自然言語処理には、テキスト データから人間の言語を分析、理解、生成する手法が含まれます。 Azureでは、感情分析やエンティティ認識からドキュメント分類やテキスト要約まで、自然言語処理ワークロードに対応するマネージド API 駆動型サービスと分散オープン ソース フレームワークが提供されます。 このガイドは、適切なテクノロジをワークロードの要件に合わせることができるように、Azureの主要な自然言語処理オプションを評価して選択するのに役立ちます。
注
このガイドでは、Azure Language および Apache Spark と Spark NLP (Azure Databricks または Microsoft Fabric で使用できる自然言語処理機能について説明します。 言語モデルを選択したり、OpenAI ソリューションAzure設計したりする方法に関するガイダンスは提供されていません。 一部のプラットフォームの説明では、サポートされている基盤モデルまたは音声モデルの統合を実装の詳細として参照する場合がありますが、このガイドでは自然言語処理サービスの選択に焦点を当てています。 詳細については、「 AI サービス テクノロジの選択」を参照してください。
自然言語処理と言語モデルを理解する
Azureサービスを評価する前に、自然言語処理とは何か、言語モデルとの違い、対処するタスクを理解してください。
自然言語処理と言語モデルの区別
このセクションでは、自然言語処理と言語モデルの境界を明らかにし、自然言語処理手法で有効なコア機能について調査します。
| ディメンション | 自然言語処理 | 言語モデル |
|---|---|---|
| Scope | トークン化、ステミング、エンティティ認識、センチメント分析、ドキュメント分類など、多様なテキスト処理手法をカバーする幅広い分野。 | 高度な言語理解と生成タスクに重点を置いた自然言語処理のディープ ラーニング サブセット。 |
| 例示 | ルールベースのパーサー、用語頻度-逆ドキュメント頻度 (TF-IDF) 分類子、名前付きエンティティ認識エンジン、センチメント アナライザー。 | GPT、BERT、および同様のトランスフォーマーベースのモデルは、人間のようにコンテキストを理解してテキストを生成します。 |
| アウトプット | ラベル、スコア、抽出されたスパン、解析された構文などの構造化シグナル。 | 流暢な自然言語である生成されたテキスト、要約、回答、完了など。 |
| Relationship | 親ドメイン。 自然言語処理には、テキスト処理メソッドの全範囲が含まれます。 | 自然言語処理内のツール。 言語モデルは、自然言語処理を置き換えることなく強化します。 より広範なコグニティブ タスクを処理しますが、自然言語処理と同義ではありません。 |
自然言語処理機能
機密またはスパムとしてラベルを付けることで、ドキュメントを分類します。 自然言語処理では、コンプライアンスとフィルター処理のワークフローをサポートするために、コンテンツに基づいてドキュメントが自動的に分類されます。
ドキュメント内のエンティティを識別してテキストを要約します。 自然言語処理では、重要なエンティティが抽出され、最も重要な情報をキャプチャする簡潔な概要が生成されます。
識別されたエンティティを使用して、キーワードを使用してドキュメントにタグ付けします。 エンティティを識別したら、ドキュメントの編成を簡略化するキーワード タグを生成できます。 これらのタグは、コンテンツ ベースの検索と取得に使用します。
ナビゲーションと関連するドキュメント検出のトピックを検出します。 自然言語処理では、ドキュメントの分類とトピックベースのナビゲーションをサポートする抽出されたエンティティを使用して、主要なトピックを識別します。
テキストセンチメントを評価します。 感情分析は、テキストの感情的なトーンを評価し、コンテンツを肯定的、否定的、または中立として分類します。
