適用対象:![]() Azure SQL データベース
Azure SQL データベース
この記事では、Azure SQL Database の Hyperscale データベースを使った自動バックアップ機能について説明します。
Hyperscale データベースでは、拡張性の高いストレージとコンピューティング パフォーマンス レベルを備えた独自のアーキテクチャが使われます。 Hyperscale のバックアップはスナップショット ベースであり、ほぼ瞬時に行われます。 ログ バックアップは、バックアップ保持期間を通じて長期的な Azure Storage に格納されます。
ハイパースケール アーキテクチャでは、SQL Server やその他の SQL Database レベルで使用されるファイル ベースのバックアップと同じバックアップ チェーンは必要ありませんが、引き続き同じ RTO と RPO の要件を満たしています。 トランザクション ログの動作は同じで、同じポイントインタイム リストア機能を使用できます。 Hyperscale では、バックアップ頻度、ストレージ コスト、スケジュール設定、ストレージ冗長性、復元機能は、Azure SQL Database の他のデータベースとは異なります。
バックアップと復元のパフォーマンス
ストレージとコンピューティングが分離されているので、Hyperscale ではバックアップと復元の操作をストレージ レイヤーに引き下げ、コンピューティング レプリカ上のリソース消費を排除することができます。 データベースのバックアップは、プライマリとセカンダリのコンピューティング レプリカのどちらのパフォーマンスにも影響しません。
Hyperscale データベースのバックアップと復元の操作は、ストレージ スナップショットを使うため、データのサイズに関係なく高速です。 バックアップは事実上瞬時に完了します。
データベースは、次の手順でバックアップ保有期間内の任意の時点に復元できます。
- 該当するファイルのスナップショットに戻します。
- 復元されたデータベースのトランザクションの整合性を確保するために、トランザクション ログを適用します。
そのため、復元はデータ サイズに左右されず、操作は同じままです。 同じ Azure リージョン内の Hyperscale データベースの復元は、数テラバイトのデータベースであっても、数時間から数日ではなく、数分で完了します。
復元の発行時に ストレージの冗長性 を変更すると、復元はデータ サイズの操作で、復元時間がデータベース サイズに比例するため、復元時間が長くなる可能性があります。
既存のバックアップの復元またはデータベースのコピーによる新しいデータベースの作成も、Hyperscale のコンピューティングとストレージの分離を利用したものです。 開発やテストを目的としたコピーの作成は、数テラバイトのデータベースであっても、同じリージョン内で同じストレージの種類を使用している場合は数分で完了します。
