このドキュメントでは、Azure Infrastructure as a Service (IaaS) に SQL Server for SAP ワークロードをデプロイする際に考慮すべきいくつかの異なる領域について説明します。 このドキュメントの前提条件として、 SAP ワークロードの Azure Virtual Machines DBMS デプロイに関する考慮事項を参照してください。 Azure 上の SAP ワークロード ドキュメントの他のガイドも参照してください。
重要
このドキュメントの範囲は、SQL Server 上の Windows バージョンです。 SAP は、どの SAP ソフトウェアでも LINUX バージョンの SQL Server をサポートしていません。 このドキュメントでは、Microsoft Azure プラットフォームのサービスとしてのプラットフォーム (PaaS) オファーである Microsoft Azure SQL Database について説明していません。 この記事では、Azure の IaaS 機能を使用して、Azure 仮想マシン (VM) でのオンプレミスデプロイで知られる SQL Server 製品の実行について説明します。 これら 2 つのオファー間のデータベースの機能は異なり、互いに混在させるべきではありません。 詳細については、「Azure SQL Database」を参照してください。
一般的に、Azure IaaS で SAP ワークロードを実行するには、最新の SQL Server リリースの使用を検討することをお勧めします。 最新の SQL Server リリースでは、Azure のサービスと機能の一部との統合性が向上しています。 または、Azure IaaS インフラストラクチャでの操作を最適化する変更が適用されています。
Azure VM で実行されている SQL Server に関する一般的なドキュメントについては、次の記事を参照してください。
- Azure Virtual Machines 上の SQL Server (Windows)
- Windows SQL Server IaaS Agent 拡張機能を使用して管理を自動化する
- Azure VM で SQL Server 用に Azure Key Vault 統合を構成する (リソース マネージャー)
- チェックリスト: Azure VM 上の SQL Server のベスト プラクティス
- ストレージ: Azure VM 上の SQL Server のパフォーマンスに関するベスト プラクティス
- HADR 構成のベスト プラクティス (Azure VM 上の SQL Server)
Azure VM の一般的な SQL Server ドキュメントで作成されたすべてのコンテンツとステートメントが SAP ワークロードに適用されるわけではありません。 しかし、このドキュメントによって原則を理解できます。 SAP ワークロードでサポートされていない機能の一例としては、FCI クラスタリングの使用があります。
先に進む前に知っておくべき IaaS での SQL Server に固有の情報があります。
SQL バージョンのサポート: SAP Note #1928533 では、サポートされている SQL Server の最小リリースは SQL Server 2008 R2 であると述べられていますが、Azure でサポートされている SQL Server バージョンは、SQL Server のライフサイクルの影響も受けます。 SQL Server 2012 の延長メンテナンスは 2022 年半ばに終了しました。 その結果、新しくデプロイされたシステムの現在の最小リリースは SQL Server 2014 です。 最新のものを使用することをお勧めします。 最新の SQL Server リリースでは、Azure のサービスと機能の一部との統合性が向上しています。 または、Azure IaaS インフラストラクチャでの操作を最適化する変更が適用されています。
Azure Marketplace からのイメージの使用: 新しい Microsoft Azure VM をデプロイする最も高速な方法は、Azure Marketplace のイメージを使用することです。 Azure Marketplace には、最新の SQL Server リリースを含むイメージがあります。 SQL Server が既にインストールされているイメージは、SAP NetWeaver アプリケーション用にすぐに使用することができません。 その理由は、それらのイメージ内に既定の SQL Server 照合順序がインストールされているが、SAP NetWeaver システムで必要な照合順序はインストールされていないためです。 このようなイメージを使用するには、「Microsoft Azure Marketplace からの SQL Server イメージの使用」の章に記載されている手順をご確認ください。
1 つの Azure VM 内で SQL Server の複数インスタンスのサポート: 次の展開方法がサポートされます。 ただし、リソースの制限事項 (特に、使用している VM の種類のネットワークとストレージの帯域幅に関するもの) に注意してください。 詳細については、「Azure の仮想マシンのサイズ」を参照してください。 これらのクォータ制限により、オンプレミスで実装できるのと同じマルチインスタンス アーキテクチャを実装できなくなる可能性があります。 1 つの VM 内で使用可能なリソースを共有する構成と干渉に関しては、オンプレミスと同じ考慮事項を考慮する必要があります。
