この記事では、増分インデックス作成によるスキーマの変更またはコンテンツの変更を使用して Azure AI Search の既存のインデックスを更新する方法について説明します。 再構築が必要な状況について説明し、進行中のクエリ要求に対する再構築の影響を軽減するための推奨事項を提供します。
アクティブな開発中は、インデックス デザインを反復処理するときにインデックスを削除して再構築するのが一般的です。 ほとんどの開発者は、小規模の代表的なデータ サンプルを使用して、インデックスの再作成が迅速に行われるようにします。
既に運用環境で使用されているアプリケーションのスキーマを変更する場合は、既存のインデックスと並行して実行する新しいインデックスを作成してテストすることをお勧めします。 アプリケーション コードの変更を回避できるように、 インデックスエイリアス を使用して新しいインデックスをスワップします。
コンテンツを更新する
ソース データの変更に対する増分インデックス作成とインデックスの同期は、ほとんどの検索アプリケーションの基礎となります。 このセクションでは、REST API を使用して検索インデックスのコンテンツを追加、削除、または上書きするワークフローについて説明しますが、Azure SDK には同等の機能があります。
要求の本文には、インデックスを作成する 1 つまたは複数のドキュメントが含まれます。 要求内では、インデックス内の各ドキュメントは次のようになります。
- 大文字と小文字を区別する一意のキーによって識別されます。
- アクション "upload"、"delete"、"merge"、または "mergeOrUpload" に関連付けられます。
- 追加中または更新中の各フィールドに対し、名前と値のペアのセットが設定されます。
{
"value": [
{
"@search.action": "upload (default) | merge | mergeOrUpload | delete",
"key_field_name": "unique_key_of_document", (key/value pair for key field from index schema)
"field_name": field_value (name/value pairs matching index schema)
...
},
...
]
}
まず、ドキュメント - インデックス (REST) や Azure SDK 内の同等の API など、ドキュメントを読み込むための API を使用します。 インデックス作成手法の詳細については、「 ドキュメントの読み込み」を参照してください。
大規模な更新の場合、推奨されるのはバッチ処理 (限度はバッチあたり最大 1,000 ドキュメントまたはバッチあたり約 16 MB のどちらか先に達した方) で、インデックス作成のパフォーマンスが大幅に向上します。
API で
@search.actionパラメーターを設定して、既存のドキュメントへの影響を判断します。アクション 効果 削除 インデックスから全体のドキュメントを削除します。 個々のフィールドを削除する場合は、代わりに merge を使い、問題のフィールドを null に設定します。 削除されたドキュメントとフィールドは、インデックス内の領域をすぐに解放しません。 数分ごとに、バックグラウンド プロセスによって物理的な削除が実行されます。 Azure portal と API のどちらを使用してインデックス統計を返す場合でも、削除が Azure portal と API に反映されるまでに少し遅延が発生する可能性があります。 マージ 既に存在するドキュメントを更新し、ドキュメントが見つからない場合は失敗します。 マージは既存の値を置き換えます。 そのため、 Collection(Edm.String)型のフィールドなど、複数の値を含むコレクション フィールドは必ず確認してください。 たとえば、tagsフィールドの値が["budget"]で始まり、値["economy", "pool"]でマージを実行した場合、tagsフィールドの最終値は["economy", "pool"]になります。["budget", "economy", "pool"]にはなりません。
同じ動作が複合コレクションにも当てはまります。 ドキュメントに Rooms という名前の複合コレクション フィールドが含まれており、値が[{ "Type": "Budget Room", "BaseRate": 75.0 }]である場合、[{ "Type": "Standard Room" }, { "Type": "Budget Room", "BaseRate": 60.5 }]の値でマージを実行すると、Rooms フィールドの最終的な値は[{ "Type": "Standard Room" }, { "Type": "Budget Room", "BaseRate": 60.5 }]になります。 新しい値の追加または既存の値とのマージは行われません。マージまたはアップロード ドキュメントが存在する場合は merge、ドキュメントが新しい場合は upload と同じように動作します。 これは、増分更新の最も一般的なアクションです。 アップロード "upsert" と同様に、ドキュメントが新しい場合は挿入され、存在する場合は更新または置換されます。 インデックスに必要な値がドキュメントにない場合、ドキュメント フィールドの値は null に設定されます。
