Azure でのミッション クリティカルなワークロードに関するアプリケーション プラットフォームの考慮事項
Azure では、高可用性アプリケーションをホストするための多くのコンピューティング サービスが提供されています。 サービスの機能と複雑さが異なります。 次に基づいてサービスを選択することをお勧めします。
- 信頼性、可用性、パフォーマンス、およびセキュリティに関する機能以外の要件。
- スケーラビリティ、コスト、操作性、複雑さなどの意思決定要因。
アプリケーション ホスティング プラットフォームの選択は、他のすべての設計領域に影響を与える重要な決定です。 たとえば、レガシまたは独自の開発ソフトウェアは、PaaS サービスやコンテナー化されたアプリケーションでは実行されない場合があります。 この制限は、コンピューティング プラットフォームの選択に影響します。
ミッション クリティカルなアプリケーションでは、複数のコンピューティング サービスを使用して、それぞれが異なる要件を持つ複数の複合ワークロードとマイクロサービスをサポートできます。
この設計領域では、コンピューティングの選択、設計、および構成のオプションに関連する推奨事項が提供されます。 また、 コンピューティング デシジョン ツリーについて理解することをお勧めします。
重要
この記事は、 Azure Well-Architected Framework のミッション クリティカルなワークロード シリーズの 一部です。 このシリーズに慣れていない場合 は、「ミッション クリティカルなワークロードとは」から始めてお勧めします。
プラットフォーム リソースのグローバル分散
ミッション クリティカルなワークロードの一般的なパターンには、グローバル リソースとリージョン リソースが含まれます。
特定の Azure リージョンに制約されていない Azure サービスは、グローバル リソースとしてデプロイまたは構成されます。 一部のユース ケースには、複数のリージョンにトラフィックを分散する、アプリケーション全体の永続的な状態を格納する、グローバルな静的データをキャッシュするなどがあります。 スケール ユニット アーキテクチャとグローバル分散の両方に対応する必要がある場合は、Azure リージョン間でリソースを最適に分散またはレプリケートする方法を検討してください。
その他のリソースは、リージョンにデプロイされます。 デプロイ スタンプの一部としてデプロイされるこれらのリソースは、通常、スケール ユニットに対応します。 ただし、リージョンには複数のスタンプを含め、スタンプには複数のユニットを含めることができます。 リージョン リソースの信頼性は、メイン ワークロードの実行を担当するため、非常に重要です。
次の図は、大まかな設計を示しています。 ユーザーは、中央のグローバル エントリ ポイントを介してアプリケーションにアクセスし、適切なリージョンデプロイ スタンプに要求をリダイレクトします。
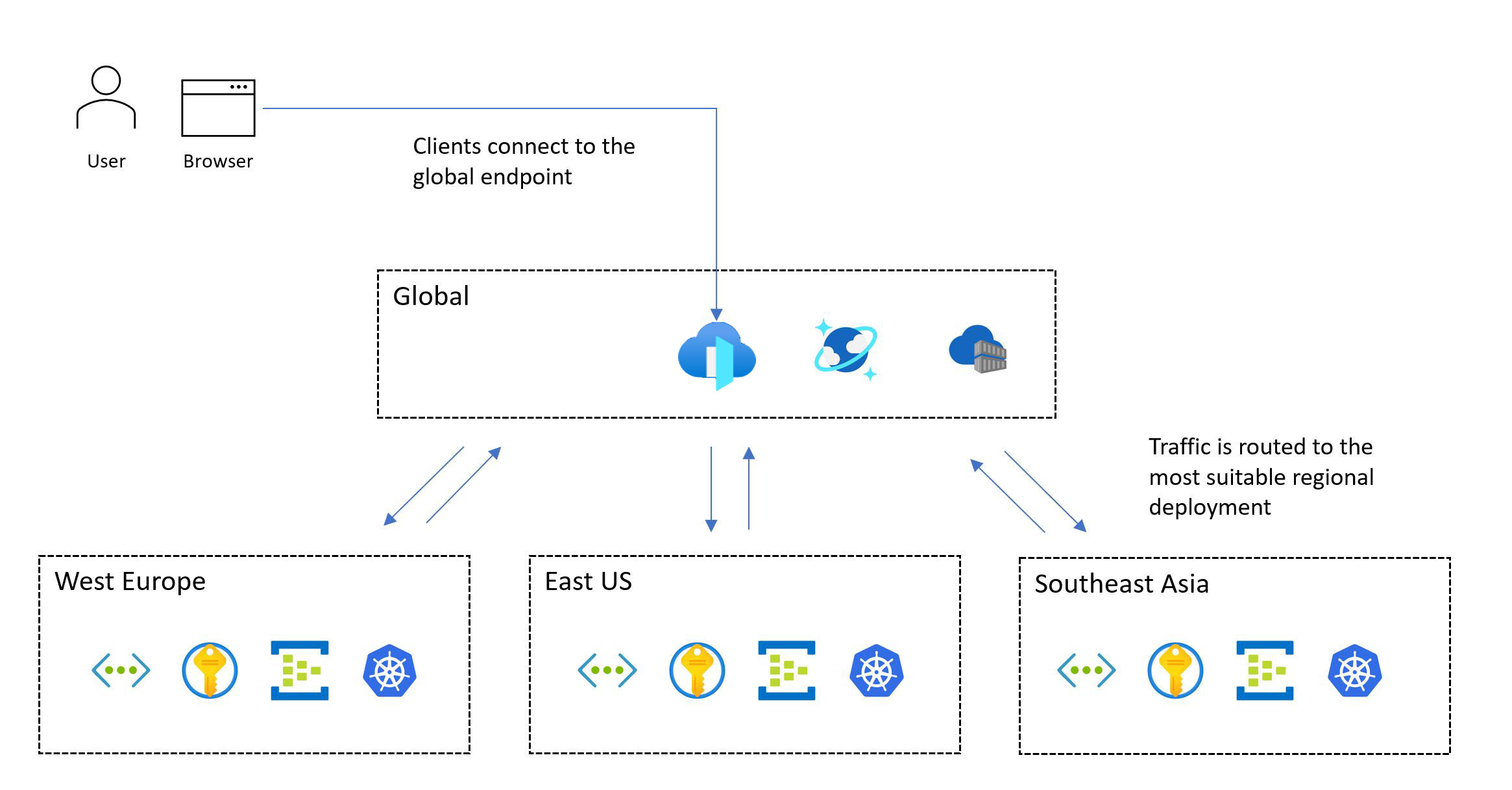
ミッション クリティカルな設計手法には、複数リージョンのデプロイが必要です。 このモデルにより、リージョン全体がダウンした場合でもアプリケーションを使用できるように、リージョンのフォールト トレランスが確保されます。 マルチリージョン アプリケーションを設計する場合は、各アプローチに大きなトレードオフがあるため、アクティブ/アクティブ/アクティブ/パッシブなどのさまざまなデプロイ戦略とアプリケーション要件を考慮してください。 ミッション クリティカルなワークロードの場合は、アクティブ/アクティブ モデルを強くお勧めします。
すべてのワークロードが複数のリージョンを同時に実行する必要やサポートしているわけではありません。 最適な設計決定を決定するには、特定のアプリケーション要件をトレードオフと比較して検討する必要があります。 信頼性のターゲットが低い特定のアプリケーション シナリオでは、アクティブ/パッシブまたはシャーディングを適切な代替手段にすることができます。
