Azure portal で単一データベースを作成するために、このクイックスタートは、Azure SQL のページから開始します。
[Select SQL Deployment option](SQL デプロイ オプションの選択) ページを参照します。
[SQL データベース] で、 [リソースの種類] を [単一データベース] に設定し、 [作成] を選択します。

[SQL データベースの作成] フォームの [基本] タブにある [プロジェクトの詳細] で、目的の Azure [サブスクリプション] を選択します。
[リソース グループ] で、 [新規作成] を選択し、「myResourceGroup」と入力して、 [OK] を選択します。
[データベース名] に「mySampleDatabase」と入力します。
[サーバー] で、 [新規作成] を選択し、 [新しいサーバー] フォームに次の値を入力します。
- [サーバー名] : 「mysqlserver」と入力し、一意にするためにいくつかの文字を追加します。 サーバー名は、サブスクリプション内で一意ではなく、Azure のすべてのサーバーに対してグローバルに一意である必要があるため、正確なサーバー名をここに示すことはできません。 mysqlserver12345などの名前を入力すると、ポータルにより、それを使用できるかどうかが通知されます。
- サーバー管理者ログイン:「azureuser」と入力します。
- パスワード:要件を満たすパスワードを入力し、 [パスワードの確認入力] フィールドにもう一度入力します。
- [場所] :ドロップダウン リストから場所を選択します。
[OK] を選択します。
[コンピューティングとストレージ] で、 [データベースの構成] を選択します。
このクイックスタートでは、Hyperscale データベースを作成するため、 [サービス レベル] で、[Hyperscale] を選択します。
![Azure SQL Database の新しいデータベースの [サービス レベルおよびコンピューティング レベルの構成] ページのスクリーンショット。[ハイパースケール サービス レベル] が選択されています。](media/hyperscale-database-create-quickstart/create-database-select-hyperscale-service-tier.png?view=azuresql-db)
[コンピューティング ハードウェア] で、[構成の変更] を選択します。 使用可能なハードウェア構成を確認し、お使いのデータベースに最適な構成を選択します。 この例では、Standard シリーズ (Gen5) 構成を選びます。
[OK] を選択して、ハードウェアの生成を確認します。
必要に応じて、データベースの仮想コアの数を増加する場合は、[仮想コア] のスライダーを調整します。 この例では、2 つの仮想コアを選択します。
[高可用性セカンダリ レプリカ] のスライダーを調整して、1 つの高可用性 (HA) レプリカを作成します。
[適用] を選択します。
Hyperscale データベースを作成する場合は、[バックアップ ストレージの冗長性] の構成オプションを慎重に検討します。 ストレージの冗長性は、Hyperscale データベースのデータベース作成プロセスの間にのみ指定できます。 ローカル冗長、ゾーン冗長、または geo 冗長ストレージを選択できます。 選択したストレージ冗長オプションは、データベースの有効期間中、データ ストレージの冗長性 と バックアップ ストレージの冗長性の両方に使用されます。 既存のデータベースは、データベースのコピー またはポイントインタイム リストアを使用して、異なるストレージ冗長性に移行できます。
