Azure では、不正による予算超過を防ぎ、Azure の容量の制約を尊重するためにクォータと制限を使用しています。 運用環境のワークロードに合わせてスケーリングするときは、これらの制限事項について考慮してください。 この記事では、次の内容について説明します。
- Azure Machine Learning に関連する Azure リソースの既定の制限事項。
- ワークスペースレベルのクォータを作成する。
- クォータと制限を表示する。
- クォータの引き上げを依頼する。
クォータと制限の管理に加えて、Azure Machine Learning のコストを計画して管理する方法や、Azure Machine Learning のサービスの制限値について説明します。
特別な考慮事項
クォータは、アカウント内の各サブスクリプションに適用されます。 複数のサブスクリプションがある場合は、サブスクリプションごとにクォータの引き上げを要求する必要があります。
クォータは、容量の保証ではなく、Azure リソースのクレジット制限です。 大規模な容量が必要な場合は、Azure サポートに連絡してクォータを引き上げてください。
クォータは、Azure Machine Learning を含め、サブスクリプション内のすべてのサービスで共有されます。 容量を評価するときは、すべてのサービスの使用量を計算します。
注意
Azure Machine Learning コンピューティングは例外です。 コア コンピューティング クォータとは別のクォータがあります。
既定の制限は、無料試用版、Standard、仮想マシン (VM) シリーズ (Dv2、F、G など) などのオファー カテゴリの種類によって異なります。
リソースの既定のクォータと制限
このセクションでは、以下のリソースの既定および最大のクォータと制限値について説明します。
- Azure Machine Learning 資産
- Azure Machine Learning コンピューティング (サーバーレス Spark を含む)
- Azure Machine Learning の共有クォータ
- Azure Machine Learning オンライン エンドポイント (マネージドと Kubernetes の両方) とバッチ エンドポイント
- Azure Machine Learning パイプライン
- Azure Machine Learning と Synapse の統合
- 仮想マシン
- Azure Container Instances (アジュール コンテナー インスタンス)
- Azure Storage
重要
制限は変更されることがあります。 最新の情報については、「Azure Machine Learning のサービスの制限値」を参照してください。
Azure Machine Learning 資産
資産に関する次の制限は、ワークスペースごとに適用されます。
| リソース | 上限 |
|---|---|
| データセット | 1,000 万 |
| 実行 | 1,000 万 |
| モデル | 1,000 万 |
| コンポーネント | 1,000 万 |
| アーティファクト | 1,000 万 |
さらに、最長実行時間は 30 日、実行ごとにログされるメトリックの最大数は 100 万です。
Azure Machine Learning コンピューティング
Azure Machine Learning コンピューティングには、サブスクリプションのリージョンごとに許可されるコアの数と一意のコンピューティング リソースの数の両方に対して、既定のクォータ制限があります。
注意
