Azure Traffic Manager と Azure Site Recovery
Azure Traffic Manager を使用すると、アプリケーション エンドポイント全体でトラフィックの分散を制御できます。 エンドポイントは、Azure の内部または外部でホストされている、インターネットに公開されたサービスです。
Traffic Manager では、ドメイン ネーム システム (DNS) を使用して、トラフィック ルーティング方法とエンドポイントの正常性に基づいて最適なエンドポイントにクライアント要求を送信します。 Traffic Manager には、さまざまなアプリケーション ニーズと自動フェールオーバー モデルに対応する、さまざまなトラフィック ルーティング方法とエンドポイント監視オプションが用意されています。 選択されたエンドポイントに、クライアントが直接接続します。 Traffic Manager はプロキシまたはゲートウェイではなく、クライアントとサービスの間のトラフィックを認識することはありません。
この記事では、Azure Traffic Manager のインテリジェントなルーティングと、Azure Site Recovery の強力なディザスター リカバリーおよび移行機能を結合する方法について説明します。
オンプレミスから Azure へのフェールオーバー
1 つ目のシナリオでは、すべてのアプリケーション インフラストラクチャをオンプレミスの環境で実行している A 社について考えます。 ビジネス継続性とコンプライアンス上の理由から、A 社は Azure Site Recovery を使用してアプリケーションを保護することに決めました。
A 社はパブリック エンドポイントでアプリケーションを実行しており、障害時にトラフィックを Azure にシームレスにリダイレクトする機能を必要としています。 Azure Traffic Manager の優先順位トラフィック ルーティング方法を使うと、A 社はこのフェールオーバー パターンを簡単に実装できます。
