このクイック スタートでは、Azure portal の データのインポートとベクター化 ウィザードを使用して 、マルチモーダル検索を開始します。 ウィザードを使用すると、テキストと画像の両方を抽出、チャンク、ベクター化、および検索可能なインデックスに読み込むプロセスが簡略化されます。
クイック スタートとは異なり、このクイック スタートでは、単純なテキストを含む画像を処理する Azure portal でのベクター検索で、マルチモーダル RAG シナリオの高度な画像処理がサポートされています。
このクイック スタートでは、 azure-search-sample-data リポジトリのマルチモーダル PDF を使用します。 ただし、さまざまなファイルを使用しても、このクイック スタートを完了できます。
前提条件
アクティブなサブスクリプションを持つ Azure アカウント。 無料でアカウントを作成できます。
Azure AI Search サービス。 Basic レベル以上をお勧めします。
Azure Storage アカウント。 標準パフォーマンス (汎用 v2) アカウントで、Azure Blob Storage または Azure Data Lake Storage Gen2 (階層型名前空間を持つストレージ アカウント) を使用します。 アクセス層は、ホット、クール、またはコールドにすることができます。
ウィザードに関する知識。 Azure portal のデータのインポート ウィザードを参照してください。
サポートされている抽出方法
コンテンツ抽出では、Azure AI Search を使用した既定の抽出または Azure AI ドキュメント インテリジェンスによる拡張抽出のいずれかを選択できます。 次の表では、両方の抽出方法について説明します。
| メソッド | 説明 |
|---|---|
| 既定の抽出 | PDF 画像からのみ場所のメタデータを抽出します。 別の Azure AI リソースは必要ありません。 |
| 強化された抽出 | 複数の種類のドキュメントのテキストと画像から場所のメタデータを抽出します。 サポートされているリージョンの Azure AI サービス マルチサービス リソース1 が必要です。 |
1 課金目的で、 Azure AI マルチサービス リソースを Azure AI Search サービス のスキルセットにアタッチする必要があります。 キーレス接続を使用してスキルセットを作成しない限り、両方のリソースが同じリージョンに存在する必要があります。
サポートされている埋め込みメソッド
コンテンツ埋め込みの場合は、画像の言語化 (その後にテキストベクター化) またはマルチモーダル埋め込みを選択できます。 モデルのデプロイ手順については、 後のセクションで説明します。 次の表では、両方の埋め込みメソッドについて説明します。
| メソッド | 説明 | サポートされているモデル |
|---|---|---|
| 画像の言語化 | LLM を使用して画像の自然言語の説明を生成し、埋め込みモデルを使用してプレーン テキストと言語化された画像をベクター化します。 Azure OpenAI リソース1、2、または Azure AI Foundry プロジェクトが必要です。 テキストベクター化の場合は、サポートされているリージョンで Azure AI サービス マルチサービス リソース3 を使用することもできます。 |
LLM: GPT-4o GPT-4o-mini phi-4 4 モデルの埋め込み: text-embedding-ada-002 text-embedding-3-small テキスト埋め込み3ラージ |
| マルチモーダル埋め込み | 埋め込みモデルを使用して、テキストと画像の両方を直接ベクター化します。 サポートされているリージョンに Azure AI Foundry プロジェクトまたは Azure AI サービス マルチサービス リソース3 が必要です。 |
