Apache Spark & Hive Tools for Visual Studio Code を使用する方法について説明します。 これらのツールを使用して、Apache Hive バッチ ジョブ、対話型 Hive クエリ、Apache Spark 用の PySpark スクリプトを作成して送信します。 最初に、Visual Studio Code で Spark & Hive Tools をインストールする方法について説明します。 次に、Spark & Hive Tools にジョブを送信する方法について説明します。
Spark & Hive Tools は、Visual Studio Code でサポートされているプラットフォームにインストールできます。 プラットフォームごとに以下の前提条件に注意してください。
前提条件
この記事の手順を完了するには、次の項目が必要です。
- Azure HDInsight クラスター。 クラスターを作成するには、HDInsight での Hadoop の使用に関するページをご覧ください。 または、Apache Livy エンドポイントをサポートする Spark および Hive クラスターを使用します。
- Visual Studio Code。
- Mono。 Mono は Linux と macOS でのみ必要です。
- Visual Studio Code 用の PySpark 対話型環境。
- ローカル ディレクトリ。 この記事では、
C:\HD\HDexampleを使用します。
Spark & Hive Tools をインストールする
前提条件を満たしたら、これらの手順に従って、Spark & Hive Tools for Visual Studio Code をインストールできます。
Visual Studio Code を開きます。
メニュー バーから [View]\(表示\)>[Extensions]\(拡張機能\) に移動します。
検索ボックスに、「Spark & Hive」と入力します。
検索結果から Spark & Hive Tools を選び、[インストール] を選択します。
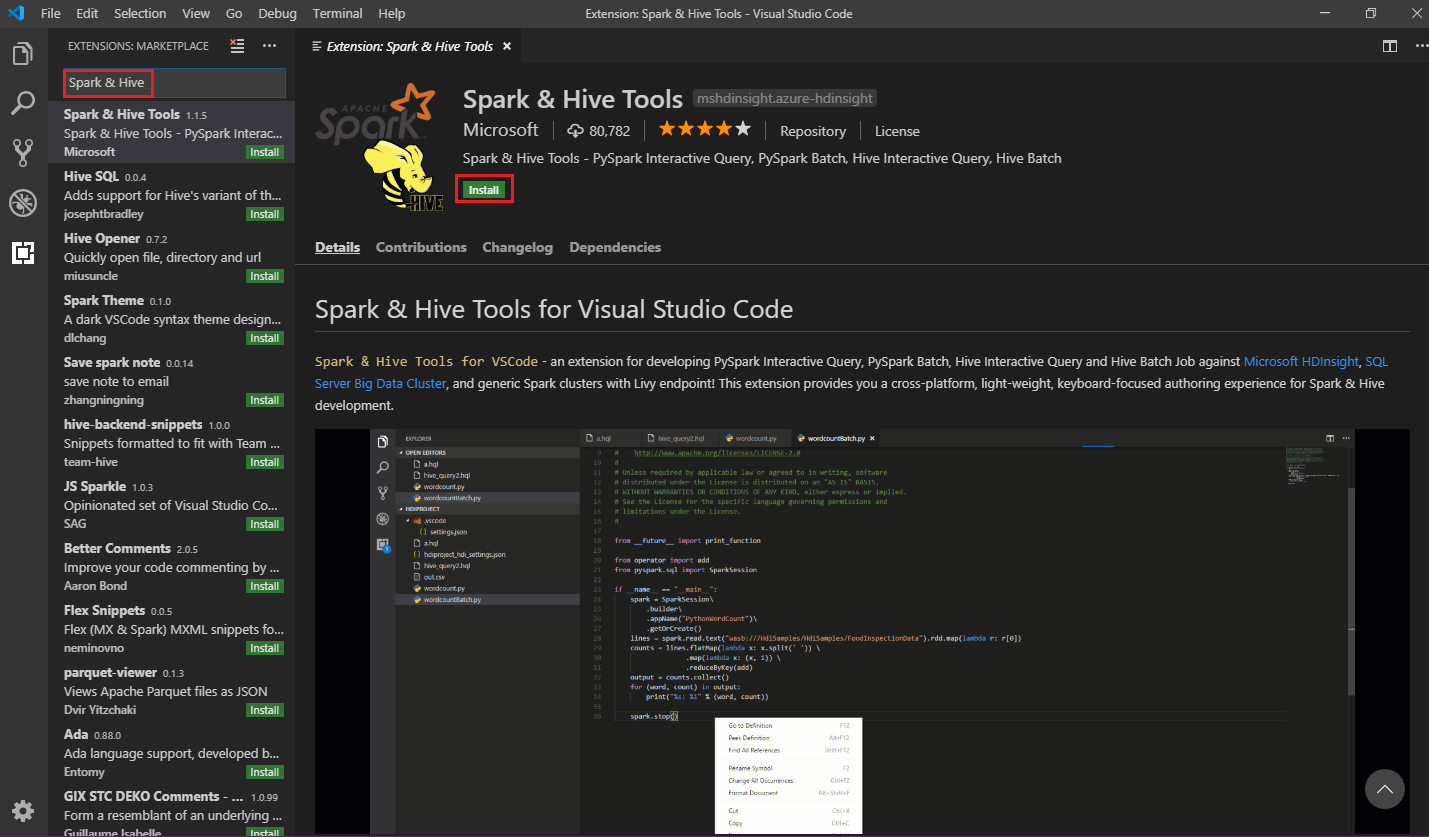
必要に応じて [再読み込み] を選択します。
作業フォルダーを開く
作業フォルダーを開いて Visual Studio Code でファイルを作成するには、これらの手順を実行します。
メニュー バーから、[ファイル]>[フォルダーを開く...]>
C:\HD\HDexampleに移動し、[フォルダーの選択] ボタンを選択します。 左側の [Explorer](エクスプローラー) ビューにフォルダーが表示されます。[エクスプローラー] ビューで
HDexampleフォルダーを選択し、作業フォルダーの横にある [新しいファイル] アイコンを選択します。![Visual Studio Code の [新しいファイル] アイコン。](media/hdinsight-for-vscode/visual-studio-code-new-file.png)
.hql(Hive クエリ) または.py(Spark スクリプト) のいずれかのファイル拡張子を使用して、新しいファイルに名前を付けます。 この例では HelloWorld.hql を使用します。
Azure 環境を設定する
国内のクラウド ユーザーの場合は、まずこれらの手順に従って Azure 環境を設定してから、Azure: Sign In コマンドを使用して Azure にサインインします。
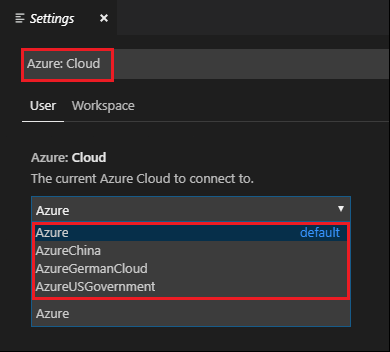
[ファイル]>[ユーザー設定]>[設定] に移動します。
次の文字列を検索します: Azure:クラウド。
一覧から国内のクラウドを選択します。
Azure アカウントに接続する
