このクイック スタートでは、Azure.Search.Documents クライアント ライブラリを使用して、フルテキスト検索用のサンプル データを使用して検索インデックスを作成、読み込み、 クエリを実行します。 フルテキスト検索では、インデックス作成とクエリに Apache Lucene を使用し、結果をスコア付けするための BM25 ランク付けアルゴリズムを使用します。
このクイック スタートでは、 azure-search-sample-data リポジトリの架空のホテル データを使用してインデックスを設定します。
ヒント
完成したプロジェクトから開始する ソース コード をダウンロードするか、次の手順に従って独自のプロジェクトを作成できます。
前提条件
アクティブなサブスクリプションを持つ Azure アカウント。 無料でアカウントを作成できます。
Azure AI Search Service。 まだ作成していない場合、サービスを作成します。 このクイック スタートでは、無料サービスを使用できます。
Microsoft Entra ID の前提条件
Microsoft Entra ID を使用して推奨されるキーレス認証を行うには、次の手順を実行する必要があります。
Azure CLI をインストールします。
ユーザー アカウントに
Search Service ContributorロールとSearch Index Data Contributorロールを割り当てます。 Azure portal の [アクセス制御 (IAM)]>[ロールの割り当ての追加] で、ロールを割り当てることができます。 詳細については、「ロールを使用して Azure AI 検索に接続する」を参照してください。
リソース情報の取得
Azure AI 検索サービスでアプリケーションを認証するには、次の情報を取得する必要があります。
| 変数名 | 値 |
|---|---|
SEARCH_API_ENDPOINT |
この値は、Azure portal で確認できます。 検索サービスを選択し、左側のメニューから [概要] を選択します。
[基本] の下の [URL] は、必要なエンドポイントです。 たとえば、エンドポイントは https://mydemo.search.windows.net のようになります。 |
設定
アプリケーションを含める新しいフォルダー
full-text-quickstartを作成し、次のコマンドを使用してそのフォルダー内で Visual Studio Code を開きます。mkdir full-text-quickstart && cd full-text-quickstart次のコマンドを使用して新しいコンソール アプリケーションを作成します。
dotnet new console次のコマンドを使用して、.NET 用の Azure AI 検索クライアント ライブラリ (Azure.Search.Documents) をインストールします。
dotnet add package Azure.Search.DocumentsMicrosoft Entra ID を使用する推奨されるキーレス認証の場合、次のコマンドを使用して Azure.Identity パッケージをインストールします。
dotnet add package Azure.IdentityMicrosoft Entra ID を使用する推奨されるキーレス認証の場合、次のコマンドを使用して Azure にサインインします。
az login
検索インデックスの作成、読み込み、クエリの実行
前の「設定」セクションで、新しいコンソール アプリケーションを作成し、Azure AI 検索クライアント ライブラリをインストールしました。
このセクションでは、検索インデックスを作成し、それにドキュメントを読み込んで、クエリを実行するコードを追加します。 プログラムを実行して、結果をコンソールに表示します。 コードの詳細な説明については、「コードの説明」セクションを参照してください。
このクイックスタートのサンプル コードでは、推奨されるキーレス認証に Microsoft Entra ID を使用します。 API キーを使用する場合は、DefaultAzureCredential オブジェクトを AzureKeyCredential オブジェクトに置き換えることができます。
Uri serviceEndpoint = new Uri($"https://<Put your search service NAME here>.search.windows.net/");
DefaultAzureCredential credential = new();
Program.cs に次のコードを貼り付けます。 検索サービス名と管理者 API キーを使用して、
serviceName変数とapiKey変数を編集します。using System; using Azure; using Azure.Identity; using Azure.Search.Documents; using Azure.Search.Documents.Indexes; using Azure.Search.Documents.Indexes.Models; using Azure.Search.Documents.Models; namespace AzureSearch.Quickstart { class Program { static void Main(string[] args) { // Your search service endpoint Uri serviceEndpoint = new Uri($"https://<Put your search service NAME here>.search.windows.net/"); // Use the recommended keyless credential instead of the AzureKeyCredential credential. DefaultAzureCredential credential = new(); //AzureKeyCredential credential = new AzureKeyCredential("Your search service admin key"); // Create a SearchIndexClient to send create/delete index commands SearchIndexClient searchIndexClient = new SearchIndexClient(serviceEndpoint, credential); // Create a SearchClient to load and query documents string indexName = "hotels-quickstart"; SearchClient searchClient = new SearchClient(serviceEndpoint, indexName, credential); // Delete index if it exists Console.WriteLine("{0}", "Deleting index...\n"); DeleteIndexIfExists(indexName, searchIndexClient); // Create index Console.WriteLine("{0}", "Creating index...\n"); CreateIndex(indexName, searchIndexClient); SearchClient ingesterClient = searchIndexClient.GetSearchClient(indexName); // Load documents Console.WriteLine("{0}", "Uploading documents...\n"); UploadDocuments(ingesterClient); // Wait 2 secondsfor indexing to complete before starting queries (for demo and console-app purposes only) Console.WriteLine("Waiting for indexing...\n"); System.Threading.Thread.Sleep(2000); // Call the RunQueries method to invoke a series of queries Console.WriteLine("Starting queries...\n"); RunQueries(searchClient); // End the program Console.WriteLine("{0}", "Complete. Press any key to end this program...\n"); Console.ReadKey(); } // Delete the hotels-quickstart index to reuse its name private static void DeleteIndexIfExists(string indexName, SearchIndexClient searchIndexClient) { searchIndexClient.GetIndexNames(); { searchIndexClient.DeleteIndex(indexName); } } // Create hotels-quickstart index private static void CreateIndex(string indexName, SearchIndexClient searchIndexClient) { FieldBuilder fieldBuilder = new FieldBuilder(); var searchFields = fieldBuilder.Build(typeof(Hotel)); var definition = new SearchIndex(indexName, searchFields); var suggester = new SearchSuggester("sg", new[] { "HotelName", "Category", "Address/City", "Address/StateProvince" }); definition.Suggesters.Add(suggester); searchIndexClient.CreateOrUpdateIndex(definition); } // Upload documents in a single Upload request. private static void UploadDocuments(SearchClient searchClient) { IndexDocumentsBatch<Hotel> batch = IndexDocumentsBatch.Create( IndexDocumentsAction.Upload( new Hotel() { HotelId = "1", HotelName = "Stay-Kay City Hotel", Description = "This classic hotel is fully-refurbished and ideally located on the main commercial artery of the city in the heart of New York. A few minutes away is Times Square and the historic centre of the city, as well as other places of interest that make New York one of America's most attractive and cosmopolitan cities.", Category = "Boutique", Tags = new[] { "view", "air conditioning", "concierge" }, ParkingIncluded = false, LastRenovationDate = new DateTimeOffset(2022, 1, 18, 0, 0, 0, TimeSpan.Zero), Rating = 3.6, Address = new Address() { StreetAddress = "677 5th Ave", City = "New York", StateProvince = "NY", PostalCode = "10022", Country = "USA" } }), IndexDocumentsAction.Upload( new Hotel() { HotelId = "2", HotelName = "Old Century Hotel", Description = "The hotel is situated in a nineteenth century plaza, which has been expanded and renovated to the highest architectural standards to create a modern, functional and first-class hotel in which art and unique historical elements coexist with the most modern comforts. The hotel also regularly hosts events like wine tastings, beer dinners, and live music.", Category = "Boutique", Tags = new[] { "pool", "free wifi", "concierge" }, ParkingIncluded = false, LastRenovationDate = new DateTimeOffset(2019, 2, 18, 0, 0, 0, TimeSpan.Zero), Rating = 3.60, Address = new Address() { StreetAddress = "140 University Town Center Dr", City = "Sarasota", StateProvince = "FL", PostalCode = "34243", Country = "USA" } }), IndexDocumentsAction.Upload( new Hotel() { HotelId = "3", HotelName = "Gastronomic Landscape Hotel", Description = "The Gastronomic Hotel stands out for its culinary excellence under the management of William Dough, who advises on and oversees all of the Hotel’s restaurant services.", Category = "Suite", Tags = new[] { "restaurant", "bar", "continental breakfast" }, ParkingIncluded = true, LastRenovationDate = new DateTimeOffset(2015, 9, 20, 0, 0, 0, TimeSpan.Zero), Rating = 4.80, Address = new Address() { StreetAddress = "3393 Peachtree Rd", City = "Atlanta", StateProvince = "GA", PostalCode = "30326", Country = "USA" } }), IndexDocumentsAction.Upload( new Hotel() { HotelId = "4", HotelName = "Sublime Palace Hotel", Description = "Sublime Palace Hotel is located in the heart of the historic center of Sublime in an extremely vibrant and lively area within short walking distance to the sites and landmarks of the city and is surrounded by the extraordinary beauty of churches, buildings, shops and monuments. Sublime Cliff is part of a lovingly restored 19th century resort, updated for every modern convenience.", Category = "Boutique", Tags = new[] { "concierge", "view", "air conditioning" }, ParkingIncluded = true, LastRenovationDate = new DateTimeOffset(2020, 2, 06, 0, 0, 0, TimeSpan.Zero), Rating = 4.60, Address = new Address() { StreetAddress = "7400 San Pedro Ave", City = "San Antonio", StateProvince = "TX", PostalCode = "78216", Country = "USA" } }) ); try { IndexDocumentsResult result = searchClient.IndexDocuments(batch); } catch (Exception) { // If for some reason any documents are dropped during indexing, you can compensate by delaying and // retrying. This simple demo just logs the failed document keys and continues. Console.WriteLine("Failed to index some of the documents: {0}"); } } // Run queries, use WriteDocuments to print output private static void RunQueries(SearchClient searchClient) { SearchOptions options; SearchResults<Hotel> response; // Query 1 Console.WriteLine("Query #1: Search on empty term '*' to return all documents, showing a subset of fields...\n"); options = new SearchOptions() { IncludeTotalCount = true, Filter = "", OrderBy = { "" } }; options.Select.Add("HotelId"); options.Select.Add("HotelName"); options.Select.Add("Rating"); response = searchClient.Search<Hotel>("*", options); WriteDocuments(response); // Query 2 Console.WriteLine("Query #2: Search on 'hotels', filter on 'Rating gt 4', sort by Rating in descending order...\n"); options = new SearchOptions() { Filter = "Rating gt 4", OrderBy = { "Rating desc" } }; options.Select.Add("HotelId"); options.Select.Add("HotelName"); options.Select.Add("Rating"); response = searchClient.Search<Hotel>("hotels", options); WriteDocuments(response); // Query 3 Console.WriteLine("Query #3: Limit search to specific fields (pool in Tags field)...\n"); options = new SearchOptions() { SearchFields = { "Tags" } }; options.Select.Add("HotelId"); options.Select.Add("HotelName"); options.Select.Add("Tags"); response = searchClient.Search<Hotel>("pool", options); WriteDocuments(response); // Query 4 - Use Facets to return a faceted navigation structure for a given query // Filters are typically used with facets to narrow results on OnClick events Console.WriteLine("Query #4: Facet on 'Category'...\n"); options = new SearchOptions() { Filter = "" }; options.Facets.Add("Category"); options.Select.Add("HotelId"); options.Select.Add("HotelName"); options.Select.Add("Category"); response = searchClient.Search<Hotel>("*", options); WriteDocuments(response); // Query 5 Console.WriteLine("Query #5: Look up a specific document...\n"); Response<Hotel> lookupResponse; lookupResponse = searchClient.GetDocument<Hotel>("3"); Console.WriteLine(lookupResponse.Value.HotelId); // Query 6 Console.WriteLine("Query #6: Call Autocomplete on HotelName...\n"); var autoresponse = searchClient.Autocomplete("sa", "sg"); WriteDocuments(autoresponse); } // Write search results to console private static void WriteDocuments(SearchResults<Hotel> searchResults) { foreach (SearchResult<Hotel> result in searchResults.GetResults()) { Console.WriteLine(result.Document); } Console.WriteLine(); } private static void WriteDocuments(AutocompleteResults autoResults) { foreach (AutocompleteItem result in autoResults.Results) { Console.WriteLine(result.Text); } Console.WriteLine(); } } }同じフォルダー内に、Hotel.cs という名前の新しいファイルを作成し、次のコードを貼り付けます。 このコードは、ホテル ドキュメントの構造を定義します。
using System; using System.Text.Json.Serialization; using Azure.Search.Documents.Indexes; using Azure.Search.Documents.Indexes.Models; namespace AzureSearch.Quickstart { public partial class Hotel { [SimpleField(IsKey = true, IsFilterable = true)] public string HotelId { get; set; } [SearchableField(IsSortable = true)] public string HotelName { get; set; } [SearchableField(AnalyzerName = LexicalAnalyzerName.Values.EnLucene)] public string Description { get; set; } [SearchableField(IsFilterable = true, IsSortable = true, IsFacetable = true)] public string Category { get; set; } [SearchableField(IsFilterable = true, IsFacetable = true)] public string[] Tags { get; set; } [SimpleField(IsFilterable = true, IsSortable = true, IsFacetable = true)] public bool? ParkingIncluded { get; set; } [SimpleField(IsFilterable = true, IsSortable = true, IsFacetable = true)] public DateTimeOffset? LastRenovationDate { get; set; } [SimpleField(IsFilterable = true, IsSortable = true, IsFacetable = true)] public double? Rating { get; set; } [SearchableField] public Address Address { get; set; } } }Hotel.cs という名前の新しいファイルを作成し、次のコードを貼り付けてホテル ドキュメントの構造を定義します。 フィールドは、その属性によって、アプリケーション内でどのように使用できるかが決まります。 たとえばフィルター式をサポートするフィールドには、それぞれ
IsFilterable属性が割り当てられている必要があります。using System; using System.Text.Json.Serialization; using Azure.Search.Documents.Indexes; using Azure.Search.Documents.Indexes.Models; namespace AzureSearch.Quickstart { public partial class Hotel { [SimpleField(IsKey = true, IsFilterable = true)] public string HotelId { get; set; } [SearchableField(IsSortable = true)] public string HotelName { get; set; } [SearchableField(AnalyzerName = LexicalAnalyzerName.Values.EnLucene)] public string Description { get; set; } [SearchableField(IsFilterable = true, IsSortable = true, IsFacetable = true)] public string Category { get; set; } [SearchableField(IsFilterable = true, IsFacetable = true)] public string[] Tags { get; set; } [SimpleField(IsFilterable = true, IsSortable = true, IsFacetable = true)] public bool? ParkingIncluded { get; set; } [SimpleField(IsFilterable = true, IsSortable = true, IsFacetable = true)] public DateTimeOffset? LastRenovationDate { get; set; } [SimpleField(IsFilterable = true, IsSortable = true, IsFacetable = true)] public double? Rating { get; set; } [SearchableField] public Address Address { get; set; } } }Address.cs という名前の新しいファイルを作成し、次のコードを貼り付けて住所ドキュメントの構造を定義します。
using Azure.Search.Documents.Indexes; namespace AzureSearch.Quickstart { public partial class Address { [SearchableField(IsFilterable = true)] public string StreetAddress { get; set; } [SearchableField(IsFilterable = true, IsSortable = true, IsFacetable = true)] public string City { get; set; } [SearchableField(IsFilterable = true, IsSortable = true, IsFacetable = true)] public string StateProvince { get; set; } [SearchableField(IsFilterable = true, IsSortable = true, IsFacetable = true)] public string PostalCode { get; set; } [SearchableField(IsFilterable = true, IsSortable = true, IsFacetable = true)] public string Country { get; set; } } }Hotel.Methods.cs という名前の新しいファイルを作成し、次のコードを貼り付けて
ToString()クラスのHotelオーバーライドを定義します。using System; using System.Text; namespace AzureSearch.Quickstart { public partial class Hotel { public override string ToString() { var builder = new StringBuilder(); if (!String.IsNullOrEmpty(HotelId)) { builder.AppendFormat("HotelId: {0}\n", HotelId); } if (!String.IsNullOrEmpty(HotelName)) { builder.AppendFormat("Name: {0}\n", HotelName); } if (!String.IsNullOrEmpty(Description)) { builder.AppendFormat("Description: {0}\n", Description); } if (!String.IsNullOrEmpty(Category)) { builder.AppendFormat("Category: {0}\n", Category); } if (Tags != null && Tags.Length > 0) { builder.AppendFormat("Tags: [ {0} ]\n", String.Join(", ", Tags)); } if (ParkingIncluded.HasValue) { builder.AppendFormat("Parking included: {0}\n", ParkingIncluded.Value ? "yes" : "no"); } if (LastRenovationDate.HasValue) { builder.AppendFormat("Last renovated on: {0}\n", LastRenovationDate); } if (Rating.HasValue) { builder.AppendFormat("Rating: {0}\n", Rating); } if (Address != null && !Address.IsEmpty) { builder.AppendFormat("Address: \n{0}\n", Address.ToString()); } return builder.ToString(); } } }Address.Methods.cs という名前の新しいファイルを作成し、次のコードを貼り付けて
ToString()クラスのAddressオーバーライドを定義します。using System; using System.Text; using System.Text.Json.Serialization; namespace AzureSearch.Quickstart { public partial class Address { public override string ToString() { var builder = new StringBuilder(); if (!IsEmpty) { builder.AppendFormat("{0}\n{1}, {2} {3}\n{4}", StreetAddress, City, StateProvince, PostalCode, Country); } return builder.ToString(); } [JsonIgnore] public bool IsEmpty => String.IsNullOrEmpty(StreetAddress) && String.IsNullOrEmpty(City) && String.IsNullOrEmpty(StateProvince) && String.IsNullOrEmpty(PostalCode) && String.IsNullOrEmpty(Country); } }アプリケーションをビルドし、次のコマンドを使用して実行します。
dotnet run
出力には、Console.WriteLine からのメッセージに加え、クエリの情報と結果が表示されます。
コードの説明
これまでのセクションでは、新しいコンソール アプリケーションを作成し、Azure AI 検索クライアント ライブラリをインストールしました。 検索インデックスを作成し、それにドキュメントを読み込んで、クエリを実行するコードを追加しました。 プログラムを実行して、結果をコンソールに表示しました。
このセクションでは、コンソール アプリケーションに追加したコードについて説明します。
検索クライアントを作成する
Program.cs では、次の 2 つのクライアントを作成しました。
- SearchIndexClient は、インデックスを作成します。
- SearchClient は、既存のインデックスを読み込んでクエリを実行します。
どちらのクライアントにも、リソース情報に関するセクションで前述した検索サービス エンドポイントと資格情報が必要です。
このクイックスタートのサンプル コードでは、推奨されるキーレス認証に Microsoft Entra ID を使用します。 API キーを使用する場合は、DefaultAzureCredential オブジェクトを AzureKeyCredential オブジェクトに置き換えることができます。
Uri serviceEndpoint = new Uri($"https://<Put your search service NAME here>.search.windows.net/");
DefaultAzureCredential credential = new();
static void Main(string[] args)
{
// Your search service endpoint
Uri serviceEndpoint = new Uri($"https://<Put your search service NAME here>.search.windows.net/");
// Use the recommended keyless credential instead of the AzureKeyCredential credential.
