適用対象: Azure Data Factory Azure Synapse Analytics
Azure Data Factory Azure Synapse Analytics
ヒント
Data Factory in Microsoft Fabric は、よりシンプルなアーキテクチャ、組み込みの AI、および新機能を備えた次世代のAzure Data Factoryです。 データ統合を初めて使用する場合は、Fabric Data Factory から始めます。 既存の ADF ワークロードをFabricにアップグレードして、データ サイエンス、リアルタイム分析、レポートの新機能にアクセスできます。
ETL ジョブのデータを処理する際は多くの場合、結果を書き込む前に列名の変更が必要になります。 あるときは、既知のターゲット スキーマに合わせて列名を調整する目的で、この処理が必要になります。 また別の場合には、スキーマの進化に合わせて、実行時に列名を設定しなければならないときもあります。 このチュートリアルでは、データ フローから外部の構成ファイルとパラメーターを使用して変換先ファイルとデータベース テーブルの列名を動的に設定する方法について説明します。
Azure Data Factoryを初めて使用する場合は、Azure Data Factory の概要を参照してください。
前提条件
- Azure サブスクリプション。 Azure サブスクリプションをお持ちでない場合は、開始する前に、free Azure アカウントを作成します。
- Azure ストレージ アカウント。 ADLS ストレージを、ソースとシンクのデータ ストアとして使用します。 ストレージ アカウントをお持ちでない場合は、「Azure ストレージ アカウントを作成する」を参照してください。
Data Factory の作成
この手順では、データ ファクトリを作成し、Data Factory UX を開いて、データ ファクトリにパイプラインを作成します。
- Microsoft Edge または Google Chrome を開きます。 現在、Data Factory UI は、Microsoft Edgeおよび Google Chrome Web ブラウザーでのみサポートされています。
- 左側のメニューで、 [リソースの作成]>[統合]>[Data Factory] を選択します。
- [新しいデータ ファクトリ] ページで、 [名前] に「ADFTutorialDataFactory」と入力します。
- データ ファクトリを作成する Azure サブスクリプションを選択します。
-
[リソース グループ] で、次の手順のいずれかを行います。
- [Use existing (既存のものを使用)] を選択し、ドロップダウン リストから既存のリソース グループを選択します。
- Create new を選択し、リソース グループの名前を入力します。リソース グループの詳細については、「リソース グループを使用してAzure リソースを管理するを参照してください。
- [バージョン] で、 [V2] を選択します。
- [場所] で、データ ファクトリの場所を選択します。 サポートされている場所のみがドロップダウン リストに表示されます。 データ ファクトリで使用されるデータ ストア (Azure Storageや SQL Database など) とコンピューティング (Azure HDInsight など) は、他のリージョンに存在できます。
- [作成] を選択します
- 作成が完了すると、その旨が通知センターに表示されます。 [リソースに移動] を選択して、Data factory ページに移動します。