- コア数のクォータは、各 VM ファミリと累積合計コアによって分割されます。
- リージョンあたりの一意のコンピューティング リソースの数に対するクォータは、Azure Machine Learning のマネージド コンピューティング リソースにのみ適用されるため、VM コア クォータとは別です。
次の項目の制限を引き上げるには、クォータの引き上げを要求します。
- VM ファミリ のコア クォータ。 クォータの引き上げを依頼する VM ファミリの詳細については、Azure の仮想マシンのサイズを参照してください。 たとえば、GPU VM ファミリは、ファミリ名が "N" で始まります (例: NCv3 シリーズ)
- 合計サブスクリプションのコア クォータ
- クラスターのクォータ
- このセクションのその他のリソース
使用可能なリソース:
リージョンあたりの専用コアには、サブスクリプション プランの種類に応じて、24 から 300 の既定の制限があります。 サブスクリプションあたりの専用コアの数は VM ファミリごとに引き上げることができます。 NCv2、NCv3、ND シリーズなど、特殊な VM ファミリは、ゼロ コアの既定から開始されます。 GPU の既定のコア数も 0 です。
リージョンあたりの低優先度のコアには、サブスクリプション プランの種類に応じて、100 から 3,000 の既定の制限があります。 サブスクリプションあたりの優先順位の低いコアの数は増やすことができ、VM ファミリ全体で 1 つの値になります。
リージョンごとの合計コンピューティング制限には、特定のサブスクリプション内のリージョンごとに既定で 500 という制限があり、リージョンごとに最大値 2500 まで引き上げることができます。 この制限は、トレーニング クラスター、コンピューティング インスタンス、およびマネージド オンライン エンドポイント デプロイ間で共有されます。 コンピューティング インスタンスは、クォータ目的で単一のノード クラスターと見なされます。
次の表は、プラットフォームにおけるその他の制限を示しています。 例外をリクエストするには、テクニカル サポート チケットを通じて Azure Machine Learning 製品チームに連絡してください。
| リソースまたはアクション | 上限 |
|---|---|
| リソース グループあたりのワークスペース数 | 800(八百) |
| 通信が有効になっていないプールとしてセットアップされた (つまり、MPI ジョブを実行できない) 1 つの Azure Machine Learning コンピューティング (AmlCompute) クラスター内のノード数 | 100 ノード。ただし、65,000 ノードまで構成可能 |
| Azure Machine Learning コンピューティング (AmlCompute) クラスターでの 1 回の並列実行ステップ実行時のノード数 | 100 ノード。ただし、クラスターが上記のようにスケーリングするようにセットアップされている場合は、65000 ノードまで構成可能 |
| 通信が有効になっているプールとしてセットアップされた 1 つの Azure Machine Learning コンピューティング (AmlCompute) クラスター内のノード数 | 300 ノード。ただし 4,000 ノードまで構成可能 |
| RDMA 対応の VM ファミリ上で通信が有効になっているプールとしてセットアップされた 1 つの Azure Machine Learning コンピューティング (AmlCompute) クラスター内のノード数 | 100 ノード |
