適用対象: Azure Data Factory Azure Synapse Analytics
Azure Data Factory Azure Synapse Analytics
ヒント
Data Factory in Microsoft Fabric は、よりシンプルなアーキテクチャ、組み込みの AI、および新機能を備えた次世代のAzure Data Factoryです。 データ統合を初めて使用する場合は、Fabric Data Factory から始めます。 既存の ADF ワークロードをFabricにアップグレードして、データ サイエンス、リアルタイム分析、レポートの新機能にアクセスできます。
ヒント
- マッピング データ フロー変換を Dataflow Gen2 の同等の変換と比較するには、マッピング データ フロー ユーザー向け Dataflow Gen2 のガイドを参照してください。
- Microsoft Fabricでのデータ変換については、「Dataflow Gen2 の概要を参照してください。
マッピング データ フローとは
マッピング データ フローは、Azure Data Factoryで視覚的に設計されたデータ変換です。 データ フローを使用すると、データ エンジニアは、コードを記述することなくデータ変換ロジックを開発できます。 結果のデータ フローは、スケールアウトされた Apache Spark クラスターを使用Azure Data Factoryパイプライン内のアクティビティとして実行されます。 データ フロー アクティビティは、既存のAzure Data Factoryスケジューリング、制御、フロー、および監視機能を使用して運用化できます。
マッピング データ フローは、コーディングを必要としない、完全に視覚的なエクスペリエンスを提供します。 データ フローは、スケール アウトされたデータ処理のために、ADF で管理される実行クラスターで実行されます。 Azure Data Factoryは、すべてのコード変換、パスの最適化、およびデータ フロー ジョブの実行を処理します。
作業の開始
データ フローは、パイプラインやデータセットなどのファクトリ リソースのペインから作成されます。 data flowを作成するには、Factory Resources の横にあるプラス記号を選択し、Data Flow を選択します。
 このアクションにより、変換ロジックを作成できるデータ フロー キャンバスに移動します。
[ソースの追加] を選択すると、ソース変換の構成が開始します。 詳細については、ソース変換に関するページを参照してください。
このアクションにより、変換ロジックを作成できるデータ フロー キャンバスに移動します。
[ソースの追加] を選択すると、ソース変換の構成が開始します。 詳細については、ソース変換に関するページを参照してください。
データ フローの作成
マッピング データ フローには、変換ロジックを簡単に構築するために設計された独自の作成キャンバスがあります。 データ フロー キャンバスは、上部バー、グラフ、および構成パネルの 3 つの部分に分かれています。
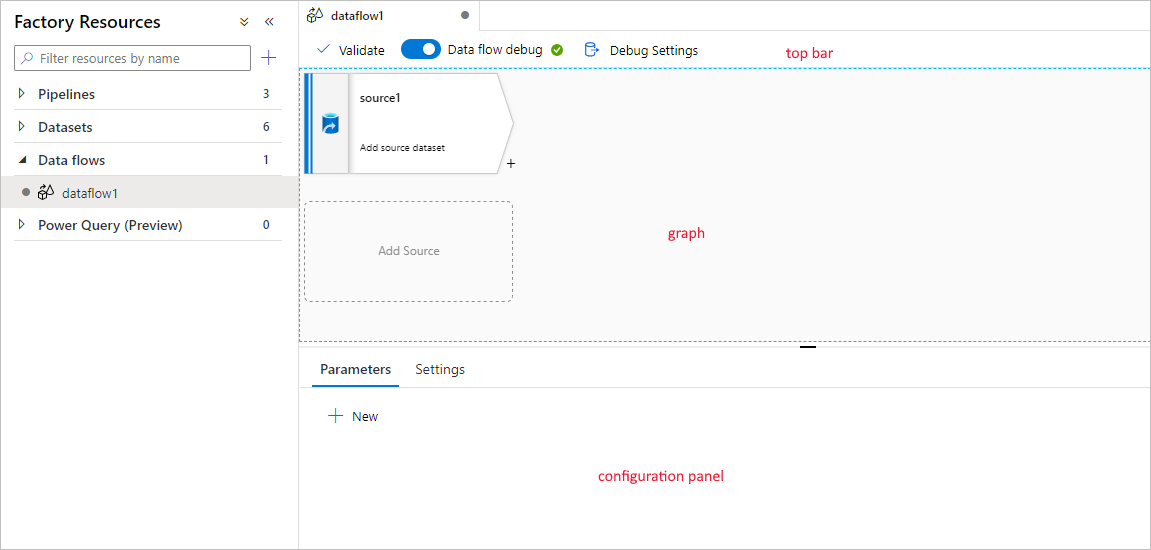
Graph
グラフには変換ストリームが表示されます。 ここにはソース データが 1 つ以上のシンクに流れるときのソース データの系列が表示されます。 データ変換の結果を移動させたい、任意のデータ ソースの宛先を、シンクとすることができます。 新しいソースを追加するには、 [ソースの追加] を選択します。 新しい変換を追加するには、既存の変換の右下にあるプラス記号を選択します。 詳しくは、データ フロー グラフの管理方法に関するページを参照してください。
![スクリーンショットには、[検索] テキスト ボックスがあるキャンバスのグラフ部分が示されています。](media/data-flow/canvas-2.png)
構成パネル
