in set di dati di addestramento e di test.
if IS_SAMPLE:
# Must sort by '_user_id' before performing limit to ensure that ALS works normally
# If training and test datasets have no common _user_id, ALS will fail
df_all = df_all.sort("_user_id").limit(SAMPLE_ROWS)
# Cast the column into the correct type
df_all = df_all.withColumn(RATING_COL, F.col(RATING_COL).cast("float"))
# Using a fraction between 0 and 1 returns the approximate size of the dataset; for example, 0.8 means 80% of the dataset
# Rating = 0 means the user didn't rate the item, so it can't be used for training
# We use the 80% of the dataset with rating > 0 as the training dataset
fractions_train = {0: 0}
fractions_test = {0: 0}
for i in ratings:
if i == 0:
continue
fractions_train[i] = 0.8
fractions_test[i] = 1
# Training dataset
train = df_all.sampleBy(RATING_COL, fractions=fractions_train)
# Join with leftanti will select all rows from df_all with rating > 0 and not in the training dataset; for example, the remaining 20% of the dataset
# test dataset
test = df_all.join(train, on="id", how="leftanti").sampleBy(
RATING_COL, fractions=fractions_test
)
La scarsità si riferisce a dati di feedback sparsi, che non possono identificare analogie negli interessi degli utenti. Per una migliore comprensione dei dati e del problema corrente, usare questo codice per calcolare la densità del set di dati:
# Compute the sparsity of the dataset
def get_mat_sparsity(ratings):
# Count the total number of ratings in the dataset - used as numerator
count_nonzero = ratings.select(RATING_COL).count()
print(f"Number of rows: {count_nonzero}")
# Count the total number of distinct user_id and distinct product_id - used as denominator
total_elements = (
ratings.select("_user_id").distinct().count()
* ratings.select("_item_id").distinct().count()
)
# Calculate the sparsity by dividing the numerator by the denominator
sparsity = (1.0 - (count_nonzero * 1.0) / total_elements) * 100
print("The ratings DataFrame is ", "%.4f" % sparsity + "% sparse.")
get_mat_sparsity(df_all)
# Check the ID range
# ALS supports only values in the integer range
print(f"max user_id: {df_all.agg({'_user_id': 'max'}).collect()[0][0]}")
print(f"max user_id: {df_all.agg({'_item_id': 'max'}).collect()[0][0]}")
Passaggio 3: Sviluppare e addestrare il modello
Addestrare un modello ALS per offrire agli utenti consigli personalizzati.
Definire il modello
Spark ML offre un'API pratica per la compilazione del modello ALS. Tuttavia, il modello non gestisce in modo affidabile i problemi come la densità dei dati e l'avvio a freddo (facendo raccomandazioni quando gli utenti o gli elementi sono nuovi). Per migliorare le prestazioni del modello, combinare la convalida incrociata e l'ottimizzazione automatica degli iperparametri.
Usare questo codice per importare le librerie necessarie per il training e la valutazione del modello:
# Import Spark required libraries
from pyspark.ml.evaluation import RegressionEvaluator
from pyspark.ml.recommendation import ALS
from pyspark.ml.tuning import ParamGridBuilder, CrossValidator, TrainValidationSplit
# Specify the training parameters
num_epochs = 1 # Number of epochs; here we use 1 to reduce the training time
rank_size_list = [64] # The values of rank in ALS for tuning
reg_param_list = [0.01, 0.1] # The values of regParam in ALS for tuning
model_tuning_method = "TrainValidationSplit" # TrainValidationSplit or CrossValidator
# Build the recommendation model by using ALS on the training data
# We set the cold start strategy to 'drop' to ensure that we don't get NaN evaluation metrics
als = ALS(
maxIter=num_epochs,
userCol="_user_id",
itemCol="_item_id",
ratingCol=RATING_COL,
coldStartStrategy="drop",
implicitPrefs=False,
nonnegative=True,
)
Ottimizzare gli iperparametri del modello
L'esempio di codice successivo costruisce una griglia di parametri per eseguire ricerche sugli iperparametri. Il codice crea anche un analizzatore di regressione che usa la radice dell'errore quadratico medio (RMSE) come metrica di valutazione:
# Construct a grid search to select the best values for the training parameters
param_grid = (
ParamGridBuilder()
.addGrid(als.rank, rank_size_list)
.addGrid(als.regParam, reg_param_list)
.build()
)
print("Number of models to be tested: ", len(param_grid))
# Define the evaluator and set the loss function to the RMSE
evaluator = RegressionEvaluator(
metricName="rmse", labelCol=RATING_COL, predictionCol="prediction"
)
L'esempio di codice successivo avvia diversi metodi di ottimizzazione del modello in base ai parametri preconfigurati. Per altre informazioni sull'ottimizzazione dei modelli, vedere ML Tuning: model selection and hyperparameter tuning (Ottimizzazione del modello: selezione del modello e ottimizzazione degli iperparametri) nel sito Web Apache Spark.