1 つの VM 内の 1 つの SQL Server インスタンス内に複数の SAP データベース: 次のような構成がサポートされます。 1 つの SQL Server インスタンスの共有リソースを共有する複数の SAP データベースに関する考慮事項は、オンプレミス展開の場合と同じです。 特定の VM の種類にアタッチできるディスク数などの他の制限に留意してください。 また、「Azure の仮想マシンのサイズ」で詳しく説明されているように、特定の VM の種類のネットワークとストレージ クォータ制限もあります。
新しい M シリーズ VM と SQL Server
Azure の Mv3 ファミリでは、M シリーズ SKU で新しいファミリがいくつかリリースされました。 このファミリの一部の VM の種類は、Windows Server ゲスト OS で SMT (ハイパースレッディング) を無効にせずに SQL Server 2022 を含め、SQL Server には使用しないでください。 理由は、64 個を超える vCPU を持つ Windows Server ゲスト OS に表示される NUMA ノードの数が大きすぎるため、SQL Server では対応できません。 Windows Server ゲスト OS で SMT を無効にすると、vCPU の数が減ります。 そのため、vCPU の数は各 NUMA ノードで 64 未満になります。 SMT を無効にする方法については、「 Azure VM で SMT を無効にする」を参照してください。 特定の VM の種類は、次のとおりです。
- M176(d)s_3_v3 - SMT を無効にするか、代わりに M176bds_4_v3 または M176bds_4_v3 を使用します
- M176(d)s_4_v3 - SMT を無効にするか、代わりに M176bds_4_v3 を使用します
- M624(d)s_12_v3 - SMT を無効にするか、代わりに M416ms_v2 を使用します
- M832(d)s_12_v3 - SMT を無効にするか、代わりに M416ms_v2 を使用します
- M832i(d)s_16_v3 - SMT を無効にするか、代わりに M416ms_v2 を使用します
注
一部の新しい M(b)v3 VM の種類では、読み取りキャッシュ Premium SSD v1 ストレージを使用すると、読み取りキャッシュを使用しない場合よりも読み取りと書き込みの IOPS レートとスループットが低下する可能性があります。
SAP 関連 SQL Server の展開の VM/VHD 構造に関する推奨事項
一般的な説明に従って、オペレーティング システム、SQL Server 実行可能ファイル、SAP 実行可能ファイルは、個別の Azure ディスクに配置またはインストールする必要があります。 通常、ほとんどの SQL Server システム データベースは、SAP NetWeaver ワークロードでは高レベルで使用されません。 それでも、SQL Server のシステム データベースは、他の SQL Server ディレクトリとともに別個の Azure ディスクに配置する必要があります。 SQL Server tempdb は、非永続 D:\ ドライブまたは別のディスクに配置する必要があります。
- すべての SAP 認定 VM の種類 (SAP Note #1928533 を参照)、
tempdbデータ、およびログ ファイルは、非永続 D:\ ドライブに配置できます。 - SQL Server リリースでは、SQL Server が 1 つのデータ ファイルのみで
tempdbをインストールするため、複数のtempdbデータ ファイルを使用することをお勧めします。 D:\ ドライブのボリュームは、VM の種類に応じてサイズと機能が異なることに注意してください。 異なる VM の D:\ ドライブの正確なサイズについては、記事「Azure の Windows 仮想マシンのサイズ」を参照してください。
これらの構成により、 tempdb は、システム ドライブが提供できるよりも多くの領域を消費し、1 秒あたりの I/O 操作数 (IOPS) とストレージ帯域幅を増やすことが可能になります。 非永続的 D:\ ドライブでは、I/O 待機時間とスループットも向上します。 適切な tempdb サイズを決定するには、既存のシステムの tempdb サイズを確認します。
注
tempdbデータ ファイルとログ ファイルを、作成した D:\ ドライブ上のフォルダーに配置する場合は、VM の再起動後にフォルダーが存在することを確認する必要があります。 D:\ ドライブは VM の再起動後に新しく初期化できるため、すべてのファイルとディレクトリ構造を消去できます。SQL Server サービスの開始前に D:\ ドライブで最終的なディレクトリ構造を再作成する可能性については、「 Azure VM の SSD を使用して SQL Server TempDB とバッファー プール拡張機能を格納する」を参照してください。
