この記事では、表示、編集、開始、終了、削除、アクセス制御、パフォーマンスとログの監視を含む、Azure Databricks コンピューティングの管理方法について説明します。 Clusters API を使用して、コンピューティングをプログラムで管理することもできます。
コンピューティングを表示する
コンピューティングを表示するには、ワークスペースのサイド バーで ![]() [コンピューティング] をクリックします。
[コンピューティング] をクリックします。
左側には、2 つの列 (コンピューティングがピン留めされているかどうかを示す列とコンピューティングの状態を示す列) があります。 状態にカーソルを合わせると、詳細情報が表示されます。
コンピューティング構成を JSON ファイルとして表示する
場合によっては、コンピューティング構成を JSON として表示すると役立つことがあります。 これは、Clusters API を使用して同様のコンピューティングを作成する場合に特に便利です。 既存のコンピューティングを表示する場合は、[構成] タブにアクセスし、タブの右上にある [JSON] をクリックします。JSON をコピーして API 呼び出しに貼り付けます。 JSON ビューは読み取り専用です。
コンピューティングをピン留めする
コンピューティングは、終了してから 30 日後に完全に削除されます。 コンピューティングが終了してから 30 日以上経過した後でも汎用コンピュータの設定を維持するには、管理者はコンピューティングをピン留めすることができます。 最大 100 個のコンピューティング リソースを固定できます。
管理者は、ピン留めアイコンをクリックして、コンピューティングの一覧またはコンピューティングの詳細ページからコンピューティングをピン留めできます。
コンピューティングを編集する
コンピューティングの構成は、コンピューティングの詳細 UI から編集できます。
メモ
- コンピューティングにアタッチされたノートブックとジョブは、編集後もアタッチされたままになります。
- コンピューティングにインストールされているライブラリは、編集後もインストールされたままになります。
- 実行中のコンピューティングの何らかの属性を編集した場合は (コンピューティング サイズとアクセス許可を除く)、そのコンピューティングを再起動する必要があります。 これにより、現在そのコンピューティングを使用しているユーザーを中断させる可能性があります。
- 編集できるのは、実行中または終了済みのコンピューティングだけです。 ただし、コンピューティングの詳細ページでは、これらの状態にないコンピューティングの "アクセス許可" を更新できます。
コンピューティングを複製する
既存のコンピューティングを複製するには、コンピューティングの から Kebab menu icon.[複製] を選択します。kebab メニュー。
[複製] を選択すると、コンピューティング構成が事前に設定されたコンピューティング作成 UI が開きます。 次の属性は、クローンに含まれません。
- コンピューティングのアクセス許可
- 添付ノートブック
複製されたコンピューティングに以前にインストールしたライブラリを含めない場合は、[コンピューティングの 作成 ] ボタンの横にあるドロップダウン メニューをクリックし、[ ライブラリなしで作成] を選択します。
コンピューティングのアクセス許可
コンピューティングには、アクセス許可なし、アタッチ可能、再起動可能、管理可能の 4 つのアクセス許可レベルがあります。 詳細については、「コンピューティング ACL」を参照してください。
メモ
シークレット は、クラスターの Spark ドライバー ログ stdout および stderr ストリームから編集されません。 機密データを保護するために、既定では、Spark ドライバー ログは、ジョブ、専用アクセス モード、標準アクセス モード のクラスターに対する CAN MANAGE アクセス許可を持つユーザーのみが表示できます。 "アタッチ可能" または "再起動可能" アクセス許可を持つユーザーがこれらのクラスターのログを表示できるようにするには、クラスター構成で次の Spark 構成プロパティを設定します: spark.databricks.acl.needAdminPermissionToViewLogs false。
