適用対象: Azure CLI ml 拡張機能 v2 (現行)Python SDK azure-ai-ml v2 (現行)
Azure CLI ml 拡張機能 v2 (現行)Python SDK azure-ai-ml v2 (現行)
この記事では、次のことについて説明します。
- Azure Machine Learning ジョブで Azure Storage からデータを読み取る方法。
- Azure Machine Learning ジョブから Azure Storage にデータを書き込む方法。
- マウント モードとダウンロード モードの違い。
- ユーザー ID とマネージド ID を使用してデータにアクセスする方法。
- ジョブで使用できるマウント設定。
- 一般的なシナリオに最適なマウント設定。
- V1 データ資産にアクセスする方法。
前提条件
Azure サブスクリプション。 Azure サブスクリプションをお持ちでない場合は、開始する前に無料アカウントを作成してください。 無料版または有料版の Azure Machine Learning をお試しください。
Azure Machine Learning ワークスペース
クイック スタート
データにアクセスするときに使用できる詳細なオプションを確認する前に、まずデータ アクセスに関連するコード スニペットについて説明します。
Azure Machine Learning ジョブで Azure Storage からデータを読み取る
この例では、パブリック BLOB ストレージ アカウントからデータにアクセスする Azure Machine Learning ジョブを送信します。 ただし、プライベート Azure Storage アカウント内の独自のデータにアクセスするようにスニペットを調整できます。 こちらで説明するようにパスを更新します。 Azure Machine Learning は、Microsoft Entra パススルーを使用してクラウド ストレージへの認証をシームレスに処理します。 ジョブを送信するときに、次のオプションを選択できます:
- ユーザー ID: Microsoft Entra ID をパススルーしてデータにアクセスします
- マネージド ID: コンピューティング先のマネージド ID を使用してデータにアクセスします
- なし: データにアクセスする ID を指定しません。 資格情報ベース (キー/SAS トークン) データストアを使用する場合、またはパブリック データにアクセスする場合は、なしを使用します
ヒント
認証にキーまたは SAS トークンを使用する場合は、 Azure Machine Learning データストアを作成することをお勧めします。 ランタイムは、資格情報を公開せずにストレージに自動的に接続します。
from azure.ai.ml import command, Input, MLClient, UserIdentityConfiguration, ManagedIdentityConfiguration
from azure.ai.ml.entities import Data
from azure.ai.ml.constants import AssetTypes, InputOutputModes
from azure.identity import DefaultAzureCredential
# Set your subscription, resource group and workspace name:
subscription_id = "<SUBSCRIPTION_ID>"
resource_group = "<RESOURCE_GROUP>"
workspace = "<AML_WORKSPACE_NAME>"
# connect to the AzureML workspace
ml_client = MLClient(
DefaultAzureCredential(), subscription_id, resource_group, workspace
)
# ==============================================================
# Set the URI path for the data.
# Supported `path` formats for input include:
# local: `./<path>
# Blob: wasbs://<container_name>@<account_name>.blob.core.windows.net/<path>
# ADLS: abfss://<file_system>@<account_name>.dfs.core.windows.net/<path>
# Datastore: azureml://datastores/<data_store_name>/paths/<path>
# Data Asset: azureml:<my_data>:<version>
# Supported `path` format for output is:
# Datastore: azureml://datastores/<data_store_name>/paths/<path>
# We set the input path to a file on a public blob container
# ==============================================================
path = "wasbs://data@azuremlexampledata.blob.core.windows.net/titanic.csv"
# ==============================================================
# What type of data does the path point to? Options include:
# data_type = AssetTypes.URI_FILE # a specific file
# data_type = AssetTypes.URI_FOLDER # a folder
# data_type = AssetTypes.MLTABLE # an mltable
# The path we set above is a specific file
# ==============================================================
data_type = AssetTypes.URI_FILE
# ==============================================================
# Set the mode. The popular modes include:
# mode = InputOutputModes.RO_MOUNT # Read-only mount on the compute target
# mode = InputOutputModes.DOWNLOAD # Download the data to the compute target
# ==============================================================
mode = InputOutputModes.RO_MOUNT
# ==============================================================
# You can set the identity you want to use in a job to access the data. Options include:
# identity = UserIdentityConfiguration() # Use the user's identity
# identity = ManagedIdentityConfiguration() # Use the compute target managed identity
# ==============================================================
# This example accesses public data, so we don't need an identity.
# You also set identity to None if you use a credential-based datastore
identity = None
# Set the input for the job:
inputs = {
"input_data": Input(type=data_type, path=path, mode=mode)
}
# This command job uses the head Linux command to print the first 10 lines of the file
job = command(
command="head ${{inputs.input_data}}",
inputs=inputs,
environment="azureml://registries/azureml/environments/sklearn-1.1/versions/4",
compute="cpu-cluster",
identity=identity,
)
# Submit the command
ml_client.jobs.create_or_update(job)
Azure Machine Learning ジョブから Azure Storage にデータを書き込む
この例では、既定の Azure Machine Learning データストアにデータを書き込む Azure Machine Learning ジョブを送信します。 必要に応じて、データ資産の name 値を設定して、出力でデータ資産を作成することもできます。
from azure.ai.ml import command, Input, Output, MLClient
from azure.ai.ml.constants import AssetTypes, InputOutputModes
from azure.identity import DefaultAzureCredential
# Set your subscription, resource group and workspace name:
subscription_id = "<SUBSCRIPTION_ID>"
resource_group = "<RESOURCE_GROUP>"
workspace = "<AML_WORKSPACE_NAME>"
# connect to the AzureML workspace
ml_client = MLClient(
DefaultAzureCredential(), subscription_id, resource_group, workspace
)
# ==============================================================
# Set the URI path for the data.
# Supported `path` formats for input include:
# local: `./<path>
# Blob: wasbs://<container_name>@<account_name>.blob.core.windows.net/<path>
# ADLS: abfss://<file_system>@<account_name>.dfs.core.windows.net/<path>
# Datastore: azureml://datastores/<data_store_name>/paths/<path>
# Data Asset: azureml:<my_data>:<version>
# Supported `path` format for output is:
# Datastore: azureml://datastores/<data_store_name>/paths/<path>
# As an example, we set the input path to a file on a public blob container
# As an example, we set the output path to a folder in the default datastore
# ==============================================================
input_path = "wasbs://data@azuremlexampledata.blob.core.windows.net/titanic.csv"
output_path = "azureml://datastores/workspaceblobstore/paths/quickstart-output/titanic.csv"
