適用対象: Azure Data Factory Azure Synapse Analytics
Azure Data Factory Azure Synapse Analytics
ヒント
Data Factory in Microsoft Fabric は、よりシンプルなアーキテクチャ、組み込みの AI、および新機能を備えた次世代のAzure Data Factoryです。 データ統合を初めて使用する場合は、Fabric Data Factory から始めます。 既存の ADF ワークロードをFabricにアップグレードして、データ サイエンス、リアルタイム分析、レポートの新機能にアクセスできます。
データ フローは、Azure Data Factory パイプラインとAzure Synapse Analytics パイプラインの両方で使用できます。 この記事は、マッピング データ フローに適用されます。 変換を初めて使用する場合は、入門記事「 マッピング データ フローを使用したデータの変換」を参照してください。
データの変換を完了したら、シンク変換を利用してそれを変換先ストアに書き込みます。 各データ フローには少なくとも 1 つのシンク変換が必要ですが、変換フローを完了するために必要な数だけのシンクに書き込むことができます。 追加のシンクに書き込むには、新しい分岐と条件分割によって新しいストリームを作成します。
各シンク変換が関連付けられるデータセット オブジェクトまたはリンクされたサービスは 1 つだけです。 シンク変換では、データの形状と書き込みを行う場所が決定されます。
インライン データセット
シンク変換を作成するとき、シンク情報をデータセット オブジェクト内で定義するのか、シンク変換内で定義するのか選択します。 ほとんどの形式はどちらか一方しかありません。 特定のコネクタの使用方法については、該当するコネクタ ドキュメントを参照してください。
形式がインラインとデータセット オブジェクトの両方でサポートされているとき、両方に利点があります。 データセット オブジェクトは、他のデータ フローと、コピーなどのアクティビティとで使用できる再利用可能なエンティティです。 これらの再利用可能なエンティティは、強化されたスキーマを使用する場合に特に役立ちます。 データセットは Spark を基盤としていません。 場合によっては、シンク変換で特定の設定またはスキーマ プロジェクションをオーバーライドすることが必要となることがあります。
柔軟なスキーマ、1 回限りのシンク インスタンス、またはパラメーター化されたシンクを使用する際は、インライン データセットが推奨されます。 シンクが大きくパラメーター化されている場合、インライン データセットを使用すると、"ダミー" オブジェクトを作成できません。 インライン データセットは Spark を基盤とし、そのプロパティはデータ フローにネイティブです。
インライン データセットを使用するには、 [シンクの種類] セレクターで目的の形式を選択します。 シンク データセットを選択するのではなく、接続するリンクサービスを選択します。
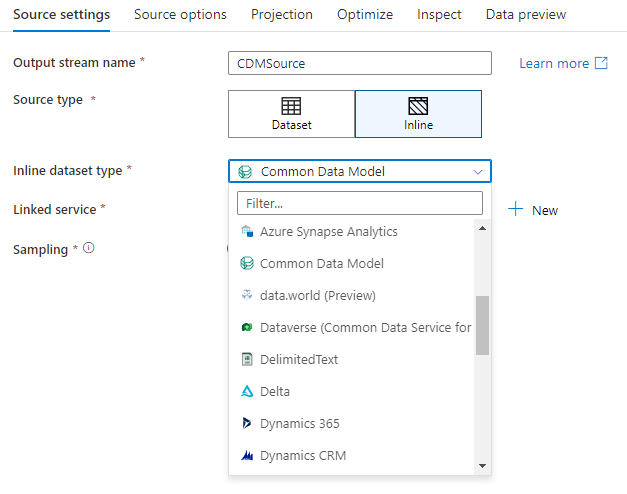
ワークスペース DB(「Synapse ワークスペース」のみ)
Azure Synapse ワークスペースでデータ フローを使用する場合は、Synapse ワークスペース内にあるデータベースの種類にデータを直接シンクする追加のオプションがあります。 これにより、それらのデータベース用のリンクされたサービスまたはデータセットを追加する必要性が軽減されます。 ワークスペース DB を選択すると、Azure Synapse データベース テンプレートを使用して作成されたデータベースにもアクセスできます。
注
Azure Synapse ワークスペース DB コネクタは現在パブリック プレビュー段階であり、現時点では Spark Lake データベースでのみ使用できます
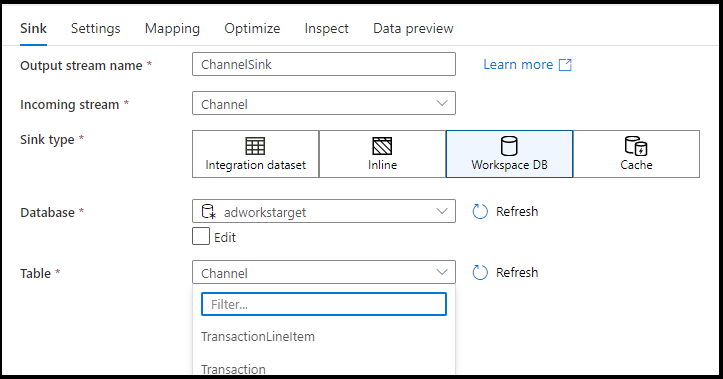
サポートされているシンクの種類
