このページでは、コードの書式設定、オートコンプリート、言語の混在、マジック コマンドなど、Databricks ノートブックでコードを開発する方法について説明します。
オートコンプリート、変数の選択、マルチカーソルのサポート、並列比較など、エディターで使用できる高度な機能の詳細については、「Databricks ノートブックとファイルエディター」をご覧ください。
ノートブックまたはファイル エディターを使用すると、Genie Code を使用してコードの生成、説明、デバッグを行うことができます。 詳細については、「 Genie Code の使用 」を参照してください。
Databricks ノートブックには、Python ノートブック用の対話型デバッガーも組み込まれています。 「ノートブックのデバッグ」を参照してください。
重要
オートコンプリート、Python コードの書式設定、デバッガーなどのコード 支援機能のために、ノートブックをアクティブな compute セッションにアタッチする必要があります。
コードをモジュール化する
Databricks Runtime 11.3 LTS 以降では、Azure Databricks ワークスペースでソース コード ファイルを作成および管理し、必要に応じてこれらのファイルをノートブックにインポートできます。
ソース コード ファイルの操作の詳細については、「 Databricks Notebooks と Work with Python and R modules の間でコードを共有する」を参照してください。
コード セルの書式設定
Azure Databricksには、ノートブック セルのPythonと SQL コードを書式設定できるツールが用意されています。 これらのツールを使用すると、コードが書式設定された状態を維持するための労力が減り、同じコーディング標準を自分のすべてのノートブックに適用するのに役立ちます。
Python ブラック フォーマッタ ライブラリ
重要
この機能はパブリック プレビュー段階にあります。
Azure Databricksでは、ノートブック内で black を使用したPythonコードの書式設定がサポートされます。 ノートブックは、black と tokenize-rt Python パッケージがインストールされているクラスターにアタッチされている必要があります。
Databricks Runtime 11.3 LTS 以降では、Azure Databricksは black と tokenize-rt をプレインストールします。 これらのライブラリをインストールしなくても、フォーマッタを直接使用できます。
Databricks Runtime 10.4 LTS 以下では、ノートブックまたはクラスターで Python フォーマッタを使用するには、PyPI から black==22.3.0 および tokenize-rt==4.2.1 をインストールする必要があります。 ノートブックで次のコマンドを実行できます:
%pip install black==22.3.0 tokenize-rt==4.2.1
または、ライブラリをクラスターにインストールします。
ライブラリのインストールの詳細については、Python環境管理を参照してください。
Databricks Git フォルダー内のファイルとノートブックの場合は、pyproject.toml ファイルに基づいて Python フォーマッタを構成できます。 この機能を使用するには、Git フォルダー ルート ディレクトリに pyproject.toml ファイルを作成し、Black 構成形式に従って構成します。 ファイルの [tool.black] セクションを編集します。 構成は、その Git フォルダー内の任意のファイルとノートブックの書式を設定する際に適用されます。
Pythonセルと SQL セルの書式を設定する方法
コードを書式設定するには、そのノートブックに対する編集可能アクセス許可が必要です。
Azure Databricksでは、カスタム SQL フォーマッタを使用して SQL と black コード フォーマッタをPythonに書式設定します。