# ==============================================================
# What type of data are you pointing to?
# AssetTypes.URI_FILE (a specific file)
# AssetTypes.URI_FOLDER (a folder)
# AssetTypes.MLTABLE (a table)
# The path we set above is a specific file
# ==============================================================
data_type = AssetTypes.URI_FILE
# ==============================================================
# Set the input mode. The most commonly-used modes:
# InputOutputModes.RO_MOUNT
# InputOutputModes.DOWNLOAD
# Set the mode to Read Only (RO) to mount the data
# ==============================================================
input_mode = InputOutputModes.RO_MOUNT
# ==============================================================
# Set the output mode. The most commonly-used modes:
# InputOutputModes.RW_MOUNT
# InputOutputModes.UPLOAD
# Set the mode to Read Write (RW) to mount the data
# ==============================================================
output_mode = InputOutputModes.RW_MOUNT
# Set the input and output for the job:
inputs = {
"input_data": Input(type=data_type, path=input_path, mode=input_mode)
}
outputs = {
"output_data": Output(type=data_type,
path=output_path,
mode=output_mode,
# optional: if you want to create a data asset from the output,
# then uncomment `name` (`name` can be set without setting `version`, and in this way, we will set `version` automatically for you)
# name = "<name_of_data_asset>", # use `name` and `version` to create a data asset from the output
# version = "<version>",
)
}
# This command job copies the data to your default Datastore
job = command(
command="cp ${{inputs.input_data}} ${{outputs.output_data}}",
inputs=inputs,
outputs=outputs,
environment="azureml://registries/azureml/environments/sklearn-1.1/versions/4",
compute="cpu-cluster",
)
# Submit the command
ml_client.jobs.create_or_update(job)
Azure Machine Learning データ ランタイム
ジョブを送信すると、Azure Machine Learning データ ランタイムによって、保存場所からコンピューティング先へのデータの読み込みが制御されます。 Azure Machine Learning データ ランタイムは、機械学習タスクを高速かつ効率的に処理できるよう最適化されています。 以下は主な利点です。
- データの読み込みは Rust 言語で記述されます。この言語は高速でメモリ効率が高いことで知られています。 並列データダウンロードでは、Rust は Python が持つグローバル インタープリター ロック (GIL) の問題を回避します
- 軽量です。Rust には、JVM など他のテクノロジへの依存関係がありません。 その結果、ランタイムがすぐにインストールされ、コンピューティング先で余分なリソース (CPU、メモリ) を消費することがありません
- マルチプロセス (並列) データ読み込み
- ディープ ラーニングの実行時に GPU の使用率を向上させるために、1 つ以上の CPU のバックグラウンド タスクとしてデータをプリフェッチする
- クラウド ストレージに対するシームレスな認証処理
- データのマウント (ストリーム) またはすべてのデータのダウンロードを行うオプションを提供します。 詳細については、「マウント (ストリーミング)」および「ダウンロード」セクションにアクセスしてください。
- fsspec とのシームレスな統合 - ローカル、リモート、および埋め込みファイル システムとバイト ストレージへの統合された Python インターフェイス。
ヒント
トレーニング (クライアント) コードで独自のマウント/ダウンロード機能を作成するのではなく、Azure Machine Learning データ ランタイムを適用することをお勧めします。 グローバル インタープリター ロック (GIL) の問題により、クライアント コードが Python を使用してストレージからデータをダウンロードする場合の、ストレージ スループットの制約を確認しました。
パス
ジョブにデータ入力または出力を指定する場合は、データの場所を指す path パラメーターを指定する必要があります。 次の表は、Azure Machine Learning がサポートするさまざまなデータの場所を示し、 path パラメーターの例を示しています。
| ロケーション | 例 | 入力 | 出力 |
|---|---|---|---|
| ローカル コンピューター上のパス | ./home/username/data/my_data |
Y | N |
| パブリック HTTP(S) サーバー上のパス | https://raw.githubusercontent.com/pandas-dev/pandas/main/doc/data/titanic.csv |
Y | N |
| Azure Storage 上のパス | wasbs://<container_name>@<account_name>.blob.core.windows.net/<path>abfss://<file_system>@<account_name>.dfs.core.windows.net/<path> |
Y (ID ベースの認証の場合のみ) | N |
| Azure Machine Learning データストアのパス | azureml://datastores/<data_store_name>/paths/<path> |
Y | Y |
| データ資産へのパス | azureml:<my_data>:<version> |
Y | いいえ (ただし、name と version を使用して、出力からデータ資産を作成できます) |
モード