| Azure Machine Learning コンピューティング (AmlCompute) クラスターでの 1 回の MPI 実行時のノード数 | 100 ノード |
| ジョブの有効期間 | 21 日1 |
| 優先順位の低いノードでのジョブの有効期間 | 7 日2 |
| ノードあたりのパラメーター サーバー数 | 1 |
1 最大有効期間は、ジョブが開始されてから完了するまでの期間です。 完了したジョブは無期限に保持されます。 最大有効期間内に完了しなかったジョブのデータにはアクセスできません。
2 容量の制約がある場合は、優先度の低いノードのジョブをいつでも横取りできます。 ジョブにチェックポイントを実装することをお勧めします。
Azure Machine Learning の共有クォータ
Azure Machine Learning には、さまざまなリージョン全体のすべてのユーザーが可用性に応じてクォータにアクセスして限られた時間のテストを実行できる、共有クォータ プールが用意されています。 具体的な時間は、ユース ケースによって異なります。 クォータ プールから一時的にクォータを使用することで、短期的なクォータ増加のサポート チケットを提出したり、クォータ要求が承認されるまで待ってからワークロードを進める必要がなくなります。
共有クォータ プールの使用は、Spark ジョブの実行や、モデル カタログからの Llama-2、Phi、Nemotron、Mistral、Dolly、Deci-DeciLM モデルの短期間の推論のテストに使用できます。 共有クォータを使用してこれらのモデルをデプロイするには、Enterprise Agreement サブスクリプションが必要です。 オンライン エンドポイントのデプロイに共有クォータを使用する方法の詳細については、「スタジオを使用して基礎モデルをデプロイする方法」を参照してください。
共有クォータは、本番エンドポイントではなく、一時的なテスト エンドポイントを作成する場合にのみ使用する必要があります。 本番環境のエンドポイントの場合は、 サポート チケットを提出して専用のクォータを要求する必要があります。 共有クォータの課金は、専用仮想マシン ファミリの課金と同様に使用量ベースです。 Spark ジョブの共有クォータをオプトアウトするには、Azure Machine Learning の共有容量割り当てオプトアウト フォームに入力します。
Azure Machine Learning オンライン エンドポイントとバッチ エンドポイント
Azure Machine Learning オンライン エンドポイントとバッチ エンドポイントには、次の表で説明するリソース制限があります。
重要
これらはリージョンの制限であり、使用している各リージョンごとに最大でこれらの制限を使用できます。 たとえば、サブスクリプションあたりのエンドポイント数の現在の制限が 100 の場合は、1 つのサブスクリプションで米国東部リージョンに 100 個のエンドポイント、米国西部リージョンに 100 個のエンドポイント、サポートされている他の各リージョンに 100 個のエンドポイントを作成できます。 他のすべての制限に同じ原則が適用されます。
エンドポイントの現在の使用状況を確認するには、メトリックを表示します。
Azure Machine Learning 製品チームに例外をリクエストするには、「エンドポイント制限の引き上げ」の手順を使用してください。
| リソース | 制限 1 | 例外を許可する | 適用対象 |
|---|---|---|---|
| エンドポイント名 | エンドポイント名は以下に従う必要があります |
