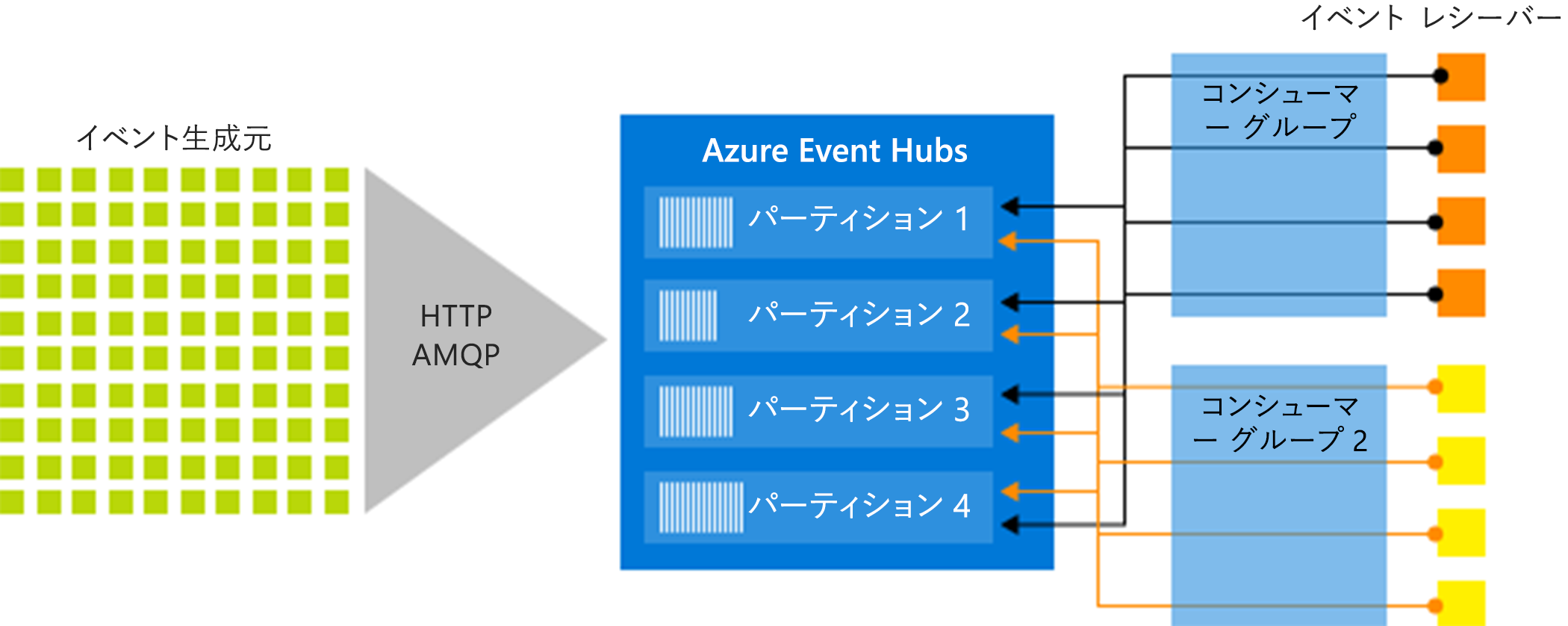
Azure Event Hubs は、大量のイベントやデータを取り込んで処理するスケーラブルなイベント処理サービスで、短い待機時間と高い信頼性を実現します。 サービスの概要については、「Event Hubs とは」を参照してください。
概要記事内の情報に基づいて作成されたこの記事では、Event Hubs のコンポーネントと機能に関する実装の技術的な詳細を説明します。
名前空間
Event Hubs 名前空間は、イベント ハブ (Kafka 用語ではトピック) の管理コンテナーです。 これにより、DNS 統合ネットワーク エンドポイントと、一連のアクセス制御およびネットワーク統合管理機能 (IP フィルタリング、仮想ネットワーク サービス エンドポイント、Private Link など) が提供されます。

メジャー グループ
イベント ハブでは、イベント ハブに送信されたイベントのシーケンスを 1 つまたは複数のパーティションにまとめて整理します。 新しいイベントが到着すると、このシーケンスの末尾に追加されます。
パーティションはコミット ログと考えることができます。 パーティションには、次の情報を含むイベント データが保持されます。
- イベントの本文
- イベントを記述するユーザー定義プロパティ バッグ
- パーティション内のオフセット、ストリーム シーケンス内の数などのメタデータ
- 受け入れられたサービス側のタイムスタンプ

パーティションを使用する利点
Event Hubs の目的は、大量のイベントの処理を支援することです。パーティションは、2 つの方法でそれを支援します。
- Event Hubs は PaaS サービスであるとはいえ、根底には物理的な現実があります。 イベントの順序を保持するログを維持するためには、根底にあるストレージとそのレプリカにそれらのイベントがまとめて保持されている必要があるため、そのようなログにはスループットの上限が生じます。 パーティションに分割することにより、同じイベント ハブで複数の並列ログを使用できるため、生の入出力 (IO) のスループット容量が増えます。
- 個々のアプリケーションは、イベント ハブに送信される量のイベントの処理に遅れずついていくことができなければなりません。 これは複雑になる場合があり、相当にスケールアウトされた並列処理能力が必要になります。 イベントを処理する 1 つのプロセスの容量は限られているため、複数のプロセスが必要になります。 パーティションを使用することで、そうしたプロセスにイベントをフィードしながら、各イベントの処理の所有者を明確化することができます。
パーティションの数
パーティションの数は、イベント ハブの作成時に指定します。 この数は、1 から、各価格レベルで許可されている最大パーティション数の間である必要があります。 各レベルのパーティション数の制限については、こちらの記事を参照してください。
アプリケーションの負荷がピークに達している状態で必要となる以上のパーティションを、その特定のイベント ハブに選択することをお勧めします。 Premium および専用レベル以外のレベルの場合、イベント ハブの作成後にイベント ハブのそのパーティション数を変更することはできません。 Premium または専用レベル内のイベント ハブの場合、イベント ハブの作成後にパーティション数を増やすことはできますが、それらを減らすことはできません。 パーティションへのパーティション キーのマッピングは変化するため、パーティション全体に対するストリームの配分は、それが実行される際に変化します。そのため、お使いのアプリケーション内でイベントの相対的な順序が重要な場合は、そのような変更は極力避けるようにしてください。