データの入出力を伴うジョブを実行する場合は、以下の "モード" オプションから選択できます:
ro_mount: 保存場所をローカル ディスク (SSD) のコンピューティング先に読み取り専用としてマウントします。rw_mount: 保存場所をローカル ディスク (SSD) のコンピューティング先に読み取り/書き込みとしてマウントします。download: 保存場所からローカル ディスク (SSD) のコンピューティング先にデータをダウンロードします。upload: コンピューティング先から保存場所にデータをアップロードします。eval_mount/eval_download:"これらのモードは MLTable に固有です。"一部のシナリオでは、MLTable ファイルをホストしているストレージ アカウントとは異なるストレージ アカウントに存在しているファイルを MLTable で生成できます。 または、MLTable でストレージ リソースに存在するデータをサブセット化またはシャッフルすることもできます。 サブセット/シャッフルのそのビューは、Azure Machine Learning データ ランタイムが MLTable ファイルを評価するときにのみ表示されます。 たとえば、この図は、eval_mountまたはeval_downloadで使用される MLTable が、異なるストレージ アカウントにある 2 つの異なるストレージ コンテナーと注釈ファイルからイメージを取得し、リモート コンピューティング ターゲットのファイルシステムにマウント/ダウンロードする方法を示しています。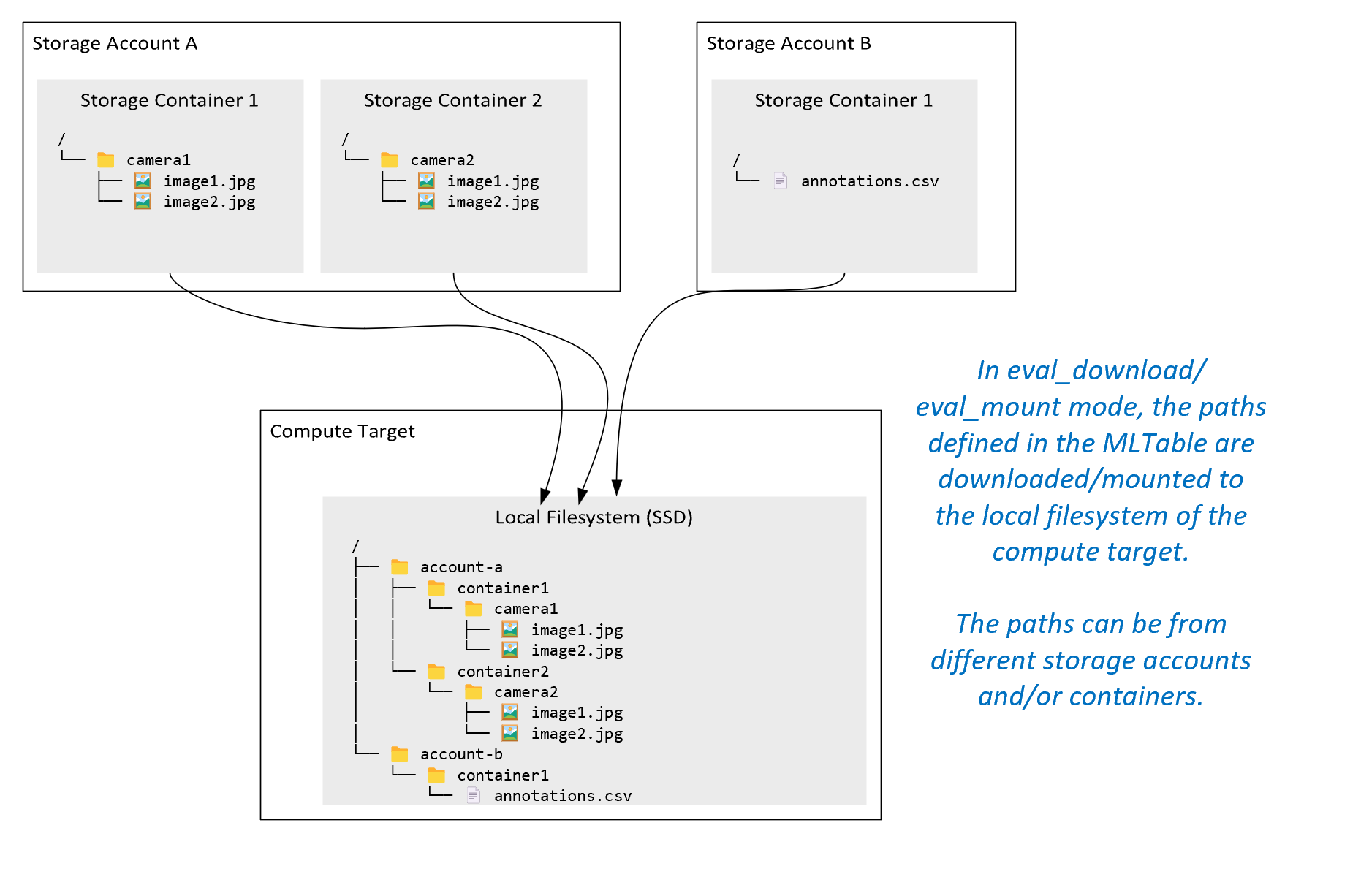
その後、
camera1フォルダー、camera2フォルダー、annotations.csvファイルは、コンピューティング先のファイルシステムの次のフォルダー構造からアクセスできます:/INPUT_DATA ├── account-a │ ├── container1 │ │ └── camera1 │ │ ├── image1.jpg │ │ └── image2.jpg │ └── container2 │ └── camera2 │ ├── image1.jpg │ └── image2.jpg └── account-b └── container1 └── annotations.csvdirect: Azure Machine Learning データ ランタイムを経由するのではなく、他の API を介して URI からデータを直接読み取りたい場合があります。 たとえば、boto s3 クライアントを使用して、(仮想ホステッド スタイルまたはパス スタイルhttpsの URL を使用して) s3 バケット上のデータにアクセスしたい場合があるかもしれません。 モードを使用すれば、入力の URI をdirectとして取得できます。 ダイレクト モードの使用例は Spark ジョブに見ることができます。これはspark.read_*()メソッドが URI の処理方法を把握しているためです。 Spark 以外のジョブの場合、アクセス資格情報を管理する責任はお客様にあります。 たとえば、明示的にコンピューティング MSI を使用するか、ブローカー アクセスを使用する必要があります。

次の表では、さまざまな種類、モード、入力、出力の組み合わせに対して使用できるモードを示します。
| タイプ | [入力または出力] | upload |
download |
ro_mount |
rw_mount |
direct |
eval_download |
eval_mount |
|---|---|---|---|---|---|---|---|---|
uri_folder |
入力 | ✓ | ✓ | ✓ | ||||
uri_file |
入力 | ✓ | ✓ | ✓ | ||||
mltable |
入力 | ✓ | ✓ | ✓ | ✓ | ✓ | ||
uri_folder |
出力 | ✓ | ✓ | |||||
uri_file |
出力 | ✓ | ✓ | |||||
mltable |
出力 | ✓ | ✓ | ✓ |
ダウンロード
ダウンロード モードでは、すべての入力データがコンピューティング先のローカル ディスク (SSD) にコピーされます。 Azure Machine Learning データ ランタイムは、すべてのデータがコピーされると、ユーザー トレーニング スクリプトを起動します。 ユーザー スクリプトが起動すると、他のファイルと同様に、ローカル ディスクからデータを読み取ります。 ジョブが完了すると、コンピューティング先のディスクからデータが削除されます。
| 長所 | 短所 |
|---|---|
| トレーニングが開始されると、トレーニング スクリプトがすべてのデータをコンピューティング先のローカル ディスク (SSD) で利用できるようになります。 Azure ストレージやネットワークの操作は必要ありません。 | データセットは、コンピューティング先のディスクに完全に収まる必要があります。 |
| 起動後のユーザー スクリプトには、ストレージ/ネットワークの信頼性と依存関係はありません。 | データセット全体がダウンロードされます (トレーニングでデータのごく一部のみをランダムに選択する必要がある場合、ダウンロードの多くは無駄になります)。 |
| Azure Machine Learning データ ランタイムでは、ダウンロードを並列処理し (小さなファイルが多いと大きな違いが出る)、ネットワーク/ストレージのスループットを最大化できます。 | ジョブは、すべてのデータがコンピューティング先のローカル ディスクにダウンロードされるまで待機します。 送信されたディープ ラーニング ジョブの場合、GPU はデータの準備ができるまでアイドル状態になります。 |
| FUSE レイヤーによって避けられないオーバーヘッドは追加されません (ラウンドトリップ: ユーザー スクリプトのユーザー空間呼び出し→カーネル→ユーザー空間ヒューズ デーモン→カーネル→ユーザー空間内のユーザー スクリプトへの応答) | ダウンロードが完了した後、ストレージの変更はデータに反映されません。 |
ダウンロードを使用する状況
- データが、他のトレーニングに干渉することなくコンピューティング先のディスクに収まるくらい小さい場合
- トレーニングでデータセットの大部分またはすべてを使用する場合
- トレーニングでデータセットからファイルを複数回読み取る場合
- トレーニングで大きなファイルのランダムな位置にジャンプする必要がある場合
- トレーニングが開始される前に、すべてのデータがダウンロードされるまで待つことができる場合
使用可能なダウンロード設定
ジョブ内の次の環境変数を使用して、ダウンロード設定を調整できます:
| 環境変数の名前 | タイプ | Default value | 説明 |
|---|---|---|---|
RSLEX_DOWNLOADER_THREADS |
u64 | NUMBER_OF_CPU_CORES * 4 |
ダウンロードが使用できる同時実行スレッドの数 |
AZUREML_DATASET_HTTP_RETRY_COUNT |
u64 | 7 | 一時的なエラーから回復するための個々のストレージ/ http 要求の再試行回数。 |
ジョブでは、環境変数を設定することで、上記の既定値を変更できます。次に例を示します:
簡潔にするために、ジョブで環境変数を定義する方法のみを示します。
from azure.ai.ml import command
env_var = {
"RSLEX_DOWNLOADER_THREADS": 64,
"AZUREML_DATASET_HTTP_RETRY_COUNT": 10
}
job = command(
environment_variables=env_var
)
ダウンロード パフォーマンスのメトリック
コンピューティング先の VM サイズは、データのダウンロード時間に影響します。 具体的な内容は次のとおりです。
