OneLake のファイルとショートカットからのデータにインデックスを付ける
この記事では、OneLake 最上部のレイクハウスから検索可能なデータとメタデータ データを抽出するように、OneLake ファイル インデクサーを構成する方法について説明します。
このインデクサーは、次のタスクに使用します。
- データのインデックス付けと増分インデックス付け: インデクサーは、レイクハウス内のデータ パスからファイルと関連するメタデータにインデックスを付けます。 組み込みの変更検出を使用して、新しいファイルと更新されたファイルとメタデータを検出します。 スケジュールまたはオンデマンドでデータ更新を構成できます。
- 削除の検出: インデクサーは、ほとんどのファイルとショートカットのカスタム メタデータを使用して削除を検出できます。 これには、"論理的な削除" を示すメタデータをファイルに追加して、検索インデックスからの削除を有効にする必要があります。 現時点では、Google Cloud Storage または Amazon S3 ショートカット ファイルの削除は検出できません。これらのデータ ソースでカスタム メタデータがサポートされていないためです。
- スキルセット経由で適用された AI: スキルセットは、OneLake ファイル インデクサーによって完全にサポートされています。 これには、データ チャンクと埋め込み手順を追加する統合ベクター化などの主要な機能が含まれます。
- 解析モード: インデクサーは、JSON 配列または行を個々の検索ドキュメントに解析する場合に JSON 解析モードをサポートします。
- 他の機能との互換性: OneLake インデクサーは、デバッグ セッション、増分エンリッチメントのためのインデクサー キャッシュ、ナレッジ ストアなど、他のインデクサー機能とシームレスに連携するように設計されています。
Azure portal で OneLake からインデックス付けするには、2024-05-01-preview REST API、ベータ版の Azure SDK パッケージ、またはデータのインポートとベクター化を使用します。
この記事では、REST API を使用して各手順を説明します。
前提条件
Fabric ワークスペース。 このチュートリアルに従って、Fabric ワークスペースを作成します。
Fabric ワークスペース内のレイクハウス。 このチュートリアルに従って、レイクハウスを作成します。
テキスト データ。 バイナリ データがある場合は、AI エンリッチメント画像分析を使用してテキストの抽出や画像説明の生成を行えます。 検索サービス レベルのインデクサー制限を超えるファイル コンテンツは使用できません。
レイクハウスのファイルの場所のコンテンツ。 次の方法でデータを追加できます。
- レイクハウスに直接アップロードする
- Microsoft Fabric からデータ パイプラインを使用する
- Amazon S3 や Google Cloud Storage などの外部データ ソースからショートカットを追加します。
システム マネージド ID またはユーザー割り当てマネージド ID のいずれかに対して構成された AI 検索サービス。 AI 検索サービスは、Microsoft Fabric ワークスペースと同じテナント内に存在する必要があります。
レイクハウスがある Microsoft Fabric ワークスペースでの共同作成者ロールの割り当て。 手順の概要については、この記事の「アクセス許可の付与」セクションを参照してください。
この記事に示すような REST 呼び出しを作成する場合は、REST クライアント。
サポートされるドキュメントの形式
OneLake ファイル インデクサーは、次の形式のドキュメントからテキストを抽出できます。
- CSV (CSV BLOB のインデックス作成に関する記事を参照)
- EML
- EPUB
- GZ
- HTML
- JSON (JSON BLOB のインデックス作成に関する記事を参照)
- KML (地理的表現の XML)
- Microsoft Office 形式: DOCX/DOC/DOCM、XLSX/XLS/XLSM、PPTX/PPT/PPTM、MSG (Outlook 電子メール)、XML (2003 と 2006 両方の WORD XML)
- オープン ドキュメント形式: ODT、ODS、ODP
