このクイック スタートでは、Azure portal の データのインポートとベクター化 ウィザードを使用して 、統合ベクター化の使用を開始します。 ウィザードはコンテンツをチャンクし、埋め込みモデルを呼び出して、インデックス作成とクエリ時にチャンクをベクター化します。
このクイック スタートでは、 azure-search-sample-data リポジトリのテキストベースの PDF を使用します。 ただし、画像を使用しても、このクイック スタートは完了です。
前提条件
アクティブなサブスクリプションを持つ Azure アカウント。 アカウントを無料で作成します。
Azure AI Search サービス。 Basic レベル以上をお勧めします。
ウィザードに関する知識。 Azure portal のデータのインポート ウィザードを参照してください。
サポートされるデータ ソース
データのインポートとベクター化ウィザードでは、さまざまな Azure データ ソースがサポートされています。 ただし、このクイック スタートでは、次の表で説明するファイル全体で動作するデータ ソースについてのみ説明します。
| サポートされているデータ ソース | 説明 |
|---|---|
| Azure Blob Storage | このデータ ソースは、BLOB とテーブルで動作します。 標準パフォーマンス (汎用 v2) アカウントを使用する必要があります。 アクセス層は、ホット、クール、またはコールドにすることができます。 |
| Azure Data Lake Storage (ADLS) Gen2 | これは、階層型名前空間が有効になっている Azure Storage アカウントです。 Data Lake Storage があることを確認するには、[概要] ページの [プロパティ] タブを確認します。
|
| OneLake | このデータ ソースは現在プレビュー段階です。 制限事項とサポートされているショートカットについては、「 OneLake のインデックス作成」を参照してください。 |
サポートされている埋め込みモデル
統合ベクター化の場合は、Azure AI プラットフォームで次のいずれかの埋め込みモデルを使用する必要があります。 デプロイの手順については、 後のセクションで説明します。
| プロバイダー | サポートされているモデル |
|---|---|
| Azure AI Foundry モデルの Azure OpenAI1、2 | text-embedding-ada-002 text-embedding-3-small テキスト埋め込み3ラージ |
| Azure AI サービスのマルチサービス リソース3 | テキストと画像の場合: Azure AI Vision マルチモーダル4 |
| Azure AI Foundry モデル カタログ | テキストの場合: Cohere-embed-v3-英語 Cohere-embed-v3-多言語 画像の場合: Facebook-DinoV2-イメージ-埋め込み-ViT-Base Facebook-DinoV2-イメージ埋め込み-ViT-Giant |
1 Azure OpenAI リソースのエンドポイントには、が必要です。 Azure portal でリソースを作成した場合、このサブドメインはリソースのセットアップ中に自動的に生成されました。