自然言語処理の出力をダウンストリーム ワークフローにフィードします。 抽出されたエンティティ、センチメント スコア、トピック ラベルなどの結果は、処理、検索インデックス作成、分析の入力として機能します。
潜在的なユース ケースを特定する
多くの業界のビジネス シナリオでは、自然言語処理ソリューションの利点があります。 次のユース ケースは、非構造化ドキュメントの処理から、サイバーセキュリティとアクセシビリティにおける新しいアプリケーションの有効化まで、自然言語処理手法が実際の課題にどのように対処するかを示しています。
ドキュメントと非構造化テキストを処理する
コンピューターで作成されたドキュメントからインテリジェンスを抽出します。 自然言語処理を使用すると、財務、医療、小売、政府、その他のセクター全体でドキュメント処理を行えます。 デジタルで作成されたドキュメントを分析して、構造化されていない入力から構造化情報を抽出できます。 手書きドキュメントの場合は、自然言語処理手法を適用する前に、Azure ドキュメント インテリジェンス を使用して手書きのコンテンツをテキストに変換します。
テキスト処理には、業界に依存しない自然言語処理タスクを適用します。 名前付きエンティティ認識 (NER)、分類、要約、関係抽出は、非構造化ドキュメント コンテンツを自動的に処理および分析するのに役立ちます。 これらのタスクはドメイン間で機能し、業界固有のカスタマイズは必要ありません。
特殊化された分析のためのドメイン固有のモデルを構築します。 これらのタスクの例としては、医療のリスク階層化モデル、ナレッジ管理のためのオントロジ分類、製品と顧客データの小売りの要約などがあります。 Azure 言語および Spark NLP でのカスタム モデル トレーニングは、これらのドメイン固有のドキュメント形式の精度を向上するのに役立ちます。
構造化データ入力から自動レポートを生成します。 構造化データから包括的なテキスト レポートを合成して生成できます。 この機能は、財務やコンプライアンスなど、徹底的なドキュメントを必要とするセクターに役立ちます。
検索、翻訳、分析を有効にする
ナレッジ グラフを作成し、情報の取得によるセマンティック検索を有効にします。 自然言語処理では、ナレッジ グラフの作成とセマンティック検索がサポートされています。これにより、システムはキーワード マッチングのみに依存するのではなく、クエリの意味を解釈できます。
医学知識グラフを使用して、創薬と臨床試験をサポートします。 自然言語処理システムは、臨床テキストを分析します。 そのテキストから構築された医療知識グラフは、創薬パイプラインと臨床試験マッチングをサポートします。 これらのグラフは、薬物、条件、結果などのエンティティを結び付けて、研究ワークフローを高速化します。 Azure 言語のテキスト分析では、これらのグラフの構築に使用できる医療エンティティ、関係、アサーションが抽出されます。
顧客向けアプリケーションで会話型 AI のテキストを翻訳します。 テキスト翻訳により、複数の業界にわたる会話型 AI が可能になります。 ユーザーの優先言語で処理および応答する多言語の顧客向けアプリケーションを構築できます。 Spark NLP は翻訳機能を直接提供します。 Azureでは、Azure 言語とは別のサービスである Azure Translator を使用します。
ブランドの認識のためにセンチメントと感情インテリジェンスを分析します。 感情分析は、テキストから肯定的、否定的、微妙な感情信号を表示することで、ブランドの認識を監視し、顧客のフィードバックを分析するのに役立ちます。
自然言語処理を新しいドメインに拡張する
モノのインターネット (IoT) とスマート デバイス用の音声アクティブ化インターフェイスを構築します。 自然言語処理は、音声認識システムのテキスト出力を処理して、ユーザーの意図を理解し、IoT とスマート デバイスのシナリオで意味を抽出します。 音声でアクティブ化されるシナリオでは、自然言語処理の前に音声からテキストへの変換にAzure Speech が必要です。