DefaultAzureCredential credential = new();
//AzureKeyCredential credential = new AzureKeyCredential("Your search service admin key");
// Create a SearchIndexClient to send create/delete index commands
SearchIndexClient searchIndexClient = new SearchIndexClient(serviceEndpoint, credential);
// Create a SearchClient to load and query documents
string indexName = "hotels-quickstart";
SearchClient searchClient = new SearchClient(serviceEndpoint, indexName, credential);
// REDACTED FOR BREVITY . . .
}
インデックスを作成する
このクイックスタートでは、Hotels インデックスを作成し、それにホテル データを読み込んでクエリを実行します。 この手順では、インデックス内のフィールドを定義します。 それぞれのフィールドの定義には、名前とデータ型、属性が存在し、それらによってフィールドの使い方が決まります。
簡潔で読みやすくするために、この例では、"Azure.Search.Documents" ライブラリの同期メソッドを使用しています。 ただし運用環境のシナリオでは、アプリのスケーラビリティと応答性を確保するために非同期メソッドを使用する必要があります。 たとえば、CreateIndex ではなく CreateIndexAsync を使用します。
構造を定義する
2 つのヘルパー クラス (Hotel.cs と Address.cs) を作成して、ホテル ドキュメントとホテルの住所の構造を定義しました。
Hotel クラスには、ホテルの ID、名前、説明、カテゴリ、タグ、駐車場、改装日、評価、住所のフィールドが含まれます。
Address クラスには、番地、市区町村、都道府県、郵便番号、国/地域のフィールドが含まれます。
"Azure.Search.Documents" クライアント ライブラリでは、SearchableField と SimpleField を使用してフィールドの定義を効率化できます。 どちらも SearchField から派生したもので、コードの簡素化に役立つ可能性があります。
SimpleFieldは、任意のデータ型にすることができます。また、常に検索不可能であり (フルテキスト検索クエリでは無視されます)、取得可能です (非表示ではありません)。 その他の属性は、既定ではオフですが、有効にすることができます。SimpleFieldは、フィルター、ファセット、スコアリング プロファイルでのみ使用されるフィールドやドキュメント ID での使用が考えられます。 その場合は必ず、シナリオに必要な属性を適用してください (ドキュメント ID のIsKey = trueなど)。 詳細については、ソース コードの SimpleFieldAttribute.cs を参照してください。SearchableFieldは文字列であることが必要です。常に検索可能で、取得可能となります。 その他の属性は、既定ではオフですが、有効にすることができます。 検索可能なタイプのフィールドであるため、同意語がサポートされるほか、アナライザーのプロパティがすべてサポートされます。 詳細については、ソース コードの SearchableFieldAttribute.cs を参照してください。
基本 SearchField API を使用する場合も、そのいずれかのヘルパー モデルを使用する場合も、フィルター、ファセット、並べ替えの属性は明示的に有効にする必要があります。 たとえば、IsFilterable、IsSortable、IsFacetable の各属性は、前のサンプルのように明示的に指定する必要があります。
検索インデックスの作成
Program.cs で、SearchIndex オブジェクトを作成し、CreateIndex メソッドを呼び出して、検索サービスのインデックスを表現します。 インデックスには、指定されたフィールドでオートコンプリートを有効にするための SearchSuggester も含まれています。
// Create hotels-quickstart index
private static void CreateIndex(string indexName, SearchIndexClient searchIndexClient)
{
FieldBuilder fieldBuilder = new FieldBuilder();
var searchFields = fieldBuilder.Build(typeof(Hotel));
var definition = new SearchIndex(indexName, searchFields);
var suggester = new SearchSuggester("sg", new[] { "HotelName", "Category", "Address/City", "Address/StateProvince" });
definition.Suggesters.Add(suggester);
searchIndexClient.CreateOrUpdateIndex(definition);
}
ドキュメントを読み込む
Azure AI Search は、サービスに保存されているコンテンツを検索します。 この手順では、作成したホテル インデックスに準拠する JSON ドキュメントを読み込みます。
Azure AI Search では、検索ドキュメントは、インデックス作成への入力とクエリからの出力の両方であるデータ構造です。 外部データ ソースから取得するドキュメント入力には、データベース内の行、Blob storage 内の BLOB、ディスク上の JSON ドキュメントがあります。 この例では、手短な方法として、4 つのホテルの JSON ドキュメントをコード自体に埋め込みます。
ドキュメントをアップロードするときは、IndexDocumentsBatch オブジェクトを使用する必要があります。
IndexDocumentsBatch オブジェクトには、 Actionsのコレクションが含まれています。各オブジェクトには、Azure AICognitive Searchに実行するアクション (アップロード、マージ、削除、および mergeOrUpload) を示すドキュメントとプロパティが含まれています。
Program.cs で、ドキュメントとインデックス アクションの配列を作成し、その配列を IndexDocumentsBatch に渡します。 以下のドキュメントは、Hotel クラスで定義されている hotels-quickstart インデックスに準拠しています。
// Upload documents in a single Upload request.
private static void UploadDocuments(SearchClient searchClient)
{
IndexDocumentsBatch<Hotel> batch = IndexDocumentsBatch.Create(
IndexDocumentsAction.Upload(
new Hotel()
{
HotelId = "1",
HotelName = "Stay-Kay City Hotel",
Description = "This classic hotel is fully-refurbished and ideally located on the main commercial artery of the city in the heart of New York. A few minutes away is Times Square and the historic centre of the city, as well as other places of interest that make New York one of America's most attractive and cosmopolitan cities.",
Category = "Boutique",
Tags = new[] { "view", "air conditioning", "concierge" },
ParkingIncluded = false,
LastRenovationDate = new DateTimeOffset(2022, 1, 18, 0, 0, 0, TimeSpan.Zero),
Rating = 3.6,
Address = new Address()
{
StreetAddress = "677 5th Ave",
City = "New York",
StateProvince = "NY",
PostalCode = "10022",
Country = "USA"
}
}),
// REDACTED FOR BREVITY
}
IndexDocumentsBatch オブジェクトを初期化したら、SearchClient オブジェクトの IndexDocuments を呼び出すことによって、それをインデックスに送信することができます。
Main() で SearchClient を使用してドキュメントを読み込みますが、この操作には、サービスに対する管理者権限も必要になります。この権限は通常、SearchIndexClient に関連付けられています。 この操作を設定する 1 つの方法は、SearchIndexClient (この例ではsearchIndexClient) を使用して SearchClient を取得することです。
SearchClient ingesterClient = searchIndexClient.GetSearchClient(indexName);
// Load documents
Console.WriteLine("{0}", "Uploading documents...\n");
UploadDocuments(ingesterClient);
すべてのコマンドを順番に実行するコンソール アプリがあるため、インデックス作成とクエリの間に 2 秒の待機時間を追加します。
// Wait 2 seconds for indexing to complete before starting queries (for demo and console-app purposes only)
Console.WriteLine("Waiting for indexing...\n");
System.Threading.Thread.Sleep(2000);
2 秒の遅延により、非同期のインデックス作成を待ち、クエリの実行前にすべてのドキュメントのインデックスを作成できるようにしています。 通常、遅延のコーディングは、デモ、テスト、およびサンプル アプリケーションでのみ必要です。
インデックスを検索する
最初のドキュメントのインデックスが作成されるとすぐにクエリの結果を取得できますが、インデックスの実際のテストではすべてのドキュメントのインデックスが作成されるまで待つ必要があります。
このセクションでは、クエリ ロジックと結果の 2 つの機能を追加します。 クエリには、Search メソッドを使用します。 このメソッドは、検索テキスト (クエリ文字列) と他のオプションを受け取ります。
その結果は、SearchResults クラスによって表されます。
Program.cs 内の WriteDocuments メソッドは、検索結果をコンソールに出力します。
// Write search results to console
private static void WriteDocuments(SearchResults<Hotel> searchResults)
{
foreach (SearchResult<Hotel> result in searchResults.GetResults())
{
Console.WriteLine(result.Document);
}
Console.WriteLine();
}
private static void WriteDocuments(AutocompleteResults autoResults)
{
foreach (AutocompleteItem result in autoResults.Results)
{
Console.WriteLine(result.Text);
}
Console.WriteLine();
}
クエリの例 1
RunQueries メソッドは、クエリを実行して結果を返します。 結果は、Hotel オブジェクトです。 このサンプルは、メソッド シグネチャと最初のクエリを示しています。 このクエリは、ドキュメントから選択されたフィールドを使用して結果を作成できる Select パラメーターを示しています。
// Run queries, use WriteDocuments to print output
private static void RunQueries(SearchClient searchClient)
{
SearchOptions options;
SearchResults<Hotel> response;
// Query 1
Console.WriteLine("Query #1: Search on empty term '*' to return all documents, showing a subset of fields...\n");
options = new SearchOptions()
{
IncludeTotalCount = true,
Filter = "",
OrderBy = { "" }
};
options.Select.Add("HotelId");
options.Select.Add("HotelName");
options.Select.Add("Address/City");
response = searchClient.Search<Hotel>("*", options);
WriteDocuments(response);
// REDACTED FOR BREVITY
}
クエリの例 2
2 つ目のクエリでは、語句を検索し、Rating が 4 を超えるドキュメントを選択するフィルターを追加したうえで、Rating の降順で並べ替えます。 フィルターは、インデックス内の IsFilterable フィールドに対して評価されるブール式です。 フィルター クエリでは、値は包含されるか除外されるかのどちらかです。 そのため、フィルター クエリに関連付けられている関連性スコアはありません。
// Query 2
Console.WriteLine("Query #2: Search on 'hotels', filter on 'Rating gt 4', sort by Rating in descending order...\n");
options = new SearchOptions()
{
Filter = "Rating gt 4",
OrderBy = { "Rating desc" }
};
options.Select.Add("HotelId");
options.Select.Add("HotelName");
options.Select.Add("Rating");
response = searchClient.Search<Hotel>("hotels", options);
WriteDocuments(response);
クエリの例 3
3 番目のクエリは、フルテキスト検索操作の範囲を特定のフィールドに設定するために使用する searchFields を示しています。
// Query 3
Console.WriteLine("Query #3: Limit search to specific fields (pool in Tags field)...\n");
options = new SearchOptions()
{
SearchFields = { "Tags" }
};
options.Select.Add("HotelId");
options.Select.Add("HotelName");
options.Select.Add("Tags");
response = searchClient.Search<Hotel>("pool", options);
WriteDocuments(response);
クエリの例 4
4 番目のクエリは、ファセット ナビゲーション構造を構築するために使用できる facets を示しています。
// Query 4
Console.WriteLine("Query #4: Facet on 'Category'...\n");
options = new SearchOptions()
{
Filter = ""
};
options.Facets.Add("Category");
options.Select.Add("HotelId");
options.Select.Add("HotelName");
options.Select.Add("Category");
response = searchClient.Search<Hotel>("*", options);
WriteDocuments(response);
クエリの例 5
5 番目のクエリでは、特定のドキュメントを返します。 ドキュメント検索は、結果セット内の OnClick イベントに対する一般的な応答です。
// Query 5
Console.WriteLine("Query #5: Look up a specific document...\n");
Response<Hotel> lookupResponse;
lookupResponse = searchClient.GetDocument<Hotel>("3");
Console.WriteLine(lookupResponse.Value.HotelId);
クエリの例 6
最後のクエリは、オートコンプリートの構文を示しています。これは、インデックスで定義した suggester に関連付けられている sourceFields の 2 つの一致候補に解決される、"sa" という部分的なユーザー入力をシミュレートしています。
// Query 6
Console.WriteLine("Query #6: Call Autocomplete on HotelName that starts with 'sa'...\n");
var autoresponse = searchClient.Autocomplete("sa", "sg");
WriteDocuments(autoresponse);
クエリの概要
上記のクエリは、クエリで語句を照合する複数の方法 (フルテキスト検索、フィルター、オートコンプリート) を示しています。
フルテキスト検索とフィルターは、SearchClient.Search メソッドを使用して実行されます。 検索クエリは searchText 文字列で渡すことができます。一方、フィルター式は SearchOptions クラスの Filter プロパティで渡すことができます。 検索せずにフィルター処理を実行するには、"*" メソッドの searchText パラメーターに を渡します。 フィルター処理を行わずに検索するには、Filter プロパティを未設定のままにするか、SearchOptions インスタンスを 1 つも渡さないようにします。
このクイック スタートでは、Azure.Search.Documents クライアント ライブラリを使用して、フルテキスト検索用のサンプル データを使用して検索インデックスを作成、読み込み、 クエリを実行します。 フルテキスト検索では、インデックス作成とクエリに Apache Lucene を使用し、結果をスコア付けするための BM25 ランク付けアルゴリズムを使用します。
このクイック スタートでは、 azure-search-sample-data リポジトリの架空のホテル データを使用してインデックスを設定します。
ヒント
完成したプロジェクトから開始する ソース コード をダウンロードするか、次の手順に従って独自のプロジェクトを作成できます。
前提条件
アクティブなサブスクリプションを持つ Azure アカウント。 無料でアカウントを作成できます。
Azure AI Search Service。 まだ作成していない場合、サービスを作成します。 このクイック スタートでは、無料サービスを使用できます。
Microsoft Entra ID の前提条件
Microsoft Entra ID を使用して推奨されるキーレス認証を行うには、次の手順を実行する必要があります。
Azure CLI をインストールします。
ユーザー アカウントに
Search Service ContributorロールとSearch Index Data Contributorロールを割り当てます。 Azure portal の [アクセス制御 (IAM)]>[ロールの割り当ての追加] で、ロールを割り当てることができます。 詳細については、「ロールを使用して Azure AI 検索に接続する」を参照してください。
リソース情報の取得
Azure AI 検索サービスでアプリケーションを認証するには、次の情報を取得する必要があります。
| 変数名 | 値 |
|---|---|
SEARCH_API_ENDPOINT |
この値は、Azure portal で確認できます。 検索サービスを選択し、左側のメニューから [概要] を選択します。
[基本] の下の [URL] は、必要なエンドポイントです。 たとえば、エンドポイントは https://mydemo.search.windows.net のようになります。 |
設定
このクイックスタートのサンプルは、Java ランタイムで動作します。 Azul Zulu OpenJDK などの Java Development Kit をインストールします。 Microsoft Build of OpenJDK またはお好みの JDK も機能する必要があります。
Apache Maven をインストールします。 次に
mvn -vを実行して、インストールが成功したことを確認します。プロジェクトのルートに新しい
pom.xmlファイルを作成し、その中に以下のコードをコピーします:<project xmlns="http://maven.apache.org/POM/4.0.0" xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance" xsi:schemaLocation="http://maven.apache.org/POM/4.0.0 http://maven.apache.org/xsd/maven-4.0.0.xsd"> <modelVersion>4.0.0</modelVersion> <groupId>azure.search.sample</groupId> <artifactId>azuresearchquickstart</artifactId> <version>1.0.0-SNAPSHOT</version> <build> <sourceDirectory>src</sourceDirectory> <plugins> <plugin> <artifactId>maven-compiler-plugin</artifactId> <version>3.7.0</version> <configuration> <source>1.8</source> <target>1.8</target> </configuration> </plugin> </plugins> </build> <dependencies> <dependency> <groupId>junit</groupId> <artifactId>junit</artifactId> <version>4.11</version> <scope>test</scope> </dependency> <dependency> <groupId>com.azure</groupId> <artifactId>azure-search-documents</artifactId> <version>11.7.3</version> </dependency> <dependency> <groupId>com.azure</groupId> <artifactId>azure-core</artifactId> <version>1.53.0</version> </dependency> <dependency> <groupId>com.azure</groupId> <artifactId>azure-identity</artifactId> <version>1.15.1</version> </dependency> </dependencies> </project>Java 用の Azure AI 検索クライアント ライブラリ (Azure.Search.Documents) と Java 用 Azure ID クライアント ライブラリを含む依存関係をインストールします。
mvn clean dependency:copy-dependenciesMicrosoft Entra ID を使用する推奨されるキーレス認証の場合、次のコマンドを使用して Azure にサインインします。
az login
検索インデックスの作成、読み込み、クエリの実行
前の「設定」セクションで、Azure AI 検索クライアント ライブラリとその他の依存関係をインストールしました。
このセクションでは、検索インデックスを作成し、それにドキュメントを読み込んで、クエリを実行するコードを追加します。 プログラムを実行して、結果をコンソールに表示します。 コードの詳細な説明については、「コードの説明」セクションを参照してください。
このクイックスタートのサンプル コードでは、推奨されるキーレス認証に Microsoft Entra ID を使用します。 API キーを使用する場合は、DefaultAzureCredential オブジェクトを AzureKeyCredential オブジェクトに置き換えることができます。
String searchServiceEndpoint = "https://<Put your search service NAME here>.search.windows.net/";
DefaultAzureCredential credential = new DefaultAzureCredentialBuilder().build();
App.java という名前の新しいファイルを作成し、次のコードを App.java に貼り付けます。