可用性ゾーン では、リージョン内の異なるデータセンター間で高可用性のリージョンデプロイを提供できます。 ほぼすべての Azure サービスは、ゾーン構成 (サービスが特定のゾーンに委任される) またはゾーン冗長構成のいずれかで使用できます。この構成では、プラットフォームによって、サービスがゾーン間で自動的に分散され、ゾーンの停止に耐えることができます。 これらの構成により、データセンター レベルまでのフォールト トレランスが提供されます。
設計上の考慮事項
地域とゾーンの機能。 すべての Azure リージョンですべてのサービスと機能を利用できるわけではありません。 この考慮事項は、選択したリージョンに影響する可能性があります。 また、 可用性ゾーン はすべてのリージョンで使用できるわけではありません。
地域ペア。 Azure リージョンは、1 つの地域の 2 つのリージョンで構成される リージョン ペア にグループ化されます。 一部の Azure サービスでは、ペアリージョンを使用してビジネス継続性を確保し、データ損失に対する保護レベルを提供します。 たとえば、Azure geo 冗長ストレージ (GRS) は、セカンダリ ペアリージョンにデータを自動的にレプリケートし、プライマリ リージョンが復旧できない場合にデータが永続的であることを確認します。 障害が複数の Azure リージョンに影響を与える場合、復旧のために、各ペアの少なくとも 1 つのリージョンが優先されます。
データの一貫性。 整合性の課題については、グローバル分散データ ストア、スタンプ付きリージョン アーキテクチャ、部分的にアクティブ/アクティブなデプロイの使用を検討してください。 部分的なデプロイでは、一部のコンポーネントはすべてのリージョンでアクティブであり、他のコンポーネントはプライマリ リージョン内に一元的に配置されます。
安全なデプロイ。 Azure の安全なデプロイ プラクティス (SDP) フレームワークを使用すると、Azure プラットフォームに対するすべてのコードと構成の変更 (計画メンテナンス) が段階的にロールアウトされます。 正常性は、リリース中の低下について分析されます。 カナリア フェーズとパイロット フェーズが正常に完了すると、プラットフォームの更新がリージョン ペア間でシリアル化されるため、各ペアの 1 つのリージョンのみが一度に更新されます。
プラットフォームの容量。 他のクラウド プロバイダーと同様に、Azure には有限のリソースがあります。 利用できないのは、リージョンの容量制限の結果である可能性があります。 リージョンの障害が発生した場合、ワークロードがペアリージョン内で復旧を試みると、リソースの需要が増加します。 停止すると、供給が一時的に需要を満たさない容量の問題が発生する可能性があります。
設計の推奨事項
リージョンの停止から保護するために、少なくとも 2 つの Azure リージョンにソリューションをデプロイします。 ワークロードに必要な機能と特性を持つリージョンにデプロイします。 この機能は、データ所在地と保持の要件を満たしながら、パフォーマンスと可用性の目標を満たす必要があります。
たとえば、一部のデータ コンプライアンス要件では、使用可能なリージョンの数が制限され、設計上の侵害が強制される可能性があります。 このような場合は、運用ラッパーに追加の投資を追加して、障害を予測、検出、対応することを強くお勧めします。 2 つのリージョンを持つ地域に制限されており、可用性ゾーン (3 + 1 データセンター モデル) をサポートしているリージョンは 1 つだけだとします。 障害ドメインの分離を使用してセカンダリ展開パターンを作成し、両方のリージョンをアクティブな構成でデプロイできるようにし、プライマリ リージョンに複数のデプロイ スタンプが格納されていることを確認します。
