この記事では、Azure Machine Learning 自動 ML を使用して、Azure Machine Learning スタジオで自動機械学習トレーニング ジョブを設定します。 この方法では、コードを 1 行も記述せずにジョブを設定できます。 自動 ML は、Azure Machine Learning が特定のデータに最適な機械学習アルゴリズムを選択するプロセスです。 このプロセスにより、機械学習モデルを迅速に生成できます。 詳細については、自動 ML プロセスの概要に関する記事を参照してください。
このチュートリアルでは、スタジオで自動 ML を操作するための概要を説明します。 次の記事では、特定の機械学習モデルを操作するための詳細な手順について説明します。
- 分類: チュートリアル: スタジオで自動 ML を使用して分類モデルをトレーニングする
- 時系列予測: チュートリアル: スタジオで自動 ML を使用して需要を予測する
- 自然言語処理 (NLP): 自動 ML を設定して NLP モデルをトレーニングする (Azure CLI または Python SDK)
- Computer vision: Computer Vision モデルをトレーニングするために AutoML を設定する (Azure CLI または Python SDK)
- 回帰: AutoML を使用して回帰モデルをトレーニングする (Python SDK)
前提条件
Azure サブスクリプション。 Azure Machine Learning 用の無料アカウントまたは有料アカウントを作成できます。
Azure Machine Learning ワークスペースまたはコンピューティング インスタンス。 これらのリソースを準備するには、「クイックスタート: Azure Machine Learning の利用を開始する」を参照してください。
自動 ML トレーニング ジョブに使用するデータ資産。 このチュートリアルでは、既存のデータ資産を選択するか、ローカル ファイル、Web URL、データストアなどのデータ ソースからデータ資産を作成する方法について説明します。 詳細については、データ アセットの作成と管理に関するページを参照してください。
重要
トレーニング データには、次の 2 つの要件があります。
- データは表形式である必要があります。
- 予測する値 (ターゲット列) は、データ内に存在する必要があります。
実験を作成する
次の手順に従って、実験を作成して実行します。
Azure Machine Learning スタジオにサインインし、お使いのサブスクリプションとワークスペースを選択します。
左側のメニューの [作成] セクションで [自動 ML] を選択します。
![Azure Machine Learning スタジオの自動 ML の [作成の概要] ページを示すスクリーンショット。](media/how-to-use-automated-ml-for-ml-models/automated-ml-overview.png?view=azureml-api-2)
スタジオで実験を初めて使用すると、空のリストとドキュメントへのリンクが表示されます。 それ以外の場合、Azure Machine Learning SDK で作成された項目を含む、最近の自動 ML 実験の一覧が表示されます。
[新規の自動機械学習ジョブ] を選択して、[自動 ML ジョブを送信する] プロセスを開始します。
既定では、プロセスは [トレーニング方法] タブの [自動的にトレーニングする] オプションを選択し、構成設定に進みます。
[基本設定] タブで、[ジョブ] 名、[実験] 名などの必要な設定の値を入力します。 必要に応じて、オプションの設定の値を指定することもできます。
次へを選んで続行します。
![Azure Machine Learning スタジオの自動 ML の [作成の概要] ページを示すスクリーンショット。](media/how-to-use-automated-ml-for-ml-models/automated-ml-overview-large.png?view=azureml-api-2#lightbox)
データ資産を特定する
[Task type & data]\(タスクの種類とデータ\) タブで、実験のデータ資産と、データのトレーニングに使用する機械学習モデルを指定します。
このチュートリアルでは、既存のデータ資産を使用するか、ローカル コンピューター上のファイルから新しいデータ資産を作成できます。 スタジオ UI ページは、データ ソースとトレーニング モデルの種類の選択に基づいて変わります。
