適用対象: Azure Data Factory Azure Synapse Analytics
Azure Data Factory Azure Synapse Analytics
ヒント
Data Factory in Microsoft Fabric は、よりシンプルなアーキテクチャ、組み込みの AI、および新機能を備えた次世代のAzure Data Factoryです。 データ統合を初めて使用する場合は、Fabric Data Factory から始めます。 既存の ADF ワークロードをFabricにアップグレードして、データ サイエンス、リアルタイム分析、レポートの新機能にアクセスできます。
Azure Data Factoryは、クラウドMicrosoftのデータ統合と ETL サービスです。 このペーパーでは、データ ファクトリの DataOps に関するガイダンスを示します。 これは、CI/CD、Git、DevOps に関する完全なチュートリアルを意図したものではありません。 このペーパーでは、データ ファクトリのデプロイのベスト プラクティス、ファクトリの管理、ガバナンスに関する詳細な実装リンクを参照しながら、サービスで DataOps を実現するのに必要なデータ ファクトリ チームのガイダンスを確認できます。 このペーパーの末尾には、チュートリアルへのリンクを含むリソース セクションも用意されています。
DataOps とは
DataOps は、意思決定者により迅速に価値を提供する目的で、データ組織が共同データ管理のために実践するプロセスです。
Gartner では、次のように明快に DataOps を定義しています。
DataOps は、組織全体のデータ マネージャーとデータ コンシューマーとの間のデータ フローのコミュニケーション、統合、自動化を改善することに重点を置いた協調的なデータ管理プラクティスです。 DataOps の目的は、データ、データ モデル、および関連する成果物の予測可能なデリバリーと変更管理を作成することで、より迅速に価値を提供することです。 DataOps では、テクノロジを使用して、適切なレベルでガバナンスを行いながら、データ デリバリーの設計、デプロイ、管理を自動化します。また、メタデータを使用して、動的環境でのデータの使いやすさと価値を向上させます。
Azure Data Factoryで DataOps を実現する方法
Azure Data Factoryは、クラウド規模のデータ統合と ETL プロジェクトを簡単に構築するための視覚的に基づくデータ パイプライン パラダイムをデータ エンジニアに提供します。 データ ファクトリは、豊富なコラボレーション、ガバナンス、成果物の関係を含む DataOps を容易にする多くの組み込み機能を提供するために、GitHubやAzure DevOpsなどの成熟したバージョン管理ツール、および広範なAzure エコシステムとのネイティブ統合に依存しています。
具体的には、独自のGitHubまたはAzure DevOps リポジトリをデータ ファクトリに取り込むと、コミット、成果物の保存、バージョン管理などの一般的なコマンドに対して直感的な組み込み UI オプションが提供されます。 また、このサービスには、CI/CD とコード チェックインのベスト プラクティスを提供して、運用環境のサニティと正常性を保護するオプションも用意されています。
Azure Data Factoryの "コード"
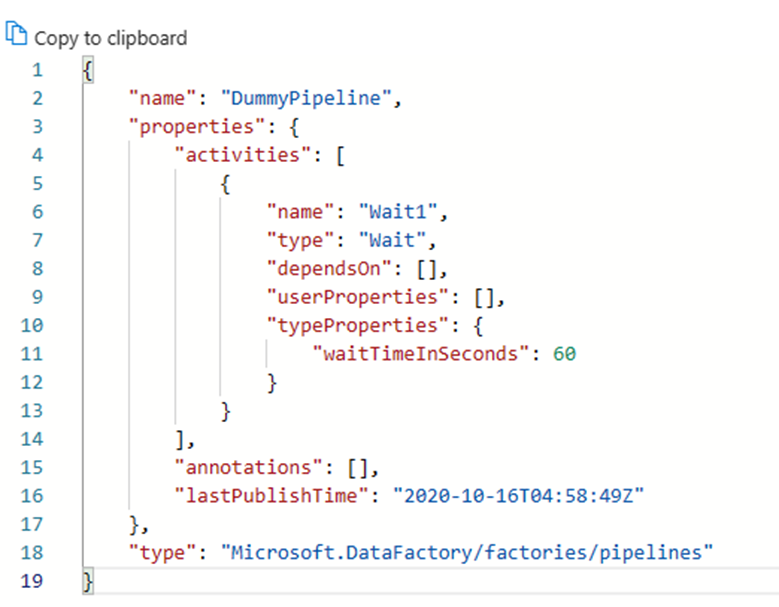
パイプライン、リンクされたサービス、トリガーなど、Azure Data Factory内のすべての成果物には、ビジュアル UI 統合の背後にある JSON に対応する "コード" 表現があります。 これらの成果物は、Azure Resource Manager テンプレート標準に準拠して動作します。 コードを見つけるには、キャンバスの右上にあるブラケット アイコンをクリックします。 サンプルの JSON "コード" は次のようになります。
![パイプライン UI 上の [JSON の表示] ボタンを示すスクリーンショット。](media/apply-dataops/view-json-button.png)
ライブ モードと Git バージョン コントロール
すべてのファクトリには、信頼できる 1 つの情報源があります。そのような情報源としては、パイプライン、リンク サービス、サービス内に格納されているトリガー定義があります。 この信頼できる情報源は、パイプライン実行が実行するものであり、トリガーの動作を決定するものになります。 ライブ モードの場合、発行のたびに、単一の信頼できる情報源が直接変更されます。 次の図は、ライブ モードの [すべて発行] (Publish All) ボタンの外観を示しています。