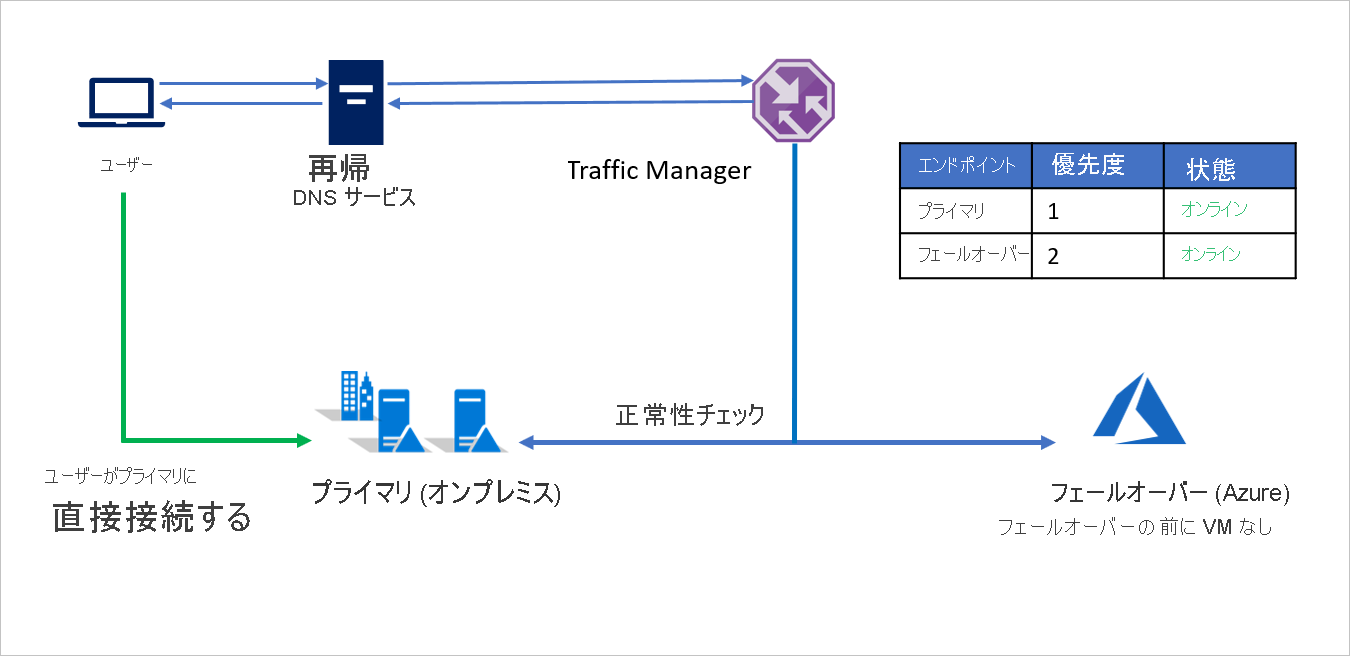
セットアップは次のとおりです。
- A 社は Traffic Manager プロファイルを作成します。
- 優先順位ルーティング方法を利用して、A 社は、オンプレミス用の Primary と Azure 用の Failover の 2 つのエンドポイントを作成します。 Primary には優先順位 1 を割り当て、Failover には優先順位 2 を割り当てます。
- Primary エンドポイントは Azure の外部でホストされているため、エンドポイントは外部エンドポイントとして作成されます。
- Azure Site Recovery では、フェールオーバーの前に Azure サイトで仮想マシンまたはアプリケーションは実行していません。 そのため、Failover エンドポイントも外部エンドポイントとして作成されます。
- 既定では、ユーザー トラフィックはエンドポイントに最も高い優先順位が関連付けられているオンプレミスのアプリケーションに送られます。 Primary エンドポイントが正常な場合、Azure にトラフィックは送られません。
障害時に、A 社は Azure へのフェールオーバーをトリガーして、アプリケーションを Azure に復旧できます。 Azure Traffic Manager は、Primary エンドポイントが正常な状態ではないことを検出すると、DNS 応答で Failover エンドポイントを自動的に使用し、ユーザーは Azure に復旧されたアプリケーションに接続します。
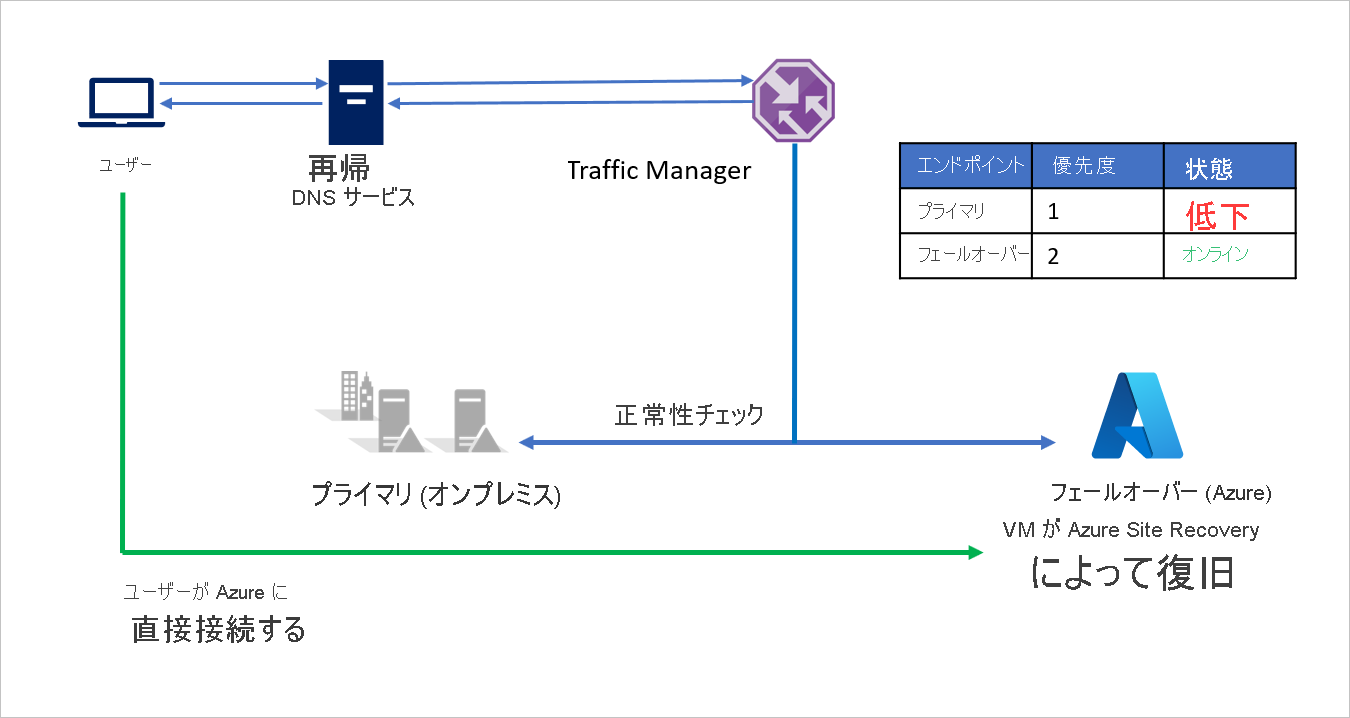
ビジネス要件によっては、A 社はより高い、またはより低いプローブ頻度を選んで障害時にオンプレミスと Azure の間を切り替え、ユーザーのダウンタイムを最小限に抑えることができます。
