注
Azure AI 検索は、Azure ポータル、REST API、およびAzure SDKから使用できます。 また、Foundry IQ は、エンタープライズ コンテンツを、Microsoft Foundry ポータルのエージェントの再利用可能なアクセス許可に対応したナレッジ ベースに変換するマネージド ナレッジ レイヤーです。
Azure AI 検索 では、複数のデータ ソースから 1 つの統合検索インデックスへのデータのインポート、分析、インデックス作成がサポートされています。
この C# チュートリアルでは、Azure SDK for .NET の Azure.Search.Documents クライアント ライブラリを使用して、Azure Cosmos DB インスタンスからのサンプル ホテル データのインデックスを作成します。 次に、Azure Blob Storage ドキュメントから取得したホテルの部屋の詳細とデータをマージします。 結果として、ホテルドキュメントを含むホテル検索インデックスが結合され、ルームは複雑なデータ型になります。
このチュートリアルでは、次の操作を行います。
- サンプル データをデータ ソースにアップロードする
- ドキュメント キーを識別する
- インデックスを定義して作成する
- Azure Cosmos DB のホテルのデータにインデックスを付ける
- Blob Storage からホテルの部屋データをマージする
概要
このチュートリアルでは、Azure.Search.Documents を使用して、複数のインデクサーを作成して実行します。 サンプル データを 2 つの Azure データ ソースにアップロードし、両方のソースからプルして単一の検索インデックスを設定するインデクサーを構成します。 2 つのデータ セットの値は、マージに対応するために共通のものである必要があります。 このチュートリアルでは、そのフィールドは ID です。 マッピングをサポートするための共通のフィールドがある限り、インデクサーは、さまざまなリソース (Azure SQL からの構造化データ、Blob Storage からの非構造化データ、または Azure で サポートされているデータ ソース の任意の組み合わせ) からデータをマージできます。
このチュートリアルのコードの完成版は、次のプロジェクトにあります。
前提条件
- アクティブなサブスクリプションを持つ Azure アカウント。 無料でアカウントを作成できます。
- Azure Cosmos DB for NoSQL アカウント。
- Azure Storage アカウント。
- Azure AI 検索 サービス。
- Visual Studio。
注
このチュートリアルには無料の検索サービスを使用できます。 Free レベルでは、インデックス、インデクサー、データ ソースがそれぞれ 3 つに限定されています。 このチュートリアルでは、それぞれ 1 つずつ作成します。 開始する前に、サービスで新しいリソースを受け入れる余裕があることを確認します。
サービスを準備する
このチュートリアルでは、インデックス作成とクエリに Azure AI 検索 を使用し、最初のデータ セットに Azure Cosmos DB を、2 番目のデータ セットに Azure Blob Storage を使用します。
可能である場合は、近接性と管理性を高めるために、すべてのサービスを同じリージョンおよびリソース グループ内に作成してください。 実際には、任意のリージョンにサービスを置くことができます。
このサンプルでは、7 つの架空のホテルを記述する 2 つの小さなデータ セットを使用します。 1 つのセットはホテル自体を記述し、Azure Cosmos DB データベースに読み込まれます。 もう 1 つのセットにはホテルルームの詳細が含まれており、Azure Blob Storage にアップロードされる 7 つの個別の JSON ファイルとして提供されます。
Azure Cosmos DB の使用を開始する
Azure portal で Azure Cosmos DB アカウントに移動します。
左側のウィンドウで、[ データ エクスプローラー] を選択します。
[ 新しいコンテナー>新しいデータベース] を選択します。
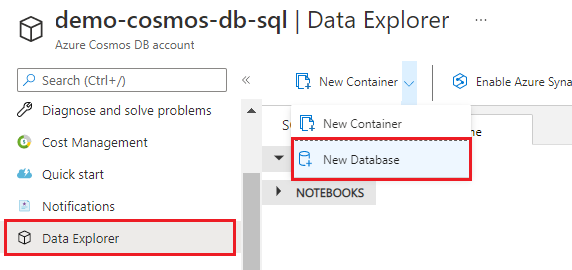
名前として 「hotel-rooms-db 」と入力します。 残りの設定の既定値をそのまま使用します。