- コアの数。 使用可能なコアが多いほど、多くの並列処理ができるため、ダウンロード速度が速くなります。
- 必要なネットワーク帯域幅。 Azure の各 VM には、ネットワーク インターフェイス カード (NIC) からの最大スループットがあります。
注
A100 GPU VM の場合、Azure Machine Learning データ ランタイムは、コンピューティング先にデータをダウンロードするときに NIC (ネットワーク インターフェイス カード) を飽和状態にすることができます (最大 24 Gbit/秒): 理論上可能な最大スループット。
次の表は、Azure Machine Learning データ ランタイムが Standard_D15_v2 VM 上の 100 GB ファイル (20cores、25 Gbit/秒のネットワーク スループット) に対して処理できるダウンロード パフォーマンスを示しています:
| データ構造 | ダウンロードのみ (秒) | MD5 のダウンロードと計算 (秒) | 達成されたスループット (Gbit/秒) |
|---|---|---|---|
| 10 x 10 GB のファイル | 55.74 | 260.97 | 14.35 Gbit/秒 |
| 100 x 1 GB のファイル | 58.09 | 259.47 | 13.77 Gbit/秒 |
| 1 x 100 GB のファイル | 96.13 | 300.61 | 8.32 Gbit/秒 |
大きなファイルを小さなファイルに分割すると、並列処理によってダウンロード パフォーマンスが向上することがわかります。 ストレージ要求の送信に必要な時間が、ペイロードのダウンロードに費やす時間に対して長くなるため、ファイルが小さくなりすぎないようにすることをお勧めします (4 MB 未満)。 詳細については、「小さなファイルが多いことの問題」をご覧ください。
マウント (ストリーミング)
マウント モードでは、Azure Machine Learning データ機能は FUSE (ユーザー空間内のファイルシステム) Linux 機能を使用して、エミュレートされたファイルシステムを作成します。 すべてのデータをコンピューティング先のローカル ディスク (SSD) にダウンロードする代わりに、ランタイムはユーザーのスクリプト アクションにリアルタイムで対応できます。 たとえば、"open file"、"read 2-KB chunk from position X"、"list directory content" などです。
| 長所 | 短所 |
|---|---|
| コンピューティング先のローカル ディスク容量を超えるデータを使用できます (コンピューティング ハードウェアによって制限されません) | Linux FUSE モジュールのオーバーヘッドが追加されます。 |
| トレーニングの開始時に遅延がありません (ダウンロード モードとは異なります)。 | ユーザーのコード動作への依存関係 (単一スレッド マウント内の小さなファイルを順番に読み取るトレーニング コードもストレージからデータを要求する場合、ネットワークまたはストレージのスループットが最大化されない可能性があります)。 |
| 使用シナリオに合わせて調整するためのさらに多くの設定を使用できます。 | Windows はサポートされません。 |
| トレーニングに必要なデータのみがストレージから読み取られます。 |
マウントを使用するタイミング
- データは大きく、コンピューティング 先のローカル ディスクには収まりません。
- クラスター内の各計算ノードが、データセット全体 (csv ファイルのランダムなファイルまたは行の選択など) を読み取る必要がない場合。
- トレーニングの開始前にすべてのデータのダウンロードを待機する遅延が問題になる可能性がある場合 (GPU のアイドル時間)。
使用可能なマウント設定
ジョブで次の環境変数を使用して、マウント設定を調整できます:
| 環境変数名 | タイプ | 既定値 | 説明 |
|---|---|---|---|
DATASET_MOUNT_ATTRIBUTE_CACHE_TTL |
u64 | 未設定 (キャッシュに有効期限はありません) |
getattr 呼び出しの結果をキャッシュに保持し、ストレージからのこの情報の後続の要求を回避するために必要な時間 (ミリ秒単位)。 |
DATASET_RESERVED_FREE_DISK_SPACE |
u64 | 150 MB | コンピューティングを正常に保つためのシステム構成を目的としています。 他の設定の値に関係なく、Azure Machine Learning データ ランタイムではディスク領域の最後の RESERVED_FREE_DISK_SPACE バイトは使用されません。 |
DATASET_MOUNT_CACHE_SIZE |
usize | 無制限 | 使用できるディスク領域のマウント量を制御します。 正の値を指定すると、絶対値がバイト単位で設定されます。 負の値は、空き領域を残すディスク領域の量を設定します。 この表では、より多くのディスク キャッシュ オプションを提供します。 利便性のため、KB、MB、GB をサポートしています。 |
DATASET_MOUNT_FILE_CACHE_PRUNE_THRESHOLD |
f64 | 1.0 | ボリューム マウントでは、キャッシュが AVAILABLE_CACHE_SIZE * DATASET_MOUNT_FILE_CACHE_PRUNE_THRESHOLD までいっぱいになるとキャッシュの排除が開始されます。 値は 0 から 1 の範囲内である必要があります。 これを < 1 に設定すると、前にバックグラウンド キャッシュの排除がトリガーされます。
AVAILABLE_CACHE_SIZE は、直接変更または表示できる環境変数ではありません。 このコンテキストでは、"システムがキャッシュ用に利用可能と計算するバイト数" を指します。この値は、ディスク サイズ、システム正常性に必要なディスク領域の容量、環境変数 (DATASET_RESERVED_FREE_DISK_SPACE や DATASET_MOUNT_CACHE_SIZE など) で設定された構成などの要因によって異なります。 |
DATASET_MOUNT_FILE_CACHE_PRUNE_TARGET |
f64 | 0.7 | キャッシュの排除は、キャッシュ領域の少なくとも (1-DATASET_MOUNT_FILE_CACHE_PRUNE_TARGET) を解放しようとします。 |
DATASET_MOUNT_READ_BLOCK_SIZE |
usize | 2 MB | ストリーミング読み取りブロック サイズ。 ファイルが十分に大きい場合は、少なくとも DATASET_MOUNT_READ_BLOCK_SIZE のデータをストレージから要求し、ヒューズがより少ない量の読み取り操作を要求した場合でもキャッシュします。 |
DATASET_MOUNT_READ_BUFFER_BLOCK_COUNT |
usize | 32 | プリフェッチするブロックの数 (ブロック k の読み取りによって、ブロック k+1、...、k.+DATASET_MOUNT_READ_BUFFER_BLOCK_COUNT のバックグラウンド プリフェッチがトリガーされます) |
DATASET_MOUNT_READ_THREADS |
usize | NUMBER_OF_CORES * 4 |
バックグラウンド プリフェッチ スレッドの数。 |
DATASET_MOUNT_BLOCK_BASED_CACHE_ENABLED |
[bool] | 偽り | ブロックベースのキャッシュを有効にします。 |
DATASET_MOUNT_MEMORY_CACHE_SIZE |
usize | 128 MB | ブロックベースのキャッシュにのみ適用されます。 RAM ブロックベースのキャッシュのサイズを使用できます。 値が 0 の場合、メモリ キャッシュが完全に無効になります。 |
DATASET_MOUNT_BLOCK_FILE_CACHE_ENABLED |