Visual Studio Code からクラスターにスクリプトを送信する前に、ユーザーは Azure サブスクリプションにサインインするか、HDInsight クラスターをリンクすることができます。 Ambari のユーザー名とパスワードまたは ESP クラスターのドメイン参加済みの資格情報を使用して、HDInsight クラスターに接続します。 Azure に接続するには、これらの手順に従います。
メニュー バーから、[表示]>[コマンド パレット] に移動し、「Azure: Sign In」と入力します。
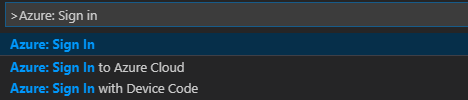
サインインの手順に従って Azure にサインインします。 接続されると、Visual Studio Code ウィンドウの下部にあるステータス バーに Azure アカウント名が表示されます。
クラスターのリンク
リンク: Azure HDInsight
Apache Ambari マネージド ユーザー名を使用して通常のクラスターをリンクするか、またはドメイン ユーザー名 (user1@contoso.com など) を使用して Enterprise Security Pack のセキュリティ保護された Hadoop クラスターをリンクできます。
メニュー バーから、 [表示]>[コマンド パレット...] に移動し、「Spark / Hive:Link a Cluster」と入力します。

リンクされるクラスターの種類として [Azure HDInsight] を選択します。
HDInsight クラスターの URL を入力します。
自分の Ambari ユーザー名を入力します。既定値は「admin」です。
自分の Ambari パスワードを入力します。
クラスターの種類を選択します。
クラスターの表示名を設定します (省略可能)。
[OUTPUT](出力) ビューを確認します。
Note
リンクされたユーザー名とパスワードは、クラスターが Azure サブスクリプションにログインし、かつクラスターにリンクしていた場合に使用されます。
リンク: ジェネリック Livy エンドポイント
メニュー バーから、 [表示]>[コマンド パレット...] に移動し、「Spark / Hive:Link a Cluster」と入力します。
リンクされるクラスターの種類として、 [Generic Livy Endpoint](ジェネリック Livy エンドポイント) を選択します。
ジェネリック Livy エンドポイントを入力します。 例: http://10.172.41.42:18080.
承認の種類として、 [基本] または [なし] を選択します。 [基本] を選択する場合:
自分の Ambari ユーザー名を入力します。既定値は「admin」です。
自分の Ambari パスワードを入力します。
[OUTPUT](出力) ビューを確認します。
クラスターを一覧表示する
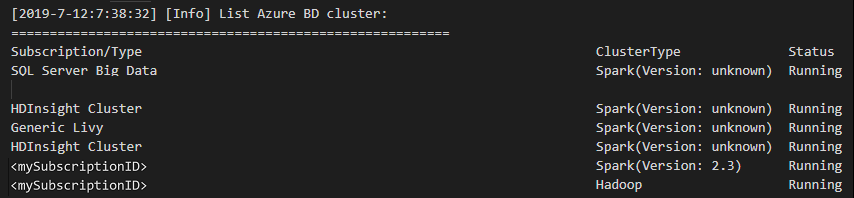
メニュー バーから、 [表示]>[コマンド パレット...] に移動し、「Spark / Hive:List Cluster」と入力します。
目的のサブスクリプションを選択します。
[OUTPUT](出力) ビューを確認します。 このビューには、リンクされたクラスターと、お使いの Azure サブスクリプションのすべてのクラスターが表示されます。
既定のクラスターを設定する
前に説明した
HDexampleフォルダーが閉じている場合、もう一度開きます。前に作成した HelloWorld.hql ファイルを選択します。 それがスクリプト エディターで開かれます。
スクリプト エディターを右クリックして、 [Spark / Hive: Set Default Cluster](Spark / Hive: 既定のクラスターの設定) を選択します。
お使いの Azure アカウントに接続するか、クラスターをリンクします (まだ行っていない場合)。
現在のスクリプト ファイルの既定のクラスターとしてクラスターを選択します。 ツールによって、構成ファイルである .VSCode\settings.json が自動的に更新されます。
