Azure AI Search でインデックスを作成する
この記事では、検索インデックスのスキーマを定義し、検索サービスにプッシュする手順について説明します。 インデックスを作成すると、検索サービスに物理的なデータ構造が確立されます。 インデックスの作成後、別のタスクとしてインデックスを読み込みます。
前提条件
Search Service 共同作成者としての書き込みアクセス許可またはキーベースの認証用の管理 API キー。
インデックスを作成するデータを理解していること。 検索インデックスは、検索可能にする外部コンテンツに基づいています。 検索可能なコンテンツは、インデックス内のフィールドとして格納されます。 Azure AI 検索でどのソース フィールドを検索可能、取得可能、フィルター処理可能、ファセット可能、並べ替え可能にするのかを明確に考えておく必要があります。 ガイダンスについては、「スキーマのチェックリスト」を参照してください。
インデックスのドキュメント キー (または ID) として使用できるソース データ内の一意のフィールドも必要です。
安定したインデックスの場所。 既存のインデックスを別の検索サービスに移動することは、簡単にはできません。 アプリケーションの要件を見直し、既存の検索サービス (容量と Azure リージョン) がニーズに十分に対応していることを確認してください。 Azure AI サービスまたは Azure OpenAI に依存する場合は、必要なすべてのリソースを提供する Azure リージョンを選択します。
最後に、すべてのサービス レベルには、作成できるオブジェクトの数に関するインデックス制限があります。 たとえば、Free レベルを試している場合は、所定の期間内に 3 つのインデックスしか作成できません。 インデックス自体には、単純フィールドと複合フィールドの数について、ベクトルに関する制限とインデックスの制限があります。
ドキュメント キー
検索インデックスの作成には 2 つの要件があります。インデックスに検索サービスで一意の名前を付けることと、ドキュメント キーを設定することです。 フィールドのブール属性 key を true に設定して、ドキュメント キーを提供するフィールドを示すことができます。
ドキュメント キーは検索ドキュメントの一意識別子であり、検索ドキュメントは何かを完全に記述するフィールドのコレクションです。 たとえば、movies データ セットのインデックスを作成する場合、検索ドキュメントには、1 つのムービーのタイトル、ジャンル、再生時間が含まれます。 ムービー名はこのデータセットで一意であるため、ムービー名をドキュメント キーとして使用することも考えられます。
Azure AI 検索では、ドキュメント キーは文字列です。これは、インデックス作成の対象コンテンツを提供するデータ ソース内の一意の値を元にする必要があります。 一般的なルールとして、検索サービスはキー値を生成しませんが、一部のシナリオ (Azure テーブル インデクサーなど) では、インデックス作成されるドキュメントに対して一意のキーを作成するために既存の値を合成します。 もう 1 つのシナリオは、チャンクまたはパーティション分割されたデータに対する 1 対多のインデックス作成です。この場合、各チャンクに対してドキュメント キーが生成されます。
新しいコンテンツと更新されたコンテンツのインデックスだけが作成される増分インデックス作成では、新しいキーを持つ着信ドキュメントは追加されますが、既存のキーを持つ着信ドキュメントは、インデックス フィールドが null か値が設定されているかに応じて、マージまたは上書きされます。
ドキュメント キーに関する重要なポイントは次のとおりです。
- キー フィールドの値の最大長は 1,024 文字です。
- インデックスごとにキー フィールドとして正確に 1 つのフィールドを選択する必要があり、その型は
Edm.Stringである必要があります。 key属性の既定値は、単純フィールドの場合は false、複合フィールドの場合は null です。
キー フィールドを使用して、ドキュメントを直接検索したり、特定のドキュメントを更新または削除したりできます。 ドキュメントの検索やインデックス作成を行うとき、キー フィールドの値は大文字と小文字を区別して処理されます。 詳細については、ドキュメントの取得 (REST) に関する記事とドキュメントのインデックス指定による処理 (REST) に関する記事を参照してください。
スキーマのチェックリスト
このチェックリストは、検索インデックスの設計上の決定を行う際に役立ちます。