import java.util.Arrays; import java.util.ArrayList; import java.time.OffsetDateTime; import java.time.ZoneOffset; import java.time.LocalDateTime; import java.time.LocalDate; import java.time.LocalTime; import com.azure.core.util.Configuration; import com.azure.core.util.Context; import com.azure.identity.DefaultAzureCredential; import com.azure.identity.DefaultAzureCredentialBuilder; import com.azure.search.documents.SearchClient; import com.azure.search.documents.SearchClientBuilder; import com.azure.search.documents.indexes.SearchIndexClient; import com.azure.search.documents.indexes.SearchIndexClientBuilder; import com.azure.search.documents.indexes.models.IndexDocumentsBatch; import com.azure.search.documents.models.SearchOptions; import com.azure.search.documents.indexes.models.SearchIndex; import com.azure.search.documents.indexes.models.SearchSuggester; import com.azure.search.documents.util.AutocompletePagedIterable; import com.azure.search.documents.util.SearchPagedIterable; public class App { public static void main(String[] args) { // Your search service endpoint "https://<Put your search service NAME here>.search.windows.net/"; // Use the recommended keyless credential instead of the AzureKeyCredential credential. DefaultAzureCredential credential = new DefaultAzureCredentialBuilder().build(); //AzureKeyCredential credential = new AzureKeyCredential("<Your search service admin key>"); // Create a SearchIndexClient to send create/delete index commands SearchIndexClient searchIndexClient = new SearchIndexClientBuilder() .endpoint(searchServiceEndpoint) .credential(credential) .buildClient(); // Create a SearchClient to load and query documents String indexName = "hotels-quickstart-java"; SearchClient searchClient = new SearchClientBuilder() .endpoint(searchServiceEndpoint) .credential(credential) .indexName(indexName) .buildClient(); // Create Search Index for Hotel model searchIndexClient.createOrUpdateIndex( new SearchIndex(indexName, SearchIndexClient.buildSearchFields(Hotel.class, null)) .setSuggesters(new SearchSuggester("sg", Arrays.asList("HotelName")))); // Upload sample hotel documents to the Search Index uploadDocuments(searchClient); // Wait 2 seconds for indexing to complete before starting queries (for demo and console-app purposes only) System.out.println("Waiting for indexing...\n"); try { Thread.sleep(2000); } catch (InterruptedException e) { } // Call the RunQueries method to invoke a series of queries System.out.println("Starting queries...\n"); RunQueries(searchClient); // End the program System.out.println("Complete.\n"); } // Upload documents in a single Upload request. private static void uploadDocuments(SearchClient searchClient) { var hotelList = new ArrayList<Hotel>(); var hotel = new Hotel(); hotel.hotelId = "1"; hotel.hotelName = "Stay-Kay City Hotel"; hotel.description = "This classic hotel is fully-refurbished and ideally located on the main commercial artery of the city in the heart of New York. A few minutes away is Times Square and the historic centre of the city, as well as other places of interest that make New York one of America's most attractive and cosmopolitan cities."; hotel.category = "Boutique"; hotel.tags = new String[] { "view", "air conditioning", "concierge" }; hotel.parkingIncluded = false; hotel.lastRenovationDate = OffsetDateTime.of(LocalDateTime.of(LocalDate.of(2022, 1, 18), LocalTime.of(0, 0)), ZoneOffset.UTC); hotel.rating = 3.6; hotel.address = new Address(); hotel.address.streetAddress = "677 5th Ave"; hotel.address.city = "New York"; hotel.address.stateProvince = "NY"; hotel.address.postalCode = "10022"; hotel.address.country = "USA"; hotelList.add(hotel); hotel = new Hotel(); hotel.hotelId = "2"; hotel.hotelName = "Old Century Hotel"; hotel.description = "The hotel is situated in a nineteenth century plaza, which has been expanded and renovated to the highest architectural standards to create a modern, functional and first-class hotel in which art and unique historical elements coexist with the most modern comforts. The hotel also regularly hosts events like wine tastings, beer dinners, and live music.", hotel.category = "Boutique"; hotel.tags = new String[] { "pool", "free wifi", "concierge" }; hotel.parkingIncluded = false; hotel.lastRenovationDate = OffsetDateTime.of(LocalDateTime.of(LocalDate.of(2019, 2, 18), LocalTime.of(0, 0)), ZoneOffset.UTC); hotel.rating = 3.60; hotel.address = new Address(); hotel.address.streetAddress = "140 University Town Center Dr"; hotel.address.city = "Sarasota"; hotel.address.stateProvince = "FL"; hotel.address.postalCode = "34243"; hotel.address.country = "USA"; hotelList.add(hotel); hotel = new Hotel(); hotel.hotelId = "3"; hotel.hotelName = "Gastronomic Landscape Hotel"; hotel.description = "The Gastronomic Hotel stands out for its culinary excellence under the management of William Dough, who advises on and oversees all of the Hotel’s restaurant services."; hotel.category = "Suite"; hotel.tags = new String[] { "restaurant", "bar", "continental breakfast" }; hotel.parkingIncluded = true; hotel.lastRenovationDate = OffsetDateTime.of(LocalDateTime.of(LocalDate.of(2015, 9, 20), LocalTime.of(0, 0)), ZoneOffset.UTC); hotel.rating = 4.80; hotel.address = new Address(); hotel.address.streetAddress = "3393 Peachtree Rd"; hotel.address.city = "Atlanta"; hotel.address.stateProvince = "GA"; hotel.address.postalCode = "30326"; hotel.address.country = "USA"; hotelList.add(hotel); hotel = new Hotel(); hotel.hotelId = "4"; hotel.hotelName = "Sublime Palace Hotel"; hotel.description = "Sublime Palace Hotel is located in the heart of the historic center of Sublime in an extremely vibrant and lively area within short walking distance to the sites and landmarks of the city and is surrounded by the extraordinary beauty of churches, buildings, shops and monuments. Sublime Cliff is part of a lovingly restored 19th century resort, updated for every modern convenience."; hotel.category = "Boutique"; hotel.tags = new String[] { "concierge", "view", "air conditioning" }; hotel.parkingIncluded = true; hotel.lastRenovationDate = OffsetDateTime.of(LocalDateTime.of(LocalDate.of(2020, 2, 06), LocalTime.of(0, 0)), ZoneOffset.UTC); hotel.rating = 4.60; hotel.address = new Address(); hotel.address.streetAddress = "7400 San Pedro Ave"; hotel.address.city = "San Antonio"; hotel.address.stateProvince = "TX"; hotel.address.postalCode = "78216"; hotel.address.country = "USA"; hotelList.add(hotel); var batch = new IndexDocumentsBatch<Hotel>(); batch.addMergeOrUploadActions(hotelList); try { searchClient.indexDocuments(batch); } catch (Exception e) { e.printStackTrace(); // If for some reason any documents are dropped during indexing, you can compensate by delaying and // retrying. This simple demo just logs failure and continues System.err.println("Failed to index some of the documents"); } } // Write search results to console private static void WriteSearchResults(SearchPagedIterable searchResults) { searchResults.iterator().forEachRemaining(result -> { Hotel hotel = result.getDocument(Hotel.class); System.out.println(hotel); }); System.out.println(); } // Write autocomplete results to console private static void WriteAutocompleteResults(AutocompletePagedIterable autocompleteResults) { autocompleteResults.iterator().forEachRemaining(result -> { String text = result.getText(); System.out.println(text); }); System.out.println(); } // Run queries, use WriteDocuments to print output private static void RunQueries(SearchClient searchClient) { // Query 1 System.out.println("Query #1: Search on empty term '*' to return all documents, showing a subset of fields...\n"); SearchOptions options = new SearchOptions(); options.setIncludeTotalCount(true); options.setFilter(""); options.setOrderBy(""); options.setSelect("HotelId", "HotelName", "Address/City"); WriteSearchResults(searchClient.search("*", options, Context.NONE)); // Query 2 System.out.println("Query #2: Search on 'hotels', filter on 'Rating gt 4', sort by Rating in descending order...\n"); options = new SearchOptions(); options.setFilter("Rating gt 4"); options.setOrderBy("Rating desc"); options.setSelect("HotelId", "HotelName", "Rating"); WriteSearchResults(searchClient.search("hotels", options, Context.NONE)); // Query 3 System.out.println("Query #3: Limit search to specific fields (pool in Tags field)...\n"); options = new SearchOptions(); options.setSearchFields("Tags"); options.setSelect("HotelId", "HotelName", "Tags"); WriteSearchResults(searchClient.search("pool", options, Context.NONE)); // Query 4 System.out.println("Query #4: Facet on 'Category'...\n"); options = new SearchOptions(); options.setFilter(""); options.setFacets("Category"); options.setSelect("HotelId", "HotelName", "Category"); WriteSearchResults(searchClient.search("*", options, Context.NONE)); // Query 5 System.out.println("Query #5: Look up a specific document...\n"); Hotel lookupResponse = searchClient.getDocument("3", Hotel.class); System.out.println(lookupResponse.hotelId); System.out.println(); // Query 6 System.out.println("Query #6: Call Autocomplete on HotelName that starts with 's'...\n"); WriteAutocompleteResults(searchClient.autocomplete("s", "sg")); } }Hotel.java という名前の新しいファイルを作成し、次のコードを Hotel.java に貼り付けます。
import com.azure.search.documents.indexes.SearchableField; import com.azure.search.documents.indexes.SimpleField; import com.fasterxml.jackson.annotation.JsonInclude; import com.fasterxml.jackson.annotation.JsonProperty; import com.fasterxml.jackson.core.JsonProcessingException; import com.fasterxml.jackson.databind.ObjectMapper; import com.fasterxml.jackson.annotation.JsonInclude.Include; import java.time.OffsetDateTime; /** * Model class representing a hotel. */ @JsonInclude(Include.NON_NULL) public class Hotel { /** * Hotel ID */ @JsonProperty("HotelId") @SimpleField(isKey = true) public String hotelId; /** * Hotel name */ @JsonProperty("HotelName") @SearchableField(isSortable = true) public String hotelName; /** * Description */ @JsonProperty("Description") @SearchableField(analyzerName = "en.microsoft") public String description; /** * Category */ @JsonProperty("Category") @SearchableField(isFilterable = true, isSortable = true, isFacetable = true) public String category; /** * Tags */ @JsonProperty("Tags") @SearchableField(isFilterable = true, isFacetable = true) public String[] tags; /** * Whether parking is included */ @JsonProperty("ParkingIncluded") @SimpleField(isFilterable = true, isSortable = true, isFacetable = true) public Boolean parkingIncluded; /** * Last renovation time */ @JsonProperty("LastRenovationDate") @SimpleField(isFilterable = true, isSortable = true, isFacetable = true) public OffsetDateTime lastRenovationDate; /** * Rating */ @JsonProperty("Rating") @SimpleField(isFilterable = true, isSortable = true, isFacetable = true) public Double rating; /** * Address */ @JsonProperty("Address") public Address address; @Override public String toString() { try { return new ObjectMapper().writeValueAsString(this); } catch (JsonProcessingException e) { e.printStackTrace(); return ""; } } }Address.java という名前の新しいファイルを作成し、次のコードを Address.java に貼り付けます。
import com.azure.search.documents.indexes.SearchableField; import com.fasterxml.jackson.annotation.JsonInclude; import com.fasterxml.jackson.annotation.JsonProperty; import com.fasterxml.jackson.annotation.JsonInclude.Include; /** * Model class representing an address. */ @JsonInclude(Include.NON_NULL) public class Address { /** * Street address */ @JsonProperty("StreetAddress") @SearchableField public String streetAddress; /** * City */ @JsonProperty("City") @SearchableField(isFilterable = true, isSortable = true, isFacetable = true) public String city; /** * State or province */ @JsonProperty("StateProvince") @SearchableField(isFilterable = true, isSortable = true, isFacetable = true) public String stateProvince; /** * Postal code */ @JsonProperty("PostalCode") @SearchableField(isFilterable = true, isSortable = true, isFacetable = true) public String postalCode; /** * Country */ @JsonProperty("Country") @SearchableField(isFilterable = true, isSortable = true, isFacetable = true) public String country; }新しいコンソール アプリケーションを実行します。
javac Address.java App.java Hotel.java -cp ".;target\dependency\*" java -cp ".;target\dependency\*" App
コードの説明
これまでのセクションでは、新しいコンソール アプリケーションを作成し、Azure AI 検索クライアント ライブラリをインストールしました。 検索インデックスを作成し、それにドキュメントを読み込んで、クエリを実行するコードを追加しました。 プログラムを実行して、結果をコンソールに表示しました。
このセクションでは、コンソール アプリケーションに追加したコードについて説明します。
検索クライアントを作成する
App.java では、次の 2 つのクライアントを作成しました。
- SearchIndexClient は、インデックスを作成します。
- SearchClient は、既存のインデックスを読み込んでクエリを実行します。
どちらのクライアントにも、リソース情報に関するセクションで前述した検索サービス エンドポイントと資格情報が必要です。
このクイックスタートのサンプル コードでは、推奨されるキーレス認証に Microsoft Entra ID を使用します。 API キーを使用する場合は、DefaultAzureCredential オブジェクトを AzureKeyCredential オブジェクトに置き換えることができます。
String searchServiceEndpoint = "https://<Put your search service NAME here>.search.windows.net/";
DefaultAzureCredential credential = new DefaultAzureCredentialBuilder().build();
public static void main(String[] args) {
// Your search service endpoint
String searchServiceEndpoint = "https://<Put your search service NAME here>.search.windows.net/";
// Use the recommended keyless credential instead of the AzureKeyCredential credential.
DefaultAzureCredential credential = new DefaultAzureCredentialBuilder().build();
//AzureKeyCredential credential = new AzureKeyCredential("Your search service admin key");
// Create a SearchIndexClient to send create/delete index commands
SearchIndexClient searchIndexClient = new SearchIndexClientBuilder()
.endpoint(searchServiceEndpoint)
.credential(credential)
.buildClient();
// Create a SearchClient to load and query documents
String indexName = "hotels-quickstart-java";
SearchClient searchClient = new SearchClientBuilder()
.endpoint(searchServiceEndpoint)
.credential(credential)
.indexName(indexName)
.buildClient();
// Create Search Index for Hotel model
searchIndexClient.createOrUpdateIndex(
new SearchIndex(indexName, SearchIndexClient.buildSearchFields(Hotel.class, null))
.setSuggesters(new SearchSuggester("sg", Arrays.asList("HotelName"))));
// REDACTED FOR BREVITY . . .