# Build cross-validation by using CrossValidator and TrainValidationSplit
if model_tuning_method == "CrossValidator":
tuner = CrossValidator(
estimator=als,
estimatorParamMaps=param_grid,
evaluator=evaluator,
numFolds=5,
collectSubModels=True,
)
elif model_tuning_method == "TrainValidationSplit":
tuner = TrainValidationSplit(
estimator=als,
estimatorParamMaps=param_grid,
evaluator=evaluator,
# 80% of the training data will be used for training; 20% for validation
trainRatio=0.8,
collectSubModels=True,
)
else:
raise ValueError(f"Unknown model_tuning_method: {model_tuning_method}")
Valutare il modello
Valutare i modelli rispetto ai dati di test. Un modello ben addestrato ha metriche elevate sul dataset.
Un modello eccessivamente adattato potrebbe richiedere più dati di addestramento o una riduzione di alcune caratteristiche ridondanti. Potrebbe essere necessario modificare l'architettura del modello o ottimizzarne i parametri.
Nota
Un valore di metrica R quadrato negativo indica che il modello sottoposto a training ha prestazioni peggiori rispetto a una linea retta orizzontale. Questa ricerca suggerisce che il modello sottoposto a training non spiega i dati.
Usare questo codice per definire una funzione di valutazione:
def evaluate(model, data, verbose=0):
"""
Evaluate the model by computing rmse, mae, r2, and variance over the data.
"""
predictions = model.transform(data).withColumn(
"prediction", F.col("prediction").cast("double")
)
if verbose > 1:
# Show 10 predictions
predictions.select("_user_id", "_item_id", RATING_COL, "prediction").limit(
10
).show()
# Initialize the regression evaluator
evaluator = RegressionEvaluator(predictionCol="prediction", labelCol=RATING_COL)
_evaluator = lambda metric: evaluator.setMetricName(metric).evaluate(predictions)
rmse = _evaluator("rmse")
mae = _evaluator("mae")
r2 = _evaluator("r2")
var = _evaluator("var")
if verbose > 0:
print(f"RMSE score = {rmse}")
print(f"MAE score = {mae}")
print(f"R2 score = {r2}")
print(f"Explained variance = {var}")
return predictions, (rmse, mae, r2, var)
Rilevamento dell'esperimento tramite MLflow
Usare MLflow per rilevare tutti gli esperimenti e registrare parametri, metriche e modelli. Per avviare il training e la valutazione del modello, usare questo codice:
from mlflow.models.signature import infer_signature
with mlflow.start_run(run_name="als"):
# Train models
models = tuner.fit(train)
best_metrics = {"RMSE": 10e6, "MAE": 10e6, "R2": 0, "Explained variance": 0}
best_index = 0
# Evaluate models
# Log models, metrics, and parameters
for idx, model in enumerate(models.subModels):
with mlflow.start_run(nested=True, run_name=f"als_{idx}") as run:
print("\nEvaluating on test data:")
print(f"subModel No. {idx + 1}")
predictions, (rmse, mae, r2, var) = evaluate(model, test, verbose=1)
signature = infer_signature(
train.select(["_user_id", "_item_id"]),
predictions.select(["_user_id", "_item_id", "prediction"]),
)
print("log model:")
mlflow.spark.log_model(
model,
f"{EXPERIMENT_NAME}-alsmodel",
signature=signature,
registered_model_name=f"{EXPERIMENT_NAME}-alsmodel",
dfs_tmpdir="Files/spark",
)