アダプティブ言語モデルを使用して言語出力を動的に調整します。 アダプティブ言語モデルは、さまざまな対象ユーザーの理解レベルに合わせて言語出力を動的に調整します。これは、教育コンテンツの配信とアクセシビリティをサポートします。
サイバーセキュリティ テキスト分析を使用して、フィッシング詐欺や誤った情報を検出します。 自然言語処理では、通信パターンと言語の使用状況をリアルタイムで分析し、デジタル通信における潜在的なセキュリティ上の脅威を特定します。 この分析は、フィッシング詐欺の試行と誤った情報のキャンペーンを検出するのに役立ちます。
Azure言語の評価
Azure Language は、テキストを理解して分析するための自然言語処理機能を提供するクラウドベースのサービスです。 Foundry ポータル、REST API、Python、C#、Java、および JavaScript 用のクライアント ライブラリからアクセスできます。管理するインフラストラクチャはありません。 AI エージェントの開発では、Azure言語モデル コンテキスト プロトコル (MCP) サーバーを介してこれらの機能にアクセスすることもできます。 Microsoft Foundry ツール カタログ内のリモート サーバーとして、またはローカルのセルフホステッド サーバーとしてアクセスできます。
事前構築済みの機能
事前構築済みの機能では、モデル トレーニングは必要なく、使用する準備が整います。
NER: テキスト内のエンティティを識別し、ユーザー、組織、場所、日付などの定義済みの型に分類します。
PII 検出: 機密性の高い個人データや健康データなど、個人を特定できる情報 (PII) をテキストおよび文字起こしされた会話で識別して編集します。
言語検出: さまざまな言語と方言にわたるドキュメントの言語を検出します。
感情分析とオピニオン マイニング: テキスト内の肯定的、否定的、または中立的なセンチメントを識別し、製品属性やサービスの側面などの特定の要素に意見をリンクします。
キー フレーズ抽出: 非構造化テキストを評価し、主要な概念とキー フレーズの一覧を返します。
概要:テキスト、チャット、コール センターの要約をサポートする抽出アプローチまたは抽象アプローチを使用して、ドキュメントと会話を圧縮します。
健康のためのテキスト分析: 非構造化の臨床テキストから医療用語、関係、主張を含む関連する健康情報を抽出してラベル付けします。
カスタム モデルをトレーニングする
カスタマイズ可能な機能を使用してデータのモデルをトレーニングし、ドメイン固有の自然言語処理タスクを処理できます。
- カスタムの名前付きエンティティ認識 (CNER): 非構造化テキストからドメイン固有のエンティティ カテゴリを抽出するカスタム モデルを構築します。 事前構築済みの NER カテゴリがドメインボキャブラリをカバーしていない場合は、CNER を使用します。
Azure 言語 MCP サーバーとエージェント
注
Azure言語 MCP サーバーと、意図ルーティングと正確な質問の回答エージェントの両方がプレビュー段階にあります。 プレビュー機能にはサービス レベル アグリーメント (SLA) は含まれていません。運用環境のワークロードにはお勧めしません。 一部の機能はサポートされていないか、機能が限られている可能性があります。 詳細については、「Microsoft Azure プレビューの使用条件を参照してください。
Azure言語は、運用の自然言語処理ワークロードに対して事前構築済みのエージェントと柔軟なデプロイ オプションを提供します。
インテント ルーティング エージェント: 会話フローを管理します。 これは、決定論的で監査可能なロジックを使用して、ユーザーの意図と正確な応答へのルーティングを理解します。 透過的で確定的な会話ルーティングが必要な場合は、このエージェントを使用します。
