ファセット ナビゲーションは、検索アプリのクエリ結果に対するセルフダイレクト フィルター処理に使用されます。アプリケーションでは、ドキュメントのグループ (カテゴリやブランドなど) に検索範囲を設定するためのフォーム コントロールが提供され、Azure AI Search はエクスペリエンスをサポートするデータ構造とフィルターを提供します。
この記事では、Azure AI Search でファセット ナビゲーション構造を返す手順について説明します。 基本的な概念とクライアントを理解したら、基本的なファセットや個別のカウントなど、さまざまなユース ケースに関する構文の ファセットの例 に進んでください。
プレビュー API を使用して、その他のファセット機能を利用できます。
- 階層ファセット構造
- ファセットフィルタリング
- ファセット集計
ファセット ナビゲーションの例では、 プレビュー機能の構文と使用方法を示します。
検索ページでのファセット ナビゲーション
ファセットは、各特定のクエリ結果セットに基づいているため、動的です。 検索応答には、結果内のドキュメント内を移動するために使用されるすべてのファセット バケットが含まれます。 まずクエリが実行され、次に現在の結果からファセットが取得され、ファセット ナビゲーション構造に構築されます。
Azure AI Search では、ファセットは 1 層深く、プレビュー API を使用しない限り階層的にすることはできません。 ファセット ナビゲーション構造になじみがない場合は、次の例の左側にそれが示されています。 カウントは、ファセットごとの一致の数を示しています。 同じドキュメントを複数のファセットで表現できます。
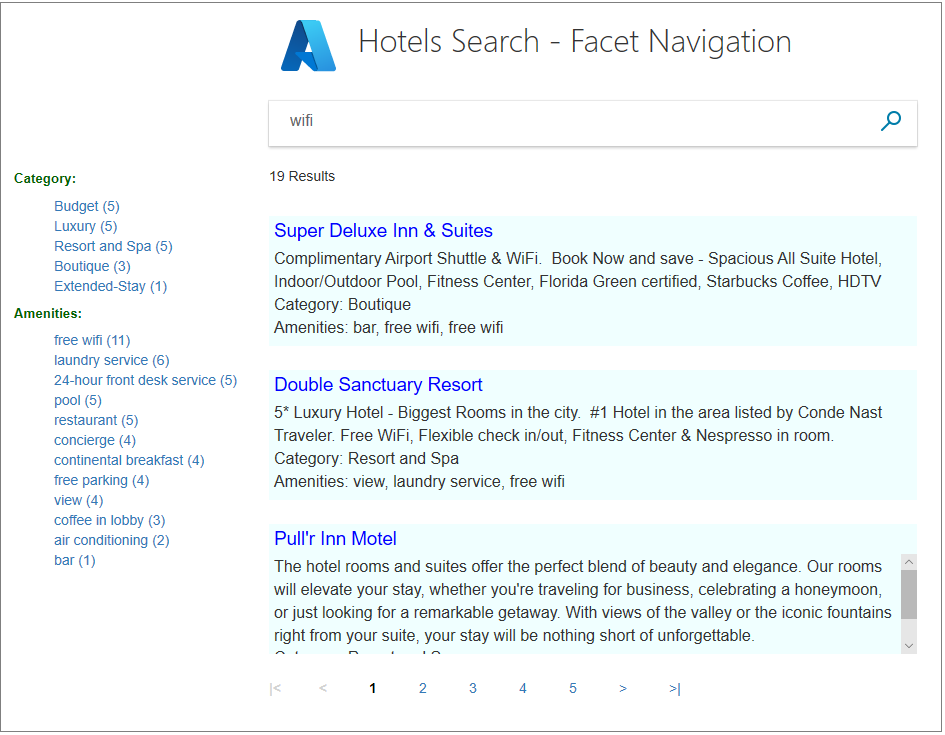
ファセットを使用すると、探しているものが見つけやすくなり、検索結果がゼロ件になることはありません。 開発者は、ファセットを使用することで検索インデックスのナビゲーションに最も役立つ検索条件を公開できます。
コード内の絞り込みナビゲーション
ファセットは、インデックス内のサポートされているフィールドで有効になり、クエリで指定されます。 ファセット ナビゲーション構造は、応答の先頭に返され、その後に結果が返されます。
次の REST の例は、インデックス全体を対象とする空のクエリ ("search": "*") です ( 組み込みのホテル サンプルを参照)。 facetsパラメーターは、"Category" フィールドを指定します。
POST https://{{service_name}}.search.windows.net/indexes/hotels/docs/search?api-version={{api_version}}
{
"search": "*",
"queryType": "simple",
"select": "",
"searchFields": "",
"filter": "",
"facets": [ "Category"],
"orderby": "",
"count": true
}
この例の応答は、ファセット ナビゲーション構造から始まります。 この構造は、"Category" 値と、それぞれに対するホテルの数で構成されています。 その後、残りの検索結果が表示され、簡潔にするために 1 つのドキュメントだけにトリミングされます。 この例は、いくつかの理由で適切に機能します。 このフィールドのファセットの数は制限 (既定値は 10) に収まるため、そのすべてが表示され、50 軒のホテルのインデックス内のすべてのホテルが、これらのカテゴリのうちの正確に 1 つで表されます。
{
"@odata.context": "https://demo-search-svc.search.windows.net/indexes('hotels')/$metadata#docs(*)",
"@odata.count": 50,
"@search.facets": {
"Category": [
{
"count": 13,
"value": "Budget"
},
{
"count": 12,
"value": "Resort and Spa"
},
{
"count": 9,
"value": "Luxury"
},
{
"count": 7,
"value": "Boutique"
},
{