インデックス名とフィールド名が名前付けルールに準拠するように、名前付け規則を確認します。
サポートされていないデータ型を確認します。 データ型は、フィールドの使用方法に影響します。 たとえば、数値コンテンツはフィルター可能ですが、フルテキスト検索はできません。 最も一般的なデータ型は、検索可能な
Edm.Stringテキストです。これは、フルテキスト検索エンジンを使用してトークン化され、クエリが実行されます。 ベクトル フィールドの最も一般的なデータ型はEdm.Singleですが、他の型も使用できます。ドキュメント キーを確認します。 ドキュメント キーはインデックス要件です。 これは、一意の値を含むソース データ フィールドから設定される単一の文字列フィールドです。 たとえば、Blob Storage からインデックスを作成する場合、メタデータ ストレージ パスは、コンテナー内の各 BLOB を一意に識別するため、ドキュメント キーとしてよく使用されます。
インデックス内の検索可能なコンテンツに作用するデータ ソース内のフィールドを特定します。
検索可能な非ベクトル コンテンツには、フルテキスト検索エンジンを使用してクエリを実行する短い文字列または長い文字列が含まれます。 コンテンツが詳細である (小さなフレーズまたは大きなチャンク) 場合は、さまざまなアナライザーを試して、テキストがどのようにトークン化されるのか確認します。
検索可能なベクトル コンテンツは、数学的表現として存在する画像またはテキスト (任意の言語) にすることができます。 狭いデータ型またはベクトル圧縮を使用して、ベクトル フィールドを小さくすることができます。
フィールドに設定される属性 (
retrievable、filterableなど) が、検索動作と、検索サービスでのインデックスの物理的な表現の両方を決定します。 フィールドの属性付けの決定は、多くの開発者にとって反復的なプロセスになります。 反復処理の速度を上げるには、簡単に削除して再構築できるサンプル データから始めます。フィルターとして使用できるソース フィールドを特定します。 数値コンテンツと短いテキスト フィールド (特に繰り返し値を持つフィールド) は、優れた選択肢です。 フィルターを使用する場合は、次のことを覚えておいてください。
フィルターはベクトルおよび非ベクトル クエリで使用できますが、フィルター自体はインデックス内の英数字 (非ベクトル) フィールドに適用されます。
フィルター可能なフィールドは、必要に応じてファセット ナビゲーションで使用できます。
フィルター可能フィールドは任意の順序で返され、関連度スコアリングが行われないため、並べ替え可能にもすることを検討してください。
ベクトル フィールドの場合は、ベクトル検索の構成と、ナビゲーション パスの作成と埋め込みスペースの入力に使用するアルゴリズムを指定します。 詳細については、「ベクトル フィールドを追加する」を参照してください。
ベクトル フィールドには、使用するアルゴリズムやベクトル圧縮など、非ベクトル フィールドにはない追加のプロパティがあります。
ベクトル フィールドでは、並べ替え、フィルター処理、ファセット化など、ベクトル データに対して有用でない属性を省略します。
非ベクトル フィールドに対しては、既定のアナライザー (
"analyzer": null) と別のアナライザーのどちらを使用するかを決定します。 アナライザーは、インデックス作成とクエリの実行中にテキスト フィールドをトークン化するために使用されます。多言語文字列の場合は、言語アナライザーのを検討してください。
ハイフンでつながれた文字列または特殊文字の場合は、特殊なアナライザーを検討してください。 たとえば、フィールドの内容全体を 1 つのトークンとして扱う keyword です。 この動作は、郵便番号、ID、製品名などのデータで役立ちます。 詳細については、「部分的な用語検索と特殊文字を含むパターン」をご覧ください。
Note
インデックス作成中にトークン化された用語に対してフルテキスト検索が実行されます。 クエリで想定した結果が返されない場合は、トークン化をテストして、検索対象の文字列が実際に存在することを確認します。 文字列に対してさまざまなアナライザーを試して、各種アナライザーでトークンがどのように生成されるかを確認できます。
フィールド定義を構成する
フィールド コレクションは検索ドキュメントの構造を定義します。 すべてのフィールドに、名前、データ型、および属性があります。
フィールドを検索可能、フィルター可能、並べ替え可能、またはファセット可能に設定すると、インデックスのサイズとクエリのパフォーマンスに影響します。 クエリ式で参照されることを意図していないフィールドには、これらの属性を設定しないでください。