適切な Azure リージョンで必要なすべての機能が提供されない場合は、地理的な分散に優先順位を付け、信頼性を最大化するために、リージョンデプロイ スタンプの一貫性を侵害する準備をしてください。 1 つの Azure リージョンのみが適している場合は、選択したリージョンに複数のデプロイ スタンプ (リージョン スケール ユニット) をデプロイしてリスクを軽減し、可用性ゾーンを使用してデータセンター レベルのフォールト トレランスを提供します。 ただし、地理的な分布のこのような重大な侵害により、達成可能な複合 SLA と全体的な信頼性が劇的に制約されます。
重要
99.99% 以上の SLO を対象とするシナリオでは、複合 SLA と全体的な信頼性を最大化するために、少なくとも 3 つのデプロイ リージョンをお勧めします。 すべてのユーザー フローの 複合 SLA を計算します。 複合 SLA がビジネス 目標と一致していることを確認します。
大量のトラフィックを含む大規模なアプリケーション シナリオの場合は、1 つのリージョン内で潜在的な容量の制約をナビゲートするために、複数のリージョン間でスケーリングするソリューションを設計します。 追加のリージョンデプロイ スタンプでは、より高い複合 SLA が実現されます。 グローバル リソースを使用すると、リージョンを追加することで達成できる複合 SLA の増加が制限されます。
目標復旧ポイント (RPO) と目標復旧時間 (RTO) を定義して検証します。
1 つの地域内で、リージョン ペアの使用に優先順位を付けて、計画メンテナンスの SDP シリアル化されたロールアウトと、計画外のメンテナンスに対するリージョンの優先順位付けを利用します。
ネットワーク待機時間を最小限に抑え、エンドツーエンドのパフォーマンスを最大化するために、Azure リソースをユーザーと地理的に併置します。
- また、Content Delivery Network (CDN) やエッジ キャッシュなどのソリューションを使用して、分散ユーザー ベースの最適なネットワーク待機時間を促進することもできます。 詳細については、「 グローバル トラフィック ルーティング」、「 アプリケーション配信サービス」、および 「キャッシュと静的コンテンツ配信」を参照してください。
デプロイ リージョンを選択するときに、現在のサービスの可用性を製品ロードマップに合わせます。 一部のサービスは、すべてのリージョンですぐに利用できない場合があります。
コンテナー詰め
コンテナーには、アプリケーション コードと、アプリケーションの実行に必要な関連する構成ファイル、ライブラリ、依存関係が含まれます。 コンテナー化は、アプリケーション コードとその依存関係の抽象化レイヤーを提供し、基になるホスティング プラットフォームからの分離を作成します。 1 つのソフトウェア パッケージは移植性が高く、さまざまなインフラストラクチャ プラットフォームとクラウド プロバイダー間で一貫して実行できます。 開発者はコードを書き換える必要がなく、アプリケーションをより迅速かつ確実にデプロイできます。
重要
ミッション クリティカルなアプリケーション パッケージにはコンテナーを使用することをお勧めします。 同じ仮想化インフラストラクチャで複数のコンテナーをホストできるため、インフラストラクチャの使用率が向上します。 また、すべてのソフトウェアがコンテナーに含まれているため、ランタイムやライブラリのバージョンに関係なく、さまざまなオペレーティング システム間でアプリケーションを移動できます。 コンテナーの管理も、従来の仮想化ホスティングよりも簡単です。
ミッション クリティカルなアプリケーションでは、パフォーマンスのボトルネックを回避するために高速にスケーリングする必要があります。 コンテナー イメージは事前に構築されているため、アプリケーションのブートストラップ中にのみ起動を制限できます。これにより、迅速なスケーラビリティが実現されます。
設計上の考慮事項