障害がなくなると、A 社は Azure Site Recovery を使って Azure からオンプレミス環境にフェールバックできます (VMware または Hyper-V)。 Traffic Manager は、Primary エンドポイントが再び正常になったことを検出すると、自動的に DNS 応答で Primary エンドポイントを利用するようになります。
オンプレミスから Azure への移行
ディザスター リカバリーだけでなく、Azure Site Recovery を使って Azure に移行することもできます。 Azure Site Recovery の強力なテスト フェールオーバー機能を使うと、オンプレミスの環境に影響を与えずに、Azure でアプリケーションのパフォーマンスを評価できます。 移行する準備が整ったら、ワークロード全体の一括移行または段階的な移行とスケーリングのどちらかを選ぶことができます。
Azure Traffic Manager の加重ルーティング方法を使うと、受信トラフィックの一部だけを Azure に送り、大部分のトラフィックをオンプレミス環境に送ることができます。 この方法は、Azure に割り当てる加重を少しずつ増やして Azure のワークロードを大きくしながら、スケール パフォーマンスを評価するのに便利です。
たとえば、B 社はアプリケーション環境の一部を移動しながら残りはオンプレミスに維持する段階的な移行を選択しました。 初期段階で、環境のほとんどがオンプレミスにあるときは、オンプレミス環境に割り当てる加重を大きくします。 Traffic Manager は、使用可能なエンドポイントに割り当てられている加重に基づいてエンドポイントを返します。
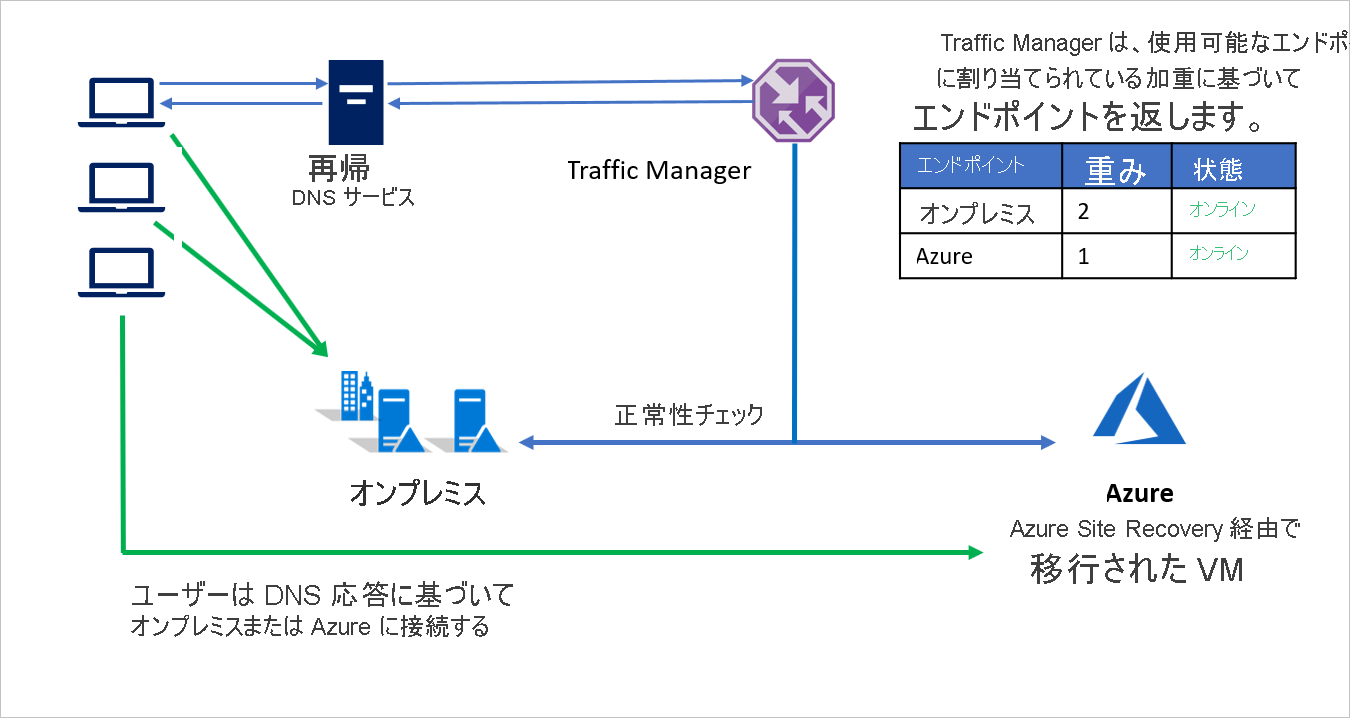
