Important
Lakebase 自動スケールは、 eastus、 eastus2、 centralus、 southcentralus、 westus、 westus2、 canadacentral、 brazilsouth、 northeurope、 uksouth、 westeurope、 australiaeast、 centralindia、 southeastasiaの各リージョンで使用できます。
Lakebase 自動スケールは、自動スケール コンピューティング、ゼロへのスケール、分岐、インスタント リストアを備えた最新バージョンの Lakebase です。 Lakebase プロビジョニング済みユーザーの場合は、「 Lakebase Provisioned」を参照してください。
同期されたテーブルを使用すると、Lakebase Postgres を介して Lakehouse データを提供できます。 Unity カタログ テーブルは Postgres に同期されるため、アプリケーションは低待機時間で lakehouse データに直接クエリを実行できます。 このプロセスは、一般に逆 ETL と呼ばれます。 Lakehouse は分析とエンリッチメント用に最適化されていますが、Lakebase は高速なルックアップ スタイルのクエリとトランザクションの一貫性を必要とする運用ワークロード向けに設計されています。
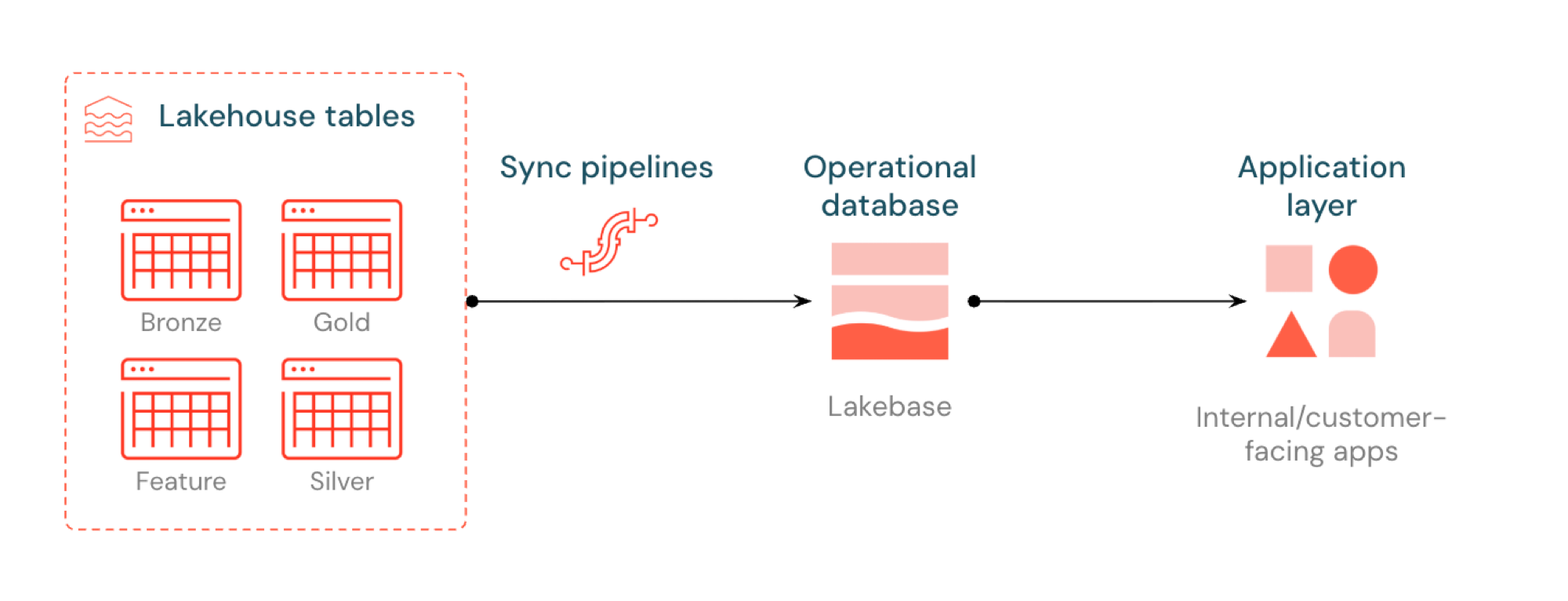
同期テーブルとは
同期されたテーブルを使用すると、Lakebase Postgres を介して Unity カタログから分析グレードのデータを提供できるため、待機時間の短いクエリ (10 ミリ秒未満) と完全な ACID トランザクションを必要とするアプリケーションで使用できます。 リアルタイム アプリケーションでデータを提供する準備を整えることで、分析ストレージと運用システムのギャップを埋めます。
サポートされているソース
同期テーブルでは、次の Unity カタログ ソースの種類がサポートされます。
- 管理されたデルタ テーブルと外部デルタ テーブル
- 管理されたIcebergテーブルと外部Icebergテーブル
- ビューと具体化されたビュー
どのように機能するのか
Databricks 同期テーブルは 、Lakebase に Unity カタログ データのマネージド コピーを作成します。 同期されたテーブルを作成すると、次の情報が得られます。
- 同期パイプラインを参照する Unity カタログの同期テーブル
- Lakebase の Postgres テーブル (アプリケーションで読み取り専用、クエリ可能)
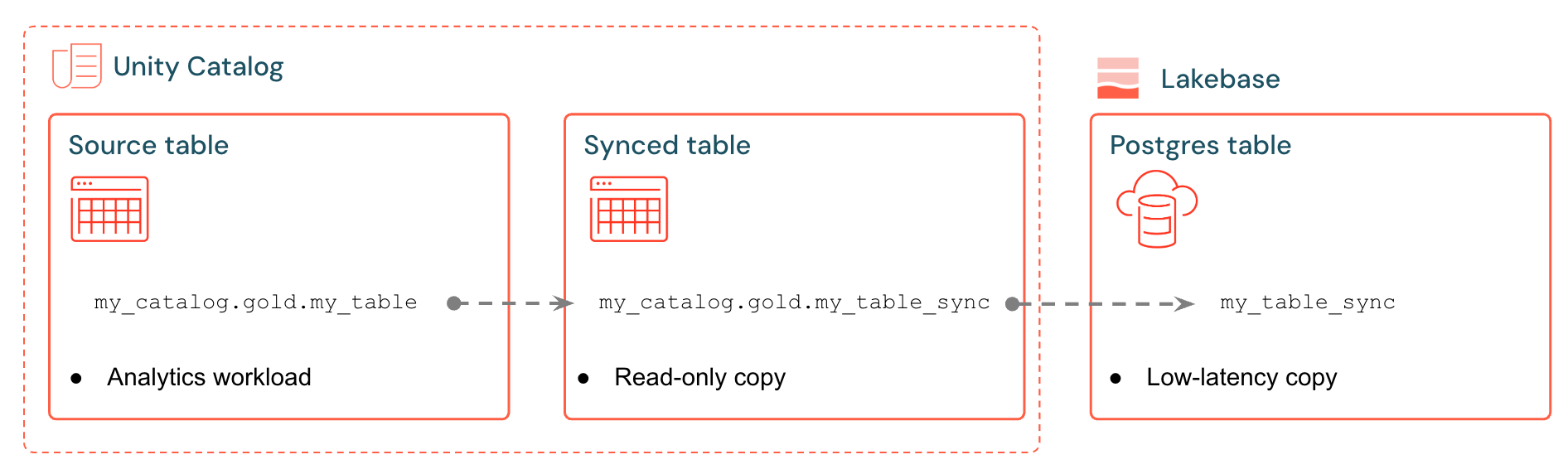
たとえば、ゴールド テーブル、エンジニアリングされた機能、または analytics.gold.user_profiles からの ML 出力を新しい同期テーブル analytics.gold.user_profiles_syncedに同期できます。 Postgres では、Unity カタログ スキーマ名が Postgres スキーマ名になるため、 "gold"."user_profiles_synced"として表示されます。
SELECT * FROM "gold"."user_profiles_synced" WHERE "user_id" = 12345;
アプリケーションは標準の Postgres ドライバーに接続し、同期されたデータを独自の運用状態と共に照会します。
Warnung
同期されたテーブルを Postgres で直接変更することは可能ですが、Azure Databricks では、ソースでデータの整合性を保護するために読み取りクエリのみを実行することを厳密に推奨しています。 同期されたテーブルでサポートされる操作については、「 サポートされる操作」を参照してください。
