適用対象:  Azure Data Factory Azure Synapse Analytics
Azure Data Factory Azure Synapse Analytics
ヒント
企業向けのオールインワン分析ソリューション、Microsoft Fabric の Data Factory をお試しください。 Microsoft Fabric は、データ移動からデータ サイエンス、リアルタイム分析、ビジネス インテリジェンス、レポートまで、あらゆるものをカバーしています。 無料で新しい試用版を開始する方法について説明します。
自動機械学習 (AutoML) は、分類、回帰、および時系列予測に指定したターゲット メトリックを使用して、最適なモデルを自動的にトレーニング、調整、および取得するために、機械学習プロジェクトで採用されています。
AutoML の 1 つの課題は、データ ウェアハウスまたはトランザクション データベースからの生データが 10 GB のような巨大なデータセットになることです。 大規模なデータセットでは、モデルのトレーニングに時間がかかります。そのため、Azure Machine Learning モデルをトレーニングする前に、データ処理を最適化することをお勧めします。 このチュートリアルでは、Azure Data Factory を使用して、データセットを Machine Learning データセットの AutoML ファイルにパーティション分割する方法について説明します。
AutoML プロジェクトには、次の 3 つのデータ処理シナリオが含まれています。
モデルをトレーニングする前に、大きなデータを AutoML ファイルにパーティション分割します。
Pandas データ フレームは、一般的に、モデルをトレーニングする前にデータを処理するために使用されます。 