![ライブ モードの [すべて発行] (Publish All) ボタンを示すスクリーンショット。](media/apply-dataops/publish-button-live-mode.png)
ライブ モードは、開発者がコード変更の即時の影響を確認できるため、サイド プロジェクトの作業を 1 人で行っている場合には便利です。 ただし、開発者がチームで運用レベルの作業プロジェクトに取り組んでいる場合には推奨されません。 タイプ ミス、重要なリソースの誤削除、テストされていないコードの発行など、数多くの危険があります。 ミッション クリティカルなプロジェクトやプラットフォームで作業している場合は、Git リポジトリの導入を検討し、データ ファクトリで Git モードを使用して、開発プロセスを効率化します。 Git モードのバージョン コントロール機能とゲート チェックイン機能は、ライブ モードに直接触れることに関連する事故のほとんど (すべてではないにしても) を防ぐのに役立ちます。
注意
Git モードでは、[発行] (Publish) または [すべて発行] (Publish All) ボタンが [保存] または [すべて保存] に置き換えられ、変更は独自のブランチにコミットされます (ライブ コード ベースは直接変更されません)。
GitHubとAzure DevOps統合の設定
Azure Data Factoryでは、リポジトリをGitHubまたはAzure DevOpsに格納することを強くお勧めします。 このサービスではどちらの方法も完全にサポートされています。どちらのリポジトリを選択して使用するかは、個々の組織の標準によって決まります。 新しいリポジトリを設定する方法と既存のリポジトリに接続する方法には、Azure ポータルを使用する方法と、Azure Data Factory Studio UI から作成する方法の 2 つがあります。
Azure ポータル ファクトリの作成
Azure ポータルから新しいデータ ファクトリを作成すると、既定の Git リポジトリがAzure DevOpsされます。 リポジトリとしてGitHubを選択し、リポジトリの設定を構成することもできます。
Azure ポータルからリポジトリの種類を選択し、リポジトリとブランチの名前を入力して、Git とネイティブに統合された新しいファクトリを作成します。
![Git 構成設定が表示された [Azure Data Factoryの作成] UI を示すスクリーンショット。](media/apply-dataops/create-data-factory-configure-git.png)
組織内のAzure Policyでの Git の使用の強制
Azure Data Factory プロジェクトで Git を使用することを強くお勧めします。 完全な CI/CD プロセスを実装していない場合でも、Git と ADF の統合により、独自のサンドボックス環境 (Git ブランチ) にリソース成果物を保存できるようになります。この環境で、他のファクトリ ブランチとは独立して変更をテストできます。 Azure Policyを使用して、組織のファクトリで Git の使用を強制できます。
Azure Data Factory Studio
データ ファクトリを作成したら、Azure Data Factory Studio を使用してリポジトリに接続することもできます。 [管理] タブには、リポジトリとリポジトリの設定を構成するオプションが表示されます。
![Git Configuration セクションが選択された [管理] タブのAzure Data Factory Studio を示すスクリーンショット。](media/apply-dataops/data-factory-studio-git-configuration.png#lightbox)
ガイド付きのプロセスで一連の手順が実行されるので、選択したリポジトリの構成と接続を簡単に行えます。 設定が完了したら、共同作業を開始し、リソースをリポジトリに保存できます。
継続的インテグレーションと継続的デリバリー (CI/CD)
CI/CD はコード開発のパラダイムであり、変更の検査とテストは、開発、テスト、ステージングなど、さまざまなステージの進捗に応じて行われます。変更は、各ステージでレビューとテストが行われた後で、最終的に運用環境のライブ コード ベースに発行されます。