既存のデータ資産を使用する場合は、「トレーニング モデルを構成する」セクションに進めます。
新しいデータ資産を作成するには、次の手順に従います。
ローカル コンピューター上のファイルから新しいデータ資産を作成するには、[作成] を選択します。
[データ型] ページで、次の手順を実行します。
- [データ資産] の名前を入力します。
- [種類] ドロップダウン リストから [表形式] を選択します。
- [次へ] を選択します。
[データ ソース] ページで、[ローカル ファイルから] を選択します。
Machine Learning スタジオでは、データ ソースを構成するための追加のオプションが左側のメニューに追加されます。
[次へ] を選択し、[Destination storage type]\(コピー先のストレージの種類\) ページに進み、データ資産をアップロードする Azure Storage の場所を指定します。
ワークスペースで自動的に作成される既定のストレージ コンテナーを指定するか、実験に使用するストレージ コンテナーを選択できます。
- [接続の種類] に [Azure Blob Storage] を選択します。
- データストアの一覧で、[workspaceblobstore] を選択します。
- [次へ] を選択します。
[File and folder selection]\(ファイルとフォルダーの選択\) ページで、[ファイルまたはフォルダーのアップロード] ドロップダウン メニューを使用し、[ファイルのアップロード] または [フォルダーのアップロード] オプションを選択します。
- アップロードするデータの場所を参照し、[開く] を選択します。
- ファイルのアップロード後、[次へ] を選択します。
Azure Machine Learning スタジオは、データを検証してアップロードします。
注
データが仮想ネットワークの背後にある場合は、検証をスキップする機能を有効にして、ワークスペースがデータにアクセスできることを確認する必要があります。 詳細については、「Azure 仮想ネットワークで Azure Machine Learning Studio を使用する」を参照してください。
[設定] ページでアップロードしたデータの精度を確認します。 ページ上のフィールドは、データのファイルの種類に基づいて事前設定されます。
フィールド 説明 ファイル形式 ファイルに格納されているデータのレイアウトと種類を定義します。 区切り記号 プレーンテキストまたは他のデータ ストリーム内の個別の独立した領域の間の境界を指定するための 1 つ以上の文字を特定します。 [エンコード] データセットの読み取りに使用する、ビットと文字のスキーマ テーブルを識別します。 列見出し データセットの見出しがある場合、それがどのように処理されるかを示します。 行のスキップ データセット内でスキップされる行がある場合、その行数を示します。 [次へ] を選択して [スキーマ] ページに進みます。 このページは、[設定] の選択内容に基づいて事前設定されます。 各列のデータ型を構成し、列名を確認し、列を管理できます。
- 列のデータ型を変更するには、[種類] ドロップダウン メニューを使用してオプションを選択します。
- データ資産から列を除外するには、列の [組み込み] オプションを切り替えます。
[次へ] を選択して、[レビュー] ページに進みます。 ジョブの構成設定の概要を確認し、[作成] を選択します。
トレーニング モデルを構成する
データ資産の準備ができたら、Azure Machine Learning スタジオは [自動 ML ジョブを送信する] プロセスの [Task type & data]\(タスクの種類とデータ\) タブに戻ります。 新しいデータ資産がページに一覧表示されます。
ジョブの構成を完了するには、次の手順に従います。
[タスクの種類の選択] ドロップダウン メニューを展開し、実験に使用するトレーニング モデルを選択します。 オプションには、分類、回帰、時系列予測、自然言語処理 (NLP)、コンピューター ビジョンなどがあります。 これらのオプションの詳細については、サポートされているタスクの種類の説明を参照してください。
トレーニング モデルを指定したら、一覧からデータセットを選択します。
[次へ] を選択して、[タスクの設定] タブに進みます。
[ターゲット列] ドロップダウン リストで、モデル予測に使用する列を選択します。
