Introduzione a Visione artificiale di Azure
La possibilità per i sistemi informatici di elaborare testo scritto e stampato è un'area di intelligenza artificiale in cui visione artificiale interseca con l'elaborazione del linguaggio naturale. Le funzionalità di visione sono necessarie per "leggere" il testo e quindi le funzionalità di elaborazione del linguaggio naturale ne hanno senso.
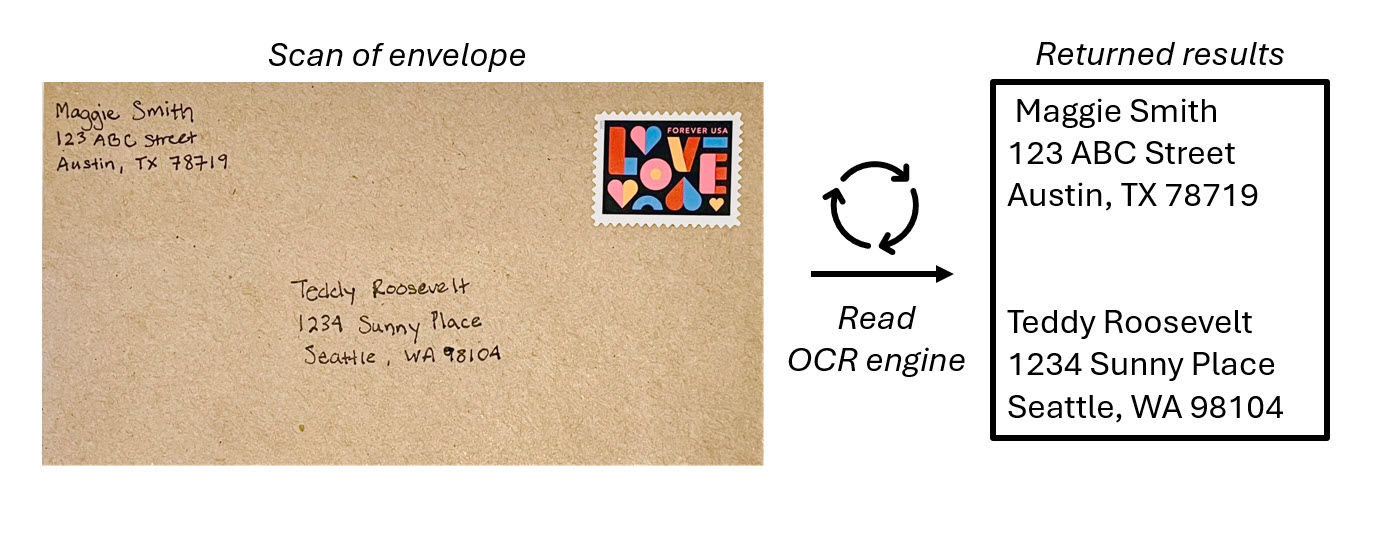
OCR è la base dell'elaborazione del testo nelle immagini e usa modelli di Machine Learning sottoposti a training per riconoscere singole forme come lettere, numeri, punteggiatura o altri elementi di testo. Gran parte del lavoro iniziale sull'implementazione di questo tipo di funzionalità è stata eseguita dai servizi postali per supportare l'ordinamento automatico della posta in base ai codici postali. Da allora, lo stato dell'arte per la lettura del testo è stato spostato e abbiamo modelli che rilevano testo stampato o scritto a mano in un'immagine e leggono riga per riga e parola per parola.
Motore OCR di Visione artificiale di Azure
Il servizio Visione artificiale di Azure ha la possibilità di estrarre testo leggibile dal computer dalle immagini. L'API di lettura di Visione artificiale di Azure è il motore OCR che supporta l'estrazione di testo da immagini, PDF e file TIFF. OCR per le immagini è ottimizzato per immagini generali e non documentate che semplificano l'incorporamento di OCR negli scenari di esperienza utente.
L'API Lettura, nota come motore OCR di lettura , usa i modelli di riconoscimento più recenti ed è ottimizzata per le immagini con una quantità significativa di testo o con un notevole rumore visivo. Può determinare automaticamente il modello di riconoscimento appropriato da usare prendendo in considerazione il numero di righe di testo, immagini che includono testo e grafia.
Il motore OCR acquisisce un file di immagine e identifica i rettangoli di delimitazione o le coordinate, in cui gli elementi si trovano all'interno di un'immagine. In OCR il modello identifica i rettangoli di delimitazione intorno a qualsiasi elemento che sembra essere testo nell'immagine.