SAP データベースを使用して SQL Server を実行し、D:\ ドライブと Azure Premium Storage v1 または v2 に tempdb データと tempdb ログ ファイルが配置される VM 構成は次のようになります。
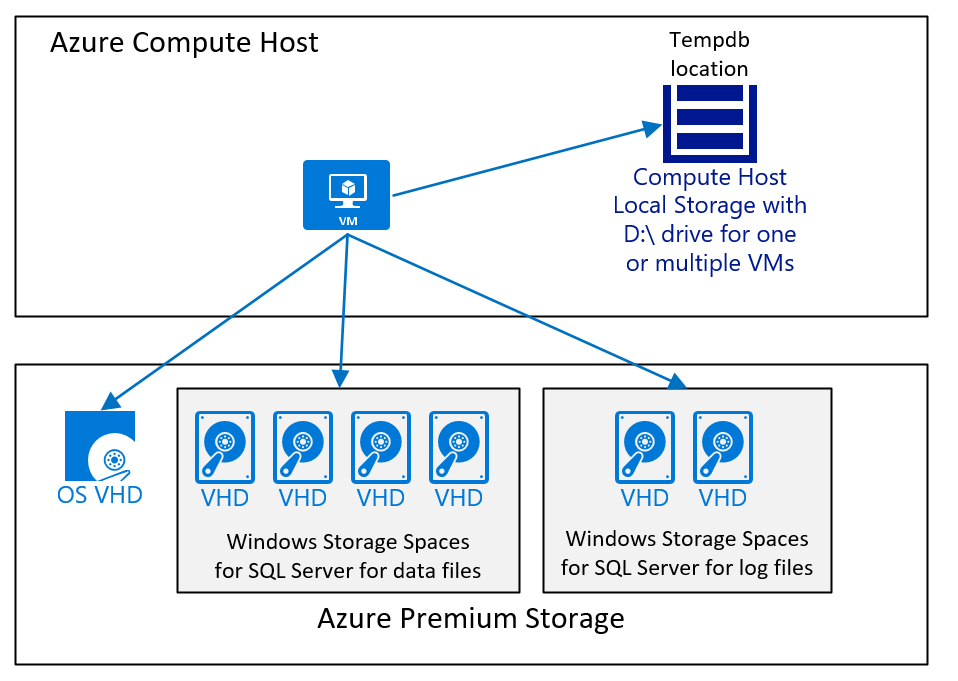
この図は単純な事例を示しています。 記事「SAP ワークロードのための Azure Virtual Machines DBMS デプロイの考慮事項」で説明されているように、Azure Storage の種類、ディスクの数とサイズはさまざまな要素によって変わります。 ただし一般的な推奨事項は次のとおりです。
- 小規模および中規模の展開の場合は、SQL Server データ ファイルを含む 1 つの大きなボリュームを使用します。 この構成を行う理由は、SQL Server データ ファイルに同じ空き領域がない場合に、さまざまな I/O ワークロードを処理するのが簡単なことです。 大規模なデプロイでは、特に顧客が Azure の SQL Server への異種データベース移行で移動したデプロイでは、個別のディスクを使用し、それらのディスクにデータ ファイルを分散しました。 このアーキテクチャは、各ディスクに同じ数のデータ ファイルがあり、すべてのデータ ファイルのサイズが同じで、ほぼ同じ空き領域がある場合にのみ成功します。
- パフォーマンスが十分である限り、
tempdbには D:\drive を使用します。 D:\ ドライブにあるtempdbのパフォーマンスが全体的に制限されている場合は、tempdbで推奨されているように、を Azure Premium Storage v1 または v2、または Ultra Disk に移動する必要があります。
SQL Server の比例配分メカニズムは、すべての SQL Server データ ファイルのサイズが同じで、空き領域が同じ場合、すべてのデータ ファイルに読み取りと書き込みを均等に配布します。 SAP on SQL Server は、使用可能なすべてのデータ ファイルについて読み取りと書き込みが均等に配布されるときに、最高のパフォーマンスを実現します。 データベースにあるデータ ファイル数が非常に少ないか、既存のデータ ファイルのバランスが非常に悪い場合、最良の修正方法は、R3load のエクスポートとインポートです。 R3load のエクスポートとインポートはダウンタイムを発生させるため、解決する必要がある明らかなパフォーマンス上の問題が存在する場合にのみ実行してください。 データ ファイルのサイズの違いがわずかな場合は、すべてのデータ ファイルを同じサイズになるように増大すると、SQL Server によって徐々にデータのバランスの再調整が行われます。 トレース フラグ 1117 が設定されている場合、または SQL Server 2016 以上がトレース フラグなしで使用されている場合は、SQL Server が自動的にデータファイルを均等に拡張します。
M シリーズ VM に関する考慮事項
Azure M シリーズ VM の場合、Azure 書き込みアクセラレータを使用する場合、Azure Premium Storage パフォーマンス v1 と比較して、トランザクション ログへの書き込み待機時間を短縮できます。 Premium Storage v1 で提供される待機時間が SAP ワークロードのスケーラビリティを制限している場合は、SQL Server トランザクション ログ ファイルを格納するディスクで書き込みアクセラレータを有効にできます。 詳細については、書き込みアクセラレータに関する記事を参照してください。 Azure 書き込みアクセラレータは、Azure Premium Storage v2 と Ultra Disk では機能しません。 どちらの場合も、待機時間は Azure Premium Storage v1 が提供する待機時間よりも優れています。 書き込みアクセラレータは、Azure Premium SSD v2 をサポートしていません。
注
一部の新しい M(b)v3 VM の種類では、読み取りキャッシュ Premium SSD v1 ストレージを使用すると、読み取りキャッシュを使用しない場合よりも読み取りと書き込みの IOPS レートとスループットが低下する可能性があります。
ディスクのフォーマット
SQL Server の場合、SQL Server のデータとログのファイルを含むディスクの NTFS ブロック サイズは 64 KB にする必要があります。 D:\ ドライブをフォーマットする必要はありません。 このドライブはフォーマット済みで出荷されます。
データベースの復元または作成によって、ファイルの内容を消去してデータ ファイルの初期化が実行されないようにするために、SQL Server サービスが実行されているユーザー コンテキストに、ボリュームの保守タスクを実行ユーザー権限があることを確認してください。 詳細については、「データベース ファイルの瞬時初期化」を参照してください。
Azure Blob Storage にデータベース ファイルを直接格納する