Pandas データ フレームは 1 GB 未満のデータ サイズに適していますが、データが 1 GB を超える場合は、Pandas データ フレームでのデータ処理速度が低下します。 場合によっては、メモリ不足のエラー メッセージが表示されることもあります。 機械学習では Parquet ファイル形式を使用することをお勧めします。それがバイナリ列形式であるためです。
Data Factory のマッピング データ フローは、データ エンジニアがコードを作成しなくても済むように視覚的に設計されたデータ変換です。 マッピング データ フローは、大きいデータを処理するための強力な手段となります。スケールアウトされた Spark クラスターがパイプラインで使用されるためです。
トレーニング データセットとテスト データセットを分割します。
トレーニング データセットは、トレーニング モデルに使用されます。 テスト データセットは、機械学習プロジェクトでモデルを評価するために使用されます。 マッピング データ フローの条件分割アクティビティによって、トレーニング データとテスト データが分割されます。
非修飾データを削除します。
非修飾データ (行が 0 の Parquet ファイルなど) は、削除することができます。 このチュートリアルでは、集計アクティビティを使用して、行数を取得します。 この行数は、非修飾データを削除するための条件になります。
準備
次の Azure SQL Database テーブルを使用します。
CREATE TABLE [dbo].[MyProducts](
[ID] [int] NULL,
[Col1] [char](124) NULL,
[Col2] [char](124) NULL,
[Col3] datetime NULL,
[Col4] int NULL
)
データ形式を Parquet に変換する
