多くの高度なソリューションでは、複数の場所で利用するために、同じイベント ストリームを使用できるようにする必要があります。または、複数の場所でイベント ストリームを収集してから、利用のための特定の場所に統合する必要があります。 多くの場合、1 つのリージョンやソリューションの中でも、イベント ストリームのエンリッチや削減をしたり、イベント形式の変換を行ったりする必要もあります。
実際には、ソリューションにおいて、多くの場合異なるリージョンや Event Hubs 名前空間内にある複数の Event Hubs を保持してから、それらの間でイベントをレプリケートすることになります。 Azure Service Bus、Azure IoT Hub、Apache Kafka などのソースとターゲットを使用してイベントを交換することもできます。
異なるリージョン内にアクティブな Event Hubs を複数保持しても、クライアントはその内容のマージ中にそれらを選択して切り替えることができます。このようにすると、リージョンの可用性に関する問題に対して、システム全体の回復性が高まります。
"フェデレーション" に関するこの章では、フェデレーション パターンと、サーバーレスの Azure Stream Analytics または Azure Functions ランタイムを使用して、これらのパターンを実現する方法について説明します。その際、イベント フロー パスに独自の変換やエンリッチメント コードを直接配置するオプションが用意されています。
フェデレーション パターン
異なる Event Hubs 間やその他のソースおよびターゲット間でイベントを移動しようとする理由は、多数考えられます。このセクションでは、最も重要なパターンを列挙し、それぞれのパターンについて、より詳しいガイダンスへのリンクも示します。
- リージョンの可用性イベントからの回復性
- 待機時間の最適化
- 検証、削減、エンリッチメント
- 分析サービスとの統合
- イベント ストリームの統合と正規化
- イベント ストリームの分割とルーティング
- ログのプロジェクション
リージョンの可用性イベントからの回復性
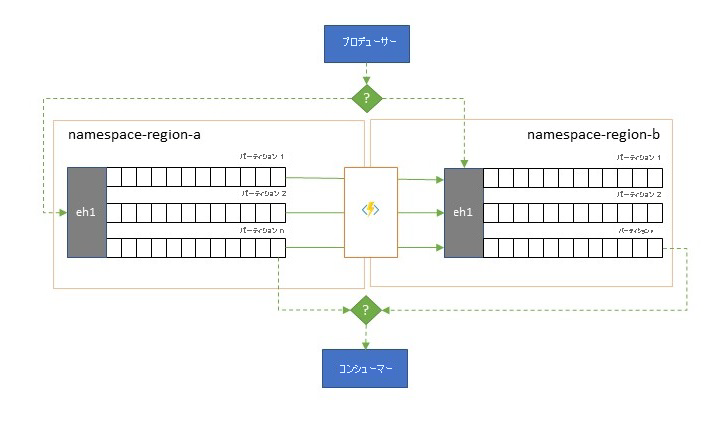
最大の可用性と信頼性は、Event Hubs の運用上の最優先事項ですが、それでもなお、ネットワークや名前解決の問題のため、または Event Hubs が実際に、一時的に応答不能になったりエラーを返したりするため、プロデューサーやコンシューマーが、割り当てられている "プライマリ" Event Hubs と通信できなくなる状況が多数あります。
そうした状況は、ディザスター リカバリーの状況で行う場合があるように、リージョンのデプロイ全体を破棄する必要があるような "壊滅的" なものではありませんが、一部のアプリケーションのビジネス シナリオが、多くて数分、または数秒さえ続かない可用性イベントによって既に影響を受けている可能性があります。
そのようなシナリオに対処するための基本パターンが 2 つあります。
- レプリケーション パターンは、プライマリ Event Hubs の内容を、セカンダリ Event Hubs にレプリケートすることに関するものです。プライマリ Event Hubs は、一般に、イベントの生成と使用の両方のためにアプリケーションによって使用され、セカンダリは、プライマリ Event Hubs が使用できなくなった場合のフォールバック オプションとして機能します。 レプリケーションは、プライマリからセカンダリへの一方向であり、プロデューサーとコンシューマーの両方の、使用できないプライマリからセカンダリへの切り替えによって、古いプライマリは、新しいイベントを受信しなくなるため最新ではなくなります。 したがって、純粋なレプリケーションは、一方向のフェールオーバー シナリオにのみ適しています。 フェール オーバーが実行されると、古いプライマリは破棄され、異なるターゲット リージョンに新しいセカンダリ Event Hubs を作成する必要があります。