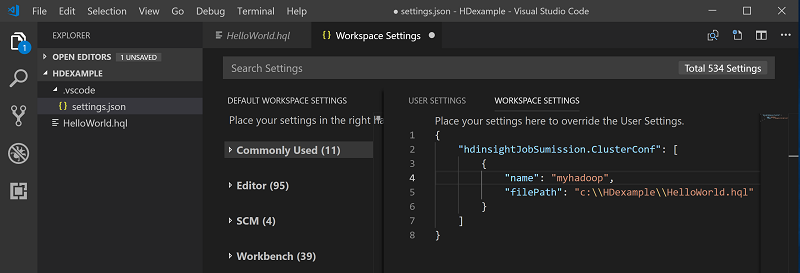
対話型 Hive クエリと Hive バッチ スクリプトを送信する
Spark & Hive Tools for Visual Studio Code を使用すると、対話型 Hive クエリと Hive バッチ スクリプトをクラスターに送信できます。
前に説明した
HDexampleフォルダーが閉じている場合、もう一度開きます。前に作成した HelloWorld.hql ファイルを選択します。 それがスクリプト エディターで開かれます。
次のコードをコピーし、Hive ファイルに貼り付けて保存します。
SELECT * FROM hivesampletable;お使いの Azure アカウントに接続するか、クラスターをリンクします (まだ行っていない場合)。
スクリプト エディターを右クリックし、 [Hive: Interactive] を選択してクエリを送信するか、キーボード ショートカットの Ctrl + Alt + I を使用します。 [Hive:Batch] を選択してスクリプトを送信するか、キーボード ショートカットの Ctrl + Alt + H を使用します。
既定のクラスターを指定していない場合は、クラスターを選択します。 また、このツールでは、コンテキスト メニューを使用して、スクリプト ファイル全体ではなく、コードのブロックを送信することもできます。 しばらくすると、新しいタブにクエリの結果が表示されます。
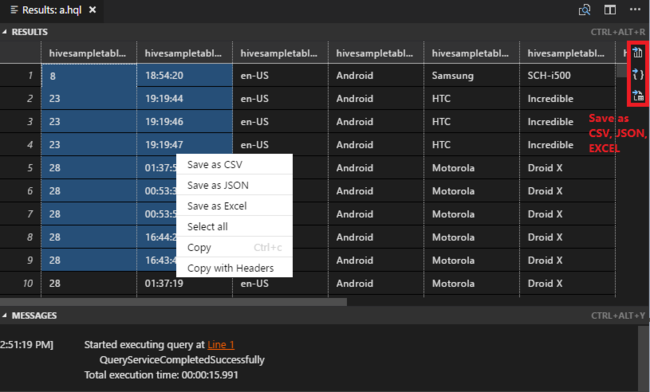
[結果] パネル:結果全体を CSV、JSON、または Excel ファイルとしてローカル パスに保存したり、複数の行だけを選択したりできます。
[メッセージ] パネル:行の番号を選択すると、実行されているスクリプトの最初の行にジャンプします。
対話型の PySpark クエリを送信する
Pyspark interactive の前提条件
ここで、HDInsight 対話型 PySpark クエリには、Jupyter 拡張機能バージョン (ms-jupyter): v2022.1.1001614873 と Python 拡張機能バージョン (ms-python): v2021.12.1559732655、Python 3.6.x、3.7.x が必要であることに注意してください。
ユーザーは、次の方法で PySpark Interactive を実行できます。
PY ファイルで PySpark Interactive コマンドを使用する
PySpark Interactive コマンドを使用してクエリを送信するには、次の手順を実行します。
前に説明した
HDexampleフォルダーが閉じている場合、もう一度開きます。前の手順に従って、新しい HelloWorld.py ファイルを作成します。
次のコードをコピーしてスクリプト ファイルに貼り付けます。
from operator import add from pyspark.sql import SparkSession spark = SparkSession.builder \ .appName('hdisample') \ .getOrCreate() lines = spark.read.text("/HdiSamples/HdiSamples/FoodInspectionData/README").rdd.map(lambda r: r[0]) counters = lines.flatMap(lambda x: x.split(' ')) \ .map(lambda x: (x, 1)) \ .reduceByKey(add) coll = counters.collect() sortedCollection = sorted(coll, key = lambda r: r[1], reverse = True) for i in range(0, 5): print(sortedCollection[i])PySpark/Synapse Pyspark カーネルをインストールするためのプロンプトが、ウィンドウの右下隅に表示されます。 PySpark/Synapse Pyspark のインストールを続行するには [インストール] ボタンをクリックします。この手順をスキップするには、 [スキップ] をクリックします。
