Azure AI 検索では、suggester を使用することで、先行入力または "入力時に検索" が有効になります。 suggester は、インデックス内の構成で、オートコンプリートと検索候補の一致を事前設定するために使用するフィールドを指定します。 これらのフィールドでは追加のトークン化が行われ、部分的な用語での一致をサポートするプレフィックス シーケンスが生成されます。 たとえば、city の値を持つ フィールドを含む suggester では、sea、seat、seatt、seattl というプレフィックスの組み合わせで先行入力をサポートします。
部分的用語での一致は、オートコンプリート クエリと一致候補のいずれかです。 同じ suggester は、両方のエクスペリエンスをサポートします。
Azure AI Search の先行入力エクスペリエンス
先行入力は、用語全体のクエリの一部入力を補完する "オートコンプリート" と、特定の一致へのクリック スルーを促す "提案" のいずれかです。 オートコンプリートでは、クエリが生成されます。 候補では、一致するドキュメントが生成されます。
次のスクリーンショットはその両方を示したものです。 オートコンプリートを使用すると、可能性のある語句が予測され、tw に in が補完されます。 検索候補はミニ検索結果であり、hotel name のようなフィールドには、インデックスから一致するホテルの検索ドキュメントが表示されます。 候補については、説明的な情報を提供する任意のフィールドを表示できます。
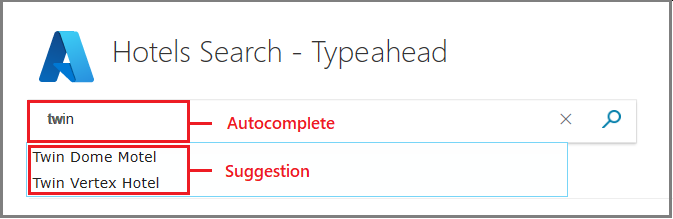
これらの機能は、個別に、または組み合わせて使用できます。 Azure AI Search でこれらの動作を実装するには、インデックスとクエリのコンポーネントがあります。
検索インデックスの定義に suggester を追加します。 この記事の残りの部分では、suggester の作成に重点を置きます。
「suggester の使用」に一覧表示されている API のいずれかを使用して、検索候補の要求またはオートコンプリートの要求の形式で suggester 対応クエリを呼び出します。
文字列フィールドの場合、フィールドごとに逐次検索が有効になります。 スクリーンショットに示したものと同様のエクスペリエンスを求めているのであれば、同じ検索ソリューション内に両方の先行入力の動作を実装できます。 どちらの要求も特定のインデックスの documents コレクションを対象にしており、ユーザーが入力文字列を少なくとも 3 文字入力すると応答が返されます。
suggester を作成する方法
suggester を作成するには、それをインデックス定義に追加します。 suggester によって、先行入力エクスペリエンスが有効になっているフィールドの名前とコレクションが取得されます。 suggester の作成に最適なタイミングは、それを使用するフィールドを定義するときです。
文字列フィールドのみを使用します。
文字列フィールドが複合型の一部である場合 (たとえば、Address 内の City フィールド)、フィールド パスに親を含めます:
"Address/City"(REST、C#、Python)、または["Address"]["City"](JavaScript)。フィールドで、既定の標準 Lucene アナライザー (
"analyzer": null) または 言語アナライザー ("analyzer": "en.Microsoft"など) を使用します。
既存のフィールドを使用して suggester を作成しようとしても、API ではそれが許可されません。 プレフィックスは、インデックス作成の間に、2 つ以上の文字の組み合わせから成る部分的な用語が完全な用語と並行してトークン化されるときに生成されます。 既存のフィールドが既にトークン化されている場合、それらを suggester に追加するには、インデックスを再構築する必要があります。 詳細については、「Azure AI 検索でインデックスを更新または再構築する」を参照してください。
フィールドの選択
suggester は、いくつかのプロパティを備えていますが、基本的には、search-as-you-type エクスペリエンスを有効にしている文字列フィールドのコレクションです。 インデックスごとに 1 つの suggester があるため、suggester リストには、候補とオートコンプリートの両方のコンテンツを提供するすべてのフィールドを含める必要があります。
追加のコンテンツには、より多くの用語が補完候補として含まれるため、オートコンプリートには、大きいフィールド プールの方がより有効です。
一方、候補では、フィールド選択が選択的である場合により良い結果が得られます。 候補は検索ドキュメントのプロキシであるため、単一の結果を最もよく表すフィールドを選択することに注意してください。 複数の一致を区別する名前、タイトル、またはその他の固有のフィールドが最適です。 フィールドが反復される値で構成されている場合、候補は同じ結果で構成され、ユーザーはどれを選択すればよいかがわかりません。
両方の逐次検索エクスペリエンスを満たすには、オートコンプリートに必要なすべてのフィールドを追加しますが、その後、select、top、filter、searchFields を使用して、検索候補の結果を制御します。
アナライザーの選択
アナライザーを選択すると、フィールドをトークン化する方法と、プレフィックスを付ける方法が決まります。 たとえば、context-sensitive のようなハイフンでつながれた文字列の場合、言語アナライザーを使用すると、context、sensitive、context-sensitive というトークンの組み合わせが得られます。 ここでは標準の Lucene アナライザーを使用したので、ハイフンでつながれた文字列は存在しません。
アナライザーを評価するときは、テキスト分析 API を使用して、用語の処理方法を把握することを検討してください。 インデックスを作成したら、文字列に対してさまざまなアナライザーを試して、トークン出力を確認することができます。
カスタム アナライザーまたは組み込みアナライザー (標準 Lucene を除く) を使用するフィールドは、不適切な結果を防ぐために明示的に禁止されています。
注
アナライザーの制約を回避する必要がある場合 (たとえば、特定のクエリ シナリオのためにキーワードまたは ngram アナライザーが必要な場合)、同じコンテンツに対して 2 つの別個のフィールドを使用する必要があります。 これにより、フィールドの 1 つに suggester を指定し、他のフィールドにはカスタム アナライザー構成を設定することができます。
Azure Portal を使用した作成
インデックスの追加またはデータ インポートウィザードを使用してインデックスを作成する場合は、suggester を有効にするオプションがあります。
インデックスの定義で、suggester の名前を入力します。
新しいフィールドの各フィールド定義で、[Suggester] 列のチェックボックスをオンにします。 チェックボックスは、文字列フィールドでのみ使用できます。
前述のように、アナライザーの選択はトークン化とプレフィックス付けに影響します。 suggester を有効にする場合は、フィールド定義全体を考慮してください。
REST を使用して作成する
REST API では、インデックスの作成またはインデックスの更新を使用して suggester を追加します。
{
"name": "hotels-sample-index",
"fields": [
. . .
