はじめに
Azure Synapse Analytics の Apache Spark 用 Azure Synapse 専用 SQL プール コネクタは、Apache Spark ランタイムと専用 SQL プールの間で大規模なデータセットを効率よく転送できるようにします。 コネクタは、Azure Synapse ワークスペースに既定のライブラリとして付属しています。 コネクタは Scala 言語を使用して実装されます。 コネクタは Scala と Python をサポートしています。 他のノートブック言語でコネクタを使うには、Spark マジック コマンド %%spark を使います。
このコネクタが提供する機能の概要は次のとおりです。
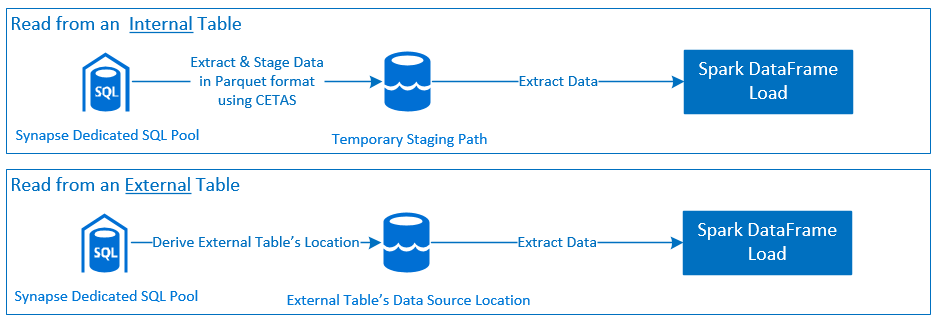
- Azure Synapse 専用 SQL プールからの読み取り:
- Synapse 専用 SQL プールのテーブル (内部および外部) とビューからの大規模データ セットの読み取り。
- 包括的な述語プッシュダウンのサポート。DataFrame のフィルターを、対応する SQL 述語プッシュダウンにマップする。
- 列の排除のサポート。
- クエリ プッシュ ダウンのサポート。
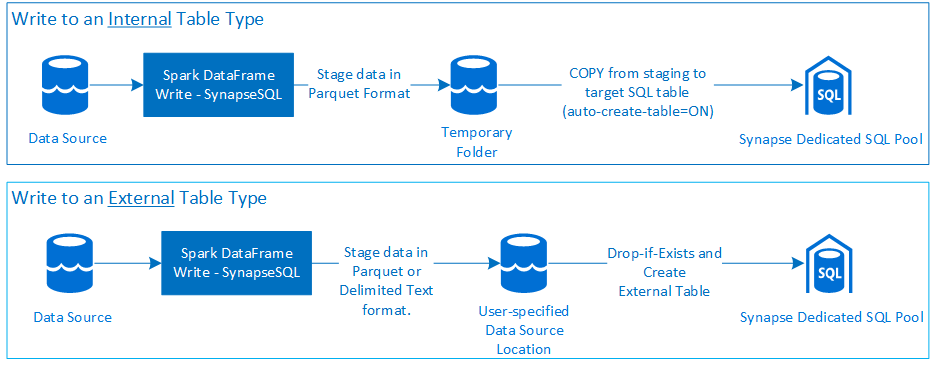
- Azure Synapse 専用 SQL プールへの書き込み:
- 内部および外部のテーブル型への大量データの取り込み。
- 次の DataFrame 保存モード設定をサポート。
AppendErrorIfExistsIgnoreOverwrite
- Parquet および区切り文字付きテキスト ファイル形式 (CSV など) をサポートする外部テーブル型への書き込み。
- 内部テーブルにデータを書き込む場合は、CETAS/CTAS アプローチではなく新たに COPY ステートメントを使用。
- エンドツーエンドの書き込みスループットのパフォーマンスを最適化するための機能強化。
- クライアントが post-write メトリクスを受信するために使用できる、オプションのコールバック ハンドル (Scala 関数の引数) を導入。
- たとえば、レコードの数、特定のアクションが完了するまでの時間、エラーの理由など。
オーケストレーション アプローチ
お読みください
書く
前提条件
このセクションでは、必要な Azure リソースの設定やそれらの構成手順などの前提条件について説明します。
Azure リソース
次の依存する Azure リソースを確認して設定します。
- Azure Data Lake Storage - Azure Synapse ワークスペースのプライマリ ストレージ アカウントとして使用されます。
- Azure Synapse ワークスペース - ノートブックを作成し、DataFrame ベースのイングレス/エグレス ワークフローを構築してデプロイします。
- 専用 SQL プール (旧称 SQL DW) - エンタープライズ データ ウェアハウスの機能を提供します。
- Azure Synapse サーバーレス Spark プール - ジョブが Spark アプリケーションとして実行される Spark ランタイムです。
データベースを準備する
Synapse 専用 SQL プール データベースに接続し、次のセットアップ ステートメントを実行します。
Azure Synapse ワークスペースへのサインインに使用される Microsoft Entra のユーザー ID にマップされるデータベース ユーザーを作成します。
CREATE USER [username@domain.com] FROM EXTERNAL PROVIDER;コネクタがそれぞれのテーブルへの書き込みと読み取りを正常に実行できるよう、テーブルを定義するスキーマを作成します。
CREATE SCHEMA [<schema_name>];
認証
Microsoft Entra ID ベースの認証
Microsoft Entra ID ベースの認証は、統合認証アプローチです。 ユーザーには、Azure Synapse Analytics ワークスペースへの正常なログインが求められます。
[基本認証]
基本認証アプローチでは、ユーザーが username と password のオプションを構成する必要があります。 Azure Synapse 専用 SQL プールのテーブルに対する読み取りと書き込みに関連する構成パラメーターについては、「構成オプション」セクションを参照してください。
承認
Azure Data Lake Storage Gen2
Azure Data Lake Storage Gen2 へのアクセス許可を付与するには、次の 2 つの方法があります - ストレージ アカウント:
- ロールベースのアクセス制御のロール - ストレージ BLOB データ共同作成者ロール
-
Storage Blob Data Contributor Roleの割り当てにより、Azure Storage Blob コンテナーから読み取り、書き込み、削除を行うアクセス許可がユーザーに付与されます。 - RBAC は、コンテナー レベルでの粗い制御アプローチを提供します。
-
-
アクセス制御リスト (ACL)
- ACL アプローチを使用すると、指定されたフォルダーの特定のパスやファイルをきめ細かく制御できます。