フィールドが検索可能、フィルター可能、並べ替え可能、またはファセット可能に設定されていない場合、フィールドはどのクエリ式でも参照できません。 これは、クエリでは使用されないが、検索結果には必要なフィールドに適しています。
REST API には、データ型に基づく既定の属性があります。これは、Azure portal のインポート ウィザードでも使用されます。 Azure SDK には既定値はありませんが、プロパティと動作を組み込むフィールド サブクラス (文字列の SearchableField、プリミティブの SimpleField など) があります。
REST API の既定のフィールド属性を次の表にまとめます。
| データの種類 | 検索可能 | 取得可能 | フィルター可能 | ファセット可能 | ソート可能 | 保存 |
|---|---|---|---|---|---|---|
Edm.String |
✅ | ✅ | ✅ | ✅ | ✅ | ✅ |
Collection(Edm.String) |
✅ | ✅ | ✅ | ✅ | ❌ | ✅ |
Edm.Boolean |
❌ | ✅ | ✅ | ✅ | ✅ | ✅ |
Edm.Int32、Edm.Int64、Edm.Double |
❌ | ✅ | ✅ | ✅ | ✅ | ✅ |
Edm.DateTimeOffset |
❌ | ✅ | ✅ | ✅ | ✅ | ✅ |
Edm.GeographyPoint |
✅ | ✅ | ✅ | ❌ | ✅ | ✅ |
Edm.ComplexType |
✅ | ✅ | ✅ | ✅ | ✅ | ✅ |
Collection(Edm.Single) とその他のすべてのベクトル フィールド型 |
✅ | ✅ または ❌ | ❌ | ❌ | ❌ | ✅ |
文字列フィールドは、必要に応じて、アナライザーやシノニム マップに関連付けることもできます。 フィルター可能、並べ替え可能、またはファセット可能である型 Edm.String のフィールドの長さは、最大 32 キロバイトです。 これは、このようなフィールドは 1 つの検索語句として扱われ、かつ Azure AI 検索の 1 つの用語の最大サイズが 32 キロバイトであるためです。 これより多くのテキストを単一の文字列フィールドに格納する必要がある場合は、インデックスの定義で明示的にフィルター可能、並べ替え可能、およびファセット可能を false に設定する必要があります。
ベクトル フィールドは、次元とベクトル プロファイルに関連付ける必要があります。 取得可能の既定値は、ポータルでインポートとベクトル化ウィザードを使用してベクトル フィールドを追加する場合は true、そうではなく REST API を使用する場合は false です。
フィールド属性について次の表で説明します。
| 属性 | 内容 |
|---|---|
| name | 必須。 フィールドの名前を設定します。これは、インデックスまたは親フィールドのフィールド コレクション内で一意である必要があります。 |
| type | 必須。 フィールドのデータ型を設定します。 フィールドは単純にも複合にもできます。 単純フィールドは、テキストの Edm.String や整数の Edm.Int32 などのプリミティブ型です。 複合フィールドは、単純と複合のいずれかであるサブフィールドを持つことができます。 これにより、オブジェクトとオブジェクトの配列をモデル化できます。これで、ほとんどの JSON オブジェクト構造をインデックスにアップロードできます。 サポートされる型の全一覧については、「サポートされているデータ型」を参照してください。 |
| キー | 必須。 フィールドの値がインデックス内のドキュメントを一意に識別するように指定するには、この属性を true に設定します。 詳細については、この記事の「ドキュメント キー」を参照してください。 |
| retrievable | 検索結果でこのフィールドを返すことができるかどうかを示します。 あるフィールドをフィルター、並べ替え、またはスコアリングのメカニズムとして使用するが、フィールドをエンド ユーザーには表示しない場合には、この属性を false に設定します。 この属性は、キー フィールドについては true にする必要があり、複合フィールドについては null にする必要があります。 この属性は、既存のフィールドのものを変更できます。 取得可能を true に設定しても、インデックス ストレージの要件は増加しません。 既定値は、単純フィールドの場合は true、複合フィールドの場合は null です。 |