移行中は、両方のエンドポイントがアクティブで、ほとんどのトラフィックがオンプレミス環境に送られます。 移行が進むにつれて、Azure のエンドポイントに割り当てることができる加重は増えていき、最終的に移行が済むとオンプレミスのエンドポイントは非アクティブにできます。
Azure から Azure へのフェールオーバー
この例では、アプリケーション インフラストラクチャがすべて Azure にある C 社について考えます。 ビジネス継続性とコンプライアンス上の理由から、C 社は Azure Site Recovery を使用してアプリケーションを保護することに決めました。
C 社はパブリック エンドポイントでアプリケーションを実行しており、障害時にトラフィックを異なる Azure リージョンにシームレスにリダイレクトする機能を必要としています。 優先順位トラフィック ルーティング方法を使うと、C 社はこのフェールオーバー パターンを簡単に実装できます。
セットアップは次のとおりです。
- C 社は Traffic Manager プロファイルを作成します。
- 優先順位ルーティング方法を利用して、C 社は、ソース リージョン (Azure 東アジア) 用の Primary と、リカバリー リージョン (Azure 東南アジア) 用の Failover の 2 つのエンドポイントを作成します。 Primary には優先順位 1 を割り当て、Failover には優先順位 2 を割り当てます。
- Primary エンドポイントは Azure でホストされているので、エンドポイントは Azure エンドポイントにできます。
- Azure Site Recovery では、フェールオーバーの前にリカバリー Azure サイトで仮想マシンまたはアプリケーションは実行していません。 そのため、Failover エンドポイントは外部エンドポイントとして作成できます。