- RBAC アプローチを使用してユーザーに既にアクセス許可が付与されている場合、ACL チェックは実行されません。
- ACL の アクセス許可は大きく 2 種類に分けられます。
- アクセス許可 (特定のレベルまたはオブジェクトで適用されます)。
- 既定のアクセス許可 (作成時に、すべての子オブジェクトに自動的に適用されます)。
- アクセス許可の種類には次のものが含まれます。
-
Executeは、フォルダー階層の走査または移動を許可します。 -
Readは、読み取りを許可します。 -
Writeは、書き込みを許可します。
-
- コネクタが保存場所で正常に書き込みおよび読み取りを行えるよう ACL を構成することが重要です。
注意
Synapse ワークスペース パイプラインを使ってノートブックを実行する場合は、Synapse ワークスペースの既定のマネージド ID に上記のアクセス許可を付与する必要もあります。 ワークスペースの既定のマネージド ID の名前は、ワークスペースの名前と同じです。
セキュリティで保護されたストレージ アカウントで Synapse ワークスペースを使用するには、マネージド プライベート エンドポイントをノートブックから構成する必要があります。 マネージド プライベート エンドポイントは、ADLS Gen2 ストレージ アカウントの
Private endpoint connectionsペインのNetworkingセクションから承認する必要があります。
Azure Synapse 専用 SQL プール
Azure Synapse 専用 SQL プールを正常に操作できるようにするには、専用 SQL エンドポイントで Active Directory Admin として構成されたユーザーである場合を除いて、次の承認が必要です。
読み取りシナリオ
システム ストアド プロシージャ
db_exporterを使用してユーザーにsp_addrolememberを付与します。EXEC sp_addrolemember 'db_exporter', [<your_domain_user>@<your_domain_name>.com];
書き込みシナリオ
- コネクタは、COPY コマンドを使用して、ステージングからマネージド内部テーブルの保存場所にデータを書き込みます。
こちらで説明されている必要なアクセス許可を構成します。
それと同じクイック アクセス スニペットを次に示します。
--Make sure your user has the permissions to CREATE tables in the [dbo] schema GRANT CREATE TABLE TO [<your_domain_user>@<your_domain_name>.com]; GRANT ALTER ON SCHEMA::<target_database_schema_name> TO [<your_domain_user>@<your_domain_name>.com]; --Make sure your user has ADMINISTER DATABASE BULK OPERATIONS permissions GRANT ADMINISTER DATABASE BULK OPERATIONS TO [<your_domain_user>@<your_domain_name>.com]; --Make sure your user has INSERT permissions on the target table GRANT INSERT ON <your_table> TO [<your_domain_user>@<your_domain_name>.com]
- コネクタは、COPY コマンドを使用して、ステージングからマネージド内部テーブルの保存場所にデータを書き込みます。
API のドキュメント
Apache Spark 用の Azure Synapse 専用 SQL プール コネクタ - API ドキュメント。
構成オプション
読み取りまたは書き込み操作のブートストラップとオーケストレーションが正常に行われるためには、コネクタに特定の構成パラメーターが必要です。 オブジェクト定義 - com.microsoft.spark.sqlanalytics.utils.Constants には、各パラメーター キーの標準化された定数の一覧が示されています。
使用シナリオに基づく構成オプションの一覧を次に示します。
-
Microsoft Entra ID ベースの認証を使用した読み取り
- 資格情報が自動でマップされるため、ユーザーが特定の構成オプションを指定する必要はありません。
- Azure Synapse 専用 SQL プールの対応するテーブルから読み取りを行うには、
synapsesqlメソッドに 3 つの要素から成るテーブル名引数を指定する必要があります。
-
基本認証を使用した読み取り
- Azure Synapse 専用 SQL エンドポイント
-
Constants.SERVER- Synapse 専用 SQL プール エンドポイント (サーバーの FQDN) -
Constants.USER- SQL ユーザー名。 -
Constants.PASSWORD- SQL ユーザー パスワード。
-
- Azure Data Lake Storage (Gen 2) エンドポイント - ステージング フォルダー。