Azure AI Foundry ポータルで作成された 2 つの Azure OpenAI リソース (埋め込みモデルにアクセス可能) はサポートされていません。 Azure Portal で作成された Azure OpenAI リソースのみが 、Azure OpenAI Embedding スキルと互換性があります。
3 課金目的で、 Azure AI マルチサービス リソースを Azure AI Search サービスのスキルセットにアタッチする必要があります。 キーレス接続 (プレビュー) を使用してスキルセットを作成しない限り、両方のリソースが同じリージョンに存在する必要があります。
4 Azure AI Vision マルチモーダル 埋め込みモデルは、 一部のリージョンで利用できます。
パブリック エンドポイントの要件
このクイックスタートでは、Azure portal ノードがアクセスできるように、上記のすべてのリソースでパブリック アクセスが有効になっている必要があります。 そうでないと、ウィザードは失敗します。 ウィザードの実行後、セキュリティのために統合コンポーネントでファイアウォールとプライベート エンドポイントを有効にすることができます。 詳細については、 インポート ウィザードでの接続のセキュリティ保護に関するページを参照してください。
プライベート エンドポイントが既に存在しており、それらを無効にすることができない場合、代替手段は仮想マシン上でスクリプトまたはプログラムからそれぞれのエンドツーエンド フローを実行することです。 仮想マシンはプライベート エンドポイントと同じ仮想ネットワーク上にある必要があります。 統合ベクター化の Python コード サンプル を次に示します。 同じ GitHub リポジトリ には、他のプログラミング言語のサンプルがあります。
ロールベースのアクセス
ロールの割り当てと共に Microsoft Entra ID を使用するか、フル アクセス接続文字列でキーベースの認証を使用できます。 他のリソースへの Azure AI Search 接続の場合は、ロールの割り当てを推奨します。 このクイックスタートでは、ロールを前提としています。
無料の検索サービスでは、Azure AI Search へのロールベースの接続がサポートされます。 ただし、Azure Storage または Azure AI Vision への送信接続ではマネージド ID はサポートされていません。 このサポート不足には、無料の検索サービスと他の Azure リソース間の接続に対するキーベースの認証が必要です。 より安全な接続を実現するには、Basic レベル以上を使用し、ロールを有効にしてマネージド ID を構成します。
推奨されるロールベースのアクセスを構成するには:
検索サービスで、 ロールを有効に して、 システム割り当てマネージド ID を構成します。
-
Search Service サービス貢献者
検索インデックス データ共同作成者
検索インデックス データ閲覧者
データ ソース プラットフォームと埋め込みモデル プロバイダーで、検索サービスがデータとモデルにアクセスできるようにするロールの割り当てを作成します。 サンプル データの準備と埋め込みモデルの準備を参照してください。
メモ