パーティション数を上限に設定したくなるかもしれませんが、複数のパーティションの利点を実際に活かせるようにイベント ストリームを構築する必要があることを常に念頭に置いてください。 すべてのイベントについて、または一部のサブストリームのみについて、絶対的な順序を保持する必要がある場合、多くのパーティションを活用できないことがあります。 また、パーティション数が多いと処理する側もより複雑になります。
イベント ハブに含まれるパーティションの数は、料金には関係ありません。 名前空間または専用クラスターの価格ユニット (Standard レベルではスループット ユニット (TU)、Premium レベルではプロセッシング ユニット (PU)、専用レベルでは容量ユニット (CU)) によって決まります。 例えば、名前空間の容量が 1 TU に設定されている場合、パーティションが 32 個でも 1 個でも、Standard レベルのイベント ハブで発生するコストはまったく同じです。 さらに、パーティション数とは関係なく、お使いの名前空間上の TU または PU、あるいは専用クラスターの CU をスケーリングできます。
パーティションは、並列発行と使用を可能にするデータ編成メカニズムです。 並列処理とスケーリングをサポートしていますが、合計容量は名前空間のスケーリングの割当に制限されたままです。 最適なスケールを実現するには、スケーリング ユニット (Standard レベルの場合はスループット ユニット、Premium レベルの場合は処理ユニット、または Dedicated レベルの場合は容量ユニット) とパーティションのバランスを取ることをお勧めします。 一般に、パーティションあたり最大スループットは 1 MB/s にすることをお勧めします。 したがって、パーティションの数を計算するための経験則は、予想される最大スループットを 1 MB/s で除算することです。 たとえば、ユース ケースで 20 MB/s が必要な場合は、最適なスループットを実現するために、少なくとも 20 個のパーティションを選ぶことをお勧めします。
ただし、アプリケーションで特定のパーティションに対してアフィニティが設定されているモデルがある場合、パーティション数を増やすことは有効ではありません。 詳細については、
パーティションへのイベントのマッピング
パーティション キーを使用すると、データ編成を目的として受信イベント データを特定のパーティションにマップすることができます。 パーティション キーは、送信者によって指定され、イベント ハブに渡される値です。 これは、パーティション割り当てを作成する静的なハッシュ関数で処理されます。 イベントを発行するときにパーティション キーを指定しないと、ラウンド ロビン割り当てが使用されます。
イベント発行元は、そのパーティション キーのみを認識し、イベントの発行先となるパーティションは認識しません。 このようにキーとパーティションを分離することにより、送信者はダウンストリーム処理について余分な情報を把握しなくてもよくなります。 デバイスごとまたはユーザーの一意の ID は適切なパーティション キーになりますが、地理的条件などのその他の属性を使用して関連するイベントを 1 つのパーティションにまとめることもできます。
パーティション キーを指定すると、関連するイベントを同じパーティションにまとめて、到着時とまったく同じ順番で保存することができます。 パーティション キーは、アプリケーションのコンテキストから得られる文字列で、イベントの相互関係を識別するものです。 パーティション キーによって識別される一連のイベントが "ストリーム" です。 パーティションは、そのようなたくさんのストリームが混在するログ ストアです。
注
イベントはパーティションに直接送信できますが、特に、高可用性が重要な場合は推奨されません。 イベント ハブの可用性がパーティション レベルにダウングレードされます。 詳細については、可用性と一貫性に関するページを参照してください。