}
インデックスを作成する
このクイックスタートでは、Hotels インデックスを作成し、それにホテル データを読み込んでクエリを実行します。 この手順では、インデックス内のフィールドを定義します。 それぞれのフィールドの定義には、名前とデータ型、属性が存在し、それらによってフィールドの使い方が決まります。
簡潔で読みやすくするために、この例では、"Azure.Search.Documents" ライブラリの同期メソッドを使用しています。 ただし運用環境のシナリオでは、アプリのスケーラビリティと応答性を確保するために非同期メソッドを使用する必要があります。 たとえば、CreateIndex ではなく CreateIndexAsync を使用します。
構造を定義する
2 つのヘルパー クラス (Hotel.java と Address.java) を作成して、ホテル ドキュメントとホテルの住所の構造を定義しました。 Hotel クラスには、ホテルの ID、名前、説明、カテゴリ、タグ、駐車場、改装日、評価、住所のフィールドが含まれます。 Address クラスには、番地、市区町村、都道府県、郵便番号、国/地域のフィールドが含まれます。
Azure.Search.Documents クライアント ライブラリでは、SearchableField と SimpleField を使用してフィールドの定義を効率化できます。
-
SimpleFieldは、任意のデータ型にすることができます。また、常に検索不可能であり (フルテキスト検索クエリでは無視されます)、取得可能です (非表示ではありません)。 その他の属性は、既定ではオフですが、有効にすることができます。 SimpleField は、フィルター、ファセット、スコアリング プロファイルでのみ使用されるフィールドやドキュメント ID での使用が考えられます。 その場合は必ず、シナリオに必要な属性を適用してください (ドキュメント ID の IsKey = true など)。 -
SearchableFieldは文字列であることが必要です。常に検索可能で、取得可能となります。 その他の属性は、既定ではオフですが、有効にすることができます。 検索可能なタイプのフィールドであるため、同意語がサポートされるほか、アナライザーのプロパティがすべてサポートされます。
基本 SearchField API を使用する場合も、そのいずれかのヘルパー モデルを使用する場合も、フィルター、ファセット、並べ替えの属性は明示的に有効にする必要があります。 たとえば、isFilterable、isSortable、isFacetable の各属性は、上のサンプルのように明示的に指定する必要があります。
検索インデックスの作成
App.java で、SearchIndex メソッドに main オブジェクトを作成し、createOrUpdateIndex メソッドを呼び出して検索サービスにインデックスを作成します。 インデックスには、指定されたフィールドでオートコンプリートを有効にするための SearchSuggester も含まれています。
// Create Search Index for Hotel model
searchIndexClient.createOrUpdateIndex(
new SearchIndex(indexName, SearchIndexClient.buildSearchFields(Hotel.class, null))
.setSuggesters(new SearchSuggester("sg", Arrays.asList("HotelName"))));
ドキュメントを読み込む
Azure AI Search は、サービスに保存されているコンテンツを検索します。 この手順では、作成したホテル インデックスに準拠する JSON ドキュメントを読み込みます。
Azure AI Search では、検索ドキュメントは、インデックス作成への入力とクエリからの出力の両方であるデータ構造です。 外部データ ソースから取得するドキュメント入力には、データベース内の行、Blob storage 内の BLOB、ディスク上の JSON ドキュメントがあります。 この例では、手短な方法として、4 つのホテルの JSON ドキュメントをコード自体に埋め込みます。
ドキュメントをアップロードするときは、IndexDocumentsBatch オブジェクトを使用する必要があります。
IndexDocumentsBatch オブジェクトには、 IndexActionsのコレクションが含まれており、それぞれにドキュメントと、実行するアクション (アップロード、マージ、削除、および mergeOrUpload) を Azure AI Search に伝えるプロパティが含まれています。
App.java で、ドキュメントとインデックス アクションを作成し、それらを IndexDocumentsBatch に渡します。 以下のドキュメントは、Hotel クラスで定義されている hotels-quickstart インデックスに準拠しています。
private static void uploadDocuments(SearchClient searchClient)
{
var hotelList = new ArrayList<Hotel>();
var hotel = new Hotel();
hotel.hotelId = "1";
hotel.hotelName = "Stay-Kay City Hotel";
hotel.description = "This classic hotel is fully-refurbished and ideally located on the main commercial artery of the city in the heart of New York. A few minutes away is Times Square and the historic centre of the city, as well as other places of interest that make New York one of America's most attractive and cosmopolitan cities.",
hotel.category = "Boutique";
hotel.tags = new String[] { "view", "air conditioning", "concierge" };
hotel.parkingIncluded = false;
hotel.lastRenovationDate = OffsetDateTime.of(LocalDateTime.of(LocalDate.of(2022, 1, 18), LocalTime.of(0, 0)), ZoneOffset.UTC);
hotel.rating = 3.6;
hotel.address = new Address();
hotel.address.streetAddress = "677 5th Ave";
hotel.address.city = "New York";
hotel.address.stateProvince = "NY";
hotel.address.postalCode = "10022";
hotel.address.country = "USA";
hotelList.add(hotel);
// REDACTED FOR BREVITY
var batch = new IndexDocumentsBatch<Hotel>();
batch.addMergeOrUploadActions(hotelList);
try
{
searchClient.indexDocuments(batch);
}
catch (Exception e)
{
e.printStackTrace();
// If for some reason any documents are dropped during indexing, you can compensate by delaying and
// retrying. This simple demo just logs failure and continues
System.err.println("Failed to index some of the documents");
}
}
IndexDocumentsBatch オブジェクトは、初期化した後、 オブジェクトに対して SearchClient を呼び出すことでインデックスに送信できます。
main() で SearchClient を使用してドキュメントを読み込みますが、この操作には、サービスに対する管理者権限も必要になります。この権限は通常、SearchIndexClient に関連付けられています。 この操作を設定する 1 つの方法は、SearchIndexClient (この例ではsearchIndexClient) を使用して SearchClient を取得することです。
uploadDocuments(searchClient);
すべてのコマンドを順番に実行するコンソール アプリがあるため、インデックス作成とクエリの間に 2 秒の待機時間を追加します。
// Wait 2 seconds for indexing to complete before starting queries (for demo and console-app purposes only)
System.out.println("Waiting for indexing...\n");
try
{
Thread.sleep(2000);
}
catch (InterruptedException e)
{
}
2 秒の遅延により、非同期のインデックス作成を待ち、クエリの実行前にすべてのドキュメントのインデックスを作成できるようにしています。 通常、遅延のコーディングは、デモ、テスト、およびサンプル アプリケーションでのみ必要です。
インデックスを検索する
最初のドキュメントのインデックスが作成されるとすぐにクエリの結果を取得できますが、インデックスの実際のテストではすべてのドキュメントのインデックスが作成されるまで待つ必要があります。
このセクションでは、2 つの機能 (クエリ ロジックと結果) を追加します。 クエリには、Search メソッドを使用します。 このメソッドは、検索テキスト (クエリ文字列) と他のオプションを受け取ります。
App.java 内の WriteDocuments メソッドは、検索結果をコンソールに出力します。
// Write search results to console
private static void WriteSearchResults(SearchPagedIterable searchResults)
{
searchResults.iterator().forEachRemaining(result ->
{
Hotel hotel = result.getDocument(Hotel.class);
System.out.println(hotel);
});
System.out.println();
}
// Write autocomplete results to console
private static void WriteAutocompleteResults(AutocompletePagedIterable autocompleteResults)
{
autocompleteResults.iterator().forEachRemaining(result ->
{
String text = result.getText();
System.out.println(text);
});
System.out.println();
}
クエリの例 1
RunQueries メソッドは、クエリを実行して結果を返します。 結果は、Hotel オブジェクトです。 このサンプルは、メソッド シグネチャと最初のクエリを示しています。 このクエリは、ドキュメントから選択されたフィールドを使用して結果を作成できる Select パラメーターを示しています。
// Run queries, use WriteDocuments to print output
private static void RunQueries(SearchClient searchClient)
{
// Query 1
System.out.println("Query #1: Search on empty term '*' to return all documents, showing a subset of fields...\n");
SearchOptions options = new SearchOptions();
options.setIncludeTotalCount(true);
options.setFilter("");
options.setOrderBy("");
options.setSelect("HotelId", "HotelName", "Address/City");
WriteSearchResults(searchClient.search("*", options, Context.NONE));
}
クエリの例 2
2 つ目のクエリでは、語句を検索し、Rating が 4 を超えるドキュメントを選択するフィルターを追加したうえで、"Rating" の降順で並べ替えます。 フィルターは、インデックス内の isFilterable フィールドに対して評価されるブール式です。 フィルター クエリでは、値は包含されるか除外されるかのどちらかです。 そのため、フィルター クエリに関連付けられている関連性スコアはありません。
// Query 2
System.out.println("Query #2: Search on 'hotels', filter on 'Rating gt 4', sort by Rating in descending order...\n");
options = new SearchOptions();
options.setFilter("Rating gt 4");
options.setOrderBy("Rating desc");
options.setSelect("HotelId", "HotelName", "Rating");
WriteSearchResults(searchClient.search("hotels", options, Context.NONE));
クエリの例 3
3 番目のクエリは、フルテキスト検索操作の範囲を特定のフィールドに設定するために使用する searchFields を示しています。
// Query 3
System.out.println("Query #3: Limit search to specific fields (pool in Tags field)...\n");
options = new SearchOptions();
options.setSearchFields("Tags");
options.setSelect("HotelId", "HotelName", "Tags");
WriteSearchResults(searchClient.search("pool", options, Context.NONE));
クエリの例 4
4 番目のクエリは、ファセット ナビゲーション構造を構築するために使用できる facets を示しています。
// Query 4
System.out.println("Query #4: Facet on 'Category'...\n");
options = new SearchOptions();
options.setFilter("");
options.setFacets("Category");
options.setSelect("HotelId", "HotelName", "Category");
WriteSearchResults(searchClient.search("*", options, Context.NONE));
クエリの例 5
5 番目のクエリでは、特定のドキュメントを返します。
// Query 5
System.out.println("Query #5: Look up a specific document...\n");
Hotel lookupResponse = searchClient.getDocument("3", Hotel.class);
System.out.println(lookupResponse.hotelId);
System.out.println();
クエリの例 6
最後のクエリは、オートコンプリートの構文を示しています。これは、インデックスで定義した suggester に関連付けられている の 2 つの一致候補に解決される、"s" という部分的なユーザー入力をシミュレートしています。sourceFields
// Query 6
System.out.println("Query #6: Call Autocomplete on HotelName that starts with 's'...\n");
WriteAutocompleteResults(searchClient.autocomplete("s", "sg"));
クエリの概要
上記のクエリは、クエリで語句を照合する複数の方法 (フルテキスト検索、フィルター、オートコンプリート) を示しています。
フルテキスト検索とフィルターは、SearchClient.search メソッドを使用して実行されます。 検索クエリは searchText 文字列で渡すことができます。一方、フィルター式は filter クラスの プロパティで渡すことができます。 検索せずにフィルター処理を実行するには、searchText メソッドの search パラメーターに "*" を渡します。 フィルター処理を行わずに検索するには、filter プロパティを未設定のままにするか、SearchOptions インスタンスを 1 つも渡さないようにします。
このクイック スタートでは、Azure.Search.Documents クライアント ライブラリを使用して、フルテキスト検索用のサンプル データを使用して検索インデックスを作成、読み込み、 クエリを実行します。 フルテキスト検索では、インデックス作成とクエリに Apache Lucene を使用し、結果をスコア付けするための BM25 ランク付けアルゴリズムを使用します。
このクイック スタートでは、 azure-search-sample-data リポジトリの架空のホテル データを使用してインデックスを設定します。
ヒント
完成したプロジェクトから開始する ソース コード をダウンロードするか、次の手順に従って独自のプロジェクトを作成できます。
前提条件
アクティブなサブスクリプションを持つ Azure アカウント。 無料でアカウントを作成できます。
Azure AI Search Service。 まだ作成していない場合、サービスを作成します。 このクイック スタートでは、無料サービスを使用できます。
Microsoft Entra ID の前提条件
Microsoft Entra ID を使用して推奨されるキーレス認証を行うには、次の手順を実行する必要があります。
Azure CLI をインストールします。
ユーザー アカウントに
Search Service ContributorロールとSearch Index Data Contributorロールを割り当てます。 Azure portal の [アクセス制御 (IAM)]>[ロールの割り当ての追加] で、ロールを割り当てることができます。 詳細については、「ロールを使用して Azure AI 検索に接続する」を参照してください。
リソース情報の取得
Azure AI 検索サービスでアプリケーションを認証するには、次の情報を取得する必要があります。
| 変数名 | 値 |
|---|---|
SEARCH_API_ENDPOINT |
この値は、Azure portal で確認できます。 検索サービスを選択し、左側のメニューから [概要] を選択します。
[基本] の下の [URL] は、必要なエンドポイントです。 たとえば、エンドポイントは https://mydemo.search.windows.net のようになります。 |
設定
アプリケーションを含める新しいフォルダー
full-text-quickstartを作成し、次のコマンドを使用してそのフォルダー内で Visual Studio Code を開きます。mkdir full-text-quickstart && cd full-text-quickstart次のコマンドで
package.jsonを作成します。npm init -y次のコマンドを使用して、JavaScript 用の Azure AI 検索クライアント ライブラリ (Azure.Search.Documents) をインストールします。
npm install @azure/search-documents推奨されるパスワードレス認証の場合、次のコマンドを使用して Azure ID クライアント ライブラリをインストールします。
npm install @azure/identity
検索インデックスの作成、読み込み、クエリの実行
前の「設定」セクションで、Azure AI 検索クライアント ライブラリとその他の依存関係をインストールしました。
このセクションでは、検索インデックスを作成し、それにドキュメントを読み込んで、クエリを実行するコードを追加します。 プログラムを実行して、結果をコンソールに表示します。 コードの詳細な説明については、「コードの説明」セクションを参照してください。
このクイックスタートのサンプル コードでは、推奨されるキーレス認証に Microsoft Entra ID を使用します。 API キーを使用する場合は、DefaultAzureCredential オブジェクトを AzureKeyCredential オブジェクトに置き換えることができます。
String searchServiceEndpoint = "https://<Put your search service NAME here>.search.windows.net/";
DefaultAzureCredential credential = new DefaultAzureCredentialBuilder().build();
index.js という名前の新しいファイルを作成し、次のコードを index.js に貼り付けます。
// Import from the @azure/search-documents library import { SearchIndexClient, odata } from "@azure/search-documents"; // Import from the Azure Identity library import { DefaultAzureCredential } from "@azure/identity"; // Importing the hotels sample data import hotelData from './hotels.json' assert { type: "json" }; // Load the .env file if it exists import * as dotenv from "dotenv"; dotenv.config(); // Defining the index definition const indexDefinition = { "name": "hotels-quickstart", "fields": [ { "name": "HotelId", "type": "Edm.String", "key": true, "filterable": true }, { "name": "HotelName", "type": "Edm.String", "searchable": true, "filterable": false, "sortable": true, "facetable": false }, { "name": "Description", "type": "Edm.String", "searchable": true, "filterable": false, "sortable": false, "facetable": false, "analyzerName": "en.lucene" }, { "name": "Description_fr", "type": "Edm.String", "searchable": true, "filterable": false, "sortable": false, "facetable": false, "analyzerName": "fr.lucene" }, { "name": "Category", "type": "Edm.String", "searchable": true, "filterable": true, "sortable": true, "facetable": true }, { "name": "Tags", "type": "Collection(Edm.String)", "searchable": true, "filterable": true, "sortable": false, "facetable": true }, { "name": "ParkingIncluded", "type": "Edm.Boolean", "filterable": true, "sortable": true, "facetable": true }, { "name": "LastRenovationDate", "type": "Edm.DateTimeOffset", "filterable": true, "sortable": true, "facetable": true }, { "name": "Rating", "type": "Edm.Double", "filterable": true, "sortable": true, "facetable": true }, { "name": "Address", "type": "Edm.ComplexType", "fields": [ { "name": "StreetAddress", "type": "Edm.String", "filterable": false, "sortable": false, "facetable": false, "searchable": true }, { "name": "City", "type": "Edm.String", "searchable": true, "filterable": true, "sortable": true, "facetable": true }, { "name": "StateProvince", "type": "Edm.String", "searchable": true, "filterable": true, "sortable": true, "facetable": true }, { "name": "PostalCode", "type": "Edm.String", "searchable": true, "filterable": true, "sortable": true, "facetable": true }, { "name": "Country", "type": "Edm.String", "searchable": true, "filterable": true, "sortable": true, "facetable": true } ] } ], "suggesters": [ { "name": "sg", "searchMode": "analyzingInfixMatching", "sourceFields": [ "HotelName" ] } ] }; async function main() { // Your search service endpoint const searchServiceEndpoint = "https://<Put your search service NAME here>.search.windows.net/"; // Use the recommended keyless credential instead of the AzureKeyCredential credential. const credential = new DefaultAzureCredential(); //const credential = new AzureKeyCredential(Your search service admin key); // Create a SearchIndexClient to send create/delete index commands const searchIndexClient = new SearchIndexClient(searchServiceEndpoint, credential); // Creating a search client to upload documents and issue queries const indexName = "hotels-quickstart"; const searchClient = searchIndexClient.getSearchClient(indexName); console.log('Checking if index exists...'); await deleteIndexIfExists(searchIndexClient, indexName); console.log('Creating index...'); let index = await searchIndexClient.createIndex(indexDefinition); console.log(`Index named ${index.name} has been created.`); console.log('Uploading documents...'); let indexDocumentsResult = await searchClient.mergeOrUploadDocuments(hotelData['value']); console.log(`Index operations succeeded: ${JSON.stringify(indexDocumentsResult.results[0].succeeded)} `); // waiting one second for indexing to complete (for demo purposes only) sleep(1000); console.log('Querying the index...'); console.log(); await sendQueries(searchClient); } async function deleteIndexIfExists(searchIndexClient, indexName) { try { await searchIndexClient.deleteIndex(indexName); console.log('Deleting index...'); } catch { console.log('Index does not exist yet.'); } } async function sendQueries(searchClient) { // Query 1 console.log('Query #1 - search everything:'); let searchOptions = { includeTotalCount: true, select: ["HotelId", "HotelName", "Rating"] }; let searchResults = await searchClient.search("*", searchOptions); for await (const result of searchResults.results) { console.log(`${JSON.stringify(result.document)}`); } console.log(`Result count: ${searchResults.count}`); console.log(); // Query 2 console.log('Query #2 - search with filter, orderBy, and select:'); let state = 'FL'; searchOptions = { filter: odata `Address/StateProvince eq ${state}`, orderBy: ["Rating desc"], select: ["HotelId", "HotelName", "Rating"] }; searchResults = await searchClient.search("wifi", searchOptions); for await (const result of searchResults.results) { console.log(`${JSON.stringify(result.document)}`); } console.log(); // Query 3 console.log('Query #3 - limit searchFields:'); searchOptions = { select: ["HotelId", "HotelName", "Rating"], searchFields: ["HotelName"] }; searchResults = await searchClient.search("sublime palace", searchOptions); for await (const result of searchResults.results) { console.log(`${JSON.stringify(result.document)}`); } console.log(); // Query 4 console.log('Query #4 - limit searchFields and use facets:'); searchOptions = { facets: ["Category"], select: ["HotelId", "HotelName", "Rating"], searchFields: ["HotelName"] }; searchResults = await searchClient.search("*", searchOptions); for await (const result of searchResults.results) { console.log(`${JSON.stringify(result.document)}`); } console.log(); // Query 5 console.log('Query #5 - Lookup document:'); let documentResult = await searchClient.getDocument('3'); console.log(`HotelId: ${documentResult.HotelId}; HotelName: ${documentResult.HotelName}`); console.log(); } function sleep(ms) { return new Promise(resolve => setTimeout(resolve, ms)); } main().catch((err) => { console.error("The sample encountered an error:", err); });hotels.json という名前のファイルを作成し、次のコードを hotels.json に貼り付けます。