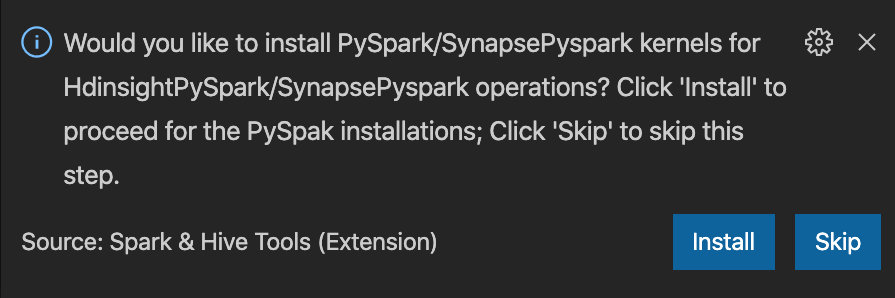
後でインストールする必要がある場合は、 [ファイル]>[基本設定]>[設定] に移動し、 [HDInsight:Pyspark のインストールをスキップする] をオフにします。
![[Pyspark のインストールのスキップを有効にする] オプションを示すスクリーンショット。](media/hdinsight-for-vscode/enable-skip-pyspark-installation.png)
手順 4 でインストールが正常に完了した場合、ウィンドウの右下隅に "PySpark が正常にインストールされました" というメッセージ ボックスが表示されます。 [再読み込み] ボタンをクリックして、ウィンドウを再度読み込みます。
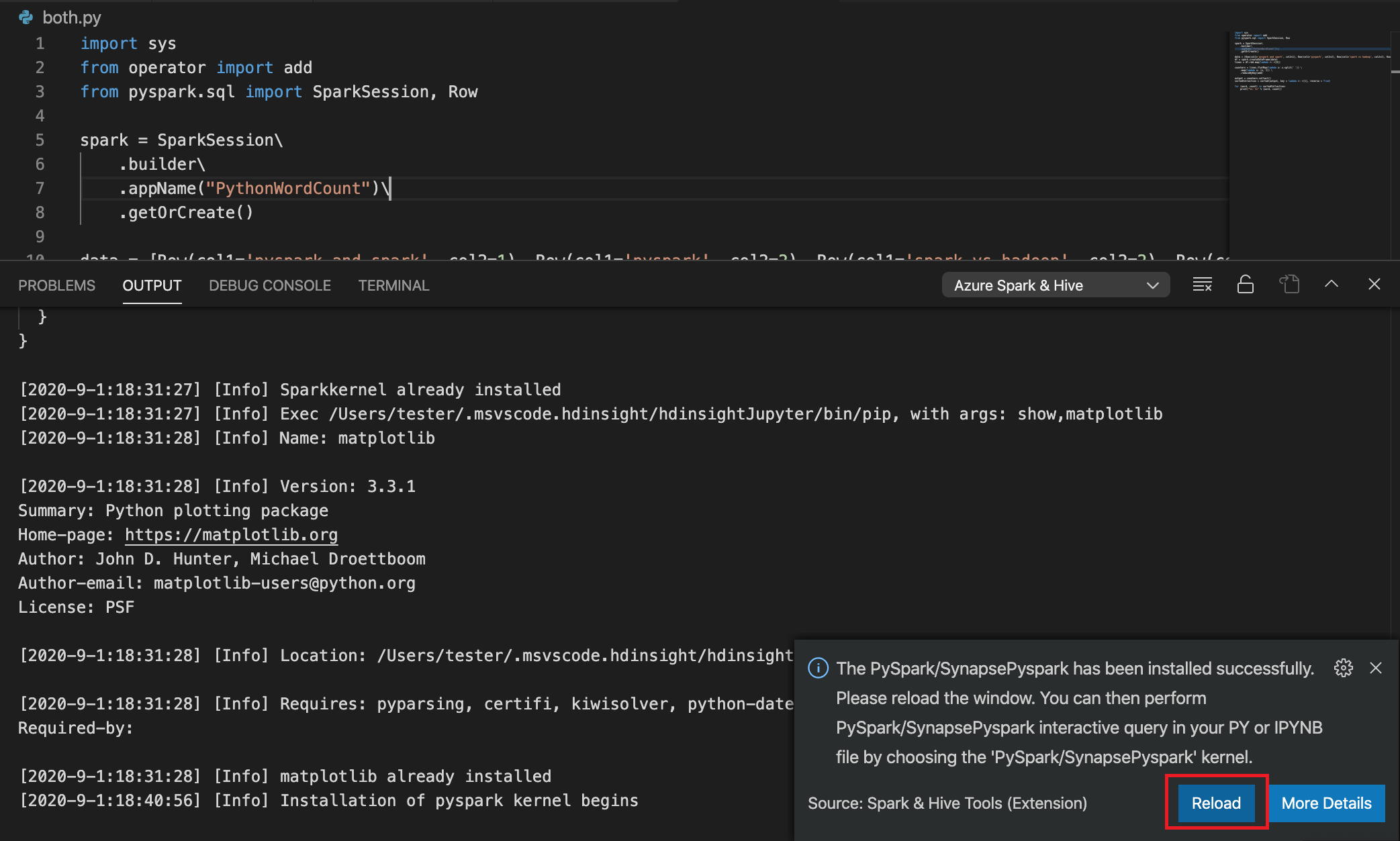
メニュー バーから、[表示]>[コマンド パレット] に移動するか、Shift + Ctrl + P キーボード ショートカットを使用して、「Python: Select Interpreter to start Jupyter Server」と入力します。

下の Python オプションを選択します。

メニュー バーから、[表示]>[コマンド パレット] に移動するか、Shift + Ctrl + P キーボード ショートカットを使用して、「Developer: Reload Window」と入力します。

お使いの Azure アカウントに接続するか、クラスターをリンクします (まだ行っていない場合)。
すべてのコードを選択し、スクリプト エディターを右クリックして、 [Spark: PySpark Interactive / Synapse:Pyspark Interactive] を選択してクエリを送信します。
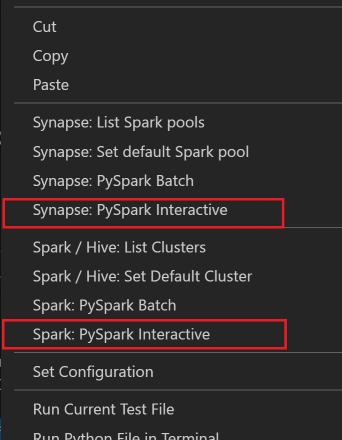
既定のクラスターを指定していない場合は、クラスターを選択します。 しばらくすると、Python Interactive の結果が新しいタブに表示されます。PySpark をクリックすると、カーネルが PySpark / Synapse Pyspark に切り替わり、コードが正常に実行されます。 Synapse Pyspark カーネルに切り替える場合は、Azure portal で自動設定を無効にすることが推奨されます。 そうしないと、クラスターをウェイクアップし、初めて使用するために Synapse カーネルを設定するのに時間がかかることがあります。 このツールでは、コンテキスト メニューを使用して、スクリプト ファイル全体ではなく、コードのブロックも送信できます。
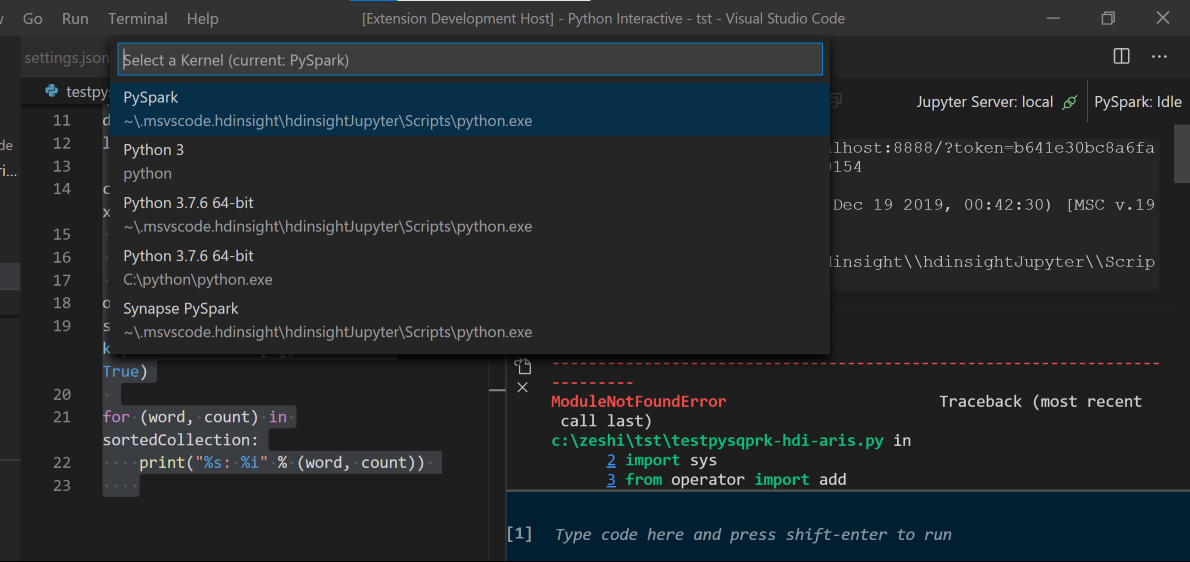
「 %%info」と入力し、Shift + Enter キーを押してジョブ情報を表示します (省略可能)。
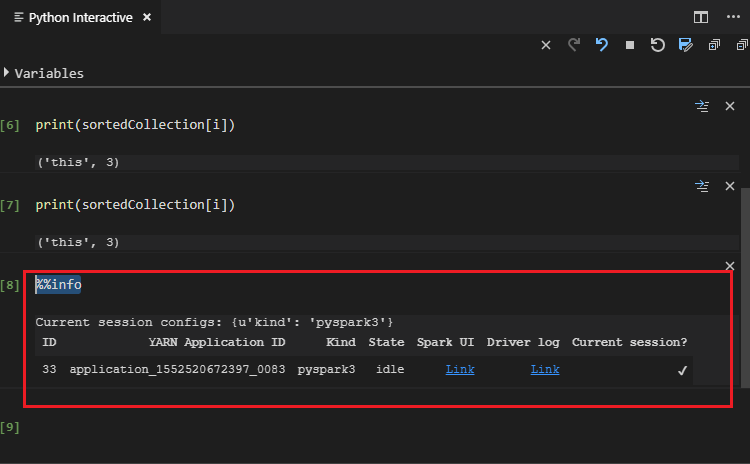
ツールでは Spark SQL クエリもサポートされています。
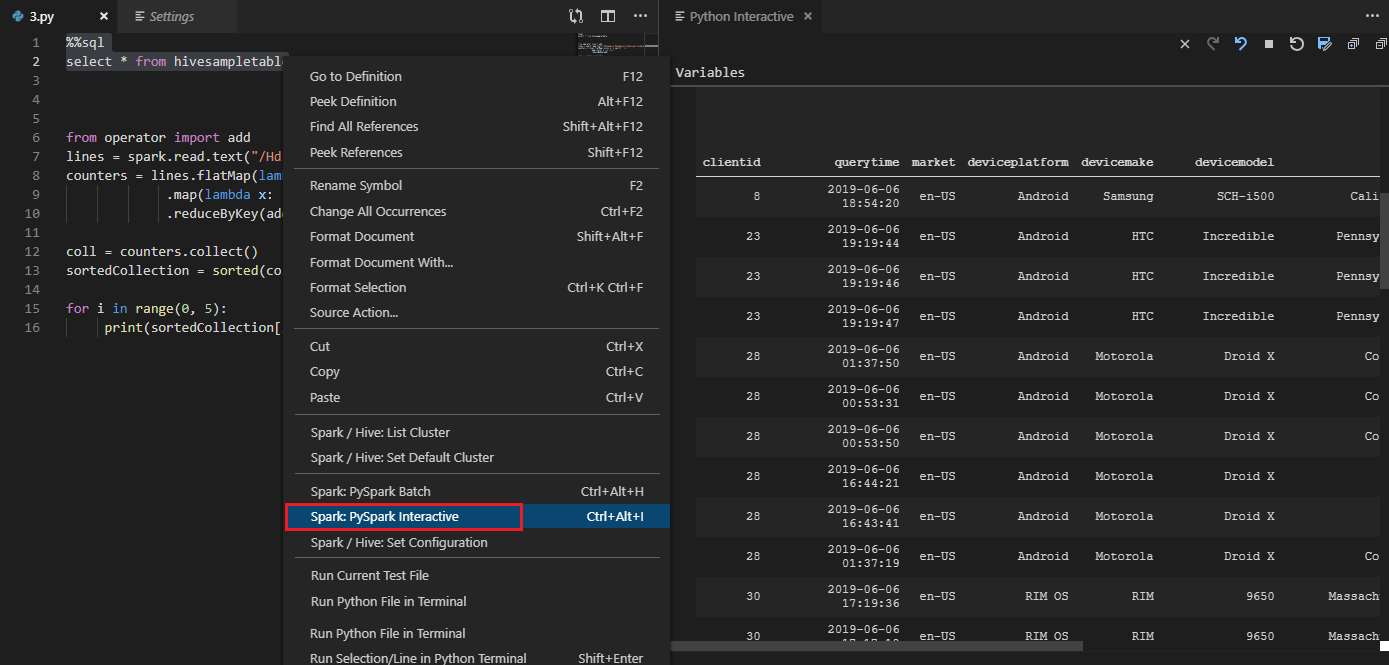
#%% コメントを使用して PY ファイルで対話型クエリを実行する
ノートブックのエクスペリエンスを得るには、PY コードの前に #%% を追加します。
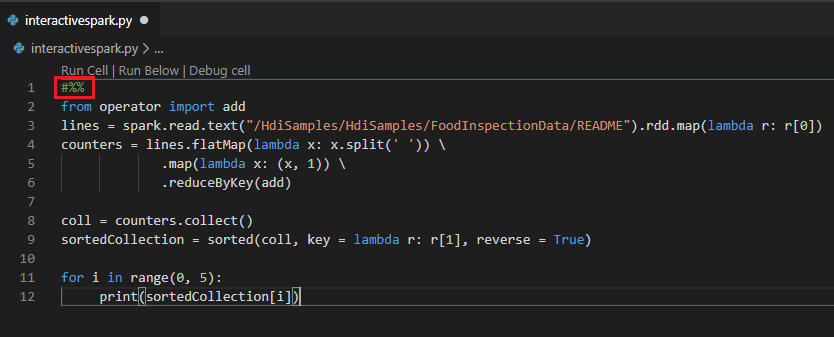
[セルの実行] をクリックします。 しばらくすると、新しいタブに Python Interactive の結果が表示されます。PySpark をクリックしてカーネルを PySpark/Synapse PySpark に切り替えてから、[セルの実行] を再度クリックすると、コードが正常に実行されます。