次のデータ フローによって、SQL Database テーブルが Parquet ファイル形式に変換されます。
- ソース データセット: SQL Database のトランザクション テーブル。
- シンク データセット: Parquet 形式の BLOB ストレージ。
行数に基づいて非修飾データを削除する
2 未満の行数を削除する必要があるとします。
集計アクティビティを使用して、行数を取得します。 Col2 に基づいた [グループ化] と、行数に
count(1)を指定した [集計] を使用します。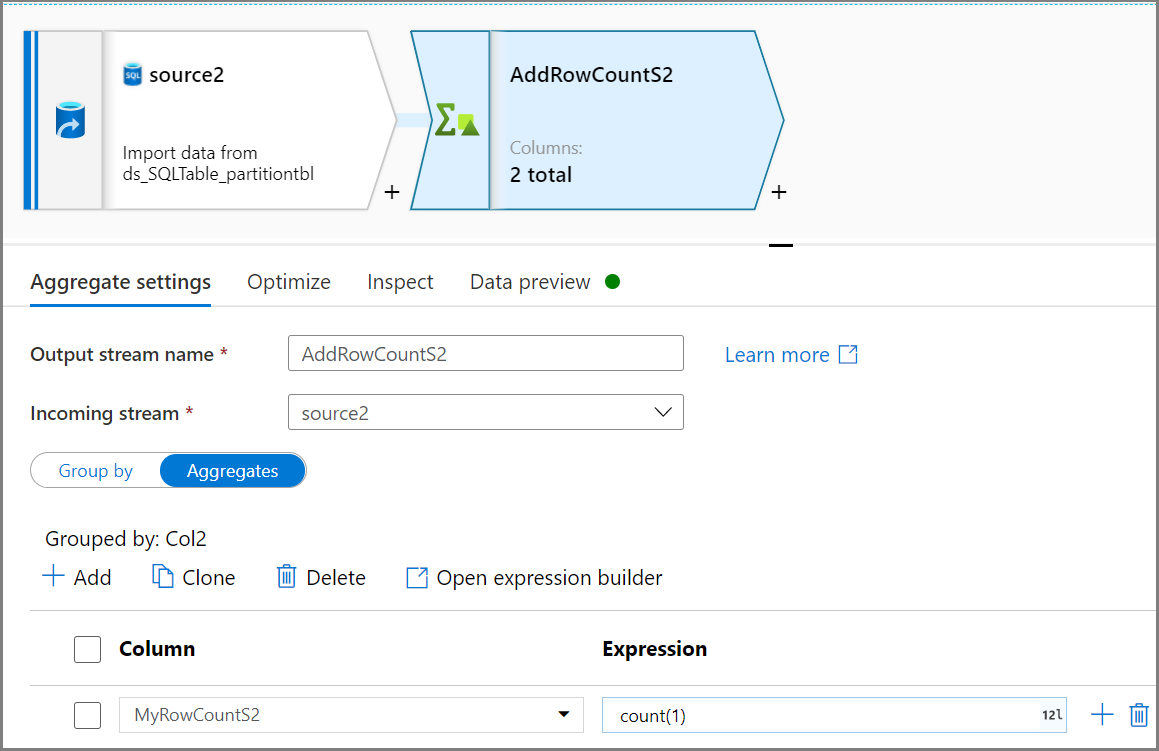
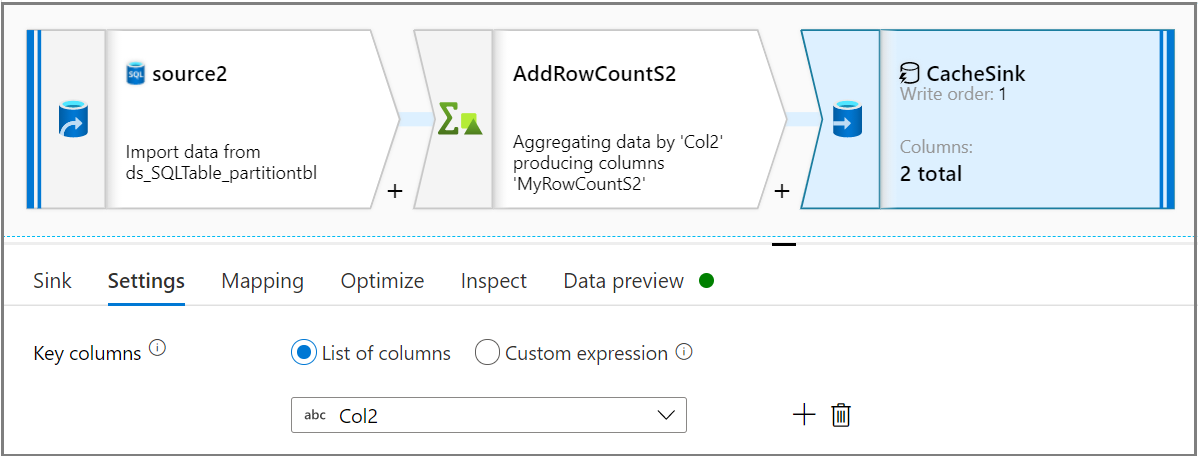
シンク アクティビティを使用して、 [シンク] タブで [シンクの種類] として [キャッシュ] を選択します。次に、 [設定] タブの [キー列] ドロップダウン リストから目的の列を選択します。