構成パネルには、現在選択されている変換に固有の設定が表示されます。 変換が選択されていない場合は、データ フローが表示されます。 データフローの全体構成では、 [パラメーター] タブを使用してパラメーターを追加できます。詳しくは、「マッピング データ フローのパラメーター」を参照してください。
各変換には、少なくとも 4 つの構成タブが含まれます。
変換設定
各変換の構成ウィンドウの最初のタブには、その変換に固有の設定が含まれています。 詳しくは、各変換のドキュメント ページを参照してください。
![[ソース設定] タブを示すスクリーンショット。](media/concepts-data-flow-overview/source-1.png)
最適化
[最適化] タブには、パーティション分割を構成するためのオプション設定が含まれています。 データ フローを最適化する方法の詳細については、マッピング データ フローのパフォーマンス ガイドに関する記事を参照してください。
![パーティション オプション、パーティションの種類、パーティションの数が含まれる [最適化] タブが示されているスクリーンショット。](media/concepts-data-flow-overview/optimize.png)
確認
[Inspect](検査) タブには、変換するデータ ストリームのメタデータのビューが表示されます。 列数、変更された列、追加された列、データ型、列の順序、および列の参照を確認できます。 [Inspect](検査) は、メタデータの読み取り専用ビューです。 [Inspect](検査) ペインでメタデータを表示するためにデバッグ モードを有効にする必要はありません。
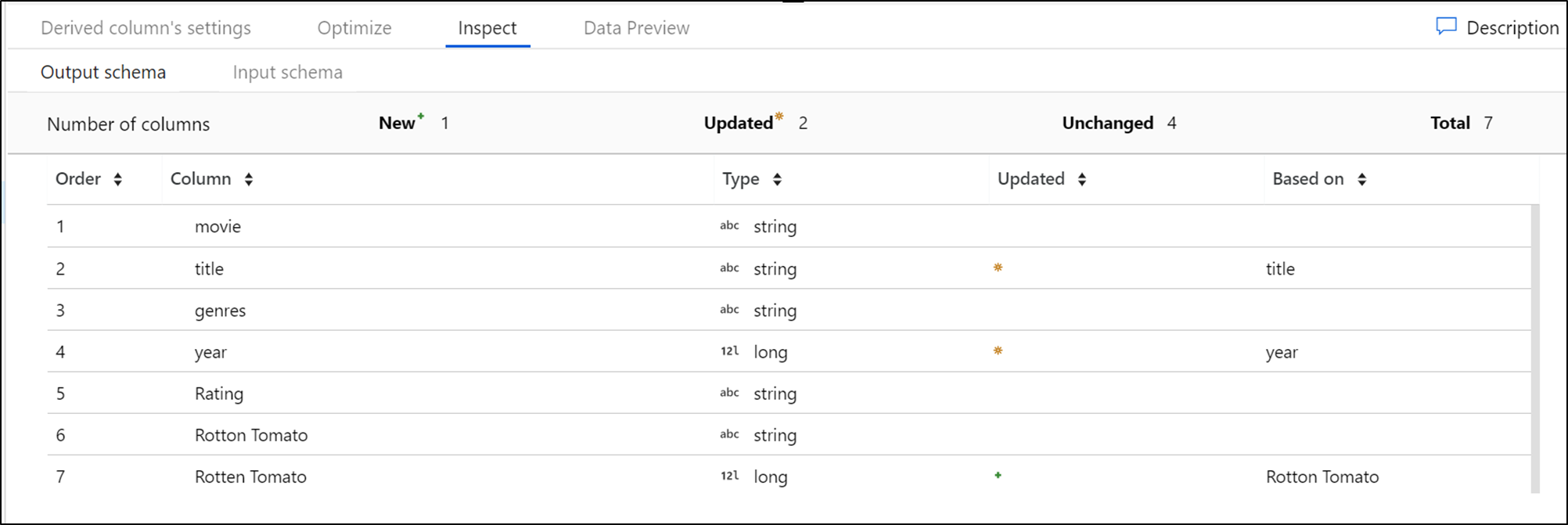
変換を通してデータの形状を変更すると、メタデータの変更フローが [検査] ペインに表示されます。 ソース変換に定義済みのスキーマが存在しない場合、メタデータは [検査] ペインには表示されません。 スキーマの誤差シナリオでは、メタデータがないことは一般的です。
データのプレビュー
デバッグ モードがオンの場合、 [データのプレビュー] タブには、各変換のデータの対話型スナップショットが表示されます。 詳細については、デバッグ モードでのデータのプレビューに関するセクションを参照してください。
上部バー
上部バーには、保存や検証など、データ フロー全体に影響を与えるアクションが含まれています。 基になる JSON コードと、変換ロジックのデータ フロー スクリプトも表示できます。 詳細については、「データ フロー スクリプト」を参照してください。
使用可能な変換
使用可能な変換の一覧を取得するには、「マッピング データ フロー変換の概要」を表示してださい。
データ フローのデータ型
- アレイ
- binary
- boolean
- 複雑
- 10進数(精度を含む)
- 日付
- float
- 整数
- long
- マップ
- short
- 文字列
- timestamp
データ フロー アクティビティ
マッピング データ フローは、ADF パイプライン内でデータ フロー アクティビティを使用して運用可能にすることができます。 ユーザーが行う必要があるのは、使用する統合ランタイムを指定し、パラメーター値を渡すことだけです。 詳細については、Azure 統合ランタイムについて説明します。
デバッグ モード
デバッグ モードを使用すると、データ フローを構築してデバッグしながら、各変換ステップの結果を対話形式で表示できます。 デバッグ セッションは、データ フロー ロジックを構築するときと、データ フロー アクティビティでパイプライン デバッグを実行するときの両方で使用できます。 詳細については、デバッグ モードのドキュメントを参照してください。
データ フローの監視
マッピング データ フローは、既存のAzure Data Factory監視機能と統合されます。 データ フローの監視出力を理解する方法については、マッピング データ フローの監視に関するページを参照してください。
Azure Data Factory チームはパフォーマンス チューニング ガイドを作成し、ビジネス ロジックを構築した後のデータ フローの実行時間を最適化します。