- プレーンテキスト ファイル (「プレーン テキストのインデックス作成」も参照)
- RTF
- XML
- 郵便番号
サポートされているショートカット
OneLake ファイル インデクサーでは、次の OneLake ショートカットがサポートされています。
OneLake ショートカット (別の OneLake インスタンスへのショートカット)
このプレビューの制限事項
Parquet (デルタ Parquet を含む) のファイルの種類は現在サポートされていません。
Amazon S3 と Google Cloud Storage のショートカットでは、ファイルの削除はサポートされていません。
このインデクサーでは、OneLake ワークスペースのテーブルの場所のコンテンツはサポートされていません。
このインデクサーは SQL クエリをサポートしていませんが、データ ソース構成で使用されるクエリは、必要に応じてアクセスするフォルダーまたはショートカットを追加するためだけに使用されます。
OneLake の [個人用ワークスペース] ワークスペースからのファイルの取り込みはサポートされません。これはユーザーごとの個人用リポジトリであるためです。
インデックス付けのためのデータを準備する
インデックス作成を設定する前に、ソース データを確認して、変更を事前に行う必要があるかどうかを判断します。 インデクサーは、一度に 1 つのコンテナーのコンテンツにインデックスを作成できます。 既定では、コンテナー内のすべてのファイルが処理されます。 より選択的な処理を行うためのオプションがいくつかあります。
仮想フォルダーにファイルを配置します。 インデクサー データ ソース定義には、lakehouse サブフォルダーまたはショートカットのいずれかを指定できる "クエリ" パラメーターが含まれています。 この値を指定すると、レイクハウス内のサブフォルダーまたはショートカット内のファイルのみがインデックス付けされます。
ファイルの種類別にファイルを含めるか除外します。 除外するファイルを決定するのに、「サポートされるドキュメントの形式」の一覧が役立ちます。 たとえば、検索可能なテキストを提供しない画像またはオーディオのファイルを除外できます。 この機能は、インデクサーの構成設定によって制御されます。
任意のファイルを含めるか、除外します。 何らかの理由で特定のファイルをスキップする場合は、OneLake レイクハウス内のファイルにメタデータのプロパティと値を追加できます。 インデクサーでこのプロパティが検出されると、インデックス付けの実行時にファイルまたはそのコンテンツがスキップされます。
ファイルを含めるか除外することについては、「インデクサーの構成」手順で説明します。 条件を設定しない場合、インデクサーは不適格なファイルをエラーとして報告し、次に進みます。 十分なエラーが発生した場合は、処理が停止することがあります。 エラーの許容範囲は、インデクサーの構成設定で指定できます。
インデクサーは通常、ファイルごとに 1 つの検索ドキュメントを作成します。ここで、テキスト コンテンツとメタデータは、インデックス内の検索可能フィールドとして取得されます。 ファイルがファイル全部の場合は、それらを複数の検索ドキュメントに解析できます。 たとえば、CSV ファイル内の行を解析して、1 行につき 1 つの検索ドキュメントを作成できます。 データをベクター化するために 1 つのドキュメントを小さな一節に分割する必要がある場合、統合ベクター化の使用を検討してください。
ファイル メタデータのインデックス作成
ファイル メタデータのインデックスを作成することもできます。これは、標準またはカスタムのメタデータ プロパティがフィルターとクエリで役に立つと思われる場合に便利です。
ユーザーが指定したメタデータ プロパティは、そのまま抽出されます。 値を受け取るには、Edm.String 型の検索インデックスに、BLOB のメタデータ キーと同じ名前のフィールドを定義する必要があります。 たとえば、BLOB に値が High のメタデータ キー Priority がある場合、検索インデックスで Priority という名前のフィールドが定義されている必要があり、値 High が設定されます。