- | すべての種類のエンドポイント 3 |
| デプロイ名 | デプロイ名は以下に従う必要があります |
- | すべての種類のエンドポイント 3 |
| サブスクリプションあたりのエンドポイントの数 | 100 | はい | すべての種類のエンドポイント 3 |
| クラスターあたりのエンドポイントの数 | 六十 | - | Kubernetes オンライン エンドポイント |
| サブスクリプションあたりのデプロイの数 | 500 | はい | すべての種類のエンドポイント 3 |
| エンドポイントあたりのデプロイの数 | 20 | はい | すべての種類のエンドポイント 3 |
| クラスターあたりのデプロイの数 | 100 | - | Kubernetes オンライン エンドポイント |
| デプロイあたりのインスタンスの数 | 50 4 | はい | マネージド オンライン エンドポイント |
| エンドポイント レベルでの最大要求タイムアウト | 180 秒 5 | - | マネージド オンライン エンドポイント |
| エンドポイント レベルでの最大要求タイムアウト | 300 秒 | - | Kubernetes オンライン エンドポイント |
| すべてのデプロイに対するエンドポイント レベルでの 1 秒あたりの要求の合計数 | 500 6 | はい | マネージド オンライン エンドポイント |
| すべてのデプロイに対するエンドポイント レベルでの 1 秒あたりの接続の合計数 | 500 6 | はい | マネージド オンライン エンドポイント |
| すべてのデプロイに対するエンドポイント レベルでのアクティブな接続の合計数 | 500 6 | はい | マネージド オンライン エンドポイント |
| すべてのデプロイのエンドポイント レベルでの帯域幅合計 | 5 MBPS 6 | はい | マネージド オンライン エンドポイント |
1 これはリージョンの制限です。 たとえば、現在のエンドポイント数の制限が 100 の場合は、1 つのサブスクリプションで米国東部リージョンに 100 個のエンドポイント、米国西部リージョンに 100 個のエンドポイント、サポートされている他の各リージョンに 100 個のエンドポイントを作成できます。 他のすべての制限に同じ原則が適用されます。
2 エンドポイント名とデプロイ名で、my-endpoint-name のような単一のダッシュを使用できます。
3 エンドポイントとデプロイにはさまざまな種類がありますが、制限はすべての種類の合計に対して適用されます。 たとえば、各サブスクリプションのマネージド オンライン エンドポイント、Kubernetes オンライン エンドポイント、バッチ エンドポイントの合計は、既定でリージョンあたり 100 を超えることはできません。 同様に、各サブスクリプションのマネージド オンライン デプロイ、Kubernetes オンライン デプロイ、バッチ デプロイの合計は、既定でリージョンあたり 500 を超えることはできません。
4 アップグレードを実行するために 20% の追加コンピューティング リソースを予約します。 たとえば、デプロイで 10 個のインスタンスを要求する場合は、12 個分のクォータが必要です。 そうしない場合、エラーが発生します。 追加のクォータから除外される VM SKU がいくつかあります。 共有クォータの詳細については、「デプロイのための仮想マシン クォータの割り当て」を参照してください。