Cohere-embed-v3-英語 Cohere-embed-v3-多言語 |
1 Azure OpenAI リソースのエンドポイントには、が必要です。 Azure portal でリソースを作成した場合、このサブドメインはリソースのセットアップ中に自動的に生成されました。
Azure AI Foundry ポータルで作成された 2 つの Azure OpenAI リソース (埋め込みモデルにアクセス可能) はサポートされていません。 Azure portal で Azure OpenAI リソースを作成する必要があります。
3 課金目的で、 Azure AI マルチサービス リソースを Azure AI Search サービスのスキルセットにアタッチする必要があります。 キーレス接続 (プレビュー) を使用してスキルセットを作成しない限り、両方のリソースが同じリージョンに存在する必要があります。
4phi-4 は、Azure AI Foundry プロジェクトでのみ使用できます。
パブリック エンドポイントの要件
上記のすべてのリソースでは、Azure portal ノードがそれらにアクセスできるように、パブリック アクセスが有効になっている必要があります。 そうでないと、ウィザードは失敗します。 ウィザードの実行後、セキュリティのために統合コンポーネントでファイアウォールとプライベート エンドポイントを有効にすることができます。 詳細については、インポート ウィザードでの安全な接続に関するページを参照してください。
プライベート エンドポイントが既に存在し、無効にできない場合は、仮想マシン上のスクリプトまたはプログラムからそれぞれのエンド ツー エンド フローを実行することもできます。 仮想マシンはプライベート エンドポイントと同じ仮想ネットワーク上にある必要があります。 垂直統合用の Python コード サンプルを次に示します。 同じ GitHub リポジトリには、他のプログラミング言語のサンプルがあります。
領域の確認
Free サービスで始める場合は、3 つのインデックス、3 つのデータ ソース、3 つのスキルセット、3 つのインデクサーに制限されます。 十分な空き領域があることを確認してから開始してください。 このクイックスタートでは、各オブジェクトを 1 つずつ作成します。
アクセスを構成する
開始する前に、コンテンツと操作にアクセスするためのアクセス許可があることを確認してください。 承認には、Microsoft Entra ID 認証とロールベースのアクセスをお勧めします。 ロールを割り当てるには、 所有者 または ユーザー アクセス管理者 である必要があります。 ロールが実現できない場合は、代わりに キーベースの認証 を使用できます。
このセクションで識別される 必要なロール と 条件付きロール を構成します。
必要な役割
すべてのマルチモーダル検索シナリオでは、Azure AI Search と Azure Storage が必要です。
Azure AI Search は、マルチモーダル パイプラインを提供します。 データの読み取り、パイプラインの実行、他の Azure リソースとの対話を行うために、自分と検索サービスのアクセスを構成します。
Azure AI Search サービスで次の手順を実行します。
-
Search Service サービス貢献者
検索インデックス データ共同作成者
検索インデックス データ閲覧者
条件付きロール
次のタブでは、マルチモーダル検索用のすべてのウィザード互換リソースについて説明します。 選択した 抽出方法 と 埋め込み方法に適用されるタブのみを選択します。
Azure OpenAI には、テキストと画像のベクター化のための画像言語化と埋め込みモデル用の LLM が用意されています。 検索サービスでは、 GenAI Prompt スキル と Azure OpenAI Embedding スキルを呼び出すアクセス権が必要です。