派生列アクティビティを使用して、ソース ストリーム内の行数列を追加します。 [派生列の設定] タブで
CacheSink#lookup式を使用して、CacheSink から行数を取得します。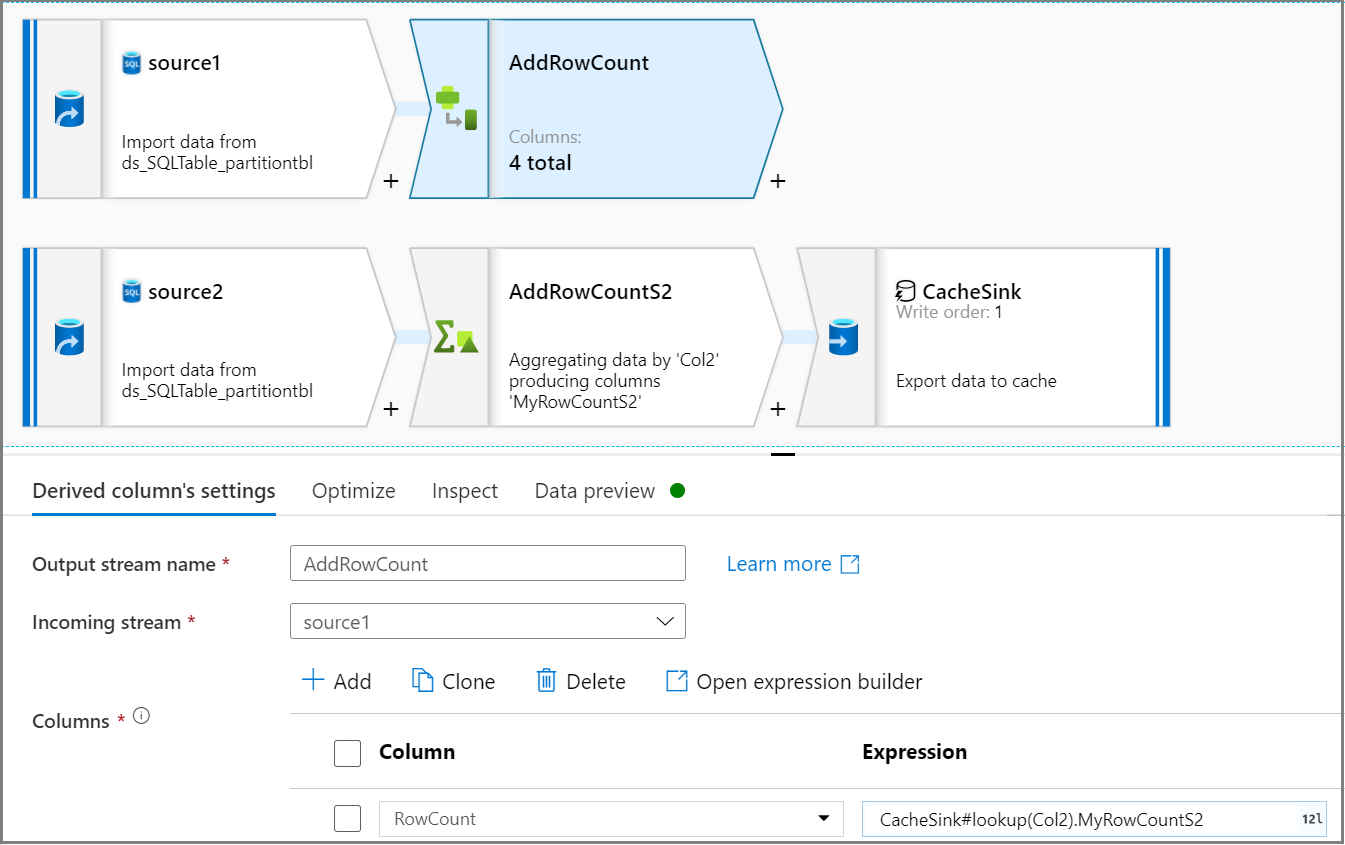
条件分割アクティビティを使用して、非修飾データを削除します。 この例では、行数は Col2 列に基づいています。 条件は 2 未満の行数を削除することであるため、2 つの行 (ID=2 と ID=7) が削除されます。 データ管理のために、非修飾データを BLOB ストレージに保存します。
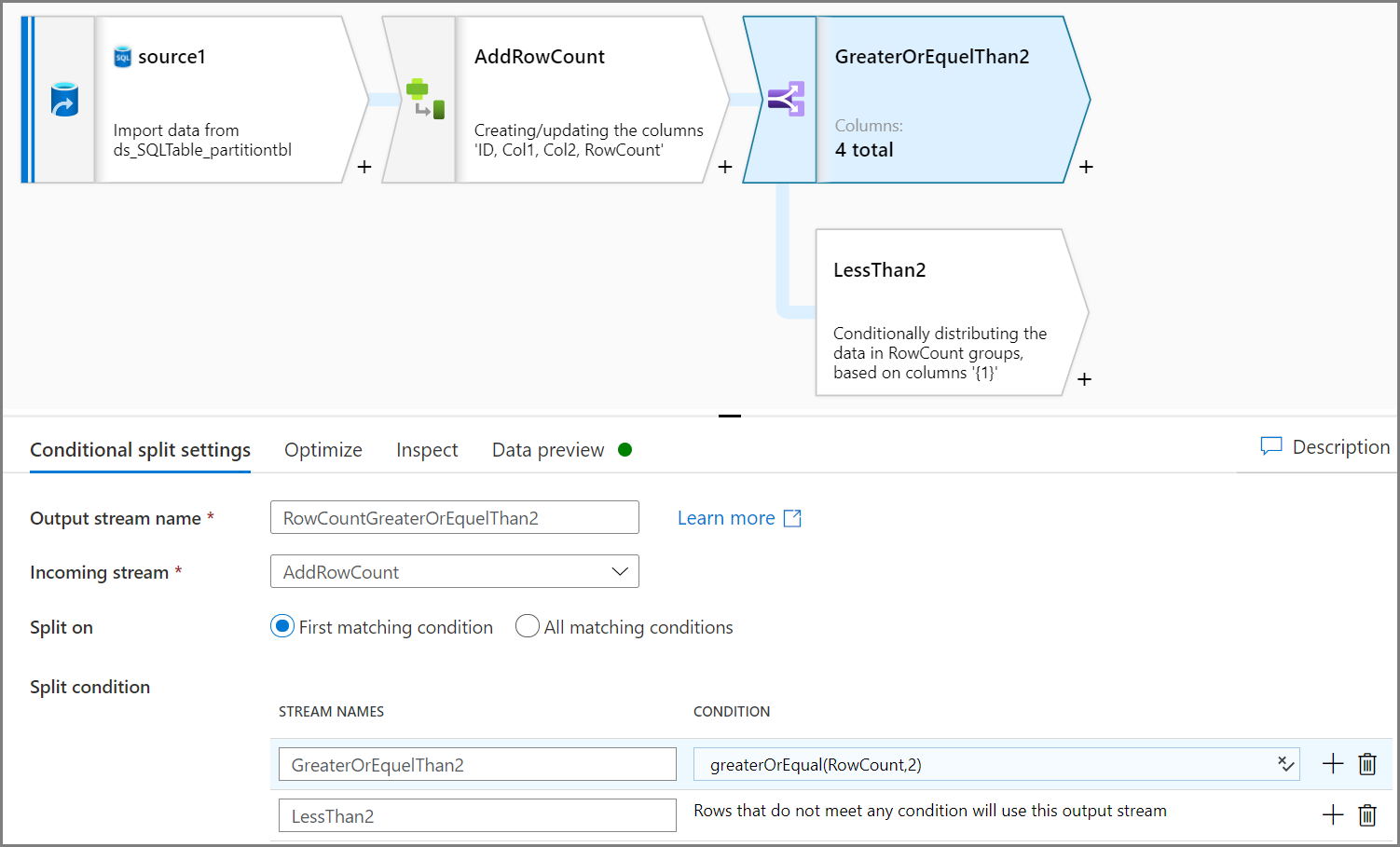
注意
- 後の手順の元のソースで使用される行数を取得するための新しいソースを作成してください。
- パフォーマンスの観点から、CacheSink を使用してください。