- 既定では、ユーザー トラフィックはエンドポイントに最も高い優先順位が関連付けられているソース リージョン (東アジア) のアプリケーションに送られます。 Primary エンドポイントが正常な場合、リカバリー リージョンにトラフィックは送られません。
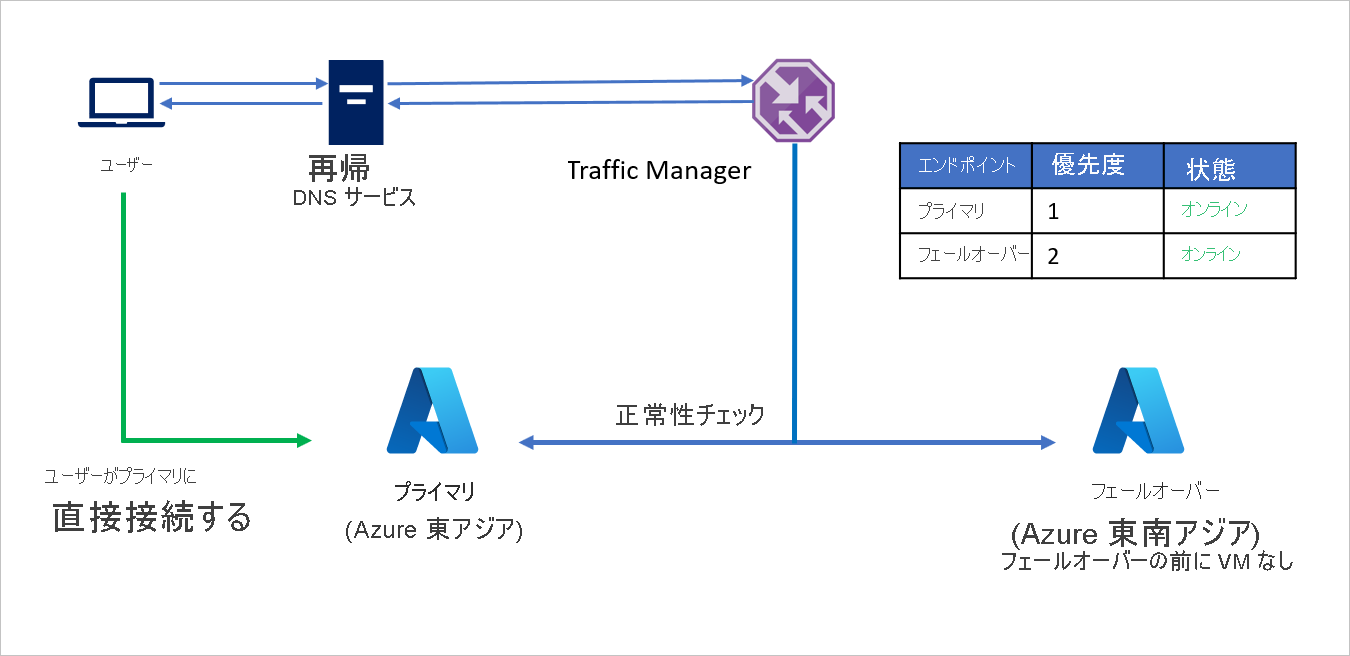
障害時に、C 社はフェールオーバーをトリガーして、アプリケーションをリカバリー Azure リージョンに復旧できます。 Azure Traffic Manager は、Primary エンドポイントが正常な状態ではないことを検出すると、DNS 応答で Failover エンドポイントを自動的に使用し、ユーザーはリカバリー Azure リージョン (東南アジア) に復旧されたアプリケーションに接続します。
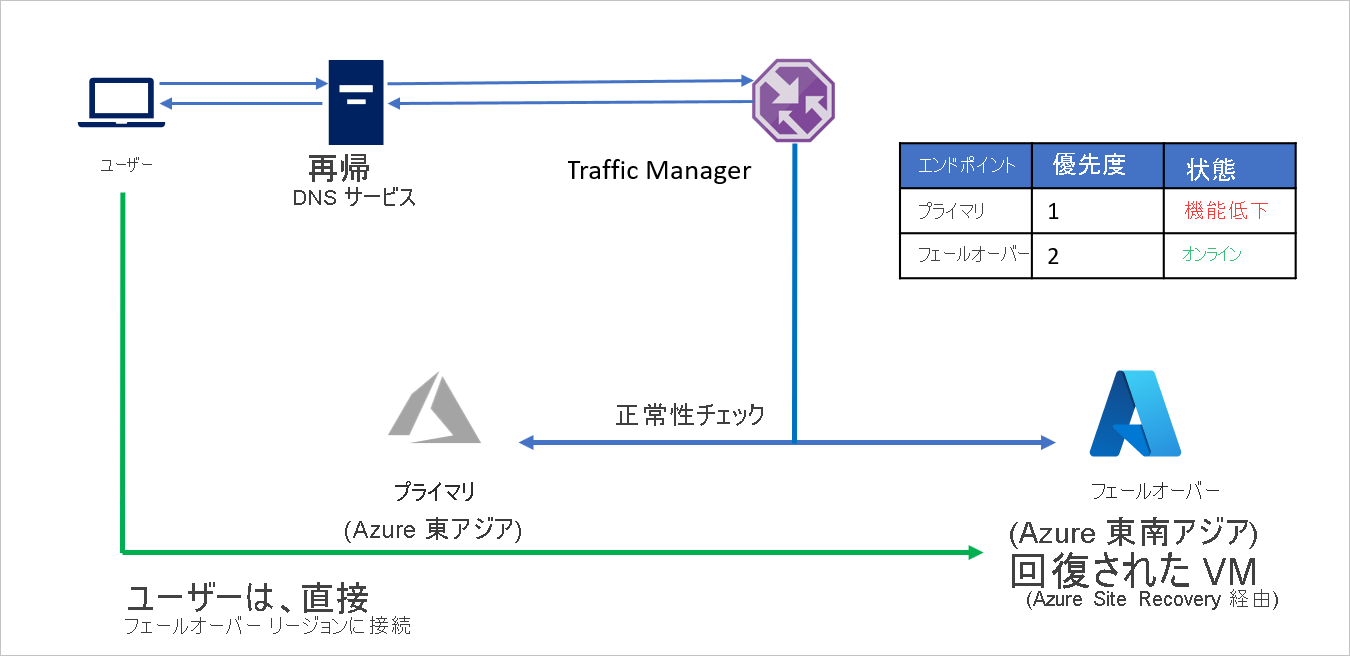
ビジネス要件によっては、C 社はより高い、またはより低いプローブ頻度を選んでソース リージョンとリカバリー リージョンの間を切り替え、ユーザーのダウンタイムを最小限に抑えることができます。
障害がなくなると、C 社は Azure Site Recovery を使ってリカバリー Azure リージョンからソース Azure リージョンにフェールバックすることができます。 Traffic Manager は、Primary エンドポイントが再び正常になったことを検出すると、自動的に DNS 応答で Primary エンドポイントを利用するようになります。
複数リージョンのエンタープライズ アプリケーションの保護
多くの場合、グローバル企業は、地域のニーズに対応するようにアプリケーションを調整することでカスタマー エクスペリエンスを向上させます。 ローカリゼーションと待機時間の削減により、アプリケーション インフラストラクチャがリージョン間で分割される場合があります。 企業は、特定の領域で各地域のデータ関連の法律によっても縛り付けられており、地域の境界内でアプリケーション インフラストラクチャの一部を分離することもあります。