トレーニング モデルに応じて、次の必須設定を構成します。
分類: ディープ ラーニングを有効にするかどうかを選択します。
時系列予測: ディープ ラーニングを有効にするかどうかを選択し、必要な設定のユーザー設定を確認します。
[時刻列] を使用して、モデルで使用する時間データを指定します。
1 つ以上の [自動検出] オプションを有効にするかどうかを選択します。 [予測期間の自動検出] などの [自動検出] オプションの選択を解除すると、特定の値を指定できます。 [予測期間] の値は、モデルが将来予測できる時間単位 (分/時間/日/週/月/年) の数を示します。 モデルで将来を予測する期間が延びるほど、モデルの正確性が下がります。
これらの設定を構成する方法の詳細については、自動 ML を使用した時系列予測モデルのトレーニングに関する記事を参照してください。
自然言語処理: 必要な設定のユーザー設定を確認します。
[サブタイプの選択] オプションを使用して、NLP モデルのサブ分類の種類を構成します。 複数クラス分類、複数ラベル分類、名前付きエンティティ認識 (NER) から選択できます。
[スイープの設定] セクションで、[Slack 係数] と [サンプリング アルゴリズム] の値を指定します。
[探索空間] セクションで、[モデル アルゴリズム] オプションのセットを構成します。
これらの設定を構成する方法の詳細については、「自動 ML を設定して NLP モデルをトレーニングする (Azure CLI または Python SDK)」を参照してください。
Computer Vision: 手動スイープを有効にするかどうかを選択し、必要な設定のユーザー設定を確認します。
- [サブタイプの選択] オプションを使用して、コンピューター ビジョン モデルのサブ分類の種類を構成します。 画像分類 (マルチクラスまたはマルチラベル)、オブジェクト検出、多角形 (インスタンスのセグメント化) から選択できます。
これらの設定を構成する方法の詳細については、「Computer Vision モデルをトレーニングするために AutoML を設定する (Azure CLI または Python SDK)」を参照してください。
オプションの設定を指定する
Azure Machine Learning スタジオには、機械学習モデルの選択に基づいて構成できるオプションの設定が用意されています。 以降のセクションでは、追加の設定について説明します。
追加の設定の構成
[追加の構成設定を表示する] オプションを選択すると、トレーニングの準備でデータに対して実行するアクションを確認できます。
[追加構成] ページには、実験の選択とデータに基づく既定値が表示されます。 既定値を使用するか、次の設定を構成できます。
| 設定 | 説明 |
|---|---|
| 主要メトリック | モデルをスコアリングするための主要なメトリックを特定します。 詳細については、モデル メトリックに関する記事を参照してください。 |
| アンサンブル スタッキングを有効にする | アンサンブル学習を可能にし、1 つのモデルを使用するのでなく、複数のモデルを組み合わせることによって、機械学習の結果と予測パフォーマンスが改善されます。 詳細については、「アンサンブル モデル」を参照してください。 |
| サポートされているすべてのモデルを使用する | このオプションを使用して、実験でサポートされているすべてのモデルを使用するかどうかを自動 ML に指示します。 詳細については、各タスクの種類でサポートされているアルゴリズムに関するページを参照してください。 - [ブロックされたモデル] 設定を構成するには、このオプションを選択します。 - [許可されたモデル] 設定を構成するには、このオプションの選択を解除します。 |
| ブロックされたモデル | ([サポートされているすべてのモデルを使用する] が選択されているときに使用可能) ドロップダウン リストを使用し、トレーニング ジョブから除外するモデルを選択します。 |
| 許可されたモデル | ([サポートされているすべてのモデルを使用する] が選択されていないときに使用可能) ドロップダウン リストを使用し、トレーニング ジョブに使用するモデルを選択します。 重要: SDK の実験のためにのみ使用できます。 |
| 最適なモデルの説明 | 自動 ML によって作成された最適なモデルで説明可能性を自動的に表示するには、このオプションを選択します。 |
| 肯定クラス ラベル | バイナリ メトリックの計算に使用する自動 ML のラベルを入力します。 |