| searchable | フィールドがフルテキスト検索可能で、検索クエリで参照できるかどうかを示します。 これは、インデックス処理中に単語区切りなどの字句解析が行われることを意味します。 検索可能フィールドを "Sunny day" などの値に設定した場合、それは内部的に個別のトークン "sunny" と "day" に正規化されます。 これにより、これらの語句をフルテキスト検索できます。 型 Edm.String や Collection(Edm.String) のフィールドは、既定で検索可能になります。 この属性は、他の非文字列データ型の単純フィールドについては false にする必要があり、複合フィールドについては null にする必要があります。 検索可能なフィールドはインデックスに余分な空間を消費します。Azure AI 検索がパフォーマンスの高い検索のために、それらのフィールドの内容を処理して補助データ構造に整理するためです。 インデックスの空間を節約する必要があり、フィールドを検索に含める必要がない場合は、検索可能を false に設定してください。 詳しくは、Azure AI 検索でのフルテキスト検索のしくみに関する記事を参照してください。 |
| filterable | $filter クエリでフィールドを参照できるようにするかどうかを示します。 フィルター可能は、文字列の処理方法が検索可能とは異なります。 フィルター可能である型 Edm.String または Collection(Edm.String) のフィールドは字句解析されないため、比較は完全一致のみになります。 たとえば、フィルター可能フィールド f を "Sunny day" に設定すると、$filter=f eq 'sunny' では一致が見つかりませんが、$filter=f eq 'Sunny day' では見つかります。 この属性は、複合フィールドについては null にする必要があります。 既定値は、単純フィールドの場合は true、複合フィールドの場合は null です。 インデックス サイズを小さくするには、フィルター処理しないフィールドに対してこの属性を false に設定します。 |
| sortable | $orderby 式でフィールドを参照できるようにするかどうかを示します。 既定では、Azure AI 検索は結果をスコア順に並べ替えますが、多くの場合、ユーザーはドキュメントのフィールドで並べ替えることを望みます。 単純フィールドは、単一値 (親ドキュメントのスコープ内に 1 つの値がある) の場合にのみ並べ替えることができます。 単純コレクション フィールドは複数値であるため、並べ替えできません。 複合コレクションの単純サブフィールドも複数値であるため、並べ替えできません。 これは、それが直接の親フィールドであるか、先祖フィールドであるかに関係なくあてはまり、複合コレクションです。 複合フィールドは並べ替え可能にできないため、このようなフィールドの並べ替え可能属性は null にする必要があります。 並べ替え可能の既定値は、単一値の単純フィールドの場合は true、複数値の単純フィールドの場合は false、複合フィールドの場合は null です。 |
| facetable | ファセット クエリでフィールドを参照できるようにするかどうかを示します。 通常、カテゴリ別のヒット カウントを含む検索結果のプレゼンテーションで使用されます (たとえば、デジタル カメラを検索し、ブランド別、メガピクセル別、価格別などでヒットを表示する場合)。 この属性は、複合フィールドについては null にする必要があります。 型 Edm.GeographyPoint や Collection(Edm.GeographyPoint) のフィールドはファセット可能にできません。 他のすべての単純フィールドについては、既定値は true です。 インデックス サイズを小さくするには、ファセット処理しないフィールドに対してこの属性を false に設定します。 |
| アナライザー | インデックス処理およびクエリ操作中に文字列をトークン化するための字句解析器を設定します。 このプロパティの有効な値には、言語アナライザー、組み込みアナライザー、およびカスタム アナライザーがあります。 既定値は、standard.lucene です。 この属性は、検索可能な文字列フィールドでのみ使用できます。searchAnalyzer や indexAnalyzer とともに設定することはできません。 アナライザーが選択され、インデックスにフィールドが作成されると、そのフィールドに対して変更することはできません。 複合フィールドについては null にする必要があります。 |