監視。 コンテナー内のアプリケーションにアクセスするには、サービスの監視が困難な場合があります。 通常、CPU や RAM 使用率などのコンテナー状態インジケーターを収集して格納するには、サードパーティ製のソフトウェアが必要です。
セキュリティ。 ホスティング プラットフォーム OS カーネルは複数のコンテナー間で共有され、1 つの攻撃ポイントが作成されます。 ただし、コンテナーは基になるオペレーティング システムから分離されているため、ホスト VM アクセスのリスクは制限されます。
状態。 実行中のコンテナーのファイル システムにデータを格納することはできますが、コンテナーの再作成時にデータは保持されません。 代わりに、外部ストレージをマウントするか、外部データベースを使用してデータを保持します。
設計の推奨事項
すべてのアプリケーション コンポーネントをコンテナー化します。 アプリケーション デプロイ パッケージのプライマリ モデルとしてコンテナー イメージを使用します。
可能な場合は、Linux ベースのコンテナー ランタイムに優先順位を付けます。 イメージはより軽量であり、Linux ノード/コンテナーの新機能が頻繁にリリースされます。
短いライフサイクルを使用して、コンテナーを変更不可にし、置き換え可能にします。
コンテナー、コンテナー ホスト、基になるクラスターから、関連するすべてのログとメトリックを収集してください。 収集されたログとメトリックを統合データ シンクに送信して、さらに処理と分析を行います。
コンテナー イメージをAzure Container Registryに格納します。 geo レプリケーションを使用して、コンテナー イメージをすべてのリージョンにレプリケートします。 コンテナー レジストリのMicrosoft Defenderを有効にして、コンテナー イメージの脆弱性スキャンを提供します。 レジストリへのアクセスが Microsoft Entra ID によって管理されていることを確認します。
コンテナーのホスティングとオーケストレーション
複数の Azure アプリケーション プラットフォームで、コンテナーを効果的にホストできます。 これらの各プラットフォームには、長所と短所があります。 ビジネス要件のコンテキストでオプションを比較します。 ただし、常に信頼性、スケーラビリティ、パフォーマンスを最適化します。 詳細と例については、次の記事をご覧ください。
重要
要件に応じて、Azure Kubernetes Service (AKS) と Azure Container Apps をコンテナー管理の最初の選択肢にする必要があります。 Azure App Serviceはオーケストレーターではありませんが、低摩擦のコンテナー プラットフォームとして、AKS に代わる実行可能な代替手段です。
Azure Kubernetes Serviceの設計に関する考慮事項と推奨事項
マネージド Kubernetes サービスである AKS は、複雑なクラスター管理アクティビティを必要とせずに迅速なクラスター プロビジョニングを可能にし、高度なネットワークと ID 機能を含む機能セットを提供します。 推奨事項の完全なセットについては、「 Azure Well-Architected Framework のレビュー - AKS」を参照してください。
重要
AKS クラスターを再デプロイしないと変更できない基本的な構成の決定がいくつかあります。 たとえば、パブリックとプライベートの AKS クラスターの選択、Azure ネットワーク ポリシーの有効化、Microsoft Entra統合、サービス プリンシパルではなく AKS のマネージド ID の使用などがあります。
[信頼性]
AKS は、ネイティブ Kubernetes コントロール プレーンを管理します。 コントロール プレーンを使用できない場合、ワークロードでダウンタイムが発生します。 AKS によって提供される信頼性機能を利用します。