同期パイプラインでは、マネージド Lakeflow Spark 宣言パイプラインを使用して、Unity カタログ同期テーブルと Postgres テーブルの両方をソース テーブルからの変更で継続的に更新します。 各同期では、Lakebase データベースへの最大 16 個の接続を使用できます。
Lakebase Postgres では、トランザクションが保証された最大 1,000 個の同時接続がサポートされているため、アプリケーションはエンリッチされたデータを読み取り、同じデータベース内の挿入、更新、削除も処理できます。
同期モード
アプリケーションのニーズに基づいて適切な同期モードを選択します。
| モード | 説明 | いつ使用するか | パフォーマンス |
|---|---|---|---|
| スナップショット | すべてのデータの 1 回限りのコピー | ソースの変更 > 10 サイクルあたりの行の%、またはソースが CDF (ビュー、Iceberg テーブル) をサポートしていない | 変更するソースデータの10% >がある場合、効率が10倍高まります。 |
| トリガー | オンデマンドまたは間隔で実行されるスケジュールされた更新 | ソース行は既知の周期で変更されます。 挿入、更新、および削除は、更新ごとに反映されます。 | コストとラグのバランスが良い。 <5 分間隔で実行するとコストがかかる |
| 連続 | 待機時間が数秒のリアルタイム ストリーミング | 変更は、ほぼリアルタイムで Lakebase に表示される必要があります | ラグが最も低く、コストが最も高い。 最小 15 秒間隔 |
トリガーモードと連続モードでは、ソース テーブルで Change Data Feed (CDF) を有効にする必要があります。 CDF が有効になっていない場合は、実行する正確な ALTER TABLE コマンドを使用して UI に警告が表示されます。 変更データ フィードの詳細については、 Databricks での Delta Lake 変更データ フィードの使用に関するページを参照してください。
利用事例の例
同期テーブルは、次のようなデータサービスのユース ケースに使用できます。
- 新しいユーザー プロファイルを Databricks Apps に提供するパーソナル化エンジン
- Lakehouse で計算されたモデル予測または特徴値を提供するアプリケーション
- リアルタイムで KPI を提供する顧客向けのダッシュボード
- リスク スコアを即時アクションに提供する不正行為検出サービス
- Lakehouse データから強化された顧客レコードを提供する支援ツール
同期テーブルを作成する (UI)
UI ワークフローの概要を次に示します。
前提条件
必要なもの:
- Lakebase が有効になっている Databricks ワークスペース。
- Lakebase プロジェクト (プロジェクト の作成を参照)。
- 同期する Unity カタログ テーブル。
- 同期されたテーブルを作成するためのアクセス許可。 使用するスキーマ にUSE_SCHEMA と CREATE_TABLE が必要です。 [同期テーブルの作成] フローのカタログとスキーマのオプションには、ID にこれらの権限があるスキーマのみが一覧表示されます。
容量計画とデータ型の互換性については、「データ型と互換性」および「容量計画」を参照してください。
手順 1: ソース テーブルを選択する
ワークスペースのサイドバーで [カタログ ] に移動し、同期する Unity カタログ テーブルを選択します。
手順 2: 変更データ フィードを有効にする (必要な場合)