-
Constants.DATA_SOURCE- データ ソースの場所パラメーターで設定されたストレージ パスは、データ ステージングに使われます。
-
- Azure Synapse 専用 SQL エンドポイント
-
Microsoft Entra ID ベースの認証を使用した書き込み
- Azure Synapse 専用 SQL エンドポイント
- 既定では、コネクタによって、
synapsesqlメソッドの 3 つの部分から成るテーブル名パラメーターで設定されるデータベース名を使って、Synapse 専用 SQL エンドポイントが推論されます。 - または、ユーザーは
Constants.SERVERオプションを使って SQL エンドポイントを指定することもできます。 エンドポイントで対応するデータベースとそれぞれのスキーマがホストされていることを確認します。
- 既定では、コネクタによって、
- Azure Data Lake Storage (Gen 2) エンドポイント - ステージング フォルダー。
- 内部テーブル型の場合:
-
Constants.TEMP_FOLDERまたはConstants.DATA_SOURCEオプションを構成します。 - ユーザーが
Constants.DATA_SOURCEオプションを指定した場合は、DataSource のlocationの値からステージング フォルダーが導出されます。 - 両方を指定した場合は、
Constants.TEMP_FOLDERオプションの値が使用されます。 - ステージング フォルダー オプションを指定しない場合は、コネクタによってランタイム構成
spark.sqlanalyticsconnector.stagingdir.prefixに基づいて導出されます。
-
- 外部テーブル型の場合:
-
Constants.DATA_SOURCEは必須の構成オプションです。 - コネクタにより、データ ソースの場所パラメーターで設定されたストレージ パスと、
locationメソッドへのsynapsesql引数の組み合わせを使って、外部テーブル データを保持するための絶対パスが導出されます。 -
locationメソッドにsynapsesql引数が指定されていない場合は、コネクタによって場所の値が<base_path>/dbName/schemaName/tableNameとして導出されます。
-
- 内部テーブル型の場合:
- Azure Synapse 専用 SQL エンドポイント
-
基本認証を使用した書き込み
- Azure Synapse 専用 SQL エンドポイント
-
Constants.SERVER- Synapse 専用 SQL プール エンドポイント (サーバーの FQDN)。 -
Constants.USER- SQL ユーザー名。 -
Constants.PASSWORD- SQL ユーザー パスワード。 -
Constants.STAGING_STORAGE_ACCOUNT_KEY(内部テーブル型のみ) またはConstants.TEMP_FOLDERSをホストするストレージ アカウントに関連付けられたConstants.DATA_SOURCE。
-
- Azure Data Lake Storage (Gen 2) エンドポイント - ステージング フォルダー。
- SQL 基本認証の資格情報は、ストレージ エンドポイントへのアクセスに適用されません。
- そのため、「Azure Data Lake Storage Gen2」セクションで説明されているように、関連するストレージ アクセス許可を割り当ててください。
- Azure Synapse 専用 SQL エンドポイント
コード テンプレート
このセクションでは、Apache Spark 用の Azure Synapse 専用 SQL プール コネクタの使用 / 起動方法を記述するための参照コード テンプレートを紹介します。
注意
Python でコネクタを使用する場合:
- コネクタは Spark 3 に対応する Python でのみサポートされています。 「具体化されたデータをセル間で使用する」を参照してください。
- Python では、コールバック ハンドルは使用できません。
Azure Synapse 専用 SQL プールからの読み取り
読み取り要求 - synapsesql メソッド シグネチャ
Microsoft Entra ID ベースの認証を使用してテーブルから読み取る
//Use case is to read data from an internal table in Synapse Dedicated SQL Pool DB
//Azure Active Directory based authentication approach is preferred here.
import org.apache.spark.sql.DataFrame
import com.microsoft.spark.sqlanalytics.utils.Constants
import org.apache.spark.sql.SqlAnalyticsConnector._
//Read from existing internal table
val dfToReadFromTable:DataFrame = spark.read.