分離なし共有アクセス モード クラスターでは、CAN ATTACH TO、CAN RESTART、CAN MANAGE アクセス許可を持つユーザーが Spark ドライバー ログを表示できます。 ログを閲覧できるユーザーを "管理可能" アクセス許可を持つユーザーのみに制限するには、spark.databricks.acl.needAdminPermissionToViewLogs を true に設定します。
クラスター構成に Spark プロパティを追加する方法については、「Spark の構成」を参照してください。
コンピューティングのアクセス許可を構成する
このセクションでは、ワークスペース UI を使用してアクセス許可を管理する方法について説明します。 Permissions API または Databricks Terraform プロバイダー を使用することもできます。
コンピューティングのアクセス許可を構成するには、コンピューティングに対する管理可能アクセス許可が必要です。
- サイドバーで、[コンピューティング] をクリックします。
- コンピュートの行の右側にあるケバブメニューアイコン
 をクリックし、アクセス許可の編集 を選択します。
をクリックし、アクセス許可の編集 を選択します。 - [アクセス許可の設定] で、[ユーザー、グループ、またはサービス プリンシパルの選択] ドロップダウン メニューをクリックし、ユーザー、グループ、またはサービス プリンシパルを選びます。
- [アクセス許可] ドロップダウン メニューからアクセス許可を選択します。
- [追加] をクリックし、[保存] をクリックします。
コンピューティングを終了する
コンピューティング リソースを保存するために、コンピューティングを終了できます。 終了したコンピューティングの構成は、後で 再利用 (またはジョブの場合は 自動開始) できるように格納されます。 手動でコンピューティングを終了することも、指定した非アクティブ期間の後に自動的に終了するようコンピューティングを構成することもできます。
コンピューティングリソースがピン留めまたは再起動されていない場合、終了してから30日後に、自動的かつ恒久的に削除されます。 この削除はユーザーまたは API アクションではなくシステムによって実行されるため、監査ログには表示されません。
終了したコンピューティングは、コンピューティング名の左側に灰色の円が付加されてコンピューティングの一覧に表示されます。
メモ
新しいジョブ コンピューティングでジョブを実行すると (通常、これが推奨されます)、コンピューティングは終了し、ジョブの完了時に再起動できなくなります。 一方、終了された既存の汎用コンピューティングで実行するジョブをスケジュールすると、そのコンピューティングは自動開始されます。
重要
試用版 Premium ワークスペースを使用している場合は、次の場合に実行中のすべてのコンピューティング リソースが終了します。
- ワークスペースをフル プレミアムにアップグレードする場合。
- ワークスペースがアップグレードされず、評価版が期限切れになった場合。
手動終了
コンピューティングの一覧から (コンピューティングの行の四角形をクリックして) またはコンピューティングの詳細ページ ([ 終了] をクリック) を手動で終了できます。
自動終了
コンピューティングに対して自動終了を設定することもできます。 コンピューティングの作成時に、コンピューティングを終了するまでの非アクティブな期間を分単位で指定できます。
現在の時刻とコンピューティングで実行された最後のコマンドの差が、指定された非アクティブ期間を超えると、Azure Databricks はそのコンピューティングを自動的に終了します。
コンピューティングは、Spark ジョブ、構造化ストリーミング、JDBC 呼び出し、Azure Databricks Web ターミナル アクティビティなど、コンピューティング上のすべてのコマンドの実行が完了すると非アクティブと見なされます。
警告
- コンピューティングでは、DStreams を使用した結果のアクティビティは報告されません。 つまり、DStreams の実行中に自動終了を設定しているコンピューティングが終了する可能性があります。 DStreams を実行するコンピューティングの自動終了をオフにするか、構造化ストリーミングの使用を検討してください。
- アイドル状態のコンピューティングでは、終了するまでの非アクティブ期間中も、DBU とクラウド インスタンスの料金が継続的に発生します。
自動終了の構成
新しいコンピューティング UI で自動終了を構成できます。 チェック ボックスがオンになっていることを確認し、[非アクティブな分数の ___ 分後に終了する] 設定に分数を入力します。