オプションが利用できないためにウィザードを進めることができない場合は (たとえば、データ ソースや埋め込みモデルを選択できない場合など)、ロールの割り当てを見直します。 エラー メッセージは、モデルまたはデプロイが存在しないことを示します。実際の原因は、検索サービスにアクセスするアクセス許可がないという場合です。
スペースの確認
無料サービスで始める場合は、3 つのインデックス、データ ソース、スキルセット、インデクサーに制限されます。 ベーシックプランでは 15 個に制限されます。 このクイック スタートでは、各オブジェクトの 1 つを作成するため、開始する前に追加項目の空きがあることを確認してください。
サンプル データの準備
このセクションでは、このクイックスタートで使用するコンテンツについて説明します。 先に進む前に、 ロールベースのアクセスの前提条件を満たしていることを確認してください。
Azure portal にサインインし、Azure Storage アカウントを選択します。
左側のウィンドウで、[ データ ストレージ>Containers] を選択します。
コンテナーを作成し、このクイックスタートガイドで使用する 健康保険 PDF ドキュメント をアップロードします。
ロールを割り当てるには、次の手順を実行します。
左側のウィンドウで、[ アクセス制御 (IAM)] を選択します。
[追加>][ロール割り当ての追加] の順に選択します。
[ジョブ関数のロール] で、[ストレージ BLOB データ閲覧者] を選択し、[次へ] を選択します。
[ メンバー] で [ マネージド ID] を選択し、[ メンバーの選択] を選択します。
サブスクリプションと検索サービスのマネージド ID を選択します。
(省略可能)コンテナー内の削除を検索インデックスの削除と同期します。 削除検出用にインデクサーを構成するには:
ストレージ アカウントで論理的な削除を有効にします。 ネイティブの論理的な削除を使用している場合、次の手順は必要ありません。
インデクサーがスキャンできるカスタム メタデータを追加して、削除対象としてマークされている BLOB を決定します。 カスタム プロパティにわかりやすい名前を付けます。 たとえば、プロパティに "IsDeleted" という名前を付け、false に設定できます。 コンテナー内のすべての BLOB に対してこの手順を繰り返します。 BLOB を削除する場合は、プロパティを true に変更します。 詳細については、「 Azure Storage からインデックスを作成するときの変更と削除の検出」を参照してください。
埋め込みモデルを準備する
ウィザードでは、Azure OpenAI、Azure AI Vision、または Azure AI Foundry ポータルのモデル カタログからデプロイされた埋め込みモデルを使用できます。 先に進む前に、 ロールベースのアクセスの前提条件を満たしていることを確認してください。
ウィザードは、text-embedding-ada-002、text-embedding-3-large、text-embedding-3-small をサポートします。 内部的には、ウィザードは AzureOpenAIEmbedding スキルを 呼び出して Azure OpenAI に接続します。