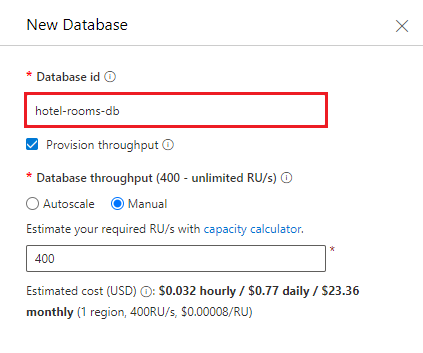
前に作成したデータベースを対象とするコンテナーを作成します。 コンテナー名の ホテル とパーティション キーの /HotelId を入力します。
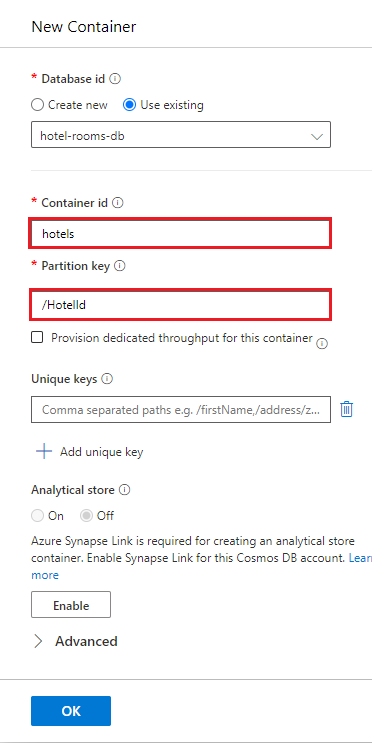
hotels>Items を選択し、コマンド バーで [アイテムのアップロード] を選択します。
cosmosdbの フォルダーから JSON ファイルをアップロードします。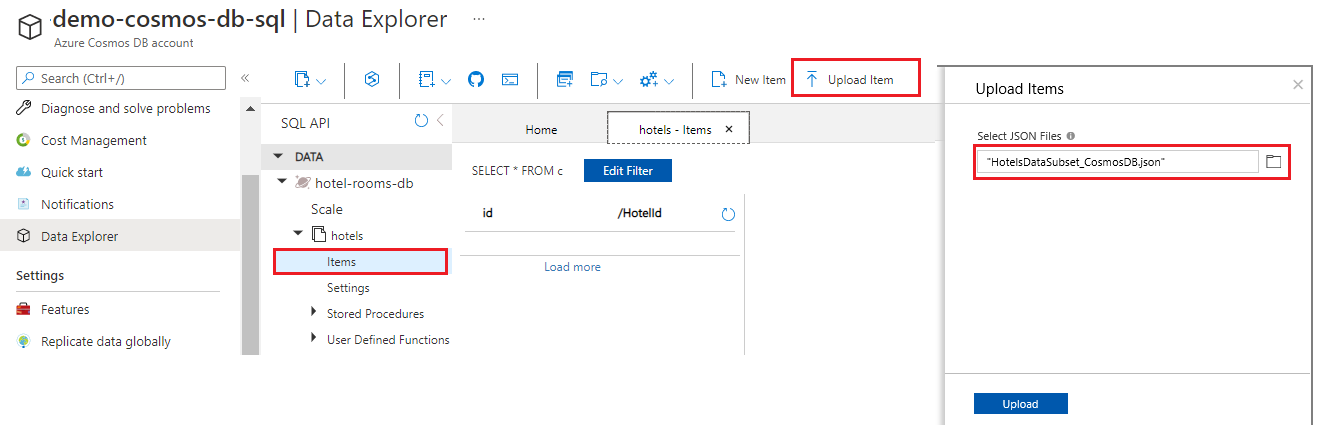
[更新] ボタンを使用して、ホテル コレクション内の項目のビューを更新します。 7 つの新しいデータベース ドキュメントが表示されることがわかります。
次に、左側のペインで [設定]>[キー] を選択します。
接続文字列を書き留めます。 この値は、後の手順で appsettings.json を活用するために必要です。 推奨される hotel-rooms-db データベース名を使用しなかった場合は、データベース名もコピーします。
Azure Blob Storage
Azure portal で Azure Storage アカウントに移動します。
左側のウィンドウで、[ データ ストレージ>Containers] を選択します。
サンプルのホテルの部屋の JSON ファイルを格納するために、hotel-rooms という名前の BLOB コンテナーを作成します。 アクセス レベルは任意の有効な値に設定できます。
コンテナーを開き、コマンド バーで [ アップロード ] を選択します。
blobの フォルダーから 7 つの JSON ファイルをアップロードします。
左側のウィンドウで、 セキュリティ + ネットワーク>Access キーを選択します。
アカウント名と接続文字列を書き留めます。 後の手順で appsettings.json には両方の値が必要です。
Azure AI 検索
3 番目のコンポーネントは Azure AI 検索であり、Azure portal で作成すること、または Azure リソースで既存の検索サービスを見つけることができます。
Azure AI 検索 の管理者キーと URL をコピーする
検索サービスに対して認証を行うには、サービス URL とアクセス キーが必要です。 有効なキーを使用すると、要求を送信するアプリケーションとそれを処理するサービスとの間で、要求ごとに信頼が確立されます。
Azure portal で、Search サービスに移動します。
左側のウィンドウで、[ 概要] を選択します。
URL を書き留めます。これは
https://my-service.search.windows.netのようになります。次に、左側のペインで [設定]>[キー] を選択します。
サービスに対する完全な権限については、管理者キーをメモしておきます。 管理キーをロールオーバーする必要がある場合に備えて、2 つの交換可能な管理キーがビジネス継続性のために提供されています。 オブジェクトの追加、変更、および削除の要求では、いずれかのキーを使用できます。
環境を設定する
Visual Studio で
AzureSearchMultipleDataSources.slnから ファイルを開きます。ソリューション エクスプローラーでプロジェクトを右クリックし、[ ソリューションの NuGet パッケージの管理...] を選択します。
[ 参照 ] タブで、次のパッケージを見つけてインストールします。
Azure.Search.Documents (バージョン 11.0 以降)
Microsoft.Extensions.Configuration
Microsoft.Extensions.Configuration.Json
ソリューション エクスプローラーで、前の手順で収集した接続情報を使用して
appsettings.jsonファイルを編集します。{ "SearchServiceUri": "<YourSearchServiceURL>", "SearchServiceAdminApiKey": "<YourSearchServiceAdminApiKey>", "BlobStorageAccountName": "<YourBlobStorageAccountName>", "BlobStorageConnectionString": "<YourBlobStorageConnectionString>", "CosmosDBConnectionString": "<YourCosmosDBConnectionString>", "CosmosDBDatabaseName": "hotel-rooms-db" }