トリガーまたは継続的同期モードを使用する予定の場合は、ソース テーブルでデータ フィードの変更を有効にする必要があります。 テーブルで CDF が既に有効になっているかどうかを確認するか、SQL エディターまたはノートブックで次のコマンドを実行します。
ALTER TABLE your_catalog.your_schema.your_table
SET TBLPROPERTIES (delta.enableChangeDataFeed = true)
your_catalog.your_schema.your_tableを実際のテーブル名に置き換えます。
手順 3: 同期テーブルを作成する
テーブルの詳細ビューで[ 作成>同期テーブル ]をクリックします。
![[同期されたテーブル] オプションを示す [作成] ボタンのドロップダウン](../../_static/images/oltp/reverse-etl-create-dropdown.png)
手順 4: 構成
[同期テーブルの作成] ダイアログで、次 の手順を実行 します。
カタログとスキーマの一覧には、現在のユーザーが USE_SCHEMA 権限と CREATE_TABLE 権限を持つ Unity カタログ スキーマのみが含まれます。 予想されるスキーマが表示されない場合は、カタログ管理者にアクセス許可を確認してください。
- テーブル名: 同期されたテーブルの名前を入力します (ソース テーブルと同じカタログとスキーマに作成されます)。 これにより、Unity カタログ同期テーブルと、クエリできる Postgres テーブルの両方が作成されます。
- データベースの種類: Lakebase サーバーレス (自動スケール) を選択します。
- 同期モード: ニーズに基づいて [スナップショット]、[ トリガー済み]、または [継続的 ] を選択します (上記の 同期モード を参照)。
- プロジェクト、ブランチ、データベースの選択を構成します。
- 主キーが正しいことを確認します (通常は自動検出されます)。
トリガー モードまたは連続モードを選択し、データ フィードの変更をまだ有効にしていない場合は、正確なコマンドを実行すると警告が表示されます。 データ型の互換性に関する質問については、「 データ型と互換性」を参照してください。
[ 作成 ] をクリックして、同期されたテーブルを作成します。
手順 5: 監視
作成後、 カタログで同期されたテーブルを監視します。 [ 概要 ] タブには、同期の状態、構成、パイプラインの状態、最後の同期タイムスタンプが表示されます。 [ 今すぐ同期] を使用して手動で更新します。
後続の同期をスケジュールまたはトリガーする
初期スナップショットは作成時に自動的に実行されます。 スナップショット モードとトリガーモードでは、後続の同期を明示的にトリガーする必要があります。 連続 モードは自己管理です。
データベース テーブル同期パイプライン タスク
Lakeflow ジョブの データベース テーブル同期パイプライン タスクは、同期されたテーブルのパイプラインをワークフロー ステップとして実行します。 テーブル更新トリガーまたはスケジュールを使用してジョブを構成します。
ソース テーブルの更新時にトリガーする
ソース Unity カタログ テーブルが更新されたときにジョブを起動します。 トリガー モードでは、新しい変更のみが増分的に適用され、継続的モードの常時オン コストなしでほぼリアルタイムの鮮度が得られます。
- サイドバーで[ ワークフロー]をクリックします。
- [ ジョブの作成 ] をクリックするか、既存のジョブを開きます。
- [ タスク ] タブで、[ + 別のタスクの種類の追加] をクリックします。
- [ インジェストと変換] で、[ データベース テーブル同期パイプライン] を選択します。
- [ パイプライン ] フィールドで、同期されたテーブルに関連付けられているパイプラインを選択します。
- [スケジュールとトリガー] で、[トリガーの追加] をクリックします。