| searchAnalyzer | インデックス処理とクエリに異なる字句解析器を指定するには、このプロパティを indexAnalyzer とともに設定します。 このプロパティを使用する場合は、アナライザーを null に設定し、indexAnalyzer が許可される値に設定されていることを確認します。 このプロパティの有効な値には、組み込みアナライザーとカスタム アナライザーがあります。 この属性は、検索可能フィールドでのみ使用できます。 検索アナライザーはクエリ時にのみ使用されるため、既存のフィールドのものを更新できます。 複合フィールドについては null にする必要があります。 |
| indexAnalyzer | インデックス処理とクエリに異なる字句解析器を指定するには、このプロパティを searchAnalyzer とともに設定します。 このプロパティを使用する場合は、アナライザーを null に設定し、searchAnalyzer が許可される値に設定されていることを確認します。 このプロパティの有効な値には、組み込みアナライザーとカスタム アナライザーがあります。 この属性は、検索可能フィールドでのみ使用できます。 インデックスのアナライザーが選択されると、該当フィールドに対して変更することはできません。 複合フィールドについては null にする必要があります。 |
| synonymMaps | このフィールドに関連付けるシノニム マップの名前の一覧。 この属性は、検索可能フィールドでのみ使用できます。 現在は、フィールドごとに 1 つのみのシノニム マップがサポートされます。 フィールドにシノニム マップを割り当てると、そのフィールドを対象とするクエリ用語が、クエリ時にシノニム マップのルールを使用して展開されます。 この属性は、既存のフィールドのものを変更できます。 複合フィールドについては、null または空のコレクションにする必要があります。 |
| fields | これが型 Edm.ComplexType や Collection(Edm.ComplexType) のフィールドである場合のサブフィールドの一覧。 単純フィールドについては、null または空にする必要があります。 サブフィールドを使用する方法とタイミングの詳細については、Azure AI 検索で複合データ型をモデル化する方法に関する記事を参照してください。 |
インデックスを作成する
インデックスを作成する準備ができたら、要求を送信できる検索クライアントを使用します。 早期開発と概念実証テストには、Azure portal または REST API を使用できます。それ以外の場合は、Azure SDK を使用するのが一般的です。
開発時に、頻繁な再構築を計画します。 物理構造はサービス内で作成されるため、変更のほとんどにおいてインデックスの削除と再作成が必要になります。 リビルドを高速化するために、データのサブセットを使って作業することを検討してもよいでしょう。
ポータルを使用したインデックスの設計では、数値フィールドに対してフルテキスト検索機能を許可しないなど、特定のデータ型に対して要件とスキーマ ルールが適用されます。
Azure portal にサインインします。
領域を確認します。 検索サービスはインデックスの最大数の影響を受けサービス レベルによって異なります。 2 番目のインデックスのための領域があることを確認します。
検索サービスの [概要] ページで、検索インデックスを作成するためのいずれかのオプションを選択します。
- [インデックスの追加] (インデックス スキーマを指定するための埋め込みエディター)
- インポート ウィザード
このウィザードは、インデクサー、データ ソース、完成したインデックスを作成するエンドツーエンドのワークフローです。 また、データも読み込まれます。 これだと目的よりも機能が多い場合は、代わりに [インデックスの追加] を使用してください。
次のスクリーンショットは、コマンド バーで [インデックスの追加]、[データのインポート]、[データのインポートとベクトル化] が表示される場所を強調表示しています。
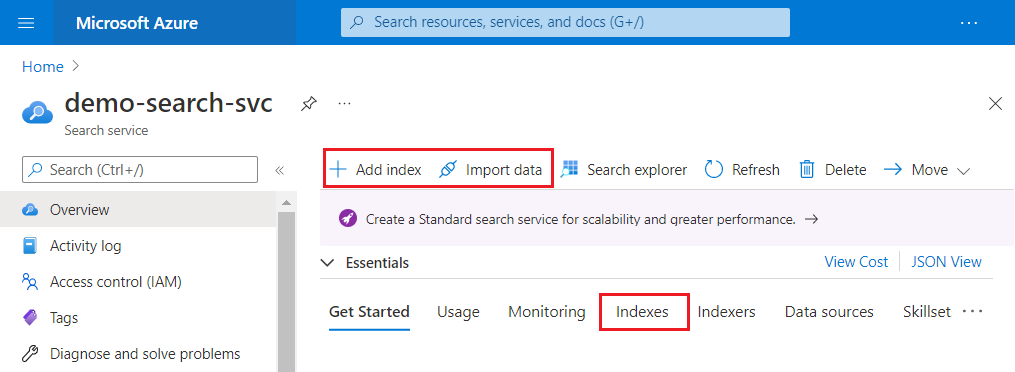
インデックスが作成されると、左側のナビゲーション ウィンドウの [インデックス] ページで再び見つけることができます。
ヒント
ポータルでインデックスを作成した後、JSON 表現をコピーしてアプリケーション コードに追加できます。
クロス オリジン クエリのために corsOptions を設定する