継続的インテグレーション (CI) は、開発者がコードベースに変更を行うたびにテストと検証を自動的に行う手法です。 継続的デリバリー (CD) は、継続的インテグレーション テストが成功すると、その変更が次のステージに継続的に導入されることを意味します。
前に簡単に説明したように、Azure Data Factoryの "コード" は Azure Resource Manager テンプレート JSON の形式になります。 そのため、継続的インテグレーションとデリバリー (CI/CD) プロセスを経る変更は、JSON BLOB への追加、削除、編集で構成されます。
Azure Data Factoryでのパイプラインの実行
Azure Data Factoryの CI/CD について説明する前に、まずサービスがパイプラインを実行する方法について説明する必要があります。 データ ファクトリは、パイプラインを実行する前に、次のことを行います。
- パイプラインの最新の発行済み定義とその関連資産 (データセットやリンク サービスなど) をプルします。
- パイプラインをアクションにコンパイルします。データ ファクトリでそのパイプラインが最近実行された場合は、キャッシュされたコンパイルからアクションを取得します。
- パイプラインを実行します。
パイプラインの実行では、次の手順のようになります。
- サービスによって、パイプライン定義のポイントインタイム スナップショットが作成されます。
- パイプラインの実行中に、定義は変更されません。
- パイプライン実行が長時間にわたる場合でも、パイプラインはその開始後に行われた後続の変更の影響を受けません。 実行中に変更をリンク サービスやパイプラインなどに発行しても、進行中の実行には影響しません。
- 変更を発行すると、発行後に開始された後続の実行では、更新された定義が使用されます。
Azure Data Factoryでの発行
Azureリリース パイプラインを使用して発行を自動化するパイプラインをデプロイしたり、手動でデプロイメントしてResource Managerテンプレートを利用したりする場合でも、バックエンドでの発行は、各成果物に対してデータセット、リンクされたサービス、パイプライン、およびトリガーに対する一連の作成や更新操作から成ります。 この効果は、基になる Rest API 呼び出しを直接行うのと同じです。
このアクションにより、次のようになります。
- これらの API 呼び出しはすべて同期的です。つまり、呼び出しは、発行が成功または失敗した場合にのみ返されます。 成果物の部分デプロイという状態は存在しません。
- API 呼び出しは、ほぼ順次処理されます。 成果物の参照依存関係を維持しながら、呼び出しを並列化するようにしています。 デプロイの順序は、リンク サービス -> データセット/統合ランタイム -> パイプライン -> トリガーです。 この順序により、依存成果物がその依存関係を正しく参照できるようになります。 たとえば、パイプラインはデータセットに依存するため、データ ファクトリはデータセットの後にそれらをデプロイします。
- リンク サービス、データセットなどのデプロイはパイプラインから独立しています。 パイプラインが更新される前に、データ ファクトリがリンク サービスを更新する場合があります。 この状況については、「トリガーを停止するタイミング」セクションで説明します。
- デプロイしても、ファクトリから成果物は削除されません。 ファクトリをクリーンアップするには、成果物の種類 (パイプライン、データセット、リンク サービスなど) ごとに DELETE API を明示的に呼び出す必要があります。 たとえば、Azure Data Factoryのデプロイ後のサンプル スクリプトを参照してください。
- ユーザーがパイプライン、データセット、リンク サービスに触れていない場合でも、ファクトリへのクイック更新 API 呼び出しが呼び出されます。
トリガーの公開
- トリガーには、開始または停止の状態があります。
- 開始モードのトリガーを変更することはできません。 変更を発行する前にトリガーを停止する必要があります。
-
開始モードのトリガーで、トリガー API の作成または更新を呼び出すことができます。
- ペイロードが変更されると、API は失敗します。
- ペイロードが変更されていない場合、API は成功します。
- この動作は、トリガーを停止するタイミングに大きな影響を与えます。
トリガーを停止するタイミング
ライブ トリガーによってパイプライン実行が常に開始される運用データ ファクトリへのデプロイについて、問題は "トリガーを停止する必要があるか" ということです。