- トリガーの種類として [テーブルの更新 ] を選択します。
- [ テーブル] で、監視するソース Unity カタログ テーブルを選択します。
- [保存] をクリックします。
スケジュールに基づいてトリガー
固定間隔で同期を実行します。 通常、夜間または毎週の完全更新が最も効率的なパターンである スナップショット モードに適しています。
- 上記の手順 1 から 5 に従って、 データベース テーブル同期パイプライン タスクをジョブに追加します。
- [スケジュールとトリガー] で、[トリガーの追加] をクリックします。
- トリガーの種類として [ スケジュール済 ] を選択します。
- cron スケジュールとタイムゾーンを設定し、[ 保存] をクリックします。
SDK を使用する
たとえば、アップストリームのノートブックやパイプラインの末尾で、プログラムによって同期の実行をトリガーします。
from databricks.sdk import WorkspaceClient
w = WorkspaceClient()
# Get the pipeline ID from the synced table
table = w.database.get_synced_database_table(name="catalog.schema.synced_table")
pipeline_id = table.data_synchronization_status.pipeline_id
# Trigger a sync run
w.pipelines.start_update(pipeline_id=pipeline_id)
データ型と互換性
Unity カタログのデータ型は、同期テーブルの作成時に Postgres 型にマップされます。 複合型 (ARRAY、MAP、STRUCT) は JSONB として Postgres に格納されます。
| ソース列の種類 | Postgres 列の種類 |
|---|---|
| BIGINT | BIGINT |
| バイナリ | BYTEA |
| BOOLEAN | BOOLEAN |
| DATE | DATE |
| DECIMAL(p,s) | 数値 |
| DOUBLE | 倍精度 |
| FLOAT | 実数 |
| INT | INTEGER |
| INTERVAL | INTERVAL |
| SMALLINT | SMALLINT |
| STRING | テキスト |
| TIMESTAMP | タイム ゾーンを含むタイムスタンプ |
| TIMESTAMP_NTZ | タイムゾーン無しタイムスタンプ |
| タイニーイント (TINYINT) | SMALLINT |
| ARRAY<要素タイプ> | JSONB |
| MAP<キータイプ,バリュータイプ> | JSONB |
| STRUCT<fieldName:fieldType[, ...]> | JSONB |
注
GEOGRAPHY、GEOMETRY、VARIANT、および OBJECT 型はサポートされていません。
無効な文字を処理する
Null バイト (0x00) などの特定の文字は、Unity カタログの STRING、ARRAY、MAP、または STRUCT 列では使用できますが、Postgres TEXT または JSONB 列ではサポートされていません。 これにより、次のようなエラーで同期エラーが発生する可能性があります。
ERROR: invalid byte sequence for encoding "UTF8": 0x00
ERROR: unsupported Unicode escape sequence DETAIL: \u0000 cannot be converted to text
ソリューション