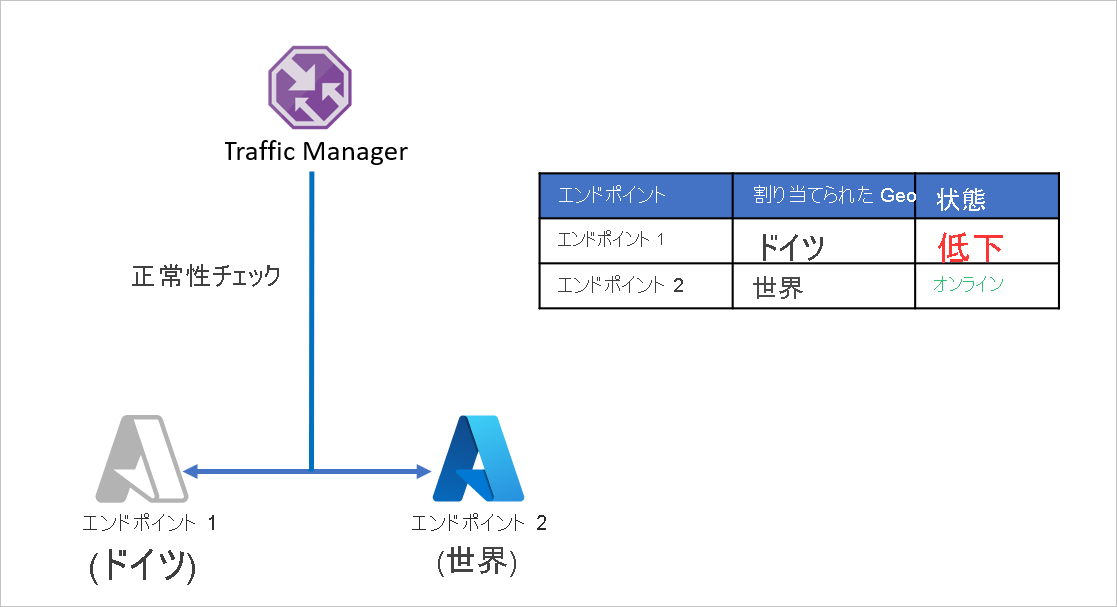
D 社は、ドイツとそれ以外でサービスを分けるため、アプリケーション エンドポイントを分割しています。 D 社は Azure Traffic Manager の地理的ルーティング方法を利用してこれをセットアップしています。 ドイツから送信されるすべてのトラフィックは Endpoint 1 に送られ、ドイツ外から送信されるトラフィックは Endpoint 2 に送られます。
このセットアップの問題は、Endpoint 1 が何らかの理由で動作を停止した場合、トラフィックが Endpoint 2 にリダイレクトされないことです。 ドイツから送信されるトラフィックはエンドポイントの正常性に関係なく Endpoint 1 にリダイレクトされ続け、ドイツのユーザーは D 社のアプリケーションにアクセスできないままになります。 同様に、Endpoint 2 がオフラインになった場合、トラフィックは Endpoint 1 にリダイレクトされません。
この問題の発生を防ぎ、アプリケーションの回復性を確保するため、D 社は Azure Site Recovery で入れ子になった Traffic Manager プロファイルを使います。 入れ子になったプロファイルの設定では、トラフィックは個別のエンドポイントにはリダイレクトされず、代わりに他の Traffic Manager プロファイルにリダイレクトされます。 このセットアップのしくみを次に示します。
- 個々のエンドポイントで地理的なルーティングを利用するのではなく、D 社は Traffic Manager プロファイルで地理的なルーティングを使います。
- 子の各 Traffic Manager プロファイルは、優先順位のルーティングをプライマリおよびリカバリー エンドポイントで利用するので、優先順位ルーティングは地理的ルーティングの中に入れ子になります。
