この記事では、Azure AI 検索 でのクエリとインデックス作成のパフォーマンスを分析するためのツール、動作、方法について説明します。
この記事は 、従来の検索、フルテキスト検索のシナリオにのみ適用されます。
ベースラインの数を作り出す
大規模な実装では、Azure AI 検索 サービスを運用環境に展開する前に、そのパフォーマンス ベンチマーク テストを実行することが重要です。 予想される検索クエリの負荷だけでなく、予想されるデータ インジェスト ワークロードもテストする必要があります (可能な場合は両方のワークロードを同時に実行します)。 ベンチマークの数値を使用すると、適切な検索レベル、サービス構成、予想されるクエリの待機時間を検証できます。
分散サービス アーキテクチャの効果を特定するには、1 つのレプリカと 1 つのパーティションからなるサービス構成でテストしてみてください。
Note
ストレージ最適化レベル (L1 および L2) では、Standard レベルよりもクエリ スループットが低く、待機時間が長くなります。
リソース ログの使用
管理者が利用できる最も重要な診断ツールはリソース ログです。 リソース ログは、検索サービスに関するオペレーショナル データとメトリックのコレクションです。 リソース ログは、Azure Monitor で有効にします。 Azure Monitor の使用やデータの格納に関連するコストが発生しますが、お使いのサービスに対して有効にすると、パフォーマンスの問題を調査するときに役立つ場合があります。
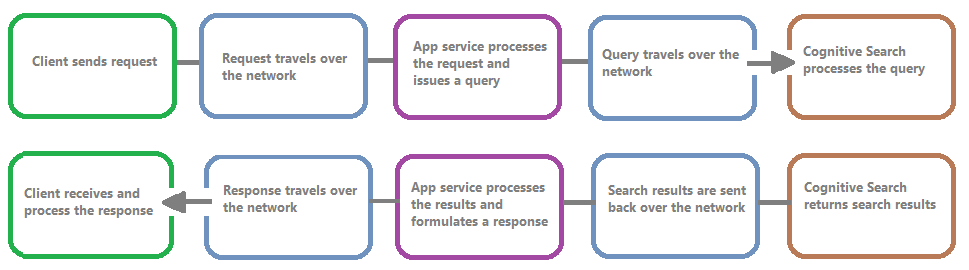
次の図は、クエリ要求と応答における一連のイベントを示しています。 待機時間は、ネットワーク転送中、アプリ サービス レイヤーでのコンテンツの処理中、または検索サービス上で、いずれの段階でも発生する可能性があります。 リソース ログの主な利点は、検索サービスの観点からアクティビティがログに記録されることです。つまり、パフォーマンスの問題の原因がクエリやインデックス作成に関する問題にあるのか、それともその他の障害点にあるのかを判断するのにこのログが役立ちます。
リソース ログには、ログに記録された情報を格納するためのオプションがあります。 Log Analytics を使用することをお勧めします。データに対する高度な kusto クエリを実行して、使用状況やパフォーマンスに関するさまざまな問題を解決できるようになります。