文字列フィールドをサニタイズする: 同期する前に、サポートされていない文字を削除します。 STRING 列の null バイトの場合:
SELECT REPLACE(column_name, CAST(CHAR(0) AS STRING), '') AS cleaned_column FROM your_tableBINARY への変換: 生バイトを保持する必要がある STRING 列の場合は、BINARY 型に変換します。
容量計画
同期テーブルの実装を計画するときは、次のリソース要件を考慮してください。
- 接続の使用状況: 同期された各テーブルは、インスタンスの接続制限にカウントされる最大 16 個の Lakebase データベースへの接続を使用します。
- サイズ制限: 同期されたすべてのテーブルの論理データ サイズの合計制限は 8 TB です。 個々のテーブルには制限はありませんが、Databricks では更新が必要なテーブルに対して 1 TB を超えないようにすることをお勧めします。
-
名前付け要件: データベース、スキーマ、およびテーブル名には、英数字とアンダースコア (
[A-Za-z0-9_]+) のみを含めることができます。 - スキーマの進化: トリガーモードと連続モードでは、追加スキーマの変更 (列の追加など) のみがサポートされます。
- 更新率:: Lakebase 自動スケーリングの場合、同期パイプラインでは、容量ユニット (CU) あたり約 150 行/秒の連続書き込みとトリガーされた書き込みがサポートされ、CU あたり 1 秒あたり最大 2,000 行のスナップショット書き込みがサポートされます。
Postgres で同期されたテーブルに対して許可される操作
Azure Databricks では、誤った上書きやデータの不整合を防ぐために、同期されたテーブルに対して Postgres で次の操作のみを実行することをお勧めします。
- 読み取り専用クエリ
- インデックスの作成
- テーブルを削除する (Unity カタログから同期されたテーブルを削除した後に領域を解放するため)
Postgres で同期されたテーブルを他の方法で変更することは可能ですが、同期パイプラインに干渉します。
同期されたテーブルを削除する
同期されたテーブルを削除するには、Unity カタログと Postgres の両方から削除する必要があります。
Unity カタログから削除する: カタログで、同期されたテーブルを見つけて、
 をクリックしてメニューをクリックし、[削除] を選択 します。 これにより、データの更新は停止されますが、テーブルは Postgres に残ります。
をクリックしてメニューをクリックし、[削除] を選択 します。 これにより、データの更新は停止されますが、テーブルは Postgres に残ります。Postgres からのドロップ: Lakebase データベースに接続し、テーブルをドロップして領域を解放します。
DROP TABLE your_database.your_schema.your_table;
SQL エディターまたは外部ツールを使用して Postgres に接続できます。
詳細情報
| Task | 説明 |
|---|---|
| プロジェクトの作成 | Lakebase プロジェクトを設定する |
| データベースに接続する | Lakebase の接続オプションについて説明します |
| Unity カタログにデータベースを登録する | 統合されたガバナンスとソース間のクエリのために、Lakebase データを Unity カタログに表示する |
| Unity カタログの統合 | ガバナンスと権限を理解する |
その他のオプション
Databricks 以外のシステムにデータを同期する場合は、Census や Hightouch などの パートナー接続の逆 ETL ソリューション を参照してください。