イベント発行元
イベント ハブにデータを送信するエンティティはすべて、"イベント発行元" ("イベント プロデューサー" と同義) です。 イベント発行元は、HTTPS、AMQP 1.0、または Kafka プロトコルを使用してイベントを発行できます。 イベントパブリッシャーは、OAuth2 で発行された JWT または Event Hub 固有の Shared Access Signature (SAS) トークンを使用して、Microsoft Entra ID ベースの承認を使用して公開アクセスを取得します。
AMQP 1.0、Kafka プロトコル、または HTTPS 経由でイベントを発行できます。 Event Hubs サービスは、イベント ハブにイベントを発行するための REST API と .NET、Java、Python、JavaScript、Go の各クライアント ライブラリを備えています。 その他のランタイムとプラットフォームには、 Apache Qpidなどの任意の AMQP 1.0 クライアントを使用できます。
AMQP または HTTPS のどちらを使用するかは、使用シナリオによって決まります。 AMQP では、トランスポート レベルのセキュリティ (TLS) または SSL/TLS に加えて、永続的な双方向ソケットを確立する必要があります。 AMQP ではセッション初期化時のネットワーク コストが高くなりますが、HTTPS では要求ごとに追加の TLS オーバーヘッドが必要になります。 AMQP は、頻度の高い発行元に対して高いパフォーマンスがあり、非同期発行コードとともに使用すると、はるかに短い待機時間を実現できます。
イベントは、個別に発行することもバッチ処理することもできます。 1 つのイベントかバッチ処理かに関係なく、1 回の発行には 1 MB の制限があります。 このしきい値を超えるイベントの発行は拒否されます。
Event Hubs のスループットは、パーティションとスループット ユニットの割り当てを使用してスケーリングされます。 発行元は、イベント ハブ用に選択された特定のパーティション分割モデルは使用せずに、関連するイベントを同じパーティションに一貫して割り当てるために使用される "パーティション キー" の指定だけを行うことをお勧めします。
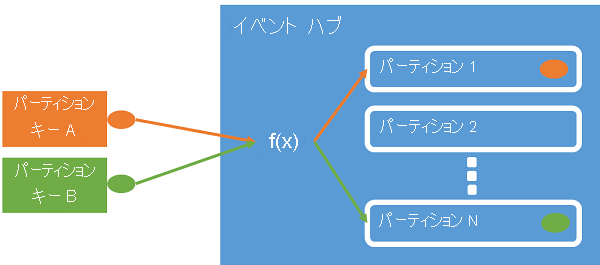
Event Hubs によって、1 つのパーティション キー値を共有するすべてのイベントが一緒に格納され、到着順に配信されます。 パーティション キーと発行元ポリシーを併用する場合は、発行元の ID とパーティション キーの値が一致する必要があります。 そうでない場合、エラーが発生します。
イベントの保持
発行されたイベントは、構成可能な時間ベースの保持ポリシーに基づいてイベント ハブから削除されます。 重要な点がいくつかあります。
- 既定値および指定可能な最小保持期間は 1 時間です。
- Event Hubs Standard の場合、最大保持期間は 7 日です。
- Event Hubs の Premium および Dedicated の場合、最大保持期間は 90 日間です。
- 保持期間を変更すると、既にイベント ハブ内にあるイベントを含むすべてのイベントに適用されます。
Event Hubs は構成された期間にわたりイベントを保持します。これは、すべてのパーティションに適用されます。 保持期間が経過するとイベントは自動的に削除されます。 保持期間を 1 日 (24 時間) に指定した場合、イベントは、その受領からちょうど 24 時間で利用できなくなります。 イベントを明示的に削除することはできません。