Azure portal にサインインし、Azure OpenAI リソースを選択します。
ロールを割り当てるには、次の手順を実行します。
左側のウィンドウで、[ アクセス制御 (IAM)] を選択します。
[追加>][ロール割り当ての追加] の順に選択します。
[職務権限ロール] で、[Cognitive Services OpenAI ユーザー] を選択した後、[次へ] を選択します。
[ メンバー] で [ マネージド ID] を選択し、[ メンバーの選択] を選択します。
サブスクリプションと検索サービスのマネージド ID を選択します。
埋め込みモデルをデプロイするには:
Azure AI Foundry ポータルにサインインし、Azure OpenAI リソースを選択します。
左側のウィンドウで、[ モデル カタログ] を選択します。
ウィザードを起動する
ベクトル検索のウィザードを開始するには:
Azure portal にサインインし、Azure AI Search サービスを選択します。
[ 概要 ] ページで、[ データのインポートとベクター化] を選択します。

データ ソース ( Azure Blob Storage、 ADLS Gen2、または OneLake) を選択します。
RAG を選択します。


データへの接続
次の手順では、検索インデックスに使用するデータ ソースに接続します。
[ データへの接続 ] ページで、Azure サブスクリプションを指定します。
サンプル データを提供するストレージ アカウントとコンテナーを選択します。
[ サンプル データの準備] で論理的な削除を有効にし、必要に応じてカスタム メタデータを追加した場合は、[ 削除の追跡を有効にする ] チェック ボックスをオンにします。
その後のインデックス作成の実行では、検索インデックスが更新され、Azure Storage で論理的に削除された BLOB に基づく検索ドキュメントが削除されます。
BLOB では、ネイティブ BLOB の論理的な削除またはカスタム メタデータを使用した論理的な削除がサポートされています。
論理的な削除用に BLOB を構成した場合は、メタデータ プロパティの名前と値のペアを指定します。 IsDeleted をお勧めします。 BLOB で IsDeleted が true に設定されている場合、インデクサーは次のインデクサーの実行時に対応する検索ドキュメントを削除します。
ウィザードでは、Azure Storage での設定が有効かどうかはチェックされず、要件が満たされていない場合でもエラーはスローされません。 代わりに、削除の検出は機能せず、時間と共に孤立したドキュメントが検索インデックスによって収集される可能性があります。
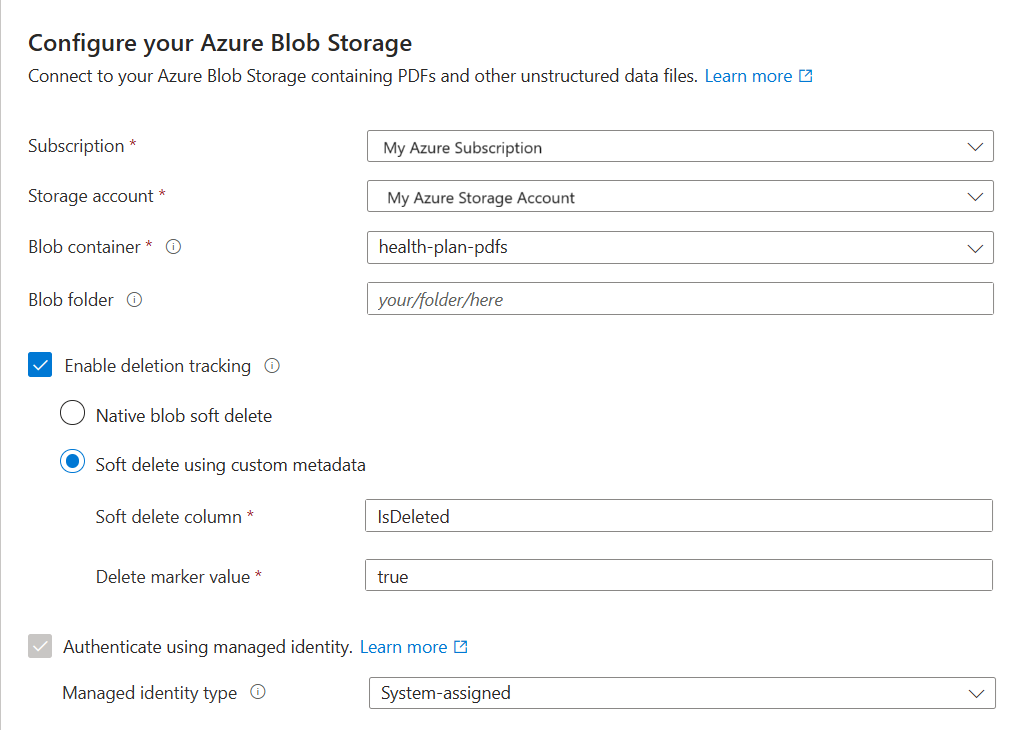
[ マネージド ID を使用して認証 する] チェック ボックスをオンにします。
マネージド ID の種類として、[ システム割り当て] を選択します。
この ID には、Azure Storage のストレージ BLOB データ閲覧者ロールが必要です。
この手順は省略しないでください。 ウィザードを Azure Storage に接続できない場合、インデックス作成中に接続エラーが発生します。
[ 次へ] を選択します。