特徴量化の設定を構成する
[特徴量化設定の表示] オプションを選択すると、トレーニングの準備でデータに対して実行するアクションを確認できます。
[特徴量化] ページに、データ列の既定の特徴量化手法が表示されます。 自動特徴量化を有効または無効にし、実験の自動特徴量化設定をカスタマイズできます。
![[特徴量化設定の表示] が強調表示された [タスクの種類を選択] ダイアログ ボックスを示すスクリーンショット。](media/how-to-use-automated-ml-for-ml-models/view-featurization.png?view=azureml-api-2#lightbox)
[特徴量化を有効にする] オプションを選択して構成を許可します。
重要
データに数値以外の列が含まれている場合、特徴量化は常に有効になります。
必要に応じて、使用可能な各列を構成します。 次の表は、現在、スタジオで使用可能なカスタマイズの概要です。
列 カスタマイズ 特徴の種類 選択された列の値の型を変更します。 次で補完 データの欠損値を補完する値を選択します。 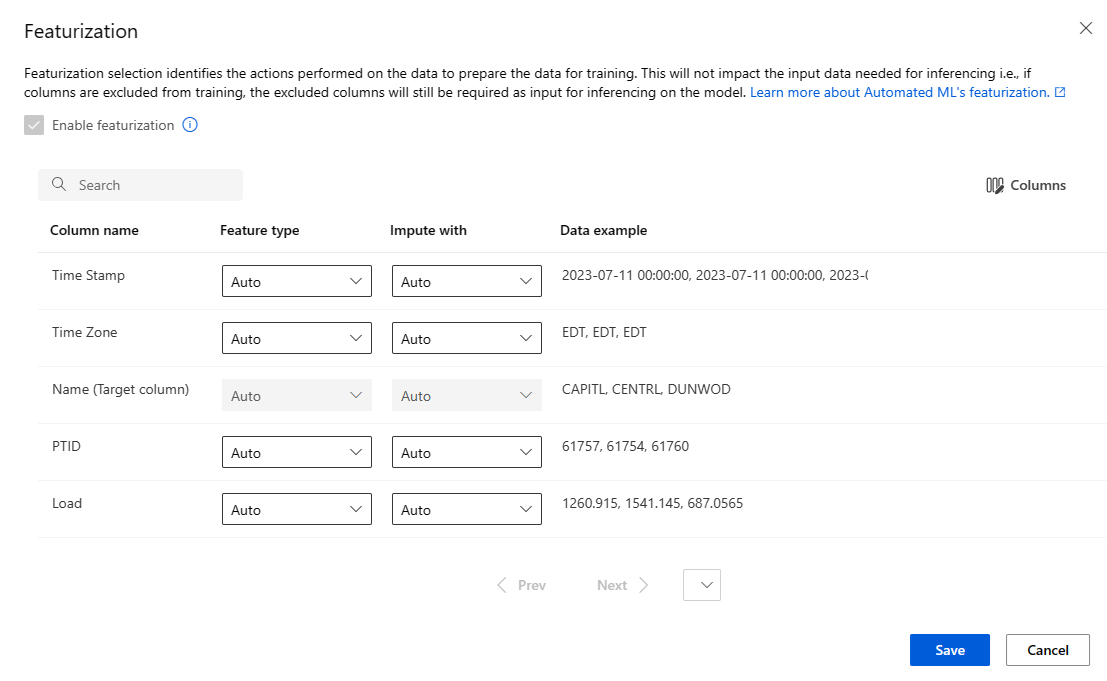

特徴量化の設定は、推論に必要な入力データには影響しません。 トレーニングから列を除外する場合、除外された列は、モデルの推論の入力として引き続き必要です。
ジョブの制限を構成する
[制限] セクションに、次の設定の構成オプションがあります。
| 設定 | 説明 | 価値 |
|---|---|---|
| 最大試行回数 | 自動 ML ジョブ中に試行する試行の最大数を指定します。各試行にはアルゴリズムとハイパーパラメーターの異なる組み合わせがあります。 | 1 ~ 1,000 の整数 |
| 最大同時試行回数 | 並列で実行できる試行ジョブの最大数を指定します。 | 1 ~ 1,000 の整数 |
| 最大ノード数 | 選択したコンピューティング先からこのジョブで使用できるノードの最大数を指定します。 | コンピューティング構成に応じて 1 つ以上 |
| メトリック スコアしきい値 | 反復メトリックしきい値を入力します。 反復がしきい値に達すると、トレーニング ジョブは終了します。 意味のあるモデルには、0 より大きい相関関係があることに注意してください。 それ以外の場合、結果は推測と同じです。 | 境界間の平均メトリックしきい値 [0, 10] |
| 実験のタイムアウト (分) | 実験全体を実行できる最大時間を指定します。 実験が制限に達すると、システムは、すべての試行 (子ジョブ) を含む自動 ML ジョブを取り消します。 | 分数 |
| イテレーション タイムアウト (分) | 各試行ジョブを実行できる最大時間を指定します。 試行ジョブがこの制限に達すると、システムは試行を取り消します。 | 分数 |
| 早期終了の有効化 | 短期的にスコアが向上しない場合にジョブを終了するには、このオプションを使用します。 | ジョブの早期終了を有効にするオプションを選択する |
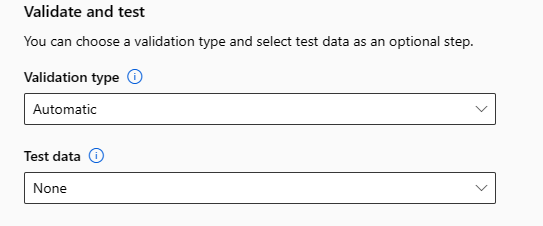
検証とテスト
[検証とテスト] セクションには、次の構成オプションがあります。
トレーニング ジョブに使用する [検証の種類] を指定します。
validation_dataまたはn_cross_validationsのいずれかのパラメーターを明示的に指定しない場合は、1 つのデータセットtraining_dataで指定された行数に応じて、自動 ML によって既定の方法が適用されます。トレーニング データのサイズ 検証の方法 20,000 行を超える トレーニング/検証データの分割が適用されます。 既定では、初期トレーニング データ セットの 10% が検証セットとして取得されます。 次に、その検証セットがメトリックの計算に使用されます。 20,000& 行未満 クロス検証アプローチが適用されます。 フォールドの既定の数は行数によって異なります。
- 1,000 行未満のデータセット: 10 個のフォールドが使用されます
- 1,000 行から 20,000 行のデータセット: 3 個のフォールドが使用されますテスト データ (プレビュー) を指定して、実験の最後に自動 ML によって生成される推奨モデルを評価します。 テスト データセットを指定すると、実験の最後にテスト ジョブが自動的にトリガーされます。 このテスト ジョブは、自動 ML によって推奨された最適なモデルでのみ実行されます。 詳細については、「リモート テスト ジョブの結果を表示する (プレビュー)」を参照してください。