バックアップ保有期間
Hyperscale データベースの既定の短期バックアップ保持期間は 7 日間です。
2023 年 9 月の時点で、1 日から 35 日間のバックアップの短期保持期間と、Hyperscale データベースの長期バックアップ 保持期間 (LTR) 機能が一般公開されています。 詳細については、「長期保有 - Azure SQL Database と Azure SQL Managed Instance」を参照してください
バックアップのスケジュール設定
Hyperscale データベースでは、従来の完全バックアップ、差分バックアップ、トランザクション ログ バックアップは存在しません。 代わりに、データ ファイルの定期ストレージ スナップショットが取得されます。
生成されたトランザクション ログは、構成された保有期間だけそのまま保持されます。 復元時、関連するトランザクション ログ レコードが、復元されたストレージ スナップショットに適用されます。 この結果、保持期間内の指定された時点で、データが失われることなく、トランザクション上一貫性のあるデータベースが復元されます。
バックアップ ストレージ消費量を監視する
Hyperscale では、Azure Monitor メトリックから、次の消費情報がわかります。
- データ バックアップ ストレージのサイズ (スナップショット バックアップのサイズ)
- データ ストレージのサイズ (割り当てられたデータベースのサイズ)
- ログ バックアップ ストレージのサイズ (トランザクション ログ バックアップのサイズ)
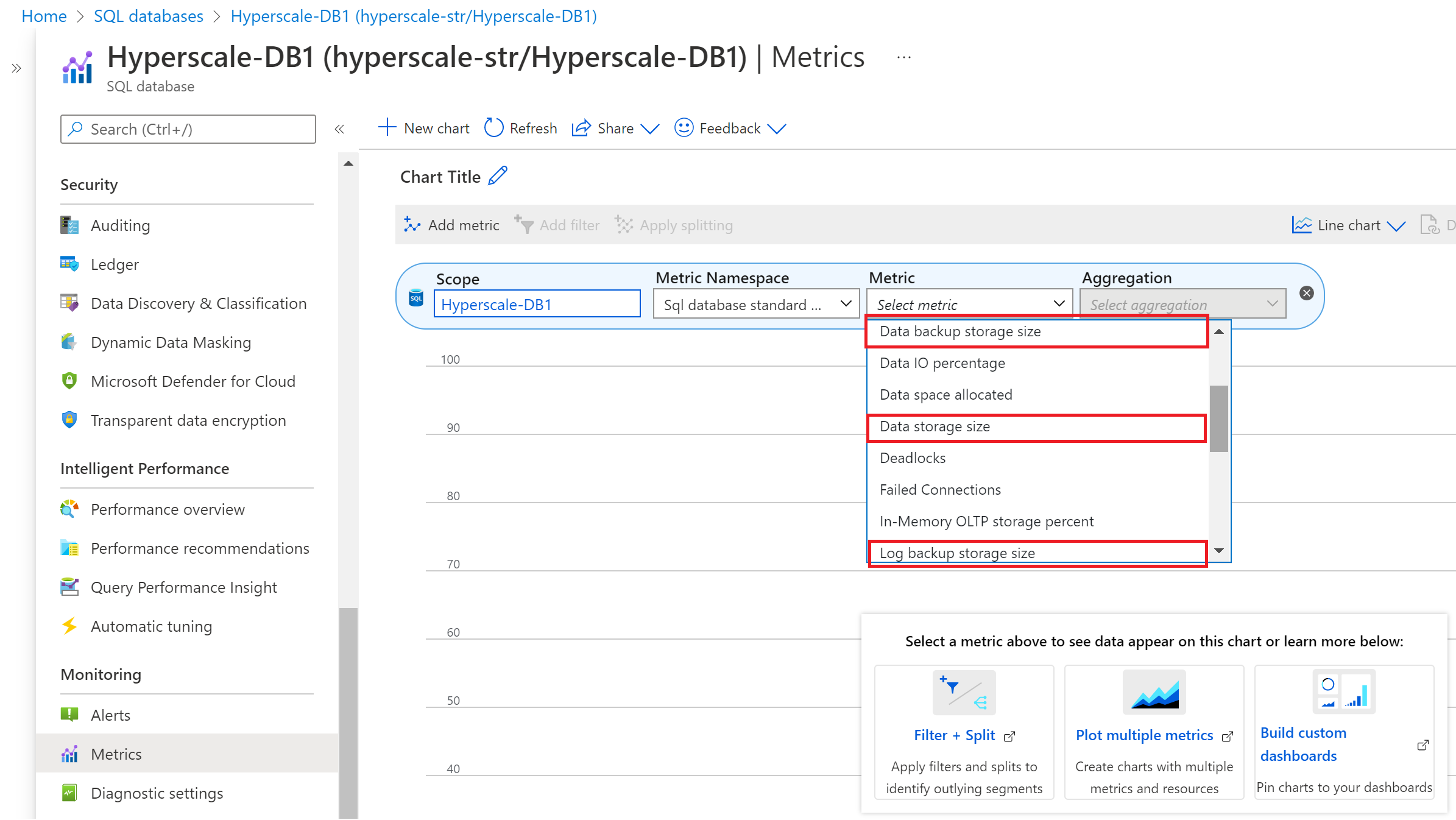
Azure portal でバックアップとデータ ストレージのメトリックを表示するには、次の手順に従います。
- バックアップとデータ ストレージのメトリックを監視する Hyperscale データベースに移動します。
- [監視] セクションの [メトリック] ページを選びます。
- [メトリック] ドロップダウン リストで、適切な集計ルールを使用して [データ バックアップ ストレージ] と [データ ストレージ サイズ]、[ログ バックアップ ストレージ] のメトリックを選びます。
バックアップ ストレージ消費量を削減する
Hyperscale データベースのバックアップ ストレージ消費量は、保有期間、リージョンの選択、バックアップ ストレージの冗長性、ワークロードの種類によって異なります。 Hyperscale データベースのバックアップ ストレージ消費量を減らすには、次の調整手法のいくつかを検討してください。
- 必要最小限までバックアップ保有期間を短縮します。