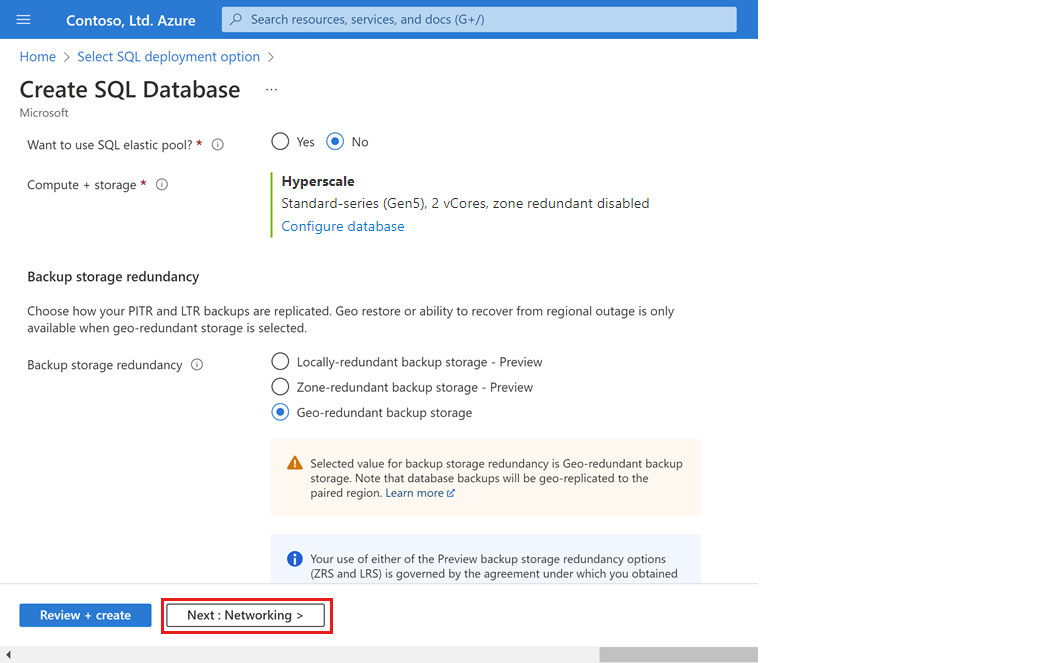
ページの下部にある [Next: Networking](次へ: ネットワーク) を選択します。
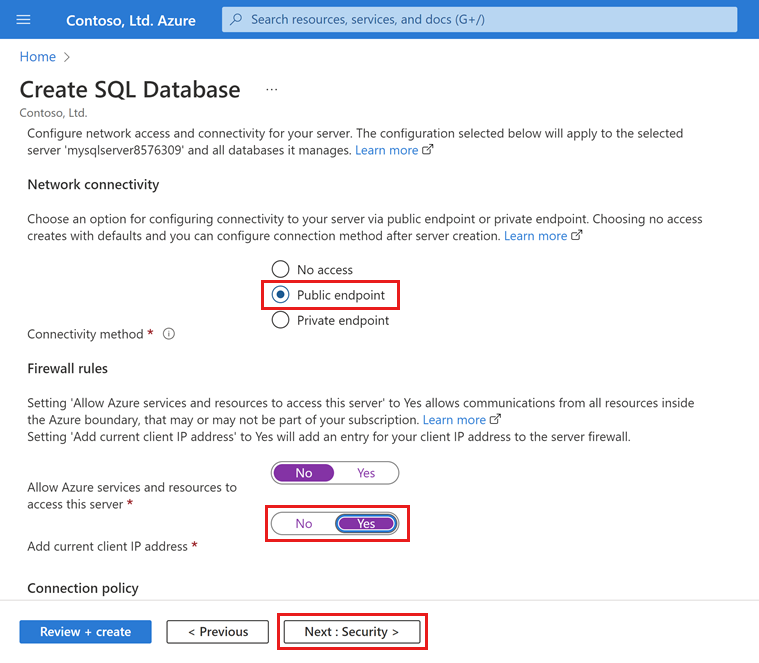
[ネットワーク] タブの [接続方法] で、 [パブリック エンドポイント] を選択します。
[ファイアウォール規則] で、 [現在のクライアント IP アドレスを追加する] を [はい] に設定します。 [Azure サービスおよびリソースにこのサーバー グループへのアクセスを許可する] を [いいえ] に設定したままにします。
ページの下部で [次へ: セキュリティ] を選択します。
必要に応じて、Microsoft Defender for SQL を有効にします。
ページの下部にある [Next: Additional settings](次へ: 追加設定) を選択します。
[追加設定] タブにある [データ ソース] セクションの [既存のデータを使用します] で、 [サンプル] を選択します。 これにより、AdventureWorksLT サンプル データベースが作成され、空のデータベースではなく、クエリと実験に使用するテーブルとデータが用意されます。
ページの下部にある [確認と作成] を選択します。
![[追加設定] 画面のスクリーンショット。この画面では、Azure SQL Database にデータベースを作成して、サンプル データを選択できます。](media/hyperscale-database-create-quickstart/azure-sql-create-database-sample-data.png?view=azuresql-db)
[確認と作成] ページで、確認後、 [作成] を選択します。
このセクションの Azure CLI コード ブロックは、サーバーにアクセスするためのリソース グループ、サーバー、単一データベース、およびサーバー レベルの IP ファイアウォール 規則を作成します。 後でこれらのリソースを管理できるように、生成されたリソース グループとサーバーの名前を必ず記録しておいてください。
Azure サブスクリプションをお持ちでない場合は、開始する前に Azure 無料アカウントを作成してください。
Azure CLI の環境を準備する
Azure Cloud Shell を起動する
Azure Cloud Shell は無料のインタラクティブ シェルです。この記事の手順は、Azure Cloud Shell を使って実行することができます。 一般的な Azure ツールが事前にインストールされており、アカウントで使用できるように構成されています。
Cloud Shell を開くには、コード ブロックの右上隅にある [使ってみる] を選択します。 https://shell.azure.com に移動して、別のブラウザー タブで Cloud Shell を起動することもできます。
Cloud Shell が開いたら、お使いの環境に対して Bash が選択されていることを確認します。 以降のセッションでは、Bash 環境で Azure CLI を使用します。 [コピー] を選択してコードのブロックをコピーし、Cloud Shell に貼り付けます。その後、Enter キーを押してそれを実行します。
Azure へのサインイン