"count": 5,
"value": "Suite"
},
{
"count": 4,
"value": "Extended-Stay"
}
]
},
"value": [
{
"@search.score": 1.0,
"HotelId": "1",
"HotelName": "Stay-Kay City Hotel",
"Description": "The hotel is ideally located on the main commercial artery of the city in the heart of New York. A few minutes away is Time's Square and the historic centre of the city, as well as other places of interest that make New York one of America's most attractive and cosmopolitan cities.",
"Category": "Boutique",
"Tags": [
"pool",
"air conditioning",
"concierge"
],
"ParkingIncluded": false,
},
. . .
]
}
フィールドでファセットを有効にする
プレーン テキストまたは数値コンテンツを含む新しいフィールドにファセットを追加できます。 サポートされているデータ型には、文字列、日付、ブール型フィールド、数値フィールド (ベクトルは含まれません) が含まれます。
Azure portal、REST API、Azure SDK、または Azure AI Search でのインデックス スキーマの作成または更新をサポートする任意の方法を使用できます。 最初の手順として、ファセットに使用するフィールドを特定します。
属性を設定するフィールドを選択する
ファセットは、単一値フィールドとコレクションに対して計算できます。 ファセット ナビゲーションで最適に機能するフィールドには、次の特性があります。
- 人間が判読できる (非ベクトル) コンテンツ。
- カーディナリティが低い (検索コーパス内のドキュメント全体で繰り返されるいくつかの個別の値)。
- ナビゲーション ツリーで適切にレンダリングされる短い説明値 (1 つまたは 2 つの単語)。
ファセット ナビゲーション構造でファセットが生成されるのは、フィールド名自体ではなく、フィールド内の値によるものです。 ファセットが Color という名前の文字列フィールドである場合、ファセットは青色、緑色、またはそのフィールドの他の任意の値になります。 フィールド値を確認して、入力ミス、null 値、大文字と小文字の違いがないことを確認します。 フィルター可能でファセット可能なフィールドに ノーマライザーを割り当てて 、テキストの小さなバリエーションを滑らかにすることを検討してください。 たとえば、「Canada」、「CANADA」、「canada」はすべて 1 つのバケットに正規化されます。
サポートされていないフィールドを回避する
既存のフィールド、ベクター フィールド、 Edm.GeographyPoint 型または Collection(Edm.GeographyPoint)型のフィールドにファセットを設定することはできません。
複合フィールドコレクションでは、"facetable" は null にする必要があります。
新しいフィールド定義から始める
フィールドのインデックス付け方法に影響する属性は、フィールドの作成時にのみ設定できます。 この制限は、ファセットとフィルターに適用されます。
インデックスが既に存在する場合は、ファセットを提供する新しいフィールド定義を追加できます。 インデックス内の既存のドキュメントは、新しいフィールドの null 値を取得します。 この null 値は、次回 インデックスを更新するときに置き換えられます。
Azure portal の [検索サービス] ページで、インデックスの [フィールド] タブに移動し、[フィールドの追加] を選択します。
名前、データ型、属性を指定します。 応答のファセット バケットに基づいてフィルターを設定するのが一般的であるため、フィルター可能を追加することをお勧めします。 フィルターによって順序付けされていない結果が生成されるため、並べ替え可能にすることをお勧めします。また、アプリケーションで並べ替えたい場合もあります。