[bool] | ほんとう | ブロックベースのキャッシュにのみ適用されます。 true に設定すると、ブロックベースのキャッシュはローカル ハード ドライブを使用してブロックをキャッシュします。 |
DATASET_MOUNT_BLOCK_FILE_CACHE_MAX_QUEUE_SIZE |
usize | 512 MB | ブロックベースのキャッシュにのみ適用されます。 ブロックベースのキャッシュは、キャッシュされたブロックをバックグラウンドでローカル ディスクに書き込みます。 この設定では、ローカル ディスク キャッシュへのフラッシュを待機しているブロックを保存するために使用できるメモリ マウントの量を制御します。 |
DATASET_MOUNT_BLOCK_FILE_CACHE_WRITE_THREADS |
usize | NUMBER_OF_CORES * 2 |
ブロックベースのキャッシュにのみ適用されます。 ダウンロードしたブロックをコンピューティング先のローカル ディスクに書き込むために、ブロックベースのキャッシュが使用するバックグラウンド スレッドの数。 |
DATASET_UNMOUNT_TIMEOUT_SECONDS |
u64 | 30 |
unmount によりマウント メッセージ ループが強制的に終了される前に、保留中のすべての操作 (フラッシュ呼び出しなど) が (適切に) 完了するまでの時間 (秒)。 |
ジョブでは、環境変数を設定することで、上記の既定値を変更できます。次に例を示します:
from azure.ai.ml import command
env_var = {
"DATASET_MOUNT_BLOCK_FILE_CACHE_ENABLED": True
}
job = command(
environment_variables=env_var
)
ブロックベースのオープン モード
ブロックベースのオープン モードでは、各ファイルは定義済みのサイズのブロックに分割されます (最後のブロックを除く)。 指定した位置からの読み取り要求は、対応するブロックをストレージから要求し、要求されたデータを直ちに返します。 読み取りでは、複数のスレッド (シーケンシャル読み取り用に最適化) を使用して、N 個の次のブロックのバックグラウンド プリフェッチもトリガーされます。 ダウンロードしたブロックは、2 つのレイヤー キャッシュ (RAM とローカル ディスク) にキャッシュされます。
| 長所 | 短所 |
|---|---|
| トレーニング スクリプトへの高速なデータ配信 (まだ要求されていないチャンクのブロックが少なくなります)。 | ランダム読み取りでは、事前にプリフェッチされたブロックが無駄になる可能性があります。 |
| より多くの作業がバックグラウンド スレッド (プリフェッチまたはキャッシュ) にオフロードされます。 その後、トレーニングを続行できます。 | ローカル ディスク キャッシュ上のファイルからの直接読み取りと比較して、キャッシュ間を移動するためのオーバーヘッドが追加されます (ファイル全体キャッシュ モードなど)。 |
| 要求されたデータ (およびプリフェッチ) のみがストレージから読み取られます。 | |
| 十分に小さいデータの場合、高速 RAM ベースのキャッシュが使用されます。 |
ブロックベースのオープン モードを使用するタイミング
ランダムなファイルの場所からの高速読み取りが必要な場合を除き、ほとんどのシナリオで推奨されます。 そのような場合、[ファイル キャッシュ全体を開く] モードを使用します。
ファイル キャッシュ全体を開く
ファイル全体モードでは、マウント フォルダーの下のファイルが開かれると (たとえば f = open(path, args))、ファイル全体がディスク上のコンピューティング先キャッシュ フォルダーにダウンロードされるまで呼び出しがブロックされます。 それ以降のすべての読み取り呼び出しはキャッシュされたファイルにリダイレクトされるため、ストレージ操作は必要ありません。 キャッシュに現在のファイルが収まる十分な空き領域がない場合、マウントは、最も長い間使われていないファイルをキャッシュから削除することでデータを少なくしようとします。 ファイルが (キャッシュ設定に関して) ディスクに収まらない場合、データ ランタイムはストリーミング モードにフォールバックします。
| 長所 | 短所 |
|---|---|
| ファイルを開いた後、ストレージの信頼性とスループットの依存関係はありません。 | OPEN の呼び出しは、ファイル全体がダウンロードされるまでブロックされます。 |
| 高速ランダム読み取り (ファイルのランダムな場所からチャンクを読み取ります)。 | ファイルの一部が不要な場合でも、ファイル全体がストレージから読み取られます。 |
いつ使用するか
128 MB を超える比較的大きなファイルに対してランダム読み取りが必要な場合。
使用法
ジョブで環境変数 DATASET_MOUNT_BLOCK_BASED_CACHE_ENABLED を false に設定します:
from azure.ai.ml import command
env_var = {
"DATASET_MOUNT_BLOCK_BASED_CACHE_ENABLED": False
}
job = command(
environment_variables=env_var
)
マウント: リスティング ファイル
何百万ものファイルを操作する場合、再帰的リスト (例: ls -R /mnt/dataset/folder/) を避けてください。 再帰的リストは、親ディレクトリのディレクトリ内容を一覧表示する多くの呼び出しをトリガーします。 その後、すべての子レベルで、内部の各ディレクトリに対して個別の再帰呼び出しが必要になります。 通常、Azure Storage では、1 つのリスト要求につき 5,000 個の要素のみを返すことができます。 その結果、それぞれに 10 個のファイルが含まれるフォルダーを 100 万個含む再帰的リストには、ストレージに 1,000,000 / 5000 + 1,000,000 = 1,000,200 件の要求が必要となります。 これに対し、10,000 個のファイルを含む 1,000 個のフォルダーでは、再帰的な一覧に対するストレージへの要求は 1,001 個だけで済みます。
Azure Machine Learning マウントでは、遅延形式でリストが処理されます。 したがって、多数の小さなファイルを一覧表示するには、完全なリストを返すクライアント ライブラリ呼び出し (Python の os.scandir() など) ではなく、反復的なクライアント ライブラリ呼び出し (Python の os.listdir() など) を使用することをお勧めします。 反復的なクライアント ライブラリ呼び出しはジェネレーターを返します。つまり、リスト全体が読み込まれるまで待機する必要はありません。 その後、より速く進むことができます。
この表は、Python の os.scandir() と os.listdir() 関数がフラット構造の最大 4 M のファイルを含むフォルダーを一覧表示するために必要な時間を比較したものです。
| メトリック | os.scandir() |
os.listdir() |
|---|---|---|
| 最初のエントリを取得する時間 (秒) | 0.67 | 553.79 |
| 最初の 50,000 エントリを取得する時間 (秒) | 9.56 | 562.73 |
| すべてのエントリを取得する時間 (秒) | 558.35 | 582.14 |
一般的なシナリオに最適なマウント設定
一般的なシナリオによっては、Azure Machine Learning ジョブで設定する必要がある最適なマウント設定が示されています。
大きなファイルを 1 回連続して読み取る (csv ファイル内の行を処理する)
Azure Machine Learning ジョブの environment_variables セクションに、次のマウント設定を含めます:
注
サーバーレス コンピューティングを使用するには、このコードで compute="cpu-cluster", を削除します。
from azure.ai.ml import command
env_var = {
"DATASET_MOUNT_BLOCK_BASED_CACHE_ENABLED": True, # Enable block-based caching
"DATASET_MOUNT_BLOCK_FILE_CACHE_ENABLED": False, # Disable caching on disk
"DATASET_MOUNT_MEMORY_CACHE_SIZE": 0, # Disabling in-memory caching
# Increase the number of blocks used for prefetch. This leads to use of more RAM (2 MB * #value set).
# Can adjust up and down for fine-tuning, depending on the actual data processing pattern.
# An optimal setting based on our test ~= the number of prefetching threads (#CPU_CORES * 4 by default)
"DATASET_MOUNT_READ_BUFFER_BLOCK_COUNT": 80,
}
job = command(
environment_variables=env_var
)
複数のスレッドから大きなファイルを 1 回読み取る (複数のスレッドでパーティション分割された csv ファイルを処理する)
Azure Machine Learning ジョブの environment_variables セクションに、次のマウント設定を含めます:
from azure.ai.ml import command
env_var = {
"DATASET_MOUNT_BLOCK_BASED_CACHE_ENABLED": True, # Enable block-based caching
"DATASET_MOUNT_BLOCK_FILE_CACHE_ENABLED": False, # Disable caching on disk
"DATASET_MOUNT_MEMORY_CACHE_SIZE": 0, # Disabling in-memory caching
}
job = command(
environment_variables=env_var
)
複数のスレッドから数百万個の小さなファイル (画像) を 1 回読み取る (画像に対する単一エポック トレーニング)
Azure Machine Learning ジョブの environment_variables セクションに、次のマウント設定を含めます:
from azure.ai.ml import command
env_var = {
"DATASET_MOUNT_BLOCK_BASED_CACHE_ENABLED": True, # Enable block-based caching
"DATASET_MOUNT_BLOCK_FILE_CACHE_ENABLED": False, # Disable caching on disk
"DATASET_MOUNT_MEMORY_CACHE_SIZE": 0, # Disabling in-memory caching
}
job = command(
environment_variables=env_var
)
複数のスレッドから数百万個の小さなファイル (画像) を複数回読み取る (画像に対する複数のエポック トレーニング)
Azure Machine Learning ジョブの environment_variables セクションに、次のマウント設定を含めます:
from azure.ai.ml import command
env_var = {
"DATASET_MOUNT_BLOCK_BASED_CACHE_ENABLED": True, # Enable block-based caching
}
job = command(
environment_variables=env_var
)
ランダム シークを使用した大きなファイルの読み取り (マウントされたフォルダーからのファイル データベースの提供など)
Azure Machine Learning ジョブの environment_variables セクションに、次のマウント設定を含めます:
from azure.ai.ml import command
env_var = {
"DATASET_MOUNT_BLOCK_BASED_CACHE_ENABLED": False, # Disable block-based caching
}
job = command(
environment_variables=env_var
)
データ読み込みのボトルネックの診断と解決
Azure Machine Learning ジョブがデータを使用して実行される場合、入力の mode は、ストレージからバイトを読み取り、コンピューティング先のローカル SSD ディスクにキャッシュする方法を決定します。 ダウンロード モードの場合、ユーザー コードが実行を開始する前に、ディスク上のすべてのデータ キャッシュが実行されます。 いくつかの要因が最大ダウンロード速度に影響します。
- 並列スレッドの数
- ファイルの数
- ファイル サイズ
マウント モードの場合、データのキャッシュを開始する前に、ユーザー コードがファイルを開き始める必要があります。 マウント設定が異なると、読み取りとキャッシュの動作が異なります。 さまざまな要因が、ストレージからデータが読み込まれる速度に影響します。
- コンピューティングするデータの局所性: ストレージとコンピューティング先の場所は同じである必要があります。 ストレージとコンピューティング先が異なるリージョンにある場合、データをリージョン間で転送する必要があるため、パフォーマンスが低下します。 データがコンピューティングと併置されるようにする方法の詳細については、「データをコンピューティングと併置する」を参照してください。
-
コンピューティング先のサイズ: 小さなコンピューティングでは、より大きなコンピューティング サイズと比較してコア数が少なく (並列処理が少なくなります)、予想されるネットワーク帯域幅が小さくなります。どちらの要因もデータ読み込みのパフォーマンスに影響します。
- たとえば、
Standard_D2_v2(2 コア、1,500 Mbps NIC) などの小さな VM サイズを使用し、50,000 MB (50 GB) のデータを読み込もうとする場合、最も達成可能なデータ読み込み時間は最大 270 秒です (187.5 MB/秒のスループットで NIC を飽和状態にすると仮定)。 これに対し、Standard_D5_v2(16 コア、12,000 Mbps) では、同じデータが約 33 秒で読み込まれます (1500 MB/秒のスループットで NIC を飽和すると仮定した場合)。
- たとえば、
- ストレージ層: ほとんどのシナリオ (大規模言語モデル (LLM) を含む) では、Standard ストレージが最適なコスト/パフォーマンス プロファイルを提供します。 ただし、小さいファイルが多数ある場合は、Premium ストレージの方がコスト/パフォーマンス プロファイルが向上します。 詳細については、「Azure Storage のオプション」をご覧ください。
- ストレージの負荷: ストレージ アカウントの負荷が高い場合 (データを要求しているクラスター内の多くの GPU ノードなど)、ストレージのエグレス容量に達するリスクがあります。 詳細については、「ストレージの負荷」をご覧ください。 並列でアクセスする必要がある小さなファイルが多数ある場合は、ストレージの要求制限に達することがあります。 エグレス容量とストレージ要求の両方の制限に関する最新情報については、「Standard ストレージ アカウントのスケール ターゲット」をご覧ください。
- ユーザー コードのデータ アクセス パターン: マウント モードを使用すると、コード内のオープン/読み取りアクションに基づいてデータがフェッチされます。 たとえば、大きなファイルでランダムにセクションを読み取る場合、マウントの既定のデータ プリフェッチ設定によって、読み取られないブロックがダウンロードされる可能性があります。 スループットを最大にするには、いくつかの設定を調整する必要がある場合があります。 詳細については、「一般的なシナリオに最適なマウント設定」をご覧ください。
ログを使用した問題の診断
ジョブからデータ ランタイムのログにアクセスするには、次の操作を実行します:
- ジョブ ページから [出力 + ログ] タブを選択します。
- system_logs フォルダーを選択し、その後に data_capability フォルダーを選択します。
- 2 つのログ ファイルが表示されます:


data-capability.log のログ ファイルには、主要なデータ読み込みタスクに費やされた時間に関する概要情報が表示されます。 たとえば、データをダウンロードすると、ランタイムはダウンロード アクティビティの開始時刻と終了時刻をログします。
INFO 2023-05-18 17:14:47,790 sdk_logger.py:44 [28] - ActivityStarted, download
INFO 2023-05-18 17:14:50,295 sdk_logger.py:44 [28] - ActivityCompleted: Activity=download, HowEnded=Success, Duration=2504.39 [ms]
ダウンロード スループットが VM サイズに対して予想されるネットワーク帯域幅の数分の一である場合は、ログ ファイルの rslex.log.<タイプスタンプ>を調べることができます。 このファイルには、Rust ベースのランタイムからのすべての詳細なログが含まれています。たとえば、並列処理は次のようになります。
2023-05-18T14:08:25.388670Z INFO copy_uri:copy_uri:copy_dataset:write_streams_to_files:collect:reduce:reduce_and_combine:reduce:get_iter: rslex::prefetching: close time.busy=23.2µs time.idle=1.90µs sessionId=012ea46a-341c-4258-8aba-90bde4fdfb51 source=Dataset[Partitions: 1, Sources: 1] file_name_column=None break_on_first_error=true skip_existing_files=false parallelization_degree=4 self=Dataset[Partitions: 1, Sources: 1] parallelization_degree=4 self=Dataset[Partitions: 1, Sources: 1] parallelization_degree=4 self=Dataset[Partitions: 1, Sources: 1] parallelization_degree=4 i=0 index=0
2023-05-18T14:08:25.388731Z INFO copy_uri:copy_uri:copy_dataset:write_streams_to_files:collect:reduce:reduce_and_combine:reduce: rslex::dataset_crossbeam: close time.busy=90.9µs time.idle=9.10µs sessionId=012ea46a-341c-4258-8aba-90bde4fdfb51 source=Dataset[Partitions: 1, Sources: 1] file_name_column=None break_on_first_error=true skip_existing_files=false parallelization_degree=4 self=Dataset[Partitions: 1, Sources: 1] parallelization_degree=4 self=Dataset[Partitions: 1, Sources: 1] parallelization_degree=4 self=Dataset[Partitions: 1, Sources: 1] parallelization_degree=4 i=0