Azure OpenAI リソースで次の手順を実行します。
- Cognitive Services OpenAI ユーザーをお使いの検索サービス ID に割り当てます。
サンプル データの準備
このクイック スタートでは、マルチモーダル PDF のサンプルを使用しますが、独自のファイルを使用することもできます。 無料の検索サービスを利用している場合は、20 個未満のファイルを使用して、エンリッチメント処理の無料クォータ内に留めます。
このクイック スタートのサンプル データを準備するには:
Azure portal にサインインし、Azure Storage アカウントを選択します。
左側のウィンドウで、[ データ ストレージ>Containers] を選択します。
コンテナーを作成し、 サンプル PDF をコンテナーにアップロードします。
PDF から抽出された画像を格納する別のコンテナーを作成します。
モデルをデプロイする
ウィザードには、コンテンツ埋め込み用のオプションがいくつか用意されています。 画像の言語化には、テキストと画像のコンテンツをベクター化するために画像と埋め込みモデルを記述する LLM が必要ですが、直接のマルチモーダル埋め込みには埋め込みモデルのみが必要です。 これらのモデルは、Azure OpenAI と Azure AI Foundry を通じて利用できます。
注
Azure AI Vision を使用している場合は、この手順をスキップします。 マルチモーダル埋め込みは Azure AI マルチサービス リソースに組み込まれており、モデルのデプロイは必要ありません。
このクイック スタートのモデルをデプロイするには:
Azure AI Foundry ポータルにサインインします。
Azure OpenAI リソースまたは Azure AI Foundry プロジェクトを選択します。
左側のウィンドウで、[ モデル カタログ] を選択します。
選択した 埋め込み方法に必要なモデルをデプロイします。
ウィザードを起動する
マルチモーダル検索のウィザードを開始するには:
Azure portal にサインインし、Azure AI Search サービスを選択します。
[概要] ページで、[データのインポートとベクトル化] を選択します。

データ ソース ( Azure Blob Storage または Azure Data Lake Storage Gen2) を選択します。

[マルチモーダル RAG] を選択します。
![ウィザードの [マルチモーダル RAG] タイルのスクリーンショット。](media/search-get-started-portal-images/wizard-scenarios-multimodal-rag.png)

![ウィザードの [マルチモーダル RAG] タイルのスクリーンショット。](media/search-get-started-portal-images/wizard-scenarios-multimodal-rag.png#lightbox)
データへの接続
Azure AI Search では、コンテンツインジェストとインデックス作成のためにデータ ソースへの接続が必要です。 この場合、データ ソースは Azure Storage アカウントです。
データに接続するには:
[ データへの接続 ] ページで、Azure サブスクリプションを指定します。
サンプル データをアップロードしたストレージ アカウントとコンテナーを選択します。
[ マネージド ID を使用して認証 する] チェック ボックスをオンにします。 ID の種類は システム割り当てのままにします。

[次へ] を選択します。

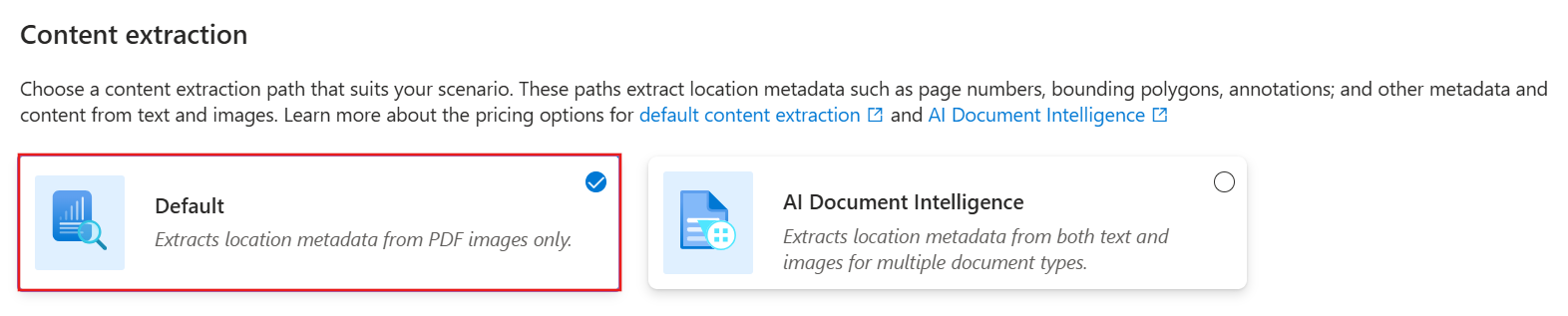
コンテンツを抽出する