許可された保持期間を超えるイベントをアーカイブする必要がある場合は、Event Hubs Capture 機能を有効にすることにより、Azure Storage または Azure Data Lake に自動的に格納できます。 そのようなディープ アーカイブを検索または分析する必要がある場合は、それらを Azure Synapse または他の同様のストアや分析プラットフォームに簡単にインポートできます。
Event Hubs でデータの保持期間に上限を設けている理由は、タイムスタンプによってのみインデックスされ、順次アクセスしかできない大きなストアに、過去に発生した大量のカスタマー データが無造作に取り込まれるのを避けるためです。 このようなアーキテクチャが採用されている理由は、履歴データには、Event Hubs や Kafka で提供されているリアルタイム イベントのインターフェイスよりも高度なインデックス作成とより直接的なアクセスが必要であると考えられるからです。 イベント ストリーミング エンジンは、イベント ソーシングのデータ レイクや長期アーカイブの用途には適していません。
注
Event Hubs はリアルタイム のイベント ストリーム エンジンであり、データベースの代わりに使用したり、無限に保持されるイベント ストリームの永続的なストアとして使用するようには設計されていません。
イベント ストリームの履歴が深いほど、特定のストリームの特定の履歴スライスを見つけるために補助インデックスが必要になります。 イベント ペイロードとインデックス作成の検査は、Event Hubs (または Apache Kafka) の機能スコープ内にありません。 そのため、 Azure Data Lake Store、Azure Data LakeAnalytics、Azure Synapse などのデータベースと特殊な分析ストアとエンジンは、履歴イベントの格納にはるかに適しています。
Event Hubs Capture は Azure Blob Storage および Azure Data Lake Storage に直接統合されており、その統合を通じてイベントを Azure Synapse に直接フローさせることができます。
発行元ポリシー
Event Hubs では、 発行元ポリシーを介してイベント プロデューサーをきめ細かく制御できます。 発行元ポリシーは、多数の独立したイベント発行元を支援するために設計されたランタイム機能です。 発行元ポリシーでは、次のメカニズムを使用してイベント ハブにイベントを発行する際に、各発行元は独自の一意の識別子を使用します。
//<my namespace>.servicebus.windows.net/<event hub name>/publishers/<my publisher name>
前もって発行元名を作成しておく必要はありませんが、独立した発行元 ID を保証するために、発行元名はイベントを発行するときに使用される SAS トークンと一致する必要があります。 発行元ポリシーを使用する場合は、PartitionKey の値を発行元の名前に設定する必要があります。 適切に機能するために、これらの値が一致する必要があります。
キャプチャ
Event Hubs Capture を使用すると、Event Hubs のストリーミング データを自動的にキャプチャし、BLOB ストレージ アカウントまたは Azure Data Lake Storage アカウントのいずれかを選択して保存できます。 Azure portal からキャプチャを有効にし、キャプチャを実行する最小サイズと時間枠を指定できます。 Event Hubs Capture を使用して、独自の Azure Blob Storage アカウントとコンテナー、または Azure Data Lake Storage アカウントを指定し、そのいずれかに、キャプチャされたデータを格納します。 キャプチャされたデータは、Apache Avro 形式で書き込まれます。