![[セルの実行] の結果。](media/hdinsight-for-vscode/run-cell-get-results.png)
Python 拡張機能の IPYNB サポートを活用する
コマンド パレットからコマンドを使用するか、ワークスペースで新しい
.ipynbファイルを作成することで、Jupyter Notebook を作成できます。 詳細については、「Visual Studio Code での Jupyter Notebook の使用」を参照してください。[セルの実行] ボタンをクリックし、画面の指示に従って既定の Spark プールを設定します (ノートブックを開く前に毎回既定のクラスターまたはプールを設定することをお勧めします)。その後、ウィンドウを [再読み込み] します。
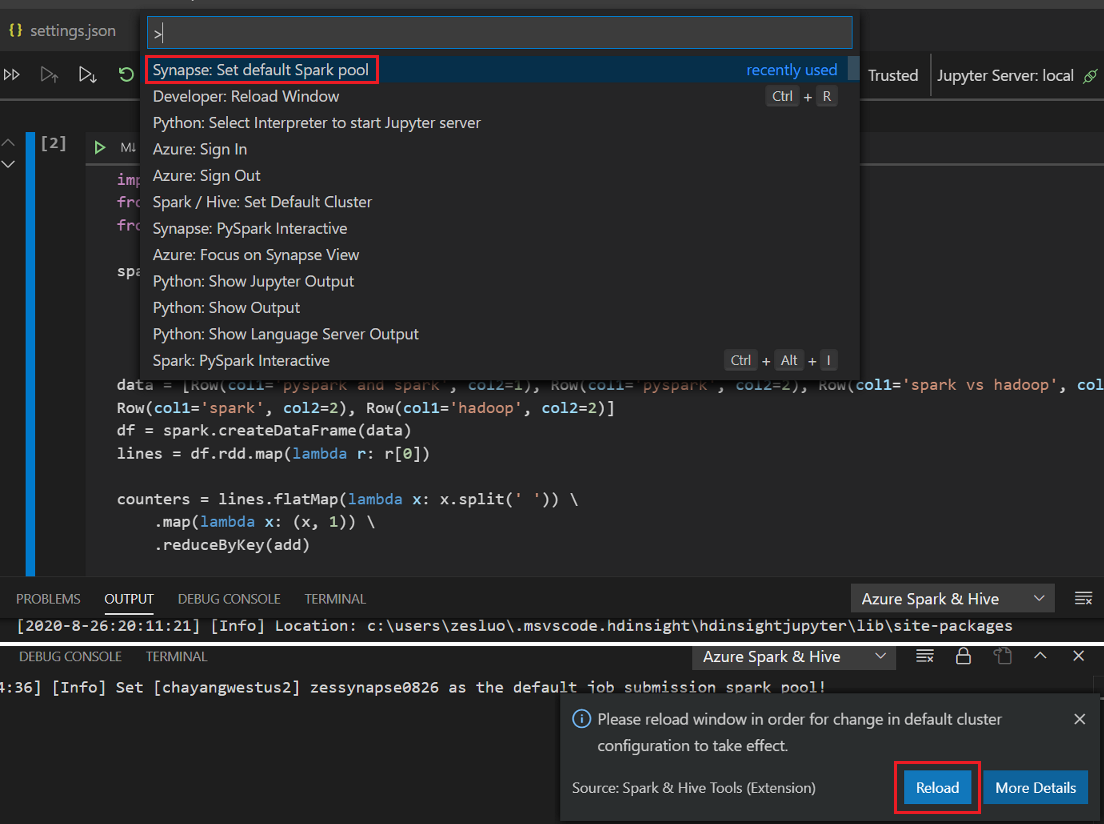
[PySpark] をクリックしてカーネルを PySpark / Synapse Pyspark に切り替え、 [セルの実行] をクリックすると、しばらくしてから結果が表示されます。
![[ipynb の実行] の結果。](media/hdinsight-for-vscode/run-ipynb-file-results.png)
Note
Synapse PySpark のインストール エラーの場合、その依存関係が他のチームによって維持されなくなるため、これも維持されなくなります。 Synapse Pyspark Interactive を使用しようとしている場合は、代わりに Azure Synapse Analytics を使用するように切り替えてください。 これは長期的な変更です。
PySpark バッチ ジョブを送信する
前に説明した
HDexampleフォルダーが閉じている場合、もう一度開きます。前の手順に従って、新しい BatchFile.py ファイルを作成します。
次のコードをコピーしてスクリプト ファイルに貼り付けます。
from __future__ import print_function import sys from operator import add from pyspark.sql import SparkSession if __name__ == "__main__": spark = SparkSession\ .builder\ .appName("PythonWordCount")\ .getOrCreate() lines = spark.read.text('/HdiSamples/HdiSamples/SensorSampleData/hvac/HVAC.csv').rdd.map(lambda r: r[0]) counts = lines.flatMap(lambda x: x.split(' '))\ .map(lambda x: (x, 1))\ .reduceByKey(add) output = counts.collect() for (word, count) in output: print("%s: %i" % (word, count)) spark.stop()お使いの Azure アカウントに接続するか、クラスターをリンクします (まだ行っていない場合)。
スクリプト エディターを右クリックし、[Spark:PySpark Batch]、または [Synapse:PySpark Batch]* を選択します。
PySpark ジョブの送信先となるクラスター/spark プールを選択します。
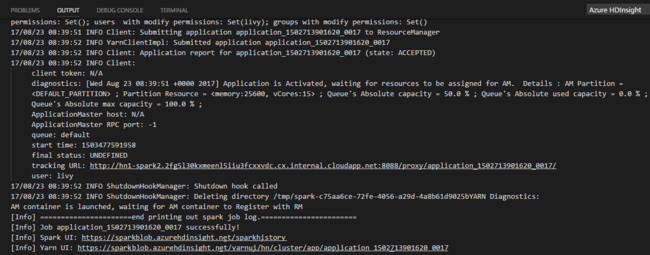
Python ジョブを送信すると、Visual Studio Code の [OUTPUT](出力) ウィンドウに送信ログが表示されます。 Spark UI URL と Yarn UI URL も表示されます。 バッチ ジョブを Apache Spark プールに送信すると、Spark の履歴 UI の URL と Spark ジョブ アプリケーション UI の URL も表示されます。 Web ブラウザーで URL を開いて、ジョブの状態を追跡することができます。