インデックス作成中もクエリは引き続き実行されますが、既存のフィールドを更新または削除する場合は、結果の混合とスロットリングの発生率が高くなる可能性があります。
注
要求本文内のどのアクションが最初に実行されるかについて、順序の保証はありません。 1 つの要求本文で、同じドキュメントに複数の "マージ" アクションを関連付けすることはお勧めしません。 同じドキュメントに対して複数の "マージ" アクションが必要な場合は、検索インデックス内のドキュメントを更新する前に、クライアント側でのマージを実行します。
応答
正常な応答を示す状態コード 200 が返されます。つまり、すべての項目が永続的に格納され、インデックスの作成が開始されます。 インデックス作成はバックグラウンドで実行され、インデックス作成操作が完了してから数秒後に新しいドキュメントが使用可能 (つまり、クエリ可能で検索可能) になります。 具体的な遅延はサービスの負荷によって異なります。
インデックス作成の成功は、すべての項目の status プロパティが true に設定され、さらに statusCode プロパティが 201 (新しくアップロードされたドキュメントの場合) または 200 (マージまたは削除されたドキュメントの場合) のいずれかに設定されることによって示されます。
{
"value": [
{
"key": "unique_key_of_new_document",
"status": true,
"errorMessage": null,
"statusCode": 201
},
{
"key": "unique_key_of_merged_document",
"status": true,
"errorMessage": null,
"statusCode": 200
},
{
"key": "unique_key_of_deleted_document",
"status": true,
"errorMessage": null,
"statusCode": 200
}
]
}
1 つ以上の項目のインデックスが正常に作成されなかった場合は、状態コード 207 が返されます。 インデックスが作成されていない項目は、status フィールドが false に設定されます。 errorMessage および statusCode は、インデックス作成エラーの理由を示すプロパティです。
{
"value": [
{
"key": "unique_key_of_document_1",
"status": false,
"errorMessage": "The search service is too busy to process this document. Please try again later.",
"statusCode": 503
},
{
"key": "unique_key_of_document_2",
"status": false,
"errorMessage": "Document not found.",
"statusCode": 404
},
{
"key": "unique_key_of_document_3",
"status": false,
"errorMessage": "Index is temporarily unavailable because it was updated with the 'allowIndexDowntime' flag set to 'true'. Please try again later.",
"statusCode": 422
}
]
}
errorMessage プロパティは、可能な場合はインデックス作成エラーの理由を示します。
次の表では、応答で返されるドキュメントごとのさまざまな状態コードについて説明します。 状態コードには、要求自体に問題があることを示すものと、一時的なエラー状態を示すものがあります。 後者の場合は、待機してから再試行する必要があります。
| 状態コード | 意味 | リトライ可能 | メモ |
|---|---|---|---|
| 200 | ドキュメントは正常に変更または削除されました。 | 該当なし | 削除操作はべき等です。 つまり、インデックスにドキュメント キーが存在しない場合でも、そのキーで削除操作を行おうとすると 200 状態コードが返されます。 |