選択した 抽出方法に応じて、ウィザードにはドキュメントのクラッキングとチャンクの構成オプションが用意されています。
既定のメソッドは 、ドキュメント抽出スキル を呼び出してテキスト コンテンツを抽出し、ドキュメントから正規化された画像を生成します。 次に 、抽出されたテキスト コンテンツをページに分割するために、テキスト分割スキルが呼び出されます。
ドキュメント抽出スキルを使用するには:
[ コンテンツ抽出 ] ページで、[ 既定] を選択します。
[次へ] を選択します。



コンテンツを埋め込む
この手順では、選択した 埋め込み方法を 使用して、テキストと画像の両方のベクター表現を生成します。
ウィザードでは、1 つのスキルを呼び出して画像の説明テキスト (画像の言語化) を作成し、もう 1 つのスキルを呼び出してテキストと画像の両方のベクター埋め込みを作成します。
画像の言語化の場合、 GenAI Prompt スキル はデプロイされた LLM を使用して、抽出された各画像を分析し、自然言語の説明を生成します。
埋め込みの場合、 Azure OpenAI Embedding スキル、 AML スキル、または Azure AI Vision マルチモーダル 埋め込みスキル では、デプロイされた埋め込みモデルを使用して、テキスト チャンクと言語化された説明を高次元ベクトルに変換します。 これらのベクターを使用すると、類似性とハイブリッド取得が可能になります。
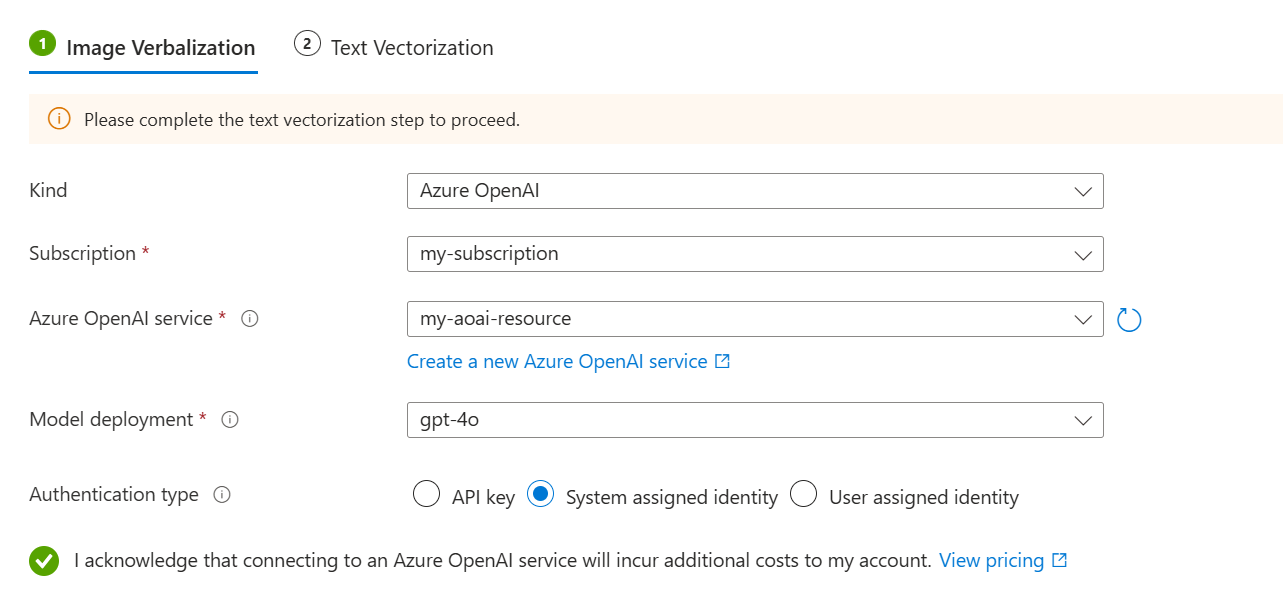
画像の言語化にスキルを使用するには:
[ コンテンツの埋め込み ] ページで、[ 画像の言語化] を選択します。
![ウィザードの [画像の言語化] タイルのスクリーンショット。](media/search-get-started-portal-images/image-verbalization-tile.png)
[ 画像の言語化 ] タブで、次の手順を実行します。
種類として、LLM プロバイダー ( Azure OpenAI または AI Foundry Hub カタログ モデル) を選択します。
Azure サブスクリプション、リソース、LLM デプロイを指定します。
認証の種類として、[ システム割り当て ID] を選択します。
これらのリソースの使用による課金への影響を認めるチェックボックスを選択します。
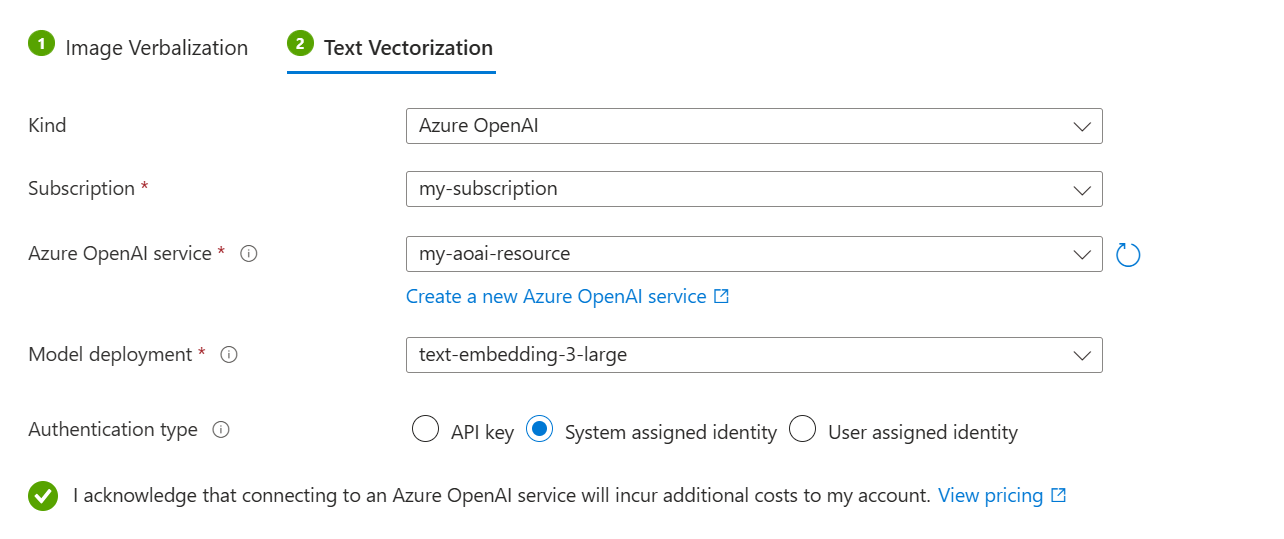
[ テキスト ベクター化 ] タブで、次の手順を実行します。
種類として、モデル プロバイダー ( Azure OpenAI、 AI Foundry Hub カタログ モデル、 AI Vision ベクター化) を選択します。
Azure サブスクリプション、リソース、埋め込みモデルのデプロイを指定します。
認証の種類として、[ システム割り当て ID] を選択します。
これらのリソースの使用による課金への影響を認めるチェックボックスを選択します。
[次へ] を選択します。
![ウィザードの [画像の言語化] タイルのスクリーンショット。](media/search-get-started-portal-images/image-verbalization-tile.png#lightbox)


![ウィザードの [マルチモーダル埋め込み] タイルのスクリーンショット。](media/search-get-started-portal-images/multimodal-embedding-tile.png#lightbox)

抽出されたイメージを格納する
次の手順では、ドキュメントから抽出されたイメージを Azure Storage に送信します。 Azure AI Search では、このセカンダリ ストレージは ナレッジ ストアと呼ばれます。
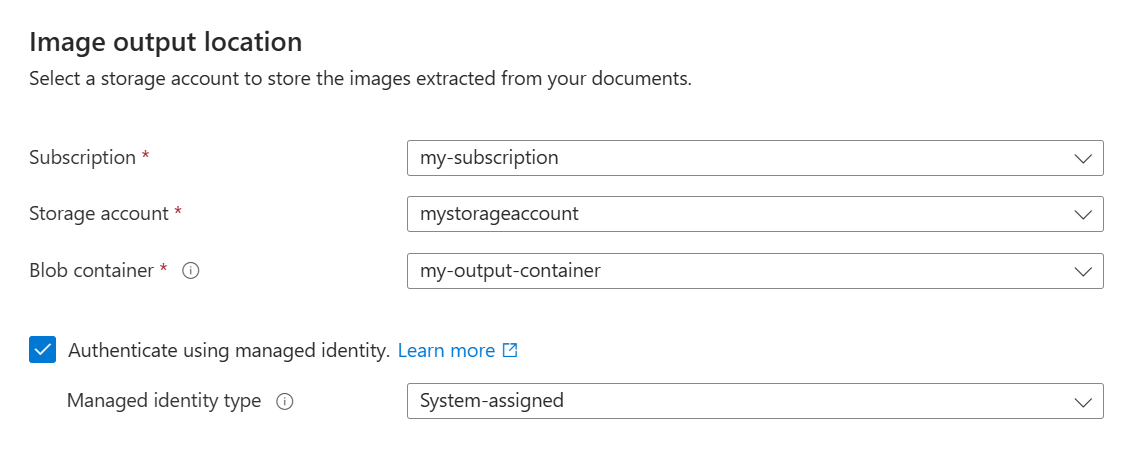