2023-05-18T14:08:25.388762Z INFO copy_uri:copy_uri:copy_dataset:write_streams_to_files:collect:reduce:reduce_and_combine:combine: rslex::dataset_crossbeam: close time.busy=1.22ms time.idle=9.50µs sessionId=012ea46a-341c-4258-8aba-90bde4fdfb51 source=Dataset[Partitions: 1, Sources: 1] file_name_column=None break_on_first_error=true skip_existing_files=false parallelization_degree=4 self=Dataset[Partitions: 1, Sources: 1] parallelization_degree=4 self=Dataset[Partitions: 1, Sources: 1] parallelization_degree=4 self=Dataset[Partitions: 1, Sources: 1] parallelization_degree=4
rslex.log ファイルは、マウント モードまたはダウンロード モードを選択したかどうかに関係なく、すべてのファイル コピーの詳細を示します。 また、使用される設定 (環境変数) についても説明します。 デバッグを開始するには、一般的なシナリオに最適なマウント設定を設定したかどうかをチェックします。
Azure Storage を監視する
Azure portal で、ストレージ アカウントを選択し、[メトリック] を選択してストレージ メトリックを表示できます。

その後、SuccessE2ELatency と SuccessServerLatency をプロットします。 メトリックで SuccessE2ELatency が高く、SuccessServerLatency が低い場合は、使用可能なスレッドが限られているか、CPU、メモリ、ネットワーク帯域幅などのリソースが不足しています。その場合は次のようにしてください。
- Azure Machine Learning スタジオの監視ビューを使用して、ジョブの CPU 使用率とメモリ使用率をチェックします。 CPU とメモリが不足している場合は、コンピューティング先の VM サイズを増やすことを検討します。
- ダウンロードしていて、CPU とメモリを使用していない場合は、
RSLEX_DOWNLOADER_THREADSを増やすことを検討してください。 mount を使用する場合、プリフェッチを増やすためにDATASET_MOUNT_READ_BUFFER_BLOCK_COUNTを増やし、読み取りスレッドを増やすためにDATASET_MOUNT_READ_THREADSを増やす必要があります。
メトリックで SuccessE2ELatency と SuccessServerLatency が低いが、クライアントの待機時間が長いことが示されている場合は、サービスに到達するストレージ要求の遅延を示しています。 次のことをチェックする必要があります:
- マウントまたはダウンロード (
DATASET_MOUNT_READ_THREADS/RSLEX_DOWNLOADER_THREADS) に使用されるスレッドの数が、コンピューティング先で使用可能なコアの数に対して低すぎないかどうか。 設定が低すぎる場合は、スレッドの数を増やします。 - ダウンロード (
AZUREML_DATASET_HTTP_RETRY_COUNT) の再試行回数が多すぎないかどうか。 多すぎる場合は、再試行回数を減らします。
ジョブ中のディスク使用量を監視する
Azure Machine Learning スタジオから、ジョブの実行中にコンピューティング先のディスク IO と使用状況を監視することもできます。 ジョブに移動し、[監視] タブを選択します。このタブには、ジョブのリソースに関する分析情報が 30 日間のローリング ベースで表示されます。 次に例を示します。

注
ジョブ監視では、Azure Machine Learning が管理するコンピューティング リソースのみがサポートされます。 実行時間が 5 分未満のジョブには、このビューを設定できるだけの十分なデータがありません。
Azure Machine Learning データ ランタイムでは、コンピューティングを正常に保つためにディスク領域の最後の RESERVED_FREE_DISK_SPACE バイトは使用されません (既定値は 150MB です)。 ディスクがいっぱいの場合、コードはファイルを出力として宣言せずにディスクにファイルを書き込みます。 そのため、コードをチェックして、データが一時ディスクに誤って書き込まれないようにします。 一時ディスクにファイルを書き込む必要があり、そのリソースがいっぱいになっている場合は、次のことを検討します:
- VM サイズを、より大きな一時ディスクを持つサイズに増やします
- キャッシュ データ (
DATASET_MOUNT_ATTRIBUTE_CACHE_TTL) に TTL を設定して、ディスクからデータを消去します
データをコンピューティングと併置する
注意
ストレージとコンピューティングが異なるリージョンにある場合、データをリージョン間で転送する必要があるため、パフォーマンスが低下します。 これにより、コストが増加します。 ストレージ アカウントとコンピューティング リソースが同じリージョンにあることを確認してください。
データと Azure Machine Learning ワークスペースが異なるリージョンに保存されている場合は、azcopy ユーティリティを使用して、同じリージョンのストレージ アカウントにデータをコピーすることをお勧めします。 AzCopy では、サーバー間 API が使用されます。そのため、データはストレージ サーバー間で直接コピーされます。 これらのコピー操作では、コンピューターのネットワーク帯域幅が使用されません。
AZCOPY_CONCURRENCY_VALUE 環境変数を使用して、これらの操作のスループットを上げることができます。 詳細については、「コンカレンシーの増加」をご覧ください。
ストレージの負荷
1 つのストレージ アカウントは、高い負荷を受ける場合に調整される可能性があります。次のような場合があります:
- ジョブで多くの GPU ノードが使用される場合
- ストレージ アカウントで、ジョブの実行時に多数のユーザー/アプリが同時にデータにアクセスする場合
このセクションでは、帯域幅調整がワークロードで問題になる可能性があるかどうかを判断するための計算と、帯域幅調整の削減にアプローチする方法について説明します。
帯域幅の制限を計算する
Azure Storage アカウントの既定のエグレス制限は 120 Gbit/秒です。 Azure VM には異なるネットワーク帯域幅があり、ストレージの既定のエグレス容量の最大値に達するために必要なコンピューティング ノードの理論上の数に影響します。
| サイズ | GPU カード | vCPU | メモリ: GiB | 一時ストレージ (SSD) GiB | GPU カードの数 | GPU メモリ: GiB | 必要なネットワーク帯域幅 (Gbit/秒) | ストレージ アカウント エグレスの既定の最大 (Gbit/秒)* | 既定のエグレス容量に達するノードの数 |
|---|---|---|---|---|---|---|---|---|---|
| Standard_ND96asr_v4 | A100 | 96 | 900 | 6,000 | 8 | 40 | 24 | 120 | 5 |
| Standard_ND96amsr_A100_v4 | A100 | 96 | 1900 | 6400 | 8 | 80 | 24 | 120 | 5 |
| Standard_NC6s_v3 | V100 | 6 | 112 | 736 | 1 | 16 | 24 | 120 | 5 |
| Standard_NC12s_v3 | V100 | 12 | 224 | 1474 | 2 | 32 | 24 | 120 | 5 |
| Standard_NC24s_v3 | V100 | 24 | 448 | 2948 | 4 | 64 | 24 | 120 | 5 |
| Standard_NC24rs_v3 | V100 | 24 | 448 | 2948 | 4 | 64 | 24 | 120 | 5 |
| Standard_NC4as_T4_v3 | T4 | 4 | 28 | 180 | 1 | 16 | 8 | 120 | 15 |
| Standard_NC8as_T4_v3 | T4 | 8 | 56 | 360 | 1 | 16 | 8 | 120 | 15 |
| Standard_NC16as_T4_v3 | T4 | 16 | 110 | 360 | 1 | 16 | 8 | 120 | 15 |
| Standard_NC64as_T4_v3 | T4 | 64 | 440 | 2880 | 4 | 64 | 32 | 120 | 3 |
A100 と V100 SKU の両方で、ノードあたりの最大ネットワーク帯域幅は 24 Gbit/秒です。 したがって、1 つのアカウントからデータを読み取る各ノードが理論上最大 24 Gbit/秒近く読み取ることができる場合、5 つのノードでエグレス容量が発生します。 6 つ以上のコンピューティング ノードを使用すると、すべてのノードのデータ スループットが低下し始めます。
重要
ワークロードで A100/V100 の 6 つ以上のノードが必要な場合、またはストレージの既定のエグレス容量 (120Gbit/秒) を超えると思われる場合は、サポートに (Azure portal 経由で) 連絡し、ストレージエグレス制限の引き上げを要求してください。
複数のストレージ アカウントでのスケーリング
ストレージの最大エグレス容量を超えたり、要求レートの制限に達したりする可能性があります。 これらの問題が発生した場合は、"まず" サポートにお問い合わせいただき、ストレージ アカウントの制限を引き上げることをお勧めします。
最大エグレス容量または要求レート制限を引き上げることができない場合は、複数のストレージ アカウント間でデータをレプリケートすることを検討する必要があります。 Azure Data Factory、Azure Storage Explorer、または azcopy を使用して複数のアカウントにデータをコピーし、トレーニング ジョブ内のすべてのアカウントをマウントします。 マウントでアクセスされたデータのみがダウンロードされます。 したがって、トレーニング コードは環境変数から RANK を読み取り、読み取る複数の入力マウントのどれを選択するかを選択できます。 ジョブ定義は、ストレージ アカウントの一覧に渡されます。
$schema: https://azuremlschemas.azureedge.net/latest/commandJob.schema.json
code: src
command: >-
python train.py
--epochs ${{inputs.epochs}}
--learning-rate ${{inputs.learning_rate}}
--data ${{inputs.cifar_storage1}}, ${{inputs.cifar_storage2}}
inputs:
epochs: 1
learning_rate: 0.2
cifar_storage1:
type: uri_folder
path: azureml://datastores/storage1/paths/cifar
cifar_storage2:
type: uri_folder
path: azureml://datastores/storage2/paths/cifar
environment: azureml:AzureML-pytorch-1.9-ubuntu18.04-py37-cuda11-gpu@latest
compute: azureml:gpu-cluster
distribution:
type: pytorch
process_count_per_instance: 1
resources:
instance_count: 2
display_name: pytorch-cifar-distributed-example
experiment_name: pytorch-cifar-distributed-example
description: Train a basic convolutional neural network (CNN) with PyTorch on the CIFAR-10 dataset, distributed via PyTorch.