HDInsight Identity Broker (HIB) との統合
HDInsight ESP cluster with ID Broker (HIB) に接続する
HDInsight ESP cluster with ID Broker (HIB) に接続するには、通常の手順に従って Azure サブスクリプションにサインインします。 サインインすると、Azure Explorer にクラスターの一覧が表示されます。 詳細な手順については、「HDInsight クラスターに接続する」を参照してください。
HDInsight ESP cluster with ID Broker (HIB) で Hive/PySpark ジョブを実行する
Hive ジョブを実行するには、通常の手順に従って、HDInsight ESP cluster with ID Broker (HIB) にジョブを送信します。 詳細な手順については、「対話型 Hive クエリと Hive バッチ スクリプトを送信する」を参照してください。
対話型 PySpark ジョブを実行するには、通常の手順に従って、HDInsight ESP cluster with ID Broker (HIB) にジョブを送信します。 「対話型の PySpark クエリを送信する」を参照してください。
PySpark バッチ ジョブを実行するには、通常の手順に従って、HDInsight ESP cluster with ID Broker (HIB) にジョブを送信します。 詳細な手順については、「PySpark バッチ ジョブを送信する」を参照してください。
Apache Livy の構成
Apache Livy の構成がサポートされています。 これは、ワークスペース フォルダーにある .VSCode\settings.json ファイルで構成できます。 現在、Livy の構成では Python スクリプトのみがサポートされています。 詳細については、Livy の README を参照してください。
方法 1
- メニュー バーから [File](ファイル)>[Preferences](基本設定)>[Settings](設定) に移動します。
- [検索設定] ボックスに「HDInsight Job Submission: Livy Conf」と入力します。
- 関連する検索結果に対して [Edit in settings.json](settings.json で編集) を選択します。
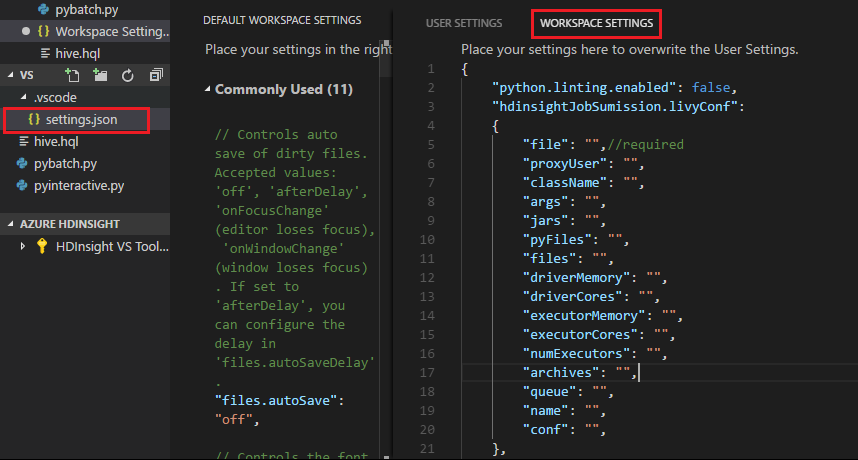
方法 2
ファイルを送信ます。また、.vscode フォルダーが作業フォルダーに自動的に追加されることに注意してください。 Livy の構成は .vscode\settings.json を選択することで確認できます。
プロジェクトの設定:
Note
driverMemory と executorMemory の設定では、値と単位を設定します。 次に例を示します。1 g、1,024 m。
サポートされている Livy の構成:
POST/バッチ
要求本文
name description type file 実行するアプリケーションを含むファイル パス (必須) proxyUser ジョブの実行時に権限を借用するユーザー String className アプリケーション Java/Spark のメイン クラス String args アプリケーションのコマンドライン引数 文字列のリスト jars このセッションで使用される Jar 文字列のリスト pyFiles このセッションで使用される Python ファイル 文字列のリスト files このセッションで使用されるファイル 文字列のリスト driverMemory ドライバー