書式指定ツールを起動するには、次の方法があります。
1 つのセルを書式設定する
- キーボード ショートカット: Cmd + Shift + F キーを押します。
- コマンド コンテキスト メニュー:
- SQL セルの書式設定: SQL セルのコマンド コンテキスト ドロップダウン メニューで [SQL の書式設定] を選択します。 このメニュー項目は、SQL ノートブックのセルまたは
%sql言語マジックがあるセル内でのみ表示されます。 - Pythonセルのコマンドコンテキストドロップダウンメニューで「Format Python」を選択します。 このメニュー項目は、Pythonノートブックのセル、または
%pythonlanguage magicを含むセルでのみ表示されます。
- SQL セルの書式設定: SQL セルのコマンド コンテキスト ドロップダウン メニューで [SQL の書式設定] を選択します。 このメニュー項目は、SQL ノートブックのセルまたは
- Notebook Edit メニュー: Pythonまたは SQL セルを選択し、Edit > Format Cell(s) を選択します。
複数のセルを書式設定する
複数のセルを選択した後、書式設定のセルを>編集を選択します。 複数の言語のセルを選択すると、SQL セルと Python セルのみが書式設定されます。 これには、
%sqlと%pythonを使用するものも含まれます。ノートブック内のすべてのPythonと SQL セルを書式設定します
[編集] > [ノートブックの書式設定] を選択します。 ノートブックに複数の言語が含まれている場合は、SQL セルと Python セルのみが書式設定されます。 これには、
%sqlと%pythonを使用するものも含まれます。
SQL クエリの書式設定方法をカスタマイズするには、「 カスタム形式の SQL ステートメント」を参照してください。
コードの書式設定の制限事項
- Black では、4 スペースインデントに対して PEP 8 標準が適用されます。 インデントは設定できません。
- SQL UDF 内の埋め込みPython文字列の書式設定はサポートされていません。 同様に、Python UDF 内の SQL 文字列の書式設定はサポートされていません。
ノートブックのコード言語
既定の言語を設定する
ノートブックの既定の言語は、ノートブック名の下に表示されます。

既定の言語を変更するには、言語ボタンをクリックし、ドロップダウン メニューから新しい言語を選択します。 既存のコマンドを引き続き確実に機能させるために、前の既定の言語のコマンドには、その先頭に言語マジック コマンドが自動的に付加されます。
言語を混在させる
既定では、ノートブックの既定の言語がセルに使用されます。 セル内で既定の言語以外の言語を使用するには、言語ボタンをクリックしてドロップダウン メニューから言語を選択します。
または、セルの先頭に %<language> 言語マジック コマンドを使用することもできます。 サポートされているマジック コマンドは %python、%r、%scala、%sql です。
注意
言語マジック コマンドを呼び出すと、そのコマンドはノートブックの実行コンテキストの中で REPL にディスパッチされます。 ある言語で定義された (したがって、その言語の REPL 内で定義された) 変数を、別の言語の REPL の中で使用することはできません。 REPL どうしが状態を共有するには、外部リソース (たとえば DBFS 内のファイルやオブジェクト ストレージ内のオブジェクト) を介する以外に方法はありません。
ノートブックでは、いくつかの補助マジック コマンドもサポートされています。
-
%sh: シェル コードをノートブック内で実行できます。 シェル コマンドの終了状態が 0 以外の場合にセルを異常終了させるには、-eオプションを追加します。 このコマンドは Apache Spark ドライバー上でのみ実行され、ワーカーでは実行されません。 シェル コマンドをすべてのノードで実行するには、初期化スクリプトを使用します。 -