- インデックスのメンテナンスなどの大規模な書き込み操作を、必要以上に頻繁に行わないようにします。 インデックスのメンテナンスの推奨事項については、「クエリのパフォーマンスを向上させてリソースの消費を削減するためにインデックスのメンテナンスを最適化する」を参照してください。
- 大規模なデータ読み込み操作の場合は、必要に応じてデータ圧縮の使用を検討してください。
- 一時的な結果やデータを保存するには、アプリケーションのロジックでの永続的テーブルではなく
tempdbデータベースを使用します。 - geo リストア機能が不要な場合 (たとえば、開発環境やテスト環境)、ローカル冗長またはゾーン冗長バックアップ ストレージを使用します。
バックアップ ストレージのコスト
Hyperscale のバックアップ ストレージ コストは、リージョンとバックアップ ストレージの冗長性の選択内容によって異なります。 また、ワークロードの種類によっても異なります。
書き込み負荷の高いワークロードでは、データ ページが頻繁に変更される可能性が高いため、ストレージ スナップショットが大きくなります。 このようなワークロードでは、トランザクション ログもより多く生成され、全体的なバックアップ コストに影響が出ます。 バックアップ ストレージは、1 か月あたりの消費量 (ギガバイト) に基づいて課金されます。 データベース サイズに等しいバックアップ ストレージ容量は、追加料金なしで提供されます。 価格設定の詳細については、Azure SQL Database の価格に関するページを参照してください。
Hyperscale の場合、課金対象のバックアップ ストレージは次のように計算されます。
Total billable backup storage size = (data backup storage size + log backup storage size)
データ ストレージ サイズは、割り当てられたデータベース ストレージとして既に課金されているため、課金対象のバックアップには含まれません。
削除された Hyperscale データベースでは、削除前の特定の時点への復旧をサポートするためのバックアップ コストが発生します。 削除された Hyperscale データベースの場合、課金対象のバックアップ ストレージは次のように計算されます。
Total billable backup storage size for deleted Hyperscale database = (data storage size + data backup size + log backup storage size) * (remaining backup retention period after deletion / configured backup retention period)