抽出されたイメージを格納するには:
[ イメージ出力 ] ページで、Azure サブスクリプションを指定します。
イメージを格納するために作成したストレージ アカウントと BLOB コンテナーを選択します。
[ マネージド ID を使用して認証 する] チェック ボックスをオンにします。 ID の種類は システム割り当てのままにします。
[次へ] を選択します。

新しいフィールドをマップする
[ 詳細設定] ページでは、必要に応じてインデックス スキーマにフィールドを追加できます。 既定では、ウィザードは次の表で説明するフィールドを生成します。
| フィールド | 適用対象 | 説明 | 属性 |
|---|---|---|---|
| content_id | テキストと画像ベクトル | 文字列フィールド。 インデックスのドキュメント キー。 | 取得可能、並べ替え可能、検索可能。 |
| ドキュメントタイトル | テキストと画像ベクトル | 文字列フィールド。 人間が判読できるドキュメントのタイトル。 | 取得可能で検索可能です。 |
| text_document_id | テキスト ベクトル | 文字列フィールド。 テキスト チャンクの作成元の親ドキュメントを識別します。 | 取得可能でフィルター可能。 |
| 画像ドキュメント識別子 | 画像ベクトル | 文字列フィールド。 画像の作成元である親ドキュメントを識別します。 | 取得可能でフィルター可能。 |
| コンテンツ_テキスト | テキスト ベクトル | 文字列フィールド。 人間が判読できるテキスト チャンクのバージョン。 | 取得可能で検索可能です。 |
| コンテンツ埋め込み | テキストと画像ベクトル | コレクション(Edm.single)。 テキストと画像のベクター表現。 | 取得可能で検索可能です。 |
| content_path | テキストと画像ベクトル | 文字列フィールド。 ストレージ コンテナー内のコンテンツへのパス。 | 取得可能で検索可能です。 |
| 所在地メタデータ | 画像ベクトル | Edm.ComplexType。 ドキュメント内のイメージの場所に関するメタデータが含まれています。 | フィールドによって異なります。 |
生成されたフィールドまたはその属性は変更できませんが、データ ソースでフィールドが提供される場合はフィールドを追加できます。 たとえば、Azure Blob Storage にはメタデータ フィールドのコレクションが用意されています。
インデックス スキーマにフィールドを追加するには:
[ インデックス] フィールドで、[ プレビューと編集] を選択します。
フィールドの追加を選択します。
使用可能なフィールドからソース フィールドを選択し、インデックスのフィールド名を入力して、既定のデータ型をそのまま使用 (またはオーバーライド) します。
スキーマを元のバージョンに復元する場合は、[リセット] を選択 します。
インデックス作成をスケジュールする
基になるデータが揮発性のデータ ソースの場合は、 インデックス作成をスケジュール して、特定の間隔または特定の日時の変更をキャプチャできます。
インデックス作成をスケジュールするには:
[ 詳細設定] ページの [ インデックス作成のスケジュール] で、インデクサーの実行スケジュールを指定します。 このクイックスタートには Once をお勧めします。

[次へ] を選択します。

ウィザードを終了する
最後の手順では、構成を確認し、マルチモーダル検索に必要なオブジェクトを作成します。 必要に応じて、ウィザードの前のページに戻り、構成を調整します。
ウィザードを完了するには:
[ 確認と作成 ] ページで、ウィザードで作成するオブジェクトのプレフィックスを指定します。 共通のプレフィックスは、整理された状態を保つのに役立ちます。

[作成] を選択します

ウィザードの構成が完了すると、次のオブジェクトが作成されます。