%fs:dbutilsのファイルシステム コマンドを使用できます。 たとえば、dbutils.fs.lsコマンドを実行してファイルを一覧表示するには、代わりに%fs lsを指定します。 詳細については、「work with files on Azure Databricks」を参照してください。 -
%md: テキスト、画像、数式や方程式など、さまざまな種類のドキュメントを含めることができます。 次のセクションを参照してください。
Python コマンドでの SQL 構文の強調表示とオートコンプリート
構文の強調表示と SQL autocomplete は、spark.sql コマンドなど、Python コマンド内で SQL を使用する場合に使用できます。
SQL セルの結果を調べる
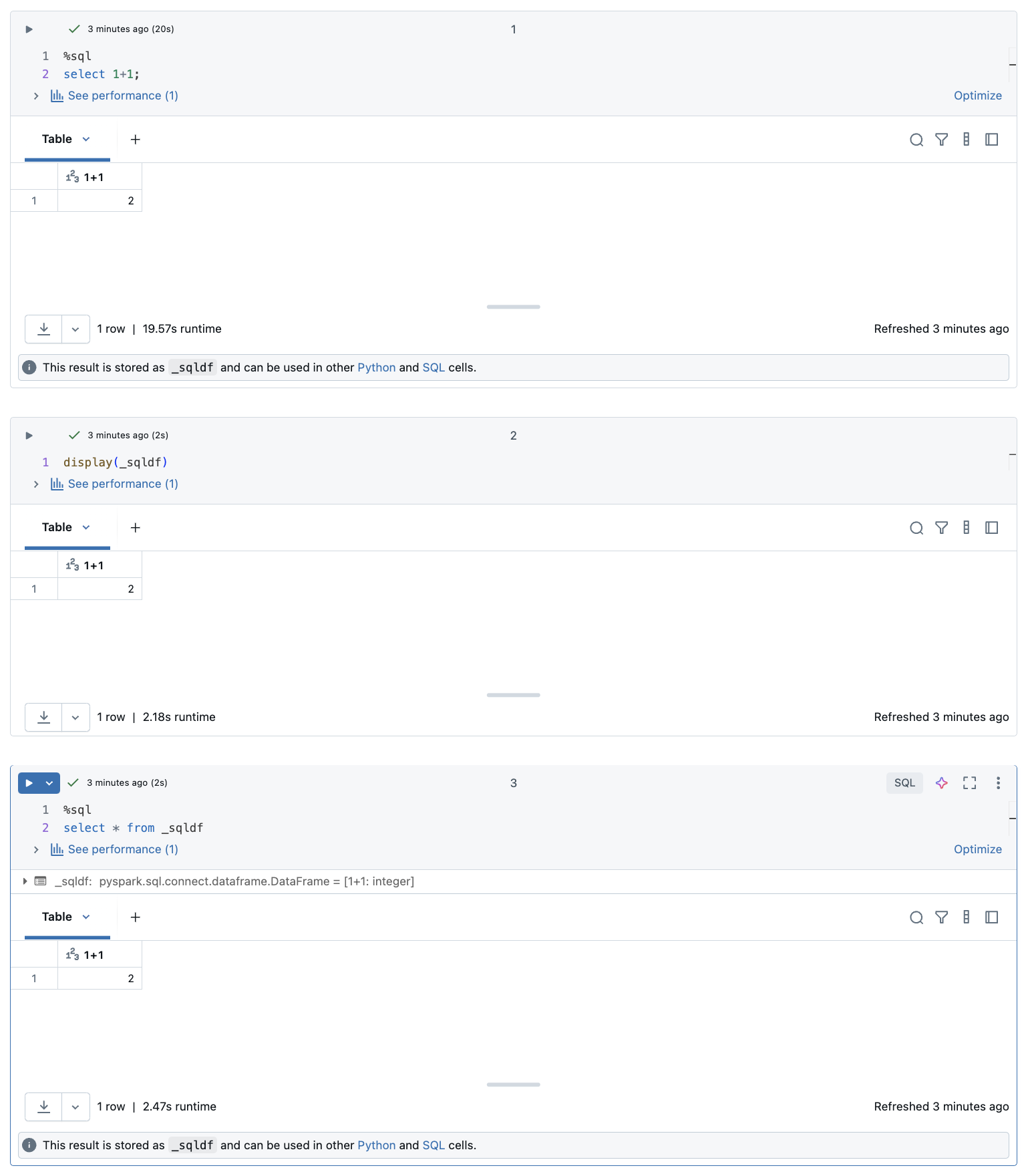
Databricks ノートブックでは、SQL 言語セルからの結果は、変数 _sqldfに割り当てられた暗黙的な DataFrame として自動的に使用できるようになります。 この変数は、ノートブック内での位置に関係なく、後で実行する任意のPythonおよび SQL セルで使用できます。
注意
この機能には次の制限があります。
-
_sqldf変数は、コンピューティングにSQL ウェアハウスを使用するノートブックでは使用できません。 - 後続の Python セルで
_sqldfを使用することは、Databricks Runtime 13.3 以降でサポートされています。 - 後続の SQL セルでの
_sqldfの使用は、Databricks Runtime 14.3 以降でのみサポートされています。 - クエリでキーワード
CACHE TABLEまたはUNCACHE TABLEを使用する場合、_sqldf変数は使用できません。
次のスクリーンショットは、後続の Python セルと SQL セルで _sqldf を使用する方法を示しています。
重要
変数 _sqldf は、SQL セルが実行されるたびに再割り当てされます。 特定の DataFrame 結果への参照が失われることを回避するには、次の SQL セルを実行する前に新しい変数名に割り当てます。
Python
new_dataframe_name = _sqldf
SQL
ALTER VIEW _sqldf RENAME TO new_dataframe_name
SQL セルを並列で実行する
コマンドが実行中で、ノートブックが対話型クラスターにアタッチされている間は、現在のコマンドと同時に SQL セルを実行できます。 SQL セルは、新しい、並列のセッションで実行されます。
セルを並列で実行するには:
[今すぐ実行] をクリックします。 セルは即座に実行されます。
セルは新しいセッションで実行されるため、一時ビュー、UDF、および implicit Python DataFrame (_sqldf) は、並列で実行されるセルではサポートされません。 また、並列実行中は既定のカタログ名とデータベース名が使用されます。 コードが別のカタログまたはデータベースのテーブルを参照している場合は、3 レベルの名前空間 (catalog.schema.table) を使用してテーブル名を指定する必要があります。
SQL ウェアハウスで SQL セルを実行する
SQL 分析用に最適化されたコンピューティングの種類である SQL ウェアハウス上の Databricks ノートブックで SQL コマンドを実行できます。 「SQL ウェアハウスを使用してノートブックを使用する」を参照してください。
マジック コマンドを使用する
Databricks ノートブックでは、一般的なタスクを簡略化するために、標準の構文を超えて機能を拡張するさまざまなマジック コマンドがサポートされています。 ラインマジックには % が付き、1 行に適用されます。 セルマジックには %% が付き、セル本体全体に適用されます。
| マジック コマンド | 例 | 説明 |
|---|---|---|
%python |
%pythonprint("Hello") |