5 要求タイムアウトの最大値は、フロー (プロンプト フロー) のデプロイでない限り、180 秒です。 フロー デプロイの最大要求タイムアウトは 300 秒です。 フロー デプロイのタイムアウトの詳細については、「プロンプト フローでフロー デプロイする」を参照してください。
6 1 秒あたりの要求数、接続数、帯域幅などが関連しています。 これらの制限のいずれかに対して引き上げを要求する場合は、他の関連する制限を一緒に見積もりまたは計算するようにしてください。
デプロイのための仮想マシン クォータの割り当て
マネージド オンライン エンドポイントの場合、Azure Machine Learning では、一部の VM SKU でアップグレードを実行するためにコンピューティング リソースの 20% が予約されます。 デプロイ内のそれらの VM SKU に対して特定の数のインスタンスを要求する場合は、使用可能な ceil(1.2 * number of instances requested for deployment) * number of cores for the VM SKU のクォータを確保して、エラーが発生しないようにする必要があります。 たとえば、デプロイで Standard_DS3_v2 VM (4 コアを搭載) の 10 個のインスタンスを要求する場合は、使用可能な 48 コア (12 instances * 4 cores) のクォータが必要です。 この追加のクォータは、OS のアップグレードや VM の復旧などのシステムによって開始される操作用に予約されており、そのような操作が実行されない限りコストは発生しません。
追加のクォータ予約から除外される特定の VM SKU があります。 完全な一覧を表示するには、マネージド オンライン エンドポイント SKU の一覧を参照してください。 使用状況を確認してクォータの増加を要求するには、「Azure portal で使用状況とクォータを表示する」を参照してください。 マネージド オンライン エンドポイントの実行コストを表示するには、「マネージド オンライン エンドポイントのコストを表示する」を参照してください。
Azure Machine Learning パイプライン
Azure Machine Learning パイプラインには次の制限事項があります。
| リソース | 制限 |
|---|---|
| パイプラインのステップ | 30,000 |
| リソース グループあたりのワークスペース数 | 800(八百) |
Azure Machine Learning と Synapse の統合
Azure Machine Learning サーバーレス Spark では、Apache Spark ジョブをスケーリングする分散コンピューティング機能に簡単にアクセスできます。 サーバーレス Spark は、Azure Machine Learning コンピューティングと同じ専用クォータを利用します。 サポート チケットを送信し、"Machine Learning service: 仮想マシン クォータ" カテゴリで ESv3 シリーズのクォータと制限の引き上げを要求すれば、クォータ制限を引き上げることができます。
クォータの使用状況を表示するには、Machine Learning Studio に移動し、使用状況を表示するサブスクリプション名を選びます。 左側のパネルで [クォータ] を選びます。

仮想マシン
各 Azure サブスクリプションには、すべてのサービスにわたる仮想マシン数の制限があります。 仮想マシン コアには、リージョンの合計の制限とサイズシリーズあたりのリージョンの制限があります。 どちらの制限も個別に適用されます。