プロセスに使用するメモリの量 String driverCores ドライバー プロセスに使用するコアの数 int executorMemory 実行プログラム プロセスごとに使用するメモリの量 String executorCores 実行プログラムごとに使用するコアの数 int numExecutors このセッションで起動する実行プログラムの数 int archives このセッションで使用するアーカイブ 文字列のリスト queue 送信先の YARN キューの名前 String name このセッションの名前 String conf Spark の構成プロパティ キーのマップ = val 応答本文 作成された Batch オブジェクト。
name description type id セッション ID int appId このセッションのアプリケーション ID String appInfo アプリケーションの詳細情報 キーのマップ = val log ログの行 文字列のリスト state バッチの状態 String 注意
割り当てられた Livy の構成は、スクリプトの送信時に出力ウィンドウに表示されます。
エクスプローラーから Azure HDInsight と統合する
Azure HDInsight のエクスプローラーを通じて直接、クラスター内の Hive テーブルをプレビューできます。
Azure アカウントに接続します (まだ接続していない場合)。
左端の列の Azure アイコンを選択します。
左側のウィンドウから、 [AZURE:HDINSIGHT] を展開します。 利用可能なサブスクリプションとクラスターが一覧表示されます。
クラスターを展開して、Hive メタデータのデータベースとテーブルのスキーマを表示します。
Hive テーブルを右クリックします。 例: hivesampletable。 [Preview](プレビュー) を選択します。
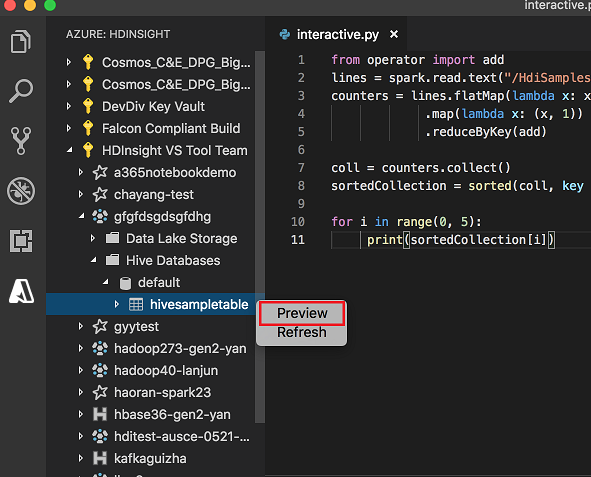
[結果のプレビュー] ウィンドウが開きます。
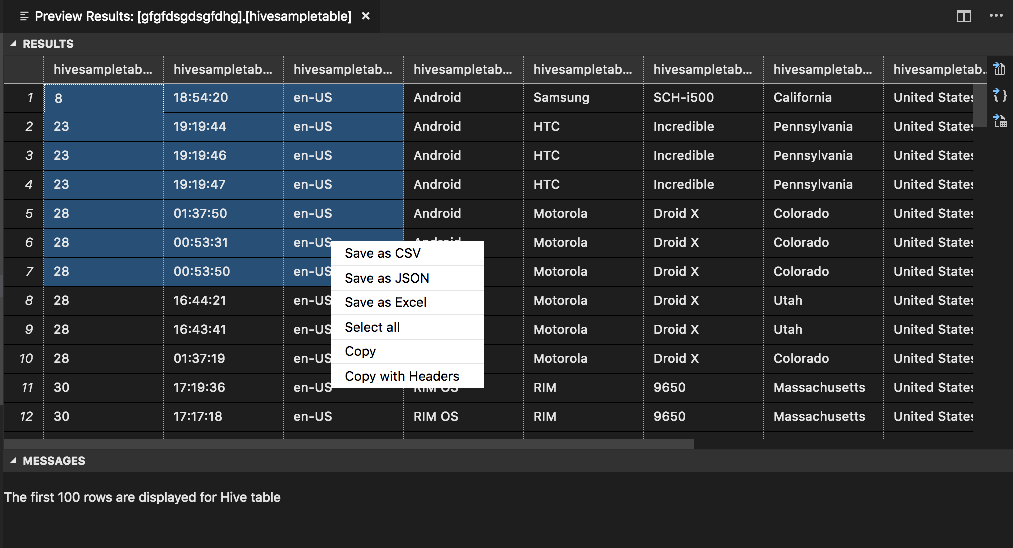
[結果] パネル
結果全体を CSV、JSON、または Excel ファイルとしてローカル パスに保存したり、複数の行だけを選択したりできます。
[メッセージ] パネル
テーブルの行数が 100 行を超えると、次のメッセージが表示されます: "The first 100 rows are displayed for Hive table (Hive テーブルの先頭から 100 行を表示しています)"。
テーブル内の行数が 100 以下の場合は、次のメッセージが表示されます: "60 rows are displayed for Hive table (Hive テーブルの 60 行を表示しています)"。
テーブルの内容がない場合は、次のメッセージが表示されます: "
0 rows are displayed for Hive table."注意
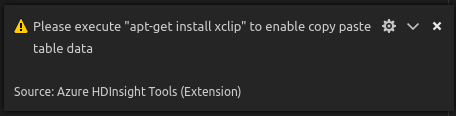
Linux でテーブル データをコピーするには、xclip をインストールします。
追加機能
Spark & Hive for Visual Studio Code では、次の機能もサポートされています。
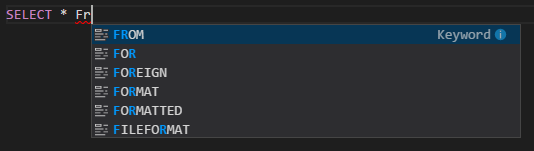
IntelliSense のオートコンプリート。 キーワード、メソッド、変数、その他のプログラミング要素の候補がポップアップ表示されます。 オブジェクトの種類ごとに異なるアイコンで表されます:
IntelliSense エラー マーカー。 言語サービスにより、Hive スクリプトの編集エラーに下線が引かれます。
構文の強調表示。 言語サービスにより、異なる色を使用して、変数、キーワード、データ型、関数、その他のプログラミング要素が区別されます。
読み取り専用ロール
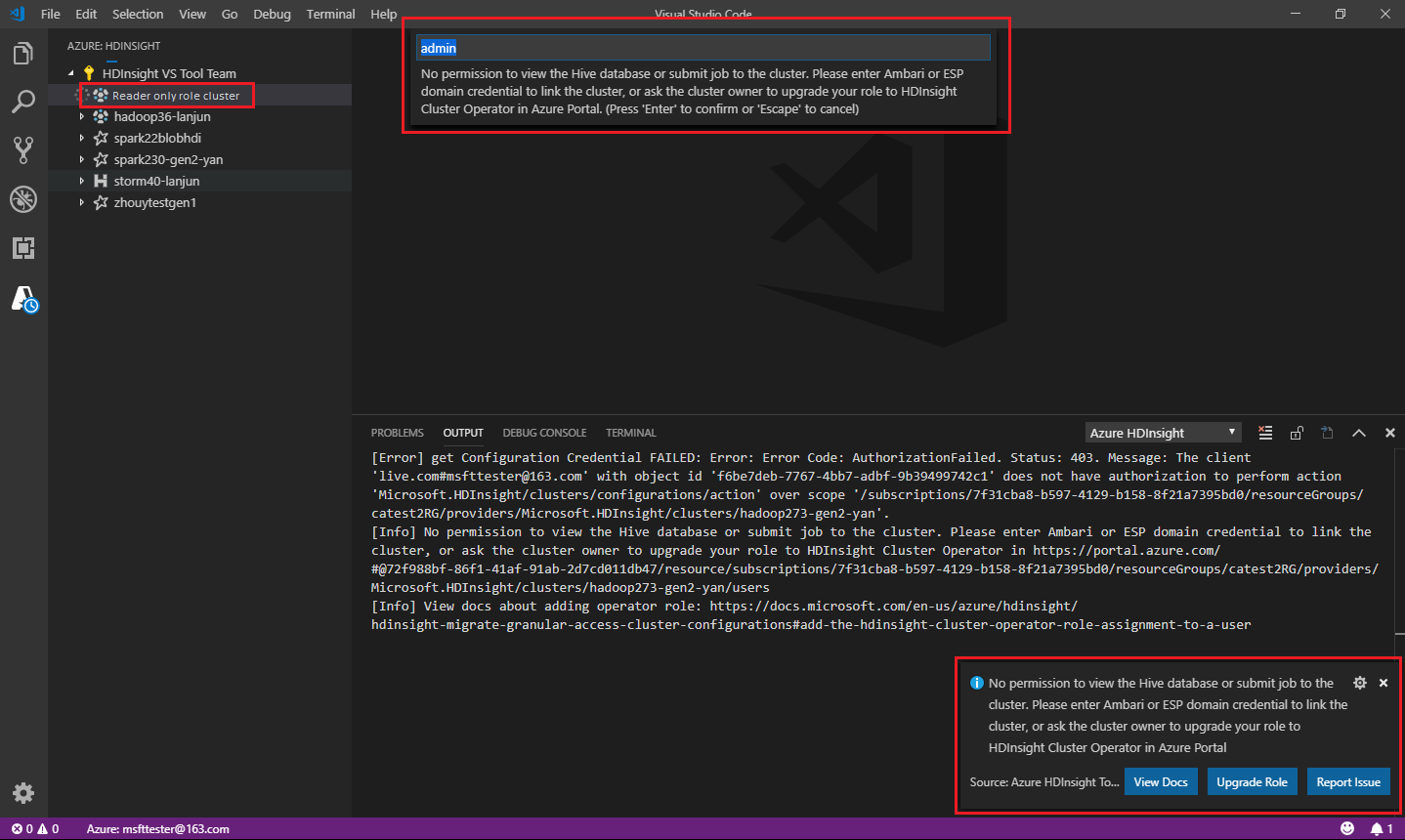