簡単に答えるなら、次のいくつかのシナリオでのみ、トリガーの停止を検討する必要があります。
- トリガー定義 (終了日、頻度、パイプラインの関連付けなどのフィールドを含む) を更新する場合は、トリガーを停止する必要があります。
- ライブ パイプラインで参照されているデータセットまたはリンク サービスを更新する場合は、トリガーを停止することをお勧めします。 たとえば、SQL Serverの資格情報をローテーションする場合です。
- 関連付けられているパイプラインでエラーがスローされ、サーバーの障害や負荷の原因になっている場合は、トリガーを停止できます。
トリガーの停止に関して考慮すべきいくつかの点を次に示します。
- 「Pipeline Runs in Azure Data Factory で説明されているように、トリガーがパイプラインの実行を開始すると、パイプライン、データセット、統合ランタイム、およびリンクされたサービス定義のスナップショットが取得されます。 変更がバックエンドに反映される前にパイプラインが実行されると、トリガーは古いバージョンで実行を開始します。 ほとんどの場合、これで問題ありません。
- 「トリガーの発行」セクションで説明されているように、 開始状態のトリガーは更新できません。 そのため、トリガー定義の詳細を変更する必要がある場合は、変更を発行する前にトリガーを停止します。
- Azure Data Factory での
発行に関するセクションで説明したように、パイプラインの変更前にデータセットまたはリンクされたサービスに対する変更が発行されます。 パイプライン実行で正しい資格情報が使用され、適切なサーバーと通信が行われるようにするため、関連付けられているトリガーも停止することをお勧めします。
"コード" 変更の準備
pull request に関しては、以下のベスト プラクティスに従うようお勧めします。
- 各開発者は、それぞれ自分のブランチで作業し、1 日の終わりにリポジトリのメイン ブランチへの pull request を作成する必要があります。 GitHub および DevOps の pull request に関するチュートリアルを参照してください。
- ゲート キーパーが pull request を承認し、変更をメイン ブランチにマージすると、CI/CD プロセスを開始できます。 環境全体で変更を促進するための推奨される手法として、自動 と 手動の 2 つがあります。
- CI/CD パイプラインを開始する準備ができたら、一般的に Azure Pipeline Release を使用してこれを行うか、この オープンソース ユーティリティを使用して、Azure Player から特定の個々のパイプラインをデプロイすることができます。
変更の自動デプロイ
自動デプロイに役立つには、Azure Data Factory ユーティリティ npm パッケージを使用することをお勧めします。 npm パッケージを使用することは、パイプライン内のすべてのリソースを検証し、ユーザーの ARM テンプレートを生成するのに役立ちます。
Azure Data Factory ユーティリティ npm パッケージの使用を開始するには、継続的インテグレーションと配信に関するAutomated 発行を参照してください。
変更の手動適用
ブランチを Git リポジトリのメイン コラボレーション ブランチにマージした後、ライブ Azure Data Factory サービスに変更を手動で発行できます。 このサービスでは、開発以外のファクトリからの発行を、[発行を無効にする (ADF Studio から)] (Disable publish (from ADF Studio)) オプションを使用して UI で制御できます。
![Git リポジトリの編集ページと、[発行を無効にする (ADF Studio から)] (Disable publish (from ADF Studio)) ボタンを示すスクリーンショット。](media/apply-dataops/disable-publish-option.png)
選択的デプロイメント
選択的展開は、GitHubとAzure DevOpsの機能 (cherry picking と呼ばれます) に依存します。 この機能を使用すると、特定の変更のみがデプロイされ、他の変更はデプロイされないようにすることができます。 たとえば、1 人の開発者が複数のパイプラインに変更を加えはしたものの、今日のデプロイでは、変更を 1 つだけにデプロイしたい場合があります。