トレーニング データとテスト データを分割する
パーティションごとにトレーニング データとテスト データを分割する必要があります。 この例では、Col2 の値が同じである場合、一番上の 2 行をテスト データとして取得し、残りの行をトレーニング データとして取得します。
ウィンドウ アクティビティを使用して、パーティションごとに 1 列の行番号を追加します。 [Over] タブで、パーティションの列を選択します。 このチュートリアルでは、Col2 のパーティション分割を行います。 [並べ替え] タブで順序を指定します。このチュートリアルでは、これは ID に基づいています。 [ウィンドウ列] タブで、各パーティションの行番号として 1 つの列を追加する順序を指定します。
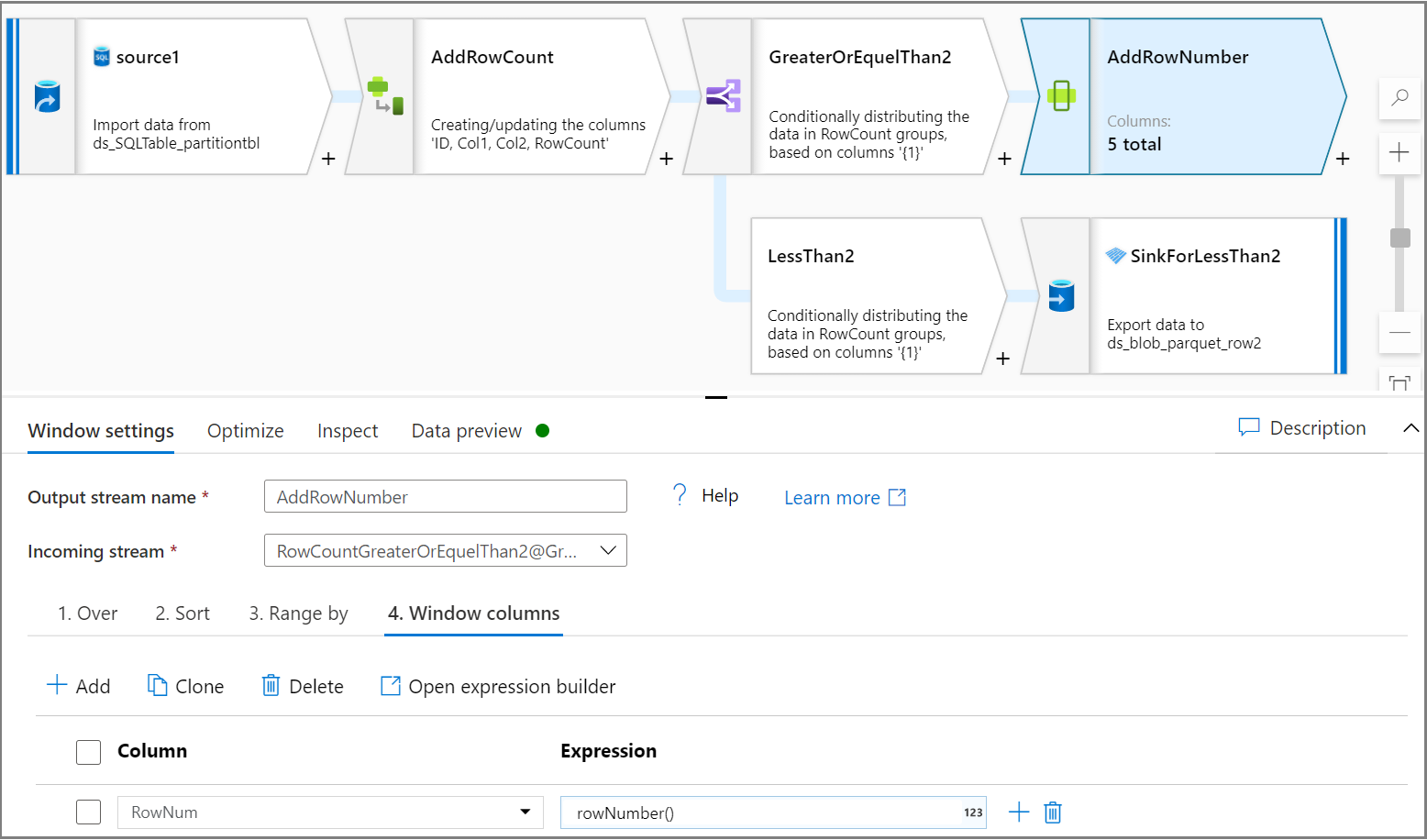