次に示すように、標準のファイル メタデータ プロパティは、同じような名前のフィールドおよび型指定されたフィールドに抽出できます。 OneLake ファイル インデクサーでは、これらのメタデータ プロパティの内部フィールド マッピングを自動的に作成し、ハイフンが付きの元の名前 ("metadata-storage-name") を下線付きの同等の名前 ("metadata_storage_name") に変換します。
その場合でも、インデックス定義に下線付きフィールドを追加する必要がありますが、インデクサーによって自動的に関連付けが実行されるため、インデクサー フィールド マッピングを省略できます。
metadata_storage_name (
Edm.String) - ファイル名。 たとえば、/mydatalake/my-folder/subfolder/resume.pdf というファイルがある場合、このフィールドの値はresume.pdfになります。metadata_storage_path (
Edm.String) - ストレージ アカウントを含む、BLOB の完全な URI。 たとえば、https://myaccount.blob.core.windows.net/my-container/my-folder/subfolder/resume.pdfのように指定します。metadata_storage_content_type (
Edm.String) - BLOB をアップロードするためのコードで指定したコンテンツ タイプ。 たとえば、「application/octet-stream」のように入力します。metadata_storage_last_modified (
Edm.DateTimeOffset) - 前回変更時の BLOB のタイムスタンプ。 インデックスの初回作成後に最初から作成し直さなくても済むよう、変更された BLOB を Azure AI Search が特定するために、このタイムスタンプが使用されます。metadata_storage_size (
Edm.Int64) - BLOB のサイズ (バイト単位)。metadata_storage_content_md5 (
Edm.String) - BLOB コンテンツの MD5 ハッシュ (利用可能な場合)。
最後に、インデックス付け対象のファイルのドキュメント形式に固有のメタデータ プロパティも、インデックス スキーマで表すことができます。 コンテンツ固有のメタデータの詳細については、コンテンツのメタデータ プロパティに関するページを参照してください。
重要な指摘点としては、検索インデックスに対し、ここに挙げたすべてのプロパティのフィールドを定義する必要はありません。実際のアプリケーションで必要となるプロパティだけを取り込んでください。
アクセス許可の付与
OneLake インデクサーは、OneLake への接続にトークン認証とロールベースのアクセスを使用します。 アクセス許可は OneLake で割り当てられます。 ショートカットをサポートする物理データ ストアにアクセス許可の要件はありません。 たとえば、AWS からインデックスを作成する場合、AWS で検索サービスのアクセス許可を付与する必要はありません。
検索サービス ID の最小ロール割り当ては、共同作成者です。
AI Search サービスのシステムまたはユーザーマネージド ID を構成します。
次のスクリーンショットは、"onelake-demo" という名前の検索サービスのシステム マネージド ID を示しています。
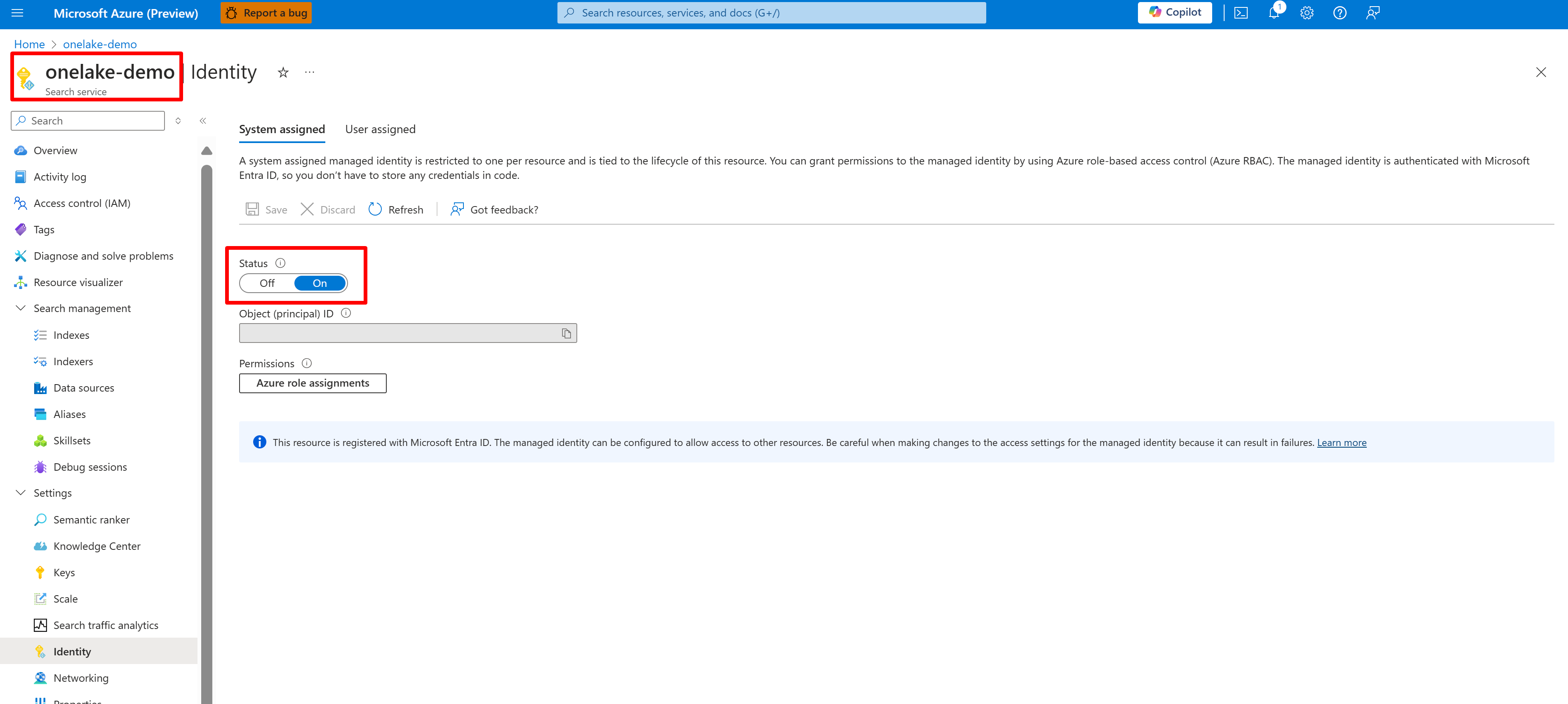
このスクリーンショットは、同じ検索サービスのユーザーマネージド ID を示しています。

Fabric ワークスペースへの検索サービス アクセスのアクセス許可を付与します。 検索サービスが、インデクサーの代わりに接続を行います。
システム割り当てマネージド ID を使用する場合は、AI Search サービスの名前を検索します。 ユーザー割り当てマネージド ID の場合は、ID リソースの名前を検索します。
次のスクリーンショットは、システム マネージド ID を使用した共同作成者ロールの割り当てを示しています。

このスクリーンショットは、システム マネージド ID を使用する共同作成者ロールの割り当てを示しています。
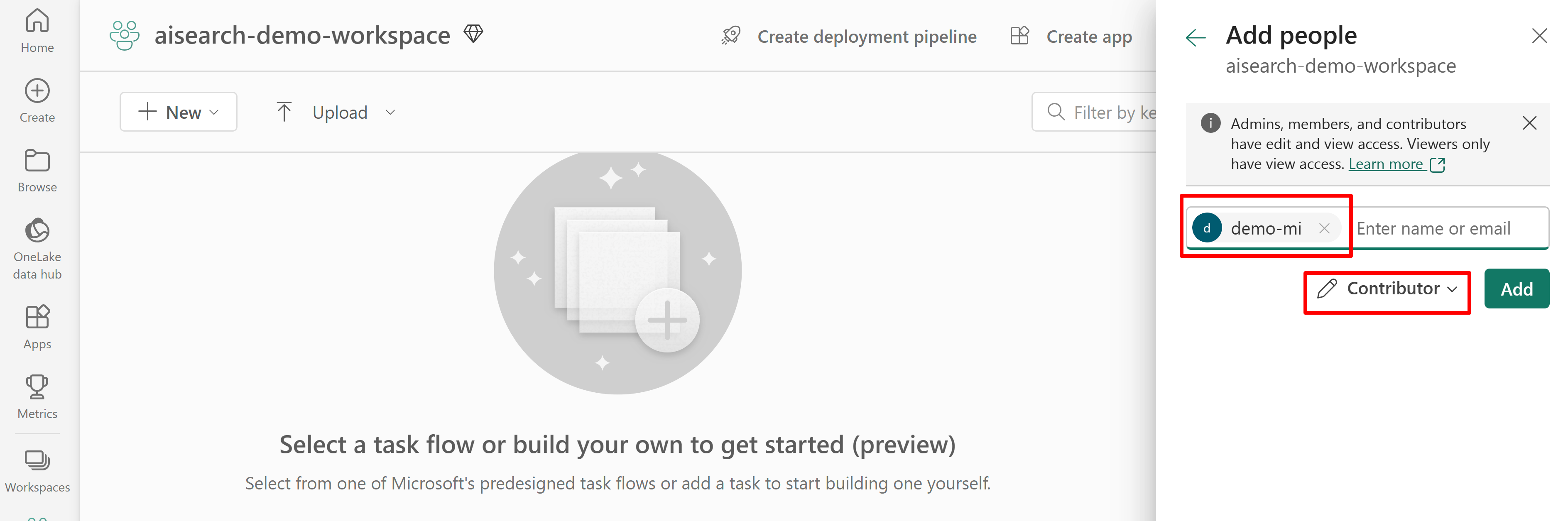




データ ソースを定義する