インデックス作成パイプラインを駆動するインデクサー。
Azure Blob Storage へのデータ ソース接続。
テキスト フィールド、ベクター フィールド、ベクター ライザー、ベクター プロファイル、およびベクター アルゴリズムを含むインデックス。 ウィザードのワークフロー中に、既定のインデックスを変更することはできません。 プレビュー機能を使用できるようにするために、インデックスは 2024-05-01-preview REST API に準拠しています。
次のスキルを持つスキルセット:
ドキュメント抽出スキルまたはドキュメント レイアウト スキルは、ソース ドキュメントからテキストと画像を抽出します。 テキスト分割スキルは、データ チャンクのドキュメント抽出スキルに付随しますが、ドキュメント レイアウト スキルにはチャンクが組み込まれています。
GenAI Prompt スキルは、自然言語で画像を言語化します。 直接マルチモーダル埋め込みを使用している場合、このスキルは存在しません。
Azure OpenAI Embedding スキル、AML スキル、または Azure AI Vision マルチモーダル 埋め込みスキルは、テキストベクター化のために 1 回、画像ベクター化のために 1 回呼び出されます。
Shaper スキルは、メタデータを使用して出力を強化し、コンテキスト情報を含む新しい画像を作成します。
ヒント
ウィザードで作成されたオブジェクトには、構成可能な JSON 定義があります。 これらの定義を表示または変更するには、左側のウィンドウから [検索管理 ] を選択します。ここでは、インデックス、インデクサー、データ ソース、スキルセットを表示できます。
結果をチェックする
このクイック スタートでは、テキストと画像の両方に対する ハイブリッド検索 をサポートするマルチモーダル インデックスを作成します。 直接マルチモーダル埋め込みを使用しない限り、インデックスは画像をクエリ入力として受け入れないので、 AML スキル または Azure AI Vision マルチモーダル埋め込みスキル と同等のベクター化が必要です。 詳細については、「 検索インデックスでベクターライザーを構成する」を参照してください。
ハイブリッド検索は、フルテキスト クエリとベクター クエリを組み合わせたものです。 ハイブリッド クエリを発行すると、検索エンジンはクエリとインデックス付きベクターの間のセマンティック類似性を計算し、それに応じて結果をランク付けします。 このクイック スタートで作成されたインデックスの場合、結果はクエリと密接に一致する content_text フィールドのコンテンツを表示します。
マルチモーダル インデックスに対してクエリを実行するには:
Azure portal にサインインし、Azure AI Search サービスを選択します。
左側のウィンドウで、[検索の管理] >[インデックス] を選択します。
インデックスを選択します。
[ クエリ オプション] を選択し、[ 検索結果のベクター値を非表示にする] を選択します。 この手順により、結果が読みやすくなります。
![検索エクスプローラーの [クエリ オプション] メニューのスクリーンショット。](media/search-get-started-portal-images/query-options.png)
検索するテキストを入力します。
energyを使用する例。クエリを実行するには、[検索] を選択 します。
![検索エクスプローラーの [検索] ボタンのスクリーンショット。](media/search-get-started-portal-images/search-button.png)
JSON の結果には、インデックス内の
