この記事には、Lakeflow ジョブのコンピューティングを構成するための推奨事項とリソースが含まれています。
重要
ジョブのサーバーレス コンピューティングには次のような制限事項があります。
- 継続的スケジューリングはサポートされません。
- 構造化ストリーミングでは、既定または時間ベースの間隔トリガーはサポートされません。
制限事項の詳細については、「サーバーレス コンピューティングの制限事項」を参照してください。
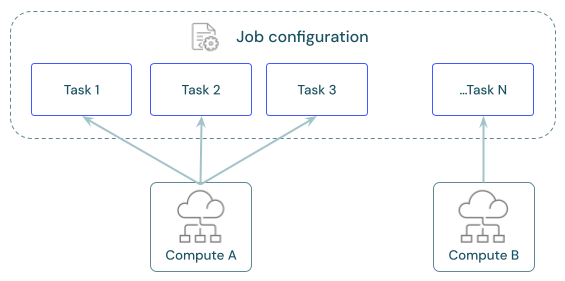
各ジョブには、1 つ以上のタスクを含めることができます。 各タスクのコンピューティング リソースを定義します。 同じジョブに対して定義された複数のタスクで、同じコンピューティング リソースを使用できます。
各タスクに推奨されるコンピューティングは何ですか?
次の表は、各タスクの種類に対して推奨されるコンピューティングの種類とサポートされているコンピューティングの種類を示しています。
注
ジョブのサーバーレス コンピューティングには制限があり、すべてのワークロードをサポートしているわけではありません。 「サーバーレス コンピューティングの制限事項」を参照してください。
| タスク | 推奨されるコンピューティング | サポートされているコンピュート |
|---|---|---|
| Notebooks | サーバーレス ジョブ | サーバーレスジョブ、クラシックジョブ、クラシックオールパーパス |
| Python スクリプト | サーバーレス ジョブ | サーバーレスジョブ、クラシックジョブ、クラシック汎用ジョブ |
| Python ホイール | サーバーレス ジョブ | サーバーレス ジョブ、クラシック ジョブ、クラシック汎用 |
| SQL | サーバーレス SQL ウェアハウス | サーバーレス SQL ウェアハウス、プロ SQL ウェアハウス |
| Lakeflow Spark 宣言型パイプライン | サーバーレス パイプライン | サーバーレス パイプライン、クラシック パイプライン |
| dbt | サーバーレス SQL ウェアハウス | サーバーレス SQL ウェアハウス、プロ SQL ウェアハウス |
| dbt CLI コマンド | サーバーレス ジョブ | サーバーレスジョブ、クラシックジョブ、クラシック万能 |
| JAR | 従来の仕事 | クラシックジョブ、多用途クラシック |
| Spark Submit(スパークサブミット) | 古典的な職業 | 古典的な職種 |
Lakeflow ジョブの価格は、タスクの実行に使用されるコンピューティングに関連付けられています。 詳細については、「Databricks の価格」を参照してください。
ジョブのコンピューティングはどのように構成しますか?
クラシック ジョブ コンピューティングは Lakeflow ジョブ UI から直接構成され、これらの構成はジョブ定義の一部です。 その他の使用可能なコンピューティングの種類はすべて、その構成を他のワークスペース アセットと共に格納します。 次の表に詳細を示します。
| コンピューティングの種類 | 詳細 |
|---|---|
| 従来のジョブ計算 | 汎用コンピューティングで使用できるのと同じ UI と設定を使用して、クラシック ジョブのコンピューティングを構成します。 「コンピューティング構成リファレンス」を参照してください。 |
| サーバーレス コンピューティングによるジョブ実行 | サーバーレスコンピューティングは、対応するすべてのタスクにおいて既定の計算方法です。 Databricks がサーバーレス コンピューティングのコンピューティング設定を管理します。 ワークフローのサーバーレス コンピューティングを使用した Lakeflow ジョブの実行を参照してください。 |
| SQL ウェアハウス | サーバーレスおよびプロ SQL ウェアハウスは、無制限のクラスター作成特権を持つワークスペース管理者またはユーザーによって構成されます。 既存の SQL ウェアハウスに対して実行するタスクを構成します。 「SQL ウェアハウスに接続する」を参照してください。 |
| Lakeflow Spark 宣言型パイプライン計算 | パイプラインの構成中に、Lakeflow Spark 宣言パイプラインのコンピューティング設定を構成します。 パイプラインのクラシック コンピューティングの構成に関するページを参照してください。 Azure Databricks は、サーバーレスの Lakeflow Spark 宣言型パイプラインのコンピューティング リソースを管理します。 サーバーレス パイプラインの構成を参照してください。 |