{ "value": [ { "HotelId": "1", "HotelName": "Stay-Kay City Hotel", "Description": "This classic hotel is fully-refurbished and ideally located on the main commercial artery of the city in the heart of New York. A few minutes away is Times Square and the historic centre of the city, as well as other places of interest that make New York one of America's most attractive and cosmopolitan cities.", "Category": "Boutique", "Tags": ["view", "air conditioning", "concierge"], "ParkingIncluded": false, "LastRenovationDate": "2022-01-18T00:00:00Z", "Rating": 3.6, "Address": { "StreetAddress": "677 5th Ave", "City": "New York", "StateProvince": "NY", "PostalCode": "10022" } }, { "HotelId": "2", "HotelName": "Old Century Hotel", "Description": "The hotel is situated in a nineteenth century plaza, which has been expanded and renovated to the highest architectural standards to create a modern, functional and first-class hotel in which art and unique historical elements coexist with the most modern comforts. The hotel also regularly hosts events like wine tastings, beer dinners, and live music.", "Category": "Boutique", "Tags": ["pool", "free wifi", "concierge"], "ParkingIncluded": "false", "LastRenovationDate": "2019-02-18T00:00:00Z", "Rating": 3.6, "Address": { "StreetAddress": "140 University Town Center Dr", "City": "Sarasota", "StateProvince": "FL", "PostalCode": "34243" } }, { "HotelId": "3", "HotelName": "Gastronomic Landscape Hotel", "Description": "The Gastronomic Hotel stands out for its culinary excellence under the management of William Dough, who advises on and oversees all of the Hotel’s restaurant services.", "Category": "Suite", "Tags": ["restaurant", "bar", "continental breakfast"], "ParkingIncluded": "true", "LastRenovationDate": "2015-09-20T00:00:00Z", "Rating": 4.8, "Address": { "StreetAddress": "3393 Peachtree Rd", "City": "Atlanta", "StateProvince": "GA", "PostalCode": "30326" } }, { "HotelId": "4", "HotelName": "Sublime Palace Hotel", "Description": "Sublime Palace Hotel is located in the heart of the historic center of Sublime in an extremely vibrant and lively area within short walking distance to the sites and landmarks of the city and is surrounded by the extraordinary beauty of churches, buildings, shops and monuments. Sublime Cliff is part of a lovingly restored 19th century resort, updated for every modern convenience.", "Category": "Boutique", "Tags": ["concierge", "view", "air conditioning"], "ParkingIncluded": true, "LastRenovationDate": "2020-02-06T00:00:00Z", "Rating": 4.6, "Address": { "StreetAddress": "7400 San Pedro Ave", "City": "San Antonio", "StateProvince": "TX", "PostalCode": "78216" } } ] }hotels_quickstart_index.json という名前のファイルを作成し、次のコードを hotels_quickstart_index.json に貼り付けます。
{ "name": "hotels-quickstart", "fields": [ { "name": "HotelId", "type": "Edm.String", "key": true, "filterable": true }, { "name": "HotelName", "type": "Edm.String", "searchable": true, "filterable": false, "sortable": true, "facetable": false }, { "name": "Description", "type": "Edm.String", "searchable": true, "filterable": false, "sortable": false, "facetable": false, "analyzerName": "en.lucene" }, { "name": "Category", "type": "Edm.String", "searchable": true, "filterable": true, "sortable": true, "facetable": true }, { "name": "Tags", "type": "Collection(Edm.String)", "searchable": true, "filterable": true, "sortable": false, "facetable": true }, { "name": "ParkingIncluded", "type": "Edm.Boolean", "filterable": true, "sortable": true, "facetable": true }, { "name": "LastRenovationDate", "type": "Edm.DateTimeOffset", "filterable": true, "sortable": true, "facetable": true }, { "name": "Rating", "type": "Edm.Double", "filterable": true, "sortable": true, "facetable": true }, { "name": "Address", "type": "Edm.ComplexType", "fields": [ { "name": "StreetAddress", "type": "Edm.String", "filterable": false, "sortable": false, "facetable": false, "searchable": true }, { "name": "City", "type": "Edm.String", "searchable": true, "filterable": true, "sortable": true, "facetable": true }, { "name": "StateProvince", "type": "Edm.String", "searchable": true, "filterable": true, "sortable": true, "facetable": true }, { "name": "PostalCode", "type": "Edm.String", "searchable": true, "filterable": true, "sortable": true, "facetable": true }, { "name": "Country", "type": "Edm.String", "searchable": true, "filterable": true, "sortable": true, "facetable": true } ] } ], "suggesters": [ { "name": "sg", "searchMode": "analyzingInfixMatching", "sourceFields": [ "HotelName" ] } ] }次のコマンドを使用して Azure にサインインします。
az login次のコマンドを使用して、JavaScript コードを実行します。
node index.js
コードの説明
インデックスを作成する
hotels_quickstart_index.json ファイルは、次の手順で読み込むドキュメントに対して Azure AI 検索がどのように機能するかを定義します。 各フィールドは name によって識別され、type が指定されています。 各フィールドには、Azure AI Search がフィールドで検索、フィルター処理、並べ替え、ファセットを実行できるかどうかを指定する一連のインデックス属性もあります。 ほとんどのフィールドは単純なデータ型ですが、AddressType のように、自分のインデックスでリッチなデータ構造を作成できる複合型もあります。
サポートされているデータ型とインデックスの属性について詳しくは、インデックスの作成 (REST) に関するページを参照してください。
インデックスの定義が完了したら、main 関数でインデックスの定義にアクセスできるように、index.js の冒頭で hotels_quickstart_index.json をインポートする必要があります。
const indexDefinition = require('./hotels_quickstart_index.json');
main 関数内で、 SearchIndexClientを作成します。これは、Azure AI Search のインデックスの作成と管理に使用されます。
const indexClient = new SearchIndexClient(endpoint, new AzureKeyCredential(apiKey));
次に、インデックスが既に存在する場合はそれを削除します。 この操作は、テストやデモのコードでは一般的な手法です。
これを行うには、インデックスの削除を試行する単純な関数を定義します。
async function deleteIndexIfExists(indexClient, indexName) {
try {
await indexClient.deleteIndex(indexName);
console.log('Deleting index...');
} catch {
console.log('Index does not exist yet.');
}
}
関数を実行するには、インデックス定義からインデックス名を抽出し、indexName と共に indexClient を deleteIndexIfExists() 関数に渡します。
const indexName = indexDefinition["name"];
console.log('Checking if index exists...');
await deleteIndexIfExists(indexClient, indexName);
その後、createIndex() メソッドを使用してインデックスを作成する準備が整います。
console.log('Creating index...');
let index = await indexClient.createIndex(indexDefinition);
console.log(`Index named ${index.name} has been created.`);
ドキュメントを読み込む
Azure AI Search では、ドキュメントはインデックス作成への入力とクエリからの出力の両方であるデータ構造です。 このようなデータをインデックスにプッシュするか、インデクサーを使用することができます。 この場合は、プログラムによってドキュメントをインデックスにプッシュします。
ドキュメント入力には、データベース内の行、Blob Storage 内の BLOB、またはこの例のようなディスク上の JSON ドキュメントがあります。
indexDefinition で行ったのと同様に、main 関数でデータにアクセスできるように、"index.js" の冒頭で hotels.json をインポートする必要もあります。
const hotelData = require('./hotels.json');
データに検索インデックスを付けるために、次は SearchClient を作成する必要があります。
SearchIndexClient はインデックスの作成と管理に使用され、SearchClient はドキュメントのアップロードとインデックスのクエリに使用されます。
SearchClient は 2 とおりの方法で作成できます。 1 つには、ゼロから SearchClient を作成する方法があります。
const searchClient = new SearchClient(endpoint, indexName, new AzureKeyCredential(apiKey));
または、getSearchClient() の SearchIndexClient メソッドを使用して SearchClient を作成することもできます。
const searchClient = indexClient.getSearchClient(indexName);
クライアントが定義できたところで、ドキュメントを検索インデックスにアップロードします。 ここでは mergeOrUploadDocuments() メソッドを使用します。これにより、ドキュメントをアップロードしたり、同じキーのドキュメントが既に存在する場合に既存のドキュメントとマージしたりします。
console.log('Uploading documents...');
let indexDocumentsResult = await searchClient.mergeOrUploadDocuments(hotelData['value']);
console.log(`Index operations succeeded: ${JSON.stringify(indexDocumentsResult.results[0].succeeded)}`);
インデックスを検索する
インデックスを作成し、ドキュメントをアップロードしたところで、クエリをインデックスに送信する準備が整いました。 このセクションでは、5 つの異なるクエリを検索インデックスに送信して、利用可能なさまざまなクエリ機能について説明します。
クエリは sendQueries() 関数で記述されます。それを、次のとおり main 関数で呼び出します。
await sendQueries(searchClient);
クエリは search() の searchClient メソッドを使用して送信されます。 1 つ目のパラメーターは検索テキストで、2 つ目のパラメーターは検索オプションを指定します。
クエリの例 1
最初のクエリでは * を検索します。これはすべてを検索することと同じで、インデックス内のフィールドのうち 3 つが選択されます。 不要なデータをプルするとクエリでの待ち時間が長くなる可能性があるため、必要なフィールドのみ select することをお勧めします。
このクエリの searchOptions は、includeTotalCount も true に設定されています。これにより、一致した結果の数が検出されて返されます。
async function sendQueries(searchClient) {
console.log('Query #1 - search everything:');
let searchOptions = {
includeTotalCount: true,
select: ["HotelId", "HotelName", "Rating"]
};
let searchResults = await searchClient.search("*", searchOptions);
for await (const result of searchResults.results) {
console.log(`${JSON.stringify(result.document)}`);
}
console.log(`Result count: ${searchResults.count}`);
// remaining queries go here
}
以下で説明する残りのクエリも sendQueries() 関数に追加する必要があります。 ここでは読みやすいようにそれらを区切ってあります。
クエリの例 2
次のクエリでは、検索用語 "wifi" を指定します。また、状態が 'FL' と一致する結果のみが返されるようにフィルターも含めます。 さらに結果はホテルの Rating の順に並べられます。
console.log('Query #2 - Search with filter, orderBy, and select:');
let state = 'FL';
searchOptions = {
filter: odata`Address/StateProvince eq ${state}`,
orderBy: ["Rating desc"],
select: ["HotelId", "HotelName", "Rating"]
};
searchResults = await searchClient.search("wifi", searchOptions);
for await (const result of searchResults.results) {
console.log(`${JSON.stringify(result.document)}`);
}
クエリの例 3
次に、searchFields パラメーターを使用して検索が単一の検索可能なフィールドに制限されます。 この方法は、特定のフィールドとの一致にのみ関心があることがわかっている場合にクエリを効率化できる優れたオプションです。
console.log('Query #3 - Limit searchFields:');
searchOptions = {
select: ["HotelId", "HotelName", "Rating"],
searchFields: ["HotelName"]
};
searchResults = await searchClient.search("Sublime Palace", searchOptions);
for await (const result of searchResults.results) {
console.log(`${JSON.stringify(result.document)}`);
}
console.log();
クエリの例 4
クエリによく含められるもう 1 つのオプションは、facets です。 ファセットを使用すると、UI 上でフィルターを構築できます。そうすることで、ユーザーがどの値をフィルターで絞り込めるかを簡単に把握できるようになります。
console.log('Query #4 - Use facets:');
searchOptions = {
facets: ["Category"],
select: ["HotelId", "HotelName", "Rating"],
searchFields: ["HotelName"]
};
searchResults = await searchClient.search("*", searchOptions);
for await (const result of searchResults.results) {
console.log(`${JSON.stringify(result.document)}`);
}
クエリの例 5
最後のクエリでは、getDocument() の searchClient メソッドを使用します。 これにより、そのキーでドキュメントを効率的に取得できます。
console.log('Query #5 - Lookup document:');
let documentResult = await searchClient.getDocument(key='3')
console.log(`HotelId: ${documentResult.HotelId}; HotelName: ${documentResult.HotelName}`)
クエリの概要
上記のクエリは、クエリで語句を照合する複数の方法 (フルテキスト検索、フィルター、オートコンプリート) を示しています。
フルテキスト検索とフィルターを実行するには、searchClient.search メソッドを使用します。 検索クエリは searchText 文字列で渡すことができます。一方、フィルター式は filter クラスの SearchOptions プロパティで渡すことができます。 検索せずにフィルター処理を実行するには、searchText メソッドの search パラメーターに "*" を渡します。 フィルター処理を行わずに検索するには、filter プロパティを未設定のままにするか、SearchOptions インスタンスを 1 つも渡さないようにします。
このクイック スタートでは、PowerShell と Azure AI Search REST API を 使用して、 フルテキスト検索用の検索インデックスを作成、読み込み、クエリを実行します。 フルテキスト検索では、インデックス作成とクエリに Apache Lucene を使用し、結果をスコア付けするための BM25 ランク付けアルゴリズムを使用します。
このクイック スタートでは、 azure-search-sample-data リポジトリの架空のホテル データを使用してインデックスを設定します。
ヒント
完成したプロジェクトから開始する ソース コード をダウンロードするか、次の手順に従って独自のプロジェクトを作成できます。
前提条件
アクティブなサブスクリプションを持つ Azure アカウント。 無料でアカウントを作成できます。
Azure AI Search Service。 サービスを作成 するか 、現在の サブスクリプションで既存のサービスを検索します。 このクイック スタートでは、無料サービスを使用できます。
Microsoft Entra ID を使用したキーレス認証用 の Azure CLI 。
PowerShell 7.3 以降。 このクイック スタートでは 、Invoke-RestMethod を使用して REST API 呼び出しを行います。
アクセスを構成する
ロールの割り当てで API キーまたは Microsoft Entra ID を使用して、Azure AI Search サービスに接続できます。 キーの方が簡単に使い始めることができますが、安全性が高いのはロールの方です。
推奨されるロールベースのアクセスを構成するには:
Azure portal にサインインし、検索サービスを選択します。
次に、左側のペインで [設定]>[キー] を選択します。
[API アクセス制御] で、[両方] を選択します。
このオプションでは、キーベース認証とキーレス認証の両方が有効になります。 ロールを割り当てた後、この手順に戻り、[ ロールベースのアクセス制御] を選択できます。
左側のウィンドウで、[ アクセス制御 (IAM)] を選択します。
[追加>][ロール割り当ての追加] の順に選択します。
Search Service 共同作成者ロールと検索インデックス データ共同作成者ロールをユーザー アカウントに割り当てます。
詳細については、「ロールを使用して Azure AI 検索に接続する」を参照してください。
エンドポイントを取得する
次のセクションでは、次のエンドポイントを指定して、Azure AI Search サービスへの接続を確立します。 これらの手順では、 ロールベースのアクセスを構成していることを前提としています。
サービス エンドポイントを取得するには:
Azure portal にサインインし、検索サービスを選択します。
左側のウィンドウで、[ 概要] を選択します。
URL を書き留めます。これは、
https://my-service.search.windows.netのようになります。
Azure AI Search に接続する
Azure AI Search サービスに対して REST API 呼び出しを行うには、事前に認証してサービスに接続する必要があります。 PowerShell では、手順 2 と 3 で使用される Azure CLI コマンドをサポートする次の手順を実行します。
検索サービスに接続するには:
ローカル システムで、PowerShell を開きます。
Azure サブスクリプションにサインインします。 複数のサブスクリプションがある場合は、検索サービスを含むサブスクリプションを選択します。
az loginアクセス トークンを格納する
$tokenオブジェクトを作成します。$token = az account get-access-token --resource https://search.azure.com/ --query accessToken --output tsvトークンとコンテンツ タイプを格納する
$headersオブジェクトを作成します。$headers = @{ 'Authorization' = "Bearer $token" 'Content-Type' = 'application/json' 'Accept' = 'application/json' }ヘッダーはセッションごとに 1 回だけ設定する必要がありますが、各要求に追加する必要があります。
検索サービスのインデックス コレクションを対象とする
$urlオブジェクトを作成します。<YOUR-SEARCH-SERVICE>を、Get エンドポイントで取得した値に置き換えます。$url = "<YOUR-SEARCH-SERVICE>/indexes?api-version=2024-07-01&`$select=name"Invoke-RestMethodを実行して、検索サービスに GET 要求を送信します。ConvertTo-Jsonを含め、サービスからの応答を表示します。Invoke-RestMethod -Uri $url -Headers $headers | ConvertTo-Jsonサービスが空でインデックスがない場合、応答は次の例のようになります。 それ以外の場合は、インデックス定義の JSON 表現が表示されます。
{ "@odata.context": "https://my-service.search.windows.net/$metadata#indexes", "value": [ ] }