マッピング データ フローは、抽出、読み込み、変換 (ELT) アプローチに従い、Azure内にある taging データセットで動作します。 現在、シンク変換には次のデータセットを使用できます。
ヒント
シンクは、ソースとは異なる形式にすることができます。 これは、ある形式から別の形式に変換する方法の 1 つのステップです。 たとえば、CSV から Parquet シンクです。 これを正しく機能させるには、ソースとシンクの間のデータ フローでいくつかの変換を行う必要がある場合があります。 (たとえば、Parquet には CSV よりも具体的なヘッダー要件があります)。
| コネクタ | フォーマット | データセット/インライン |
|---|---|---|
| Azure Blob Storage |
Avro 区切りテキスト デルタ JSON ORC パーケット |
✓/✓ ✓/✓ -/✓ ✓/✓ ✓/✓ ✓/✓ |
| Azure Cosmos DB for NoSQL | ✓/- | |
| Azure Data Lake Storage Gen1 |
Avro 区切りテキスト JSON ORC パーケット |
✓/- ✓/- ✓/- ✓/✓ ✓/- |
| Azure Data Lake Storage Gen2 |
Avro 共通データモデル 区切りテキスト デルタ JSON ORC パーケット |
✓/✓ -/✓ ✓/✓ -/✓ ✓/✓ ✓/✓ ✓/✓ |
| Azure Database for MySQL | ✓/✓ | |
| Azure Database for PostgreSQL | ✓/✓ | |
| Azure Data Explorer | ✓/✓ | |
| Azure SQL データベース | ✓/✓ | |
| Azure SQL Managed Instance | ✓/- | |
| Azure Synapse Analytics | ✓/- | |
| Dataverse (データバース | ✓/✓ | |
| Dynamics 365 | ✓/✓ | |
| Dynamics CRM | ✓/✓ | |
| ファブリック レイクハウス | ✓/✓ | |
| SFTP |
Avro 区切りテキスト JSON ORC パーケット |
✓/✓ ✓/✓ ✓/✓ ✓/✓ ✓/✓ |
| 雪片 | ✓/✓ | |
| SQL Server | ✓/✓ |
これらのコネクタに固有の設定は、[設定] タブにあります。これらの設定に関する情報とデータ フロー スクリプトの例は、コネクタのドキュメントに記載されています。
このサービスから、90 を超えるネイティブ コネクタにアクセスできます。 それらの他のソースにデータ フローからデータを書き込むには、コピー アクティビティを使用し、サポートされているシンクからそのデータを読み込みます。
シンクの設定
シンクを追加したら、 [シンク] タブを使用して構成を行います。ここでは、シンクを書き込むデータセットを選択して作成できます データセット パラメーターの開発値は、デバッグの設定で構成できます (デバッグ モードをオンにする必要があります)。
以下のビデオでは、テキスト区切りのファイルの種類に対応するさまざまなシンク オプションについて説明します。
![[シンク] の設定を示すスクリーンショット。](media/data-flow/sink-settings.png)
[スキーマの誤差] : [スキーマの誤差] は、データ フロー内の柔軟なスキーマをネイティブに処理するこのサービスの機能であり、列の変更を明示的に定義する必要はありません。 シンク データ スキーマで定義されている内容に加え、追加の列を書き込むには、Allow schema drift(スキーマ ドリフトを許可する)を有効にします。
[スキーマの検証] : [スキーマの検証] を選択すると、シンク プロジェクションの列がシンク ストアで見つからない場合、またはデータ型が一致しない場合にデータ フローは失敗します。 この設定を使用して、シンク スキーマが定義済みのプロジェクションのコントラクトを満たすように強制できます。 これは、列の名前または型が変更されたことを通知する、データベース シンクのシナリオにおいて便利です。
キャッシュ シンク
