監視と監視は、Azure Kubernetes Service (AKS) での AI ワークロードデプロイの高パフォーマンスと低コストを維持する上で重要な役割を果たします。 システムとパフォーマンスのメトリックの可視性は、基になるインフラストラクチャの制限を示し、ワークロードの中断を減らすためにリアルタイムの調整と最適化の動機付けを行うことができます。 また、監視は、コンピューティング リソースのコスト効率の高い管理と正確なプロビジョニングのためのリソース使用率に関する貴重な分析情報も提供します。
Kubernetes AI Toolchain Operator (KAITO) は、AKS クラスター内の AI モデルのデプロイと操作を簡略化する AKS 用のマネージド アドオンです。
KAITO バージョン 0.4.4 以降のバージョンでは、aKS マネージド アドオンで vLLM 推論ランタイムが既定で有効になっています。 vLLM は、言語モデルの推論と提供のためのライブラリです。 KAITO 推論デプロイの評価に使用できる Prometheus メトリック の主要なシステム パフォーマンス、リソース使用量、および要求処理が表示されます。
重要
AKS のプレビュー機能は、セルフサービスのオプトイン単位で利用できます。 プレビューは、"現状有姿のまま" および "利用可能な限度" で提供され、サービス レベル アグリーメントおよび限定保証から除外されるものとします。 AKS プレビューは、ベストエフォート ベースでカスタマー サポートによって部分的にカバーされます。 そのため、これらの機能は、運用環境での使用を意図していません。 詳細については、次のサポート記事を参照してください。
この記事では、Azure の Prometheus と AKS クラスターの Azure Managed Grafana のマネージド サービスで AI ツールチェーン オペレーター アドオンを使用して、vLLM 推論メトリックを監視および視覚化する方法について説明します。
開始する前に
- この記事では、既存の AKS クラスターがすでにあることを前提としています。 クラスターがない場合は、 Azure CLI、 Azure PowerShell、または Azure portal を使用してクラスターを作成します。
- Azure CLI バージョン 2.47.0 以降をインストールして構成します。 バージョンを確認するには、
az --versionを実行します。 インストールまたは更新するには、「 Azure CLI のインストール」を参照してください。
前提条件
- Kubernetes コマンド ライン クライアントである kubectl をインストールして構成します。 詳細については、kubectl のインストールに関するページを参照してください。
- AKS クラスターで AI ツールチェーン オペレーター アドオン を有効にします。
- AI ツールチェーン オペレーター アドオンが既に有効になっている場合は、KAITO v0.4.4 以降を実行するように AKS クラスターを最新バージョンに更新します。
- AKS クラスター で Prometheus と Azure Managed Grafana のマネージド サービス を有効にします。
- Azure サブスクリプションで Azure Managed Grafana インスタンスを作成または更新するための アクセス許可を持っている。
KAITO 推論サービスをデプロイする
この例では、 Qwen-2.5-coder-7B-instruct 言語モデルのメトリックを収集します。
まず、次の KAITO ワークスペース カスタム リソースをクラスターに適用します。
kubectl apply -f https://raw.githubusercontent.com/Azure/kaito/main/examples/inference/kaito_workspace_qwen_2.5_coder_7b-instruct.yamlKAITO ワークスペースでライブ リソースの変更を追跡します。
kubectl get workspace workspace-qwen-2-5-coder-7b-instruct -w注
マシンの準備には最大 10 分かかる場合があり、言語モデルのサイズによってはワークスペースの準備に最大 20 分かかることがあります。
推論サービスが実行されていることを確認し、サービスの IP アドレスを取得します。
export SERVICE_IP=$(kubectl get svc workspace-qwen-2-5-coder-7b-instruct -o jsonpath='{.spec.clusterIP}') echo $SERVICE_IP