- アプリケーションに回復性を持たせるため、各ワークロードの配分では、Azure Site Recovery を利用して障害時のリカバリー リージョンへのフェールオーバーを行います。
- 親 Traffic Manager は、DNS クエリを受信すると、関連する子 Traffic Manager にそれを送り、子は使用可能なエンドポイントでクエリに応答します。
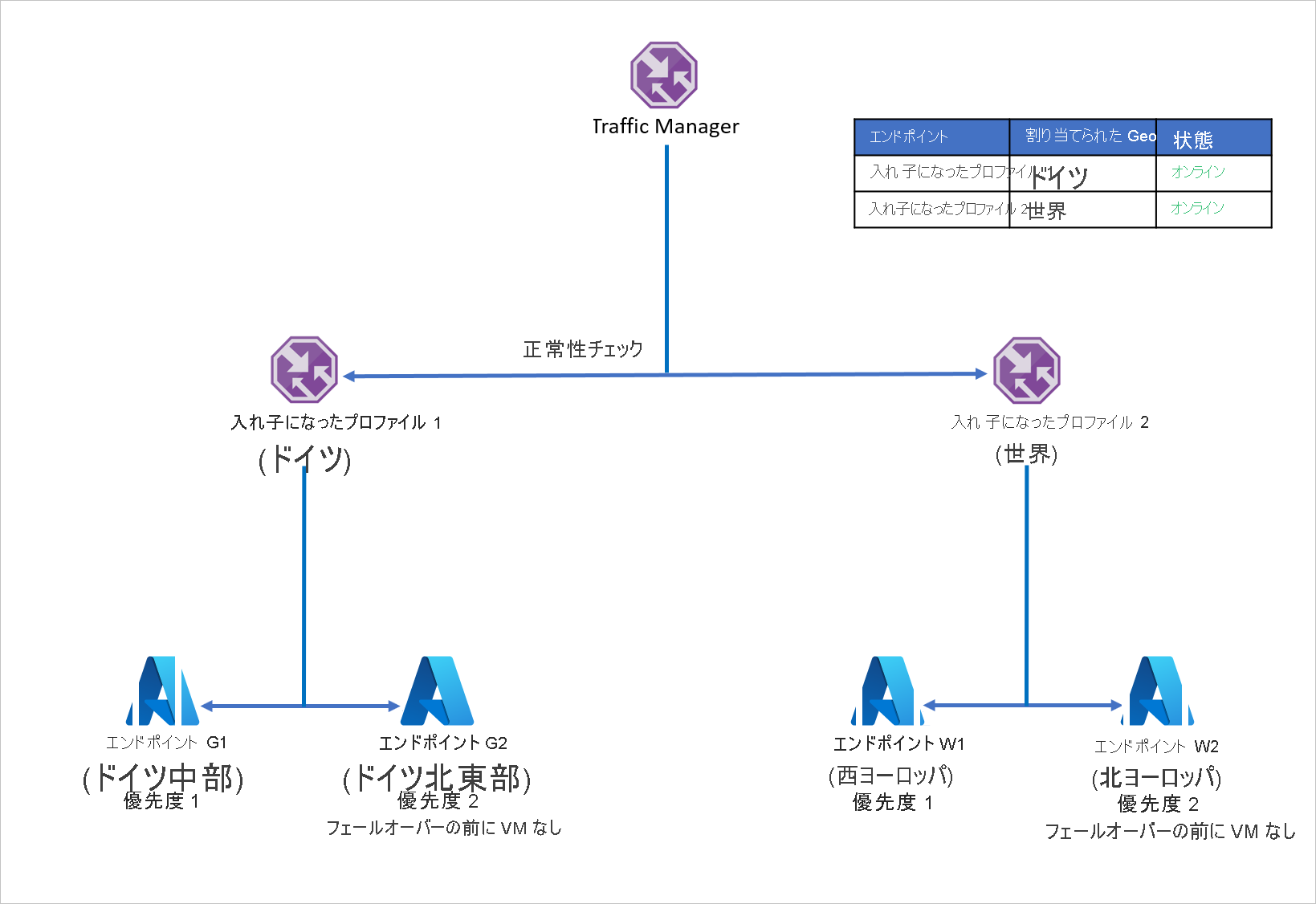
たとえば、ドイツ中部のエンドポイントで障害が発生した場合は、ドイツ北東部にアプリケーションをすばやく復旧できます。 新しいエンドポイントは、最小限のユーザー ダウンタイムで、ドイツからのトラフィックを処理します。 同様に、西ヨーロッパのエンドポイントの障害は、北ヨーロッパにアプリケーションのワークロードを復旧することによって処理でき、Azure Traffic Manager は使用可能なエンドポイントへの DNS のリダイレクトを処理します。
上記のセットアップは、必要な数のリージョンとエンドポイントの組み合わせを含むように拡張できます。 Traffic Manager は入れ子になったプロファイルを最大 10 レベルまでサポートし、入れ子になった構成内でのループは許可されません。
目標復旧時間 (RTO) に関する考慮事項
ほとんどの組織では、DNS レコードの追加または変更は、別のチームまたは組織外の誰かによって処理されます。 これにより、DNS レコード変更タスクは非常に困難になります。 DNS インフラストラクチャを管理する他のチームまたは組織による DNS レコードの更新にかかる時間は組織によって異なり、アプリケーションの RTO に影響を与えます。