energyに関連するテキストと画像のコンテンツが含まれている必要があります。 セマンティック ランカーを有効にした場合、@search.answers配列は、関連性のある一致をすばやく識別するのに役立つ簡潔で信頼性の高い セマンティック回答 を提供します。"@search.answers": [ { "key": "a71518188062_aHR0cHM6Ly9oYWlsZXlzdG9yYWdlLmJsb2IuY29yZS53aW5kb3dzLm5ldC9tdWx0aW1vZGFsLXNlYXJjaC9BY2NlbGVyYXRpbmctU3VzdGFpbmFiaWxpdHktd2l0aC1BSS0yMDI1LnBkZg2_normalized_images_7", "text": "A vertical infographic consisting of three sections describing the roles of AI in sustainability: 1. **Measure, predict, and optimize complex systems**: AI facilitates analysis, modeling, and optimization in areas like energy distribution, resource allocation, and environmental monitoring. **Accelerate the development of sustainability solution...", "highlights": "A vertical infographic consisting of three sections describing the roles of AI in sustainability: 1. **Measure, predict, and optimize complex systems**: AI facilitates analysis, modeling, and optimization in areas like<em> energy distribution, </em>resource<em> allocation, </em>and environmental monitoring. **Accelerate the development of sustainability solution...", "score": 0.9950000047683716 }, { "key": "1cb0754930b6_aHR0cHM6Ly9oYWlsZXlzdG9yYWdlLmJsb2IuY29yZS53aW5kb3dzLm5ldC9tdWx0aW1vZGFsLXNlYXJjaC9BY2NlbGVyYXRpbmctU3VzdGFpbmFiaWxpdHktd2l0aC1BSS0yMDI1LnBkZg2_text_sections_5", "text": "...cross-laminated timber.8 Through an agreement with Brookfield, we aim 10.5 gigawatts (GW) of renewable energy to the grid.910.5 GWof new renewable energy capacity to be developed across the United States and Europe.Play 4 Advance AI policy principles and governance for sustainabilityWe advocated for policies that accelerate grid decarbonization", "highlights": "...cross-laminated timber.8 Through an agreement with Brookfield, we aim <em> 10.5 gigawatts (GW) of