条件分割アクティビティを使用して、各パーティションの一番上の 2 行をテスト データセットに、残りの行をトレーニング データセットに分割します。 [条件分割の設定] タブで、式
lesserOrEqual(RowNum,2)を条件として使用します。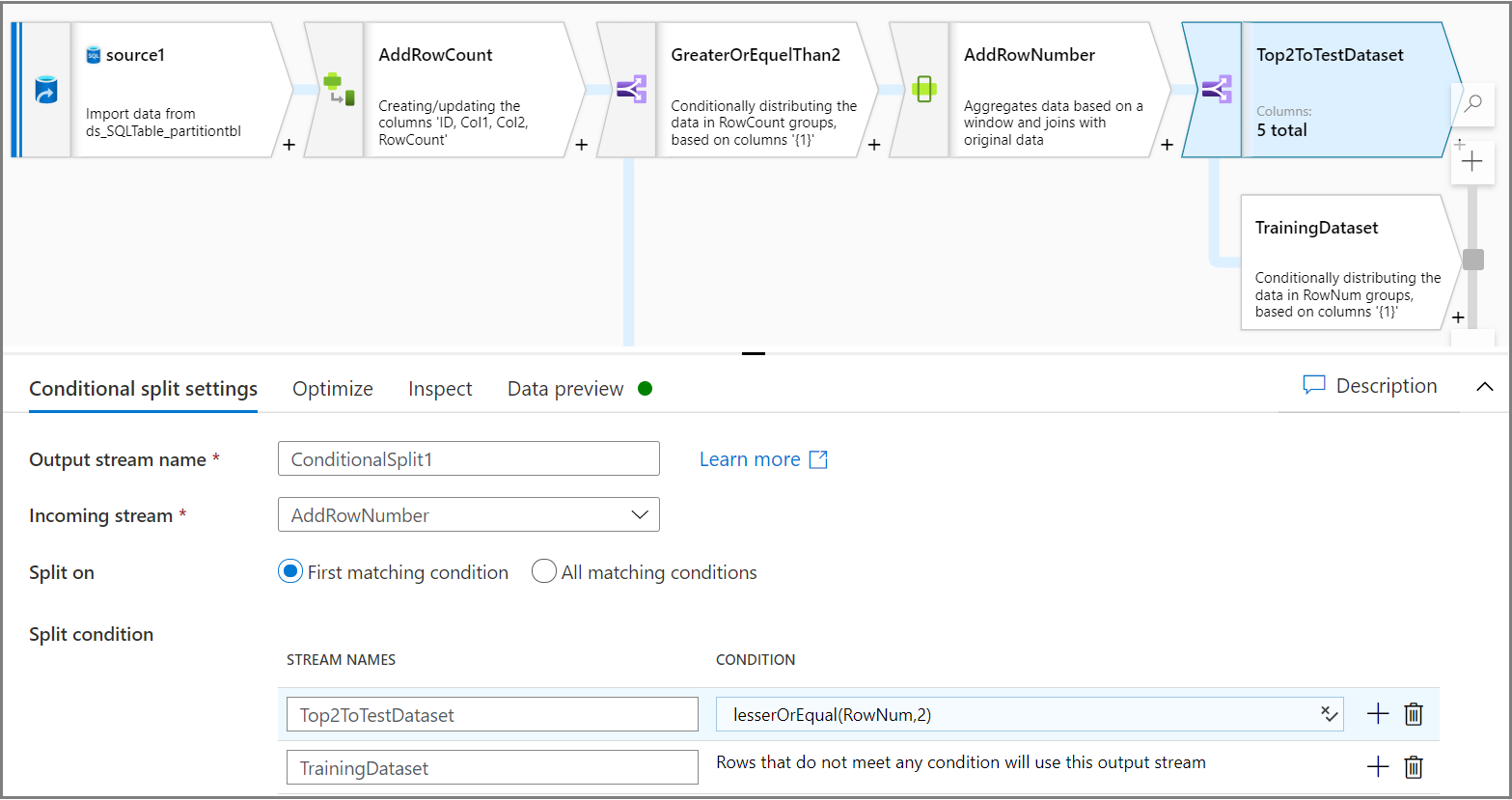
Parquet 形式でトレーニングおよびテスト データセットをパーティション分割する
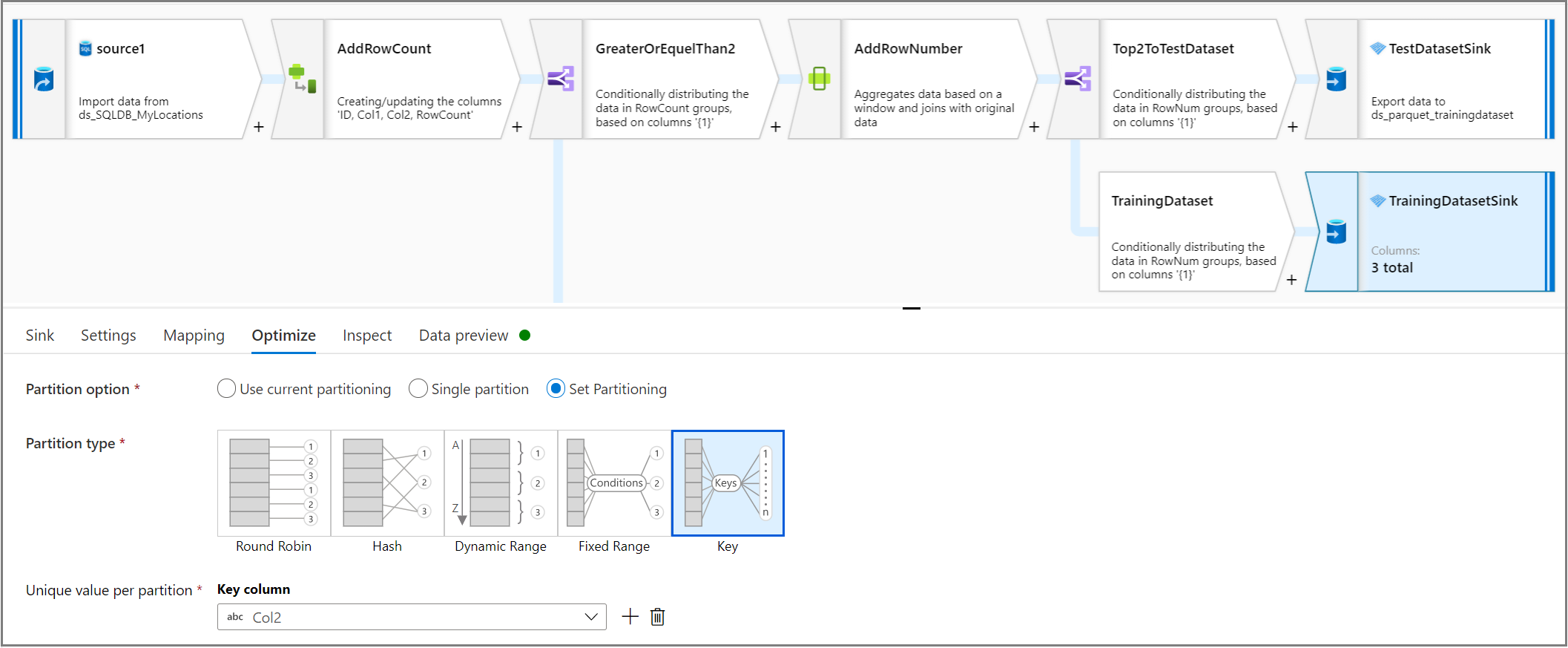
[最適化] タブで、 [パーティションごとの一意の値] を使用してパーティションの列キーとして列を設定して、シンク アクティビティを使用します。
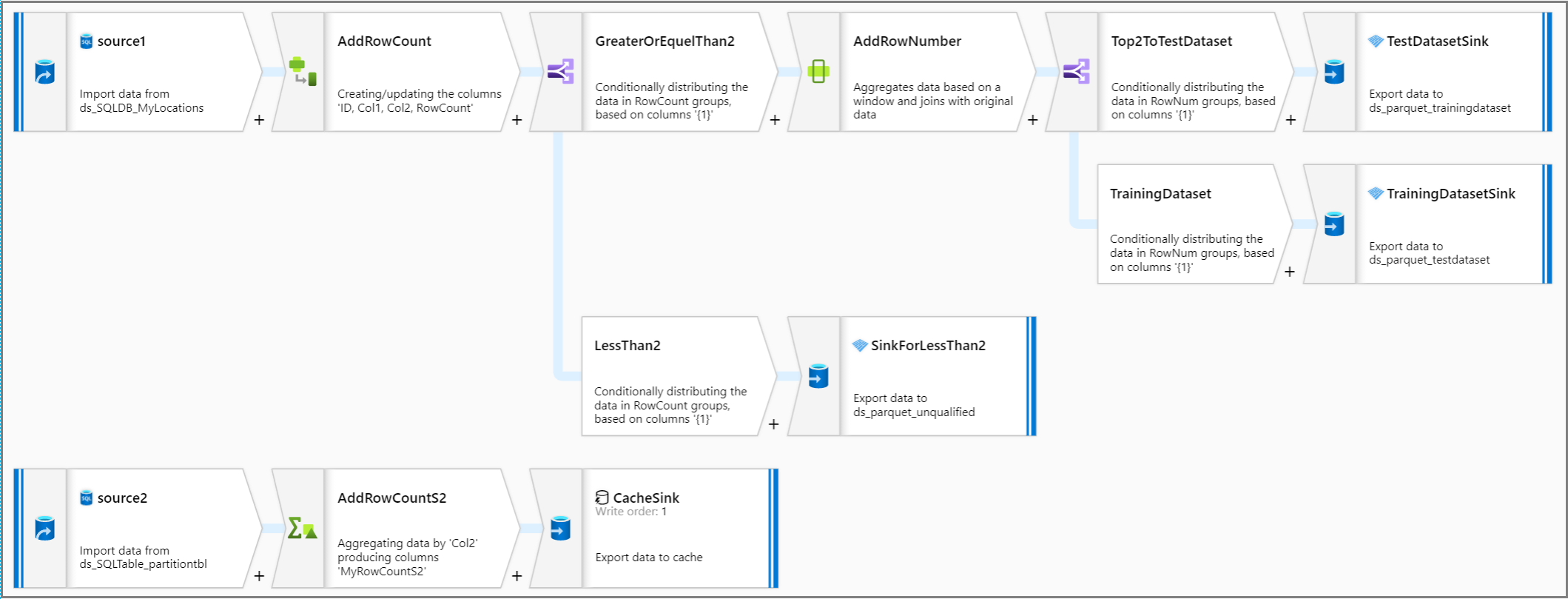
パイプライン全体のロジックを見てみましょう。
関連するコンテンツ
マッピング データ フローの変換を使用して、残りのデータ フロー ロジックを構築します。