適用対象: Azure Data Factory Azure Synapse Analytics
Azure Data Factory Azure Synapse Analytics
ヒント
Data Factory in Microsoft Fabric は、よりシンプルなアーキテクチャ、組み込みの AI、および新機能を備えた次世代のAzure Data Factoryです。 データ統合を初めて使用する場合は、Fabric Data Factory から始めます。 既存の ADF ワークロードをFabricにアップグレードして、データ サイエンス、リアルタイム分析、レポートの新機能にアクセスできます。
データ フローは、Azure Data Factory パイプラインとAzure Synapse Analytics パイプラインの両方で使用できます。 この記事は、マッピング データ フローに適用されます。 変換を初めて使用する場合は、入門記事「 マッピング データ フローを使用したデータの変換」を参照してください。
データの各行に増分キー値を追加するには、代理キー変換を使用します。 これは、スター スキーマ分析データ モデルでディメンション テーブルを設計する場合に便利です。 スター スキーマでは、ディメンション テーブル内の各メンバーには、ビジネス キー以外の一意のキーが必要です。
構成
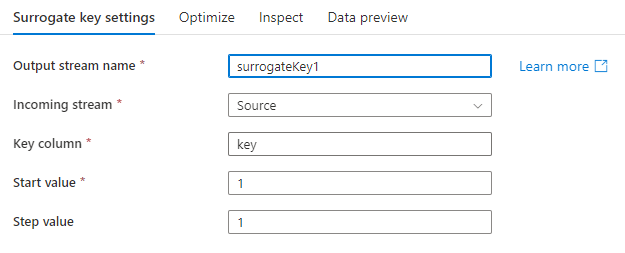
キー列: 生成された代理キー列の名前。
開始値: 生成される最小のキー値。
既存のソースからキーをインクリメントする