| 汎用コンピュート | 必要に応じて、クラシック汎用コンピューティングを使用してタスクを構成できます。 Databricks では、運用環境の場合、この構成はお勧めしません。 「コンピューティング構成リファレンス」と「ジョブには常に汎用コンピューティングを使用した方がよいでしょうか?」を参照してください。 |
タスク間でコンピューティングを共有する
複数のタスクのオーケストレーションを行うジョブでリソースの使用量を最適化するために、同じジョブ コンピューティング リソースを使用するようにタスクを構成します。 タスク間でコンピューティングを共有すると、起動時間に関連する待機時間を短縮できます。
1 つのジョブ コンピューティング リソースを使用して、ジョブの一部であるすべてのタスク、または特定のワークロード用に最適化された複数のジョブ リソースを実行できます。 ジョブの一部として構成されたジョブ コンピューティングは、ジョブ内の他のすべてのタスクで使用できます。
次の表は、1 つのタスク用に構成されたジョブ コンピューティングと、タスク間で共有されるジョブ コンピューティングの違いを示しています。
| 1 つのタスク | タスク間で共有 | |
|---|---|---|
| 始める | タスクの実行が開始されたとき。 | コンピューティング リソースを使用するように構成された最初のタスクの実行が開始されたとき。 |
| 終了する | タスクが実行された後。 | コンピューティング リソースを使用するように構成された最後のタスクが実行された後。 |
| アイドルコンピューティング | 該当なし。 | コンピューティング リソースを使用していないタスクの実行中も、コンピューティングはオンのままでアイドル状態になります。 |
共有ジョブ クラスターのスコープは 1 つのジョブ実行に設定され、同じジョブの他のジョブまたは実行では使用できません。
ライブラリを共有ジョブ クラスター構成で宣言することはできません。 依存ライブラリはタスク設定に追加する必要があります。
タスク間の共有ドライバーの状態
複数のタスクが 1 つのジョブ コンピューティング リソースを共有する場合、タスクは同じドライバー JVM で実行されます。 クラスの状態とシングルトンは、ジョブの実行期間中、タスク間で保持されます。 ほとんどのワークロードでは、これは透過的ですが、次の影響に注意してください。
- Scala シングルトンとコンパニオン オブジェクトは、タスク間で共有されます。 Scala コンパニオン オブジェクトの変更可能な状態は、同じ共有クラスターで実行されるタスク間で保持されます。 並列タスクが同じコンパニオン オブジェクト変数に対して読み取りまたは書き込みを行う場合、あるタスクの値によって別のタスクの値が上書きされる可能性があります。 実際の例については、 正しくないパラメーター値を使用したマルチタスク ワークフローに関するサポート技術情報の記事を参照してください。
- 1 つのタスクによって読み込まれたライブラリは、ジョブの実行期間中、後続のタスクで引き続き使用できます 。
コードでタスク レベルの分離が必要な場合は、次のいずれかの方法を使用します。
- 個別のジョブ コンピューティング リソースを使用するように各タスクを構成します。
- タスクが並列ではなく順番に実行されるように、明示的なタスク依存関係を追加します。
- シングルトンまたは共有の変更可能な状態に依存しないようにコードをリファクタリングします。 たとえば、パラメーターをコンパニオン オブジェクトから読み取るのではなく、各関数に明示的に渡します。
ジョブの計算を確認し、設定を行い、スワップする
[ジョブの詳細] パネルの [コンピューティング] セクションには、現在のジョブのタスク用に構成されているすべてのコンピューティングが一覧表示されます。
コンピューティング仕様にマウス ポインターを合わせると、コンピューティング リソースを使用するように構成されたタスクがタスク グラフで強調表示されます。
[スワップ] ボタンを使用して、コンピューティング リソースに関連付けられているすべてのタスクのコンピューティングを変更します。
クラシック ジョブ コンピューティング リソースには、構成オプションがあります。 その他のコンピューティング リソースには、コンピューティング構成の詳細を表示および変更するためのオプションがあります。
詳細情報
Azure Databricks クラシック ジョブの構成の詳細については、「 クラシック Lakeflow ジョブを構成するためのベスト プラクティス」を参照してください。