正確な質問回答エージェント: 人間の監視と品質管理を維持しながら、ビジネスクリティカルな質問に対する信頼性の高い単語単位の応答を提供します。 応答の精度と一貫性が不可欠な場合は、このエージェントを使用します。
Foundry ツール カタログから両方のエージェントにアクセスできます。 詳細については、「Azure 言語 MCP サーバーとエージェント (プレビュー)を参照してください。
Azure言語 MCP サーバーでは、複数の展開オプションがサポートされています。
リモート クラウドでホストされる MCP サーバー: Foundry ツール カタログには、このサーバーが一覧表示されます。 サーバーは、Azure言語機能へのクラウド管理アクセスを提供し、ローカル インフラストラクチャを必要としません。
ローカルのセルフホステッド MCP サーバー: コンプライアンス、セキュリティ、またはデータ所在地の要件に対して、オンプレミスまたは自己管理型のデプロイをサポートします。
コンテナー化されたデプロイ: 次の機能は、ローカル処理またはエアギャップ環境を必要とするシナリオのコンテナー化されたデプロイをサポートします。 使用可能なコンテナーとその可用性の状態の完全な一覧については、Azure AI コンテナーのサポートを参照してください。
- センチメント分析
- 言語検出
- キー フレーズ抽出
- NER
- PII 検出
- CNER
- Text Analytics for Health
- 概要 (プレビュー)
Spark NLP を使用して Apache Spark を評価する
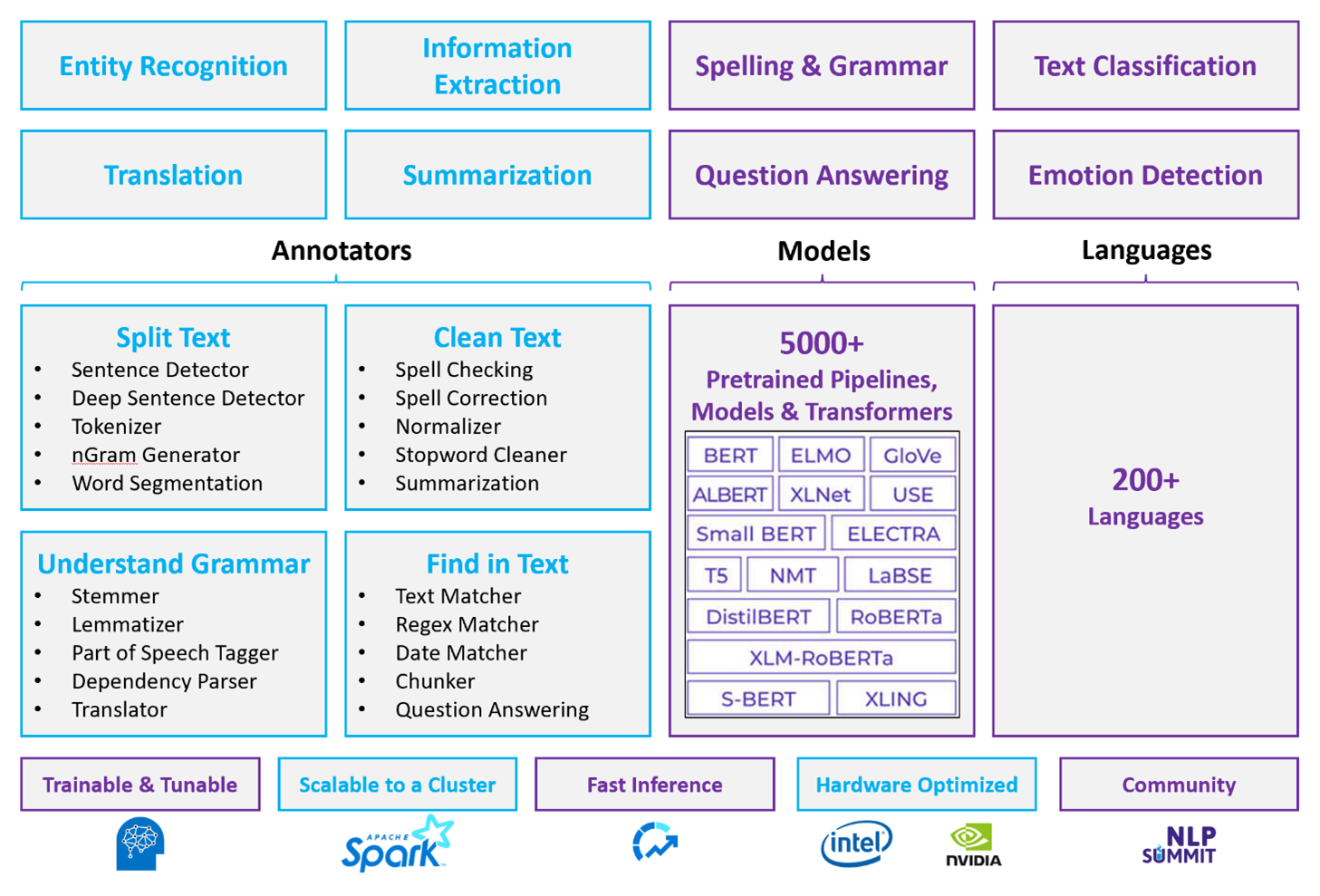
Apache Spark と Spark NLP は、クラスター規模で動作する自然言語処理に対する分散型のオープンソース アプローチです。 Spark NLP プラットフォームのアーキテクチャ、パフォーマンス、事前構築済みのモデル エコシステムにより、Azure Databricks または Fabric 上の大規模でカスタマイズ可能な自然言語処理ワークロードに対する強力なオプションになります。
プラットフォームとアーキテクチャについて
Apache Spark ベースの自然言語処理ワークロードには、Fabric または Azure Databricks を使用することをお勧めします。
Apache Spark は、ビッグ データ分析用の並列メモリ内処理を提供します。 FabricとAzure Databricksを使用すると、大規模な自然言語処理ワークロード用の Apache Spark 処理機能にアクセスできます。
Spark NLP は、データ フレーム上の Spark ML のネイティブ拡張機能として動作します。 この統合により、分散クラスターのパフォーマンスが向上した、統一された自然言語処理と機械学習パイプラインが可能になります。
Spark NLP は、Python、Java、Scala をサポートするオープンソース ライブラリです。 このライブラリには、スペル チェック、センチメント分析、ドキュメント分類など、 spaCy および 自然言語ツールキット (NLTK) に相当する機能が用意されています。

Apache®、Apache Spark、および炎のロゴは、United Statesおよびその他の国の Apache Software Foundation の登録商標または商標です。 これらのマークを使用することが、Apache Software Foundation による保証を意味するものではありません。
パフォーマンスとスケーラビリティを評価する
パブリック ベンチマークでは、他の 自然言語処理ライブラリに比べて大幅な速度の向上が示されています。 Spark NLP は、spaCy や NLTK などのフレームワークと比較して、分散クラスターでのトレーニングと推論の高速化を示します。 Spark NLP がトレーニングするカスタム モデルは、他の自然言語処理フレームワークと一致する精度レベルに達します。これにより、速度と精度を必要とする運用環境のワークロードに適しています。