割り当てられたデータベース ストレージは削除されたデータベースに対して個別に課金されないため、データ ストレージのサイズはフォーミュラに含まれます。 削除されたデータベースの場合、データは削除後に格納され、構成されたバックアップ保有期間中の復旧が可能になります。
削除されたデータベースに対する課金対象のバックアップ ストレージは、削除後に時間の経過と共に徐々に減少します。 バックアップが保持されなくなり、復旧が不可能になると、ゼロになります。 完全な削除であり、バックアップが不要になった場合は、データベースを削除する前に保持期間を短縮することで、コストを最適化することができます。
バックアップ コストを監視する
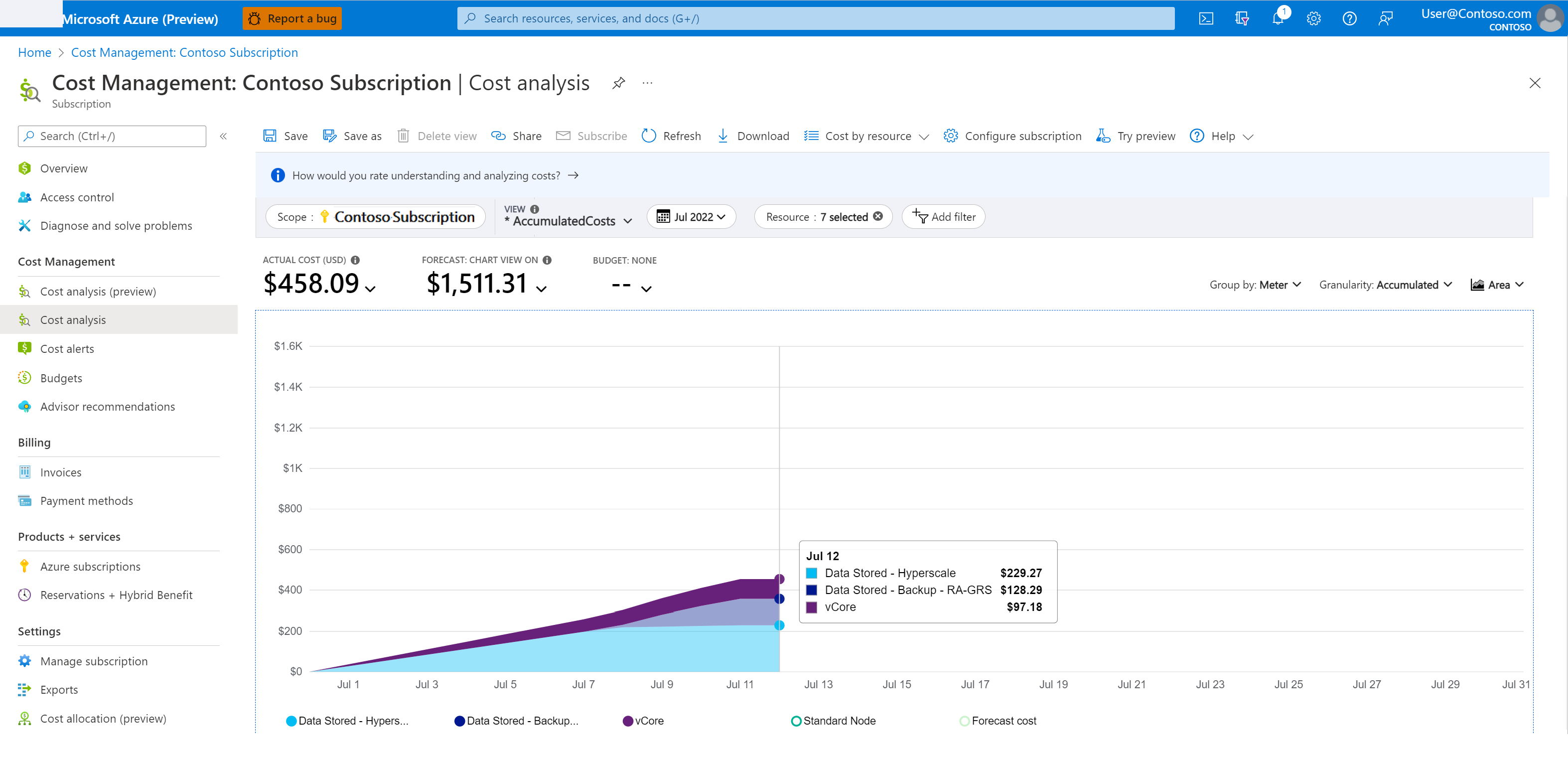
バックアップ ストレージ コストを理解するには:
Azure portal で、 [コストの管理と請求] に移動します。
[Cost Management]>[コスト分析] の順に選択します。
[スコープ] で目的のサブスクリプションを選びます。
次の手順で、関心のある期間とサービスをフィルター処理します。
- [サービス名] のフィルターを追加します。
- ドロップダウン リストから [sql-database] を選びます。
- [測定] のフィルターをもう 1 つ追加します。
- ポイントインタイム リストアのバックアップ コストを監視するには、ドロップダウン リストから [格納データ - バックアップ - RA] を選びます。
次のスクリーンショットは、コストの分析例を示しています。
データとバックアップ ストレージの冗長性
Hyperscale では、ストレージの冗長性を構成できます。 Hyperscale データベースを作成するときは、好みのストレージの種類として、読み取りアクセス geo ゾーン冗長ストレージ (RA-GZRS)、読み取りアクセス geo 冗長ストレージ (RA-GRS)、ゾーン冗長ストレージ (ZRS)、またはローカル冗長ストレージ (LRS) を選択できます。
- geo ゾーン冗長ストレージ: プライマリ リージョンの 3 つの Azure 可用性ゾーン間でバックアップを同期的にコピーします。 ゾーン冗長ストレージ (ZRS) に似ています。 さらに、データを非同期的に連携しているセカンダリーリージョン内の 1 つの物理的な場所にコピーします。 現在、特定のリージョンでのみ使用できます。
他の種類のストレージのバックアップがどのようにレプリケートされるかについては、「バックアップ ストレージの冗長性」を参照してください。
Hyperscale ではバックアップにストレージ スナップショットが使用されるため、データとバックアップは同じストレージ アカウントを共有します。 そのため、選択したバックアップ ストレージの冗長性は、データとバックアップの両方に適用されます。