キーフィールドのマッピング
コンテンツをマージするには、両方のデータ ストリームが検索インデックス内の同じドキュメントを対象としている必要があります。
Azure AI 検索 では、各ドキュメントがキー フィールドによって一意に識別されます。 それぞれの検索インデックスには、 Edm.String型のキー フィールドが 1 つだけ必要です。 そのキー フィールドは、インデックスに追加されるデータ ソース内のドキュメントごとに存在する必要があります。 (実際のところ、これは唯一の必須フィールドです)。
複数のデータ ソースからデータのインデックスを作成する場合は、各受信行またはドキュメントに共通のドキュメント キーが含まれていることを確認します。 これにより、2 つの物理的に異なるソース ドキュメントのデータを、結合されたインデックス内の新しい検索ドキュメントにマージできます。
多くの場合、インデックスの意味のあるドキュメント キーを識別し、両方のデータ ソースに存在することを確認するための事前計画が必要です。 このデモでは、Azure Cosmos DB の各ホテルの HotelId キーも Blob Storage の会議室の JSON BLOB に存在します。
Azure AI 検索 インデクサーでは、フィールド マッピングを使用して、インデックス作成プロセス中にデータ フィールドの名前を変更したり、データ フィールドを再フォーマットしたりすることができます。これにより、ソース データを適切なインデックス フィールドに対応させることができます。 たとえば、Azure Cosmos DB では、ホテル識別子は HotelId と呼ばれますが、ホテルの部屋の JSON BLOB ファイルでは、ホテル識別子の名前は Id です。 プログラムでは、BLOB の Id フィールドをインデクサー内の HotelId キー フィールドにマップして、この不一致を処理します。
注
ほとんどの場合、一部のインデクサーによって既定で作成されたドキュメント キーなど、自動生成されたドキュメント キーは、結合されたインデックスに適したドキュメント キーを作成しません。 一般に、データ ソースに既に存在する、または簡単に追加できる、意味のある一意のキー値を使用します。
コードを調べる
データと構成の設定が整ったら、 AzureSearchMultipleDataSources.sln のサンプル プログラムをビルドして実行する準備が整う必要があります。
この単純な C# または .NET コンソール アプリは次のタスクを実行します。
- C# Hotel クラスのデータ構造に基づいて新しいインデックスを作成します。Address クラスと Room クラスも参照します。
- 新しいデータソースと、インデックス フィールドに Azure Cosmos DB データをマップするインデクサーを作成します。 これらはどちらも Azure AI 検索 のオブジェクトです。
- インデクサーを実行して、Azure Cosmos DB からホテル データを読み込みます。
- 2 番目のデータ ソースと、JSON BLOB データをインデックス フィールドにマップするインデクサーを作成します。
- 2 番目のインデクサーを実行して、Blob Storage からホテルの部屋のデータを読み込みます。
プログラムを実行する前に、コード、インデックス定義、およびインデクサー定義を調べます。 関連するコードは次の 2 つのファイルにあります。
-
Hotel.csには、インデックスを定義するスキーマが含まれています。 -
Program.csには、Azure AI 検索 インデックス、データ ソース、インデクサーを作成し、結合された結果をインデックスに読み込む関数が含まれています。
インデックスを作成する
このサンプル プログラムでは、CreateIndexAsync を使用して、Azure AI 検索 のインデックスを定義および作成します。 FieldBuilder クラスを利用して、C# データ モデル クラスからインデックス構造を生成します。
このデータ モデルは、Address クラスと Room クラスへの参照も含む Hotel クラスで定義されています。 FieldBuilder は、複数のクラス定義をドリルダウンして、このインデックスの複雑なデータ構造を生成します。 メタデータ タグは、検索や並べ替えが可能かどうかなど、各フィールドの属性を定義するために使用されます。