CPU、GPU、Intel Xeon チップ用に最適化されたビルドでは、Apache Spark クラスターが完全に使用されます。 これらのビルドを使用すると、トレーニングと推論をクラスター ノード間で効率的にスケーリングできます。
MPNet 埋め込みと ONNX のサポートにより、コンテキストに対応した正確な処理が可能になります。 MPNet ではセマンティックな意味をキャプチャする高密度ベクター表現が生成され、 ONNX のサポート により、推論用に最適化されたモデルをインポートして実行できます。
事前構築済みのモデルとパイプラインを使用する
事前構築済みのディープ ラーニング モデルは、NER、ドキュメント分類、センチメント検出を処理します。 ライブラリには、事前構築済みのディープ ラーニング モデルが付属しています。
事前トレーニング済みの言語モデルでは、単語、チャンク、文、ドキュメントの埋め込みをサポートしています。 ライブラリには、単語、チャンク、文、ドキュメント埋め込みレベルをサポートする事前トレーニング済みの言語モデルが含まれています。 これらの埋め込みでは、類似性検索や分類などのダウンストリーム タスクを可能にする高密度ベクター表現が提供されます。
統一された自然言語処理と機械学習パイプラインは、ドキュメントの分類とリスク予測をサポートします。 Spark ML との統合では、ドキュメントの分類やリスク予測などのタスクに対して、統一された自然言語処理と機械学習パイプラインがサポートされます。 この統合されたアプローチでは、テキスト処理と従来の機械学習モデルを 1 つのパイプラインで組み合わせて、アーキテクチャの複雑さを軽減できます。
一般的な自然言語処理の課題に対処する
Azure Language と Apache Spark と Spark NLP の両方が、大規模な自然言語処理において一般的な課題に直面しています。 これらの課題を理解している場合は、いずれかのオプションにコミットする前に、リソースを計画し、パイプラインを設計し、精度の期待値を設定できます。
リソース処理
自由形式のテキストを処理するには、大量の計算リソースと時間が必要です。 自由形式のテキスト ドキュメントは、計算コストが高く、分析に時間がかかります。 すべてのドキュメントでは、使用可能な結果を生成する前に、トークン化、正規化、およびモデル推論が必要です。
Spark NLP ワークロードでは、多くの場合、GPU コンピューティングのデプロイが必要です。 大規模な Spark NLP パイプラインの場合、Azure Databricks または Fabric 上の GPU アクセラレーション クラスターは、トレーニングと推論に必要な並列処理能力を提供します。 Llama 3.x モデル量子化などの最適化は、メモリ占有領域を削減し、これらの集中的なタスクのスループットを向上するのに役立ちます。
Azure言語では、スループットの計画とクォータ管理が必要です。 このサービスはリソース管理を処理しますが、大量の API 呼び出しには慎重なスループット計画が必要です。 調整を回避し、一貫した処理パフォーマンスを確保するために、サービスの制限とレート制限に対して要求レートを監視します。
ドキュメントの標準化
実際のドキュメントが一貫した構造に従うことはめったにありません。 この不整合により、抽出パイプラインの課題が生じ、ソース間で精度を維持するための意図的な戦略が必要になります。
一貫性のない形式: 標準化されたドキュメント形式がないと、自由形式のテキストから特定の事実を抽出するのが難しい場合があります。 たとえば、フィールドレイアウト、ラベル、書式はソースによって異なるため、異なるベンダーから請求書番号と日付を抽出するのは困難な場合があります。