信頼性と可用性を最大化するために、 さまざまな Azure リージョンに AKS クラスター をスケール ユニットとしてデプロイします。 AKS コントロール プレーンとエージェント ノードを物理的に分離されたデータセンターに分散することで、 可用性ゾーン を使用して Azure リージョン内の回復性を最大化します。 ただし、コロケーション待機時間に問題がある場合は、1 つのゾーン内で AKS デプロイを行うか、 近接配置グループ を使用してノード間の待機時間を最小限に抑えることができます。
運用クラスターの AKS アップタイム SLA を 使用して、Kubernetes API エンドポイントの可用性の保証を最大化します。
スケーラビリティ
ノードの数、クラスターあたりのノード プール、サブスクリプションごとのクラスター数など、AKS スケールの制限を考慮します。
スケール制限が制約である場合は、 スケール ユニット戦略を利用し、クラスターを使用してより多くのユニットをデプロイします。
クラスター自動スケーリングを有効にすると、リソースの制約に応じてエージェント ノードの数が自動的に調整されます。
ポッドの 水平オートスケーラー を使用して、CPU 使用率やその他のメトリックに基づいてデプロイ内のポッドの数を調整します。
大規模およびバーストのシナリオでは、大規模で迅速なスケールに 仮想ノード を使用することを検討してください。
アプリケーション配置マニフェストで ポッド リソースの要求と制限 を定義します。 そうしないと、パフォーマンスの問題が発生する可能性があります。
分離:
ワークロードとシステム ツールで使用されるインフラストラクチャ間の境界を維持します。 インフラストラクチャを共有すると、リソース使用率が高くなり、近隣のシナリオが騒がしい可能性があります。
システム サービスとワークロード サービスには、個別のノード プールを使用します。 ワークロード コンポーネント用の専用ノード プールは、高メモリ GPU VM などの特殊なインフラストラクチャ リソースの要件に基づいている必要があります。 一般に、不要な管理オーバーヘッドを減らすために、多数のノード プールをデプロイしないようにします。
テイントと容認を使用して専用ノードを提供し、リソースを集中的に使用するアプリケーションを制限します。
アプリケーション アフィニティとアンチアフィニティの要件を評価し、ノード上のコンテナーの適切なコロケーションを構成します。
セキュリティ
既定のバニラ Kubernetes では、ミッション クリティカルなシナリオに適したセキュリティ体制を確保するために重要な構成が必要です。 AKS は、さまざまなセキュリティ リスクにすぐに対処できます。 機能には、プライベート クラスター、Log Analytics への監査とログイン、強化されたノード イメージ、マネージド ID が含まれます。
AKS セキュリティ ベースラインに記載されている構成ガイダンスを適用します。
AKS 機能を使用してクラスター ID とアクセス管理を処理し、運用オーバーヘッドを削減し、一貫性のあるアクセス管理を適用します。
資格情報の管理とローテーションを回避するには、サービス プリンシパルの代わりにマネージド ID を使用します。 マネージド ID は、クラスター レベルで追加できます。 ポッド レベルでは、Microsoft Entra ワークロード ID経由でマネージド ID を使用できます。
Microsoft Entra統合を使用して、一元化されたアカウント管理とパスワード、アプリケーション アクセス管理、強化された ID 保護を行います。 最小限の特権のためにMicrosoft Entra ID を持つ Kubernetes RBAC を使用し、管理者特権の付与を最小限に抑えて、構成とシークレットのアクセスを保護します。 また、Azure ロールベースのアクセス制御を使用して 、Kubernetes クラスター構成 ファイルへのアクセスを制限します。 コンテナーが実行できるアクションへのアクセスを制限し、アクセス許可の最小数を指定し、ルート特権エスカレーションの使用を回避します。