この例を複数回実行する場合は、新しいインデックスを作成する前に、同じ名前の既存のインデックスが削除されます。
Hotel.cs ファイルの次のスニペットは、1 つのフィールドを示し、その後に別のデータ モデル クラス Room[] への参照を示します。このクラスは、Room.cs ファイルで定義されています (表示されません)。
. . .
[SimpleField(IsFilterable = true, IsKey = true)]
public string HotelId { get; set; }
[SearchableField(IsFilterable = true, IsSortable = true)]
public string HotelName { get; set; }
. . .
public Room[] Rooms { get; set; }
. . .
Program.cs ファイルでは、SearchIndex は、FieldBuilder.Build メソッドによって生成された名前とフィールド コレクションを使用して定義され、次のように作成されます。
private static async Task CreateIndexAsync(string indexName, SearchIndexClient indexClient)
{
// Create a new search index structure that matches the properties of the Hotel class.
// The Address and Room classes are referenced from the Hotel class. The FieldBuilder
// will enumerate these to create a complex data structure for the index.
FieldBuilder builder = new FieldBuilder();
var definition = new SearchIndex(indexName, builder.Build(typeof(Hotel)));
await indexClient.CreateIndexAsync(definition);
}
Azure Cosmos DB データ ソースとインデクサーを作成する
メイン プログラムには、ホテル データ用の Azure Cosmos DB データ ソースを作成するロジックが含まれています。
最初に、Azure Cosmos DB データベース名を接続文字列に連結します。 次に、 SearchIndexerDataSourceConnection オブジェクトを 定義します。
private static async Task CreateAndRunCosmosDbIndexerAsync(string indexName, SearchIndexerClient indexerClient)
{
// Append the database name to the connection string
string cosmosConnectString =
configuration["CosmosDBConnectionString"]
+ ";Database="
+ configuration["CosmosDBDatabaseName"];
SearchIndexerDataSourceConnection cosmosDbDataSource = new SearchIndexerDataSourceConnection(
name: configuration["CosmosDBDatabaseName"],
type: SearchIndexerDataSourceType.CosmosDb,
connectionString: cosmosConnectString,
container: new SearchIndexerDataContainer("hotels"));
// The Azure Cosmos DB data source does not need to be deleted if it already exists,
// but the connection string might need to be updated if it has changed.