重要
生成されたモデルを評価するためのテスト データセットの提供は、プレビュー機能です。 この機能は試験段階のプレビュー機能であり、随時変更される可能性があります。
テスト データは、トレーニングや検証とは分けて考え、推奨モデルのテスト ジョブの結果が、テスト データのために偏ることがあってはいけません。 詳細については、「トレーニング、検証、テストのデータ」を参照してください。
独自のテスト データセットを指定するか、トレーニング データセットの割合を使用することを選択できます。 テスト データは Azure Machine Learning テーブル データセットの形式である必要があります。
テスト データセットのスキーマは、トレーニング データセットと一致する必要があります。 ターゲット列は省略可能ですが、ターゲット列が示されていない場合、テスト メトリックは計算されません。
テスト データセットは、トレーニング データセットまたは検証データセットと同じにすべきではありません。
予測ジョブでは、トレーニング/テスト分割はサポートされていません。
コンピューティングを構成する
次の手順に従ってコンピューティングを構成します。
[次へ] を選択して、[計算する] タブに進みます。
[コンピューティングの種類を選択] ドロップダウン リストを使用して、データ プロファイルとトレーニング ジョブのオプションを選択します。 オプションには、[コンピューティング クラスター]、[コンピューティング インスタンス]、[サーバーレス] などがあります。
コンピューティングの種類を選択すると、選択内容に基づいてページ上の他の UI が変更されます。
サーバーレス: 現在のページに構成設定が表示されます。 構成する設定の説明について、次の手順に進みます。
コンピューティング クラスターまたはコンピューティング インスタンス: 次のオプションから選択します。
[Select Automated ML compute]\(自動 ML コンピューティングの選択\) ドロップダウン リストを使用して、ワークスペースの既存のコンピューティングを選択し、[次へ] を選択します。 [実験を実行して結果を表示] セクションに進みます。
[新規] を選択して、新しいコンピューティング インスタンスまたはクラスターを作成します。 このオプションを選択すると、[コンピューティングの作成] ページが開きます。 構成する設定の説明について、次の手順に進みます。
サーバーレス コンピューティングまたは新しいコンピューティングの場合は、必要なすべての設定 (*) を構成します。
構成設定は、コンピューティングの種類によって異なります。 次の表は、構成する必要があるさまざまな設定をまとめたものです。
フィールド 説明 コンピューティング名 コンピューティング コンテキストを識別する一意名を入力します。 場所 マシンのリージョンを指定します。 仮想マシンの優先度 低優先度の仮想マシンは低コストですが、コンピューティング ノードが保証されません。 仮想マシンのタイプ 仮想マシンのタイプとして [CPU] または [GPU] を選択します。 仮想マシンの階層 実験の優先順位を選択します。 [仮想マシンのサイズ] コンピューティングの仮想マシン サイズを選択します。 最小/最大ノード データをプロファイリングするには、1 つ以上のノードを指定する必要があります。 コンピューティングの最大ノード数を入力します。 Azure Machine Learning コンピューティングのデフォルトは 6 ノードです。 スケールダウンする前のアイドル時間 (秒) クラスターが自動的に最小ノード数にスケールダウンされるまでのアイドル時間を指定します。 詳細設定 これらの設定を使用すると、ユーザー アカウントと、実験用の既存の仮想ネットワークを構成できます。 必要な設定を構成したら、必要に応じて [次へ] または [作成] を選択します。
新しいコンピューティングの作成には数分かかる場合があります。 作成が完了したら、[次へ] を選択します。
実験を実行して結果を表示
[完了] を選択して実験を実行します。 実験の準備プロセスには最大で 10 分かかることがあります。 トレーニング ジョブで各パイプラインの実行を完了するには、さらに 2 ~ 3 分かかる場合があります。 最適な推奨モデルの RAI ダッシュボードを生成するように指定した場合は、最大で 40 分かかる場合があります。
注