クラスターに対する読み取り専用ロールが割り当てられているユーザーは、HDInsight クラスターにジョブを送信することも、Hive データベースを表示することもできません。 クラスター管理者に連絡し、Azure portal で HDInsight クラスター オペレーターへとロールをアップグレードしてもらいます。 有効な Ambari 資格情報を持っている場合は、次のガイダンスに従って、クラスターを手動でリンクすることができます。
HDInsight クラスターを参照する
Azure HDInsight のエクスプローラー上で選択して HDInsight クラスターを展開したときに、そのクラスターに対して読み取り専用ロールを持っている場合は、クラスターをリンクするよう求められます。 自分の Ambari 資格情報を使用してクラスターにリンクするには、次の方法を使用します。
HDInsight クラスターにジョブを送信する
HDInsight クラスターにジョブを送信するときに、そのクラスターに対して読み取り専用ロールを持っている場合は、クラスターをリンクするよう求められます。 Ambari 資格情報を使用してクラスターにリンクするには、次の手順を使用します。
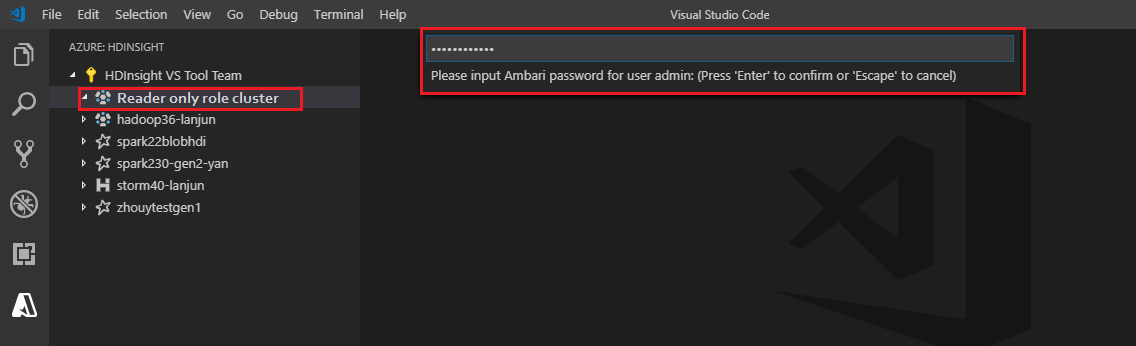
クラスターにリンクする
有効な Ambari ユーザー名を入力します。
有効なパスワードを入力します。
Note
Spark / Hive: List Clusterを使用して、リンクされたクラスターを確認できます。
Azure Data Lake Storage Gen2
Data Lake Storage Gen2 アカウントを参照する
Azure HDInsight エクスプローラーを選択して Data Lake Storage Gen2 アカウントを展開します。 Azure アカウントに Gen2 ストレージへのアクセス権がない場合は、ストレージ アクセス キーを入力するよう求められます。 アクセス キーが検証されると、Data Lake Storage Gen2 アカウントは自動的に展開されます。
Data Lake Storage Gen2 を使用して HDInsight クラスターにジョブを送信する
Data Lake Storage Gen2 を使用して HDInsight クラスターにジョブを送信します。 Azure アカウントに Gen2 ストレージへの書き込みアクセス権がない場合は、ストレージ アクセス キーを入力するよう求められます。 アクセス キーが検証されると、ジョブは正常に送信されます。

Note
ストレージ アカウントのアクセス キーは Azure portal から取得できます。 詳細については、「ストレージ アカウント アクセス キーを管理する」を参照してください。
クラスターのリンク解除
メニュー バーから、 [表示]>[コマンド パレット] の順に移動し、「Spark / Hive: Unlink a Cluster」と入力します。
リンクを解除するクラスターを選択します。
検証のため、 [出力] ビューを確認します。
サインアウトする
メニュー バーから、 [ビュー]>[コマンド パレット] の順に移動し、「Azure: Sign Out」と入力します。
既知の問題
Synapse PySpark のインストール エラー。
Synapse PySpark のインストール エラーの場合、その依存関係が他のチームによって維持されなくなるため、これは維持されなくなります。 Synapse Pyspark Interactive を使用しようとしている場合は、代わりに Azure Synapse Analytics を使用してください。 これは長期的な変更です。
次のステップ
Spark & Hive for Visual Studio Code の使用については、Spark & Hive for Visual Studio Code のデモ ビデオをご覧ください。