await indexerClient.CreateOrUpdateDataSourceConnectionAsync(cosmosDbDataSource);
データ ソースが作成されると、 hotel-rooms-cosmos-indexerという名前の Azure Cosmos DB インデクサーがプログラムによって設定されます。
プログラムは、同じ名前の既存のインデクサーを更新し、既存のインデクサーを前のコードの内容で上書きします。 また、この例を複数回実行する場合に備えて、リセットおよび実行アクションも含められています。
次の例では、1 日に 1 回実行されるように、インデクサーのスケジュールを定義します。 今後自動的にインデクサーが再実行されないようにする場合は、この呼び出しから schedule プロパティを削除できます。
SearchIndexer cosmosDbIndexer = new SearchIndexer(
name: "hotel-rooms-cosmos-indexer",
dataSourceName: cosmosDbDataSource.Name,
targetIndexName: indexName)
{
Schedule = new IndexingSchedule(TimeSpan.FromDays(1))
};
// Indexers keep metadata about how much they have already indexed.
// If we already ran the indexer, it "remembers" and does not run again.
// To avoid this, reset the indexer if it exists.
try
{
await indexerClient.GetIndexerAsync(cosmosDbIndexer.Name);
// Reset the indexer if it exists.
await indexerClient.ResetIndexerAsync(cosmosDbIndexer.Name);
}
catch (RequestFailedException ex) when (ex.Status == 404)
{
// If the indexer does not exist, 404 will be thrown.
}
await indexerClient.CreateOrUpdateIndexerAsync(cosmosDbIndexer);
Console.WriteLine("Running Azure Cosmos DB indexer...\n");
try
{
// Run the indexer.
await indexerClient.RunIndexerAsync(cosmosDbIndexer.Name);
}
catch (RequestFailedException ex) when (ex.Status == 429)
{
Console.WriteLine("Failed to run indexer: {0}", ex.Message);
}
この例には、実行中にエラーが発生した場合にレポートするための簡単な try-catch ブロックが含まれています。
Azure Cosmos DB インデクサーの実行後、検索インデックスには、サンプルのホテル ドキュメントの完全なセットが含まれます。 ただし、Azure Cosmos DB データ ソースでは部屋の詳細が省略されているため、各ホテルの rooms フィールドは空の配列です。 次に、プログラムは Blob Storage からデータを取得し、部屋データをロードして統合します。
Blob Storage データ ソースとインデクサーを作成する
会議室の詳細を取得するために、プログラムは最初に、個々の JSON BLOB ファイルのセットを参照するように Blob Storage データ ソースを設定します。
private static async Task CreateAndRunBlobIndexerAsync(string indexName, SearchIndexerClient indexerClient)
{
SearchIndexerDataSourceConnection blobDataSource = new SearchIndexerDataSourceConnection(
name: configuration["BlobStorageAccountName"],
type: SearchIndexerDataSourceType.AzureBlob,
connectionString: configuration["BlobStorageConnectionString"],
container: new SearchIndexerDataContainer("hotel-rooms"));
// The blob data source does not need to be deleted if it already exists,
// but the connection string might need to be updated if it has changed.