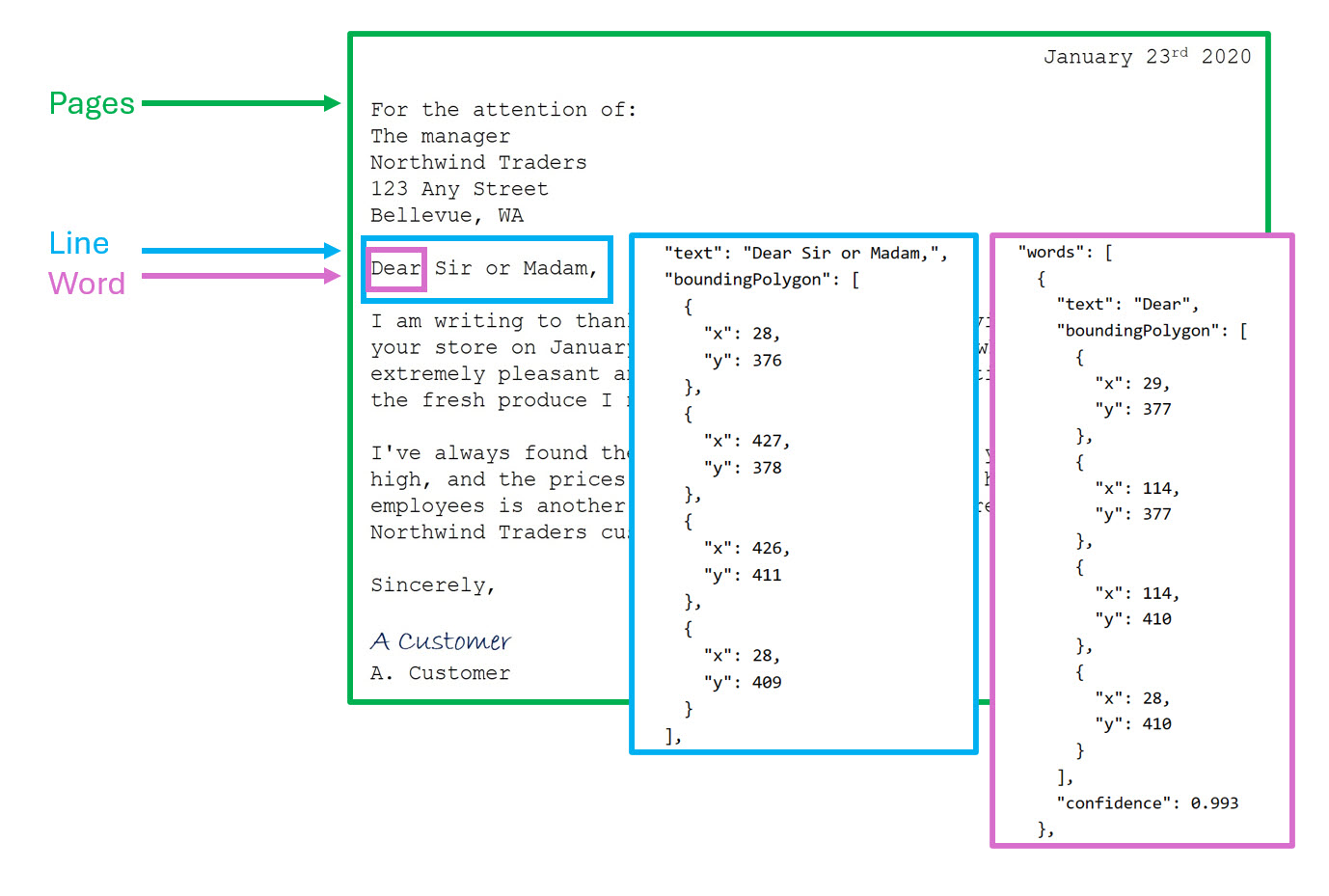
La chiamata all'API lettura restituisce i risultati disposti nella gerarchia seguente:
- pagine: una per ogni pagina di testo, incluse le informazioni sulle dimensioni e l'orientamento della pagina.
- Righe : righe di testo in una pagina.
- Parole : parole in una riga di testo, incluse le coordinate del rettangolo delimitatore e il testo stesso.
Ogni riga e parola include coordinate del rettangolo di delimitazione che ne indicano la posizione nella pagina.