Azure DevOpsとGitHubのチュートリアルに従って、必要なパイプラインに関連するコミットを選択します。 トリガー、リンク サービス、およびパイプラインに関連付けられている依存関係に対して行われた関連する変更など、すべての変更が選択されていることを確認します。
変更をチェリー ピックし、メイン コラボレーション パイプラインにマージしたら、提案された変更の CI/CD プロセスを開始できます。 追加の情報として、この記事の「自動テスト」セクションでは、選択的デプロイのための外部フレームワークをどのようにホットフィックスし、チェリーピックまたは利用するかについて説明されています。
単体テスト
単体テストは、新しいパイプラインの開発プロセスや既存のデータ ファクトリ成果物の編集プロセスの重要な部分で、コードのコンポーネントをテストすることに重点が置かれています。 Data Factory では、パイプライン デバッグ機能を使用することにより、パイプライン レベルとデータ フロー成果物レベルの両方で個別に単体テストを行うことができます。

データ フローを開発するときは、データ プレビュー機能を使用して、変更を運用環境にデプロイする前に単体テストを実行することにより、個々の変換とコード変更に関する分析情報を得ることができます。

このサービスは、Azure Data Factoryでデバッグと単体テストを行うときに、UI でパイプライン アクティビティのライブおよび対話型のフィードバックを提供します。
自動テスト
Azure Data Factoryで使用できる自動テストに使用できるツールがいくつかあります。 サービスは JSON エンティティとしてサービスにオブジェクトを格納するため、Visual Studioでオープンソースの .NET 単体テスト フレームワーク NUnit を使用すると便利です。 ファクトリの自動単体テスト環境を設定する方法について詳しく説明した記事として、Azure Data Factory の自動テストをセットアップする を参照してください。 (このブログの使用許可に関して、Richard Swinbank 氏に感謝します。)
デプロイ前とデプロイ後の手順の CI/CD プロセスの一環として、PowerShell または AZ CLI で、TEST パイプラインを実行することもできます。
データ ファクトリの主な強みは、データ セットのパラメーター化にあります。 この機能を使用することで、異なるデータ セットで同じパイプラインを実行して、新しい開発がすべてのソースとターゲットの要件を満たしていることを確認できます。
Azure Data Factory用のその他の CI/CD フレームワーク
前に説明したように、組み込みの Git 統合は、マージ、分岐、比較、および公開を含むAzure Data Factory UI を通じてネイティブに使用できます。 ただし、同様の機能を提供する代替メカニズムを提供する、Azure コミュニティで人気のある他の便利な CI/CD フレームワークがあります。 Azure Data Factory Git 手法は ARM テンプレートに基づいていますが、
Azure Data Factoryでのデータ ガバナンス
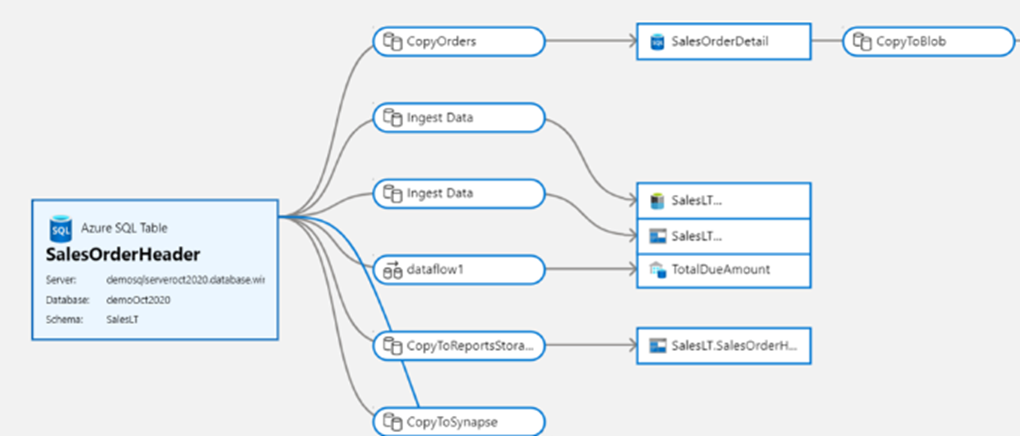
効果的な DataOps の重要な側面は、データ ガバナンスです。 データ統合 ETL ツールでは、データ系列と成果物のリレーションシップを提供することで、ダウンストリームの変更の影響をデータ エンジニアが理解するための重要な情報を提供できます。 データ ファクトリには、ファクトリの実装を構成する組み込みの関連成果物ビューが用意されています。
Microsoft Purviewとのネイティブ統合により、系列、影響分析、データ カタログ化がさらに提供されます。
Microsoft Purview は、オンプレミス、マルチクラウド、サービスとしてのソフトウェア (SaaS) データの管理と管理に役立つ統合データ ガバナンス ソリューションを提供します。 これにより、自動化されたデータ検出、機密データ分類、エンドツーエンドのデータ系列を使用して、データ環境全体の最新のマップを簡単に作成できるようになります。 これらの機能により、データ コンシューマーは貴重で信頼できるデータ管理を利用できるようになります。
Purview Data Catalogへのネイティブ統合により、データ ファクトリを使用すると、組織のデータ資産全体にわたってデータ統合パイプラインで使用するデータ資産を簡単に検索および検出できます。
Azure Data Factory Studio のメイン検索バーを使用して、Purview カタログ内のデータ資産を検索できます。