アップグレード
クラスターとノードは定期的にアップグレードする必要があります。 AKS では、ネイティブ Kubernetes のリリース サイクルに合わせて Kubernetes バージョンがサポートされます。
今後の変更、機能強化、最も重要な Kubernetes バージョンのリリースと非推奨について最新の状態を維持するために、GitHub のパブリック AKS ロードマップ と リリース ノート をサブスクライブします。
AKS チェックリストに記載されているガイダンスを適用して、ベスト プラクティスとの整合性を確保します。
ノードやクラスターを更新するために AKS でサポートされているさまざまな方法に注意してください。 これらの方法は、手動または自動化できます。 計画メンテナンスを使用して、これらの操作のメンテナンス期間を定義できます。 新しいイメージは毎週リリースされます。 また、AKS では、AKS クラスターを新しいバージョンの Kubernetes や新しいノード イメージが使用可能になったときに自動的にアップグレードするための 自動アップグレード チャネル もサポートされています。
ネットワーク
ユース ケースに最適なネットワーク プラグインを評価します。 ポッド間のトラフィックをきめ細かく制御する必要があるかどうかを判断します。 Azure では、kubenet、 Azure CNI がサポートされており、特定のユース ケースに対 して独自の CNI を使用できます 。
ネットワーク要件とクラスターのサイズを評価した後、Azure CNI の使用に優先順位を付けます。 Azure CNI を使用すると、 クラスター 内のトラフィックを制御するための Azure または Calico ネットワーク ポリシーを使用できます。
監視
監視ツールは、実行中のポッドからログとメトリックをキャプチャできる必要があります。 また、Kubernetes Metrics API から情報を収集して、実行中のリソースとワークロードの正常性を監視する必要もあります。
Azure Monitor と Application Insights を使用して、トラブルシューティングのために AKS リソースからメトリック、ログ、および診断を収集します。
Kubernetes リソース ログを有効にして確認します。
Azure Monitor で Prometheus メトリック を構成します。 Monitor の Container insights はオンボードを提供し、すぐに使用できる監視機能を有効にし、組み込みの Prometheus サポートを使用してより高度な機能を有効にします。
ガバナンス
ポリシーを使用して、一貫した方法で AKS クラスターに一元的なセーフガードを適用します。 サブスクリプション スコープ以上でポリシーの割り当てを適用して、開発チーム間の一貫性を高めます。
Azure Policyを使用して、ポッドに付与される関数と、実行がポリシーと矛盾するかどうかを制御します。 このアクセスは、AKS の Azure Policy アドオンによって提供される組み込みのポリシーを使用して定義されます。
Azure Policyを使用して、AKS クラスターとポッド構成の一貫した信頼性とセキュリティ ベースラインを確立します。
AKS 用Azure Policy アドオンを使用して、ルート特権などのポッド関数を制御し、ポリシーに準拠していないポッドを禁止します。
注意
Azure ランディング ゾーンにデプロイする場合、一貫した信頼性とセキュリティを確保するのに役立つ Azure ポリシーは、ランディング ゾーンの実装によって提供される必要があります。
ミッション クリティカルな 参照実装では、 推奨される信頼性とセキュリティ構成を推進するための一連のベースライン ポリシーが提供されます。
Azure App Serviceの設計に関する考慮事項と推奨事項