{
"name": "HotelName",
"type": "Edm.String",
"facetable": false,
"filterable": false,
"key": false,
"retrievable": true,
"searchable": true,
"sortable": false,
"analyzer": "en.microsoft",
"indexAnalyzer": null,
"searchAnalyzer": null,
"synonymMaps": [],
"fields": []
},
],
"suggesters": [
{
"name": "sg",
"searchMode": "analyzingInfixMatching",
"sourceFields": ["HotelName"]
}
],
"scoringProfiles": [
. . .
]
}
.NET を使用して作成する
C# で、SearchSuggester オブジェクトを定義します。 Suggesters は SearchIndex オブジェクトのコレクションですが、1 つのアイテムのみを受け取ることができます。 インデックスの定義に suggester を追加します。
private static void CreateIndex(string indexName, SearchIndexClient indexClient)
{
FieldBuilder fieldBuilder = new FieldBuilder();
var searchFields = fieldBuilder.Build(typeof(Hotel));
var definition = new SearchIndex(indexName, searchFields);
var suggester = new SearchSuggester("sg", new[] { "HotelName", "Category", "Address/City", "Address/StateProvince" });
definition.Suggesters.Add(suggester);
indexClient.CreateOrUpdateIndex(definition);
}
プロパティ リファレンス
| プロパティ | 内容 |
|---|---|
| 名前 | suggester の定義に指定しますが、オートコンプリートまたは候補の要求でも呼び出されます。 |
| ソースフィールド | suggester 定義で指定します。 候補の内容のソースであるインデックスの 1 つまたは複数のフィールドのリストです。 フィールドは Edm.String 型である必要があります。 フィールドにアナライザーが指定されている場合、LexicalAnalyzerName Struct に記載されている (カスタム アナライザーではない) 名前付きの字句アナライザーでなければなりません。 ベスト プラクティスとしては、検索バーまたはドロップダウン リストのどちらの補完された文字列でも、想定される適切な応答に利用するフィールドのみを指定します。 ホテル名は正確なため、適切な選択肢です。 説明やコメントなどの詳細なフィールドは、文字数が多くなりすぎます。 同様に、カテゴリやタグなどの反復的なフィールドでは、効果が低くなります。 例では、複数のフィールドを含めることができることを示すために、ひとまず category を含めています。 |
| 検索モード | REST のみのパラメーターですが、Azure portal にも表示されます。 このパラメーターは .NET SDK では使用できません。 候補語句の検索に使用される戦略を示します。 現在サポートされているモードは analyzingInfixMatching のみです。これは、現在、用語の先頭でマッチングを実行します。 |
suggester を使用する
クエリには suggester が使用されています。 suggester を作成したら、search-as-you-type エクスペリエンス用の次の API のいずれかを呼び出します。
検索アプリケーションでは、クライアント コードで、jQuery UI オートコンプリート などのライブラリを利用して、部分クエリを収集し、一致を提供する必要があります。 このタスクの詳細については、クライアント コードへのオートコンプリートまたは候補の結果の追加に関するページを参照してください。
API の使用方法については、オートコンプリート REST API の次の呼び出しで説明します。 この例では、2 つのポイントがあります。 第一に、すべてのクエリと同様に、操作はインデックスの documents コレクションに対して行われ、クエリには search パラメーターが含まれます。この場合、部分クエリが提供されます。 第二に、suggesterName を要求に追加する必要があります。 インデックスで suggester が定義されていない場合、オートコンプリートまたは検索候補の呼び出しは失敗します。
POST /indexes/myxboxgames/docs/autocomplete?search&api-version=2024-07-01
{
"search": "minecraf",
"suggesterName": "sg"
}
サンプル コード
クライアント アプリで部分的な用語の補完にオープン ソースの検索候補パッケージを使用する方法については、「.NET 検索コードについて確認する」を参照してください。
次のステップ
要求の形成の詳細について確認してください。