Custom モデルトレーニング: Spark NLP と Azure 言語 でカスタム モデルをトレーニングする場合は、ドメイン固有のドキュメント形式に適応できます。 実際のドキュメントの代表的なサンプルをトレーニングすると、事前構築済みモデルでは適切に処理されないフィールド、エンティティ、パターンの抽出精度を向上させることができます。
データの多様性と複雑さ
多様なドキュメント構造と言語的な差異により、複雑さが増します。 実際のテキスト データには、さまざまな形式、書き方、言語が用意されています。 これらのバリエーションに対処するには、精度を維持しながら、あいまいさ、スラング、省略形、ドメイン固有の用語を処理できるモデルが必要です。
Spark NLP の MPNet 埋め込みにより、コンテキストの理解が強化されます。 MPNet 埋め込みでは、単語と語句の間のコンテキスト関係がキャプチャされます。これは、Spark NLP パイプラインが微妙なテキストをより効果的に処理するのに役立ちます。 これらの埋め込みにより、さまざまなドキュメント形式でセマンティックな意味を保持する高密度ベクター表現が生成されます。
Azure言語のカスタム モデルは、ドメイン固有のテキスト パターンに適応します。 CNER を使用すると、独自のラベル付きデータでモデルをトレーニングして、ドメインに固有のパターンを認識できます。 このアプローチでは、事前構築済みモデルが見逃しているエンティティとカテゴリを認識するようにモデルに教えることで、信頼性が向上します。
キー選択条件を適用する
次の条件を使用して、要件に最も適Azure自然言語処理オプションを決定します。 各条件は、ワークロードの特性を記述し、それに対処するサービスを識別します。
自然言語処理機能の管理: エンティティの認識、意図の識別、トピック検出、センチメント分析に Azure Language API を使用します。 これらの機能は、最小限のセットアップでマネージド サービスとして利用でき、インフラストラクチャをプロビジョニングまたは管理する必要はありません。
事前構築済みモデルまたは事前トレーニング済みモデル: インフラストラクチャを管理せずに事前構築済みモデルまたは事前トレーニング済みモデルを使用する場合は、Azure言語を使用します。 このアプローチは、事前構築済みのモデルが十分な精度を提供する小規模から中規模のデータセットや標準の自然言語処理タスクに適しています。 クラスター管理のオーバーヘッドなしで、自動スケーリング、組み込みのセキュリティ、および呼び出しごとの支払い価格が提供されます。
大きなテキスト データセットに対するCustom モデルトレーニング: Spark NLP で Azure Databricks または Fabric を使用します。 これらのプラットフォームは、大規模なテキスト データセットに対する広範なモデル トレーニングに必要な計算能力と柔軟性を提供します。 Llama 3.x や MPNet など、Spark NLP を使用してモデルをダウンロードすることもできます。
低レベルの自然言語処理プリミティブ: トークン化、ステミング、レンマ化、TF-IDF には、Azure Databricks または Fabric と Spark NLP を使用します。 または、spaCy や NLTK などのオープン ソース ライブラリを使用します。 Foundry Tools のAzure言語では、モデル パイプラインの一部として内部的にトークン化が使用されますが、これらの手順はスタンドアロンの制御可能な API として公開されません。
Spark NLP を使用して自然言語処理パイプラインを構築する
Spark NLP は、自然言語処理パイプラインを実行するときに、従来の Spark ML モデルと同じ開発パターンに従います。 実験の追跡と運用のデプロイには MLflow を使用して、トレーニング済みのモデルを管理します。

コア パイプライン コンポーネントをアセンブルする