| 201 | ドキュメントは正常に作成されました。 | 該当なし | |
| 400 | ドキュメントにエラーがあり、インデックスを作成できませんでした。 | いいえ | 応答に含まれるエラー メッセージに、ドキュメントに関する問題が示されます。 |
| 404 | 指定されたキーがインデックス内に存在しないため、ドキュメントをマージできませんでした。 | いいえ | アップロードの場合は新しいドキュメントが作成されるため、このエラーは発生しません。また、削除はべき等なので、やはりこのエラーは発生しません。 |
| 409 | ドキュメントのインデックスを作成しようとしたときにバージョンの競合が検出されました。 | はい | これは、同じドキュメントに対して同時に複数回インデックスを作成しようとしたときに発生することがあります。 |
| 422 | インデックスは、allowIndexDowntime フラグを true に設定して更新されたため、一時的に使用できない状態です。 | はい | |
| 429 | 要求が多すぎます | はい | インデックス作成中にこのエラー コードが表示される場合は、通常、ストレージが不足していることを意味します。 ストレージの制限に近付くと、一部のドキュメントを削除するまでサービスは追加または更新できない状態になります。 詳細については、「容量を 計画して管理 する」を参照するか、ドキュメントを削除して容量を解放してください。 |
| 503 | 検索サービスは一時的に使用できない状態です。負荷が高いことが原因として考えられます。 | はい | この場合は、待機してから再試行する必要があります。そうしないと、サービスを使用できない状態が長引く場合があります。 |
クライアント コードで 207 応答が頻繁に検出される場合、理由の 1 つとしてシステムが高負荷の状態にあることが考えられます。 これは、statusCode プロパティが 503 になっているかどうかをチェックすることで確認できます。 statusCode が 503 の場合は、インデックス作成要求を調整することをお勧めします。 もしインデックス作成トラフィックが減らない場合、システムは503エラーで全ての要求を拒否し始める可能性があります。
状態コード 429 は、インデックスあたりのドキュメント数のクォータを超えたことを示します。 容量制限を高くするためにアップグレードするか、新しいインデックスを作成する必要があります。
注
タイム ゾーン情報を含む DateTimeOffset 値をインデックスにアップロードすると、Azure AI 検索によってこれらの値が UTC に正規化されます。 たとえば、2024-01-13T14:03:00-08:00 は 2024-01-13T22:03:00Z として格納されます。 タイム ゾーン情報を格納する必要がある場合は、このデータ ポイント用の列をインデックスに追加します。
増分インデックス作成のヒント
インデクサーは増分インデックス作成を自動化します。 インデクサーが利用可能でデータ ソースが変更の追跡をサポートしている場合は、インデクサーを定期的なスケジュールで実行して、検索可能なコンテンツを追加、更新、または上書きし、外部データと同期させることができます。
プッシュ API を介してインデックス呼び出しを直接行う場合は、検索アクションとして
mergeOrUploadを使用します。ペイロードには、追加、更新、または削除するすべてのドキュメントのキーまたは識別子が含まれている必要があります。
インデックスにベクター フィールドが含まれており、
storedプロパティを false に設定する場合は、値が変更されていない場合でも、部分的なドキュメント更新でベクターを指定してください。storedを false に設定すると、インデックス再作成操作でベクトルが削除されるという副作用があります。 ドキュメント ペイロードでベクトルを提供すると、このようなことが起きなくなります。複合型の簡易フィールドとサブフィールドの内容を更新するには、変更するフィールドのみを一覧表示します。 たとえば、説明フィールドのみを更新しなければならない場合、ペイロードはドキュメント キーと変更された説明で構成されている必要があります。 他のフィールドを省略することで、既存の値が保持されます。
インライン変更を文字列コレクションにマージするには、値全体を指定します。 前のセクションの
tagsフィールドの例を思い出してください。 新しい値によってフィールド全体の古い値が上書きされ、フィールドの内容内でマージは行われません。
これらのヒントを示す REST API の例 を次に示します。