Prometheus のマネージド サービスに対する Surface KAITO 推論メトリック
Prometheus メトリックは、KAITO /metrics エンドポイントで既定で収集されます。
Kubernetes
ServiceMonitorデプロイで検出できるように、KAITO 推論サービスに次のラベルを追加します。kubectl label svc workspace-qwen-2-5-coder-7b-instruct App=qwen-2-5-coderServiceMonitorリソースを作成して、推論サービス エンドポイントと、vLLM Prometheus メトリックをスクレイピングするために必要な構成を定義します。 次のServiceMonitorYAML マニフェストをkube-system名前空間にデプロイして、Prometheus のマネージド サービスにこれらのメトリックをエクスポートします。cat <<EOF | kubectl apply -n kube-system -f - apiVersion: azmonitoring.coreos.com/v1 kind: ServiceMonitor metadata: name: prometheus-kaito-monitor spec: selector: matchLabels: App: qwen-2-5-coder endpoints: - port: http interval: 30s path: /metrics scheme: http EOF次の出力を確認して、
ServiceMonitorが作成されていることを確認します。servicemonitor.azmonitoring.coreos.com/prometheus-kaito-monitor createdServiceMonitorデプロイが正常に実行されていることを確認します。kubectl get servicemonitor prometheus-kaito-monitor -n kube-systemAzure portal で、Prometheus のマネージド サービスで vLLM メトリックが正常に収集されていることを確認します。
Azure Monitor ワークスペースで、 Managed Prometheus>Prometheus エクスプローラーに移動します。
[ グリッド ] タブを選択し、メトリック項目が
workspace-qwen-2-5-coder-7b-instructという名前のジョブに関連付けられていることを確認します。注
この項目の
up値は1する必要があります。1の値は、Prometheus メトリックが AI 推論サービス エンドポイントから正常にスクレイピングされていることを示します。
Azure Managed Grafana で KAITO 推論メトリックを視覚化する
vLLM プロジェクトには、推論ワークロードの監視に grafana.json という名前の Grafana ダッシュボード構成が用意されています。
サンプル ページの下部に移動し、
grafana.jsonファイルの内容全体をコピーします。
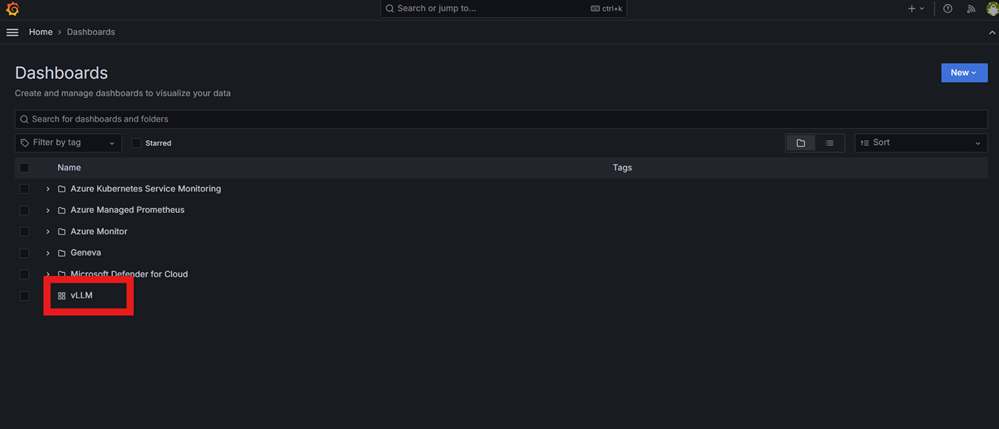
Azure Managed Grafana の新しいダッシュボードに Grafana 構成をインポートする手順を完了します。
Managed Grafana エンドポイントに移動し、使用可能なダッシュボードを表示して、 vLLM ダッシュボードを選択します。
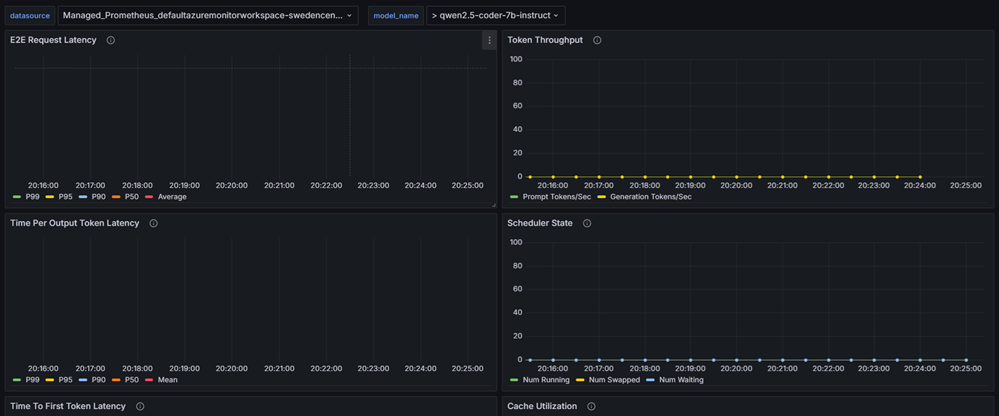
選択したモデル デプロイのデータ収集を開始するには、Grafana ダッシュボードの左上に表示される データソース 値が、この例用に作成した Prometheus のマネージド サービスのインスタンスであることを確認します。
KAITO ワークスペースで定義されている推論プリセット名を、Grafana ダッシュボードの model_name フィールドにコピーします。 この例では、モデル名は qwen2.5-coder-7b-instruct です。
しばらくして、KAITO 推論サービスのメトリックが vLLM Grafana ダッシュボードに表示されることを確認します。
注
これらの推論メトリックの値は、要求がモデル推論サーバーに送信されるまで 0 のままです。



関連コンテンツ
GitHub で Microsoft と共同作業する
このコンテンツのソースは GitHub にあります。そこで、issue や pull request を作成および確認することもできます。 詳細については、共同作成者ガイドを参照してください。

Azure Kubernetes Service