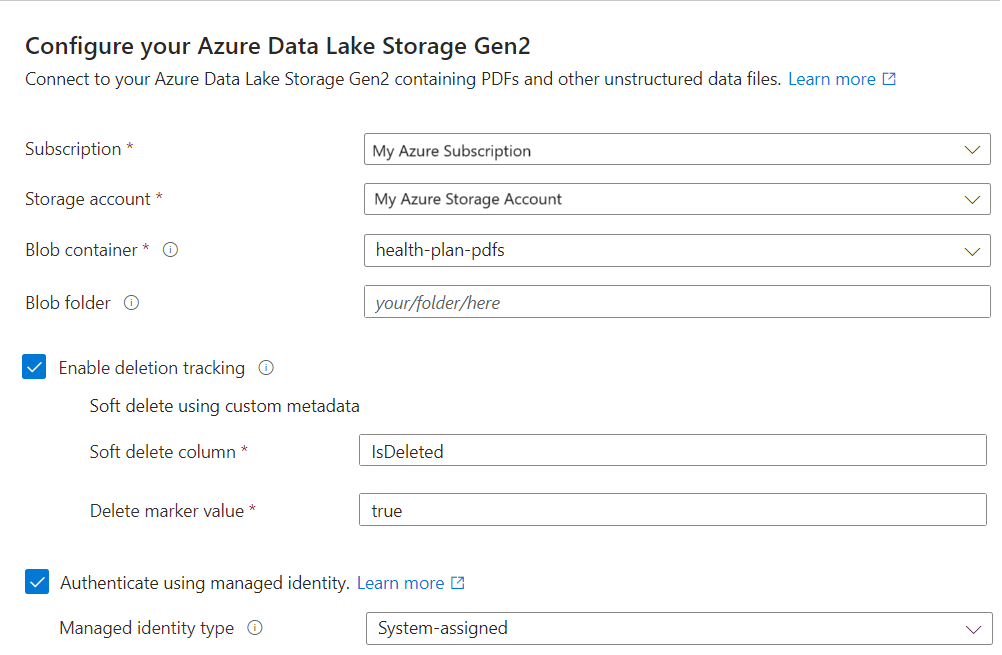
テキストをベクター化する
この手順では、チャンク されたデータをベクター化する埋め込みモデルを指定します。 チャンクは組み込まれており、設定を変更できません。 有効な設定は次のとおりです。
"textSplitMode": "pages",
"maximumPageLength": 2000,
"pageOverlapLength": 500,
"maximumPagesToTake": 0, #unlimited
"unit": "characters"
[テキストのベクター化] ページで、埋め込みモデルのソースを選択します。
Azure OpenAI
Azure AI Foundry のモデル カタログ
Azure AI Vision (Azure AI Search と同じリージョンの Azure AI サービス マルチサービス リソース 経由)
Azure サブスクリプションを指定します。
リソースに応じて、次の選択を行います。
認証の種類として、[ システム割り当て ID] を選択します。
- ID には、Azure AI サービスのマルチサービス リソースに対する Cognitive Services ユーザー ロールが必要です。
これらのリソースの使用による課金への影響を認めるチェックボックスを選択します。
![ウィザードの [テキストのベクター化] ページのスクリーンショット。](media/search-get-started-portal-import-vectors/vectorize-text.png)
[ 次へ] を選択します。
画像をベクトル化し、強化する
健康計画のPDFには企業のロゴが含まれていますが、それ以外には画像はありません。 サンプル ドキュメントを使用している場合は、このステップをスキップできます。
ただし、有用な画像を含むコンテンツを扱う場合は、次の 2 つの方法で AI を適用できます。
カタログまたは Azure AI Vision マルチモーダル 埋め込み API でサポートされている画像埋め込みモデルを使用して、画像をベクター化します。
光学式文字認識 (OCR) を使用して、画像内のテキストを認識する。 このオプションは、 OCR スキル を呼び出して画像からテキストを読み取ります。
Azure AI Search と Azure AI リソースは、同じリージョンにあるか、 キーレス課金接続用に構成されている必要があります。
[ イメージのベクター化 ] ページで、ウィザードで行う接続の種類を指定します。 画像のベクター化の場合、ウィザードは Azure AI Foundry ポータルまたは Azure AI Vision で埋め込みモデルに接続できます。
サブスクリプションを指定します。
Azure AI Foundry モデル カタログの場合は、プロジェクトとデプロイを指定します。 詳細については、「 埋め込みモデルの準備」を参照してください。
(省略可能)スキャンされたドキュメント ファイルなどのバイナリ 画像を解読し、 OCR を使用してテキストを認識します。
これらのリソースの使用による課金への影響を認めるチェックボックスを選択します。