- [Author & Monitor] (作成と監視) を選択して、別のタブで Data Factory UI を起動します。
データ フロー アクティビティが含まれるパイプラインの作成
この手順では、データ フロー アクティビティが含まれるパイプラインを作成します。
ADF のホーム ページから [パイプラインを作成] を選択します。
パイプラインの [全般] タブで、パイプラインの名前として「DeltaLake」と入力します。
ファクトリの上部バーで、Data Flow debug スライダーをオンにします。 デバッグ モードを使用すると、ライブ Spark クラスターに対する変換ロジックの対話型テストが可能になります。 Data Flow クラスターのウォームアップには 5 ~ 7 分かかります。ユーザーは、Data Flow開発を計画している場合は、最初にデバッグを有効にすることをお勧めします。 詳細については、デバッグ モードに関するページを参照してください。
[アクティビティ] ウィンドウで、 [移動と変換] アコーディオンを展開します。 Data Flow アクティビティをウィンドウからパイプライン キャンバスにドラッグ アンド ドロップします。
[追加Data Flowポップアップで、Create new Data Flow を選択し、data flow DynaCols という名前を付けます。 完了したら [完了] を選択します。
データ フローで動的な列マッピングを作成する
このチュートリアルでは、サンプル映画評価ファイルを使用し、ソース内のいくつかのフィールドを、新しい一連のターゲット列の名前に変更します。ターゲット列の名前は時間と共に変わる可能性があります。 以下で作成するデータセットは、Blob Storageまたは ADLS Gen2 ストレージ アカウント内のこのムービー CSV ファイルを指している必要があります。 映画ファイルをこちらからダウンロードし、Azure ストレージ アカウントにそのファイルを格納します。
チュートリアルの目標
データ フローを使用して列名を動的に設定する方法について学習します
- 映画の CSV ファイルのソース データセットを作成します。
- フィールド マッピング JSON 構成ファイルのルックアップ データセットを作成します。
- ソースの列をターゲットの列名に変換します。
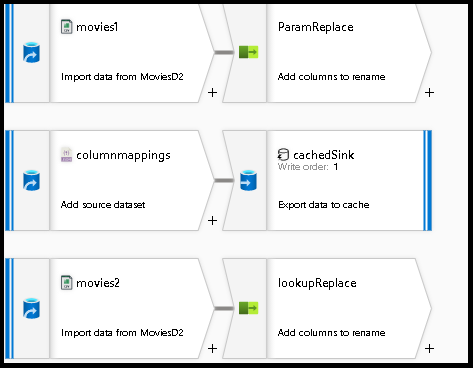
空のデータ フロー キャンバスから開始する
まず、ADLS Gen2 のデータ配置用に、以下で説明する各メカニズムのデータ フロー環境を設定してみましょう。
ソース変換を選択して
movies1という名前を付けます。下部パネルのデータセットの横にある [新規] ボタンを選択します。
先ほど moviesDB.csv ファイルを保存した場所に応じて、BLOB または ADLS Gen2 を選択します。
2 つ目のソースを追加します。これは、フィールドのマッピングをルックアップするための構成 JSON ファイルのソースとして使用します。
これに
columnmappingsという名前を付けます。データセットについて、列マッピングの構成を格納する新しい JSON ファイルを参照します。 このチュートリアルの例の JSON ファイルに貼り付けることができます。
[ {"prevcolumn":"title","newcolumn":"movietitle"}, {"prevcolumn":"year","newcolumn":"releaseyear"} ]このソース設定を
array of documentsに設定します。3 つ目のソースを追加し、
movies2という名前を付けます。 これは、movies1とまったく同じように構成します。