検索サービスのポータル ページで、[診断設定] を使用してログ記録を有効にした後、[ログ] を選択して Log Analytics に対する kusto クエリを発行できます。 リソース ログを Log Analytics ワークスペースに送信し、ログ クエリを使用して分析する方法については、「Azure リソースからリソース ログを収集して分析する」を参照してください。
調整動作
検索サービスが容量の上限に達すると、調整が行われます。 調整は、クエリまたはインデックス作成の実行中に行われる可能性があります。 クライアント側からは、API 呼び出しが抑えられたときに 503 HTTP 応答が生成されます。 インデックス作成中に 207 HTTP 応答を受け取ることがあります。これは、1 つ以上の項目のインデックス作成に失敗したことを示します。 このエラーは、検索サービスが容量の上限に近づきつつあることを示しています。
経験則として、調整の量とパターンを定量化することをお勧めします。 たとえば、500,000 件の検索クエリのうち 1 件が調整された場合、調査する価値がない可能性があります。 一方、クエリの大部分が一定期間にわたって抑えられている場合、これは大きな問題になります。 一定期間にわたって調整を調べると、調整が行われやすい時間帯を特定したり、それに対応する最適な方法を判断したりするのにも役立ちます。
調整に関するほとんどの問題を簡単に解決する方法は、検索サービスでより多くのリソースを投入することです (通常、クエリベースの調整ではレプリカ、インデックスベースの調整ではパーティション)。 ただし、レプリカやパーティションを増やすとコストが増大します。調整が行われている原因を把握することが重要なのはそのためです。 次のいくつかのセクションでは、調整の原因となる状況の調査方法について説明します。
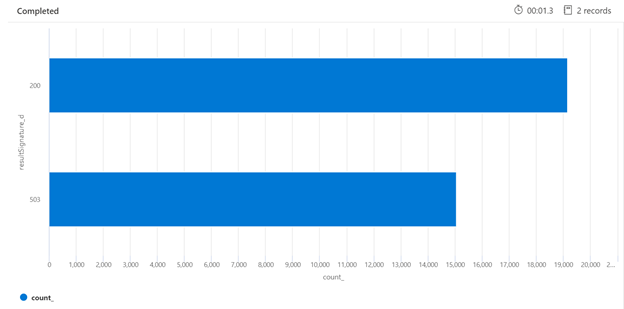
以下に示す Kusto クエリの例では、読み込み中の検索サービスからの HTTP 応答の内訳を確認できます。 7 日間の期間に対してレンダリングされた横棒グラフは、成功した (200) 応答の数と比較して、かなりの割合の検索クエリが抑えられたことを示しています。
AzureDiagnostics