- マージ パターンでは、2 つ以上の Event Hubs の内容の継続的マージが実行されて、レプリケーション パターンが拡張されます。 スキームに含まれるいずれかの Event Hubs 内に当初生成された各イベントは、その他の Event Hubs にレプリケートされます。 イベントは、レプリケートされるときに、その後のレプリケーション ターゲットのレプリケーション プロセスでは無視されるように注釈が付けられます。 マージ パターンを使用すると、最終的に一貫性のある形で同じイベント セットが含まれる Event Hubs が 2 つ以上ある結果となります。
どちらの場合も、Event Hubs の内容はまったく同じではありません。 任意の 1 つのプロデューサーからのもので、同じパーティション キーでグループ化されたイベントは、当初送信されたのと同じ相対順序で表示されますが、イベントの絶対順序は異なっている場合があります。 これが特に当てはまるのは、ソースとターゲットの Event Hubs のパーティション数が異なるシナリオです。このシナリオは、ここで説明するいくつかの拡張パターンに適しています。 スプリッターまたはルーターでは、数百のパーティションを持つずっと大きな Event Hubs のスライスを取得し、少数のパーティションだけを持つ小さな Event Hubs へと送り込む場合があります。これは、限られた処理リソースでサブセットを処理する場合に適しています。 逆に統合では、複数の小さな Event Hubs からのデータを、より多くのパーティションを持つ 1 つの大きな Event Hubs に送り込み、スループットと処理に関する統合されたニーズに対処する場合があります。
イベントを一緒に保持するための条件はパーティション キーであり、元のパーティション ID ではありません。 相対順序に関するその他の考慮事項と、同じ範囲のストリーム オフセットに依存せずに 1 つの Event Hubs から次の Event Hubs へのフェールオーバーを実行する方法については、レプリケーション パターンの説明で取り上げています。
ガイダンス:
待機時間の最適化
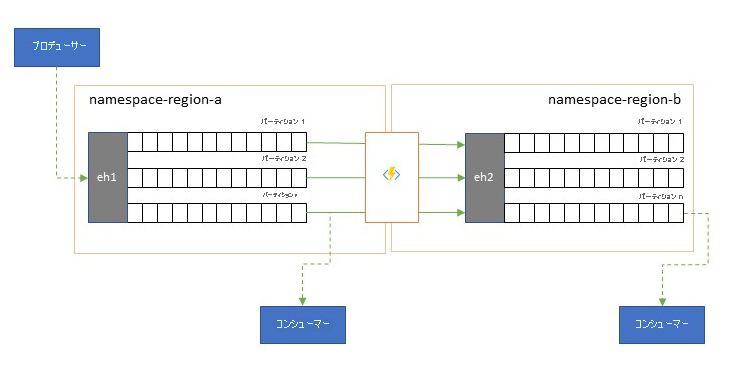
イベント ストリームは、プロデューサーによって 1 回書き込まれますが、イベント コンシューマーで何回でも読み取ることができます。 あるリージョン内のイベント ストリームが複数のコンシューマーによって共有されていて、別のリージョンに置かれている分析処理中に繰り返しアクセスする必要があるシナリオの場合や、同時実行コンシューマーを減らすようなスループットの要求があるシナリオの場合は、分析プロセッサの近くにイベント ストリームのコピーを配置して、ラウンドトリップの待機時間を減らすと有益なことがあります。
複数のリージョンからリモートでイベントを使用するよりもレプリケーションを優先させる必要がある場合の良い例は、特に、それらのリージョンが非常に離れている場合です。たとえば、地理的にほぼ正反対に位置するヨーロッパとオーストラリアでは、ラウンド トリップのためのネットワーク待機時間が、簡単に 250 ミリ秒を超える場合があります。 光回線の速度を上げることはできませんが、データを操作するための待機時間の長いラウンド トリップの数は削減できます。
ガイダンス:
検証、削減、エンリッチメント
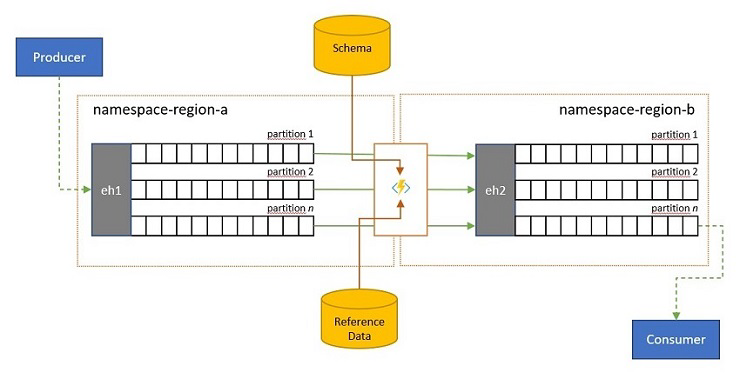