Traffic Manager を利用すると、DNS の更新に必要な作業を前倒しにできます。 実際のフェールオーバーのときに、手動またはスクリプトによる操作は必要ありません。 この方法により、素早い切り替え (したがって RTO の短縮) と、障害時のコストと時間のかかる DNS 変更エラーの回避を実現できます。 他の手段では別に管理する必要があるフェールバック ステップでさえも、Traffic Manager では自動化されます。
基本間隔または高速間隔の正常性チェックによって適切なプローブ間隔を設定すると、フェールオーバー中の RTO をかなり短縮でき、ユーザーのダウンタイムを抑えることができます。
Traffic Manager プロファイルの DNS Time to Live (TTL) 値をさらにカスタマイズできます。 TTL は、DNS エントリがクライアントによってキャッシュされる値です。 レコードの場合、DNS が TTL の間に 2 回照会されることはありません。 各 DNS レコードには TTL が関連付けられています。 この値を小さくすると Traffic Manager への DNS クエリの数は増えますが、停止の検出が速くなるので RTO を短縮できます。
また、クライアントと権限のある DNS サーバーの間の DNS リゾルバーの数が増えた場合、クライアントが検出する TTL は大きくなりません。 DNS リゾルバーは TTL を "カウント ダウン" し、レコードがキャッシュされてからの経過時間を反映する TTL 値だけを渡します。 これにより、チェーン内の DNS リゾルバーの数に関係なく、DNS レコードは TTL の後でクライアントにおいて更新されます。
次のステップ
- Traffic Manager のルーティング方法の詳細を確認する。
- 入れ子になった Traffic Manager プロファイルの詳細を確認する。
- エンドポイントの監視の詳細について学習します。
- アプリケーションのフェールオーバーを自動化するための復旧計画の詳細を確認する。