セルの言語をPythonに切り替えます。 セルのPythonコードを実行します。 |
%r |
%rprint("Hello") |
セルの言語を R に切り替えます。セル内の R コードを実行します。 |
%scala |
%scalaprintln("Hello") |
セル言語を Scala に切り替えます。 セル内の Scala コードを実行します。 |
%sql |
%sqlSELECT * FROM table |
セル言語を SQL に切り替えます。 結果は、Python/SQL セルで _sqldf として使用できます。 |
%md |
%md# TitleContent here |
セルの言語を Markdown に切り替えます。 セル内の Markdown コンテンツをレンダリングします。 テキスト、画像、数式、LaTeX をサポートします。 |
%pip |
%pip install pandas |
Python パッケージ (ノートブック スコープ) をインストールします。 「Notebook スコープのPython ライブラリ」を参照。 |
%run |
%run /path/to/notebook |
別のノートブックを実行し、その関数と変数をインポートします。 Notebook ワークフローを参照してください。 |
%fs |
%fs ls /path |
dbutils ファイルシステム コマンドを実行します。
dbutils.fs コマンドの短縮形。
「ファイルの操作」を参照してください。 |
%sh |
%sh ls -la |
シェル コマンドを実行します。 ドライバー ノードでのみ実行されます。 エラー時に失敗するには、 -e を使用します。 |
%tensorboard |
%tensorboard --logdir /logs |
TensorBoard UI をインラインで表示します。 Databricks ランタイム ML でのみ使用できます。 TensorBoard を参照してください。 |
%set_cell_max_output_size_in_mb |
%set_cell_max_output_size_in_mb 10 |
セルの最大出力サイズを設定します。 範囲: 1 ~ 20 MB。 ノートブック内の後続のすべてのセルに適用されます。 |
%skip |
%skipprint("This won't run") |
セルの実行をスキップします。 ノートブックの実行時にセルが実行されないようにします。 |
%%profile |
%%profilemy_function() |
Pythonコード実行をプロファイリングする。 タイミング情報を含む階層型呼び出しツリーを表示します。 Databricks Runtime 17.2 以降が必要です。 |
%%oprofile |
%%oprofilemy_function() |
セルの実行中にオブジェクトの作成をプロファイルします。 新しく作成された新しいオブジェクトのテーブルを、種類別にグループ化して表示します。 Databricks Runtime 17.2 以降が必要です。 |
注意
IPython Automagic: Databricks ノートブックでは IPython automagic が既定で有効になっており、 pip などの特定のコマンドを % プレフィックスなしで動作できます。 たとえば、 pip install pandas は %pip install pandasと同じように動作します。
重要
- 変数と状態は、異なる言語の REPL 間で分離されます。 たとえば、scala セルではPython変数にアクセスできません。
- ノートブック セルには 1 つのセル マジック コマンドしか含めず、セルの最初の行である必要があります。
-
%runは、ノートブック全体をインラインで実行するため、単独でセル内に存在する必要があります。 - Databricks Runtime 12.2 LTS 以降で
%pipを使用する場合は、インストール後にPython状態がリセットされるため、すべてのパッケージ インストール コマンドをノートブックの先頭に配置します。