Cloud Shell は、サインインした最初のアカウントで自動的に認証されます。 別のサブスクリプションを使用してサインインするには、次のスクリプトを使用し、<Subscription ID> をご使用の Azure サブスクリプション ID に置き換えます。 Azure サブスクリプションをお持ちでない場合は、開始する前に Azure 無料アカウントを作成してください。
subscription="<subscriptionId>" # add subscription here
az account set -s $subscription # ...or use 'az login'
詳細については、アクティブなサブスクリプションの設定または対話形式のログインに関する記事を参照してください
パラメーターの値を設定する
次の値は、データベースと必要なリソースを作成するために、後続のコマンドで使用されます。 サーバー名は、すべての Azure でグローバルに一意である必要があるため、サーバー名の作成に $RANDOM 関数が使用されます。
サンプル コードを実行する前に、お使いの環境に合わせて location を変更します。 0.0.0.0 を、ご使用の特定の環境に合った IP アドレスの範囲に置き換えます。 ご使用のコンピューターのパブリック IP アドレスを使用して、サーバーへのアクセスをその IP アドレスのみに制限します。
# <FullScript>
# Create a single database and configure a firewall rule
# <SetParameterValues>
# Variable block
let "randomIdentifier=$RANDOM*$RANDOM"
location="East US"
resourceGroup="msdocs-azuresql-rg-$randomIdentifier"
tag="create-and-configure-database"
server="msdocs-azuresql-server-$randomIdentifier"
database="msdocsazuresqldb$randomIdentifier"
login="azureuser"
password="Pa$$w0rD-$randomIdentifier"
# Specify appropriate IP address values for your environment
# to limit access to the SQL Database server
startIp=0.0.0.0
let "randomIdentifier=$RANDOM*$RANDOM"
location="East US"
resourceGroupName="myResourceGroup"
tag="create-and-configure-database"
serverName="mysqlserver-$randomIdentifier"
databaseName="mySampleDatabase"
login="azureuser"
password="Pa$$w0rD-$randomIdentifier"
# Specify appropriate IP address values for your environment
# to limit access to the SQL Database server
startIp=0.0.0.0
endIp=0.0.0.0
echo "Using resource group $resourceGroupName with login: $login, password: $password..."