| where TimeGenerated > ago(7d)
| summarize count() by resultSignature_d
| render barchart
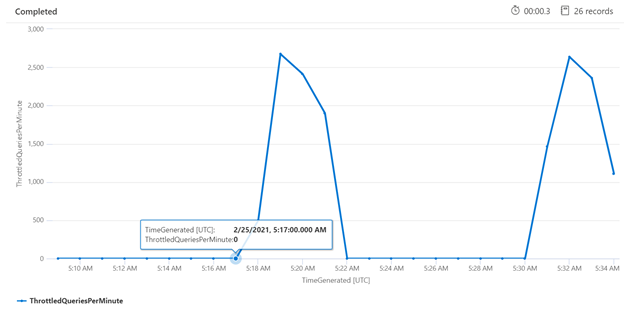
特定の期間にわたって調整を調べることは、調整が頻繁に行われやすい時間を特定するのに役立ちます。 以下の例では、時系列グラフを使用して、指定された期間にわたって発生した、抑えられたクエリの数を示しています。 この例では、抑えられたクエリは、パフォーマンス ベンチマークが実行された時間と関連がありました。
let ['_startTime']=datetime('2024-02-25T20:45:07Z');
let ['_endTime']=datetime('2024-03-03T20:45:07Z');
let intervalsize = 1m;
AzureDiagnostics
| where TimeGenerated > ago(7d)
| where resultSignature_d != 403 and resultSignature_d != 404 and OperationName in ("Query.Search", "Query.Suggest", "Query.Lookup", "Query.Autocomplete")
| summarize
ThrottledQueriesPerMinute=bin(countif(OperationName in ("Query.Search", "Query.Suggest", "Query.Lookup", "Query.Autocomplete") and resultSignature_d == 503)/(intervalsize/1m), 0.01)
by bin(TimeGenerated, intervalsize)
| render timechart
個々のクエリを測定する
場合によっては、個々のクエリをテストして、そのパフォーマンスを確認することが役立つことがあります。 このためには、検索サービスで作業が完了するまでにかかる時間と、クライアントからラウンドトリップ要求を行って、クライアントに戻るまでにかかる時間を確認できることが重要です。 診断ログを使用して個々の操作を検索することもできますが、これをすべて REST クライアントから行う方が簡単かもしれません。