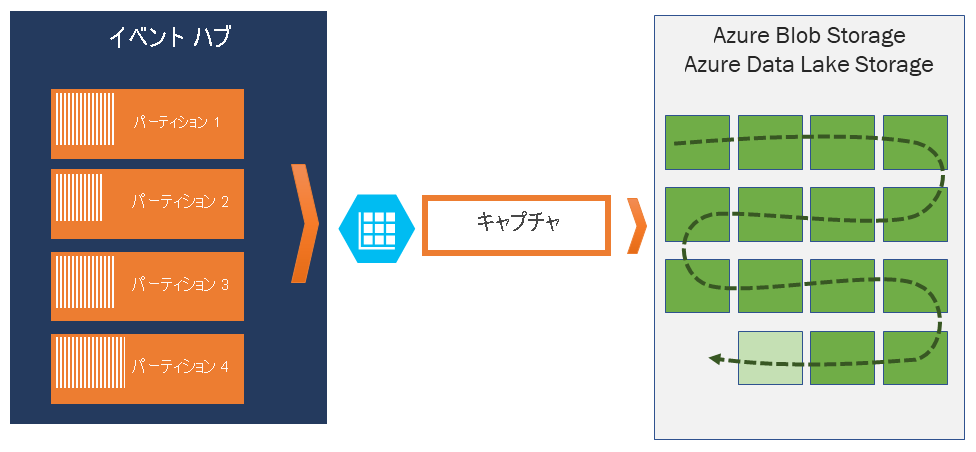
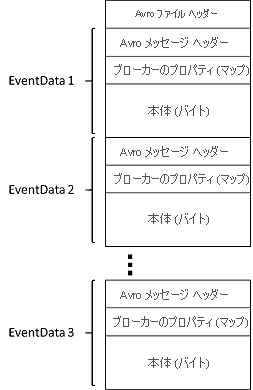
Event Hubs Capture によって生成されたファイルには、次の Avro スキーマがあります。
注
Azure portal でコード エディターを使用しない場合は、Event Hubs のストリーミング データを Parquet 形式のAzure Data Lake Storage Gen2 アカウントでキャプチャできます。 詳細については、「方法: Parquet 形式で Event Hubs からデータをキャプチャする」と「チュートリアル: Parquet 形式で Event Hubs データをキャプチャし、Azure Synapse Analytics を使用して分析する」を参照してください。
SAS トークン
Event Hubs は、名前空間とイベント ハブのレベルで利用可能な Shared Access Signature を使用します。 SAS トークンは、SAS キーから生成されるものであり、特定の形式でエンコードされた URL の SHA ハッシュです。 Event Hubs では、キー (ポリシー) の名前とトークンを使用してハッシュを再生成し、送信者を認証することができます。 通常、イベント発行元の SAS トークンは特定のイベント ハブへの送信特権のみを付加して作成されます。 この SAS トークン URL のメカニズムは、発行元ポリシーに導入された発行元識別のための基盤です。 SAS を使用する方法の詳細については、「Service Bus による Shared Access Signature 認証」を参照してください。
イベント コンシューマー
イベント ハブからイベント データを読み取るエンティティは、いずれも "イベント コンシューマー" です。 コンシューマーまたは受信者は AMQP または Apache Kafka を使用して、イベント ハブからイベントを受信します。 Event Hubs は、コンシューマーがイベントを受信できるプル モデルのみをサポートします。 イベント ハンドラーを使用してイベント ハブからのイベントを処理する場合でも、イベント プロセッサは内部的にプル モデルを使用してイベント ハブからイベントを受信します。
コンシューマー グループ
Event Hubs の発行/サブスクライブのメカニズムは、"コンシューマー グループ" によって有効になります。 コンシューマー グループは、イベント ハブまたは Kafka トピックからデータを読み取るコンシューマーの論理グループです。 こうすることで、複数の使用アプリケーションが、イベント ハブ内の同じストリーミング データを、独自のペースで独自のオフセットによって別々に読み取ることができます。 これにより、各パーティション内のメッセージの順序を維持しながら、メッセージの使用を並列化し、複数のコンシューマー間でワークロードを分散できます。
コンシューマー グループ内のパーティションには、アクティブなレシーバーを 1 つだけ配置することをお勧めします。 ただし、一部のシナリオでは、パーティションごとに最大 5 つのコンシューマーまたはレシーバーを使用できます。この場合、すべてのレシーバーがパーティションのすべてのイベントを取得します。 同じパーティションに複数のリーダーがある場合、重複したイベントを処理します。 お使いのコード内でこの動作を処理する必要があり、相応の作業量が生じます。 ただし、これは一部のシナリオで有効な手法です。