SQL Server 2014 以降では、Azure Blob ストアの周囲に VHD の "ラッパー" を用意しなくても、Azure Blob ストアに直接データベース ファイルを格納できます。 この機能は、何年も前の Azure ブロック ストレージの弱点に対応することを目的としていました。 最近では、このデプロイ方法を使用することはお勧めしません。代わりに、要件に応じて Azure Premium Storage v1 または v2、または Ultra Disk のいずれかを選択してください。
SQL Server のバックアップと回復に関する考慮事項
SQL Server を Azure に展開するときは、バックアップ アーキテクチャを確認する必要があります。 システムが運用システムでない場合でも、SQL Server SAP データベースは定期的にバックアップする必要があります。 Azure Storage は 3 つのイメージを保持するため、ストレージの障害から復旧するという点ではバックアップの重要度は低くなりました。 適切なバックアップと復旧の計画を維持する主な理由は、ポイントイン タイム復旧機能が論理エラーや人的エラーを修正するために重要です。 目標は、バックアップを使用して、データベースを特定の時点に復元することです。 または、Azure 内のバックアップを使用して、既存のデータベース バックアップをコピーして別のシステムをシードすることです。
Azure で SQL Server データベースをバックアップおよび復元するには、いくつかの方法があります。 最適な概要と詳細については、「Azure VM における SQL Server のバックアップと復元」を参照してください。 この記事では、さまざまな選択肢をいくつかご紹介します。
Microsoft Azure Marketplace からの SQL Server イメージの使用
Microsoft は、SQL Server のバージョンが既に含まれている Azure Marketplace で VM を提供しています。 SQL Server および Windows のライセンスが必要な SAP ユーザーの場合、これらのイメージを使用すると、SQL Server が既にインストールされている VM をスピン アップしてライセンスの必要性に対応できます。 SAP でそのようなイメージを使用するためには、次の事項を考慮する必要があります。
- SQL Server 評価版以外のバージョンでは、Azure Marketplace から "Windows のみ" の VM をデプロイする場合よりもコストがかかります。 価格を比較するには、「Windows Virtual Machines の料金」と「SQL Server Enterprise Virtual Machines の料金」を参照してください。
- 使用できるのは、SAP がソフトウェアをサポートする SQL Server リリースのみです。
- Azure Marketplace で提供される VM にインストールされている SQL Server インスタンスの照合順序は、SAP NetWeaver が SQL Server インスタンスを実行するために必要な照合順序ではありません。 以降のセクションの指示で、照合順序を変更できます。
Microsoft Windows SQL Server VM の SQL Server 照合順序の変更
Azure Marketplace の SQL Server イメージは、SAP NetWeaver アプリケーションに必要な照合順序を使用するように設定されていないため、デプロイの直後に変更する必要があります。 SQL Server の場合、この照合順序の変更は、VM がデプロイされ、管理者がデプロイされた VM にログインできるようになるとすぐに、次の手順で行うことができます。
- 管理者として Windows コマンド ウィンドウを開きます。
- ディレクトリを C:\Program Files\Microsoft SQL Server\110\Setup Bootstrap\SQLServer2012 に変更します。
- 次のコマンドを実行します。Setup.exe /QUIET /ACTION=REBUILDDATABASE /INSTANCENAME=MSSQLSERVER /SQLSYSADMINACCOUNTS=
<local_admin_account_name> /SQLCOLLATION=SQL_Latin1_General_Cp850_BIN2-
<local_admin_account_name>は、ギャラリーを介して VM を初めてデプロイするときに管理者アカウントとして定義されたアカウントです。
-
処理にかかるのは、わずか数分間です。 この手順で正しい結果が得られるかどうかを確認するため、次の手順を実行します。
- SQL Server Management Studio を開きます。
- クエリ ウィンドウを開きます。
- SQL Server マスター データベースで sp_helpsort コマンドを実行します。
結果が、次のように表示されます。
Latin1-General, binary code point comparison sort for Unicode Data, SQL Server Sort Order 40 on Code Page 850 for non-Unicode Data