キャッシュ シンクは、データ フローによって、データ ストアではなく Spark キャッシュにデータが書き込まれる場合に使用されます。 マッピング データ フローでは、キャッシュ参照を使用して、同じフロー内でこのデータを何度も参照できます。 これは、式の一部としてデータを参照したいが、列を明示的に結合したくない場合に便利です。 キャッシュ シンクが有用である一般的な例としては、データ ストアで最大値を検索することや、エラー コードをエラー メッセージ データベースと照合することが挙げられます。
キャッシュ シンクに書き込むには、シンク変換を追加し、シンクの種類として [キャッシュ] を選択します。 他のシンクの種類とは異なり、外部ストアに書き込むのではないため、データセットやリンクされたサービスを選択する必要はありません。
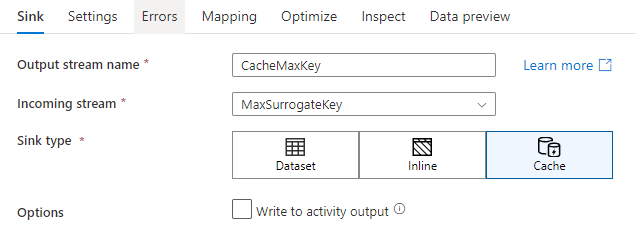
シンクの設定で、必要に応じてキャッシュ シンクのキー列を指定できます。 これは、キャッシュ参照で lookup() 関数を使用する場合に、一致条件として使用されます。 キー列を指定する場合は、キャッシュ参照で outputs() 関数は使用できません。 キャッシュ参照構文の詳細については、キャッシュされた参照に関する記事を参照してください。
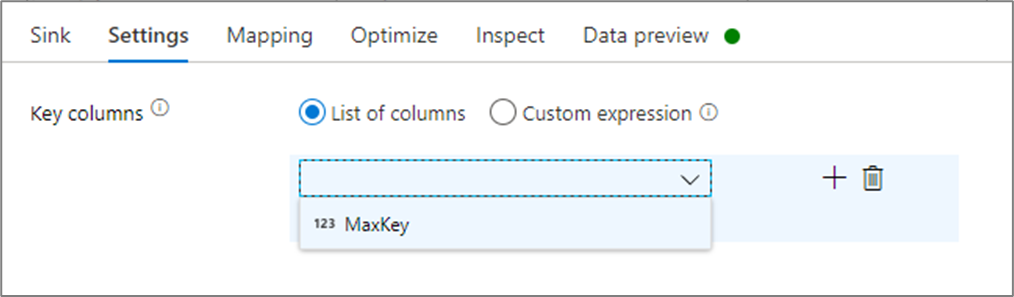
たとえば、column1 というキャッシュ シンクに 1 つのキー列 cacheExample を指定する場合、cacheExample#lookup() の呼び出しに、キャッシュ シンク内のどの行と照合するかを指定する 1 つのパラメーターを含めます。 この関数によって、マップされた各列のサブ列を含む 1 つの複合列が出力されます。
注
キャッシュ シンクは、キャッシュ参照を使用してそれを参照する変換から、完全に独立したデータ ストリームに存在する必要があります。 また、キャッシュ シンクは、最初に書き込まれるシンクである必要があります。
アクティビティ出力への書き込み
キャッシュ シンクは必要に応じて、Data Flow アクティビティの出力にデータを書き込み、パイプライン内の別のアクティビティへの入力として使用できます。 これにより、データ ストアにデータを保持することなく、データ フロー アクティビティからデータをすばやく簡単に渡すことができます。
パイプラインに直接挿入されるData Flowからの出力は 2 MB に制限されることに注意してください。 したがって、Data Flowは、2 MB の制限内に留まっている間にできるだけ多くの行を出力するように追加しようとします。したがって、アクティビティ出力内のすべての行が表示されない場合があります。 Data Flow アクティビティ レベルで "最初の行のみ" を設定すると、必要に応じてData Flowからのデータ出力を制限することもできます。
更新方法
データベース シンクの種類の場合、[設定] タブに [Update method] (更新メソッド) プロパティが含まれます。 既定値は insert ですが、update、upsert、delete 用のチェックボックス オプションも含まれています。 これらの追加オプションを利用するには、Alter Row 変換をシンクの前に追加する必要があります。 行の変更を使用すると、各データベース アクションの条件を定義できます。 ソースがネイティブ CDC 対応ソースの場合、行の変更を使用せずに更新メソッドを設定できます。ADF では insert、update、upsert、delete の行マーカーを既に認識しているためです。
フィールドのマッピング
シンクの [マッピング] タブ上では、Select 変換と同様に、受信列が書き込まれるかどうかを決定できます。 既定では、誤差のある列を含め、すべての入力列がマップされます。 この動作は "自動マッピング" として知られています。