また、フィールドのフルテキスト検索をサポートする場合は検索可能を設定し、検索応答にフィールドを含める場合は取得可能に設定することもできます。
![Azure portal の [フィールドの追加] ページのスクリーンショット。](media/search-faceted-navigation/portal-add-facetable-field.png)
フィールド定義を保存します。
![Azure portal の [フィールドの追加] ページのスクリーンショット。](media/search-faceted-navigation/portal-add-facetable-field.png#lightbox)
クエリでファセットを返す
ファセットはクエリ応答の結果から動的に計算されることを思い出してください。 現在のクエリで見つかったドキュメントのファセットのみが取得されます。
Search Explorer の JSON ビューを使用して、 Azure portal でファセット パラメーターを設定します。
- インデックスを選択し、JSON ビューで検索エクスプローラーを開きます。
- JSON でクエリを指定します。 入力したり、REST の例から JSON をコピーしたり、Intellisense を使用して構文を支援することができます。 ファセット式のリファレンスについては、次のタブの REST の例を参照してください。
- JSON で明確に示されたファセット結果を返すには、[ 検索 ] を選択します。
hotels サンプル インデックスの基本的なファセット クエリの例のスクリーンショットを次に示します。 この記事の他の例を貼り付けて、Search Explorer で結果を返すことができます。
![Azure portal の [Search Explorer] ページのスクリーンショット。](media/search-faceted-navigation/portal-facet-query.png#lightbox)
ファセットを操作するためのベスト プラクティス
このセクションは、アプリケーション開発に役立つヒントと回避策のコレクションです。
C#: プレゼンテーション レイヤーのコードを含むファセット ナビゲーションの例については、 Web アプリに検索を追加 することをお勧めします。 サンプルには、フィルター、提案、オートコンプリートも含まれています。 プレゼンテーション レイヤーには JavaScript と React が使用されます。
修飾されていない、または空の検索文字列を使用してファセット ナビゲーション構造を初期化します
ファセット ナビゲーション構造を完全に埋めるために、開いているクエリ ("search": "*") を使用して検索ページを初期化すると便利です。 クエリ用語を要求で渡すと、ファセットナビゲーション構造はインデックス全体ではなく、結果内の一致に限定されます。 この方法は、テスト中にファセットとフィルターの動作を確認する場合に役立ちます。 クエリに一致条件を含める場合、応答では一致しないドキュメントが除外され、ファセットを除外するダウンストリーム効果が生じる可能性があります。
ファセットをクリアする
ユーザー エクスペリエンスを設計するときは、ファセットをクリアするためのメカニズムを必ず追加してください。 ファセットをクリアするための一般的な方法は、開いているクエリを発行してページをリセットすることです。
ファセットを無効にしてストレージを節約し、パフォーマンスを向上させる
パフォーマンスとストレージの最適化のために、ファセットとして使用してはならないフィールドの "facetable": false を設定します。 たとえば、ID や製品名などの一意の値の文字列フィールドを使用して、ファセット ナビゲーションでの誤った (および効果のない) 使用を防ぎます。 このベスト プラクティスは、既定で文字列フィールドのフィルターとファセットを有効にする REST API にとって特に重要です。