結果が異なる場合は、すべての展開を中止し、setup コマンドが期待通りに動作しなかった原因を調査します。 SAP NetWeaver アプリケーションを SQL Server インスタンスに展開する場合、NetWeaver 展開では上記以外の SQL Server コード ページはサポートされていません。
Azure の SAP 向け SQL Server 高可用性
SAP 用の Azure IaaS 展開で SQL Server を使用する場合、高可用なデータベース レイヤーを展開するさまざまな選択肢がいくつかあります。 Azure では、次を使用して、1 つの VM に対して異なるアップタイム SLA が提供されます。
- さまざまな Azure ブロック ストレージ
- Azure 可用性セットにデプロイされた VM のペア
- Azure Availability Zones にデプロイされた VM のペア
運用システムの場合、2 つの可用性ゾーン間で柔軟なオーケストレーションを行う仮想マシン スケール セット内に VM のペアを展開することを想定しています。 詳細については、 SAP ワークロードのさまざまなデプロイの種類の比較を参照してください。 1 台の VM がアクティブな SQL Server インスタンスを実行します。 もう 1 つの VM はパッシブ インスタンスを実行します。
Windows スケールアウト ファイル サーバーまたは Azure 共有ディスクを使用する SQL Server クラスタリング
Microsoft は Windows Server 2016 で記憶域スペース ダイレクトを導入しました。 記憶域スペース ダイレクトのデプロイに基づいて、SQL Server FCI クラスタリングが一般にサポートされています。 Azure は、Windows クラスタリングに使用できる Azure 共有ディスクも提供しています。 SAP ワークロードの場合、これらの HA オプションはサポートされていません。
SQL Server ログ配布
高可用性機能の 1 つに、SQL Server のログ配布があります。 HA 構成に参加している VM で名前解決が機能している場合、問題はありません。 Azure でのセットアップは、ログ配布の設定とログ配布に関する原則に関してはオンプレミスで実行されるどのセットアップとも違いはありません。 「ログ配布について (SQL Server)」という記事で SQL Server のログ配布の詳細を確認できます。
1 つの Azure リージョン内で高可用を達成する目的で、SQL Server のログ配布機能が Azure で使用されることはほとんどありませんでした。 ただし、以下のシナリオでは、SAP ユーザーは Azure と適切に連携するログ配布を使用していました。
- ある Azure リージョンから別の Azure リージョンへのディザスター リカバリー シナリオ
- オンプレミスから Azure リージョンへのディザスター リカバリー構成
- オンプレミスから Azure への切り替えシナリオ これらの場合、Azure 内の新しいデータベースの展開を、実行中のオンプレミスの運用システムと同期させるためにログ配布が使用されます。 切り替え時に、運用環境がシャットダウンされ、最後と最新のトランザクション ログ バックアップが Azure データベースのデプロイに転送されたことを確認します。 次に、Azure データベース展開が運用のために開かれます。
SQL Server AlwaysOn
Always On は SAP オンプレミスでサポートされ (SAP Note #1772688 を参照)、Azure の SAP と組み合わせてサポートされます。 SQL Server 可用性グループ リスナー (Azure 可用性セットとは異なります) のデプロイにはいくつかの特別な考慮事項があります。 そのため、異なるインストール手順が必要です。
可用性グループ リスナーを使用する場合の考慮事項は次のとおりです。
- 可用性グループ リスナーの使用は、Windows Server 2012 以降を VM のゲスト OS としてのみ使用できます。 Windows Server 2012 の場合は、 Windows Server 2008 R2 および Windows Server 2012 ベースの Microsoft Azure 仮想マシン上の SQL Server 可用性グループ リスナー が適用されていることを確認します。
- Windows Server 2008 R2 の場合、このパッチは存在しません。 この場合は、データベース ミラーリングと同じ方法で Always On を使用する必要があります。 SAP default.pfl パラメーター dbs/mss/server を使用して、接続文字列にフェールオーバー パートナーを指定します。 SAP Note #965908 を参照してください。
- 可用性グループ リスナーを使用する場合、データベース VM を専用のロード バランサーに接続する必要があります。 Always On 構成で、それらの VM のネットワーク インターフェイスに静的 IP アドレスを割り当てる必要があります。 静的 IP アドレスの定義については、静的 プライベート IP アドレスを使用した VM の作成に関する説明を示します。 DHCP と比較して、静的 IP アドレスを使用すると、両方の VM が停止した場合に新しい IP アドレスの割り当てが行われなくなります。