![ウィザードの [イメージのベクター化] ページのスクリーンショット。](media/search-get-started-portal-import-vectors/vectorize-images.png)
[ 次へ] を選択します。
セマンティック 優先度付けを追加する
[ 詳細設定] ページでは、必要に応じて セマンティック ランク付けを 追加して、クエリの実行終了時に結果を再ランク付けできます。 再ランク付けによって、最も意味的な関連性が高いマッチが上位にきます。
新しいフィールドをマップする
この手順の重要なポイントは次のとおりです。
インデックス スキーマは、チャンク されたデータのベクター フィールドと非ベクトル フィールドを提供します。
フィールドを追加することはできますが、生成されたフィールドを削除または変更することはできません。
ドキュメント解析モードでは、チャンク (チャンクごとに 1 つの検索ドキュメント) が作成されます。
[ 詳細設定] ページでは、データ ソースが最初のパスで取得されないメタデータまたはフィールドを提供すると仮定して、必要に応じて新しいフィールドを追加できます。 既定では、ウィザードは次の表で説明するフィールドを生成します。
| フィールド | 適用対象 | 説明 |
|---|---|---|
| chunk_id | テキストと画像ベクトル | 生成された文字列フィールド。 検索可能、取得可能、並べ替え可能。 これはインデックスのドキュメント キーです。 |
| parent_id | テキスト ベクトル | 生成された文字列フィールド。 取得可能でフィルター可能。 チャンクの作成元である親ドキュメントを識別します。 |
| チャンク | テキストと画像ベクトル | 文字列フィールド。 データチャンクの人間が判読可能なバージョン。 検索可能で取得可能ですが、フィルター可能、ファセット可能、または並べ替え可能ではありません。 |
| タイトル | テキストと画像ベクトル | 文字列フィールド。 人間が読みやすいドキュメントのタイトル、ページタイトル、またはページ番号。 検索可能で取得可能ですが、フィルター可能、ファセット可能、または並べ替え可能ではありません。 |
| テキストベクトル | テキスト ベクトル | Collection(Edm.single)。 チャンクのベクトル表現。 検索可能で取得可能ですが、フィルター可能、ファセット可能、または並べ替え可能ではありません。 |
生成されたフィールドやその属性は変更できませんが、データ ソースにある場合は、新しいフィールドを追加できます。 たとえば、Azure Blob Storage にはメタデータ フィールドのコレクションが用意されています。
フィールドの追加を選択します。
使用可能なフィールドからソース フィールドを選択し、インデックスのフィールド名を入力して、既定のデータ型をそのまま使用 (またはオーバーライド) します。
メモ
メタデータ フィールドは検索可能ですが、取得可能、フィルター可能、ファセット可能、または並べ替え可能ではありません。
スキーマを元のバージョンに復元する場合は、[リセット] を選択 します。
インデックス作成をスケジュールする
[ 詳細設定] ページでは、インデクサーの オプションの実行スケジュール を指定することもできます。 ドロップダウン リストから間隔を選択したら、[ 次へ] を選択します。
ウィザードを終了する