イベント ストリームは、独自ソリューションの外部にいるクライアントによって Event Hubs に送信されることがあります。 そのようなイベント ストリームでは、外部から送信されたイベントが特定のスキーマに準拠しているかどうかをチェックし、準拠していないイベントを破棄する必要がある場合があります。
従量課金制の帯域幅を使用する多くの "モノのインターネット" シナリオの場合のように、クライアントに非常に厳しい帯域幅の制限があるシナリオや、イベントが最初はパケット サイズに制限がある非 IP ネットワークを介して送信されるシナリオでは、ダウンストリームのイベント プロセッサで使用できるように、参照データを使用してイベントをエンリッチすることが必要な場合があります。
その他の場合には、特にストリームが統合されるのであれば、一部の詳細を省略して、イベント データの複雑さや純然たるサイズを減らすことが必要になる可能性があります。
これらのどの操作も、レプリケーション、統合、またはマージのフローの一部として発生することがあります。
ガイダンス:
分析サービスとの統合
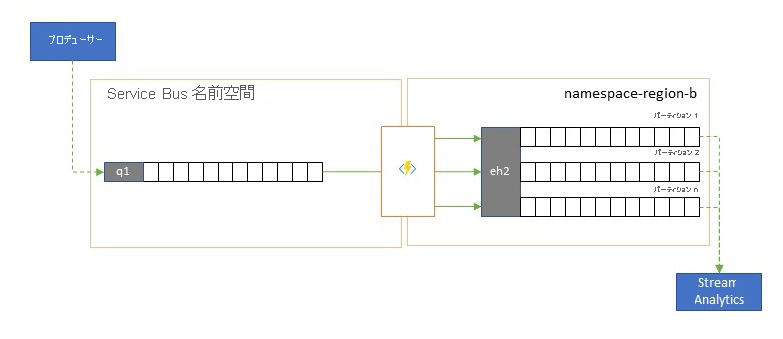
Azure Stream Analytics や Azure Synapse など、いくつかの Azure のクラウド ネイティブ分析サービスは、Azure Event Hubs から提供されるストリーミングデータや、事前にバッチ処理されるデータで最適に機能します。また、Azure Event Hubs を使用すると、Apache Samza、Apache Flink、Apache Spark、Apache Storm などのオープンソースの分析パッケージと統合することもできます。
お使いのソリューションで主に Service Bus または Event Grid が使用されている場合、そのような分析システムから、また、Event Hubs に送り込む場合は Event Hubs キャプチャでのアーカイブのために、これらのイベントを簡単にアクセス可能にすることができます。 Event Grid では、Event Hub 統合を使用して、それをネイティブに行うことができます。Service Bus については、Service Bus のレプリケーション ガイダンスに従ってください。
Azure Stream Analytics は、Event Hubs と直接統合されます。
ガイダンス:
イベント ストリームの統合と正規化
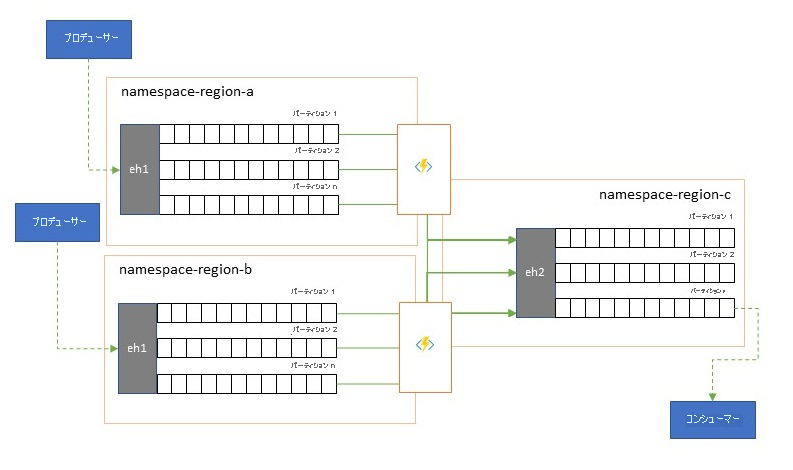
グローバルなソリューションは、多くの場合、独自の分析機能を含め、主に独立したリージョンのフットプリントで構成されますが、リージョンを超えたグローバルな分析観点からは、統合された分析観点が必要になります。それが、各リージョンのフットプリントでローカルの分析観点のために評価されるのと同じイベント ストリームを、一元的に統合する理由です。
正規化は、統合シナリオの 1 つの構成であり、2 つ以上の受信イベント ストリームで同じ種類のイベントが伝達されますが、それらは構造やエンコードが異なっていて、使用可能にするには、大半のイベントをトランスコードまたは変換する必要があります。
正規化には、エンド ツー エンドで暗号化されたペイロードの解読や、ダウンストリームのコンシューマー対象ユーザーに向けた、異なるキーとアルゴリズムでの再暗号化などの暗号化作業も含まれる場合があります。
ガイダンス:
イベント ストリームの分割とルーティング
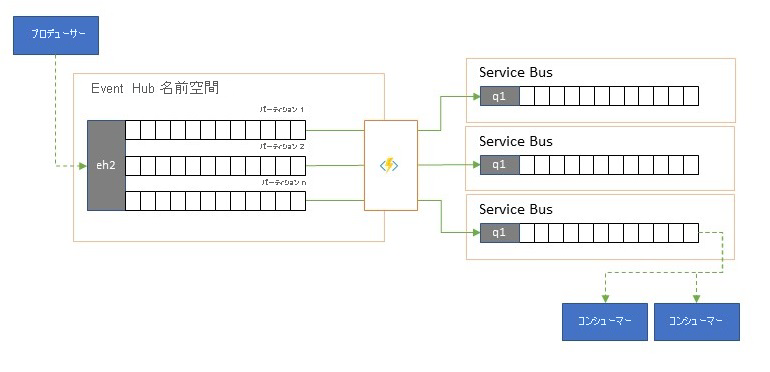