- WSFC クラスター構成を構築する際には、クラスターに特別な IP アドレスが割り当てられている必要がある特別な手順が必要です。 現在の機能を備えた Azure では、クラスター名に、クラスターが作成されるノードと同じ IP アドレスが割り当てられます。 この動作は、クラスターに別の IP アドレスを割り当てるためには手動の手順を行う必要があることを意味します。
- TCP/IP エンドポイントを使用して Azure に可用性グループ リスナーを作成しようとしています。TCP/IP エンドポイントは、可用性グループのプライマリ レプリカとセカンダリ レプリカを実行している VM に割り当てられています。
- これらのエンドポイントと ACL をセキュリティで保護する必要があります。
Azure VM の SQL Server で Always On を展開する方法の詳細については、以下のドキュメントを参照してください。
- Azure Virtual Machines での SQL Server Always On 可用性グループの概要。
- 異なるリージョンに存在する Azure 仮想マシンへの Always On 可用性グループの構成。
- Azure の AlwaysOn 可用性グループに使用するロード バランサーの構成。
- HADR 構成のベスト プラクティス (Azure VM 上の SQL Server)
注
Azure 仮想マシン上の SQL Server Always On 可用性グループの概要に関するページを参照すると、SQL Server の Direct Network Name (DNN) リスナーに関する記事が含まれています。 DNN 機能は SQL Server 2019 CU8 で導入されました。 この新機能により、可用性グループ リスナーの仮想 IP アドレスを処理する、Azure ロード バランサーの使用が廃止されます。
SQL Server Always On は、Azure for SAP ワークロードの展開で使用される最も一般的な高可用性とディザスター リカバリー機能です。 ほとんどのユーザーは、単一の Azure リージョン内で高可用性のために Always On を使用しています。 展開が 2 つのノードのみに制限されている場合、接続には 2 つの選択肢があります。
可用性グループ リスナーを使用します。 可用性グループ リスナーを使用する場合、Azure Load Balancer を展開する必要があります。
Azure ロード バランサーの代わりに、Direct Network Name (DNN) リスナーを使用できます。 DNN では、Azure ロード バランサーを使用する必要がなくなります。これは、次の場合にも適用されます。
SQL Server 2016 SP3
- Windows Server 2016 の最新の SQL Server リリース
SQL Server 2017 CU 25
SQL Server 2019 CU8
SQL Server データベース ミラーリングの接続パラメーターの使用は、他の 2 つの方法に関する問題を調査する場合にのみ考慮する必要があります。 この場合、両方のノードに名前を付ける方法で SAP アプリケーションの接続を構成する必要があります。 このような SAP 側構成の厳密な詳細については、SAP Note #965908 を参照してください。 このオプションを使用する場合、可用性グループ リスナーを構成する必要はありません。 そして、この方法を使うと、Azure Load Balancer は必要はなく、またこれらのコンポーネントの問題を調査できます。 ただし、このオプションは、可用性グループが 2 つのインスタンスにまたがるように制限する場合にのみ機能する点に注意してください。
多くのユーザーは、SQL Server Always On 機能を Azure リージョン間のディザスター リカバリー機能に使用しています。 一部のユーザーは、セカンダリ レプリカからバックアップを実行する機能も使用しています。
SQL Server Transparent Data Encryption
Azure に SAP SQL Server データベースを展開するときに、多くのユーザーが SQL Server の Transparent Data Encryption (TDE) を使用しています。 SAP では、SQL Server TDE 機能が完全にサポートされています。 SAP Note #1380493 を参照してください。
SQL Server TDE の適用
オンプレミスで実行されている別のデータベースから Azure で実行されている Windows SQL Server への異種移行を実行する場合は、事前に空のターゲット データベースを SQL Server に作成する必要があります。 次の手順として、この空のデータベースに SQL Server TDE 機能を適用します。 この順序で実行する理由は、空のデータベースを暗号化するプロセスにかなりの時間がかかることです。 次に、SAP インポート プロセスで、ダウンタイム フェーズ中にデータを暗号化されたデータベースにインポートします。 暗号化されたデータベースにインポートする場合のオーバーヘッドは、エクスポート フェーズ後にダウン タイム フェーズでデータベースを暗号化する場合よりも、時間の影響が少なくなります。 データベース上で実行されている SAP ワークロードで TDE を適用しようとすると、否定的なエクスペリエンスが発生しました。 したがって、TDE の展開は、特定のデータベース上に SAP ワークロードがないか少ない状態で実行する必要があるアクティビティとして扱うことをお勧めします。 SQL Server 2016 以降は、初期暗号化を実行する TDE スキャンを停止して再開できます。