[ 構成の確認 ] ページで、ウィザードで作成するオブジェクトのプレフィックスを指定します。 共通のプレフィックスは、整理された状態を保つのに役立ちます。
作成を選択します。
ウィザードによる構成が完了すると、以下のオブジェクトが作成されます。
データソースへの接続。
ベクトル フィールド、ベクター ライザー、ベクター プロファイル、およびベクター アルゴリズムを含むインデックス。 ウィザードのワークフロー中に既定のインデックスを設計したり、変更したりすることはできません。 インデックスは 、2024-05-01-preview REST API に準拠しています。
テキスト分割スキルを使ってチャンクするスキルと、ベクター化のための埋め込みスキルを持つ。 埋め込みスキルは、 Azure OpenAI 用の AzureOpenAIEmbeddingModel スキル か、Azure AI Foundry モデル カタログの AML スキル のいずれかです。 スキルセットには、インデックス プロジェクション構成もあり、データ ソース内の 1 つのドキュメントのデータを"子"インデックス内の対応するチャンクにマップします。
フィールド マッピングと出力フィールド マッピングを持つインデクサー (該当する場合)。
ヒント
ウィザードで作成されたオブジェクトには、構成可能な JSON 定義があります。 これらの定義を表示または変更するには、左側のウィンドウから [検索管理 ] を選択します。ここでは、インデックス、インデクサー、データ ソース、スキルセットを表示できます。
結果をチェックする
検索エクスプローラーは、テキスト文字列を入力として受け取った後、ベクトル クエリの実行のためにテキストをベクトル化します。
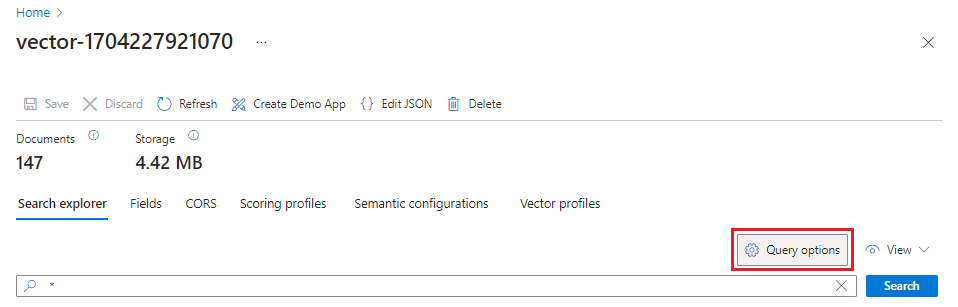
Azure portal で、 Search Management>Indexes に移動し、インデックスを選択します。
[ クエリ オプション] を選択し、[ 検索結果のベクター値を非表示にする] を選択します。 この手順により、結果が読みやすくなります。
[表示] メニューから JSON ビューを選択し、ベクター クエリのテキストを
textベクター クエリ パラメーターに入力できるようにします。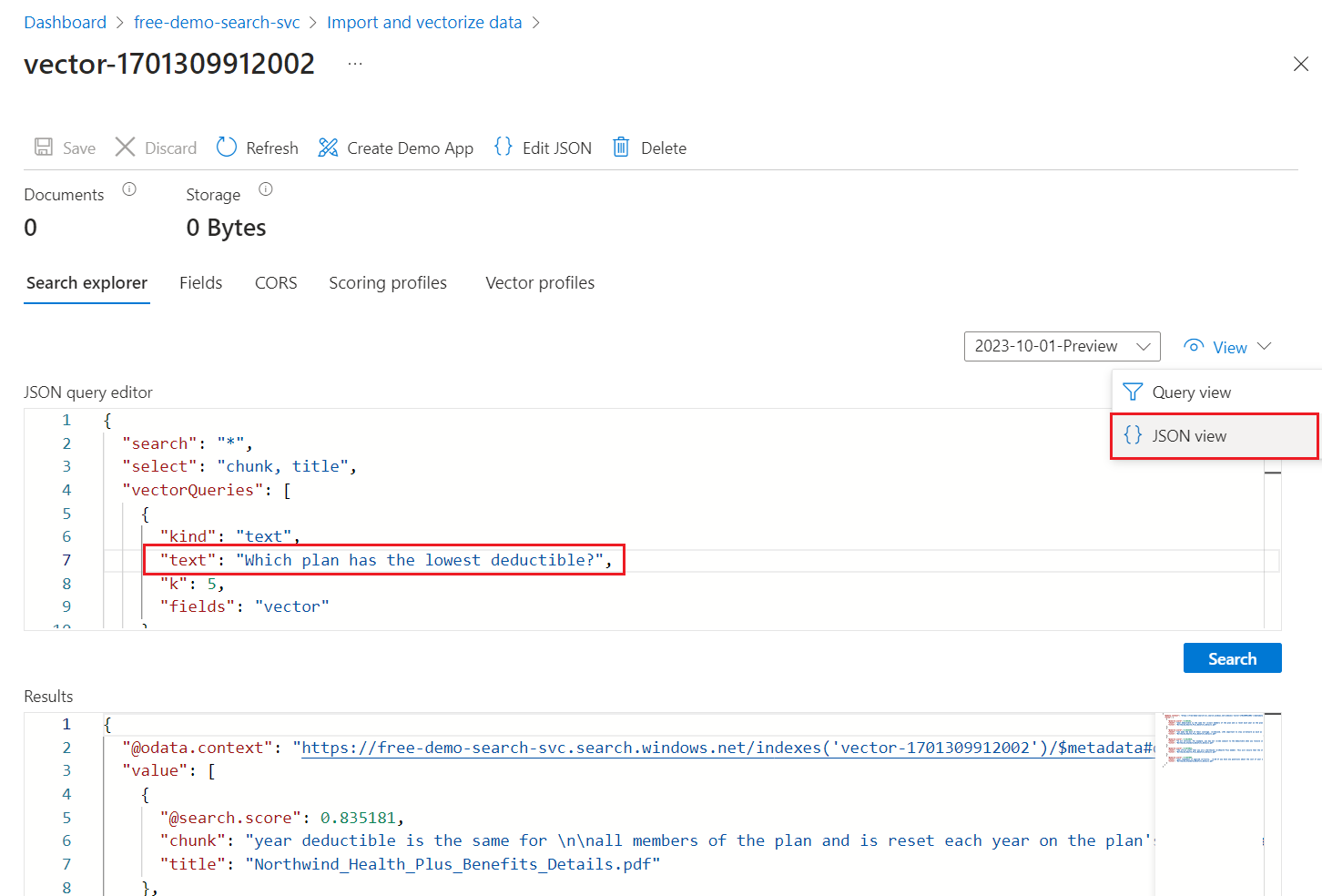
既定のクエリは空の検索 (
"*") ですが、一致する数を返すパラメーターが含まれています。 これは、テキスト クエリとベクトル クエリを並列で実行するハイブリッド クエリです。 また、セマンティック ランク付けも含まれ、selectステートメントを使用して結果に返すフィールドを指定します。{ "search": "*", "count": true, "vectorQueries": [ { "kind": "text", "text": "*", "fields": "text_vector,image_vector" } ], "queryType": "semantic", "semanticConfiguration": "my-demo-semantic-configuration", "captions": "extractive", "answers": "extractive|count-3", "queryLanguage": "en-us", "select": "chunk_id,text_parent_id,chunk,title,image_parent_id" }両方のアスタリスク (