検索インデックスを作成する
Azure AI Search にコンテンツを追加する前に、コンテンツの格納方法と構造化方法を定義するインデックスを作成する必要があります。 インデックスは概念的にはリレーショナル データベースのテーブルに似ていますが、フルテキスト検索などの検索操作用に特別に設計されています。
前のセクションで開始したのと同じ PowerShell セッションで、次のコマンドを実行します。
インデックスを作成するには:
インデックス スキーマを定義する
$bodyオブジェクトを作成します。$body = @" { "name": "hotels-quickstart", "fields": [ {"name": "HotelId", "type": "Edm.String", "key": true, "filterable": true}, {"name": "HotelName", "type": "Edm.String", "searchable": true, "filterable": false, "sortable": true, "facetable": false}, {"name": "Description", "type": "Edm.String", "searchable": true, "filterable": false, "sortable": false, "facetable": false, "analyzer": "en.lucene"}, {"name": "Category", "type": "Edm.String", "searchable": true, "filterable": true, "sortable": true, "facetable": true}, {"name": "Tags", "type": "Collection(Edm.String)", "searchable": true, "filterable": true, "sortable": false, "facetable": true}, {"name": "ParkingIncluded", "type": "Edm.Boolean", "filterable": true, "sortable": true, "facetable": true}, {"name": "LastRenovationDate", "type": "Edm.DateTimeOffset", "filterable": true, "sortable": true, "facetable": true}, {"name": "Rating", "type": "Edm.Double", "filterable": true, "sortable": true, "facetable": true}, {"name": "Address", "type": "Edm.ComplexType", "fields": [ {"name": "StreetAddress", "type": "Edm.String", "filterable": false, "sortable": false, "facetable": false, "searchable": true}, {"name": "City", "type": "Edm.String", "searchable": true, "filterable": true, "sortable": true, "facetable": true}, {"name": "StateProvince", "type": "Edm.String", "searchable": true, "filterable": true, "sortable": true, "facetable": true}, {"name": "PostalCode", "type": "Edm.String", "searchable": true, "filterable": true, "sortable": true, "facetable": true}, {"name": "Country", "type": "Edm.String", "searchable": true, "filterable": true, "sortable": true, "facetable": true} ] } ] } "@$urlオブジェクトを更新して、新しいインデックスをターゲットにします。<YOUR-SEARCH-SERVICE>を Get エンドポイント で取得した値に置き換えてください。$url = "<YOUR-SEARCH-SERVICE>/indexes/hotels-quickstart?api-version=2024-07-01"Invoke-RestMethodを実行して、検索サービスにインデックスを作成します。Invoke-RestMethod -Uri $url -Headers $headers -Method Put -Body $body | ConvertTo-Json応答には、インデックス スキーマの JSON 表現が含まれている必要があります。
インデックス作成要求について
このクイック スタートでは 、Indexes - Create (REST API) を呼び出して、 hotels-quickstart という名前の検索インデックスとその物理データ構造を検索サービスに構築します。
インデックス スキーマ内では、 fields コレクションによってホテル ドキュメントの構造が定義されます。 各フィールドには、インデックス作成とクエリ中の動作を決定する name、データ type、および属性があります。
HotelId フィールドはキーとしてマークされ、Azure AI Search ではインデックス内の各ドキュメントを一意に識別する必要があります。
インデックス スキーマに関する重要なポイント:
文字列フィールド (
Edm.String) を使用して、数値データのフルテキスト検索を可能にします。Edm.Int32など、サポートされているその他のデータ型は、フィルター可能、並べ替え可能、ファセット可能、および取得可能ですが、検索できません。ほとんどのフィールドは単純なデータ型ですが、
Addressフィールドなど、入れ子になったデータを表す複合型を定義できます。フィールド属性は、許可されるアクションを決定します。 REST API では、多くのアクションが既定で使用できます。 たとえば、すべての文字列は検索可能で取得可能です。 REST API では、動作を無効にする必要がある場合にのみ属性を使用できます。
インデックスを読み込む
新しく作成されたインデックスは空です。 インデックスを設定して検索できるようにするには、インデックス スキーマに準拠する JSON ドキュメントをアップロードする必要があります。
Azure AI Search では、ドキュメントはインデックス作成の入力とクエリの出力の両方として機能します。 わかりやすくするために、このクイック スタートでは、サンプルのホテル ドキュメントをインライン JSON として提供します。 ただし、運用環境のシナリオでは、多くの場合、コンテンツは接続されたデータ ソースからプルされ、 インデクサーを使用して JSON に変換されます。
ドキュメントをインデックスにアップロードするには:
4 つのサンプル ドキュメントの JSON ペイロードを格納する
$bodyオブジェクトを作成します。$body = @" { "value": [ { "@search.action": "upload", "HotelId": "1", "HotelName": "Stay-Kay City Hotel", "Description": "This classic hotel is fully-refurbished and ideally located on the main commercial artery of the city in the heart of New York. A few minutes away is Times Square and the historic centre of the city, as well as other places of interest that make New York one of America's most attractive and cosmopolitan cities.", "Category": "Boutique", "Tags": [ "view", "air conditioning", "concierge" ], "ParkingIncluded": false, "LastRenovationDate": "2022-01-18T00:00:00Z", "Rating": 3.60, "Address": { "StreetAddress": "677 5th Ave", "City": "New York", "StateProvince": "NY", "PostalCode": "10022", "Country": "USA" } }, { "@search.action": "upload", "HotelId": "2", "HotelName": "Old Century Hotel", "Description": "The hotel is situated in a nineteenth century plaza, which has been expanded and renovated to the highest architectural standards to create a modern, functional and first-class hotel in which art and unique historical elements coexist with the most modern comforts. The hotel also regularly hosts events like wine tastings, beer dinners, and live music.", "Category": "Boutique", "Tags": [ "pool", "free wifi", "concierge" ], "ParkingIncluded": false, "LastRenovationDate": "2019-02-18T00:00:00Z", "Rating": 3.60, "Address": { "StreetAddress": "140 University Town Center Dr", "City": "Sarasota", "StateProvince": "FL", "PostalCode": "34243", "Country": "USA" } }, { "@search.action": "upload", "HotelId": "3", "HotelName": "Gastronomic Landscape Hotel", "Description": "The Gastronomic Hotel stands out for its culinary excellence under the management of William Dough, who advises on and oversees all of the Hotel’s restaurant services.", "Category": "Suite", "Tags": [ "restaurant", "bar", "continental breakfast" ], "ParkingIncluded": true, "LastRenovationDate": "2015-09-20T00:00:00Z", "Rating": 4.80, "Address": { "StreetAddress": "3393 Peachtree Rd", "City": "Atlanta", "StateProvince": "GA", "PostalCode": "30326", "Country": "USA" } }, { "@search.action": "upload", "HotelId": "4", "HotelName": "Sublime Palace Hotel", "Description": "Sublime Palace Hotel is located in the heart of the historic center of Sublime in an extremely vibrant and lively area within short walking distance to the sites and landmarks of the city and is surrounded by the extraordinary beauty of churches, buildings, shops and monuments. Sublime Cliff is part of a lovingly restored 19th century resort, updated for every modern convenience.", "Category": "Boutique", "Tags": [ "concierge", "view", "air conditioning" ], "ParkingIncluded": true, "LastRenovationDate": "2020-02-06T00:00:00Z", "Rating": 4.60, "Address": { "StreetAddress": "7400 San Pedro Ave", "City": "San Antonio", "StateProvince": "TX", "PostalCode": "78216", "Country": "USA" } } ] } "@インデックス作成エンドポイントをターゲットにするように
$urlオブジェクトを更新します。<YOUR-SEARCH-SERVICE>をエンドポイントで取得した値に置き換えます。$url = "<YOUR-SEARCH-SERVICE>/indexes/hotels-quickstart/docs/index?api-version=2024-07-01"Invoke-RestMethodを実行して、アップロード要求を検索サービスに送信します。Invoke-RestMethod -Uri $url -Headers $headers -Method Post -Body $body | ConvertTo-Json応答には、アップロードされた各ドキュメントのキーと状態が含まれている必要があります。
アップロード要求について
このクイック スタートでは 、Documents - Index (REST API) を呼び出して、インデックスに 4 つのサンプル ホテル ドキュメントを追加します。 前の要求と比較して、URI は、 docs コレクションと index 操作を含むように拡張されます。
value配列内の各ドキュメントはホテルを表し、インデックス スキーマに一致するフィールドが含まれています。
@search.action パラメーターは、各ドキュメントに対して実行する操作を指定します。 この例では、 uploadを使用します。ドキュメントが存在しない場合はドキュメントを追加し、存在する場合はドキュメントを更新します。
インデックスのクエリを実行する
ドキュメントがインデックスに読み込まれたので、フルテキスト検索を使用して、フィールド内の特定の用語または語句を検索できます。
インデックスに対してフルテキスト クエリを実行するには:
$urlオブジェクトを更新して、検索パラメーターを指定します。<YOUR-SEARCH-SERVICE>を Get エンドポイント で取得した値に置き換えてください。$url = '<YOUR-SEARCH-SERVICE>/indexes/hotels-quickstart/docs?api-version=2024-07-01&search=attached restaurant&searchFields=Description,Tags&$select=HotelId,HotelName,Tags,Description&$count=true'Invoke-RestMethodを実行して、クエリ要求を検索サービスに送信します。Invoke-RestMethod -Uri $url -Headers $headers | ConvertTo-Json応答は、一致する 1 つのホテル ドキュメント、その関連性スコア、および選択したフィールドを示す次の例のようになります。
{ "@odata.context": "https://my-service.search.windows.net/indexes('hotels-quickstart')/$metadata#docs(*)", "@odata.count": 1, "value": [ { "@search.score": 0.5575875, "HotelId": "3", "HotelName": "Gastronomic Landscape Hotel", "Description": "The Gastronomic Hotel stands out for its culinary excellence under the management of William Dough, who advises on and oversees all of the Hotel's restaurant services.", "Tags": "restaurant bar continental breakfast" } ] }
クエリ要求について
このクイック スタートでは 、Documents - Search Post (REST API) を呼び出して、検索条件に一致するホテル ドキュメントを検索します。 URI は引き続き docs コレクションを対象としますが、 index 操作は含めなくなりました。
フルテキスト検索要求には、クエリ テキストを含む search パラメーターが常に含まれます。 クエリ テキストには、1 つ以上の用語、語句、または演算子を含めることができます。
searchに加えて、他のパラメーターを指定して、検索動作と結果を絞り込むことができます。
このクエリでは、各ホテル ドキュメントの Description フィールドと Tags フィールドに "attached restaurant" という用語が検索されます。
$select パラメーターは、応答で返されるフィールドを、HotelId、HotelName、Tags、およびDescriptionに制限します。
$count パラメーターは、一致するドキュメントの合計数を要求します。
その他のクエリの例
次のコマンドを実行して、クエリ構文を調べてください。 文字列検索の実行、 $filter 式の使用、結果セットの制限、特定のフィールドの選択などを行うことができます。
<YOUR-SEARCH-SERVICE>は、Get エンドポイントで取得した値に置き換えてください。
# Query example 1
# Search the index for the terms 'restaurant' and 'wifi'
# Return only the HotelName, Description, and Tags fields
$url = '<YOUR-SEARCH-SERVICE>/indexes/hotels-quickstart/docs?api-version=2024-07-01&search=restaurant wifi&$count=true&$select=HotelName,Description,Tags'
# Query example 2
# Use a filter to find hotels rated 4 or higher
# Return only the HotelName and Rating fields
$url = '<YOUR-SEARCH-SERVICE>/indexes/hotels-quickstart/docs?api-version=2024-07-01&search=*&$filter=Rating gt 4&$select=HotelName,Rating'
# Query example 3
# Take the top two results
# Return only the HotelName and Category fields
$url = '<YOUR-SEARCH-SERVICE>/indexes/hotels-quickstart/docs?api-version=2024-07-01&search=boutique&$top=2&$select=HotelName,Category'
# Query example 4
# Sort by a specific field (Address/City) in ascending order
# Return only the HotelName, Address/City, Tags, and Rating fields
$url = '<YOUR-SEARCH-SERVICE>/indexes/hotels-quickstart/docs?api-version=2024-07-01&search=pool&$orderby=Address/City asc&$select=HotelName, Address/City, Tags, Rating'
このクイック スタートでは、Azure.Search.Documents クライアント ライブラリを使用して、フルテキスト検索用のサンプル データを使用して検索インデックスを作成、読み込み、 クエリを実行します。 フルテキスト検索では、インデックス作成とクエリに Apache Lucene を使用し、結果をスコア付けするための BM25 ランク付けアルゴリズムを使用します。
このクイック スタートでは、 azure-search-sample-data リポジトリの架空のホテル データを使用してインデックスを設定します。
ヒント
完成したノートブックをダウンロードして実行することができます。
前提条件
アクティブなサブスクリプションを持つ Azure アカウント。 無料でアカウントを作成できます。
Azure AI Search Service。 まだ作成していない場合、サービスを作成します。 このクイック スタートでは、無料サービスを使用できます。
Python 拡張機能を備えた Visual Studio Code、または Python 3.10 以降を使用した同等の IDE。 適切なバージョンの Python をインストールしていない場合は、 VS Code Python チュートリアルの手順に従ってください。
Microsoft Entra ID の前提条件
Microsoft Entra ID を使用して推奨されるキーレス認証を行うには、次の手順を実行する必要があります。
Azure CLI をインストールします。
ユーザー アカウントに
Search Service ContributorロールとSearch Index Data Contributorロールを割り当てます。 Azure portal の [アクセス制御 (IAM)]>[ロールの割り当ての追加] で、ロールを割り当てることができます。 詳細については、「ロールを使用して Azure AI 検索に接続する」を参照してください。
リソース情報の取得
Azure AI 検索サービスでアプリケーションを認証するには、次の情報を取得する必要があります。
| 変数名 | 値 |
|---|---|
SEARCH_API_ENDPOINT |
この値は、Azure portal で確認できます。 検索サービスを選択し、左側のメニューから [概要] を選択します。
[基本] の下の [URL] は、必要なエンドポイントです。 たとえば、エンドポイントは https://mydemo.search.windows.net のようになります。 |
環境を設定する
Jupyter ノートブックでサンプル コードを実行します。 そのため、Jupyter ノートブックを実行する環境を設定する必要があります。
GitHub からサンプル ノートブックをダウンロードするか、コピーします。
そのノートブックを Visual Studio Code で開きます。
このチュートリアルに必要なパッケージをインストールするために使用する新しい Python 環境を作成します。
重要
グローバルな Python インストールにパッケージをインストールしないでください。 Python パッケージをインストールするときは、常に仮想環境または conda 環境を使用する必要があります。そうしないと、Python のグローバル インストールが中断される場合があります。
短時間で設定されます。 問題が発生した場合は、「VS Code での Python 環境」を参照してください。
まだインストールしていない場合は、Jupyter Notebooks と Jupyter Notebooks 用 IPython カーネルをインストールします。
pip install jupyter pip install ipykernel python -m ipykernel install --user --name=.venvノートブック カーネルを選択します。
- ノートブックの右上隅にある [カーネルの選択] を選択します。
- 一覧に
.venvが表示されている場合は、それを選択します。 表示されていない場合は、[別のカーネルを選択]>[Python 環境]>.venvの順に選択します。
検索インデックスの作成、読み込み、クエリの実行
このセクションでは、検索インデックスを作成し、それにドキュメントを読み込んで、クエリを実行するコードを追加します。 プログラムを実行して、結果をコンソールに表示します。 コードの詳細な説明については、「コードの説明」セクションを参照してください。
前のセクションで説明したように、ノートブックが
.venvカーネルで開いていることを確認します。最初のコード セルを実行して、azure-search-documents など、必要なパッケージをインストールします。
! pip install azure-search-documents==11.6.0b1 --quiet ! pip install azure-identity --quiet ! pip install python-dotenv --quiet認証方法に応じて、2 番目のコード セルの内容を次のコードに置き換えます。
注
このクイックスタートのサンプル コードでは、推奨されるキーレス認証に Microsoft Entra ID を使用します。 API キーを使用する場合は、
DefaultAzureCredentialオブジェクトをAzureKeyCredentialオブジェクトに置き換えることができます。from azure.core.credentials import AzureKeyCredential from azure.identity import DefaultAzureCredential, AzureAuthorityHosts search_endpoint: str = "https://<Put your search service NAME here>.search.windows.net/" authority = AzureAuthorityHosts.AZURE_PUBLIC_CLOUD credential = DefaultAzureCredential(authority=authority) index_name: str = "hotels-quickstart-python"Create an index コード セルから次の 2 行を削除します。 資格情報は、前のコード セルで既に設定されています。
from azure.core.credentials import AzureKeyCredential credential = AzureKeyCredential(search_api_key)Create an index コード セルを実行して、検索インデックスを作成します。
残りのコード セルを順番に実行して、ドキュメントを読み込み、クエリを実行します。
コードの説明
インデックスを作成する
SearchIndexClient は、Azure AI 検索のインデックスを作成して管理するために使用されます。 各フィールドは name によって識別され、type が指定されています。
各フィールドには、Azure AI Search がフィールドで検索、フィルター処理、並べ替え、ファセットを実行できるかどうかを指定する一連のインデックス属性もあります。 ほとんどのフィールドは単純なデータ型ですが、AddressType のように、自分のインデックスでリッチなデータ構造を作成できる複合型もあります。
サポートされているデータ型とインデックスの属性について詳しくは、インデックスの作成 (REST) に関するページを参照してください。
ドキュメント ペイロードを作成してドキュメントをアップロードする
インデックス アクションで、upload や merge-and-upload などの操作の種類を指定します。 ドキュメントは、GitHub の HotelsData サンプルに由来します。
インデックスを検索する
最初のドキュメントのインデックスが作成されるとすぐにクエリの結果を取得できますが、インデックスの実際のテストではすべてのドキュメントのインデックスが作成されるまで待つ必要があります。
search.client クラスの search メソッドを使用します。
ノートブック内のサンプルクエリは次のとおりです。
- 基本的なクエリ: 空の検索 (
search=*) を実行し、任意のドキュメントのランク付けされていない一覧 (検索スコア = 1.0) を返します。 条件がないため、すべてのドキュメントが結果に含まれます。 - 用語のクエリ: 検索式に用語全体を追加します ("wifi")。 このクエリでは、
selectステートメント内のフィールドのみが結果に含まれることを指定しています。 返されるフィールドを制限すると、ネットワーク経由で返されるデータの量が最小限に抑えられ、検索の待ち時間が短縮されます。 - フィルター処理されたクエリ: 評価が 4 を超えるホテルのみを降順に並べ替えて返すフィルター式を追加します。
- フィールド スコープ:
search_fieldsを追加し、クエリ実行のスコープを特定のフィールドに設定します。 - ファセット: 検索結果で見つかった正の一致のファセットを生成します。 0 件の一致はありません。 検索結果に "wifi" という用語が含まれていない場合、"wifi" はファセット ナビゲーション構造に表示されません。
- ドキュメントの検索: ドキュメントのキーに基づいてドキュメントを返します。 この操作は、ユーザーが検索結果の項目を選択したときにドリルスルーを提供したい場合に便利です。
- オートコンプリート: ユーザーが検索ボックスに入力しているときに一致する可能性のある候補を提供します。 オートコンプリートでは、suggester (
sg) を使用して、suggester 要求に一致する可能性があるものを含むフィールドを把握します。 このクイックスタートでは、これらのフィールドはTags、Address/City、Address/Countryです。 オートコンプリートをシミュレートするには、文字 "sa" を部分文字列として渡します。 SearchClient の autocomplete メソッドにより、一致する可能性のある用語が返されます。
インデックスを削除する
このインデックスの使用が完了したら、Clean up コード セルを実行してインデックスを削除できます。 不要なインデックスを削除すると、スペースが解放され、より多くのクイックスタートやチュートリアルを実行できます。
このクイック スタートでは、 Azure AI Search REST API を 使用して、 フルテキスト検索用の検索インデックスを作成、読み込み、クエリを実行します。 フルテキスト検索では、インデックス作成とクエリに Apache Lucene を使用し、結果をスコア付けするための BM25 ランク付けアルゴリズムを使用します。