Spark NLP パイプラインは、アノテーターを順番にチェーンします。 各アノテーターは、前のステージの出力を変換し、生のテキストからセマンティック ベクターにビルドします。
DocumentAssembler は、すべての Spark NLP パイプラインのエントリ ポイントです。
setCleanupModeを使用して、ダウンストリーム アノテーターを実行する前に、HTML タグの削除や空白の正規化などの省略可能なテキストの前処理を適用します。SentenceDetector は、アセンブリされたドキュメント内の文の境界を識別します。 パイプラインの構成に応じて、検出された文が 1 行内の
Arrayとして、または個別の行として返されます。 多くのダウンストリーム アノテーターは文レベルで動作するため、正確な文検出が重要です。トークナイザーは、生のテキストを単語、数字、記号などの個別のトークンに分割します。 ドメインに対して既定のルールが不十分な場合は、特殊なボキャブラリ、ハイフネーションされた用語、またはドメイン固有のパターンを処理するカスタム ルールを追加します。
ノーマライザーは、正規表現とディクショナリ変換を適用してトークンを絞り込みます。 埋め込む前にテキストをクリーンアップしてノイズを軽減します。 たとえば、アクセントを削除したり、小文字に変換したり、ユーザー辞書マッピングを適用して用語を標準化することができます。
WordEmbeddings は、コンテキスト処理のためにトークンをセマンティック ベクターにマップします。 各トークンは、他のトークンに対する意味をキャプチャする密ベクターとして表されます。 埋め込みボキャブラリに表示されない未解決のトークンは、既定で 0 個のベクトルに設定されます。
MLflow を使用してモデルを管理する
Spark NLP では、ネイティブ MLflow をサポートする Spark MLlib パイプラインが使用されます。 カスタムシリアル化または統合コードを記述する必要はありません。
MLflow は、実験の追跡、モデルのバージョン管理、デプロイを管理します。 トレーニングの実行中に、パイプラインのパラメーター、メトリック、成果物をログに記録できます。 MLflow は各実験を追跡するため、イテレーション間で結果を比較し、成功した構成を再現できます。
MLflow は、Azure Databricks および Fabric と直接統合されます。 Azure Databricksでは、MLflow がプレインストールされ、ワークスペースと緊密に統合されます。 Fabricでは、ネイティブの実験追跡と自動ログ記録を備えた組み込みの MLflow エクスペリエンスも提供されるため、MLflow を個別にインストールする必要はありません。 別の Apache Spark ベースの環境で Spark NLP を実行する場合は、MLflow を個別にインストールし、リモート追跡サーバーに対する実験を追跡するように構成できます。
MLflow モデル レジストリを使用して、モデルを運用環境に昇格させ、ガバナンスを維持します。 Model Registry には、自然言語処理パイプライン全体でモデル バージョンを管理するための中央リポジトリが用意されています。 クラシック デプロイでは、ステージング、運用、アーカイブなどのステージを通じてモデルを移行します。
Azure Databricks では、新しいデプロイでは、Unity Catalog のModels が使用されます。これは、固定ステージをカスタム エイリアスとタグに置き換えて、より柔軟なライフ サイクル管理を実現します。 Fabric では、ワークスペースは独自の MLflow ベースのモデル レジストリを提供します。
機能マトリックス
次の表は、Azure Databricks または Fabric の Spark NLP と Azure 言語の機能の主な違いをまとめたものです。
