この記事では、Azure Databricks から Azure Cosmos DB MongoDB 仮想コアに接続する方法について説明します。 Python コードを使用した、読み取り、フィルター、SQL、集計パイプライン、テーブルの書き込みなどの基本的なデータ操作言語 (DML) の操作について説明します。
前提条件
- Azure Cosmos DB for MongoDB 仮想コア クラスターをプロビジョニングします。
- 任意の Spark 環境 Azure Databricks をプロビジョニングします。
接続の依存関係を構成する
Azure Databricks から Azure Cosmos DB for MongoDB 仮想コアに接続するために必要な依存関係を次に示します。
- MongoDB 用 Spark コネクタ Spark コネクタは、Azure Cosmos DB for MongoDB 仮想コアに接続するために使用されます。 Maven central で、実際の Spark 環境の Spark および Scala のバージョンと互換性のあるコネクタのバージョンを指定して使用します。 Spark 3.2.1 以上をサポートする環境と、maven 座標
org.mongodb.spark:mongo-spark-connector_2.12:3.0.1で使用できる spark コネクタを使用することをお勧めします。 - Azure Cosmos DB for MongoDB 接続文字列: Azure Cosmos DB for MongoDB 仮想コア接続文字列、ユーザー名、パスワード。
Azure Databricks ワークスペースをプロビジョニングする
手順に従って 、Azure Databricks ワークスペースをプロビジョニングできます。 使用可能な既定のコンピューティングを使用するか 、新しいコンピューティング リソースを作成 してノートブックを実行できます。 必ず、少なくとも Spark 3.0 をサポートする Databricks ランタイムを選択してください。
依存関係を追加する
MongoDB Connector for Spark ライブラリをコンピューティングに追加して、ネイティブ MongoDB エンドポイントと Azure Cosmos DB for MongoDB エンドポイントの両方に接続します。 コンピュータで、[Libraries]>Install New>Maven を選択し、Maven 座標をorg.mongodb.spark:mongo-spark-connector_2.12:3.0.1追加します。
[インストール] を選択し、インストールが完了したらコンピューティングを再起動します。
注
MongoDB Connector for Spark ライブラリがインストールされた後、Databricks コンピューティングを再起動してください。
その後、移行用の Scala または Python ノートブックを作成できます。
Python ノートブックを作成して Azure Cosmos DB for MongoDB 仮想コアに接続する
Databricks で Python ノートブックを作成します。 次のコードを実行する前に、必ず変数に適切な値を入力してください。
Azure Cosmos DB for MongoDB 接続文字列を使用して Spark 構成を更新する
- Azure portal の Azure Cosmos DB MongoDB 仮想コア リソースの [設定] ->[接続文字列] にある接続文字列をメモしてください。 形式: "mongodb+srv://<user>:<password>@<database_name>.mongocluster.cosmos.azure.com"
- コンピューティング構成の Databricks に戻り、[ 詳細オプション] (ページ下部) に、
spark.mongodb.output.uri変数とspark.mongodb.input.uri変数の両方の接続文字列を貼り付けます。 ユーザー名とパスワード フィールドを適切に入力します。 これにより、計算処理を行っているすべてのワークブックでこの構成が使用されます。 - または、API を呼び出すときに
optionを明示的に設定することもできます (例:spark.read.format("mongo").option("spark.mongodb.input.uri", connectionString).load())。 クラスターで変数を構成する場合は、オプションを設定する必要はありません。
connectionString_vcore="mongodb+srv://<user>:<password>@<database_name>.mongocluster.cosmos.azure.com/?tls=true&authMechanism=SCRAM-SHA-256&retrywrites=false&maxIdleTimeMS=120000"
database="<database_name>"
collection="<collection_name>"
データ サンプル セット
このラボでは、CSV 'Citibike2019' データ セットを使用します。 CitiBike Trip History 2019 からインポートできます。 "CitiBikeDB" というデータベースとコレクション "CitiBike2019" にこれを読み込みました。 読み込まれたデータを指すように変数データベースとコレクションを設定し、例で変数を使用します。
database="CitiBikeDB"