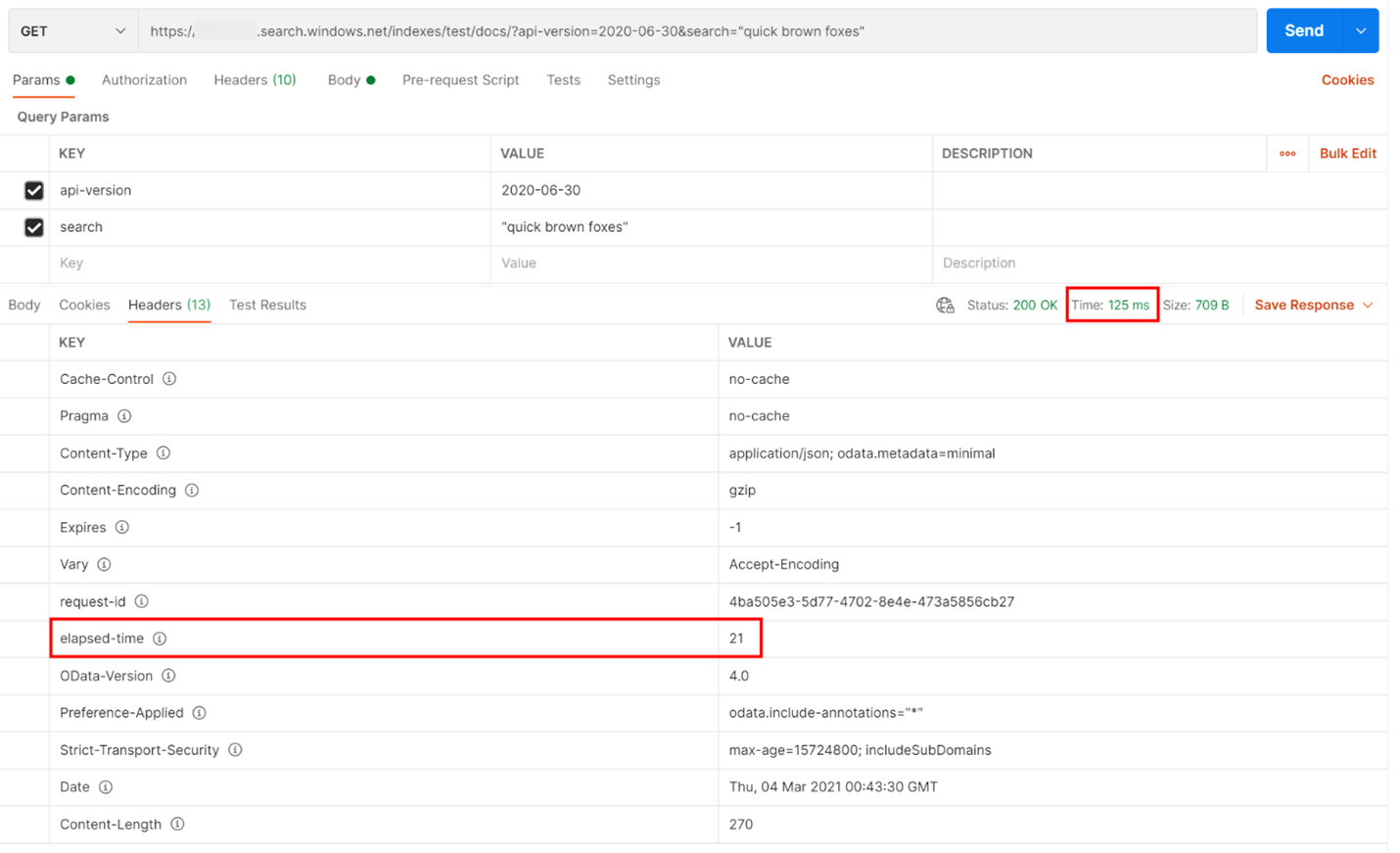
以下の例では、REST ベースの検索クエリが実行されました。 Azure AI 検索 では、クエリを完了するのにかかった時間 (ミリ秒) をどの応答にも含めています ([ヘッダー] タブの [経過時間] に表示されます)。 応答の上部にある [状態] の横に、ラウンドトリップ期間 (この場合は 125 ミリ秒) が表示されます。 結果セクションで、[ヘッダー] タブが選択されました。 以下の図の赤いボックスで強調表示された 2 つの値を使用すると、検索サービスでその検索クエリを完了するのに 21 ミリ秒かかったことと、クライアントのラウンドトリップ要求全体の所要時間が 125 ミリ秒だったことがわかります。 この 2 つの数値を差し引くことによって、検索クエリを検索サービスに送信し、検索結果をクライアントに送り返すのに 104 ミリ秒の追加時間がかかったことがわかります。
この手法は、クエリのパフォーマンスに影響を与える他の要因からネットワークの待機時間を特定するのに役立ちます。
クエリ速度
検索サービスによって要求が抑えられる原因の 1 つと考えられるのは、量が 1 秒あたりのクエリ数 (QPS) または 1 分あたりのクエリ数 (QPM) としてキャプチャされる、膨大な数のクエリが実行されることです。 検索サービスで受信される QPS が増えるにつれて、通常、そうしたクエリへの応答にかかる時間が長くなり、その状態を維持できなくなると、調整用の 503 HTTP 応答が返されます。
次の Kusto クエリでは、QPM 単位で計測されるクエリ量を、ミリ秒単位のクエリの平均実行時間 (AvgDurationMS) とそれぞれで返される平均ドキュメント数 (AvgDocCountReturned) と共に示しています。
AzureDiagnostics
| where OperationName == "Query.Search" and TimeGenerated > ago(1d)
| extend MinuteOfDay = substring(TimeGenerated, 0, 16)
| project MinuteOfDay, DurationMs, Documents_d, IndexName_s