ソース内に存在する値からシーケンスを開始するには、キャッシュ シンクを使用してその値を保存し、派生列変換を使用して 2 つの値をまとめて追加することをお勧めします。 キャッシュされた参照を使用して出力を取得し、生成されたキーにそれを追加します。 詳細については、キャッシュ シンクおよびキャッシュされた参照に関するページを参照してください。
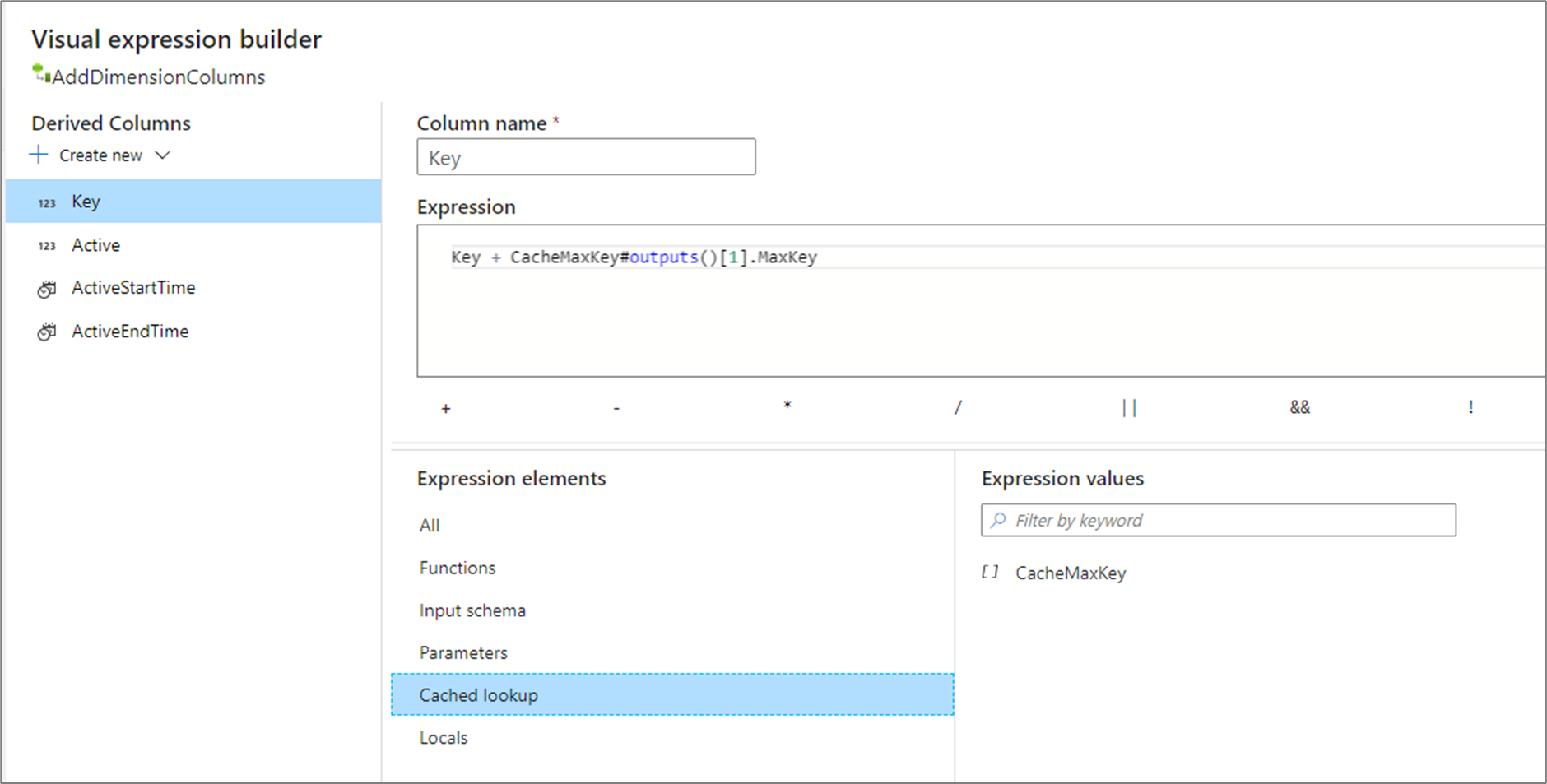
既存の最大値からの増分
以前の最大によってキー値をシードするには、ソース データがある場所に基づいて 2 つの手法を使用できます。
データベース ソース
SQL クエリ オプションを使用して、ソースから MAX () を選択します。 たとえば、Select MAX(<surrogateKeyName>) as maxval from <sourceTable> のようにします。
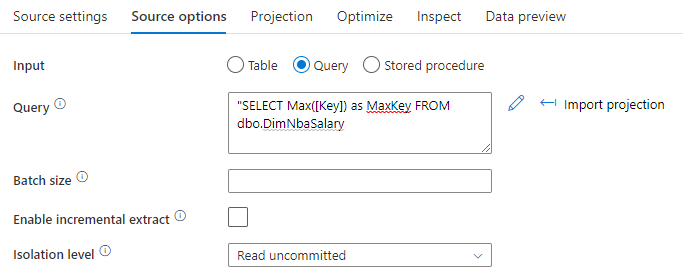
ファイル ソース
前の最大値がファイル内にある場合は、集計変換内で max() 関数を使用して、前の最大値を取得します。
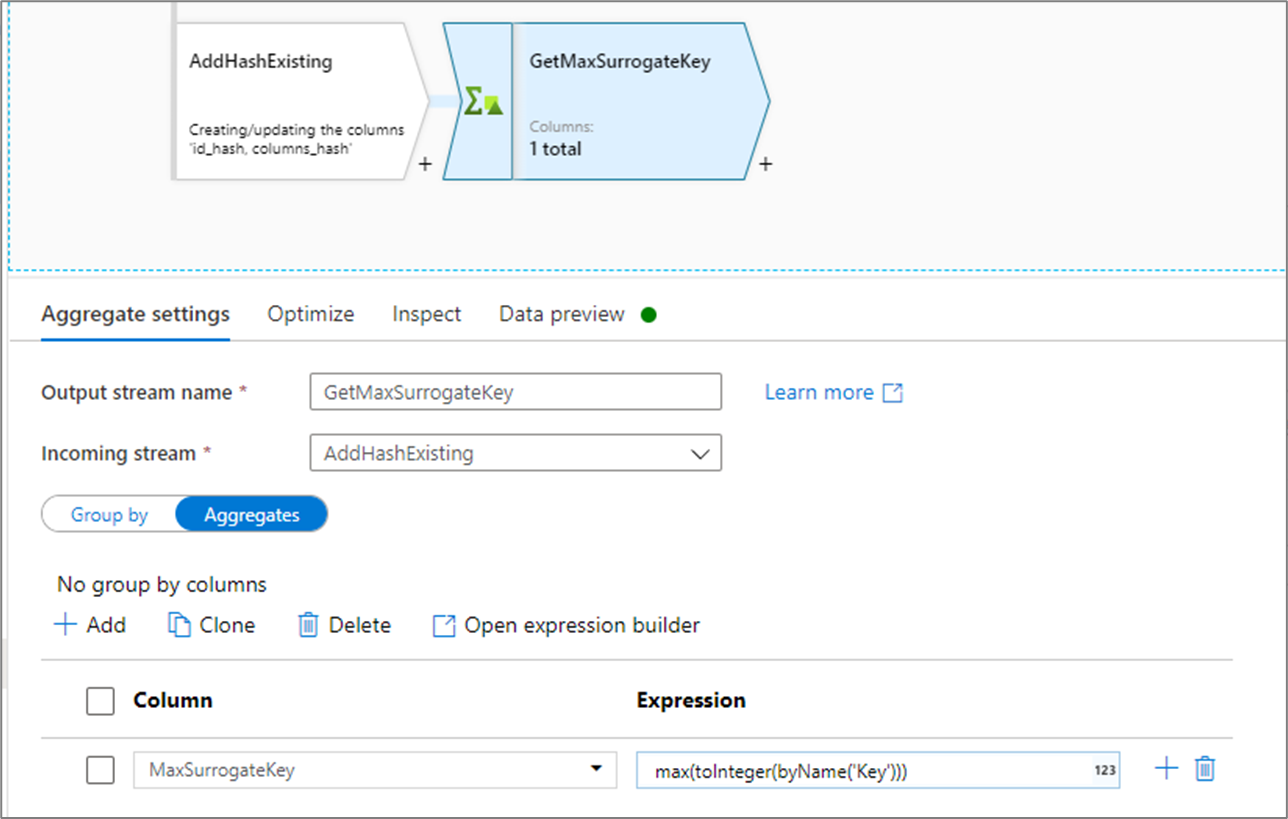
どちらの場合も、キャッシュ シンクに書き込み、値を参照する必要があります。
データ フローのスクリプト
構文
<incomingStream>
keyGenerate(
output(<surrogateColumnName> as long),
startAt: <number>L
) ~> <surrogateKeyTransformationName>
例
次のコード スニペットには、上記の代理キー構成に対するデータ フロー スクリプトが含まれています。
AggregateDayStats
keyGenerate(
output(key as long),
startAt: 1L
) ~> SurrogateKey1