//If `Constants.SERVER` is not provided, the `<database_name>` from the three-part table name argument
//to `synapsesql` method is used to infer the Synapse Dedicated SQL End Point.
option(Constants.SERVER, "<sql-server-name>.sql.azuresynapse.net").
//Defaults to storage path defined in the runtime configurations
option(Constants.TEMP_FOLDER, "abfss://<container_name>@<storage_account_name>.dfs.core.windows.net/<some_base_path_for_temporary_staging_folders>").
//Three-part table name from where data will be read.
synapsesql("<database_name>.<schema_name>.<table_name>").
//Column-pruning i.e., query select column values.
select("<some_column_1>", "<some_column_5>", "<some_column_n>").
//Push-down filter criteria that gets translated to SQL Push-down Predicates.
filter(col("Title").startsWith("E")).
//Fetch a sample of 10 records
limit(10)
//Show contents of the dataframe
dfToReadFromTable.show()
Microsoft Entra ID ベースの認証を使用してクエリから読み取る
注意
クエリからの読み取り中の制限事項:
- テーブル名とクエリを同時に指定することはできません。
- 選択クエリのみが許可されます。 DDL および DML SQL は使用できません。
- クエリが指定されている場合、データフレームの選択およびフィルター処理のオプションは SQL 専用プールにプッシュダウンされません。
- クエリからの読み取りは、Spark 3 でのみ使用できます。
//Use case is to read data from an internal table in Synapse Dedicated SQL Pool DB
//Azure Active Directory based authentication approach is preferred here.
import org.apache.spark.sql.DataFrame
import com.microsoft.spark.sqlanalytics.utils.Constants
import org.apache.spark.sql.SqlAnalyticsConnector._
// Read from a query
// Query can be provided either as an argument to synapsesql or as a Constant - Constants.QUERY
val dfToReadFromQueryAsOption:DataFrame = spark.read.
// Name of the SQL Dedicated Pool or database where to run the query
// Database can be specified as a Spark Config - spark.sqlanalyticsconnector.dw.database or as a Constant - Constants.DATABASE
option(Constants.DATABASE, "<database_name>").
//If `Constants.SERVER` is not provided, the `<database_name>` from the three-part table name argument
//to `synapsesql` method is used to infer the Synapse Dedicated SQL End Point.
option(Constants.SERVER, "<sql-server-name>.sql.azuresynapse.net").
//Defaults to storage path defined in the runtime configurations
option(Constants.TEMP_FOLDER, "abfss://<container_name>@<storage_account_name>.dfs.core.windows.net/<some_base_path_for_temporary_staging_folders>")
//query from which data will be read
.option(Constants.QUERY, "select <column_name>, count(*) as cnt from <schema_name>.<table_name> group by <column_name>")
synapsesql()
val dfToReadFromQueryAsArgument:DataFrame = spark.read.
// Name of the SQL Dedicated Pool or database where to run the query
// Database can be specified as a Spark Config - spark.sqlanalyticsconnector.dw.database or as a Constant - Constants.DATABASE
option(Constants.DATABASE, "<database_name>")
//If `Constants.SERVER` is not provided, the `<database_name>` from the three-part table name argument
//to `synapsesql` method is used to infer the Synapse Dedicated SQL End Point.
option(Constants.SERVER, "<sql-server-name>.sql.azuresynapse.net").
//Defaults to storage path defined in the runtime configurations
option(Constants.TEMP_FOLDER, "abfss://<container_name>@<storage_account_name>.dfs.core.windows.net/<some_base_path_for_temporary_staging_folders>")
//query from which data will be read
.synapsesql("select <column_name>, count(*) as counts from <schema_name>.<table_name> group by <column_name>")
//Show contents of the dataframe
dfToReadFromQueryAsOption.show()
dfToReadFromQueryAsArgument.show()
基本認証を使用したテーブルからの読み取り
//Use case is to read data from an internal table in Synapse Dedicated SQL Pool DB
//Azure Active Directory based authentication approach is preferred here.
import org.apache.spark.sql.DataFrame
import com.microsoft.spark.sqlanalytics.utils.Constants
import org.apache.spark.sql.SqlAnalyticsConnector._
//Read from existing internal table
val dfToReadFromTable:DataFrame = spark.read.
//If `Constants.SERVER` is not provided, the `<database_name>` from the three-part table name argument
//to `synapsesql` method is used to infer the Synapse Dedicated SQL End Point.
option(Constants.SERVER, "<sql-server-name>.sql.azuresynapse.net").