自動マッピングを無効にすると、固定列ベースのマッピングまたはルールベースのマッピングのいずれかを追加することができます。 ルールベースのマッピングを使用すると、パターン マッチングを含む式を作成できます。 固定マッピングを使用すると、論理および物理列名がマップされます。 ルールベースのマッピングの詳細については、マッピング データ フローの列パターンに関するページを参照してください。
カスタム シンクの順序付け
既定では、データが複数のシンクに書き込まれる順序は決まっていません。 変換ロジックが完了すると、実行エンジンによってデータは並列に書き込まれます。シンクの順序は実行ごとに異なる場合があります。 シンクの順序を正確に指定するには、データフローの [全般] タブで [カスタム シンクの順序付け] を有効にします。 有効にすると、シンクは昇順で連続して書き込まれます。
![[カスタム シンクの順序付け] を示すスクリーンショット。](media/data-flow/custom-sink-ordering.png)
注
キャッシュされた参照を使用する場合は、シンクの順序付けで、キャッシュされたシンクが順序付けの一番下 (または最初) である 1 に設定されるようにしてください。
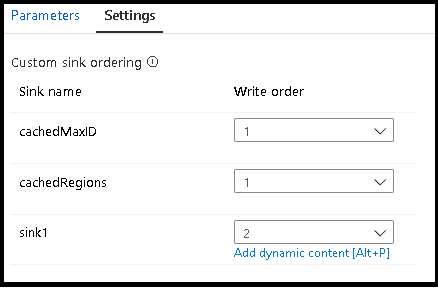
シンク グループ
シンクをグループ化するには、一連のシンクに同じ順序番号を適用します。 このサービスは、それらのシンクを並列に実行できるグループとして扱います。 並列実行のオプションは、パイプライン データ フロー アクティビティに表示されます。
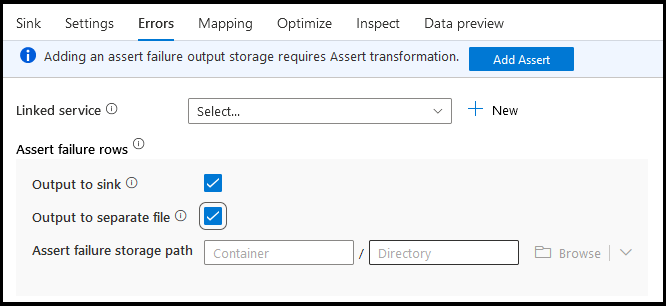
エラー
シンク エラー タブでは、データベース ドライバー エラーおよび失敗したアサーションの出力をキャプチャしてリダイレクトするように、エラー行の処理を構成できます。
データベースに書き込む場合、書き込み先で設定されている制約によって、データの特定の行が失敗することがあります。 既定では、データ フローの実行は最初に発生したエラーで失敗します。 一部のコネクタでは、 [エラーのまま続行する] を選択すると、個々の行でエラーが発生した場合でもデータ フローを完了することができます。 現時点では、この機能はAzure SQL DatabaseとAzure Synapseでのみ使用できます。 詳細については、Azure SQL DB での
以下は、シンク変換でデータベースのエラー行の処理を自動的に使用する方法を説明するビデオ チュートリアルです。
アサートエラー行の場合は、データ フローのアップストリームで Assert 変換を使用し、失敗したアサーションをシンク エラー タブの出力ファイルにリダイレクトできます。また、ここには、アサーションエラーが発生した行を無視し、それらの行をシンク変換先データ ストアにまったく出力しないオプションもあります。
シンクでのデータのプレビュー
デバッグ モードでデータ プレビューをフェッチすると、データはシンクに書き込まれません。 データの外観を示すスナップショットが返されますが、指定した変換先には何も書き込まれません。 シンクへのデータの書き込みをテストするには、パイプライン キャンバスからパイプラインのデバッグを実行します。
データ フローのスクリプト
例
次に示すのは、シンク変換とそのデータ フロー スクリプトの例です。
sink(input(
movie as integer,
title as string,
genres as string,
year as integer,
Rating as integer
),
allowSchemaDrift: true,
validateSchema: false,
deletable:false,
insertable:false,
updateable:true,
upsertable:false,
keys:['movie'],
format: 'table',
skipDuplicateMapInputs: true,
skipDuplicateMapOutputs: true,
saveOrder: 1,
errorHandlingOption: 'stopOnFirstError') ~> sink1
関連するコンテンツ
これでデータ フローが作成されたので、データ フローのアクティビティをパイプラインに追加します。