データ ソースは、複数のインデクサーで使用できるように、独立したリソースとして定義します。 データ ソースを作成するには、2024-05-01-preview REST API を使用する必要があります。
データ ソース REST API の作成または更新を使用して、その定義を設定します。 これらは、定義の最も重要な手順です。
"type"を"onelake"に設定します (必須)。Microsoft Fabric ワークスペース GUID とレイクハウス GUID を取得します。
URL からデータをインポートするレイクハウスに移動します。 この例の https://msit.powerbi.com/groups/00000000-0000-0000-0000-000000000000/lakehouses/11111111-1111-1111-1111-111111111111?experience=power-bi" のようなページが表示されます。 データ ソース定義で使用されている次の値をコピーします。
{FabricWorkspaceGuid}を呼び出すワークスペース GUID をコピーします。この GUID は、URL の "グループ" の直後に表示されます。 この例では 00000000-0000-0000-0000-000000000000 になります。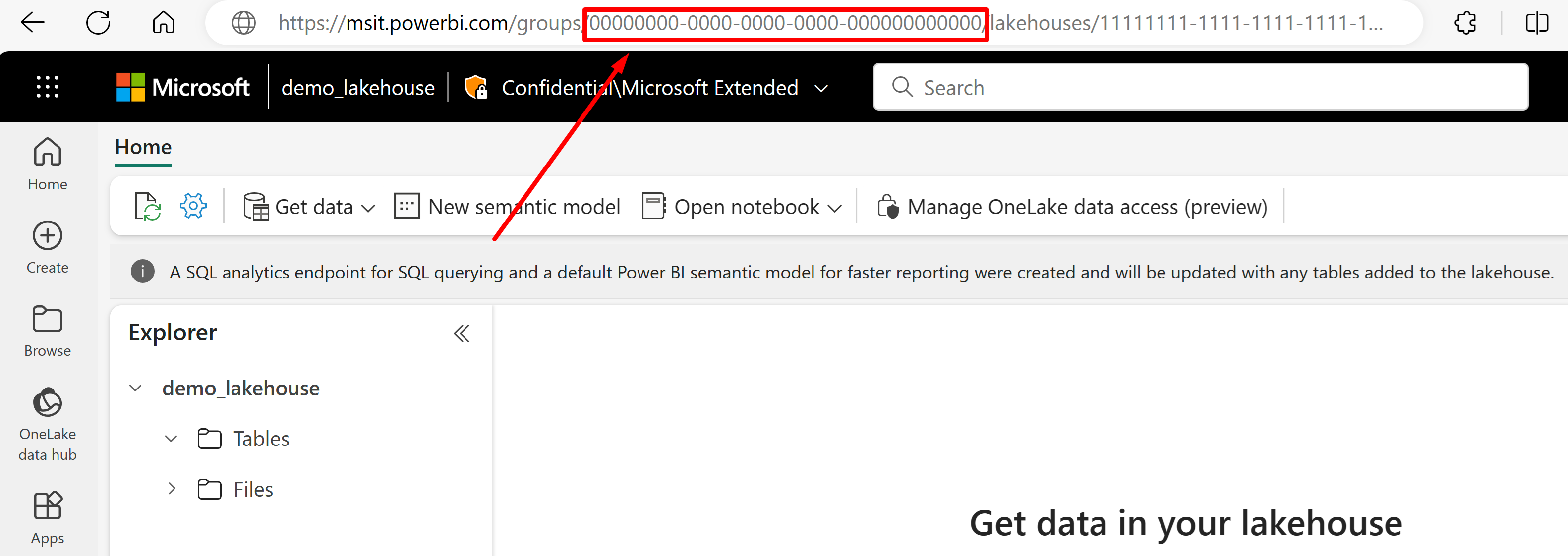
{lakehouseGuid}を呼び出すレイクハウス GUID をコピーします。この GUID は、URL の "lakehouses" の直後に示されています。 この例では 11111111-1111-1111-1111-111111111111 になります。
{FabricWorkspaceGuid}を前の手順でコピーした値に置き換えることで、"credentials"を Microsoft Fabric ワークスペース GUID に設定します。 これは、このガイドの後半で設定する、マネージド ID を使用してアクセスする OneLake です。"credentials": { "connectionString": "ResourceId={FabricWorkspaceGuid}" }"container.name"をレイクハウス GUID に設定し、{lakehouseGuid}を前の手順でコピーした値に置き換えます。 必要に応じて、lakehouse サブフォルダーまたはショートカットを指定するために"query"を使用します。"container": { "name": "{lakehouseGuid}", "query": "{optionalLakehouseFolderOrShortcut}" }ユーザー割り当てマネージド ID を使用して認証方法を設定するか、システム マネージド ID の次の手順に進みます。
{ "name": "{dataSourceName}", "description": "description", "type": "onelake", "credentials": { "connectionString": "ResourceId={FabricWorkspaceGuid}" }, "container": { "name": "{lakehouseGuid}", "query": "{optionalLakehouseFolderOrShortcut}" }, "identity": { "@odata.type": "Microsoft.Azure.Search.DataUserAssignedIdentity", "userAssignedIdentity": "{userAssignedManagedIdentity}" } }userAssignedIdentity値は、プロパティの下の{userAssignedManagedIdentity}リソースにアクセスすることで見つけられ、Idと呼ばれます。
例:
{ "name": "mydatasource", "description": "description", "type": "onelake", "credentials": { "connectionString": "ResourceId=a0a0a0a0-bbbb-cccc-dddd-e1e1e1e1e1e1" }, "container": { "name": "11111111-1111-1111-1111-111111111111", "query": "folder_name" }, "identity": { "@odata.type": "Microsoft.Azure.Search.DataUserAssignedIdentity", "userAssignedIdentity": "/subscriptions/333333-3333-3333-3333-33333333/resourcegroups/myresourcegroup/providers/Microsoft.ManagedIdentity/userAssignedIdentities/demo-mi" } }必要に応じて、代わりにシステム割り当てマネージド ID を使用します。 システム割り当てマネージド ID を使用している場合、"ID" は定義から削除されます。
{ "name": "{dataSourceName}", "description": "description", "type": "onelake", "credentials": { "connectionString": "ResourceId={FabricWorkspaceGuid}" }, "container": { "name": "{lakehouseGuid}", "query": "{optionalLakehouseFolderOrShortcut}" } }例:
{ "name": "mydatasource", "description": "description", "type": "onelake", "credentials": { "connectionString": "ResourceId=a0a0a0a0-bbbb-cccc-dddd-e1e1e1e1e1e1" }, "container": { "name": "11111111-1111-1111-1111-111111111111", "query": "folder_name" } }



カスタム メタデータを使用して削除を検出する
インデクサーが検出したソース ドキュメントが削除用にフラグされており、そのドキュメントが削除されるように設定する場合、OneLake ファイル インデクサー データ ソースの定義に論理的な削除ポリシーを含めることもできます。
ファイルの自動削除を有効にするには、カスタム メタデータを使用して、検索ドキュメントをインデックスから削除するかどうかを指定します。
ワークフローには、次の 3 つの個別のアクションが必要です。
- OneLake でファイルを "論理的に削除" する
- インデクサーがインデックス内の検索ドキュメントを削除する
- OneLake でファイルを "物理的に削除" する
"論理的な削除" は、インデクサーに何をすべきかを指示します (検索ドキュメントの削除)。 OneLake で物理ファイルを最初に削除した場合、インデクサーが読み取るものは何もなく、インデックス内の対応する検索ドキュメントは孤立します。
OneLake と Azure AI Search の両方で実行する手順がありますが、その他の機能の依存関係はありません。
レイクハウス ファイルでは、カスタム メタデータのキーと値のペアをファイルに追加して、ファイルに削除のフラグが付けられていることを示します。 たとえば、プロパティに "IsDeleted" という名前を指定し、それを false に設定できます。 ファイルを削除する場合は、true に変更します。

Azure AI Search では、データソースの定義を編集して "dataDeletionDetectionPolicy" プロパティを含めます。 たとえば、次のポリシーでは、ファイルのメタデータ プロパティ "IsDeleted" の値が true のときに、そのファイルが削除されるものと見なされます。
PUT https://[service name].search.windows.net/datasources/file-datasource?api-version=2024-05-01-preview { "name" : "onelake-datasource", "type" : "onelake", "credentials": { "connectionString": "ResourceId={FabricWorkspaceGuid}" }, "container": { "name": "{lakehouseGuid}", "query": "{optionalLakehouseFolderOrShortcut}" }, "dataDeletionDetectionPolicy" : { "@odata.type" :"#Microsoft.Azure.Search.SoftDeleteColumnDeletionDetectionPolicy", "softDeleteColumnName" : "IsDeleted", "softDeleteMarkerValue" : "true" } }