SAP SQL Server データベースをオンプレミスから Azure に移行する場合は、暗号化を最速で適用できるインフラストラクチャをテストすることをお勧めします。 この場合、次の点に注意してください。
- データベースにデータの暗号化を適用するために使用されるスレッドの数は定義できません。 スレッド数は、主に SQL Server のデータとログ ファイルが分散されるディスク ボリュームの数によって変わります。 つまり、個別のボリューム (ドライブ文字) が多くなるほど、暗号化の実行に並行して使用されるスレッドが多くなります。 このような構成は、1 つ、または Azure VM 内の SQL Server データベース ファイル用の記憶域スペースの数を減らした、以前のディスク構成の提案と矛盾しています。 ボリュームが少ない構成では、暗号化を実行するスレッド数が少なくなります。 1 つのスレッドの暗号化では、64 KB のエクステントを読み取り、暗号化した後、トランザクション ログ ファイルにレコードを書き込み、エクステントが暗号化されたことを示します。 その結果、トランザクション ログにかかる負荷は中程度です。
- 以前の SQL Server リリースでは、SQL Server データベースを暗号化するときにバックアップの圧縮は効率化されませんでした。 オンプレミスの SQL Server データベースを暗号化してから Azure にバックアップをコピーして Azure でデータベースを復元する予定の場合、この動作が問題になる可能性があります。 SQL Server のバックアップ圧縮では、4 倍の圧縮率を達成できます。
- SQL Server 2016 では、暗号化されたデータベースのバックアップも効率的に圧縮できる新しい機能が SQL Server に導入されました。 詳細については、こちらのブログを参照してください。
Azure Key Vault の使用
Azure は、暗号キーを格納する Key Vault のサービスを提供しています。 一方、SQL Server は、TDE 証明書のストアとして Azure Key Vault を使用するコネクタを用意しています。
Azure Key Vault を SQL Server TDE に使用する方法の詳細については、以降のドキュメントを参照してください。
Azure VM で SQL Server 用に Azure Key Vault 統合を構成する (リソース マネージャー)。
SQL Server Transparent Data Encryption について寄せられるその他の質問 - TDE + Azure Key Vault。
重要
特に Azure Key Vault で SQL Server TDE を使用する場合は、SQL Server 2014、SQL Server 2016、および SQL Server 2017 の最新のパッチを使用することをお勧めします。 その理由は、ユーザーのフィードバックに基づいて、最適化と修正がコードに適用されていることです。 例については、KBA #4058175 を参照してください。
最小の展開構成
このセクションでは、SAP ワークロードの下にあるさまざまなサイズのデータベースに対する一連の最小構成を提案します。 これらのサイズが特定のワークロードに適合するかどうかを評価するのは非常に難しいことです。 場合によっては、データベース サイズと比較してメモリ量が多すぎる場合があります。 一方、一部のワークロードではディスクのサイズ設定が低すぎる可能性があります。 したがって、これらの構成は、そのようなものとして扱う必要があります。 これらは、出発点を提供する構成です。 ユーザーの特定のワークロードとコスト効率の要件に合わせて微調整するための構成です。
データベース サイズが 50 GB から 250 GB の小さな SQL Server インスタンスの構成の例を次に示します。
| 構成 | データベース VM | コメント |
|---|---|---|
| VM の種類 | E4s_v3/v4/v5 (4 vCPU/32 GiB RAM) | |
| 高速ネットワーク | 有効 | |
| SQL Server のバージョン | SQL Server 2019 以降 | |
| データ ファイルの数 | 4 | |
| ログ ファイルの数 | 1 | |
| 一時データ ファイルの数 | 4 または SQL Server 2016 以降の既定値 | |
| オペレーティング システム | Windows Server 2019 以降 | |
| ディスク集計 | 必要に応じて記憶域スペース | |
| ファイル システム | NTFS | |