一般的な機能
| 能力 | Spark NLP (Azure DatabricksまたはFabric) | Azure言語 |
|---|---|---|
| サービスとしての事前トレーニング済みモデル | イエス | イエス |
| REST API | イエス | イエス |
| プログラム可能性 | Python、Scala | サポートされているプログラミング言語を参照してください。 |
| 大規模なデータセットと大規模なドキュメントの処理をサポートします | イエス | 制限あり1 |
アノテーター機能
| 能力 | Spark NLP (Azure DatabricksまたはFabric) | Azure言語 |
|---|---|---|
| 文検出機能 | イエス | いいえ |
| 文のディープ検出機能 | イエス | いいえ |
| トークナイザー | イエス | 内部のみ (スタンドアロン API として公開されない) |
| N グラム ジェネレーター | イエス | いいえ |
| 単語分割 | イエス | イエス |
| ステマー | イエス | いいえ |
| レンマタイザー | イエス | いいえ |
| 品詞のタグ付け | イエス | いいえ |
| 依存関係パーサー | イエス | いいえ |
| 翻訳 | イエス | いいえ |
| ストップワード クリーナー | イエス | いいえ |
| スペル修正 | イエス | いいえ |
| ノーマライザー | イエス | イエス |
| テキスト マッチャー | イエス | いいえ |
| TF-IDF | イエス | いいえ |
| 正規表現マッチャー | イエス | 制限あり |
| 日付マッチャー | イエス | 制限あり |
| チャンカー | イエス | いいえ |
高度な自然言語処理機能
| 能力 | Spark NLP (Azure DatabricksまたはFabric) | Azure言語 |
|---|---|---|
| スペル チェック | イエス | いいえ |
| 要約 | イエス | イエス |
| 質問応答 | イエス | イエス |
| センチメント検出 | イエス | イエス |
| 感情検出 | イエス | 限定2 |
| トークンの分類 | イエス | 制限 3 |
| テキスト分類 | イエス | 制限 3 |
| テキスト表現 | イエス | いいえ |
| NER | イエス | はい (事前構築済み)。 CNER はカスタム モデルを通じて利用できます。 3 |
| 言語検出 | イエス | イエス |
| 英語以外の言語をサポート | Yes. Spark NLP でサポートされている言語を参照してください。 | Yes. サポートされている言語Azure言語を参照してください。 |
2.Azure 言語ではオピニオン マイニングがサポートされています。これは、テキストの特定の側面にリンクされているセンチメントを識別しますが、専用の感情検出 (喜び、怒り、悲しみの分類など) を提供しません)。
3.カスタムモデルを通じて利用可能。独自のラベル付きデータで CNER またはカスタム エンティティ認識モデルをトレーニングします。
貢献者
Microsoftはこの記事を保持します。 次の共同作成者がこの記事を書きました。
主要な著者:
- アナンヤ・ゴーシュ・ショウドゥリー |プリンシパル クラウド ソリューション アーキテクト
- クランティ・マンチカンティ |シニア AI ソリューション エンジニア
その他の共同作成者:
- フレディ・アヤラ |クラウド ソリューション アーキテクト
- ティンシー・エリアス |シニア クラウド ソリューション アーキテクト
- Moritz Steller | シニア クラウド ソリューション アーキテクト
次のステップ
関連リソース
Azure言語のドキュメント:
Spark NLP のドキュメント
Azureコンポーネント:
学習リソース