//Set database user name
option(Constants.USER, "<user_name>").
//Set user's password to the database
option(Constants.PASSWORD, "<user_password>").
//Set name of the data source definition that is defined with database scoped credentials.
//Data extracted from the table will be staged to the storage path defined on the data source's location setting.
option(Constants.DATA_SOURCE, "<data_source_name>").
//Three-part table name from where data will be read.
synapsesql("<database_name>.<schema_name>.<table_name>").
//Column-pruning i.e., query select column values.
select("<some_column_1>", "<some_column_5>", "<some_column_n>").
//Push-down filter criteria that gets translated to SQL Push-down Predicates.
filter(col("Title").startsWith("E")).
//Fetch a sample of 10 records
limit(10)
//Show contents of the dataframe
dfToReadFromTable.show()
基本認証を使用したクエリからの読み取り
//Use case is to read data from an internal table in Synapse Dedicated SQL Pool DB
//Azure Active Directory based authentication approach is preferred here.
import org.apache.spark.sql.DataFrame
import com.microsoft.spark.sqlanalytics.utils.Constants
import org.apache.spark.sql.SqlAnalyticsConnector._
// Name of the SQL Dedicated Pool or database where to run the query
// Database can be specified as a Spark Config or as a Constant - Constants.DATABASE
spark.conf.set("spark.sqlanalyticsconnector.dw.database", "<database_name>")
// Read from a query
// Query can be provided either as an argument to synapsesql or as a Constant - Constants.QUERY
val dfToReadFromQueryAsOption:DataFrame = spark.read.
//Name of the SQL Dedicated Pool or database where to run the query
//Database can be specified as a Spark Config - spark.sqlanalyticsconnector.dw.database or as a Constant - Constants.DATABASE
option(Constants.DATABASE, "<database_name>").
//If `Constants.SERVER` is not provided, the `<database_name>` from the three-part table name argument
//to `synapsesql` method is used to infer the Synapse Dedicated SQL End Point.
option(Constants.SERVER, "<sql-server-name>.sql.azuresynapse.net").
//Set database user name
option(Constants.USER, "<user_name>").
//Set user's password to the database
option(Constants.PASSWORD, "<user_password>").
//Set name of the data source definition that is defined with database scoped credentials.
//Data extracted from the SQL query will be staged to the storage path defined on the data source's location setting.
option(Constants.DATA_SOURCE, "<data_source_name>").
//Query where data will be read.
option(Constants.QUERY, "select <column_name>, count(*) as counts from <schema_name>.<table_name> group by <column_name>" ).
synapsesql()
val dfToReadFromQueryAsArgument:DataFrame = spark.read.
//Name of the SQL Dedicated Pool or database where to run the query
//Database can be specified as a Spark Config - spark.sqlanalyticsconnector.dw.database or as a Constant - Constants.DATABASE
option(Constants.DATABASE, "<database_name>").
//If `Constants.SERVER` is not provided, the `<database_name>` from the three-part table name argument
//to `synapsesql` method is used to infer the Synapse Dedicated SQL End Point.
option(Constants.SERVER, "<sql-server-name>.sql.azuresynapse.net").
//Set database user name
option(Constants.USER, "<user_name>").
//Set user's password to the database
option(Constants.PASSWORD, "<user_password>").
//Set name of the data source definition that is defined with database scoped credentials.
//Data extracted from the SQL query will be staged to the storage path defined on the data source's location setting.
option(Constants.DATA_SOURCE, "<data_source_name>").
//Query where data will be read.
synapsesql("select <column_name>, count(*) as counts from <schema_name>.<table_name> group by <column_name>")
//Show contents of the dataframe
dfToReadFromQueryAsOption.show()
dfToReadFromQueryAsArgument.show()
Azure Synapse 専用 SQL プールへの書き込み
書き込み要求 - synapsesql メソッド シグネチャ
synapsesql(tableName:String,
tableType:String = Constants.INTERNAL,
location:Option[String] = None,
callBackHandle=Option[(Map[String, Any], Option[Throwable])=>Unit]):Unit
Microsoft Entra ID ベースの認証を使用した書き込み
次の包括的なコード テンプレートには、書き込みシナリオでコネクタを使用する方法が記述されています。
//Add required imports
import org.apache.spark.sql.DataFrame
import org.apache.spark.sql.SaveMode
import com.microsoft.spark.sqlanalytics.utils.Constants
import org.apache.spark.sql.SqlAnalyticsConnector._
//Define read options for example, if reading from CSV source, configure header and delimiter options.
val pathToInputSource="abfss://<storage_container_name>@<storage_account_name>.dfs.core.windows.net/<some_folder>/<some_dataset>.csv"
//Define read configuration for the input CSV
val dfReadOptions:Map[String, String] = Map("header" -> "true", "delimiter" -> ",")
//Initialize DataFrame that reads CSV data from a given source
val readDF:DataFrame=spark.
read.
options(dfReadOptions).
csv(pathToInputSource).
limit(1000) //Reads first 1000 rows from the source CSV input.