インデックス スキーマには、corsOptions を設定するためのセクションが含まれます。 既定では、ブラウザーではすべてのクロスオリジン要求が禁止されるので、クライアント側 JavaScript で API を呼び出すことはできません。 インデックスに対するクロスオリジン クエリを許可するには、corsOptions 属性を設定することによって、CORS (クロスオリジン リソース共有) を有効にします。 セキュリティ上の理由から、CORS がサポートされているのはクエリ API だけです。
"corsOptions": {
"allowedOrigins": [
"*"
],
"maxAgeInSeconds": 300
CORS には次のプロパティを設定できます。
allowedOrigins (必須): インデックスへのアクセスが許可されるオリジンのリストです。 これらのオリジンから提供される JavaScript コードは、インデックスのクエリを実行できます (呼び出し元が有効なキーを提示するか、アクセス許可を持っている場合)。 各オリジンの標準的な形式は
protocol://<fully-qualified-domain-name>:<port>ですが、多くの場合<port>は省略されます。 詳細については、「クロス オリジン リソース共有 (Wikipedia) 」を参照してください。すべてのオリジンにアクセスを許可する場合は、allowedOrigins 配列の唯一の要素として
*を指定します。 "運用環境の検索サービスに対してはこれは推奨されません" が、開発およびデバッグでは役に立つことがよくあります。maxAgeInSeconds (省略可能): (省略可能): ブラウザーはこの値を使用して、CORS プレフライト応答をキャッシュする期間 (秒) を決定します。 負ではない整数を指定する必要があります。 キャッシュ期間が長いほどパフォーマンスは向上しますが、CORS ポリシーを有効にするために必要な時間が長くなります。 この値が設定されていない場合は、既定の期間として 5 分が使用されます。
既存のインデックスに対して許可される更新
インデックスの作成では、検索サービスに物理データ構造 (ファイルと逆インデックス) を作成します。 インデックスの作成後、インデックスの作成または更新を使用して変更を有効にできるかどうかは、その変更によってこれらの物理構造が無効になるかどうかに応じて決まります。 ほとんどのフィールド属性は、インデックスにフィールドが作成された後は変更できません。
アプリケーション コードのチャーンを最小化するために、検索インデックスに対する安定した参照として機能するインデックスの別名を作成できます。 インデックス名でコードを更新する代わりに、インデックスの別名を更新して、新しいインデックス バージョンを指すようにできます。
設計プロセスのチャーンを最小限に抑えるために、次の表で、スキーマに固定される要素と、柔軟性のある要素を説明します。 固定要素を変更するにはインデックスを再構築する必要がありますが、柔軟性のある要素は物理実装に影響を与えることなくいつでも変更できます。 詳細については、インデックスの更新または再構築に関する記事を参照してください。
| 要素 | 更新可能かどうか |
|---|---|
| 名前 | いいえ |
| キー | いいえ |
| フィールド名と型 | いいえ |
| フィールド属性 (検索可能、フィルター可能、ファセット可能、並べ替え可能) | いいえ |
| フィールド属性 (取得可能) | はい |
| 格納済み (ベクトルに適用) | いいえ |
| Analyzer | インデックス内のカスタム アナライザーを追加および変更できます。 文字列フィールドでのアナライザーの割り当てについては、searchAnalyzer のみを変更できます。 その他すべての割り当てと変更には、再構築が必要です。 |
| スコアリング プロファイル | はい |
| Suggesters | いいえ |
| クロスオリジン リソース共有 (CORS) | はい |
| 暗号化 | はい |
| シノニム マップ | はい |
| セマンティック構成 | はい |
次のステップ
インデックスに追加できる特殊な機能については、次のリンクを参照してください。
- ベクトル フィールドとベクトル プロファイルの追加
- スコアリング プロファイルの追加
- セマンティック ランク付けの追加
- suggester の追加
- シノニム マップの追加
- アナライザーの追加
- 暗号化の追加
インデックスの読み込みまたは更新には、次のリンクを使用してください。