インデクサーが実行され、検索インデックスからドキュメントが削除されたら、データ レイク内の物理ファイルを削除できます。
重要なポイントには次のようなものがあります。
インデクサーの実行スケジュールを設定すると、このプロセスを自動化できます。 すべての増分インデックス付けシナリオに、スケジュールを設定することをお勧めします。
最初のインデクサーの実行時に削除検出ポリシーが設定されていない場合は、更新された構成を読み取るようにインデクサーをリセットする必要があります。
カスタム メタデータの依存関係のため、Amazon S3 と Google Cloud Storage のショートカットでは削除検出がサポートされていないことを思い出してください。
インデックスに検索フィールドを追加する
検索インデックスに、OneLake データ レイク ファイルのコンテンツとメタデータを受け入れるためのフィールドを追加します。
インデックスを作成または更新して、ファイルのコンテンツとメタデータを格納する検索フィールドを定義します。
{ "name" : "my-search-index", "fields": [ { "name": "ID", "type": "Edm.String", "key": true, "searchable": false }, { "name": "content", "type": "Edm.String", "searchable": true, "filterable": false }, { "name": "metadata_storage_name", "type": "Edm.String", "searchable": false, "filterable": true, "sortable": true }, { "name": "metadata_storage_size", "type": "Edm.Int64", "searchable": false, "filterable": true, "sortable": true }, { "name": "metadata_storage_content_type", "type": "Edm.String", "searchable": false, "filterable": true, "sortable": true } ] }ドキュメント キー フィールド ("key": true) を作成します。 ファイル コンテンツの場合、候補として最適なのはメタデータ プロパティです。
metadata_storage_path(既定値)。オブジェクトまたはファイルへの完全なパス。 キー フィールド (この例では "ID") には、metadata_storage_path の値が設定されます (これが既定値であるため)。metadata_storage_name。名前が一意である場合にのみ使用可能。 このフィールドをキーとして必要とする場合は、"key": trueをこのフィールド定義に移動します。ファイルに追加するカスタム メタデータ プロパティ。 この方法を選んだ場合、ファイルのアップロード プロセスで、該当するメタデータのプロパティをすべての BLOB に追加する必要があります。 キーは必須のプロパティであるため、値が欠落しているファイルについては、インデックスが一切作成されません。 カスタム メタデータ プロパティをキーとして使用する場合は、そのプロパティを変更しないでください。 キー プロパティが変更されると、インデクサーでは同じファイルに対して重複したドキュメントを追加します。
メタデータ プロパティには、ドキュメント キーとして無効な文字 (