その後、トレーニング Python コードで RANK を使用して、そのノードに固有のストレージ アカウントを取得できます。
import argparse
import os
parser = argparse.ArgumentParser()
parser.add_argument('--data', nargs='+')
args = parser.parse_args()
world_size = int(os.environ["WORLD_SIZE"])
rank = int(os.environ["RANK"])
local_rank = int(os.environ["LOCAL_RANK"])
data_path_for_this_rank = args.data[rank]
小さなファイルが多いことの問題
ストレージからファイルを読み取る場合、各ファイルに対して要求を行う必要があります。 ファイルごとの要求数は、ファイル サイズと、ファイルの読み取りを処理するソフトウェアの設定によって異なります。
ファイルは、サイズが 1 ~ 4 MB の ブロック で読み取られます。 1 ブロックより小さいファイルは 1 つの要求 (GET file.jpg 0 から 4 MB) で読み取られ、1 ブロックより大きいファイルはブロックごとに 1 つの要求が行われます (GET file.jpg 0 から 4 MB、GET file.jpg 4 から 8 MB)。 この表は、4 MB のブロックより小さいファイルの場合、大きなファイルと比較してストレージ要求が多くあることを示しています。
| ファイル数 | ファイル サイズ | 合計データ サイズ | ブロック サイズ | ストレージ要求数 |
|---|---|---|---|---|
| 2,000,000 | 500 KB | 1 TB (テラバイト) | 4 MB | 2,000,000 |
| 1,000 | 1 GB | 1 TB (テラバイト) | 4 MB | 256,000 |
小さいファイルの場合、待機時間の間隔には、データ転送ではなく、ストレージへの要求の処理が主に含まれます。 そのため、ファイル サイズを増やすために、次の推奨事項を提供します:
- 非構造化データ (画像、ビデオなど) の場合は、小さなファイルをまとめてアーカイブ (zip/tar) し、複数のチャンクで読み取ることができる大きなファイルとして格納します。 これらの大きなアーカイブ ファイルはコンピューティング リソースで開くことができ、PyTorch Archive DataPipes で小さいファイルを抽出できます。
- 構造化データ (CSV、Parquet など) の場合、ETL プロセスを調べて、ファイルが結合されてサイズが大きなるようにします。 Spark には、ファイル サイズを増やすのに役立つ
repartition()メソッドとcoalesce()メソッドがあります。
ファイル サイズを大きくできない場合は、Azure Storage のオプションをご覧ください。
Azure Storage オプション
Azure Storage には、Standard と Premium の 2 つのレベルが用意されています。
| Storage | シナリオ |
|---|---|
| Azure BLOB - Standard (HDD) | データが、より大きな BLOB (画像、ビデオなど) で構成されている。 |
| Azure BLOB - Premium (SSD) | トランザクション レートが高い、オブジェクトが小さい、またはストレージ待機時間の要件が一貫して低い場合 |
ヒント
"多くの" 小さなファイル (KB 規模) は、ストレージのコストが GPU コンピューティングの実行コストよりも少ないため、Premium (SSD) を使用することをお勧めします。
V1 データ資産の読み取り
このセクションでは、V1 の FileDataset と TabularDataset のデータ エンティティを V2 のジョブで読み取る方法について説明します。
FileDataset の読み取り
Input オブジェクトで、type を AssetTypes.MLTABLE に、mode を InputOutputModes.EVAL_MOUNT に指定します。
注
サーバーレス コンピューティングを使用するには、このコードで compute="cpu-cluster", を削除します。
MLClient オブジェクト、MLClient オブジェクト初期化オプション、ワークスペースへの接続方法の詳細については、「ワークスペースへの接続」を参照してください。
from azure.ai.ml import command
from azure.ai.ml.entities import Data
from azure.ai.ml import Input
from azure.ai.ml.constants import AssetTypes, InputOutputModes
from azure.ai.ml import MLClient
ml_client = MLClient.from_config(credential=DefaultAzureCredential())
filedataset_asset = ml_client.data.get(name="<filedataset_name>", version="<version>")
my_job_inputs = {
"input_data": Input(
type=AssetTypes.MLTABLE,
path=filedataset_asset.id,
mode=InputOutputModes.EVAL_MOUNT
)
}
job = command(
code="./src", # Local path where the code is stored
command="ls ${{inputs.input_data}}",
inputs=my_job_inputs,
environment="<environment_name>:<version>",
compute="cpu-cluster",
)
# Submit the command
returned_job = ml_client.jobs.create_or_update(job)
# Get a URL for the job status
returned_job.services["Studio"].endpoint
TabularDataset の読み取り
Input オブジェクトで、type として AssetTypes.MLTABLE を指定し、mode として InputOutputModes.DIRECT を指定します。
注
サーバーレス コンピューティングを使用するには、このコードで compute="cpu-cluster", を削除します。
from azure.ai.ml import command
from azure.ai.ml.entities import Data
from azure.ai.ml import Input
from azure.ai.ml.constants import AssetTypes, InputOutputModes
from azure.ai.ml import MLClient
ml_client = MLClient.from_config(credential=DefaultAzureCredential())
filedataset_asset = ml_client.data.get(name="<tabulardataset_name>", version="<version>")
my_job_inputs = {
"input_data": Input(
type=AssetTypes.MLTABLE,
path=filedataset_asset.id,
mode=InputOutputModes.DIRECT
)
}
job = command(
code="./src", # Local path where the code is stored
command="python train.py --inputs ${{inputs.input_data}}",
inputs=my_job_inputs,
environment="<environment_name>:<version>",
compute="cpu-cluster",
)
# Submit the command
returned_job = ml_client.jobs.create_or_update(job)
# Get a URL for the status of the job
returned_job.services["Studio"].endpoint