ストリーム処理アーキテクチャにおいて、各ダウンストリーム アプリケーションはコンシューマー グループに相当します。 (パーティションからさらに) 長期的なストレージにイベント データを書き込む場合、そのストレージ ライター アプリケーションはコンシューマー グループとなります。 複雑なイベント処理は、別の異なるコンシューマー グループで実行できます。 パーティションにはコンシューマー グループを介してのみアクセスできます。 イベント ハブには必ず、既定のコンシューマー グループが存在します。対応する価格レベルに応じたコンシューマー グループの最大数まで作成できます。
Azure SDK によって提供される一部のクライアントはインテリジェントなコンシューマー エージェントです。これは、各パーティションに 1 つのリーダーがあり、イベント ハブのすべてのパーティションが読み取られていることを確認するための詳細を自動的に管理します。 これにより、コードではイベント ハブから読み取られるイベントの処理に注力できるため、パーティションの詳細の多くを無視できます。 詳細については、「パーティションに接続する」を参照してください。
コンシューマー グループ URI 表記の例を次に示します。
//<my namespace>.servicebus.windows.net/<event hub name>/<Consumer Group #1>
//<my namespace>.servicebus.windows.net/<event hub name>/<Consumer Group #2>
次の図は、Event Hubs ストリーム処理のアーキテクチャを示しています。
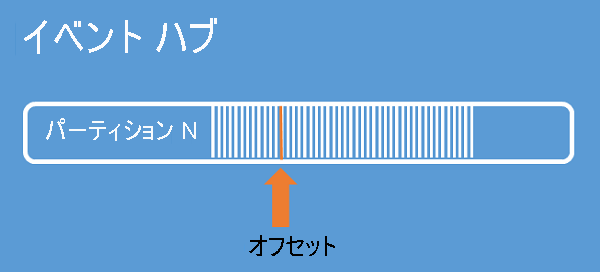
ストリームのオフセット
"オフセット" は、パーティション内のイベントの位置です。 オフセットは、クライアント側のカーソルと考えることができます。 オフセットはイベントのバイト位置です。 このオフセットにより、イベント コンシューマー (リーダー) は、イベント ストリーム内でのイベント読み取りの開始点を指定することができます。 オフセットは、タイムスタンプとして、またはオフセット値として指定することができます。 Event Hubs サービスの外部で独自のオフセット値を格納する場合は、コンシューマーの責任で行います。 パーティション内では、各イベントにオフセットが含まれます。
チェックポイント機能
"チェックポイント処理" とは、リーダーがパーティションにおけるイベント シーケンス内の位置をマークまたはコミットするために使用する処理です。 チェックポイント処理はコンシューマーの責任で行います。この処理はコンシューマー グループ内でパーティションごとに発生します。 つまり、コンシューマー グループごとに、各パーティション リーダーは、イベント ストリーム内でのその現在の位置を追跡する必要があり、データ ストリームが完了したと見なしたときにサービスに通知することができます。
リーダーがパーティションから切断し、その後再び接続すると、該当するコンシューマー グループ内の該当するパーティションの最後のリーダーによって最後に送信されたチェックポイントから読み取りが開始されます。 リーダーは接続の際に、このオフセットをイベント ハブに渡して、読み取りを開始する場所を指定します。 このように、チェックポイント処理を使用することで、ダウンストリーム アプリケーションごとにイベントに "完了" のマークを付けると共に、異なるコンピューター上で実行中のリーダー間でフェールオーバーが発生した場合に回復性をもたらすことができます。 このチェックポイント処理で、より小さなオフセットを指定すると、古いデータに戻ることができます。 このメカニズムにより、チェックポイント処理ではフェールオーバーの回復性とイベント ストリームの再生の両方を実現できます。
重要
オフセットは、Event Hubs サービスによって提供されます。 イベントが処理されるときにチェックポイント処理を行うのはコンシューマーの責任です。