ファセット ナビゲーションでは Edm.GeographyPoint または Collection(Edm.GeographyPoint) フィールドを使用できないことに注意してください。 ファセットはカーディナリティの低いフィールドで最適に機能することを思い出してください。 geo 座標の解決方法により、特定のデータセットで 2 つの座標セットが等しいことはまれです。 そのため、ファセットは地理座標ではサポートされていません。 場所ごとにファセットするには、市区町村または地域フィールドを使用する必要があります。
不適切なデータを確認する
インデックス作成用のデータを準備する際は、フィールド内のnull値、スペルミス、大文字小文字の不一致、および同じ単語の単数形と複数形を確認してください。 既定では、フィルターやファセットでは字句解析やスペル チェックは実行されません。つまり、単語が 1 文字だけ異なる場合でも、"facetable" フィールドのすべての値が潜在的なファセットになります。
ノーマライザー は、データの不一致を軽減し、大文字小文字や文字の違いを修正できます。 それ以外の場合は、データを検査するために、ソースのフィールドを確認したり、インデックスから値を返すクエリを実行したりできます。
インデックスは、null または無効な値を修正するのに最適な場所ではありません。 ソースのデータの問題は、データベースまたは永続ストレージ、またはインデックス作成の前に実行するデータ クレンジング手順で修正する必要があります。
ファセット バケットの順序付け
バケット内で並べ替えることができますが、ナビゲーション構造全体のファセット バケットの順序を制御するためのパラメーターはありません。 ファセット バケットを特定の順序で指定する場合は、アプリケーション コードで指定する必要があります。
ファセット数の不一致
特定の状況では、シャーディング アーキテクチャのために、ファセット数が十分に正確でない場合があります。 すべての検索インデックスが複数のシャードに展開され、それぞれのシャードがドキュメント数によって上位 N 個のファセットを報告すると、単一の結果に結合されます。 これは、各シャードの上位 N 個のファセットに過ぎないため、ファセット応答で一致するドキュメントが欠落または不足する可能性があります。
正確性を保証するために、数: <number> を大きい数に人為的に膨らませて、各シャードから完全なレポートを強制的に実行できます。 ファセットを無制限にするために、"count": "0" を指定できます。 または、"count" を、ファセット フィールドの一意の値の数以上の値に設定できます。 たとえば、一意の値が 5 つある "size" フィールドでファセットを実行する場合、すべての一致がファセット応答で表されるように "count:5" を設定できます。
この対処法のトレードオフは、クエリ待機時間が増加することです。そのため、この方法は必要な場合にのみ使用してください。
フィルター処理された結果のファセット ナビゲーション構造を非同期に保持する
Azure AI Search では、ファセットは現在の結果にのみ存在します。 一般的なアプリケーションの要件として、ユーザーが元のルートをたどり直し、検索コンテンツを通じて代替パスを探索できるようにするために、静的なファセットのセットを保持することがあります。
動的ドリルダウン エクスペリエンスと共にファセットの静的セットが必要な場合は、2 つのフィルター処理されたクエリを使用して実装できます。1 つは結果にスコープを設定し、もう 1 つはナビゲーション目的でファセットの静的リストを作成するために使用します。
フィルターを使用して大きなファセット数をオフセットする
検索結果とファセットの結果が大きすぎる場合は、 フィルターを追加することでトリミングできます。 次の例では、 クラウド コンピューティングのクエリでは、254 項目がコンテンツ タイプとして 内部仕様 を持っています。 結果が大きすぎる場合、フィルターを追加すると、ユーザーは条件を追加してクエリを絞り込むことができます。
項目は相互に排他的ではありません。 1 つの項目が両方のフィルターの条件を満たしている場合、その項目はそれぞれにカウントされます。 この重複は、ドキュメントのタグ付けを実装するために使用されることの多い Collection(Edm.String) フィールドのファセット処理で発生する可能性があります。
Search term: "cloud computing"
Content type
Internal specification (254)
Video (10)