自動 ML のアルゴリズムには特有のランダム性があり、推奨モデルの最終的なメトリック スコア (精度など) にわずかな変動が生じる可能性があります。 自動 ML によって、トレーニングとテストの分割、トレーニングと検証の分割、クロス検証などのデータに対する操作も必要に応じて実行されます。 同じ構成設定とプライマリ メトリックを使用して実験を複数回実行した場合、これらの要因により、各実験の最終的なメトリック スコアに変動が見られる可能性があります。
実験の詳細の表示
[ジョブの詳細] 画面が開き、 [詳細] タブが表示されます。この画面には、上部のジョブ番号の横のステータス バーを含む実験ジョブの概要が表示されます。
[Models](モデル) タブには、メトリック スコアの順で作成されたモデルの一覧が表示されます。 既定では、選択したメトリックに基づいて最高のスコアを付けたモデルが、一覧の先頭になります。 トレーニング ジョブがより多くのモデルを試みるにつれて、演習されたモデルが一覧に追加されます。 この方法を使用すると、これまでに生成されたモデルのメトリックを簡単に比較できます。
トレーニング ジョブの詳細を表示する
完成したモデルのいずれかをドリル ダウンして、トレーニング ジョブの詳細を表示します。 [メトリクス] タブでは、特定のモデルのパフォーマンス メトリック グラフを確認できます。詳細については、「自動機械学習実験の結果を評価」を参照してください。 このページで、モデルのすべてのプロパティに関する詳細と、関連付けられているコード、子ジョブ、およびイメージを確認することもできます。
リモート テスト ジョブの結果を表示する (プレビュー)
テスト データセットを指定した場合、または実験のセットアップ中にトレーニングまたはテスト分割を選択した場合、[Validate and test]\(検証とテスト\) フォームで、自動 ML では、既定で推奨されるモデルを自動的にテストします。 その結果、自動 ML によりテスト メトリックが計算され、推奨されるモデルの品質とその予測が決定されます。
重要
生成されたモデルを評価するためにテスト データセットを使ってモデルをテストする機能はプレビュー段階です。 この機能は試験段階のプレビュー機能であり、随時変更される可能性があります。
この機能は、次の自動 ML シナリオでは使用できません。
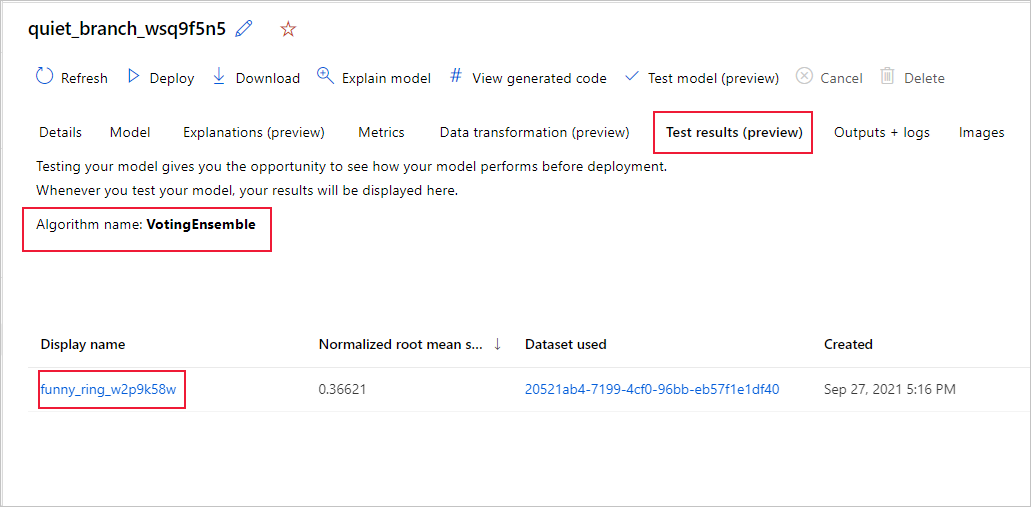
次の手順に従って、推奨されるモデルのテスト ジョブ メトリックを表示します。
スタジオで、[モデル] ページに移動し、最適なモデルを選択します。
[テスト結果 (プレビュー)] タブを選択します。
目的のジョブを選択し、[メトリクス] タブを表示します。
次の手順に従って、テスト メトリックの計算に使用されるテスト予測を表示します。
ページの下部で、[出力データセット] の下にあるリンクを選択して、データセットを開きます。
[データセット] ページで、[探索] タブを選択して、テスト ジョブからの予測を表示します。
予測ファイルは、[出力とログ] タブから表示およびダウンロードすることもできます。Predictions フォルダーを展開して、prediction.csv ファイルを見つけます。
モデル テスト ジョブでは、predictions.csv ファイルが生成され、ワークスペースで作成された既定のデータストアに格納されます。 このデータストアは、同じサブスクリプションを持つすべてのユーザーに表示されます。 テスト ジョブは、テスト ジョブで使用または作成された情報を非公開にする必要があるシナリオにはお勧めできません。
既存の自動 ML モデルをテストする (プレビュー)
実験が完了したら、自動 ML によって自動的に生成されるモデルをテストできます。
重要
生成されたモデルを評価するためにテスト データセットを使ってモデルをテストする機能はプレビュー段階です。 この機能は試験段階のプレビュー機能であり、随時変更される可能性があります。
この機能は、次の自動 ML シナリオでは使用できません。
推奨されるモデルでなく、別の自動 ML 生成モデルをテストする場合は、次の手順に従います。
既存の自動 ML 実験ジョブを選択します。
ジョブの [モデル] タブに移動し、テストする完成モデルを選択します。
モデルの [詳細] ページで、[Test model (preview)]\(モデルのテスト (プレビュー)\) オプションを選択して、[Test model]\(モデルのテスト\) ペインを開きます。
[テスト モデル] ペインで、テスト ジョブに使用するコンピューティング クラスターとテスト データセットを選択します。