[自動終了] チェックボックスをオフにするか、非アクティブ期間に 0 を指定することで、自動終了を解除できます。
メモ
自動終了は、最新の Spark バージョンで最適にサポートされています。 以前のバージョンの Spark では、コンピューティング アクティビティのレポートが不正確になる可能性のある制限が確認されていました。 たとえば、JDBC、R、またはストリーミング コマンドを実行しているコンピューティングでは、コンピューティングの早期終了につながる古いアクティビティ時間を報告する可能性があります。 バグの修正や自動終了の機能強化が反映されるように、最新の Spark バージョンにアップグレードしてください。
予期しない終了
手動終了または自動終了の構成の結果としてではなく、予期せずにコンピューティングが終了することがあります。
終了の理由と修復手順の一覧については、ナレッジ ベースを参照してください。
コンピュートユニットを削除する
コンピューティングを削除すると、コンピューティングが終了し、その構成も削除されます。 コンピューティングを削除するには、コンピューティングの から Kebab menu icon.[削除] を選択します。
警告
この操作を元に戻すことはできません。
ピン留めされたコンピューティングを削除するには、まず管理者によってピン留めが解除される必要があります。
Clusters API エンドポイントを呼び出して、プログラムでコンピューティングを削除することもできます。
コンピューティングを再起動する
以前に終了したコンピューティングは、コンピューティングの一覧、コンピューティングの詳細ページ、またはノートブックから再起動できます。 Clusters API エンドポイントを呼び出して、プログラムでコンピューティングを開始することもできます。
Azure Databricks では、一意のクラスター ID を使用してコンピューティングを識別します。 終了したコンピューティングを開始すると、Databricks は同じ ID でコンピューティングを再作成し、すべてのライブラリを自動的にインストールして、ノートブックを再アタッチします。
メモ
試用版ワークスペースを使用していて、試用期間が終了した場合は、コンピューティングを開始できなくなります。
コンピューティングを再起動して最新のイメージで更新する
コンピューティングを再起動すると、コンピューティング リソース コンテナーと VM ホストの最新のイメージが取得されます。 ストリーミング データの処理などで使われる実行時間の長いコンピューティングの場合、定期的な再起動をスケジュールすることが重要です。
すべてのコンピューティング リソースを定期的に再起動し、最新のイメージ バージョンでイメージを最新の状態に保つことは、ユーザーの責任です。
重要
アカウントまたはワークスペースのコンプライアンス セキュリティ プロファイルを有効にすると、長時間実行されているコンピューティングは、スケジュールされたメンテナンス期間中に必要に応じて自動的に再起動されます。 これにより、自動再起動によってスケジュールされたジョブが中断されるリスクが軽減されます。 メンテナンス期間中に強制的に再起動することもできます。 「自動クラスター更新」を参照してください。
ノートブックの例: 長期間実行されているコンピューティングを特定する
ワークスペース管理者は、各コンピューティングが実行されている期間を特定するスクリプトを実行し、指定されている日数より古い場合は必要に応じて再起動できます。 このスクリプトは、Azure Databricks でノートブックとして提供されています。
スクリプトの最初の行では、構成パラメーターを定義します。
-
min_age_output: コンピューティングを実行できる最大日数。 既定値の は 1 です。 -
perform_restart:Trueの場合、スクリプトは経過時間がmin_age_outputで指定された日数を超えるすべてのコンピューティングを再起動します。 既定値はFalseで、長期間実行されているコンピューティングが特定されますが、再起動は行われません。 -
secret_configuration:REPLACE_WITH_SCOPEとREPLACE_WITH_KEYは、シークレット スコープとキー名に置き換えます。 シークレットの設定について詳しくは、ノートブックをご覧ください。
警告