renewable energy </em>to the<em> grid.910.5 </em>GWof new<em> renewable energy </em>capacity to be developed across the United States and Europe.Play 4 Advance AI policy principles and governance for sustainabilityWe advocated for policies that accelerate grid decarbonization", "score": 0.9890000224113464 }, { "key": "1cb0754930b6_aHR0cHM6Ly9oYWlsZXlzdG9yYWdlLmJsb2IuY29yZS53aW5kb3dzLm5ldC9tdWx0aW1vZGFsLXNlYXJjaC9BY2NlbGVyYXRpbmctU3VzdGFpbmFiaWxpdHktd2l0aC1BSS0yMDI1LnBkZg2_text_sections_50", "text": "ForewordAct... Similarly, we have restored degraded stream ecosystems near our datacenters from Racine, Wisconsin120 to Jakarta, Indonesia.117INNOVATION SPOTLIGHTAI-powered Community Solar MicrogridsDeveloping energy transition programsWe are co-innovating with communities to develop energy transition programs that align their goals with broader s.", "highlights": "ForewordAct... Similarly, we have restored degraded stream ecosystems near our datacenters from Racine, Wisconsin120 to Jakarta, Indonesia.117INNOVATION SPOTLIGHTAI-powered Community<em> Solar MicrogridsDeveloping energy transition programsWe </em>are co-innovating with communities to develop<em> energy transition programs </em>that align their goals with broader s.", "score": 0.9869999885559082 } ]
![検索エクスプローラーの [クエリ オプション] メニューのスクリーンショット。](media/search-get-started-portal-images/query-options.png#lightbox)
![検索エクスプローラーの [検索] ボタンのスクリーンショット。](media/search-get-started-portal-images/search-button.png#lightbox)
リソースをクリーンアップする
このクイック スタートでは、課金対象の Azure リソースを使用します。 リソースが不要になった場合は、料金が発生しないようにサブスクリプションからリソースを削除してください。
次のステップ
このクイック スタートでは、 データのインポートとベクター化 ウィザードについて説明しました。これにより、マルチモーダル検索に必要なすべてのオブジェクトが作成されます。 各手順を詳しく調べるには、次のチュートリアルを参照してください。