[テスト] オプションを選択します。 テスト データセットのスキーマは、トレーニング データセットと一致する必要がありますが、ターゲット列は省略可能です。
モデル テスト ジョブが正常に作成されると、[詳細] ページに成功メッセージが表示されます。 [テスト結果] タブを選択して、ジョブの進行状況を確認します。
テスト ジョブの結果を表示するには、[詳細] ページを開き、「リモート テスト ジョブの結果を表示する (プレビュー)」セクションの手順に従います。
![[Test model]\(モデルのテスト\) フォームを示すスクリーンショット。](media/how-to-use-automated-ml-for-ml-models/test-model-form.png?view=azureml-api-2)
責任ある AI ダッシュボードの作成 (プレビュー)
モデルをより深く理解するために、責任ある AI ダッシュボードを使用して、モデルに関するさまざまな分析情報を確認できます。 この UI を使用すると、最適な自動 ML モデルを評価およびデバッグできます。 責任ある AI ダッシュボードでは、モデルのエラーと公平性の問題を評価し、トレーニング データやテスト データを評価し、モデルの説明を観察することで、それらのエラーが発生している理由を診断します。 これらの分析情報を組み合わせることで、モデルに対する信頼を構築し、監査プロセスに合格するのに役立ちます。 責任ある AI ダッシュボードは、既存の自動 ML モデルに対して生成することはできません。 ダッシュボードは、新しい自動 ML ジョブが作成されるときに最適な推奨モデルに対してのみ作成されます。 既存のモデルへのサポートが提供されるまで、ユーザーは引き続き Model Explanations (プレビュー) を使用する必要があります。
次の手順に従って、特定のモデルの責任ある AI ダッシュボードを生成します。
自動 ML ジョブを送信する際に、左側のメニューの [タスク設定] セクションに進み、[追加の構成設定の表示] オプションを選択します。
[追加の構成] ページで、[最適なモデルの説明] オプションを選択します。
![[最適なモデルの説明] が選択された自動 ML ジョブ構成ページを示すスクリーンショット。](media/how-to-use-automated-ml-for-ml-models/best-model-selection-updated.png?view=azureml-api-2)
[計算する] タブに切り替え、コンピューティングの [サーバーレス] オプションを選択します。
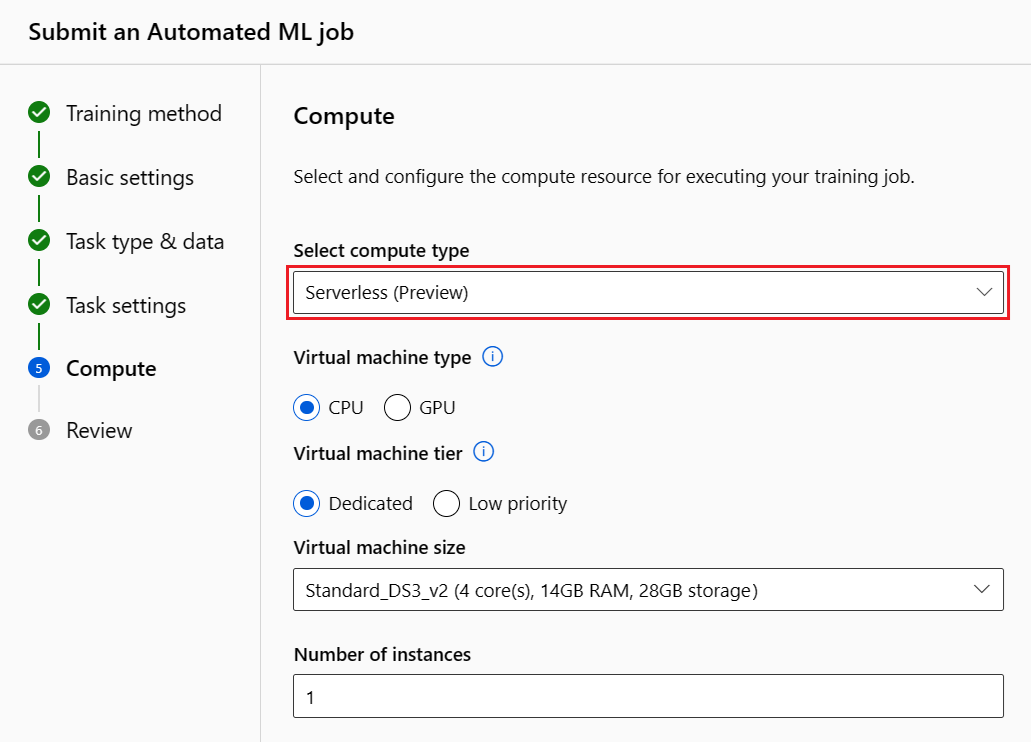
操作が完了したら、自動 ML ジョブの [モデル] ページを参照します。このページには、トレーニング済みのモデルの一覧が含まれています。 [責任ある AI ダッシュボードの表示] リンクを選択します。
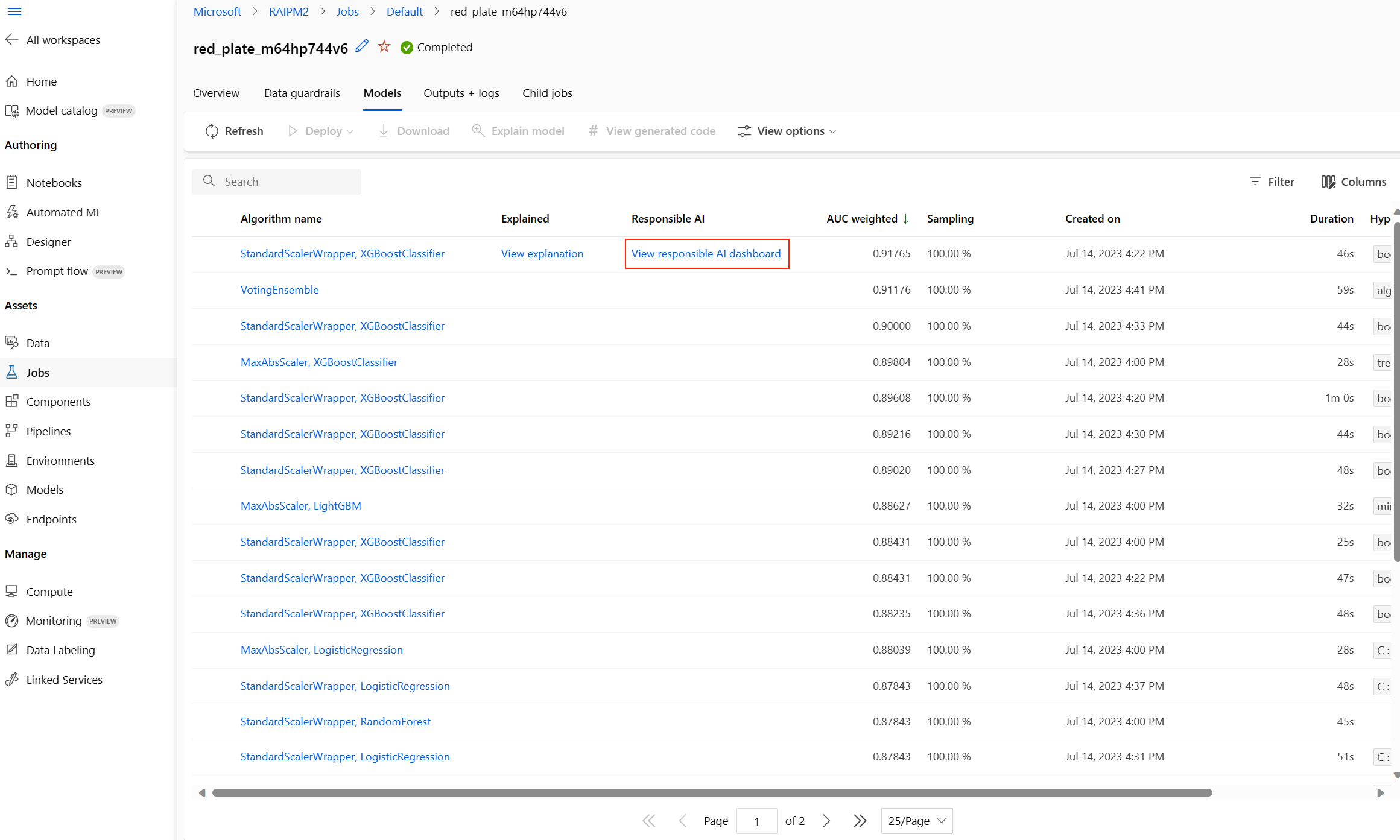
選択したモデルの責任ある AI ダッシュボードが表示されます。
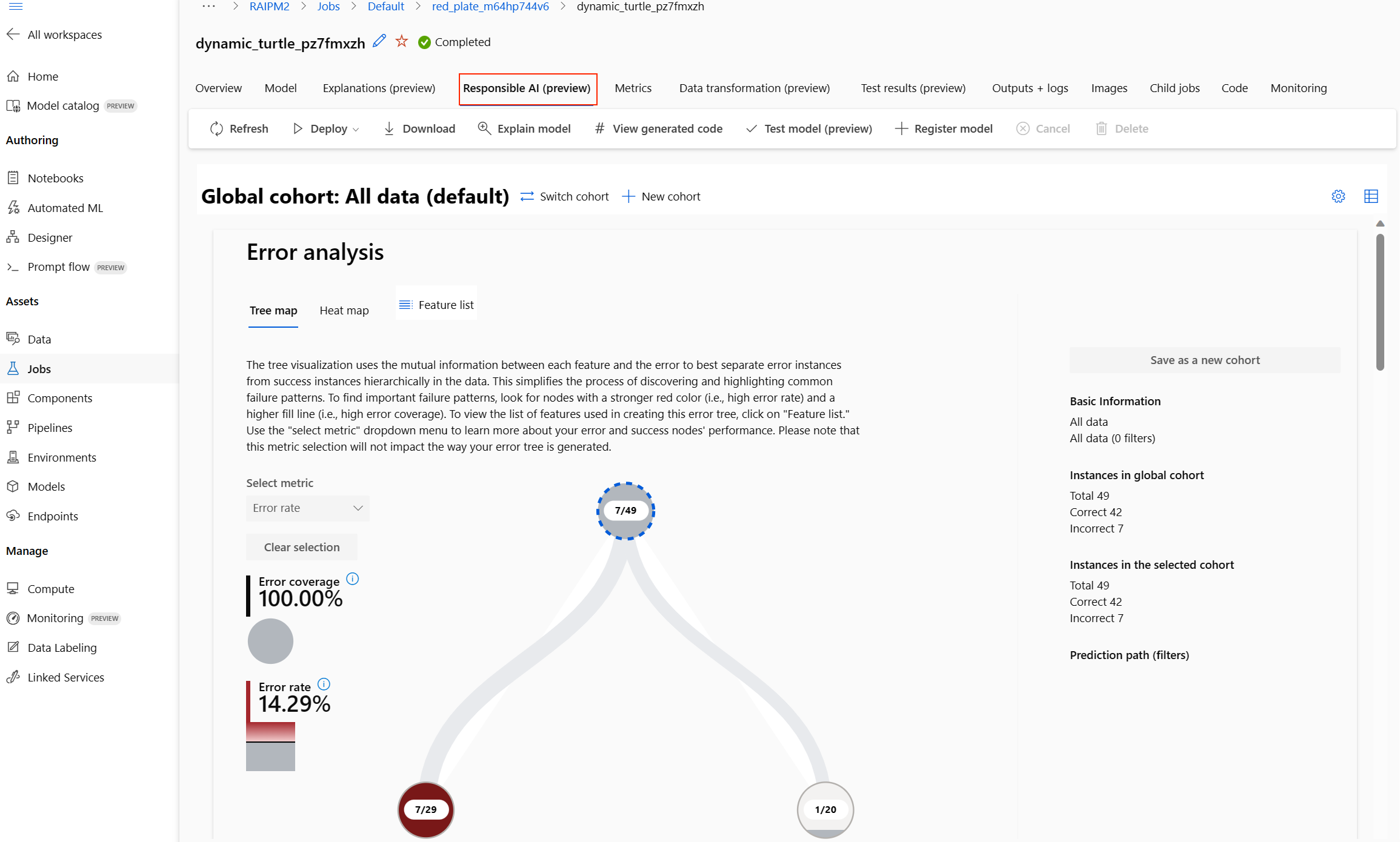
ダッシュボードでは、自動 ML の最適なモデル用に 4 つのコンポーネントがアクティブ化されているのがわかります。
コンポーネント コンポーネントが示す内容 グラフを読む方法 エラー分析 次のことを行う必要がある場合は、エラー分析を使用します。
- モデルの失敗がデータセット全体で、および複数の入力と特徴のディメンション間でどのように分散されるかについて深く理解する。
- ターゲットを絞った軽減策を通知するために、集計したパフォーマンスのメトリックを分解して誤ったコーホートを自動的に検出する。エラー分析グラフ モデルの概要と公平性 このコンポーネントを使用して、次を行います。
- データのさまざまなコーホート全体でのモデルのパフォーマンスを深く理解します。
- 不均衡メトリックを見て、モデルの公平性の問題を理解します。 これらのメトリックは、センシティブ特徴 (または非センシティブ特徴) の観点から識別されたサブグループ間でモデルの動作を評価および比較できます。モデルの概要と公平性のグラフ モデルの説明 モデル説明コンポーネントを使用して機械学習モデルの予測に関する人間が理解可能な説明を生成するには、次を参照してください。
- グローバルな説明: たとえば、ローン配賦モデルの全体的な動作に影響する特徴量は何ですか?