チェックポイント ストアとして Azure Blob Storage を使用する場合は、次の推奨事項に従います。
- コンシューマー グループごとに個別のコンテナーを使用します。 同じストレージ アカウントを使用できますが、各グループごとに 1 つのコンテナーを使用します。
- ストレージ アカウントを他の目的で使用しないでください。
- コンテナーを他の目的で使用しないでください。
- デプロイされたアプリケーションと同じリージョンにストレージ アカウントを作成します。 アプリケーションがオンプレミスの場合は、可能な中で最も近いリージョンを選択することを試みてください。
Azure portal の [ストレージ アカウント] ページの [Blob service] セクションで、次の設定が無効になっていることを確認してください。
- 階層型名前空間
- BLOB の論理的な削除
- バージョン管理
ログの圧縮
Azure Event Hubs では、特定のイベント キーの最新のイベントを保持するイベント ログの圧縮がサポートされています。 圧縮されるイベント ハブ/Kafka トピックを使用すると、粒度が粗い時間ベースの保持を使用せずに、キー ベースの保持を使用できます。
ログ圧縮の詳細については、ログ圧縮に関する記事を参照してください。
一般的なコンシューマー タスク
すべての Event Hubs コンシューマーは、AMQP 1.0 セッション (状態に対応する双方向の通信チャネル) を介して接続します。 各パーティションには、パーティションによって分離されたイベントの転送を容易にする AMQP 1.0 セッションがあります。
パーティションに接続する
パーティションに接続する場合は、特定のパーティションへのリーダーの接続を調整するためにリース メカニズムを使用するのが一般的です。 このため、コンシューマー グループ内のどのパーティションもアクティブなリーダーが 1 つだけである可能性があります。 チェックポイント処理、リース、およびリーダーの管理は、インテリジェントなコンシューマー エージェントとして機能する Event Hubs SDK 内のクライアントを使用して簡略化されます。 以下のとおりです:
- .NET 用 EventProcessorClient
- Java 用 EventProcessorClient
- Python 用 EventHubConsumerClient
- JavaScript/TypeScript 用 EventHubConsumerClient
イベントを読み取る
特定のパーティションに対して AMQP 1.0 のセッションおよびリンクが開かれると、Event Hubs サービスによってイベントが AMQP 1.0 クライアントに配信されます。 この配信メカニズムでは、HTTP GET などのプル ベースのメカニズムよりも高いスループットおよび短い遅延時間を実現します。 イベントがクライアントに送信されるとき、イベント データの各インスタンスには、イベント シーケンスでのチェックポイント処理を容易にするために使用されるオフセットやシーケンス番号などの重要なメタデータが含まれます。
イベント データ:
- オフセット
- シーケンス番号
- 体
- ユーザー プロパティ
- システム プロパティ
オフセットを管理するのはユーザーの責任になります。
アプリケーション グループ
アプリケーション グループは、セキュリティ コンテキスト (共有アクセス ポリシーや Microsoft Entra アプリケーション ID) などの一意の識別条件を共有する Event Hubs 名前空間に接続するクライアント アプリケーションのコレクションです。
Azure Event Hubs を使用すると、特定のアプリケーション グループの調整ポリシーなどのリソース アクセス ポリシーを定義し、クライアント アプリケーションと Event Hubs の間でイベント ストリーミング (公開または使用) を制御できます。