//Setup and trigger the read DataFrame for write to Synapse Dedicated SQL Pool.
//Fully qualified SQL Server DNS name can be obtained using one of the following methods:
// 1. Synapse Workspace - Manage Pane - SQL Pools - <Properties view of the corresponding Dedicated SQL Pool>
// 2. From Azure portal, follow the bread-crumbs for <Portal_Home> -> <Resource_Group> -> <Dedicated SQL Pool> and then go to Connection Strings/JDBC tab.
//If `Constants.SERVER` is not provided, the value will be inferred by using the `database_name` in the three-part table name argument to the `synapsesql` method.
//Like-wise, if `Constants.TEMP_FOLDER` is not provided, the connector will use the runtime staging directory config (see section on Configuration Options for details).
val writeOptionsWithAADAuth:Map[String, String] = Map(Constants.SERVER -> "<dedicated-pool-sql-server-name>.sql.azuresynapse.net",
Constants.TEMP_FOLDER -> "abfss://<storage_container_name>@<storage_account_name>.dfs.core.windows.net/<some_temp_folder>")
//Setup optional callback/feedback function that can receive post write metrics of the job performed.
var errorDuringWrite:Option[Throwable] = None
val callBackFunctionToReceivePostWriteMetrics: (Map[String, Any], Option[Throwable]) => Unit =
(feedback: Map[String, Any], errorState: Option[Throwable]) => {
println(s"Feedback map - ${feedback.map{case(key, value) => s"$key -> $value"}.mkString("{",",\n","}")}")
errorDuringWrite = errorState
}
//Configure and submit the request to write to Synapse Dedicated SQL Pool (note - default SaveMode is set to ErrorIfExists)
//Sample below is using AAD-based authentication approach; See further examples to leverage SQL Basic auth.
readDF.
write.
//Configure required configurations.
options(writeOptionsWithAADAuth).
//Choose a save mode that is apt for your use case.
mode(SaveMode.Overwrite).
synapsesql(tableName = "<database_name>.<schema_name>.<table_name>",
//For external table type value is Constants.EXTERNAL
tableType = Constants.INTERNAL,
//Optional parameter that is used to specify external table's base folder; defaults to `database_name/schema_name/table_name`
location = None,
//Optional parameter to receive a callback.
callBackHandle = Some(callBackFunctionToReceivePostWriteMetrics))
//If write request has failed, raise an error and fail the Cell's execution.
if(errorDuringWrite.isDefined) throw errorDuringWrite.get
基本認証を使用した書き込み
次のコード スニペットでは、「Microsoft Entra ID ベースの認証を使用した書き込み」セクションで説明した書き込み定義が置き換えられており、SQL 基本認証アプローチを使用して書き込み要求が送信されます。
//Define write options to use SQL basic authentication
val writeOptionsWithBasicAuth:Map[String, String] = Map(Constants.SERVER -> "<dedicated-pool-sql-server-name>.sql.azuresynapse.net",
//Set database user name
Constants.USER -> "<user_name>",
//Set database user's password
Constants.PASSWORD -> "<user_password>",
//Required only when writing to an external table. For write to internal table, this can be used instead of TEMP_FOLDER option.
Constants.DATA_SOURCE -> "<Name of the datasource as defined in the target database>"
//To be used only when writing to internal tables. Storage path will be used for data staging.
Constants.TEMP_FOLDER -> "abfss://<storage_container_name>@<storage_account_name>.dfs.core.windows.net/<some_temp_folder>")
//Configure and submit the request to write to Synapse Dedicated SQL Pool.
readDF.
write.
options(writeOptionsWithBasicAuth).
//Choose a save mode that is apt for your use case.
mode(SaveMode.Overwrite).
synapsesql(tableName = "<database_name>.<schema_name>.<table_name>",
//For external table type value is Constants.EXTERNAL
tableType = Constants.INTERNAL,
//Not required for writing to an internal table
location = None,
//Optional parameter.