print("log metrics:")
current_metric = {
"RMSE": rmse,
"MAE": mae,
"R2": r2,
"Explained variance": var,
}
mlflow.log_metrics(current_metric)
if rmse < best_metrics["RMSE"]:
best_metrics = current_metric
best_index = idx
print("log parameters:")
mlflow.log_params(
{
"subModel_idx": idx,
"num_epochs": num_epochs,
"rank_size_list": rank_size_list,
"reg_param_list": reg_param_list,
"model_tuning_method": model_tuning_method,
"DATA_FOLDER": DATA_FOLDER,
}
)
# Log the best model and related metrics and parameters to the parent run
mlflow.spark.log_model(
models.subModels[best_index],
f"{EXPERIMENT_NAME}-alsmodel",
signature=signature,
registered_model_name=f"{EXPERIMENT_NAME}-alsmodel",
dfs_tmpdir="Files/spark",
)
mlflow.log_metrics(best_metrics)
mlflow.log_params(
{
"subModel_idx": idx,
"num_epochs": num_epochs,
"rank_size_list": rank_size_list,
"reg_param_list": reg_param_list,
"model_tuning_method": model_tuning_method,
"DATA_FOLDER": DATA_FOLDER,
}
)
Selezionare l'esperimento denominato aisample-recommendation dall'area di lavoro per visualizzare le informazioni di log per l'esecuzione dell'addestramento. Se si modifica il nome dell'esperimento, selezionare l'esperimento con il nuovo nome. Le informazioni registrate sono simili a questa immagine:

Passaggio 4: caricare il modello finale per l'assegnazione dei punteggi ed eseguire previsioni
Dopo aver completato il training del modello e aver selezionato il modello migliore, caricare il modello per l'assegnazione dei punteggi (talvolta definito inferenza). Questo codice carica il modello e usa le stime per consigliare i primi 10 libri per ogni utente:
# Load the best model
# MLflow uses PipelineModel to wrap the original model, so we extract the original ALSModel from the stages
model_uri = f"models:/{EXPERIMENT_NAME}-alsmodel/1"
loaded_model = mlflow.spark.load_model(model_uri, dfs_tmpdir="Files/spark").stages[-1]
# Generate top 10 book recommendations for each user
userRecs = loaded_model.recommendForAllUsers(10)
# Represent the recommendations in an interpretable format
userRecs = (
userRecs.withColumn("rec_exp", F.explode("recommendations"))
.select("_user_id", F.col("rec_exp._item_id"), F.col("rec_exp.rating"))
.join(df_items.select(["_item_id", "Book-Title"]), on="_item_id")
)
userRecs.limit(10).show()
L'output è simile a questa tabella:
| _item_id | _user_id | valutazione | Titolo-libro |
|---|---|---|---|
| 44865 | 7 | 7.9996786 | Lasher: Vite di ... |
| 786 | 7 | 6.2255826 | Il D del Pianista... |
| 45330 | 7 | 4.980466 | Stato della mente |
| 38960 | 7 | 4.980466 | Tutto quello che ha mai voluto |
| 125415 | 7 | 4.505084 | Harry Potter e ... |
| 44939 | 7 | 4.3579073 | Taltos: Vite di ... |
| 175247 | 7 | 4.3579073 | Il Bonesetter è ... |
| 170183 | 7 | 4,228735 | Vivere il semplice... |
| 88503 | 7 | 4.221206 | Isola del Blu... |
| 32894 | 7 | 3,9031885 | Solstizio d'inverno |
Salvare le previsioni nel lakehouse
Usare questo codice per scrivere di nuovo le raccomandazioni nel lakehouse:
# Code to save userRecs into the lakehouse
userRecs.write.format("delta").mode("overwrite").save(
f"{DATA_FOLDER}/predictions/userRecs"
)