### Get Stay-Kay City Hotel by ID
GET {{baseUrl}}/indexes/hotels-vector-quickstart/docs('1')?api-version=2024-07-01 HTTP/1.1
Content-Type: application/json
api-key: {{apiKey}}
### Change the description, city, and tags for Stay-Kay City Hotel
POST {{baseUrl}}/indexes/hotels-vector-quickstart/docs/search.index?api-version=2024-07-01 HTTP/1.1
Content-Type: application/json
api-key: {{apiKey}}
{
"value": [
{
"@search.action": "mergeOrUpload",
"HotelId": "1",
"Description": "I'm overwriting the description for Stay-Kay City Hotel.",
"Tags": ["my old item", "my new item"],
"Address": {
"City": "Gotham City"
}
}
]
}
### Retrieve the same document, confirm the overwrites and retention of all other values
GET {{baseUrl}}/indexes/hotels-vector-quickstart/docs('1')?api-version=2024-07-01 HTTP/1.1
Content-Type: application/json
api-key: {{apiKey}}
インデックス スキーマを更新する
インデックス スキーマは、検索サービスで作成された物理データ構造を定義するため、完全な再構築を行わずに行うことができるスキーマの変更はあまりありません。
リビルドなしの更新
次の一覧は、既存のインデックスにシームレスに導入できるスキーマの変更を列挙したものです。 一般に、一覧には、クエリの実行中に使用される新しいフィールドと機能が含まれています。
- インデックスの説明を追加する (プレビュー)
- 新しいフィールドの追加
- 既存のフィールドに
retrievable属性を設定する - 既存の
searchAnalyzerを持つフィールドのindexAnalyzerを更新する - インデックスに新しい アナライザー定義 を追加する (新しいフィールドに適用できます)
- スコアリング プロファイルの追加、更新、または削除
- synonymMaps の追加、更新、または削除
- セマンティック構成の追加、更新、または削除
- CORS の設定を追加、更新、削除する
操作の順序は次のとおりです。
以前の一覧からの更新を使用してスキーマを変更します。
検索サービスのインデックス スキーマを更新します。
新しいフィールドを追加した場合は、変更したスキーマに合わせてインデックスの内容を更新します。 その他の変更については、インデックスが作成された既存の内容がそのまま使用されます。
新しいフィールドを含めるようにインデックス スキーマを更新すると、インデックス内の既存のドキュメントにはそのフィールドに null 値が割り当てられます。 次のインデックス作成ジョブでは、外部ソース データからの値が、Azure AI 検索によって追加された null に置き換えられます。
更新中にクエリが中断されることはありませんが、更新が反映されるとクエリ結果は変わります。
リビルドが必要な更新
一部の変更では、インデックスをドロップして再構築し、現在のインデックスを新しいインデックスに置き換える必要があります。
| アクション | 説明 |
|---|---|
| フィールドの削除 | フィールドのすべてのトレースを物理的に削除するには、インデックスを再構築する必要があります。 即時再構築が実用的でない場合は、古いフィールドからアクセスをリダイレクトするようにアプリケーション コードを変更するか 、searchFields を使用してクエリ パラメーター を選択 して、検索して返されるフィールドを選択できます。 物理的には、そのフィールドを無視するスキーマを適用すると、次に再構築が行われるまでフィールドの定義と内容はインデックスに維持されます。 |
| フィールド定義を変更する | フィールド名、データ型、または特定の インデックス属性 (検索可能、フィルター可能、並べ替え可能、ファセット可能) の変更には、完全な再構築が必要です。 |