たとえば、米国東部で VM のコア上限が 30、A シリーズのコア上限が 30、D シリーズのコア上限が 30 のサブスクリプションがあるとします。 このサブスクリプションを使用すると、30 個の A1 VM、30 個の D1 VM、または合計 30 コアを超えないこれら 2 つの組み合わせをデプロイできます。
次の表に示す値を超えて仮想マシンの制限を引き上げることはできません。
| リソース | 制限 |
|---|---|
| Microsoft Entra テナントに関連付けられた Azure サブスクリプション | 無制限 |
| サブスクリプションあたりの共同管理者数 | 無制限 |
| サブスクリプションあたりのリソース グループ数 | 980 |
| Azure Resource Manager API 要求サイズ | 4,194,304 バイト |
| サブスクリプションあたりのタグ数1 | 50 |
| サブスクリプションあたりの一意のタグの計算2 | 80,000 |
| 場所あたりのサブスクリプション レベルのデプロイ数 | 8003 |
| サブスクリプションレベルのデプロイの場所 | 10 |
1サブスクリプションにはタグを最大で 50 個直接適用することができます。 サブスクリプション内では、各リソースまたはリソース グループもタグが 50 個に制限されます。 ただし、サブスクリプションには、リソースとリソース グループ間に分散されるタグを無制限に含めることができます。
2サブスクリプションに存在するタグ名と値のリストが Resource Manager から返されるのは、一意のタグの数が 80,000 以下の場合に限られます。 一意のタグは、リソース ID、タグ名、タグ値の組み合わせによって定義されます。 たとえば、同じタグ名と値を持つ 2 つのリソースは、2 つの一意のタグとして計算されます。 タグの数が 80,000 を超える場合でも、タグでリソースを検出することはできます。
3この制限に近づくと、デプロイは履歴から自動的に削除されます。 詳細については、「デプロイ履歴からの自動削除」を参照してください。
コンテナ事例
詳細については、「Container Instances の制限」を参照してください。
記憶域
Azure Storage では、サブスクリプションおよびリージョンあたりのストレージ アカウント数が 250 に制限されています。 この制限には、Standard および Premium ストレージ アカウントの両方が含まれます。
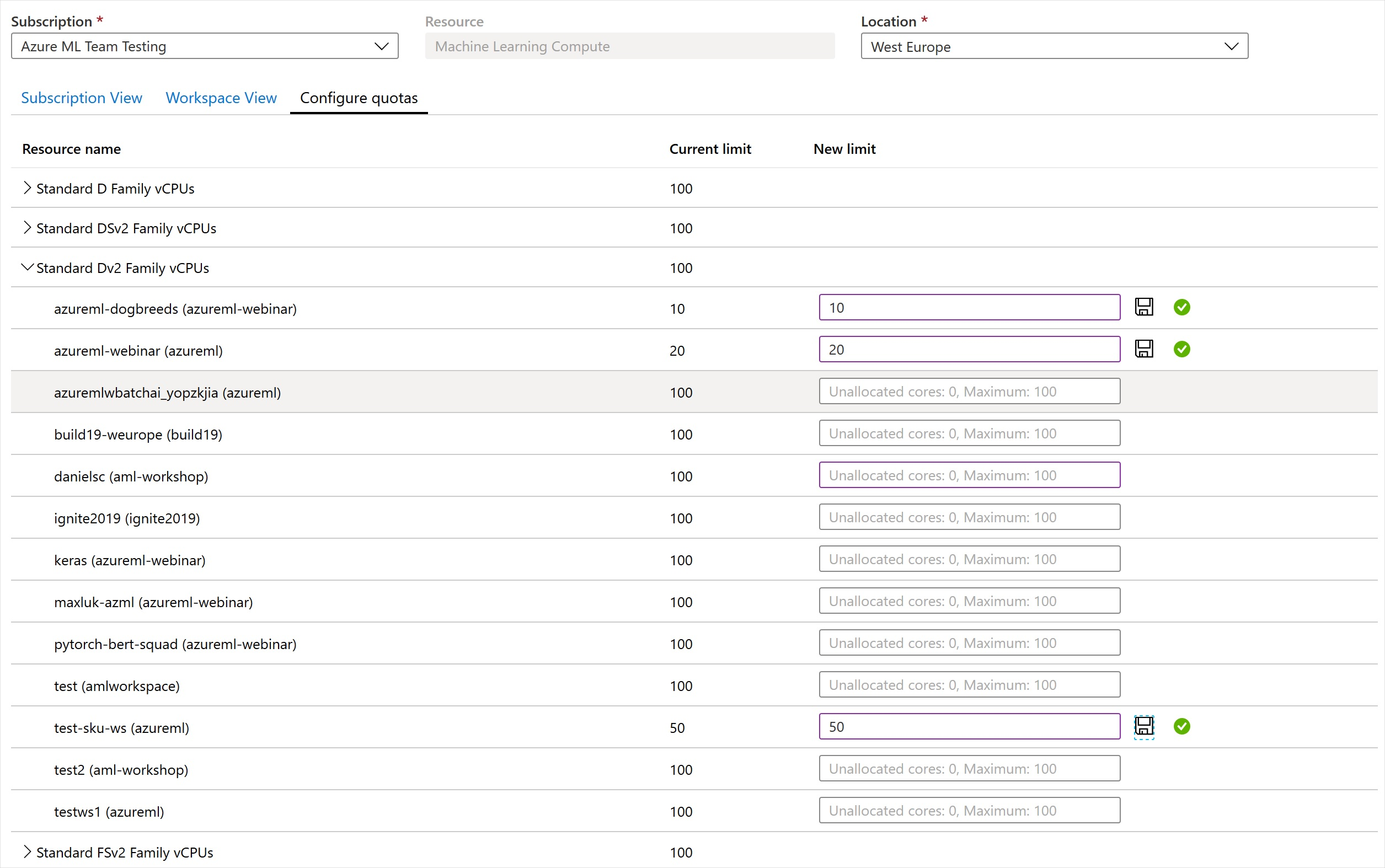
ワークスペースレベルのクォータ
同じサブスクリプション内の複数のワークスペース間の Azure Machine Learning コンピューティング ターゲットの割り当てを管理するには、ワークスペース レベル クォータを使用します。
既定では、すべてのワークスペースが VM ファミリのサブスクリプション レベル クォータと同じクォータを共有しています。 ただし、サブスクリプション内のワークスペース上の個々の VM ファミリに最大クォータを設定できます。 個々の VM ファミリのクォータを使用すると、容量を共有し、リソースの競合の問題を回避できます。
- サブスクリプション内の任意のワークスペースに移動します。
- 左側のペインで、[使用量 + クォータ] を選択します。
- [クォータの構成] タブを選択して、クォータを表示します。
- VM ファミリを展開します。
- その VM ファミリの下に表示されているワークスペースにクォータ制限を設定します。
負の値またはサブスクリプション レベルのクォータよりも大きい値は設定できません。