*) プレースホルダーを、Which plan has the lowest deductible?などの健康保険プランに関連する質問に置き換えます。{ "search": "Which plan has the lowest deductible?", "count": true, "vectorQueries": [ { "kind": "text", "text": "Which plan has the lowest deductible?", "fields": "text_vector,image_vector" } ], "queryType": "semantic", "semanticConfiguration": "my-demo-semantic-configuration", "captions": "extractive", "answers": "extractive|count-3", "queryLanguage": "en-us", "select": "chunk_id,text_parent_id,chunk,title" }クエリを実行するには、[検索] を選択 します。
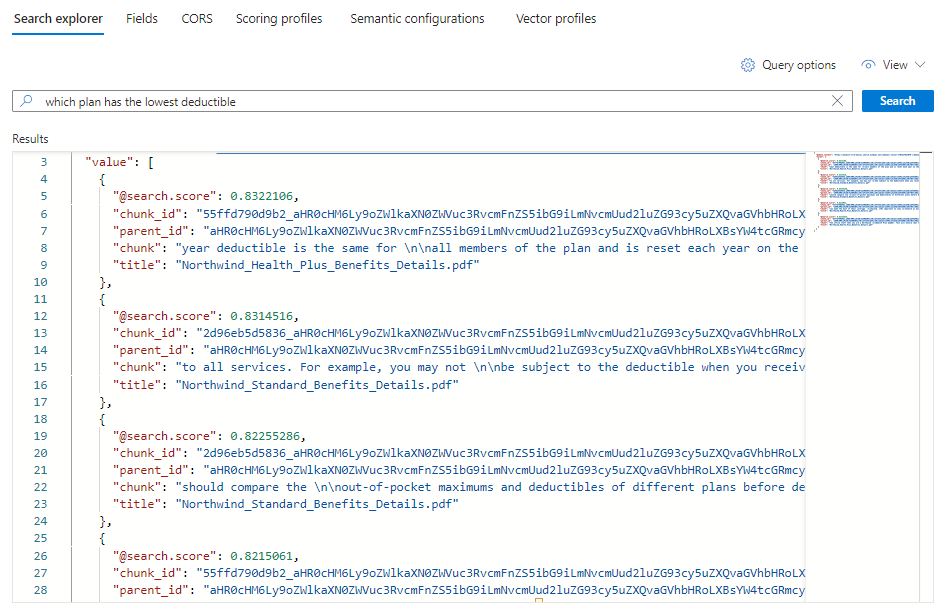
各ドキュメントは、元の PDF のチャンクです。
titleフィールドは、チャンクがどの PDF からのものであるかを示します。 各chunkは長いです。 1 つをコピーしてテキスト エディターに貼り付けると、値全体を読み取ることができます。特定のドキュメントからのチャンクをすべて表示するには、以下のように特定の PDF 用の
title_parent_idフィールドのフィルターを追加します。 インデックスの [ フィールド] タブをチェックして、フィールドがフィルター可能であることを確認できます。{ "select": "chunk_id,text_parent_id,chunk,title", "filter": "text_parent_id eq 'aHR0cHM6Ly9oZWlkaXN0c3RvcmFnZWRlbW9lYXN0dXMuYmxvYi5jb3JlLndpbmRvd3MubmV0L2hlYWx0aC1wbGFuLXBkZnMvTm9ydGh3aW5kX1N0YW5kYXJkX0JlbmVmaXRzX0RldGFpbHMucGRm0'", "count": true, "vectorQueries": [ { "kind": "text", "text": "*", "k": 5, "fields": "text_vector" } ] }
クリーンアップ
Azure AI Search は課金対象のリソースです。 今後これが必要ない場合は、課金を防ぐためにサブスクリプションからこれを削除してください。
次のステップ
このクイック スタートでは、統合ベクター化に必要なすべてのオブジェクトを作成する データのインポートとベクター化ウィザードについて説明しました。 各手順の詳細については、「 Azure AI Search で統合ベクター化を設定する」を参照してください。