| summarize QPM=count(), AvgDuractionMs=avg(DurationMs), AvgDocCountReturned=avg(Documents_d) by MinuteOfDay
| order by MinuteOfDay desc
| render timechart
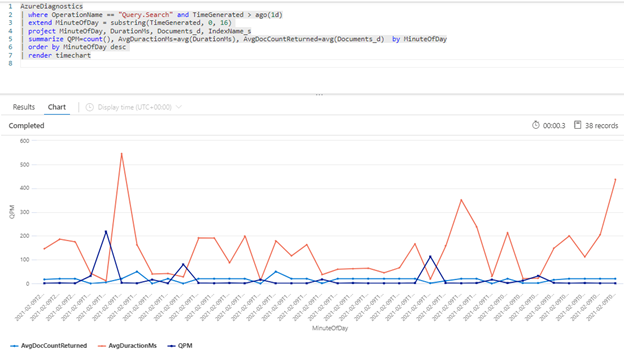
Tip
このグラフの背後にあるデータを表示するには、| render timechart 行を削除してから、クエリを再実行します。
クエリへのインデックス作成の影響
パフォーマンスを調べるときに考慮すべき重要な要素は、インデックス作成で検索クエリと同じリソースが使われることです。 大量のコンテンツのインデックスを作成している場合、サービスで両方のワークロードに対応しようとするのに伴って待機時間が長くなることが予想されます。
クエリの速度が低下している場合は、インデックス作成アクティビティの実施時期を調べて、それがクエリの低下と重なっていないかどうかを確認します。 たとえば、検索クエリのパフォーマンスの低下に関係する日単位または時間単位のジョブがインデクサーによって実行されているのかもしれません。
ここでは、検索とインデックス作成の速度を視覚化するのに役立つ一連のクエリをご紹介します。 これらの例では、クエリ内に時間範囲が設定されています。 Azure portal でクエリを実行する場合は、[クエリに設定] を必ず指定してください。
クエリの平均待機時間
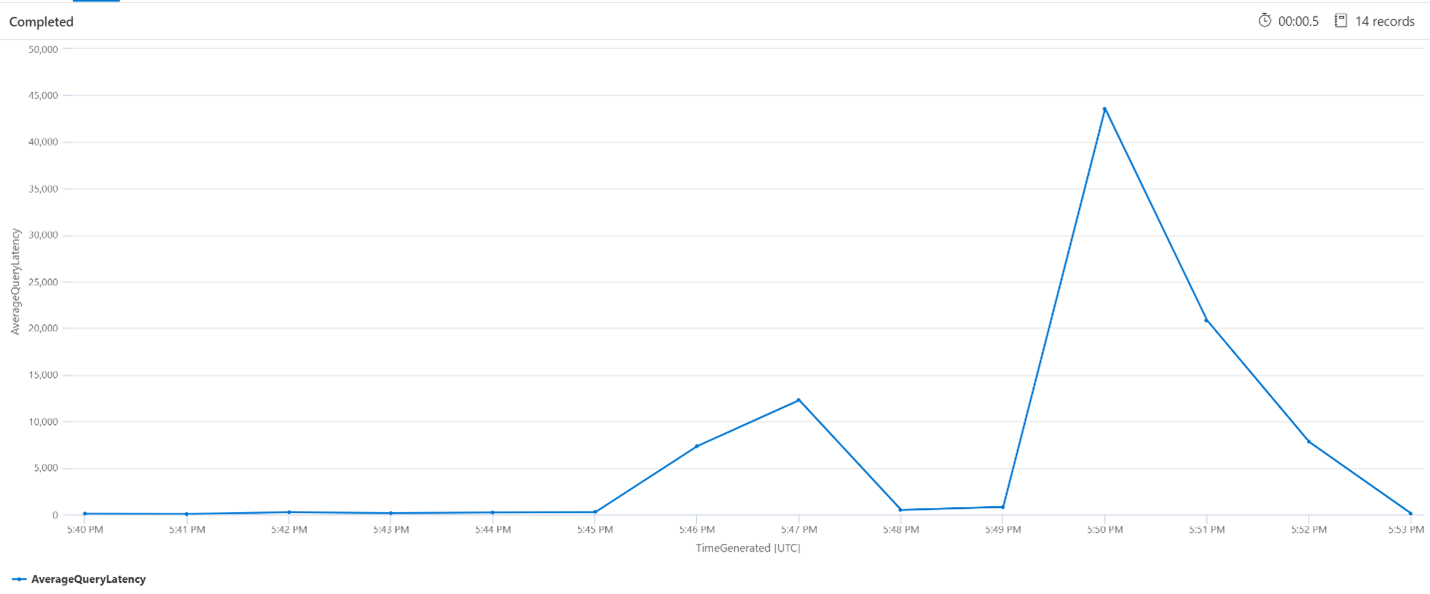
以下のクエリでは、間隔のサイズを 1 分間に設定した場合の検索クエリの平均待機時間を示しています。 このグラフから、平均待機時間が午後 5: 45 までは短く、午前 5: 53 までは長い状態が継続していたことがわかります。
let intervalsize = 1m;
let _startTime = datetime('2024-02-23 17:40');
let _endTime = datetime('2024-02-23 18:00');
AzureDiagnostics
| where TimeGenerated between(['_startTime']..['_endTime']) // Time range filtering