注意
ワークスペース レベルでクォータを設定するには、サブスクリプションレベルのアクセス許可が必要です。
スタジオでクォータを表示する
新しいコンピューティング リソースを作成すると、既定では、既に使用するクォータがある VM サイズのみが表示されます。 ビューを [すべてのオプションから選択] に切り替えます。
![より多くのクォータを必要とするコンピューティング リソースを表示するための [すべてのオプションから選択] を示すスクリーンショット](media/how-to-manage-quotas/select-all-options.png?view=azureml-api-2)
クォータがない VM サイズの一覧が表示されるまで下にスクロールします。
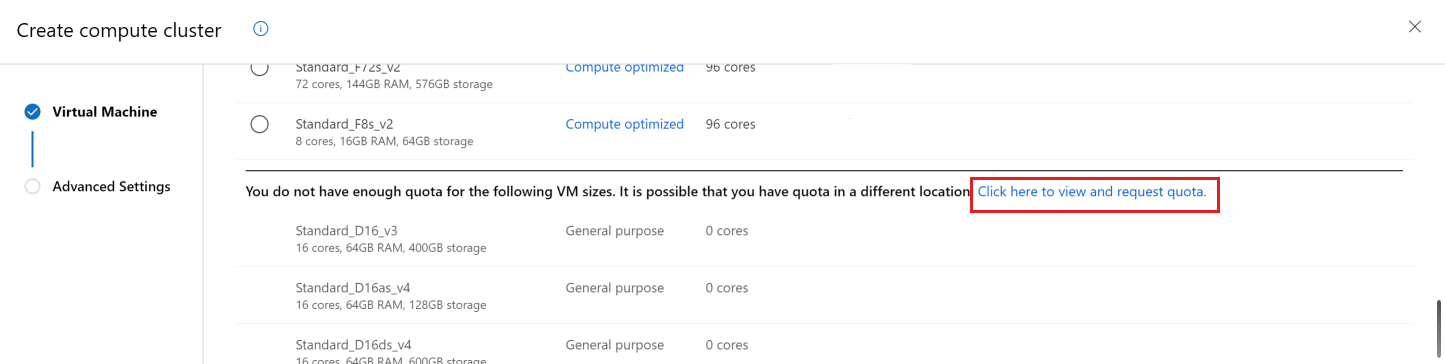
このリンクを使用して、クォータを増やすためのオンライン カスタマー サポート申請に直接移動します。
Azure portal で使用状況とクォータを表示する
仮想マシン、ストレージ、ネットワークなどのさまざまな Azure リソースのクォータを表示するには、Azure portal を使用します。
左側のペインで、 [すべてのサービス] を選択し、 [一般] カテゴリの下にある [サブスクリプション] を選択します。
サブスクリプションの一覧から、検索するクォータのサブスクリプションを選択します。
現在のクォータ制限と使用状況を表示するには、 [使用量 + クォータ] を選択します。 フィルターを使用して、プロバイダーと場所を選択します。
サブスクリプションの Azure Machine Learning コンピューティング クォータは、他の Azure のクォータとは別に管理します。
Azure portal で Azure Machine Learning ワークスペースに移動します。
左側のペインにある [サポート + トラブルシューティング] セクションで [使用量 + クォータ] を選択して、現在のクォータ制限と使用状況を表示します。

クォータ制限を表示するサブスクリプションを選択します。 目的のリージョンにフィルターを適用します。
サブスクリプション レベル ビューとワークスペース レベル ビューを切り替えることができます。
クォータと制限の引き上げ要求
VM クォータの引き上げは、リージョンごとの VM ファミリあたりのコア数を増やすことです。 エンドポイント制限の引き上げは、リージョンごとのサブスクリプションあたりのエンドポイント固有の制限数を引き上げることです。 次のセクションで説明するように、クォータの引き上げ要求を送信するときは適切なカテゴリを選択してください。
VM クォータの引き上げ
Azure Machine Learning VM クォータの制限を既定の制限を超えて引き上げるには、上記の [使用量 + クォータ] ビューからクォータの引き上げを要求するか、Azure Machine Learning スタジオからクォータの引き上げ要求を送信します。
上記の手順に従って、[使用量 + クォータ] ページに移動します。 現在のクォータ制限を確認します。 増加を要求する SKU を選択します。
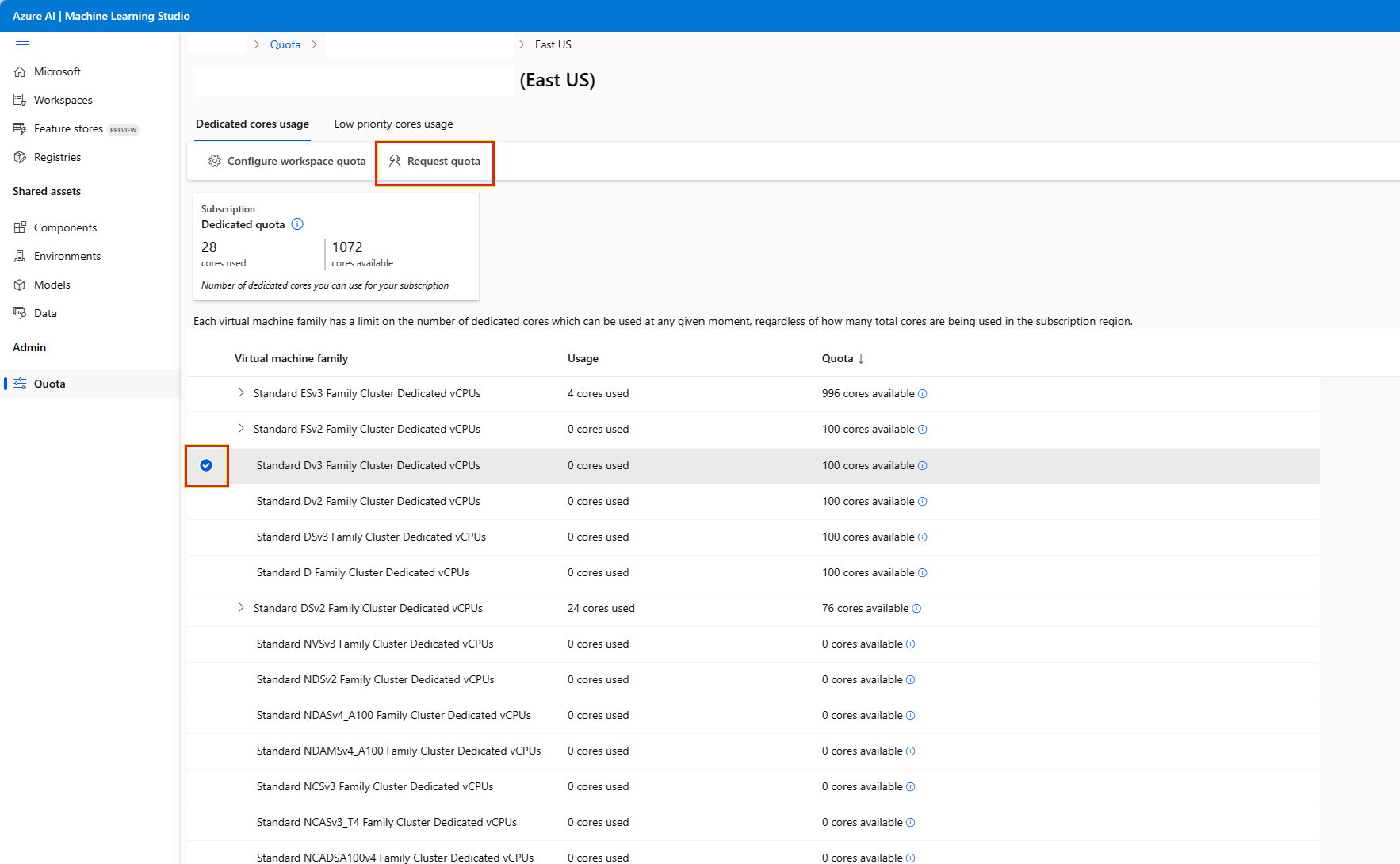
増やすクォータと新しい制限値を指定します。 最後に、[送信] を選択して続けます。

エンドポイント制限の引き上げ
エンドポイント制限を引き上げるには、オンライン カスタマー サポート リクエストを作成してください。 エンドポイント制限の引き上げを要求するときは、次の情報を入力します。