collection="CitiBike2019"
Azure Cosmos DB for MongoDB 仮想コアからデータを読み取る
一般的な構文は次のようになります。
df_vcore = spark.read.format("mongo").option("database", database).option("spark.mongodb.input.uri", connectionString_vcore).option("collection",collection).load()
読み込まれたデータ フレームは、次のように検証できます。
df_vcore.printSchema()
display(df_vcore)
例を見てみましょう。
df_vcore = spark.read.format("mongo").option("database", database).option("spark.mongodb.input.uri", connectionString_vcore).option("collection",collection).load()
df_vcore.printSchema()
display(df_vcore)
出力:
[スキーマ]
DataFrame
Azure Cosmos DB for MongoDB 仮想コアからデータをフィルター処理する
一般的な構文は次のようになります。
df_v = df_vcore.filter(df_vcore[column number/column name] == [filter condition])
display(df_v)
例を見てみましょう。
df_v = df_vcore.filter(df_vcore[2] == 1970)
display(df_v)
出力: 
ビューまたは一時テーブルを作成し、それに対して SQL クエリを実行する
一般的な構文は次のようになります。
df_[dataframename].createOrReplaceTempView("[View Name]")
spark.sql("SELECT * FROM [View Name]")
例を見てみましょう。
df_vcore.createOrReplaceTempView("T_VCORE")
df_v = spark.sql(" SELECT * FROM T_VCORE WHERE birth_year == 1970 and gender == 2 ")
display(df_v)
出力: 
Azure Cosmos DB for MongoDB 仮想コアにデータを書き込む
一般的な構文は次のようになります。
df.write.format("mongo").option("spark.mongodb.output.uri", connectionString).option("database",database).option("collection","<collection_name>").mode("append").save()
例を見てみましょう。
df_vcore.write.format("mongo").option("spark.mongodb.output.uri", connectionString_vcore).option("database",database).option("collection","CitiBike2019").mode("append").save()
このコマンドは、コレクションに直接書き込むため、出力がありません。 読み取りコマンドを使用して、レコードが更新されているかどうかをクロスチェックできます。
集計パイプラインを実行している Azure Cosmos DB for MongoDB 仮想コア コレクションからデータを読み取る
[!注] 集計パイプラインは、Azure Cosmos DB for MongoDB 内のデータを前処理および変換できる強力な機能です。 これは、リアルタイム分析、ダッシュボード、ロールアップによるレポート生成、"サーバー側" データの後処理による合計と平均に最適です。 (注: これについて書かれた本があります)。
Azure Cosmos DB for MongoDB では、必要なデータのみを処理、抽出、フィルター処理する充実したセカンダリ/複合インデックスもサポートしています。
たとえば、最初に完全なデータセットを読み込む必要なくデータベース内から直接、特定の地域にいるすべての顧客を分析し、データ移動を最小限に抑え、待機時間を減らします。
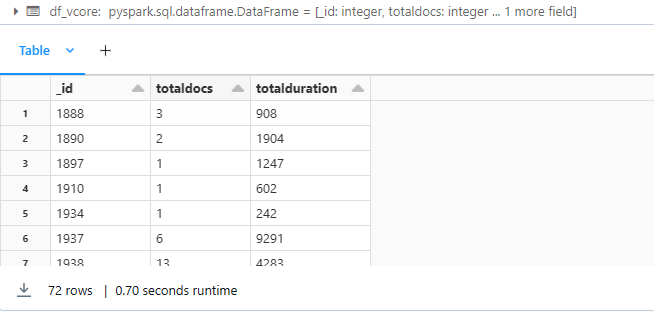
集計機能の使用例を次に示します。
pipeline = "[{ $group : { _id : '$birth_year', totaldocs : { $count : 1 }, totalduration: {$sum: '$tripduration'}} }]"
df_vcore = spark.read.format("mongo").option("database", database).option("spark.mongodb.input.uri", connectionString_vcore).option("collection",collection).option("pipeline", pipeline).load()
display(df_vcore)
出力:
関連コンテンツ
次の記事では、Azure Cosmos DB for MongoDB 仮想コアで集計パイプラインを使用する方法を紹介しています。
- Maven Central では、Spark コネクタについて説明しています。
- 集約パイプライン