| ブロック サイズのフォーマット | 64 KB | |
| データ ディスクの数と種類 | Premium Storage v1: 2 x P10 (RAID0) Premium Storage v2: 2 x 150 GiB (RAID0) - 既定の IOPS とスループットまたは同等の Premium SSD v2 |
Premium Storage v1 では、Cache = Read Only |
| ログ ディスクの数と種類 | Premium Storage v1: 1 x P20 Premium Storage v2: 1 x 128 GiB - 既定の IOPS とスループットまたは同等の Premium SSD v2 |
キャッシュ = なし |
| SQL Server の最大メモリ パラメーター | 物理 RAM の 90% | 1 つのインスタンスを想定 |
たとえば、この構成は、SQL Server 上の SAP Business Suite のデータベース VM 構成です。 この VM は、年間収益が 200 億ドルを超え、従業員が 2,000 万人を超えるグローバル企業の 1 つのグローバル SAP Business Suite インスタンスの 30 TB データベースをホストします。 このシステムは、すべての財務処理、販売、流通処理、および北米の給与計算を含めさまざまな領域の多くのビジネス プロセスを実行しています。 このシステムは、Azure M シリーズ VM をデータベース VM として使用して、2018 年の初めから Azure で実行されています。 高可用性として、システムでは、同じ Azure リージョンの別の可用性ゾーン内の 1 つの同期レプリカと、 別の Azure リージョン内の別の非同期レプリカで Always on を使用しています。 NetWeaver アプリケーション レイヤーは、最新の D(a)/E(a) VM ファミリ上に展開されます。
| 構成 | データベース VM | コメント |
|---|---|---|
| VM の種類 | M192dms_v2 (192 vCPU/4,196 GiB RAM) | |
| 高速ネットワーク | 有効化済み | |
| SQL Server のバージョン | SQL Server 2019 | |
| データ ファイルの数 | 32 | |
| ログ ファイルの数 | 1 | |
| 一時データ ファイルの数 | 8 | |
| オペレーティング システム | Windows Server 2019 | |
| ディスク集計 | 記憶域スペース | |
| ファイル システム | NTFS | |
| ブロック サイズのフォーマット | 64 KB | |
| データ ディスクの数と種類 | Premium Storage v1: 16 x P40 または同等の Premium SSD v2 | キャッシュ = 読み取り専用 |
| ログ ディスクの数と種類 | Premium Storage v1: 1 x P60 または同等の Premium SSD v2 | 書き込みアクセラレータの使用 |
#と tempdb ディスクの種類 |
Premium Storage v1: 1 x P30 または同等の Premium SSD v2 | キャッシュなし |
| SQL Server の最大メモリ パラメーター | 物理 RAM の 95% |
Azure の SAP 向け SQL Server の全般的なまとめ
このガイドには多くの推奨事項が記載されているため、Azure 展開を計画する前に 2 回以上読むことをお勧めします。 一般に、Azure 固有の推奨事項で上位の SQL Server に従ってください。
- Azure で多くのメリットのある SQL Server 2022 のように、最新の SQL Server リリースを使用します。
- データ ファイルのレイアウトと Azure の制限のバランスを取るために、Azure で SAP システムのランドスケープを慎重に計画します。
- 多すぎないが、必要な IOPS を達成するには十分な数のディスクを持つこと。
- 高いスループットを実現する必要がある場合にのみディスク間でストライピングすること。
- 多すぎないが、必要な IOPS を達成するには十分な数のディスクを持つこと。
- D:\ ドライブは非永続であるため、ソフトウェアをインストールしたり、永続性を必要とするファイルを配置したりしないでください。 このドライブに配置されたものは Windows や VM を再起動したときにすべて失われます。
- データベース データをレプリケートするには、SQL Server Always On ソリューションを使用します。
- 常に名前解決を使用して、IP アドレスに依存しないようにします。
- SQL Server TDE を使用して、最新の SQL Server パッチを適用します。
- Azure Marketplace の SQL Server イメージを使用する場合は注意してください。 いずれかの SQL Server を使用する場合は、SAP NetWeaver システムをインストールする前にインスタンスの照合順序を変更する必要があります。
- デプロイ ガイドに従い、SAP Host Monitoring for Azure をインストールして構成します。