/や-など) が含まれていることがよくあります。 インデクサーには "base64EncodeKeys" プロパティ (規定値は true) があるため、構成やフィールド マッピングをしなくても、メタデータ プロパティは自動的にエンコードされます。"content" フィールドを追加して、各ファイルから抽出されたテキストをファイルの "content" プロパティを通して格納します。 この名前を使用する必要はありませんが、そうすることで暗黙的なフィールド マッピングを利用できます。
標準メタデータ プロパティのフィールドを追加します。 インデクサーは、カスタム メタデータ プロパティ、標準メタデータ プロパティ、コンテンツ固有メタデータ プロパティを読み取ることができます。
OneLake ファイル インデクサーを構成して実行する
インデックスとデータ ソースを作成した後、インデクサーを作成できるようになります。 インデクサーの構成では、実行時の動作を制御する入力、パラメーター、プロパティを指定します。 また、インデックスを作成する BLOB の部分を指定することもできます。
名前を指定し、データ ソースとターゲット インデックスを参照することで、インデクサーを作成または更新します。
{ "name" : "my-onelake-indexer", "dataSourceName" : "my-onelake-datasource", "targetIndexName" : "my-search-index", "parameters": { "batchSize": null, "maxFailedItems": null, "maxFailedItemsPerBatch": null, "base64EncodeKeys": null, "configuration": { "indexedFileNameExtensions" : ".pdf,.docx", "excludedFileNameExtensions" : ".png,.jpeg", "dataToExtract": "contentAndMetadata", "parsingMode": "default" } }, "schedule" : { }, "fieldMappings" : [ ] }既定値 (10 個のドキュメント) では使用できるリソースが不足または過剰である場合は、"batchSize" を設定します。 既定のバッチ サイズは、データ ソースによって異なります。 ファイルのインデックス作成では、より大きな平均ドキュメント サイズを認識して、バッチ サイズが 10 のドキュメントに設定されます。
"configuration" の下で、ファイルの種類に基づいてインデックスを作成するファイルを制御するか、指定しないままにしてファイルをすべて取得します。
"indexedFileNameExtensions"には、ファイル拡張子のコンマ区切りリストを指定します (先頭にドットを付けます)。"excludedFileNameExtensions"についても同様に行って、スキップする必要がある拡張子を指定します。 同じファイル拡張子が両方のリストにある場合、それはインデックス作成から除外されます。"configuration" の下で、"dataToExtract" を設定して、インデックスが作成されるファイルの部分を制御します。
"contentAndMetadata" が既定値です。 すべてのメタデータと、ファイルから抽出されたテキスト コンテンツにインデックスを作成するように指定します。
"storageMetadata" には、標準的なファイルのプロパティおよびユーザー指定のメタデータのみにインデックスを作成するように指定します。 Azure BLOB のプロパティは文書化されていますが、ファイルのプロパティは、SAS 関連のメタデータを除き、OneLkae の場合と同じです。
"allMetadata" には、標準のファイル プロパティと、見つかったコンテンツの種類に対するメタデータをファイルのコンテンツから抽出し、インデックスを作成するように指定します。
ファイルが複数の検索ドキュメントにマップされる必要がある場合や、プレーンテキスト、JSON ドキュメント、または CSV ファイルで構成されている場合は、"configuration" の下に "parsingMode" を設定します。
フィールドの名前または種類に違いがある、または検索インデックスで複数のソース フィールドのバージョンが必要な場合、フィールド マッピングを定義します。