Azure Event Hubs は、ときとして、"発行 - サブスクライブ" スタイルのシナリオで使用されます。このシナリオでは、取り込まれるイベントの着信が急増して、Azure Service Bus や Azure Event Grid の容量を大きく超過します。どちらにも、パブリッシュ - サブスクライブ用のフィルター処理と配布機能がネイティブで備わっていて、このパターンに適しています。
真の "パブリッシュ - サブスクライブ" 機能では、必要なイベントの選択はサブスクライバーに任されていますが、分割パターンには、事前に決定された配布モデルによる、パーティションに対するプロデューサー マップ イベントがあり、指定されたコンシューマーがその後、"自分の" パーティションから排他的にプルします。 Event Hubs によってトラフィック全体がバッファーリングされると、その後、元のスループット量の一部を表す特定パーティションの内容が、信頼性の高いトランザクションの競合コンシューマーの消費のためにキューにレプリケートされることがあります。
Event Hubs が主に 1 つのリージョン内のアプリケーション内部でイベントを移動するために使用される多くのシナリオでは、選ばれたイベント (単に単一パーティションからのものなど) を、他の場所でも使用できるようにする必要がある場合があります。 このシナリオは分割シナリオに似ていますが、スケーラブルなルーターを使用する場合があります。このルーターでは、Event Hubs に到着したすべてのメッセージを考慮に入れ、その先へのルーティングにはごくわずかなメッセージを選択して、イベントのメタデータや内容によってルーティング ターゲットを区別することもできます。
ガイダンス:
ログのプロジェクション
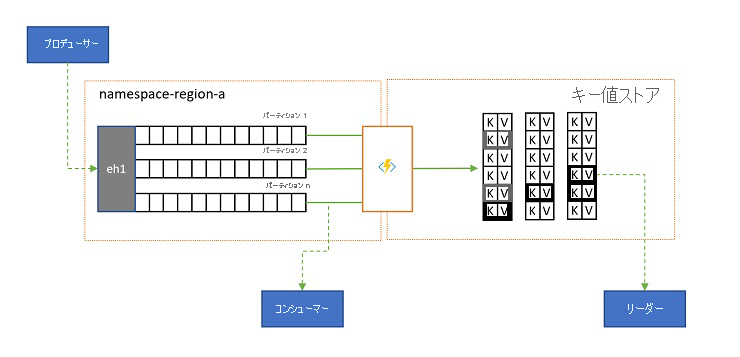
一部のシナリオでは、イベントの任意のサブストリームのために送信され、一般にパーティション キーによって識別される最新の値にアクセスできる必要があります。 Apache Kafka では、これは多くの場合、1 つのトピックに関する "ログ圧縮" を有効にすることで実現されます。これで、一意のキーでラベル付けされた最新のイベント以外はすべて破棄されます。 ログ圧縮アプローチには、3 つの複合した不利な点があります。
- 圧縮を行うには、ログを継続的に再編成する必要があります。これは、追加専用のワークロード用に最適化されたブローカーにとって、過度の負荷がかかる操作です。
- 圧縮は破壊的なもので、同じストリームの圧縮された分析観点と圧縮されていない分析観点を使用することはできません。
- 圧縮されたストリームには、まだ順次アクセス モデルがあります。これは、ログ内で必要な値を見つけるには、最悪の場合ログ全体を読み取る必要があることを意味します。これは一般に、ここで示した正確なパターンを実装する最適化、つまり、ログの内容のデータベースまたはキャッシュへのプロジェクションにつながります。
結局、圧縮されたログはキーと値のストアであるため、その性質上、このようなストアに対しては最悪の実装オプションです。 参照やクエリのためには、適切なキーと値のストアまたはその他の一部のデータベースに対して、ログの永続的なプロジェクションを作成して使用するのがはるかに効率的です。
イベントは不変であり、その順序は常にログに保存されるため、キーと値のストアへのログのプロジェクションはすべて、同じ範囲のイベントについては常に同じになります。これは、更新を続けているプロジェクションでは常に信頼できるビューが提供されるので、いったん構築すれば、ログの内容からプロジェクションを再構築する適切な理由は何もないことを意味します。
ガイダンス:
レプリケーション アプリケーションのテクノロジ