perform_restart を True に設定すると、スクリプトは対象となるコンピューティングを自動的に再起動します。そのため、アクティブなジョブが失敗したり、開いているノートブックがリセットされたりする可能性があります。 ワークスペースのビジネス クリティカルなジョブを中断するリスクを軽減するには、スケジュールされたメンテナンス期間を計画し、ワークスペース ユーザーに必ず通知してください。
長期間実行されているコンピューティングを特定し、必要に応じて再起動する
ジョブと JDBC/ODBC クエリのコンピューティングの自動開始
終了済みコンピューティングに割り当てられたジョブが実行されるようにスケジュールされている場合、または JDBC/ODBC インターフェイスから終了したコンピューティングに接続する場合、コンピューティングは自動的に再起動されます。 「ジョブ用にコンピューティングを構成する」および「JDBC 接続」を参照してください。
コンピューティングの自動開始を使用すると、スケジュールされたジョブのコンピューティングを再起動するように手動で介入しなくても、コンピューティングを自動的に終了するように構成できます。 さらに、終了したコンピューティングで実行するジョブをスケジュールすることで、コンピューティングの初期化をスケジュールすることもできます。
コンピューティングを自動的に再起動する前に、コンピューティングとジョブのアクセス制御のアクセス許可がチェックされます。
メモ
コンピューティングが Azure Databricks プラットフォーム バージョン 2.70 以前で作成された場合、自動開始は利用できません。終了したコンピューティングで実行するようにスケジュールされたジョブは失敗します。
Spark UI でコンピューティング情報を表示する
コンピューティングの詳細ページの [Spark UI] タブを選択して、Spark ジョブに関する詳細情報を表示できます。
終了したコンピューティングを再起動した場合、Spark UI には、終了したコンピューティングの履歴情報ではなく、再起動したコンピューティングの情報が表示されます。
Spark UI を使用してコストとパフォーマンスの問題を診断する方法については、「Spark UI を使用してコストとパフォーマンスの問題を診断する」をご覧ください。
コンピューティング ログを表示する
Azure Databricks では、次の 3 種類のコンピューティング関連アクティビティのログ記録が表示されます。
- コンピューティング イベント ログ。作成、終了、構成の編集などのコンピューティング ライフサイクル イベントをキャプチャします。
- Apache Spark ドライバーとワーカー ログ。デバッグに使用できます。
- init スクリプトのログを生成し、これらは init スクリプトのデバッグに役立ちます。
このセクションでは、コンピューティング イベント ログとドライバーおよびワーカー ログについて説明します。 init スクリプトのログの詳細については、「init スクリプト ログ」を参照してください。
コンピューティング イベント ログ
コンピューティング イベント ログには、ユーザー操作によって手動でトリガーされるか、Azure Databricks によって自動的にトリガーされる、重要なコンピューティング ライフサイクル イベントが表示されます。 このようなイベントは、コンピューティング全体とコンピューティング内で実行されているジョブの動作に影響します。
サポートされているイベントの種類については、Clusters API データ構造体に関するページを参照してください。
イベントは 60 日間保存されます。これは、Azure Databricks の他のデータ保持期間と同程度です。
コンピューティングのイベント ログを表示する
コンピューティングのイベント ログを表示するには、コンピューティングの詳細ページで [ イベント ログ ] タブを選択します。
イベントの詳細については、ログでその行をクリックし、[JSON] タブをクリックして詳細を確認してください。
コンピューティング ドライバーとワーカー ログ
ノートブック、ジョブ、ライブラリから print および log ステートメントを実行することによって、Spark ドライバー ログにアクセスできます。 これらのログ ファイルには、コンピューティングの詳細ページの [ドライバー ログ] タブからアクセスできます。 ログ ファイルをダウンロードするには、その名前をクリックします。
これらのログには、次の 3 つの出力があります。
- 標準出力
- 標準エラー