callBackHandle = Some(callBackFunctionToReceivePostWriteMetrics))
基本認証アプローチでは、ソース ストレージ パスからデータを読み取るために、他の構成オプションが必要となります。 次のコード スニペットは、サービス プリンシパルの資格情報を使用して Azure Data Lake Storage Gen2 データソースから読み取りを行う例を示しています。
//Specify options that Spark runtime must support when interfacing and consuming source data
val storageAccountName="<storageAccountName>"
val storageContainerName="<storageContainerName>"
val subscriptionId="<AzureSubscriptionID>"
val spnClientId="<ServicePrincipalClientID>"
val spnSecretKeyUsedAsAuthCred="<spn_secret_key_value>"
val dfReadOptions:Map[String, String]=Map("header"->"true",
"delimiter"->",",
"fs.defaultFS" -> s"abfss://$storageContainerName@$storageAccountName.dfs.core.windows.net",
s"fs.azure.account.auth.type.$storageAccountName.dfs.core.windows.net" -> "OAuth",
s"fs.azure.account.oauth.provider.type.$storageAccountName.dfs.core.windows.net" ->
"org.apache.hadoop.fs.azurebfs.oauth2.ClientCredsTokenProvider",
"fs.azure.account.oauth2.client.id" -> s"$spnClientId",
"fs.azure.account.oauth2.client.secret" -> s"$spnSecretKeyUsedAsAuthCred",
"fs.azure.account.oauth2.client.endpoint" -> s"https://login.microsoftonline.com/$subscriptionId/oauth2/token",
"fs.AbstractFileSystem.abfss.impl" -> "org.apache.hadoop.fs.azurebfs.Abfs",
"fs.abfss.impl" -> "org.apache.hadoop.fs.azurebfs.SecureAzureBlobFileSystem")
//Initialize the Storage Path string, where source data is maintained/kept.
val pathToInputSource=s"abfss://$storageContainerName@$storageAccountName.dfs.core.windows.net/<base_path_for_source_data>/<specific_file (or) collection_of_files>"
//Define data frame to interface with the data source
val df:DataFrame = spark.
read.
options(dfReadOptions).
csv(pathToInputSource).
limit(100)
サポートされている DataFrame の保存モード
Azure Synapse 専用 SQL プールのターゲット テーブルにソース データを書き込む場合は、次の保存モードがサポートされます。
- ErrorIfExists (既定の保存モード)
- ターゲット テーブルが存在する場合は、呼び出し先に対して返された例外により書き込みが中止されます。 それ以外の場合は、ステージング フォルダーのデータで新しいテーブルが作成されます。
- 不問に付す
- ターゲット テーブルが存在する場合は、書き込みはエラーを返さずに書き込み要求を無視します。 それ以外の場合は、ステージング フォルダーのデータで新しいテーブルが作成されます。
- Overwrite
- ターゲット テーブルが存在する場合は、ターゲット テーブルの既存のデータは、ステージング フォルダーのデータに置き換えられます。 それ以外の場合は、ステージング フォルダーのデータで新しいテーブルが作成されます。
- Append
- ターゲット テーブルが存在する場合は、新しいデータがそこに追加されます。 それ以外の場合は、ステージング フォルダーのデータで新しいテーブルが作成されます。
書き込み要求のコールバック ハンドル
新しい書き込みパス API の変更により、クライアントに post-write メトリクスのキー > 値マップを提供する実験的な機能が導入されました。 メトリクスのキーは、新しいオブジェクト定義 Constants.FeedbackConstants で定義されます。 メトリクスは、コールバック ハンドル (Scala Function) を渡すことで JSON 文字列として取得できます。 次に示すのは関数シグネチャです。
//Function signature is expected to have two arguments - a `scala.collection.immutable.Map[String, Any]` and an Option[Throwable]
//Post-write if there's a reference of this handle passed to the `synapsesql` signature, it will be invoked by the closing process.
//These arguments will have valid objects in either Success or Failure case. In case of Failure the second argument will be a `Some(Throwable)`.