このクイック スタートでは、 azure-search-sample-data リポジトリの架空のホテル データを使用してインデックスを設定します。
ヒント
完成したプロジェクトから開始する ソース コード をダウンロードするか、次の手順に従って独自のプロジェクトを作成できます。
前提条件
アクティブなサブスクリプションを持つ Azure アカウント。 無料でアカウントを作成できます。
Azure AI Search Service。 サービスを作成 するか 、現在の サブスクリプションで既存のサービスを検索します。 このクイック スタートでは、無料サービスを使用できます。
Microsoft Entra ID を使用したキーレス認証用 の Azure CLI 。
アクセスを構成する
ロールの割り当てで API キーまたは Microsoft Entra ID を使用して、Azure AI Search サービスに接続できます。 キーの方が簡単に使い始めることができますが、安全性が高いのはロールの方です。
推奨されるロールベースのアクセスを構成するには:
Azure portal にサインインし、検索サービスを選択します。
次に、左側のペインで [設定]>[キー] を選択します。
[API アクセス制御] で、[両方] を選択します。
このオプションでは、キーベース認証とキーレス認証の両方が有効になります。 ロールを割り当てた後、この手順に戻り、[ ロールベースのアクセス制御] を選択できます。
左側のウィンドウで、[ アクセス制御 (IAM)] を選択します。
[追加>][ロール割り当ての追加] の順に選択します。
Search Service 共同作成者ロールと検索インデックス データ共同作成者ロールをユーザー アカウントに割り当てます。
詳細については、「ロールを使用して Azure AI 検索に接続する」を参照してください。
エンドポイントとトークンを取得する
次のセクションでは、次のエンドポイントとトークンを指定して、Azure AI Search サービスへの接続を確立します。 これらの手順では、 ロールベースのアクセスを構成していることを前提としています。
サービス エンドポイントとトークンを取得するには:
Azure portal にサインインし、検索サービスを選択します。
左側のウィンドウで、[ 概要] を選択します。
URL を書き留めます。これは、
https://my-service.search.windows.netのようになります。ローカル システムで、ターミナルを開きます。
Azure サブスクリプションにサインインします。 複数のサブスクリプションがある場合は、検索サービスを含むサブスクリプションを選択します。
az loginMicrosoft Entra トークンを書き留めます。
az account get-access-token --scope https://search.azure.com/.default
ファイルを設定する
Azure AI Search サービスに対して REST API 呼び出しを行う前に、サービス エンドポイント、認証トークン、および最終的な要求を格納するファイルを作成する必要があります。 Visual Studio Code の REST クライアント拡張機能では、このタスクがサポートされています。
要求ファイルを設定するには:
ローカル システムで、Visual Studio Code を開きます。
.restまたは.httpファイルを作成します。次のプレースホルダーと要求をファイルに貼り付けます。
@baseUrl = PUT-YOUR-SEARCH-SERVICE-ENDPOINT-HERE @token = PUT-YOUR-PERSONAL-IDENTITY-TOKEN-HERE ### List existing indexes by name GET {{baseUrl}}/indexes?api-version=2024-07-01 HTTP/1.1 Authorization: Bearer {{token}}@baseUrlと@tokenのプレースホルダーを、「エンドポイントとトークンの取得」で取得した値に置き換えます。 引用符は含めません。[
### List existing indexes by nameで、[ 要求の送信] を選択します。隣接するウィンドウに応答が表示されます。 既存のインデックスがある場合、そのインデックスが一覧表示されます。 そうしないと、一覧は空です。 HTTP コードが
200 OKの場合は、次の手順に進むことができます。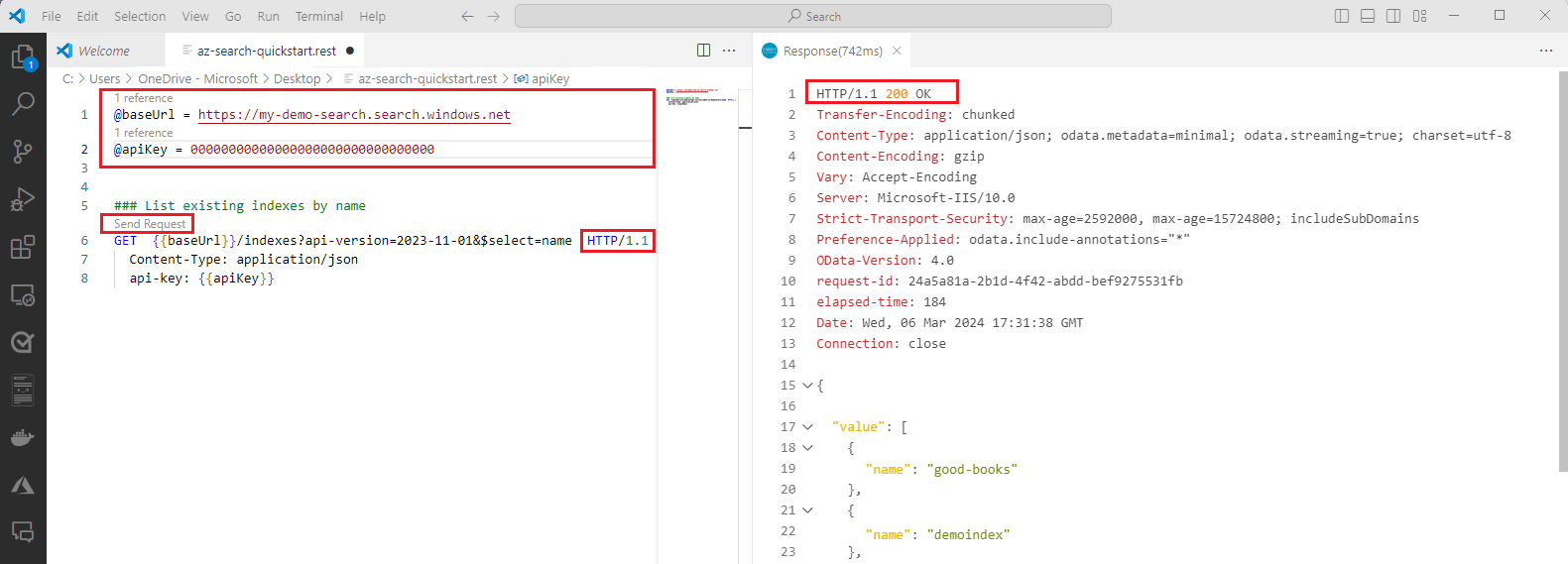

検索インデックスを作成する
Azure AI Search にコンテンツを追加する前に、コンテンツの格納方法と構造化方法を定義するインデックスを作成する必要があります。 インデックスは概念的にはリレーショナル データベースのテーブルに似ていますが、フルテキスト検索などの検索操作用に特別に設計されています。
インデックスを作成するには:
次の要求をファイルに貼り付けます。
### Create a new index POST {{baseUrl}}/indexes?api-version=2024-07-01 HTTP/1.1 Content-Type: application/json Authorization: Bearer {{token}} { "name": "hotels-quickstart", "fields": [ {"name": "HotelId", "type": "Edm.String", "key": true, "filterable": true}, {"name": "HotelName", "type": "Edm.String", "searchable": true, "filterable": false, "sortable": true, "facetable": false}, {"name": "Description", "type": "Edm.String", "searchable": true, "filterable": false, "sortable": false, "facetable": false, "analyzer": "en.lucene"}, {"name": "Category", "type": "Edm.String", "searchable": true, "filterable": true, "sortable": true, "facetable": true}, {"name": "Tags", "type": "Collection(Edm.String)", "searchable": true, "filterable": true, "sortable": false, "facetable": true}, {"name": "ParkingIncluded", "type": "Edm.Boolean", "filterable": true, "sortable": true, "facetable": true}, {"name": "LastRenovationDate", "type": "Edm.DateTimeOffset", "filterable": true, "sortable": true, "facetable": true}, {"name": "Rating", "type": "Edm.Double", "filterable": true, "sortable": true, "facetable": true}, {"name": "Address", "type": "Edm.ComplexType", "fields": [ {"name": "StreetAddress", "type": "Edm.String", "filterable": false, "sortable": false, "facetable": false, "searchable": true}, {"name": "City", "type": "Edm.String", "searchable": true, "filterable": true, "sortable": true, "facetable": true}, {"name": "StateProvince", "type": "Edm.String", "searchable": true, "filterable": true, "sortable": true, "facetable": true}, {"name": "PostalCode", "type": "Edm.String", "searchable": true, "filterable": true, "sortable": true, "facetable": true}, {"name": "Country", "type": "Edm.String", "searchable": true, "filterable": true, "sortable": true, "facetable": true} ] } ] }[
### Create a new indexで、[ 要求の送信] を選択します。本文にインデックス スキーマの JSON 表現が含まれる
HTTP/1.1 201 Created応答を受け取る必要があります。
インデックス作成要求について
このクイック スタートでは 、Indexes - Create (REST API) を呼び出して、 hotels-quickstart という名前の検索インデックスとその物理データ構造を検索サービスに構築します。
インデックス スキーマ内では、 fields コレクションによってホテル ドキュメントの構造が定義されます。 各フィールドには、インデックス作成とクエリ中の動作を決定する name、データ type、および属性があります。
HotelId フィールドはキーとしてマークされ、Azure AI Search ではインデックス内の各ドキュメントを一意に識別する必要があります。
インデックス スキーマに関する重要なポイント:
文字列フィールド (
Edm.String) を使用して、数値データのフルテキスト検索を可能にします。Edm.Int32など、サポートされているその他のデータ型は、フィルター可能、並べ替え可能、ファセット可能、および取得可能ですが、検索できません。ほとんどのフィールドは単純なデータ型ですが、
Addressフィールドなど、入れ子になったデータを表す複合型を定義できます。フィールド属性は、許可されるアクションを決定します。 REST API では、多くのアクションが既定で使用できます。 たとえば、すべての文字列は検索可能で取得可能です。 REST API では、動作を無効にする必要がある場合にのみ属性を使用できます。
インデックスを読み込む
新しく作成されたインデックスは空です。 インデックスを設定して検索できるようにするには、インデックス スキーマに準拠する JSON ドキュメントをアップロードする必要があります。
Azure AI Search では、ドキュメントはインデックス作成の入力とクエリの出力の両方として機能します。 わかりやすくするために、このクイック スタートでは、サンプルのホテル ドキュメントをインライン JSON として提供します。 ただし、運用環境のシナリオでは、多くの場合、コンテンツは接続されたデータ ソースからプルされ、 インデクサーを使用して JSON に変換されます。
ドキュメントをインデックスにアップロードするには:
次の要求をファイルに貼り付けます。
### Upload documents POST {{baseUrl}}/indexes/hotels-quickstart/docs/index?api-version=2024-07-01 HTTP/1.1 Content-Type: application/json Authorization: Bearer {{token}} { "value": [ { "@search.action": "upload", "HotelId": "1", "HotelName": "Stay-Kay City Hotel", "Description": "This classic hotel is fully-refurbished and ideally located on the main commercial artery of the city in the heart of New York. A few minutes away is Times Square and the historic centre of the city, as well as other places of interest that make New York one of America's most attractive and cosmopolitan cities.", "Category": "Boutique", "Tags": [ "view", "air conditioning", "concierge" ], "ParkingIncluded": false, "LastRenovationDate": "2022-01-18T00:00:00Z", "Rating": 3.60, "Address": { "StreetAddress": "677 5th Ave", "City": "New York", "StateProvince": "NY", "PostalCode": "10022", "Country": "USA" } }, { "@search.action": "upload", "HotelId": "2", "HotelName": "Old Century Hotel", "Description": "The hotel is situated in a nineteenth century plaza, which has been expanded and renovated to the highest architectural standards to create a modern, functional and first-class hotel in which art and unique historical elements coexist with the most modern comforts. The hotel also regularly hosts events like wine tastings, beer dinners, and live music.", "Category": "Boutique", "Tags": [ "pool", "free wifi", "concierge" ], "ParkingIncluded": false, "LastRenovationDate": "2019-02-18T00:00:00Z", "Rating": 3.60, "Address": { "StreetAddress": "140 University Town Center Dr", "City": "Sarasota", "StateProvince": "FL", "PostalCode": "34243", "Country": "USA" } }, { "@search.action": "upload", "HotelId": "3", "HotelName": "Gastronomic Landscape Hotel", "Description": "The Gastronomic Hotel stands out for its culinary excellence under the management of William Dough, who advises on and oversees all of the Hotel's restaurant services.", "Category": "Suite", "Tags": [ "restaurant", "bar", "continental breakfast" ], "ParkingIncluded": true, "LastRenovationDate": "2015-09-20T00:00:00Z", "Rating": 4.80, "Address": { "StreetAddress": "3393 Peachtree Rd", "City": "Atlanta", "StateProvince": "GA", "PostalCode": "30326", "Country": "USA" } }, { "@search.action": "upload", "HotelId": "4", "HotelName": "Sublime Palace Hotel", "Description": "Sublime Palace Hotel is located in the heart of the historic center of Sublime in an extremely vibrant and lively area within short walking distance to the sites and landmarks of the city and is surrounded by the extraordinary beauty of churches, buildings, shops and monuments. Sublime Cliff is part of a lovingly restored 19th century resort, updated for every modern convenience.", "Category": "Luxury", "Tags": [ "concierge", "view", "air conditioning" ], "ParkingIncluded": true, "LastRenovationDate": "2020-02-06T00:00:00Z", "Rating": 4.60, "Address": { "StreetAddress": "7400 San Pedro Ave", "City": "San Antonio", "StateProvince": "TX", "PostalCode": "78216", "Country": "USA" } } ] }[
### Upload documentsで、[ 要求の送信] を選択します。アップロードされた各ドキュメントのキーと状態が本文に含まれる
HTTP/1.1 200 OK応答を受け取る必要があります。
アップロード要求について
このクイック スタートでは 、Documents - Index (REST API) を呼び出して、インデックスに 4 つのサンプル ホテル ドキュメントを追加します。 前の要求と比較して、URI は、 docs コレクションと index 操作を含むように拡張されます。
value配列内の各ドキュメントはホテルを表し、インデックス スキーマに一致するフィールドが含まれています。
@search.action パラメーターは、各ドキュメントに対して実行する操作を指定します。 この例では、 uploadを使用します。ドキュメントが存在しない場合はドキュメントを追加し、存在する場合はドキュメントを更新します。
インデックスのクエリを実行する
ドキュメントがインデックスに読み込まれたので、フルテキスト検索を使用して、フィールド内の特定の用語または語句を検索できます。
インデックスに対してフルテキスト クエリを実行するには:
次の要求をファイルに貼り付けます。
### Run a query POST {{baseUrl}}/indexes/hotels-quickstart/docs/search?api-version=2024-07-01 HTTP/1.1 Content-Type: application/json Authorization: Bearer {{token}} { "search": "attached restaurant", "select": "HotelId, HotelName, Tags, Description", "searchFields": "Description, Tags", "count": true }[
### Run a queryで、[ 要求の送信] を選択します。次の例のような
HTTP/1.1 200 OK応答を受け取ります。この応答には、一致する 1 つのホテル ドキュメント、その関連性スコア、および選択したフィールドが表示されます。{ "@odata.context": "https://my-service.search.windows.net/indexes('hotels-quickstart')/$metadata#docs(*)", "@odata.count": 1, "value": [ { "@search.score": 0.5575875, "HotelId": "3", "HotelName": "Gastronomic Landscape Hotel", "Description": "The Gastronomic Hotel stands out for its culinary excellence under the management of William Dough, who advises on and oversees all of the Hotel\u2019s restaurant services.", "Tags": [ "restaurant", "bar", "continental breakfast" ] } ] }
クエリ要求について
このクイック スタートでは 、Documents - Search Post (REST API) を呼び出して、検索条件に一致するホテル ドキュメントを検索します。 URI は、 /docs/search 操作を対象とするようになりました。
フルテキスト検索要求には、クエリ テキストを含む search パラメーターが常に含まれます。 クエリ テキストには、1 つ以上の用語、語句、または演算子を含めることができます。
searchに加えて、他のパラメーターを指定して、検索動作と結果を絞り込むことができます。
このクエリでは、各ホテル ドキュメントの Description フィールドと Tags フィールドに "attached restaurant" という用語が検索されます。
select パラメーターは、応答で返されるフィールドを、HotelId、HotelName、Tags、およびDescriptionに制限します。
count パラメーターは、一致するドキュメントの合計数を要求します。
このクイック スタートでは、Azure.Search.Documents クライアント ライブラリを使用して、フルテキスト検索用のサンプル データを使用して検索インデックスを作成、読み込み、 クエリを実行します。 フルテキスト検索では、インデックス作成とクエリに Apache Lucene を使用し、結果をスコア付けするための BM25 ランク付けアルゴリズムを使用します。
このクイック スタートでは、 azure-search-sample-data リポジトリの架空のホテル データを使用してインデックスを設定します。
ヒント
完成したプロジェクトから開始する ソース コード をダウンロードするか、次の手順に従って独自のプロジェクトを作成できます。
前提条件
- アクティブなサブスクリプションを持つ Azure アカウント。 無料でアカウントを作成できます。
- Azure AI Search Service。 まだ作成していない場合、サービスを作成します。 このクイック スタートでは、無料サービスを使用できます。
Microsoft Entra ID の前提条件
Microsoft Entra ID を使用して推奨されるキーレス認証を行うには、次の手順を実行する必要があります。
Azure CLI をインストールします。
ユーザー アカウントに
Search Service ContributorロールとSearch Index Data Contributorロールを割り当てます。 Azure portal の [アクセス制御 (IAM)]>[ロールの割り当ての追加] で、ロールを割り当てることができます。 詳細については、「ロールを使用して Azure AI 検索に接続する」を参照してください。
リソース情報の取得
Azure AI 検索サービスでアプリケーションを認証するには、次の情報を取得する必要があります。
| 変数名 | 値 |
|---|---|
SEARCH_API_ENDPOINT |
この値は、Azure portal で確認できます。 検索サービスを選択し、左側のメニューから [概要] を選択します。
[基本] の下の [URL] は、必要なエンドポイントです。 たとえば、エンドポイントは https://mydemo.search.windows.net のようになります。 |
設定
アプリケーションを含める新しいフォルダー
full-text-quickstartを作成し、次のコマンドを使用してそのフォルダー内で Visual Studio Code を開きます。mkdir full-text-quickstart && cd full-text-quickstart次のコマンドで
package.jsonを作成します。npm init -y次のコマンドを使用して、
package.jsonを ECMAScript に更新します。npm pkg set type=module次のコマンドを使用して、JavaScript 用の Azure AI 検索クライアント ライブラリ (Azure.Search.Documents) をインストールします。
npm install @azure/search-documents推奨されるパスワードレス認証の場合、次のコマンドを使用して Azure ID クライアント ライブラリをインストールします。
npm install @azure/identity
検索インデックスの作成、読み込み、クエリの実行
前の「設定」セクションで、Azure AI 検索クライアント ライブラリとその他の依存関係をインストールしました。
このセクションでは、検索インデックスを作成し、それにドキュメントを読み込んで、クエリを実行するコードを追加します。 プログラムを実行して、結果をコンソールに表示します。 コードの詳細な説明については、「コードの説明」セクションを参照してください。
このクイックスタートのサンプル コードでは、推奨されるキーレス認証に Microsoft Entra ID を使用します。 API キーを使用する場合は、DefaultAzureCredential オブジェクトを AzureKeyCredential オブジェクトに置き換えることができます。
const searchServiceEndpoint = "https://<Put your search service NAME here>.search.windows.net/";
const credential = new DefaultAzureCredential();
index.ts という名前の新しいファイルを作成し、次のコードを index.ts に貼り付けます。
// Import from the @azure/search-documents library import { SearchIndexClient, SearchClient, SearchFieldDataType, AzureKeyCredential, odata, SearchIndex } from "@azure/search-documents"; // Import from the Azure Identity library import { DefaultAzureCredential } from "@azure/identity"; // Importing the hotels sample data import hotelData from './hotels.json' assert { type: "json" }; // Load the .env file if it exists import * as dotenv from "dotenv"; dotenv.config(); // Defining the index definition const indexDefinition: SearchIndex = { "name": "hotels-quickstart", "fields": [ { "name": "HotelId", "type": "Edm.String" as SearchFieldDataType, "key": true, "filterable": true }, { "name": "HotelName", "type": "Edm.String" as SearchFieldDataType, "searchable": true, "filterable": false, "sortable": true, "facetable": false }, { "name": "Description", "type": "Edm.String" as SearchFieldDataType, "searchable": true, "filterable": false, "sortable": false, "facetable": false, "analyzerName": "en.lucene" }, { "name": "Category", "type": "Edm.String" as SearchFieldDataType, "searchable": true, "filterable": true, "sortable": true, "facetable": true }, { "name": "Tags", "type": "Collection(Edm.String)", "searchable": true, "filterable": true, "sortable": false, "facetable": true }, { "name": "ParkingIncluded", "type": "Edm.Boolean", "filterable": true, "sortable": true, "facetable": true }, { "name": "LastRenovationDate", "type": "Edm.DateTimeOffset", "filterable": true, "sortable": true, "facetable": true }, { "name": "Rating", "type": "Edm.Double", "filterable": true, "sortable": true, "facetable": true }, { "name": "Address", "type": "Edm.ComplexType", "fields": [ { "name": "StreetAddress", "type": "Edm.String" as SearchFieldDataType, "filterable": false, "sortable": false, "facetable": false, "searchable": true }, { "name": "City", "type": "Edm.String" as SearchFieldDataType, "searchable": true, "filterable": true, "sortable": true, "facetable": true }, { "name": "StateProvince", "type": "Edm.String" as SearchFieldDataType, "searchable": true, "filterable": true, "sortable": true, "facetable": true }, { "name": "PostalCode", "type": "Edm.String" as SearchFieldDataType, "searchable": true, "filterable": true, "sortable": true, "facetable": true }, { "name": "Country", "type": "Edm.String" as SearchFieldDataType, "searchable": true, "filterable": true, "sortable": true, "facetable": true } ] } ], "suggesters": [ { "name": "sg", "searchMode": "analyzingInfixMatching", "sourceFields": [ "HotelName" ] } ] }; async function main() { // Your search service endpoint const searchServiceEndpoint = "https://<Put your search service NAME here>.search.windows.net/"; // Use the recommended keyless credential instead of the AzureKeyCredential credential. const credential = new DefaultAzureCredential(); //const credential = new AzureKeyCredential(Your search service admin key); // Create a SearchIndexClient to send create/delete index commands const searchIndexClient: SearchIndexClient = new SearchIndexClient( searchServiceEndpoint, credential ); // Creating a search client to upload documents and issue queries const indexName: string = "hotels-quickstart"; const searchClient: SearchClient<any> = searchIndexClient.getSearchClient(indexName); console.log('Checking if index exists...'); await deleteIndexIfExists(searchIndexClient, indexName); console.log('Creating index...'); let index: SearchIndex = await searchIndexClient.createIndex(indexDefinition); console.log(`Index named ${index.name} has been created.