| アナライザーをフィールドに割り当てる | アナライザー はインデックスで定義され、フィールドに割り当てられ、インデックス作成中に呼び出され、トークンの作成方法が通知されます。 新しいアナライザー定義はいつでもインデックスに追加できますが、アナライザーはフィールドの作成時にのみ 割り当てることができます 。 これは、 アナライザー プロパティと indexAnalyzer プロパティの両方に当てはまります。 searchAnalyzer プロパティは例外です (このプロパティを既存のフィールドに割り当てることができます)。 |
| インデックス内のアナライザー定義を更新または削除する | インデックス全体を再構築しない限り、インデックス内にある既存のアナライザー構成 (アナライザー、トークナイザー、トークン フィルター、または文字フィルター) を削除または変更することはできません。 |
| suggester にフィールドを追加する | フィールドが既に存在し、 Suggesters コンストラクトに追加する場合は、インデックスを再構築します。 |
| サービスまたはレベルをアップグレードする | さらに容量が必要な場合は、 サービスをアップグレード できるか、 より高い価格レベルに切り替えることができるか確認してください。 そうでない場合は、新しいサービスを作成し、インデックスを最初から再構築する必要があります。 このプロセスを自動化するために、インデックスを一連の JSON ファイルにバックアップするコード サンプルを使用できます。 その後、指定した検索サービスでインデックスを再作成できます。 |
操作の順序は次のとおりです。
将来参照する必要がある場合や、新しいバージョンの基礎として使用する場合に備えて、インデックス定義を取得します。
バックアップと復元のソリューションを使用して、インデックス内容のコピーを保持することを検討してください。 C# と Python にはソリューションがあります。 Python バージョンは最新の状態であるため、お勧めします。
検索サービスの容量がある場合は、新しいインデックスを作成してテストする間、既存のインデックスを残しておきます。
既存のインデックスを削除します。 そのインデックスを対象とするすべてのクエリがすぐに削除されます。 インデックスの削除は元に戻すことができません。フィールド コレクションやその他の構造の物理ストレージが破壊されます。
変更されたインデックスを投稿します。要求の本文には、変更または変更されたフィールドの定義と構成が含まれます。
外部ソースからドキュメントを含むインデックスを読み込みます。 ドキュメントは、新しいスキーマのフィールド定義と構成を使用してインデックスが作成されます。
インデックスを作成すると、インデックス スキーマのフィールドごとに物理ストレージが割り当てられ、検索可能なフィールドごとの逆インデックスと、ベクター フィールドごとのベクター インデックスが作成されます。 検索できないフィールドは、フィルターまたは式で使用できますが、逆インデックスを持たないため、フルテキスト検索やあいまい検索はできません。 インデックスの再構築では、これらの逆インデックスとベクター フィールドが削除されて、指定したインデックス スキーマに基づいて再作成されます。
アプリケーション コードの中断を最小限に抑えるには、 インデックスエイリアスを作成することを検討してください。 アプリケーション コードは別名を参照しますが、別名が指すインデックスの名前は更新することができます。
インデックスの説明を追加する (プレビュー)
REST API バージョン 2025-05-01-preview 以降では、 ddescription がサポートされるようになりました。 この人間が判読できるテキストは、システムが複数のインデックスにアクセスし、説明に基づいて決定を下す必要がある場合に非常に重要です。 実行時に適切なインデックスを選択する必要があるモデル コンテキスト プロトコル (MCP) サーバーについて考えてみましょう。 決定は、インデックス名だけでではなく、説明に基づいて行うことができます。
インデックスの説明はスキーマの更新であり、インデックス全体を再構築しなくても追加できます。
- 文字列の長さは最大 4,000 文字です。
- Unicode では、コンテンツは人間が判読できる必要があります。 ユース ケースで、使用する言語を決定する必要があります。
インデックスの説明のサポートは、プレビュー REST API、Azure portal、または機能を提供するプレリリース Azure SDK パッケージで提供されます。
Azure portal では、最新のプレビュー API がサポートされています。
Azure portal にサインインし、検索サービスを見つけます。
[ 検索の管理>インデックス] で、インデックスを選択します。
[JSON の編集] を選択します。
"description"を挿入し、その後に説明を挿入します。 値は 4,000 文字未満で、Unicode で指定する必要があります。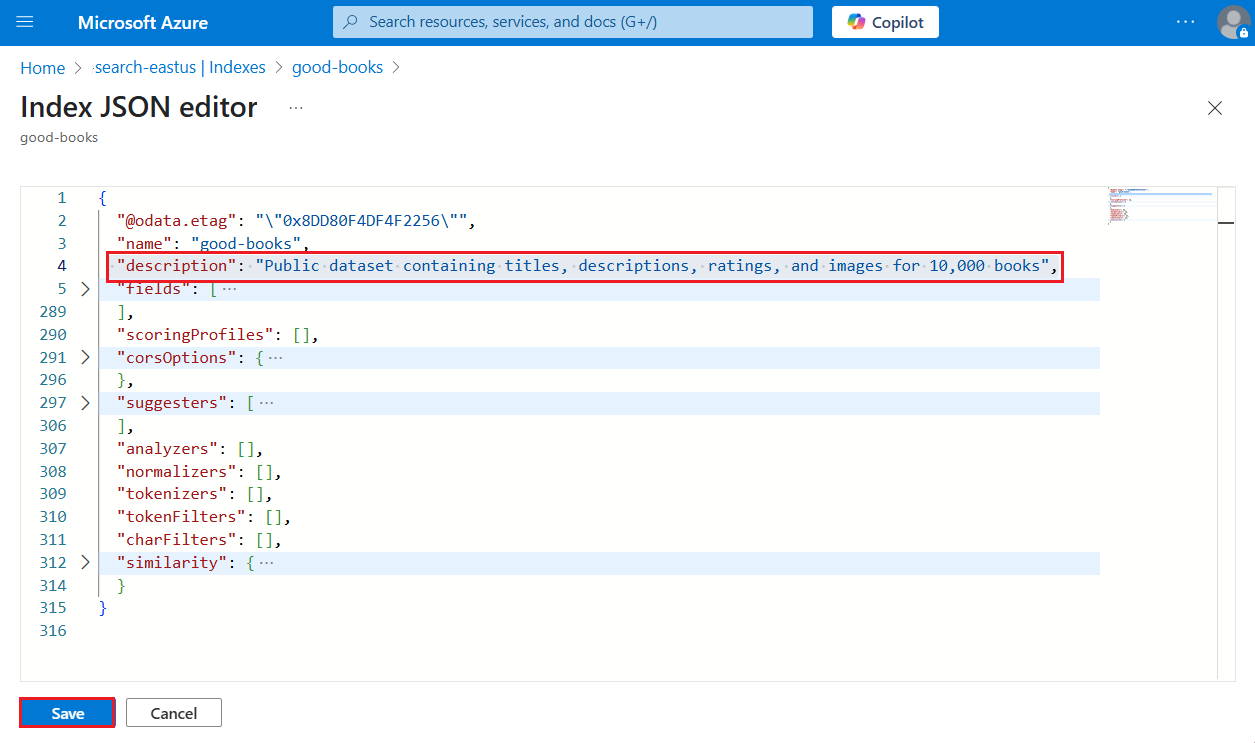