パラメーター化された列マッピング
この最初のシナリオでは、入力フィールドとパラメーター (列の文字列配列) との対応、そして各配列インデックスと入力列序数位置との対応に基づいて列マッピングを設定し、データ フローの出力列名を設定します。 このデータ フローをパイプラインから実行するとき、この文字列配列パラメーターをデータ フロー アクティビティに送信することで、パイプラインを実行するたびに異なる列名を設定できるようになります。
データ フロー デザイナーに戻り、先ほど作成したデータ フローを編集します。
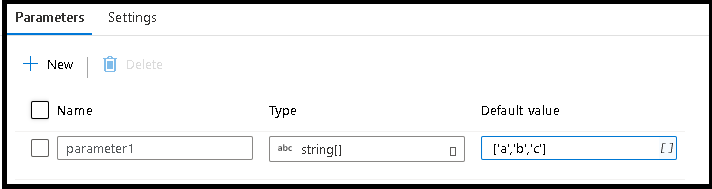
[パラメーター] タブを選択します。
新しいパラメーターを作成し、文字列配列のデータ型を選択します
既定値として「
['a','b','c']」を入力します一番上の
movies1ソースを使用して、これらの配列値に対応するよう列名を変更します選択変換を追加します。 選択変換は、入力列を出力用の新しい列名にマップする目的で使用されます。
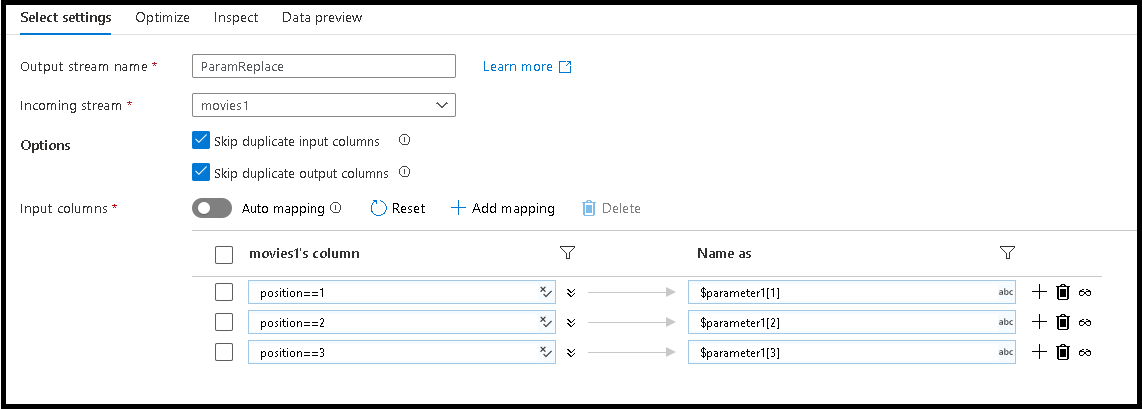
最初の 3 つの列名を、パラメーターで定義された新しい名前に変更します
そのためには、ルールベースの 3 つのマッピング エントリを下部ペインに追加します
先頭列では、一致規則が
position==1で、名前は$parameter1[1]になります2 列目と 3 列目についても、同じパターンに従います
選択変換の [検査] タブと [データ プレビュー] タブを選択し、元の列名 movie、title、genres が新しい列名値
(a,b,c)に置き換わっていることを確認します
外部列マッピングのキャッシュされた検索を作成する
次に、後で参照するためのキャッシュシンクを設定します。 このキャッシュは、データ フローの各パイプライン実行で列名を動的に変更するために使用できる外部 JSON 構成ファイルを読み取ります。
- データ フロー デザイナーに戻り、先ほど作成したデータ フローを編集します。
columnmappingsソースにシンク変換を追加します。 - シンクの種類を
Cacheに設定します。 - [設定] で、キー列として
prevcolumnを選択します。
キャッシュされたシンクから列名を検索する
これで構成ファイルの内容をメモリに格納したので、新しい出力列名に対して入力列名を動的にマップすることができます。
- データ フロー デザイナーに戻り、先に作成したデータ フローを編集します。
movies2ソース変換を選択します。 - 選択変換を追加します。 今回は選択変換を使用し、キャッシュされたシンクに格納される JSON 構成ファイル内のターゲット名に基づいて列名を変更します。
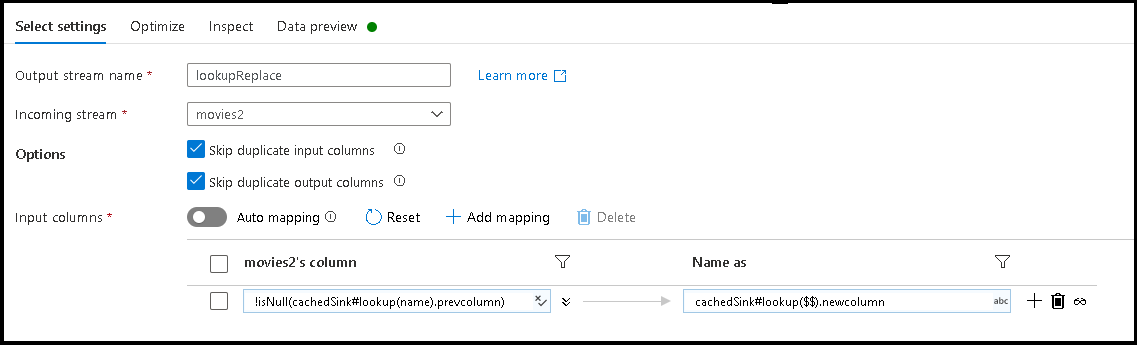
- ルールベースのマッピングを追加します。 [Matching Condition](一致条件) には
!isNull(cachedSink#lookup(name).prevcolumn)という式を使用します。 - 出力列名には、
cachedSink#lookup($$).newcolumnという式を使用します。 - ここでは、外部 JSON 構成ファイルの
prevcolumnプロパティと一致する列名をすべて検索し、一致したものそれぞれの名前を新しいnewcolumn名に変更しています。 - 選択変換の [データ プレビュー] タブと [検査] タブを選択すると、今度は、外部マッピング ファイルに基づく新しい列名が表示されます。
関連するコンテンツ
- このチュートリアルで作成したパイプラインは、こちらからダウンロードできます
- データ フロー シンクの詳細を確認する。