await indexerClient.CreateOrUpdateDataSourceConnectionAsync(blobDataSource);
データ ソースが作成されると、次に示すように、 hotel-rooms-blob-indexerという名前の BLOB インデクサーがプログラムによって設定されます。
JSON BLOB には、 Id ではなく、 HotelId という名前のキー フィールドが含まれています。 このコードでは、FieldMapping クラスを使用して、 Id フィールド値をインデックス内の HotelId ドキュメント キーに対応させるようインデクサーに指示しています。
Blob Storage インデクサーでは 、IndexingParameters を 使用して解析モードを指定できます。 BLOB が 1 つのドキュメントを表すか、同じ BLOB 内の複数のドキュメントを表すかに応じて、さまざまな解析モードを設定する必要があります。 この例では、各 BLOB が単一の JSON ドキュメントを表すため、このコードでは json 分析モードを使用しています。 JSON BLOB 用のインデクサー解析パラメーターの詳細については、JSON BLOB のインデックス作成に関するページを参照してください。
この例では、1 日に 1 回実行されるように、インデクサーのスケジュールを定義します。 今後自動的にインデクサーが再実行されないようにする場合は、この呼び出しから schedule プロパティを削除できます。
IndexingParameters parameters = new IndexingParameters();
parameters.Configuration.Add("parsingMode", "json");
SearchIndexer blobIndexer = new SearchIndexer(
name: "hotel-rooms-blob-indexer",
dataSourceName: blobDataSource.Name,
targetIndexName: indexName)
{
Parameters = parameters,
Schedule = new IndexingSchedule(TimeSpan.FromDays(1))
};
// Map the Id field in the Room documents to the HotelId key field in the index
blobIndexer.FieldMappings.Add(new FieldMapping("Id") { TargetFieldName = "HotelId" });
// Reset the indexer if it already exists
try
{
await indexerClient.GetIndexerAsync(blobIndexer.Name);
await indexerClient.ResetIndexerAsync(blobIndexer.Name);
}
catch (RequestFailedException ex) when (ex.Status == 404) { }
await indexerClient.CreateOrUpdateIndexerAsync(blobIndexer);
try
{
// Run the indexer.
await searchService.Indexers.RunAsync(blobIndexer.Name);
}
catch (CloudException e) when (e.Response.StatusCode == (HttpStatusCode)429)
{
Console.WriteLine("Failed to run indexer: {0}", e.Response.Content);
}
インデックスには Azure Cosmos DB データベースのホテル データが既に設定されているため、BLOB インデクサーはインデックス内の既存のドキュメントを更新し、会議室の詳細を追加します。
注
両方のデータ ソースに同じキー以外のフィールドがあり、それらのフィールド内のデータが一致しない場合、インデックスには、最近実行されたインデクサーの値が含まれます。 この例では、両方のデータ ソースに HotelName フィールドが含まれています。 何らかの理由でこのフィールドのデータが異なる場合、同じキー値を持つドキュメントの場合、最近インデックスが作成されたデータ ソースの HotelName データはインデックスに格納されている値になります。
Search
プログラムを実行した後は、Azure portal の Search エクスプローラー を使用して、設定された検索インデックスを調べることができます。
Azure portal で、Search サービスに移動します。
左側のウィンドウで、[検索の管理] >[インデックス] を選択します。
インデックスの一覧から hotel-rooms-sample を選択します。
[ 検索エクスプローラー ] タブで、
Luxuryなどの用語のクエリを入力します。結果には少なくとも 1 つのドキュメントが表示されます。 このドキュメントには、
Rooms配列内の会議室オブジェクトの一覧が含まれている必要があります。
リセットして再実行する
開発の初期の実験的な段階では、設計反復のための最も実用的なアプローチは、Azure AI 検索 からオブジェクトを削除してリビルドできるようにすることです。 リソース名は一意です。 オブジェクトを削除すると、同じ名前を使用して再作成することができます。
このサンプル コードでは、プログラムを再実行できるように、既存のオブジェクトを確認し、削除または更新します。 Azure portal を使って、インデックス、インデクサー、データ ソースを削除することもできます。
リソースをクリーンアップする
自分のサブスクリプションで作業している場合は、プロジェクトの最後に、不要になったリソースを削除することをお勧めします。 リソースを稼働させたままにすると、費用がかかる場合があります。 リソースを個別に削除するか、リソース グループを削除してリソースのセット全体を削除することができます。
左側のウィンドウの [すべてのリソース] または [リソース グループ] リンクを使用して、Azure portal でリソースを検索および管理できます。
次のステップ
複数のソースからのデータの取り込みについて理解したら、Azure Cosmos DB 以降のインデクサーの構成を詳しく見てみましょう。