上記のパターンを実装するには、構成して実行するレプリケーション タスクのための、スケーラブルで信頼性の高い実行環境が必要です。 Azure では、このようなタスクに最適なランタイム環境は、ステートレスなタスクです。ステートフルなストリーム レプリケーション タスクの場合は Azure Stream Analytics、ステートレス レプリケーション タスクの場合は Azure Functions を使用します。
Azure Stream Analytics のステートフル レプリケーション アプリケーション
イベント間の関係の考慮、複合イベントの作成、イベントのエンリッチまたはイベントの削減、データ集計の作成、イベント ペイロードの変換を行う必要があるステートフル レプリケーション アプリケーションの場合は、Azure Stream Analytics が最適な実装オプションです。
Azure Stream Analytics では、入力と出力を統合するジョブを作成し、結果を生成するクエリを通して入力からのデータを統合して、その結果を後で出力で使用できるようにします。
クエリは、SQL クエリ言語に基づいていて、これを使用して、一定期間にわたるストリーミング データのフィルター処理、並べ替え、集計、結合を容易に行うことができます。 この SQL 言語は、JavaScript や C# のユーザー定義関数 (UDF) で拡張することもできます。 単純な言語コンストラクトや構成を使用して集計操作を実行するときに、イベントの順序付けのオプションや時間枠の期間を簡単に調整できます。
各ジョブには変換されたデータの 1 つまたは複数の出力が含まれるため、分析した情報に応じてどのような処理を実行するかを制御できます。 たとえば、次のように操作できます。
- Azure Functions、Service Bus Topics、Queues などのサービスにデータを送信して、通信またはダウンストリームのカスタム ワークフローをトリガーする。
- リアルタイムのダッシュボード作成のためにデータを Power BI ダッシュボードに送信する。
- インデックスが付けられた、非常に大きい履歴データのプールに基づいてバッチ分析を実行するか、機械学習モデルをトレーニングするために、データを他の Azure ストレージ サービス (Azure Data Lake、Azure Synapse Analytics など) に格納する。
- データベース (SQL Database、Azure Cosmos DB) にプロジェクション ("具体化されたビュー" とも呼ばれます) を格納する。
Azure Functions のステートレス レプリケーション アプリケーション
ペイロードを考慮せずにイベントを転送したり、イベントの関係 (それらの相対順序を除く) を考慮せずにイベントを処理したりするステートレス レプリケーション タスクの場合は、非常に高い柔軟性が備わっている Azure Functions を使用できます。
Azure Functions には、Azure Event Hubs、Azure IoT Hub、Azure Service Bus、Azure Event Grid、Azure Queue Storage、RabbitMQ 用のカスタム拡張機能、Apache Kafka のために、あらかじめ構築されたスケーラブルなトリガーと出力バインドが用意されています。 ほとんどのトリガーは、文書に記載されたメトリックに基づいて同時実行インスタンスの数をスケーリングし、スループットのニーズに動的に適応されます。
ログのプロジェクションを構築するために、Azure Functions では Azure Cosmos DB と Azure Table Storage の出力バインドをサポートしています。