リソース グループを作成する
az group create コマンドを使用して、リソース グループを作成します。 Azure リソース グループとは、Azure リソースのデプロイと管理に使用する論理コンテナーです。 次の例では、前の手順で location に指定した場所でリソース グループを作成します。
echo "Creating $resourceGroupName in $location..."
az group create --name $resourceGroupName --location "$location" --tag $tag
サーバーの作成
az sql server create コマンドを使用して論理サーバーを作成します。
echo "Creating $serverName in $location..."
az sql server create --name $serverName --resource-group $resourceGroupName --location "$location" --admin-user $login --admin-password $password
az sql server firewall-rule create コマンドを使用してファイアウォール規則を作成します。
echo "Configuring firewall..."
az sql server firewall-rule create --resource-group $resourceGroupName --server $serverName -n AllowYourIp --start-ip-address $startIp --end-ip-address $endIp
単一データベースを作成する
az sql db create コマンドを使用して Hyperscale サービス レベルにデータベースを作成します。
Hyperscale データベースを作成する場合、backup-storage-redundancy の設定を慎重に検討してください。 ストレージの冗長性は、Hyperscale データベースのデータベース作成プロセスの間にのみ指定できます。 ローカル冗長、ゾーン冗長、または geo 冗長ストレージを選択できます。 選択したストレージ冗長オプションは、データベースの有効期間中、データ ストレージの冗長性 と バックアップ ストレージの冗長性の両方に使用されます。 既存のデータベースは、データベースのコピー またはポイントインタイム リストアを使用して、異なるストレージ冗長性に移行できます。 backup-storage-redundancy パラメーターに使用できる値は、Local、Zone、Geo です。 明示的に指定しない限り、データベースは geo 冗長バックアップ ストレージを使用するように構成されます。
次のコマンドを実行して、AdventureWorksLT サンプル データが設定された Hyperscale データベースを作成します。 このデータベースでは、2 つの仮想コアを備えた Standard シリーズ (Gen5) ハードウェアを使用います。 このデータベースには、geo 冗長バックアップ ストレージが使用されます。 このコマンドでは、1 つの 高可用性 (HA) レプリカも作成されます。
az sql db create \
--resource-group $resourceGroupName \
--server $serverName \
--name $databaseName \3
--sample-name AdventureWorksLT \
--edition Hyperscale \
--compute-model Provisioned \
--family Gen5 \
--capacity 2 \
--backup-storage-redundancy Geo \
--ha-replicas 1
Azure PowerShell を使用して、リソース グループ、サーバー、単一データベースを作成できます。
Azure Cloud Shell を起動する
Azure Cloud Shell は無料のインタラクティブ シェルです。この記事の手順は、Azure Cloud Shell を使って実行することができます。 一般的な Azure ツールが事前にインストールされており、アカウントで使用できるように構成されています。
Cloud Shell を開くには、コード ブロックの右上隅にある [使ってみる] を選択します。 https://shell.azure.com に移動して、別のブラウザー タブで Cloud Shell を起動することもできます。
Cloud Shell が開いたら、環境で PowerShell が選択されていることを確認します。 以降のセッションでは、PowerShell 環境で Azure CLI を使用します。 [コピー] を選択してコードのブロックをコピーし、Cloud Shell に貼り付けます。その後、Enter キーを押してそれを実行します。
パラメーターの値を設定する
次の値は、データベースと必要なリソースを作成するために、後続のコマンドで使用されます。 サーバー名は、すべての Azure でグローバルに一意である必要があるため、サーバー名の作成に Get-Random コマンドレットが使用されます。
サンプル コードを実行する前に、お使いの環境に合わせて location を変更します。 0.0.0.0 を、ご使用の特定の環境に合った IP アドレスの範囲に置き換えます。 ご使用のコンピューターのパブリック IP アドレスを使用して、サーバーへのアクセスをその IP アドレスのみに制限します。
# Set variables for your server and database
$resourceGroupName = "myResourceGroup"
$location = "eastus"
$adminLogin = "azureuser"
$password = "Pa$$w0rD-$(Get-Random)"
$serverName = "mysqlserver-$(Get-Random)"
$databaseName = "mySampleDatabase"
# The ip address range that you want to allow to access your server
$startIp = "0.0.0.0"
$endIp = "0.0.0.0"
# Show randomized variables
Write-host "Resource group name is" $resourceGroupName
Write-host "Server name is" $serverName
Write-host "Password is" $password
リソース グループの作成
New-AzResourceGroup を使用して Azure リソース グループを作成します。 リソース グループとは、Azure リソースのデプロイと管理に使用する論理コンテナーです。
Write-host "Creating resource group..."