`); console.log('Uploading documents...'); let indexDocumentsResult = await searchClient.mergeOrUploadDocuments(hotelData['value']); console.log(`Index operations succeeded: ${JSON.stringify(indexDocumentsResult.results[0].succeeded)} `); // waiting one second for indexing to complete (for demo purposes only) sleep(1000); console.log('Querying the index...'); console.log(); await sendQueries(searchClient); } async function deleteIndexIfExists(searchIndexClient: SearchIndexClient, indexName: string) { try { await searchIndexClient.deleteIndex(indexName); console.log('Deleting index...'); } catch { console.log('Index does not exist yet.'); } } async function sendQueries(searchClient: SearchClient<any>) { // Query 1 console.log('Query #1 - search everything:'); let searchOptions: any = { includeTotalCount: true, select: ["HotelId", "HotelName", "Rating"] }; let searchResults = await searchClient.search("*", searchOptions); for await (const result of searchResults.results) { console.log(`${JSON.stringify(result.document)}`); } console.log(`Result count: ${searchResults.count}`); console.log(); // Query 2 console.log('Query #2 - search with filter, orderBy, and select:'); let state = 'FL'; searchOptions = { filter: odata`Address/StateProvince eq ${state}`, orderBy: ["Rating desc"], select: ["HotelId", "HotelName", "Rating"] }; searchResults = await searchClient.search("wifi", searchOptions); for await (const result of searchResults.results) { console.log(`${JSON.stringify(result.document)}`); } console.log(); // Query 3 console.log('Query #3 - limit searchFields:'); searchOptions = { select: ["HotelId", "HotelName", "Rating"], searchFields: ["HotelName"] }; searchResults = await searchClient.search("sublime palace", searchOptions); for await (const result of searchResults.results) { console.log(`${JSON.stringify(result.document)}`); } console.log(); // Query 4 console.log('Query #4 - limit searchFields and use facets:'); searchOptions = { facets: ["Category"], select: ["HotelId", "HotelName", "Rating"], searchFields: ["HotelName"] }; searchResults = await searchClient.search("*", searchOptions); for await (const result of searchResults.results) { console.log(`${JSON.stringify(result.document)}`); } console.log(); // Query 5 console.log('Query #5 - Lookup document:'); let documentResult = await searchClient.getDocument('3'); console.log(`HotelId: ${documentResult.HotelId}; HotelName: ${documentResult.HotelName}`); console.log(); } function sleep(ms: number) { return new Promise(resolve => setTimeout(resolve, ms)); } main().catch((err) => { console.error("The sample encountered an error:", err); });hotels.json という名前のファイルを作成し、次のコードを hotels.json に貼り付けます。
{ "value": [ { "HotelId": "1", "HotelName": "Stay-Kay City Hotel", "Description": "This classic hotel is fully-refurbished and ideally located on the main commercial artery of the city in the heart of New York. A few minutes away is Times Square and the historic centre of the city, as well as other places of interest that make New York one of America's most attractive and cosmopolitan cities.", "Category": "Boutique", "Tags": ["view", "air conditioning", "concierge"], "ParkingIncluded": false, "LastRenovationDate": "2022-01-18T00:00:00Z", "Rating": 3.6, "Address": { "StreetAddress": "677 5th Ave", "City": "New York", "StateProvince": "NY", "PostalCode": "10022" } }, { "HotelId": "2", "HotelName": "Old Century Hotel", "Description": "The hotel is situated in a nineteenth century plaza, which has been expanded and renovated to the highest architectural standards to create a modern, functional and first-class hotel in which art and unique historical elements coexist with the most modern comforts. The hotel also regularly hosts events like wine tastings, beer dinners, and live music.", "Category": "Boutique", "Tags": ["pool", "free wifi", "concierge"], "ParkingIncluded": "false", "LastRenovationDate": "2019-02-18T00:00:00Z", "Rating": 3.6, "Address": { "StreetAddress": "140 University Town Center Dr", "City": "Sarasota", "StateProvince": "FL", "PostalCode": "34243" } }, { "HotelId": "3", "HotelName": "Gastronomic Landscape Hotel", "Description": "The Gastronomic Hotel stands out for its culinary excellence under the management of William Dough, who advises on and oversees all of the Hotel’s restaurant services.", "Category": "Suite", "Tags": ["restaurant, "bar", "continental breakfast"], "ParkingIncluded": "true", "LastRenovationDate": "2015-09-20T00:00:00Z", "Rating": 4.8, "Address": { "StreetAddress": "3393 Peachtree Rd", "City": "Atlanta", "StateProvince": "GA", "PostalCode": "30326" } }, { "HotelId": "4", "HotelName": "Sublime Palace Hotel", "Description": "Sublime Palace Hotel is located in the heart of the historic center of Sublime in an extremely vibrant and lively area within short walking distance to the sites and landmarks of the city and is surrounded by the extraordinary beauty of churches, buildings, shops and monuments. Sublime Cliff is part of a lovingly restored 19th century resort, updated for every modern convenience.", "Category": "Boutique", "Tags": ["concierge", "view", "air conditioning"], "ParkingIncluded": true, "LastRenovationDate": "2020-02-06T00:00:00Z", "Rating": 4.6, "Address": { "StreetAddress": "7400 San Pedro Ave", "City": "San Antonio", "StateProvince": "TX", "PostalCode": "78216" } } ] }TypeScript コードをトランスパイルするために
tsconfig.jsonファイルを作成して、ECMAScript 向けの次のコードをコピーします。{ "compilerOptions": { "module": "NodeNext", "target": "ES2022", // Supports top-level await "moduleResolution": "NodeNext", "skipLibCheck": true, // Avoid type errors from node_modules "strict": true // Enable strict type-checking options }, "include": ["*.ts"] }TypeScript から JavaScript にトランスパイルします。
tsc次のコマンドを使用して Azure にサインインします。
az login次のコマンドを使用して、JavaScript コードを実行します。
node index.js
コードの説明
インデックスを作成する
hotels_quickstart_index.json というファイルを作成します。 このファイルは、次の手順で読み込むドキュメントに対して Azure AI 検索がどのように機能するかを定義します。 各フィールドは name によって識別され、type が指定されています。 各フィールドには、Azure AI Search がフィールドで検索、フィルター処理、並べ替え、ファセットを実行できるかどうかを指定する一連のインデックス属性もあります。 ほとんどのフィールドは単純なデータ型ですが、AddressType のように、自分のインデックスでリッチなデータ構造を作成できる複合型もあります。
サポートされているデータ型とインデックスの属性について詳しくは、インデックスの作成 (REST) に関するページを参照してください。
main 関数でインデックスの定義にアクセスできるように、hotels_quickstart_index.json をインポートする必要があります。
import indexDefinition from './hotels_quickstart_index.json';
interface HotelIndexDefinition {
name: string;
fields: SimpleField[] | ComplexField[];
suggesters: SearchSuggester[];
};
const hotelIndexDefinition: HotelIndexDefinition = indexDefinition as HotelIndexDefinition;
main 関数内で、 SearchIndexClientを作成します。これは、Azure AI Search のインデックスの作成と管理に使用されます。
const indexClient = new SearchIndexClient(endpoint, new AzureKeyCredential(apiKey));
次に、インデックスが既に存在する場合はそれを削除します。 この操作は、テストやデモのコードでは一般的な手法です。
これを行うには、インデックスの削除を試行する単純な関数を定義します。
async function deleteIndexIfExists(indexClient: SearchIndexClient, indexName: string): Promise<void> {
try {
await indexClient.deleteIndex(indexName);
console.log('Deleting index...');
} catch {
console.log('Index does not exist yet.');
}
}
関数を実行するには、インデックス定義からインデックス名を抽出し、indexName と共に indexClient を deleteIndexIfExists() 関数に渡します。
// Getting the name of the index from the index definition
const indexName: string = hotelIndexDefinition.name;
console.log('Checking if index exists...');
await deleteIndexIfExists(indexClient, indexName);
その後、createIndex() メソッドを使用してインデックスを作成する準備が整います。
console.log('Creating index...');
let index = await indexClient.createIndex(hotelIndexDefinition);
console.log(`Index named ${index.name} has been created.`);
ドキュメントを読み込む
Azure AI Search では、ドキュメントはインデックス作成への入力とクエリからの出力の両方であるデータ構造です。 このようなデータをインデックスにプッシュするか、インデクサーを使用することができます。 この場合は、プログラムによってドキュメントをインデックスにプッシュします。
ドキュメント入力には、データベース内の行、Blob Storage 内の BLOB、またはこの例のようなディスク上の JSON ドキュメントがあります。 hotels.json をダウンロードするか、次の内容を使って独自の hotels.json ファイルを作成できます。
indexDefinition で行ったのと同様に、main 関数でデータにアクセスできるように、hotels.json の冒頭で をインポートする必要もあります。
import hotelData from './hotels.json';
interface Hotel {
HotelId: string;
HotelName: string;
Description: string;
Category: string;
Tags: string[];
ParkingIncluded: string | boolean;
LastRenovationDate: string;
Rating: number;
Address: {
StreetAddress: string;
City: string;
StateProvince: string;
PostalCode: string;
};
};
const hotels: Hotel[] = hotelData["value"];
データに検索インデックスを付けるために、次は SearchClient を作成する必要があります。
SearchIndexClient はインデックスの作成と管理に使用され、SearchClient はドキュメントのアップロードとインデックスのクエリに使用されます。
SearchClient は 2 とおりの方法で作成できます。 1 つには、ゼロから SearchClient を作成する方法があります。
const searchClient = new SearchClient<Hotel>(endpoint, indexName, new AzureKeyCredential(apiKey));
または、getSearchClient() の SearchIndexClient メソッドを使用して SearchClient を作成することもできます。
const searchClient = indexClient.getSearchClient<Hotel>(indexName);
クライアントが定義できたところで、ドキュメントを検索インデックスにアップロードします。 ここでは mergeOrUploadDocuments() メソッドを使用します。これにより、ドキュメントをアップロードしたり、同じキーのドキュメントが既に存在する場合に既存のドキュメントとマージしたりします。 次に、少なくとも最初のドキュメントが存在していることを確認し、操作が成功したことを確認します。
console.log("Uploading documents...");
const indexDocumentsResult = await searchClient.mergeOrUploadDocuments(hotels);
console.log(`Index operations succeeded: ${JSON.stringify(indexDocumentsResult.results[0].succeeded)}`);
tsc && node index.ts でプログラムを再度実行します。 手順 1 で表示されたのとは若干異なるメッセージが表示されるはずです。 今回はインデックスが存在して "いる" ので、その削除に関するメッセージが表示されます。そしてその後に、アプリによって新しいインデックスが作成され、そこにデータがポストされます。
次の手順でクエリを実行する前に、プログラムを 1 秒間待機させる関数を定義します。 これは、インデックスの作成を確実に完了し、クエリ用のインデックスでドキュメントを利用できるようにするために、ただテストやデモの目的で行います。
function sleep(ms: number): Promise<void> {
return new Promise((resolve) => setTimeout(resolve, ms));
}
プログラムを 1 秒間待機させるには、sleep 関数を呼び出します。
sleep(1000);
インデックスを検索する
インデックスを作成し、ドキュメントをアップロードしたところで、クエリをインデックスに送信する準備が整いました。 このセクションでは、5 つの異なるクエリを検索インデックスに送信して、利用可能なさまざまなクエリ機能について説明します。
クエリは sendQueries() 関数で記述されます。それを、次のとおり main 関数で呼び出します。
await sendQueries(searchClient);
クエリは search() の searchClient メソッドを使用して送信されます。 1 つ目のパラメーターは検索テキストで、2 つ目のパラメーターは検索オプションを指定します。
クエリの例 1
最初のクエリでは * を検索します。これはすべてを検索することと同じで、インデックス内のフィールドのうち 3 つが選択されます。 不要なデータをプルするとクエリでの待ち時間が長くなる可能性があるため、必要なフィールドのみ select することをお勧めします。
このクエリでは、searchOptions の includeTotalCount が true に設定されています。これにより、一致した結果の数が検出されて返されます。
async function sendQueries(
searchClient: SearchClient<Hotel>
): Promise<void> {
// Query 1
console.log('Query #1 - search everything:');
const selectFields: SearchFieldArray<Hotel> = [
"HotelId",
"HotelName",
"Rating",
];
const searchOptions1 = {
includeTotalCount: true,
select: selectFields
};
let searchResults = await searchClient.search("*", searchOptions1);
for await (const result of searchResults.results) {
console.log(`${JSON.stringify(result.document)}`);
}
console.log(`Result count: ${searchResults.count}`);
// remaining queries go here
}
以下で説明する残りのクエリも sendQueries() 関数に追加する必要があります。 ここでは読みやすいようにそれらを区切ってあります。
クエリの例 2
次のクエリでは、検索用語 "wifi" を指定します。また、状態が 'FL' と一致する結果のみが返されるようにフィルターも含めます。 さらに結果はホテルの Rating の順に並べられます。
console.log('Query #2 - search with filter, orderBy, and select:');
let state = 'FL';
const searchOptions2 = {
filter: odata`Address/StateProvince eq ${state}`,
orderBy: ["Rating desc"],
select: selectFields
};
searchResults = await searchClient.search("wifi", searchOptions2);
for await (const result of searchResults.results) {
console.log(`${JSON.stringify(result.document)}`);
}
クエリの例 3
次に、searchFields パラメーターを使用して検索が単一の検索可能なフィールドに制限されます。 この方法は、特定のフィールドとの一致にのみ関心があることがわかっている場合にクエリを効率化できる優れたオプションです。
console.log('Query #3 - limit searchFields:');
const searchOptions3 = {
select: selectFields,
searchFields: ["HotelName"] as const
};
searchResults = await searchClient.search("Sublime Palace", searchOptions3);
for await (const result of searchResults.results) {
console.log(`${JSON.stringify(result.document)}`);
}
クエリの例 4
クエリによく含められるもう 1 つのオプションは、facets です。 ファセットを使用すると、UI の結果からユーザーが自身で絞り込みを行うことができます。 ファセットの結果は、結果ウィンドウのチェック ボックスに変えることができます。
console.log('Query #4 - limit searchFields and use facets:');
const searchOptions4 = {
facets: ["Category"],
select: selectFields,
searchFields: ["HotelName"] as const
};
searchResults = await searchClient.search("*", searchOptions4);
for await (const result of searchResults.results) {
console.log(`${JSON.stringify(result.document)}`);
}
クエリの例 5
最後のクエリでは、getDocument() の searchClient メソッドを使用します。 これにより、そのキーでドキュメントを効率的に取得できます。
console.log('Query #5 - Lookup document:');
let documentResult = await searchClient.getDocument('3')
console.log(`HotelId: ${documentResult.HotelId}; HotelName: ${documentResult.HotelName}`)
クエリの概要
上記のクエリは、クエリで語句を照合する複数の方法 (フルテキスト検索、フィルター、オートコンプリート) を示しています。
フルテキスト検索とフィルターを実行するには、searchClient.search メソッドを使用します。 検索クエリは searchText 文字列で渡すことができます。一方、フィルター式は filter クラスの SearchOptions プロパティで渡すことができます。 検索せずにフィルター処理を実行するには、searchText メソッドの search パラメーターに "*" を渡します。 フィルター処理を行わずに検索するには、filter プロパティを未設定のままにするか、SearchOptions インスタンスを 1 つも渡さないようにします。
リソースをクリーンアップする
独自のサブスクリプションで作業する場合は、作成したリソースがまだ必要かどうかを判断して、プロジェクトを完了することをお勧めします。 リソースを動作させたままだと、お金がかかることがあります。 リソースは個別に削除することも、リソース グループを削除してリソースのセット全体を削除することもできます。
Azure portal では、左側のウィンドウから [すべてのリソース] または [リソース グループ] を選択することで、リソースを検索および管理できます。
無料サービスを使っている場合は、3 つのインデックス、インデクサー、およびデータソースに制限されることに注意してください。 Azure portal で個別の項目を削除して、制限を超えないようにすることができます。