- Log4j ログ
Spark ワーカー ログを表示するには、[Spark UI] タブを使用します。コンピューティングのログ配信場所を構成することもできます。 指定した場所には、ワーカーおよびコンピューティング ログの両方が配信されます。
パフォーマンスの監視
Azure Databricks コンピューティングのパフォーマンスを監視できるようにするため、Azure Databricks ではクラスターの詳細ページからメトリックにアクセスできます。 Databricks Runtime 12.2 以下の場合、Azure Databricks は Ganglia メトリックへのアクセスを提供します。 Databricks Runtime 13.3 LTS 以降の場合、コンピューティング メトリックは Azure Databricks によって提供されます。
さらに、Azure の監視プラットフォームである Azure Monitor の Log Analytics ワークスペースにメトリックを送信するように Azure Databricks コンピューティングを構成することもできます。
また、コンピューティング ノードに Datadog エージェントをインストールして、Datadog メトリックを Datadog アカウントに送信することもできます。
コンピューティング メトリック
コンピューティング メトリックは、サーバーレスではない汎用およびジョブ コンピューティングに対する既定の監視ツールです。 コンピューティング メトリック UI にアクセスするには、コンピューティングの詳細ページの [メトリック] タブに移動します。
日付の選択フィルターを使用して時間の範囲を選択することで、履歴メトリックを表示できます。 メトリックは 1 分ごとに収集されます。 [最新の情報に更新] ボタンをクリックして、最新のメトリックを取得することもできます。 詳細については、「コンピューティング メトリックの表示」を参照してください。
Ganglia メトリック
メモ
Ganglia メトリックは、Databricks Runtime 12.2 以下でのみ使用できます。
Ganglia UI にアクセスするには、コンピューティングの詳細ページの [メトリック] タブに移動して、[レガシ メトリック] の設定を有効にします。 GPU メトリックは、GPU 対応コンピューティングで使用できます。
ライブ メトリックを表示するには、[GANGLIA UI] リンクをクリックします。
履歴のメトリックを表示するには、スナップショット ファイルをクリックします。 スナップショットには、選択した時刻より前の時間の集計されたメトリックが含まれます。
メモ
Ganglia は Docker コンテナーではサポートされていません。 コンピューティングで Docker コンテナー を使用する場合、Ganglia メトリックは使用できません。
Ganglia メトリックのコレクションを構成する
既定では、Azure Databricks によって 15 分ごとに Ganglia メトリックが収集されます。 収集期間を構成するには、DATABRICKS_GANGLIA_SNAPSHOT_PERIOD_MINUTESを使用するか、Create cluster API の spark_env_vars フィールドで 環境変数を設定します。
Azure Monitor
Azure の監視プラットフォームである Azure Monitor の Log Analytics ワークスペースにメトリックを送信するように Azure Databricks コンピューティングを構成することもできます。
メモ
独自の仮想ネットワークに Azure Databricks ワークスペースをデプロイし、Azure Databricks で必要とされないすべての送信トラフィックを拒否するようにネットワーク セキュリティ グループ (NSG) を構成している場合は、"AzureMonitor" サービス タグに対して追加の送信規則を構成する必要があります。
ノートブックの例: Datadog メトリック
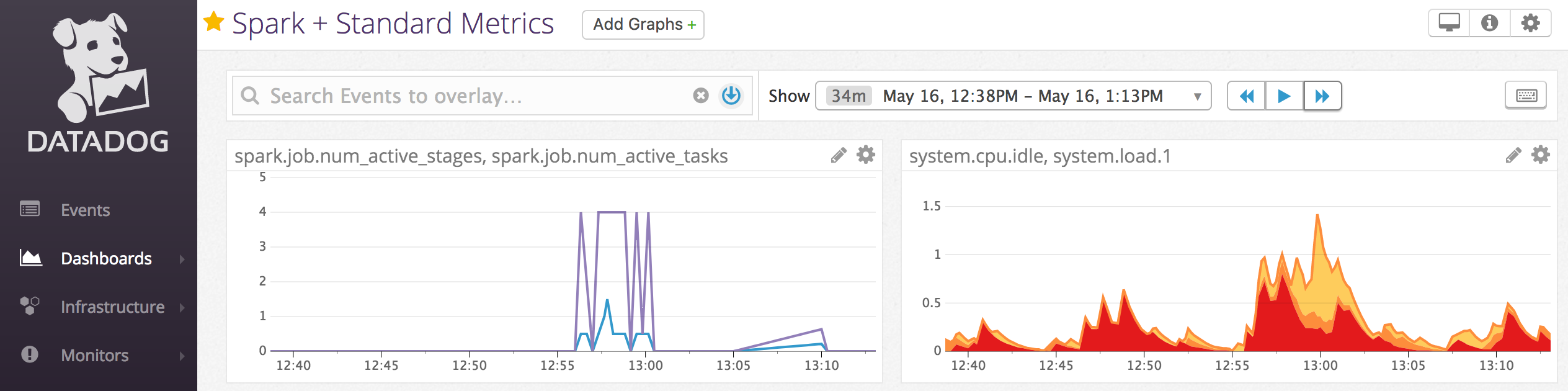
コンピューティング ノードに Datadog エージェントをインストールして、Datadog メトリックを Datadog アカウントに送信できます。 次のノートブックには、コンピューティング スコープの init スクリプトを使用してコンピューティングに Datadog エージェントをインストールする方法が示されています。