(Map[String, Any], Option[Throwable]) => Unit
注目すべきメトリクスを次に示します (キャメル ケースで示されています)。
WriteFailureCauseDataStagingSparkJobDurationInMillisecondsNumberOfRecordsStagedForSQLCommitSQLStatementExecutionDurationInMillisecondsrows_processed
次に示すのは、post-write メトリクスを含むサンプル JSON 文字列です。
{
SparkApplicationId -> <spark_yarn_application_id>,
SQLStatementExecutionDurationInMilliseconds -> 10113,
WriteRequestReceivedAtEPOCH -> 1647523790633,
WriteRequestProcessedAtEPOCH -> 1647523808379,
StagingDataFileSystemCheckDurationInMilliseconds -> 60,
command -> "COPY INTO [schema_name].[table_name] ...",
NumberOfRecordsStagedForSQLCommit -> 100,
DataStagingSparkJobEndedAtEPOCH -> 1647523797245,
SchemaInferenceAssertionCompletedAtEPOCH -> 1647523790920,
DataStagingSparkJobDurationInMilliseconds -> 5252,
rows_processed -> 100,
SaveModeApplied -> TRUNCATE_COPY,
DurationInMillisecondsToValidateFileFormat -> 75,
status -> Completed,
SparkApplicationName -> <spark_application_name>,
ThreePartFullyQualifiedTargetTableName -> <database_name>.<schema_name>.<table_name>,
request_id -> <query_id_as_retrieved_from_synapse_dedicated_sql_db_query_reference>,
StagingFolderConfigurationCheckDurationInMilliseconds -> 2,
JDBCConfigurationsSetupAtEPOCH -> 193,
StagingFolderConfigurationCheckCompletedAtEPOCH -> 1647523791012,
FileFormatValidationsCompletedAtEPOCHTime -> 1647523790995,
SchemaInferenceCheckDurationInMilliseconds -> 91,
SaveModeRequested -> Overwrite,
DataStagingSparkJobStartedAtEPOCH -> 1647523791993,
DurationInMillisecondsTakenToGenerateWriteSQLStatements -> 4
}
その他のコード サンプル
具体化されたデータをセル間で使用する
Spark DataFrame の createOrReplaceTempView で一時ビューを登録することにより、別のセルでフェッチされたデータにアクセスできます。
- データがフェッチされるセル (ノートブックの言語設定は
Scala)
//Necessary imports
import org.apache.spark.sql.DataFrame
import org.apache.spark.sql.SaveMode
import com.microsoft.spark.sqlanalytics.utils.Constants
import org.apache.spark.sql.SqlAnalyticsConnector._
//Configure options and read from Synapse Dedicated SQL Pool.
val readDF = spark.read.
//Set Synapse Dedicated SQL End Point name.
option(Constants.SERVER, "<synapse-dedicated-sql-end-point>.sql.azuresynapse.net").
//Set database user name.
option(Constants.USER, "<user_name>").
//Set database user's password.
option(Constants.PASSWORD, "<user_password>").
//Set name of the data source definition that is defined with database scoped credentials.
option(Constants.DATA_SOURCE,"<data_source_name>").
//Set the three-part table name from which the read must be performed.
synapsesql("<database_name>.<schema_name>.<table_name>").
//Optional - specify number of records the DataFrame would read.
limit(10)
//Register the temporary view (scope - current active Spark Session)
readDF.createOrReplaceTempView("<temporary_view_name>")
- 次に、ノートブックの言語設定を
PySpark (Python)に変更し、登録されたビュー<temporary_view_name>からデータをフェッチします
spark.sql("select * from <temporary_view_name>").show()
応答処理
synapsesql の呼び出しには、成功と失敗の 2 つの終了状態の可能性があります。 このセクションでは、各シナリオで要求応答を処理する方法について説明します。
読み取り要求の応答
完了すると、読み取り応答スニペットがセルの出力に表示されます。 現在のセルで失敗が発生すると、後続のセルの実行も取り消されます。 詳細なエラー情報は、Spark アプリケーションのログで確認できます。
書き込み要求の応答
既定では、書き込み応答はセル出力に出力されます。 失敗が発生すると、現在のセルが失敗とマークされ、後続のセルの実行は中止されます。 もう 1 つのアプローチは、コールバック ハンドル オプションを synapsesql メソッドに渡すことです。 コールバック ハンドルによって、書き込み応答にプログラムからアクセスできます。
その他の考慮事項
- Azure Synapse 専用 SQL プール テーブルから読み取る場合
- コネクタの列排除機能を利用するために、DataFrame に必要なフィルターを適用することを検討してください。
- 読み取りシナリオでは、
TOP(n-rows)クエリ ステートメントをフレーム化するときにSELECT句がサポートされません。 データを制限するときには、DataFrame の limit(.) 句を使用します。- 「具体化されたデータをセル間で使用する」セクションの例を参照してください。
- Azure Synapse 専用 SQL プール テーブルに書き込む場合
- 内部テーブル型:
- テーブルは ROUND_ROBIN データ分散を指定して作成されます。
- 列の型は、ソースからデータを読み取る DataFrame から推論されます。 文字列の列は
NVARCHAR(4000)にマップされます。
- 外部テーブル型:
- DataFrame の最初の並列処理によって、外部テーブルのデータが編成されます。
- 列の型は、ソースからデータを読み取る DataFrame から推論されます。
- Executor 間で適切にデータが分散されるようにするために、
spark.sql.files.maxPartitionBytesと DataFrame のrepartitionパラメーターを調整します。 - 大規模なデータセットを書き込む場合は、トランザクション サイズを制限する DWU パフォーマンス レベル設定の影響を考慮することが重要です。
- 内部テーブル型:
- Azure Data Lake Storage Gen2 の使用率の傾向を監視して、読み取りと書き込みのパフォーマンスに影響する可能性がある調整動作を特定します。