$resourceGroup = New-AzResourceGroup -Name $resourceGroupName -Location $location -Tag @{Owner="SQLDB-Samples"}
$resourceGroup
サーバーの作成
New-AzSqlServer コマンドレットを使用してサーバーを作成します。
Write-host "Creating primary server..."
$server = New-AzSqlServer -ResourceGroupName $resourceGroupName `
-ServerName $serverName `
-Location $location `
-SqlAdministratorCredentials $(New-Object -TypeName System.Management.Automation.PSCredential `
-ArgumentList $adminLogin, $(ConvertTo-SecureString -String $password -AsPlainText -Force))
$server
ファイアウォール規則を作成する
New-AzSqlServerFirewallRule コマンドレットを使用して、サーバーのファイアウォール規則を作成します。
Write-host "Configuring server firewall rule..."
$serverFirewallRule = New-AzSqlServerFirewallRule -ResourceGroupName $resourceGroupName `
-ServerName $serverName `
-FirewallRuleName "AllowedIPs" -StartIpAddress $startIp -EndIpAddress $endIp
$serverFirewallRule
単一データベースを作成する
New-AzSqlDatabase コマンドレットを使用して、単一データベースを作成します。
Hyperscale データベースを作成する場合、BackupStorageRedundancy の設定を慎重に検討してください。 ストレージの冗長性は、Hyperscale データベースのデータベース作成プロセスの間にのみ指定できます。 ローカル冗長、ゾーン冗長、または geo 冗長ストレージを選択できます。 選択したストレージ冗長オプションは、データベースの有効期間中、データ ストレージの冗長性 と バックアップ ストレージの冗長性の両方に使用されます。 既存のデータベースは、データベースのコピー またはポイントインタイム リストアを使用して、異なるストレージ冗長性に移行できます。 BackupStorageRedundancy パラメーターに使用できる値は、Local、Zone、Geo です。 明示的に指定しない限り、データベースは geo 冗長バックアップ ストレージを使用するように構成されます。
次のコマンドを実行して、AdventureWorksLT サンプル データが設定された Hyperscale データベースを作成します。 このデータベースでは、2 つの仮想コアを備えた Standard シリーズ (Gen5) ハードウェアを使用います。 このデータベースには、geo 冗長バックアップ ストレージが使用されます。 このコマンドでは、1 つの 高可用性 (HA) レプリカも作成されます。
Write-host "Creating a standard-series (Gen5) 2 vCore Hyperscale database..."