すべてのコンピューティングに Datadog エージェントをインストールするには、コンピューティング ポリシーを使用するコンピューティング スコープの init スクリプトを管理します。
Datadog エージェントの init スクリプト ノートブックのインストール
スポット インスタンスの使用停止
スポット インスタンスはコストを削減できるため、オンデマンド インスタンスではなくスポット インスタンスを使用してコンピューティングを作成する方法は、ジョブを実行する一般的な方法です。 ただし、スポット インスタンスは、クラウド プロバイダーのスケジュール メカニズムによってプリエンプトされる場合があります。 スポット インスタンスのプリエンプションによって、次のような実行中のジョブに関する問題が発生する可能性があります。
- シャッフル フェッチの失敗
- シャッフルによるデータの損失
- RDD データ損失
- ジョブの失敗
これらの問題に対処するために、使用停止を有効にすることができます。 使用停止では、スポット インスタンスを使用停止にする前に、クラウド プロバイダーが通常送信する通知を利用します。 実行プログラムを含むスポット インスタンスがプリエンプション通知を受け取ると、使用停止プロセスはシャッフルと RDD データを正常な実行プログラムに移行しようとします。 最終的なプリエンプションの前の期間は、クラウド プロバイダーに応じて、通常 30 秒から 2 分になります。
Databricks では、使用停止も有効になっている場合に、データ移行を有効にすることを推奨します。 通常、シャッフル フェッチ エラー、シャッフル データ損失、RDD データ損失などのエラーの可能性は、より多くのデータが移行されるにつれて低下します。 データの移行により、再計算やコストの削減にもつながります。
メモ
廃止は最善の努力であり、最後の利用停止の前にすべてのデータが移行できることを保証するものではありません。 使用停止では、実行中のタスクが実行プログラムからシャッフル データをフェッチしている場合、シャッフル フェッチの失敗を防ぐことを保証できません。
使用停止が有効になっていると、スポット インスタンスのプリエンプションによって発生したタスク エラーは、失敗した試行の合計数に追加されません。 失敗の原因はタスクの外部にあり、ジョブの失敗にはならないため、プリエンプションによって発生したタスク エラーは、失敗した場合としてカウントされません。
使用停止を有効にする
コンピューティングで使用停止を有効にするには、コンピューティング構成 UI の [詳細オプション] の [Spark] タブに次のプロパティを入力します。 これらのプロパティの詳細については、「Spark の構成」を参照してください。
アプリケーションの使用停止を有効にするには、[Spark 構成] フィールドに次のプロパティを入力します。
spark.decommission.enabled true使用停止中にシャッフル データ移行を有効にするには、[Spark 構成] フィールドに次のプロパティを入力します。
spark.storage.decommission.enabled true spark.storage.decommission.shuffleBlocks.enabled true使用停止中に RDD キャッシュ データ移行を有効にするには、[Spark 構成] フィールドに次のプロパティを入力します。
spark.storage.decommission.enabled true spark.storage.decommission.rddBlocks.enabled trueメモ
RDD StorageLevel レプリケーションが 1 より大きい値に設定されている場合、Databricks では、RDD によってデータが失われないようにするため、RDD データ移行を有効にすることは推奨されません。
ワーカーの使用停止を有効にするには、[環境変数] フィールドに次のプロパティを入力します。
SPARK_WORKER_OPTS="-Dspark.decommission.enabled=true"
使用停止の状態と失われた理由を UI で表示する
UI からワーカーの使用停止状態にアクセスするには、 Spark コンピューティング UI の [マスター ] タブに移動します。
使用停止が完了すると、コンピューティングの詳細ページの Spark UI > Executors タブで Executor の損失の理由を表示できます。