詳細については、アプリケーション グループを使用したクライアント アプリケーションのリソース ガバナンスに関するページを参照してください。
Apache Kafka のサポート
Apache Kafka クライアント (バージョン >=1.0) のプロトコル サポートにより、既存の Kafka アプリケーションで、Event Hubs を使用できるようにするエンドポイントが提供されます。 既存の Kafka アプリケーションのほとんどは、Kafka クラスターのブートストラップ サーバーではなく、名前空間を指すように再構成できます。
コスト、運用の作業量、信頼性の観点から見ると、Azure Event Hubs は、独自の Kafka および Zookeeper クラスターをデプロイして運用したり、Azure にネイティブではないサービスとしての Kafka を提供したりすることに代わる優れた手段です。
Apache Kafka ブローカーと同じコア機能を利用できるだけでなく、Azure Event Hubs の機能にアクセスすることもできます。これには、Event Hubs Capture 経由の自動のバッチ処理とアーカイブ、自動のスケーリングと分散、ディザスター リカバリー、コストに依存しない可用性ゾーンのサポート、柔軟で安全なネットワーク統合、ファイアウォールに適した WebSocket 経由の AMQP プロトコルを含むマルチプロトコル サポートなどがあります。
プロトコル
プロデューサーまたは送信者は、Advanced Messaging Queuing Protocol (AMQP)、Kafka、または HTTPS プロトコルを使用して、イベント ハブにイベントを送信できます。
コンシューマーまたは受信者は AMQP または Kafka を使用して、イベント ハブからイベントを受信します。 Event Hubs は、コンシューマーがイベントを受信できるプル モデルのみをサポートします。 イベント ハンドラーを使用してイベント ハブからのイベントを処理する場合でも、イベント プロセッサは内部的にプル モデルを使用してイベント ハブからイベントを受信します。
AMQP
AMQP 1.0 プロトコルを使用して、Azure Event Hubs との間でイベントを送受信できます。 AMQP により、イベントの送信と受信の両方に、信頼性が高く、パフォーマンスが高く、セキュリティで保護された通信を実現できます。 これは、ハイパフォーマンスのリアルタイム ストリーミングに使用できます。また、ほとんどの Azure Event Hubs SDK でサポートされています。
HTTPS/REST API
Event Hubs にイベントを送信できるのは、HTTP POST 要求を使用した場合のみです。 Event Hubs は、HTTPS 経由でのイベントの受信をサポートしていません。 これは、直接 TCP 接続を利用できない軽量クライアントに適しています。
Apache Kafka
Azure Event Hubs には、Kafka プロデューサーとコンシューマーをサポートする Kafka エンドポイントが組み込まれています。 Kafka を使用して構築されたアプリケーションは、コードを変更することなく、Kafka プロトコル (バージョン 1.0 以降) を使用して Event Hubs との間でイベントを送受信できます。
Azure SDK を使用することで、基礎の通信プロトコルを抽象化し、C#、Java、Python、JavaScript などの言語を使用して簡単に Event Hubs からイベントを送受信できます。
次のステップ
Event Hubs の詳細については、次のリンクを参照してください。
- Event Hubs の使用