| summarize AverageQueryLatency = avgif(DurationMs, OperationName in ("Query.Search", "Query.Suggest", "Query.Lookup", "Query.Autocomplete"))
by bin(TimeGenerated, intervalsize)
| render timechart
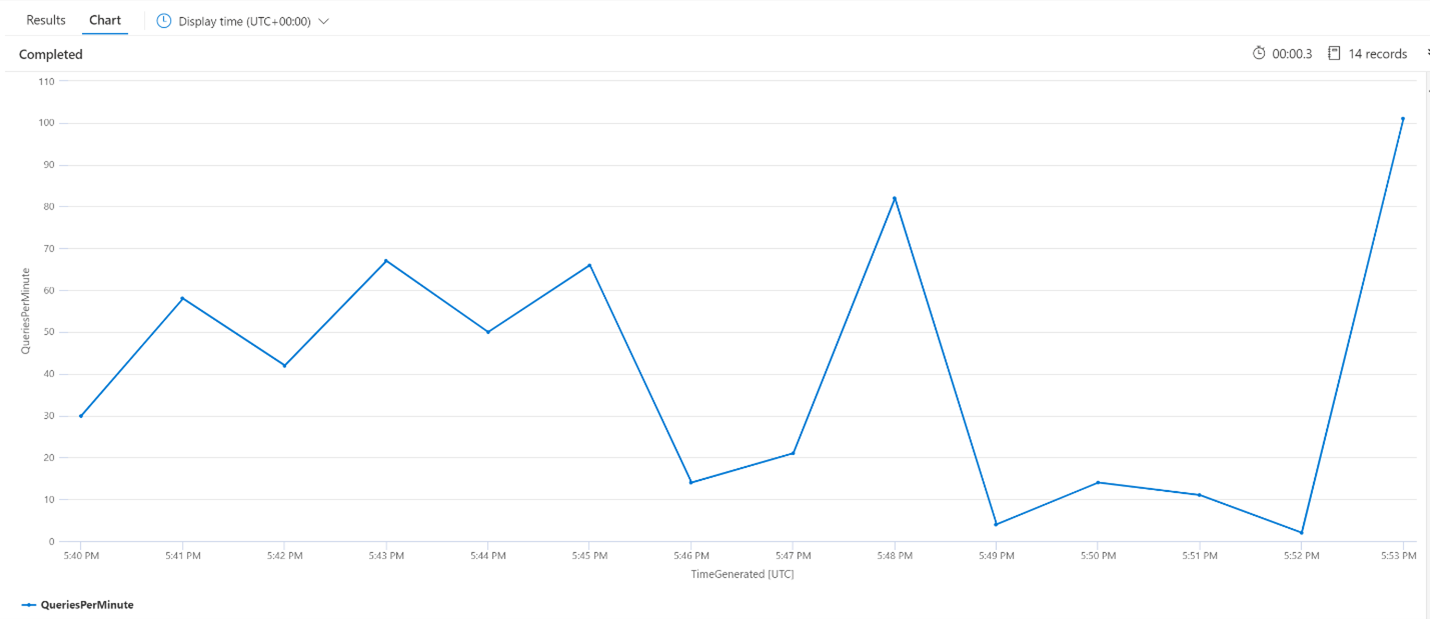
平均 QPM (1 分あたりのクエリ数)
次のクエリを使用して、1 分あたりの平均クエリ数を調べて、待機時間に影響を与える可能性のある検索要求のスパイクがなかったことを確認します。 このグラフから、多少の分散があることがわかりますが、要求数のスパイクを示すものはありません。
let intervalsize = 1m;
let _startTime = datetime('2024-02-23 17:40');
let _endTime = datetime('2024-02-23 18:00');
AzureDiagnostics
| where TimeGenerated between(['_startTime'] .. ['_endTime']) // Time range filtering
| summarize QueriesPerMinute=bin(countif(OperationName in ("Query.Search", "Query.Suggest", "Query.Lookup", "Query.Autocomplete"))/(intervalsize/1m), 0.01)
by bin(TimeGenerated, intervalsize)
| render timechart
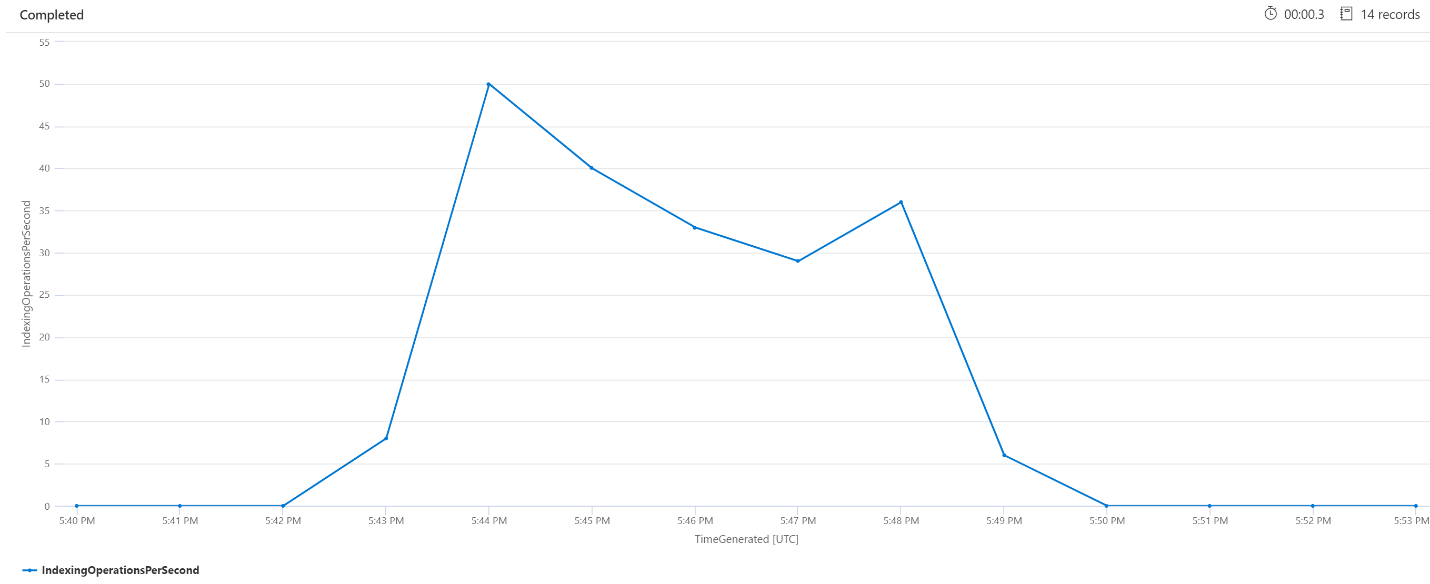
インデックス作成の 1 分あたりの操作回数 (OPM)
ここでは、1 分あたりのインデックス作成操作の回数を調べます。 このグラフから、午後 5:42 から午後 5: 50 の間に大量のデータのインデックス作成が行われたことがわかります。 このインデックス作成は、検索クエリが潜在的な状態になり始める 3 分前に開始され、検索クエリが潜在的な状態でなくなる 3 分前に終了しました。