サポート リクエストを開く際に、問題の種類として [サービスとサブスクリプションの制限 (クォータ)] を選択します。
任意のサブスクリプションを選択します。
クォータの種類として [Machine Learning Service: エンドポイントの制限] を選択します。
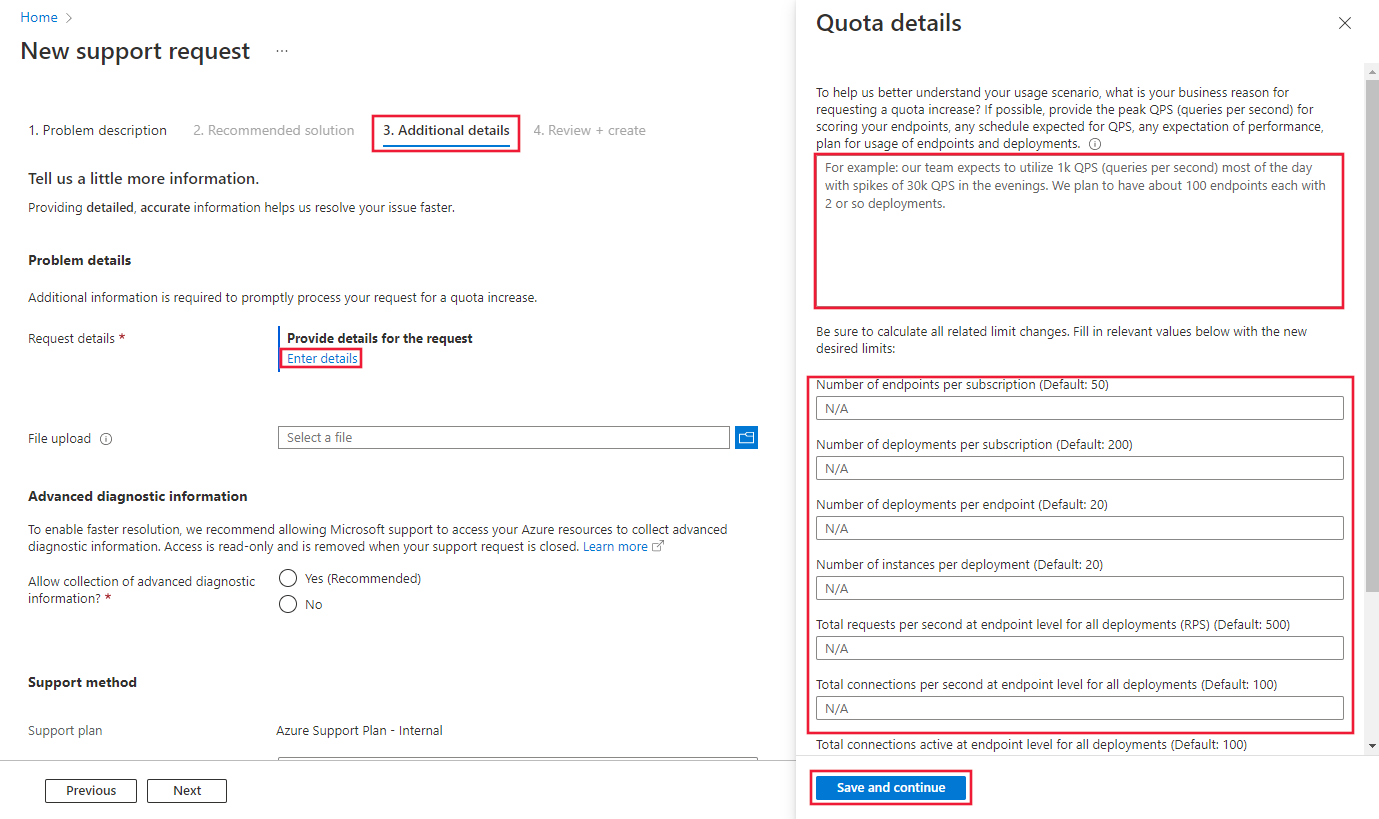
要求が処理されるようにするには、[追加情報] タブで、制限引き上げの詳細な理由を入力する必要があります。 [詳細を入力] を選択し、引き上げる制限と各制限の新しい値、制限引き上げ要求の理由、制限の引き上げが必要な場所 (複数可)を指定します。 制限引き上げの理由には、次の情報を必ず追加してください。
- シナリオとワークロードの説明 (テキスト、画像など)。
- 要求した引き上げの根拠。
- ターゲット スループットとそのパターン (平均またはピーク QPS、同時ユーザー数) を入力します。
- 大規模なターゲット待ち時間と、1 つのインスタンスで観察された現在の待ち時間を入力します。
- ターゲットのスループットと待ち時間をサポートするための VM SKU と合計インスタンス数を指定します。 各リージョンで使用する予定のエンドポイント、デプロイ、インスタンスの数を指定します。
- 選択した VM SKU と、スループットと待ち時間の要件を満たすインスタンスの数を示すベンチマーク テストがあるかどうかを確認します。
- ペイロードの種類と 1 つのペイロードのサイズを指定します。 ネットワーク帯域幅は、ペイロード サイズと 1 秒あたりの要求数に合わせる必要があります。
- 計画された時間計画 (いつまでに制限引き上げが必要か。可能な場合は段階的な計画を指定する) を指定し、(1) そのスケールでの実行コストが予算に反映されているか、(2) ターゲットの VM SKU が承認されているかを確認します。
最後に、[保存して続行] を選択して続行します。
注意
このエンドポイントの制限引き上げ要求は、VM クォータ引き上げ要求とは異なります。 要求が VM クォータの引き上げに関連している場合は、「VM クォータの引き上げ」セクションの手順に従ってください。
コンピューティング制限の引き上げ
合計コンピューティング制限を引き上げるには、オンライン カスタマー サポート リクエストを開いてください。 次の情報を指定します。
サポート リクエストのフォームで、 [問題の種類]として [技術] を選びます。
任意のサブスクリプションを選択します
[サービス]として [機械学習] を選びます。
対象のリソースを選びます
[概要] に「合計コンピューティング制限の引き上げ」と入力します。
[問題の種類] として [コンピューティング クラスター] を、 [問題のサブタイプ] として [クラスターがスケールアップしない、またはサイズ設定でスタックしている] を選びます。
![[問題の説明] タブを示すスクリーンショット。](media/how-to-manage-quotas/problem-description.png?view=azureml-api-2)
[その他の詳細] タブで、サブスクリプション ID、リージョン、新しい制限 (500 から 2500 の間)、このリージョンの合計コンピューティング制限を引き上げる場合のビジネス上の正当な理由を入力します。
![[その他の詳細] タブのスクリーンショット。](media/how-to-manage-quotas/additional-details.png?view=azureml-api-2)
最後に [作成] を選んでサポート リクエスト チケットを作成します。