注
バックアップ ストレージの冗長性は、Hyperscale データベースを作成するときに慎重に検討してください。これを設定できるのはデータベースの作成時のみだからです。 リソースのプロビジョニング後にこの設定を変更することはできません。
ダウンタイムを最小限に抑えて既存の Hyperscale データベースに対するバックアップ ストレージの冗長性設定を更新するには、アクティブ geo レプリケーションを使用します。 または、データベース コピーを使用することもできます。
警告
Hyperscale データベースを別のリージョンに復元する
場合によっては、Hyperscale データベースを現在のリージョンとは異なるリージョンに復元する必要があります。 一般的な理由としては、ディザスター リカバリーの操作または訓練、再配置などがあります。 主な方法は、データベースの geo リストアを行うことです。 Azure SQL Database の他のデータベースを別のリージョンに復元するときと同じ手順を使います。
- ターゲット リージョンにまだ適切なサーバーが存在しない場合は、そこにサーバーを作成します。 このサーバーは、元の (ソース) サーバーと同じサブスクリプションが所有する必要があります。
- 自動バックアップからの Azure SQL Database のデータベースの復元に関するページの「geo リストア」セクションにある手順に従ってください。
注
ソースとターゲットが別々のリージョンにあるため、データベースは、geo リストア以外と同様に、スナップショット ストレージをソース データベースと共有することができません。 非 geo リストアの場合、データベース サイズに関係なく短時間で完了します。
Hyperscale データベースの geo リストアは、ターゲットが geo レプリケーション ストレージのペア リージョンにある場合でも、データ サイズに応じた操作になります。 そのため、geo リストアは、同じリージョン内のポイントインタイム リストアと比較すると、かかる時間が大幅に長くなります。
ターゲットがペア リージョン内にある場合、データ転送はリージョン内で行われます。 その転送は、リージョンをまたぐデータ転送よりも大幅に高速です。 ただし、データ サイズに左右される操作でもあります。
必要に応じて、別のリージョンにデータベースをコピーすることができます。 選択したストレージ冗長性の種類がサポートしていないため、geo リストアが利用できない場合には、この方法を使用してください。 詳細については、Hyperscale のデータベース コピーに関する記事を参照してください。
関連するコンテンツ
データの不慮の破損または削除から保護するのに役立つデータベース バックアップは、事業継続とディザスター リカバリー戦略の最も重要な部分です。