この分析から、検索サービスがビジー状態になり、インデックス作成がクエリの待機時間に影響を及ぼすまでに約 3 分かかったことがわかります。 また、インデックス作成が完了した後、新しくインデックスが作成されたコンテンツのすべての作業が検索サービスで完了し、クエリの待機時間が解決されるまでにさらに 3 分かかったこともわかります。
let intervalsize = 1m;
let _startTime = datetime('2024-02-23 17:40');
let _endTime = datetime('2024-02-23 18:00');
AzureDiagnostics
| where TimeGenerated between(['_startTime'] .. ['_endTime']) // Time range filtering
| summarize IndexingOperationsPerSecond=bin(countif(OperationName == "Indexing.Index")/ (intervalsize/1m), 0.01)
by bin(TimeGenerated, intervalsize)
| render timechart
バックグラウンド サービスの処理
クエリやインデックス作成の待機時間がときどき急増するのはよくあることです。 スパイクは、インデックス作成や高速クエリに応じて発生する可能性がありますが、マージ操作中に発生することもあります。 検索インデックスは、チャンクまたはシャード単位で格納されます。 システムでは定期的に、小さいシャードをマージして大きいシャードにしており、これがサービスのパフォーマンスを最適化するのに役立つことがあります。 また、このマージ プロセスでは、これまでにインデックスから削除対象としてマークされていたドキュメントをクリーンアップして、ストレージ領域の回復を図ります。
シャードのマージは高速ですが、リソースを大量に消費するため、サービスのパフォーマンスが低下する可能性があります。 クエリの待機時間が短時間急上昇し、その急上昇がインデックス作成対象のコンテンツに対する最近の変更と一致する場合、待機時間はシャード マージ操作によるものであると想定できます。
次のステップ
サービス パフォーマンスの分析に関連するこれらの記事を確認します。