- ローカルな説明: たとえば、顧客のローン申請が承認または却下されたのはなぜですか?モデルの説明性のグラフ データ分析 次のことを行う必要がある場合は、データ分析を使用します。
- さまざまなフィルターを選択してデータをさまざまなディメンション (コーホートとも呼ばれます) にスライスすることで、データセットの統計情報を探索する。
- さまざまなコーホートと特徴量グループ間でのデータセットの分布を把握する。
- 公平性、エラー分析、因果関係 (他のダッシュボード コンポーネントから派生) に関連する検出結果がデータセットの分布の結果であるかどうかを判断する。
- 表現の問題、ラベル ノイズ、特徴量ノイズ、ラベル バイアスや同様のファクターから発生するエラーを軽減するために、より多くのデータを収集する領域を決定する。データ エクスプローラーのグラフ コーホート (指定した特性を共有するデータ ポイントのサブグループ) をさらに作成して、各コンポーネントの分析を異なるコーホートに集中させることができます。 ダッシュボードに現在適用されているコーホートの名前が、常にダッシュボードの左上に表示されます。 ダッシュボードの既定のビューはデータセット全体であり、既定ですべてのデータというタイトルです。 詳細については、ダッシュボードに関する「グローバル コントロール」を参照してください。


ジョブの編集と送信 (プレビュー)
既存の実験の設定に基づいて新しい実験を作成するシナリオの場合、自動 ML では、スタジオ UI の [編集と送信] オプションが提供されます。 この機能は、スタジオ UI から開始された実験に限定され、新しい実験のデータ スキーマが元の実験のものと一致する必要があります。
重要
既存の実験に基づいて新しい実験をコピー、編集、送信する機能は、プレビュー機能です。 この機能は試験段階のプレビュー機能であり、随時変更される可能性があります。
[編集と送信] オプションをクリックすると、データ、コンピューティング、事前に設定済みの実験設定が反映された [新しい自動 ML ジョブの作成] ウィザードが開きます。 ウィザードの各タブでオプションを構成し、新しい実験のために必要に応じて選択内容を編集できます。
モデルをデプロイする
最適なモデルを作成したら、モデルを Web サービスとしてデプロイして、新しいデータを予測できます。
注
Python SDK が含まれる automl パッケージで生成されたモデルをデプロイする場合、ワークスペースにモデルを登録する必要があります。
モデルを登録した後は、左側のメニューで [モデル] を選択して、スタジオでモデルを特定できます。 モデルの概要ページで、[展開する] オプションを選択し、このセクションの手順 2 に進めます。
自動 ML は、コードを記述せずにモデルをデプロイするのに役立ちます。
次のいずれかの方法を使用してデプロイを開始します。
定義したメトリック条件を使用して最適なモデルをデプロイします。
実験が完了したら、[ジョブ 1] を選択し、親ジョブ ページを参照します。
[最適なモデルの概要] セクションに一覧表示されているモデルを選択し、[展開する] を選択します。
この実験から特定のモデル反復をデプロイします。
- [モデル] タブから目的のモデルを選択し、[展開する] を選択します。
[Deploy model]\(モデルのデプロイ\) ペインにデータを入力します。
フィールド 価値 名前 デプロイの一意の名前を入力します。 説明 デプロイの目的をより適切に識別するための説明を入力します。 コンピューティングの種類 デプロイするエンドポイントの種類 (Azure Kubernetes Service (AKS) または Azure Container Instance (ACI)) を選択します。 コンピューティング名 (AKS にのみ適用) デプロイする AKS クラスターの名前を選択します。 認証を有効にする トークンベースまたはキーベースの認証を許可する場合に選択します。 カスタム デプロイ アセットを使用する 独自のスコアリング スクリプトと環境ファイルをアップロードする場合は、カスタム アセットを有効にします。 それ以外の場合、既定で、これらのアセットが自動 ML によって提供されます。 詳細については、「オンライン エンドポイントを使用して機械学習モデルをデプロイおよびスコア付けする」を参照してください。 重要
ファイル名は 1 から 32 文字にする必要があります。 名前の先頭と末尾は英数字である必要があり、間にダッシュ、アンダースコア、ドット、英数字を含められます。 スペースは使用できません。
"詳細設定" メニューには、データ収集やリソース使用率の設定などの既定のデプロイ特徴量が用意されています。 このメニューのオプションを使用して、これらの既定値をオーバーライドできます。 詳しくは、「オンライン エンドポイントを監視する」をご覧ください。
[デプロイ] を選択します。 デプロイの完了には 20 分程度かかる場合があります。
デプロイが開始されると、[モデルの概要] タブが開きます。 [Deploy status]\(デプロイの状態\) セクションで、デプロイの進行状況を監視できます。
これで、予測を生成するための運用 Web サービスが作成されました。 予測をテストするには、Microsoft Fabric のエンド ツー エンド AI サンプルからサービスに対してクエリを実行します。