インデックスを保存します。
ワークロードの分散
インデックス作成はバックグラウンドでは実行されませんが、インデックス作成ジョブと進行中のクエリのバランスは、検索サービスによって調整されます。 インデックス作成中に、Azure portal で クエリ要求を監視 して、クエリがタイムリーに完了していることを確認できます。
インデックス作成ワークロードで許容できないレベルのクエリ待機時間が発生する場合は、 パフォーマンス分析 を実施し、潜在的な軽減策についてこれらの パフォーマンスのヒント を確認してください。
更新プログラムの確認
最初のドキュメントが読み込まれたらすぐに、インデックスのクエリを始めることができます。 ドキュメントの ID がわかっている場合、 Lookup Document REST API は特定のドキュメントを返します。 さらに範囲の広いテストでは、インデックスが完全に読み込まれるまで待ってから、クエリを使用して表示されるはずのコンテキストを確認する必要があります。
Search Explorer または REST クライアントを使用して、更新されたコンテンツを確認できます。
フィールドを追加または名前変更した場合は、 select を使用してそのフィールドを返します。
"search": "*",
"select": "document-id, my-new-field, some-old-field",
"count": true
Azure portal には、インデックス サイズとベクター インデックス サイズが用意されています。 これらの値はインデックスの更新後に確認できます。ただし、サービスが変更を処理する際に若干の遅延が発生すること、およびポータルの更新速度を考慮することを忘れないでください。これは数分です。
孤立したドキュメントを削除する
Azure AI Search では、ドキュメント レベルの操作がサポートされているため、特定のドキュメントを別個に検索、更新、削除できます。 次の例は、ドキュメントを削除する方法を示しています。
ドキュメントを削除しても、インデックス内の領域はすぐには解放されません。 数分ごとに、バックグラウンド プロセスによって物理的な削除が実行されます。 Azure portal と API のどちらを使用してインデックス統計を返す場合でも、削除が Azure portal と API のメトリックに反映されるまでに少し遅延が発生する可能性があります。
ドキュメント キーであるフィールドを特定します。 Azure portal で、各インデックスのフィールドを表示できます。 ドキュメント キーは文字列フィールドであり、見つけやすくするためにキー アイコンで示されます。
ドキュメント キー フィールドの値
search=*&$select=HotelIdを確認します。 単純な文字列は分かりやすいですが、インデックスで base-64 でエンコードされたフィールドが使用されている場合、または検索ドキュメントがparsingMode設定から生成されている場合は、馴染みのない値を操作する可能性があります。ドキュメントを検索してドキュメント ID の値を確認し、その内容を確認してから削除します。 要求でキーまたはドキュメント ID を指定します。 次の例は、 Hotels サンプル インデックス の単純な文字列と、 cog-search-demo インデックスのmetadata_storage_path キーに base-64 でエンコードされた文字列を示しています。
GET https://[service name].search.windows.net/indexes/hotel-sample-index/docs/1111?api-version=2024-07-01GET https://[service name].search.windows.net/indexes/cog-search-demo/docs/aHR0cHM6Ly9oZWlkaWJsb2JzdG9yYWdlMi5ibG9iLmNvcmUud2luZG93cy5uZXQvY29nLXNlYXJjaC1kZW1vL2d1dGhyaWUuanBn0?api-version=2024-07-01削除 を使用して
@search.actionし、検索インデックスから削除します。POST https://[service name].search.windows.net/indexes/hotels-sample-index/docs/index?api-version=2024-07-01 Content-Type: application/json api-key: [admin key] { "value": [ { "@search.action": "delete", "id": "1111" } ] }