$database = New-AzSqlDatabase -ResourceGroupName $resourceGroupName `
-ServerName $serverName `
-DatabaseName $databaseName `
-Edition Hyperscale `
-ComputeModel Provisioned `
-ComputeGeneration Gen5 `
-VCore 2 `
-MinimumCapacity 2 `
-SampleName "AdventureWorksLT" `
-BackupStorageRedundancy Geo `
-HighAvailabilityReplicaCount 1
$database
Transact-SQL を使用して Hyperscale データベースを作成するには、最初に、Azure の既存の論理サーバーに関する接続情報を作成または識別する必要があります。
Transact-SQL コマンド (sqlcmd など) を実行するために、SQL Server Management Studio (SSMS)、Azure Data Studio、または任意のクライアントを使用して master データベースに接続します。
Hyperscale データベースを作成する場合、BACKUP_STORAGE_REDUNDANCY の設定を慎重に検討してください。 ストレージの冗長性は、Hyperscale データベースのデータベース作成プロセスの間にのみ指定できます。 ローカル冗長、ゾーン冗長、または geo 冗長ストレージを選択できます。 選択したストレージ冗長オプションは、データベースの有効期間中、データ ストレージの冗長性 と バックアップ ストレージの冗長性の両方に使用されます。 既存のデータベースは、データベースのコピー またはポイントインタイム リストアを使用して、異なるストレージ冗長性に移行できます。 BackupStorageRedundancy パラメーターに使用できる値は、LOCAL、ZONE、GEO です。 明示的に指定しない限り、データベースは geo 冗長バックアップ ストレージを使用するように構成されます。
次の Transact-SQL コマンドを実行して、Gen 5 ハードウェア、2 つの仮想コア、geo 冗長バックアップ ストレージを使用する Hyperscale データベースを作成します。 CREATE DATABASE ステートメントにエディションとサービス目標の両方を指定する必要があります。 HS_Gen5_2などの有効なサービス目標の一覧については、リソース制限に関するページを参照してください。
このコード例では、空のデータベースを作成します。 サンプル データが設定されたデータベースを作成する場合は、このクイックスタートの Azure portal、Azure CLI、または PowerShell の例を使用します。
CREATE DATABASE [myHyperscaleDatabase]
(EDITION = 'Hyperscale', SERVICE_OBJECTIVE = 'HS_Gen5_2') WITH BACKUP_STORAGE_REDUNDANCY= 'LOCAL';
GO
その他のパラメーターおよびオプションについては、「CREATE DATABASE (Transact-SQL)」を参照してください。
1 つ以上の高可用性 (HA) レプリカをデータベースに追加するには、Azure portal でデータベースの [計算とストレージ] ウィンドウ、Set-AzSqlDatabase PowerShell コマンド、またはaz sql db update Azure CLI コマンドを使用します。

![Azure SQL Database の新しいデータベースの [サービス レベルおよびコンピューティング レベルの構成] ページのスクリーンショット。[ハイパースケール サービス レベル] が選択されています。](media/hyperscale-database-create-quickstart/create-database-select-hyperscale-service-tier.png?view=azuresql-db#lightbox)


![2 つの認証オプションが表示された Azure SQL Database の [クエリ エディター (プレビュー)] ウィンドウのスクリーンショット。この例では、[SQL サーバー認証] で [ログイン] と [パスワード] に入力しています。](media/hyperscale-database-create-quickstart/query-editor-azure-portal-authenticate.png?view=azuresql-db)
![AdventureWorks のサンプル データに対してクエリを実行した後の Azure SQL Database の [クエリ エディター (プレビュー)] 画面のスクリーンショット。](media/hyperscale-database-create-quickstart/query-editor-azure-portal-run-query.png?view=azuresql-db)
![2 つの認証オプションが表示された Azure SQL Database の [クエリ エディター (プレビュー)] ウィンドウのスクリーンショット。この例では、[SQL サーバー認証] で [ログイン] と [パスワード] に入力しています。](media/hyperscale-database-create-quickstart/query-editor-azure-portal-authenticate.png?view=azuresql-db#lightbox)
![AdventureWorks のサンプル データに対してクエリを実行した後の Azure SQL Database の [クエリ エディター (プレビュー)] 画面のスクリーンショット。](media/hyperscale-database-create-quickstart/query-editor-azure-portal-run-query.png?view=azuresql-db#lightbox)