ファイルのインデックス作成では、多くの場合、フィールド マッピングを省略できます。インデクサーには、"content" プロパティとメタデータ プロパティを、インデックス内の似たような名前と種類のフィールドにマッピングするためのサポートが組み込まれているためです。 メタデータ プロパティの場合、インデクサーにより検索インデックスでハイフン
-は自動的にアンダースコアに置き換えられます。
その他のプロパティについて詳しくは、「インデクサーの作成」を参照してください。 パラメーターの説明の完全な一覧については、REST API の「インデクサーを作成する (REST)」を参照してください。 パラメーターは OneLake の場合も同じです。
既定では、インデクサーは作成時に自動的に実行されます。 この動作を変更するには、"無効" を true に設定します。 インデクサーの実行を制御するには、インデクサーをオンデマンドで実行するか、スケジュールを設定します。
インデクサーの状態を確認する
インデクサーの状態と実行履歴を監視する複数の方法については、ここを参照してください。
エラーの処理
インデックス作成中に通常発生するエラーには、サポートされていないコンテンツの種類、コンテンツの欠落、ファイルのサイズ超過などがあります。 既定では、OneLake ファイル インデクサーは、サポートされていないコンテンツ タイプのファイルが検出されるとすぐに停止します。 ただし、エラーが発生した場合でも引き続きインデックスを付けて、後から個々のドキュメントをデバッグすることができます。
一時的なエラーは、複数のプラットフォームと製品を含むソリューションでよく発生します。 ただし、インデクサーを一定のスケジュール (5 分ごとなど) で保持すると、インデクサーは次の実行時にこれらのエラーから回復できるはずです。
エラーが発生したときのインデクサーの応答を制御する 5 つのインデクサー プロパティがあります。
{
"parameters" : {
"maxFailedItems" : 10,
"maxFailedItemsPerBatch" : 10,
"configuration" : {
"failOnUnsupportedContentType" : false,
"failOnUnprocessableDocument" : false,
"indexStorageMetadataOnlyForOversizedDocuments": false
}
}
}
| パラメーター | 有効な値 | 説明 |
|---|---|---|
| "maxFailedItems" | -1、null または 0、正の整数 | BLOB の解析中またはインデックスへのドキュメントの追加中、処理のどこかの時点でエラーが発生した場合に、インデックス付けを続行します。 これらのプロパティには、許容できるエラーの数を設定します。 値を -1 に設定すると、どれだけエラーが発生しても処理を継続します。 それ以外の場合、値は正の整数です。 |
| "maxFailedItemsPerBatch" | -1、null または 0、正の整数 | 上記と同じですが、バッチ インデックス作成に使用されます。 |
| "failOnUnsupportedContentType" | true または false | インデクサーがコンテンツの種類を判別できない場合は、ジョブを続行するか失敗するかを指定します。 |
| "failOnUnprocessableDocument" | true または false | サポートされているコンテンツの種類のドキュメントをインデクサーで処理できない場合は、ジョブを続行するか失敗するかを指定します。 |
| "indexStorageMetadataOnlyForOversizedDocuments" | true または false | サイズが大きい BLOB は、既定ではエラーとして扱われます。 このパラメーターを true に設定すると、コンテンツにインデックスを作成できない場合でも、インデクサーはそのメタデータのインデックスを作成しようとします。 BLOB サイズの制限については、「サービスの制限」を参照してください。 |
次のステップ
データのインポートとベクター化ウィザードの動作を確認し、このインデクサーに対して試してください。 統合ベクター化を使用して、既定のスキーマを使用してベクター検索またはハイブリッド検索用の埋め込みをチャンクおよび作成できます。