Azure Functions は Azure マネージド ID のもとで実行することができ、それを使用して、Azure Key Vault 内の厳格にアクセス制御されたストレージに資格情報の構成値を保持できます。
さらに、Azure Functions を使用すると、レプリケーション タスクをすべての Azure メッセージング サービス用の Azure 仮想ネットワークやサービス エンドポイントと直接統合することができ、Azure Monitor と簡単に統合できます。
Azure Functions の従量課金プランでは、レプリケーションに使用できるメッセージがないときに、事前に作成されたトリガーをゼロにスケールダウンすることさえできます。これは、スケールアップし直す準備ができている構成を維持するためのコストが発生しないことを意味します。従量課金プランを使用する場合の主な短所は、この状態からレプリケーション タスクを "ウェイクアップ" するための待機時間が、インフラストラクチャが実行され続けるホスティング プランよりも大幅に長くなることです。
このすべてと対照的に、メッセージングとイベントのための最も一般的なレプリケーション エンジン (Apache Kafka の MirrorMaker など) では、お客様がホスティング環境を提供し、自身でレプリケーション エンジンをスケーリングする必要があります。 それには、セキュリティとネットワークの機能を構成して統合したり、監視データのフローを可能にしたりすることが含まれます。それなのに、カスタム レプリケーション タスクをフローに挿入することはできません。
Azure Functions と Azure Stream Analytics との間の選択
Azure Stream Analytics (ASA) は、イベントのレプリケート中にイベントのペイロードを処理する必要がある場合には常に最適なオプションです。 ASA では、1 つずつイベントをコピーすることも、転送前にイベント ストリームの情報をまとめる集計を作成することもできます。 このようなデータをストリームにインポートしなくても、Azure Blob Storage または Azure SQL Database で保持されている補足用の参照データを簡単に利用できます。
ASA を使用すると、ハイパースケール データベース内に、ストリームの具体化された永続的ビューを簡単に作成できます。 これは、Apache Kafka や、Kafka Streams の揮発性クライアント側テーブル プロジェクションの扱いにくい "ログ圧縮" モデルよりもはるかに優れたアプローチです。
ASA では、ペイロードが CSV 形式、JSON 形式、Apache Avro 形式でエンコードされているイベントを容易に処理できます。また、他のどの形式用のカスタム逆シリアライザーでもプラグインすることができます。
Azure Functions が最適なオプションであるのは、イベント ストリームを "そのまま" コピーし、ペイロードに触れないすべてのレプリケーション タスクの場合、ルーターを実装し、暗号化処理を実行して、ペイロードのエンコードを変更する必要がある場合、データ ストリームの内容を完全に制御する必要がある場合です。
次の手順
この記事では、さまざまなフェデレーション パターンを調べ、Azure でのイベントとメッセージングのレプリケーション ランタイムとしての Azure Functions の役割について説明しました。
次に、 Azure Stream Analytics または Azure Functions でレプリケーター アプリケーションをセットアップする方法と、Event Hubs と他のさまざまなイベントおよびメッセージング システムの間でイベント フローをレプリケートする方法について読むことをお勧めします。