Web および API ベースのワークロード シナリオでは、App Serviceが AKS の代わりに適している可能性があります。 Kubernetes の複雑さなしで、低摩擦のコンテナー プラットフォームを提供します。 推奨事項の完全なセットについては、「App Serviceの信頼性に関する考慮事項」と「App Serviceのオペレーショナル エクセレンス」を参照してください。
[信頼性]
TCP ポートと SNAT ポートの使用を評価します。 TCP 接続は、すべての送信接続に使用されます。 SNAT ポートは、パブリック IP アドレスへの送信接続に使用されます。 SNAT ポートの枯渇は、一般的な障害シナリオです。 Azure Diagnosticsを使用してポートを監視しているときに、ロード テストによってこの問題を予測的に検出する必要があります。 SNAT エラーが発生した場合は、より多くのワーカーまたは大規模なワーカー間でスケーリングするか、SNAT ポートの保持と再利用に役立つコーディング プラクティスを実装する必要があります。 使用できるコーディングプラクティスの例としては、接続プールやリソースの遅延読み込みなどがあります。
TCP ポートの枯渇は、もう 1 つの障害シナリオです。 これは、特定のワーカーからの送信接続の合計が容量を超えたときに発生します。 使用可能な TCP ポートの数は、ワーカーのサイズによって異なります。 推奨事項については、「 TCP ポートと SNAT ポート」を参照してください。
スケーラビリティ
最初から適切な推奨事項を適用できるように、将来のスケーラビリティ要件とアプリケーションの拡張を計画します。 これにより、ソリューションの拡大に伴う技術的な移行負債を回避できます。
自動スケーリングを有効にして、適切なリソースをサービス要求で使用できるようにします。 App Serviceでの高密度ホスティングについて、アプリごとのスケーリングを評価します。
App Serviceには、App Service プランごとのインスタンスの既定のソフト制限があることに注意してください。
自動スケーリング ルールを適用します。 App Serviceプランは、プロファイル内のルールが満たされた場合はスケールアウトされますが、プロファイル内のすべてのルールが満たされている場合にのみスケールインされます。 スケールアウトとスケールインの両方のルールの組み合わせを使用して、自動スケーリングがスケールアウトとスケールインの両方に対してアクションを実行できるようにします。 1 つのプロファイルでの複数のスケーリング ルールの動作について理解します。
アプリごとのスケーリングは、App Service プランのレベルで有効にして、アプリケーションをホストするApp Service プランとは別にスケーリングできるようにすることに注意してください。 アプリは、偶数配布のベスト エフォート アプローチを使用して、使用可能なノードに割り当てられます。 均等分散は保証されませんが、プラットフォームでは、同じアプリの 2 つのインスタンスが同じインスタンスでホストされていないことが保証されます。
監視
アプリケーションの動作を監視し、関連するログとメトリックにアクセスして、アプリケーションが期待どおりに動作することを確認します。
診断ログを使用して、アプリケーション レベルおよびプラットフォーム レベルのログを、Azure Event Hubsを使用して Log Analytics、Azure Storage、またはサードパーティ製ツールに取り込むことができます。
Application Insights を使用したアプリケーション パフォーマンスの監視は、アプリケーションのパフォーマンスに関する詳細な分析情報を提供します。
ミッション クリティカルなアプリケーションには、障害が発生した場合に自己修復する機能が必要です。 [自動回復] を有効にして、異常なワーカーを自動的にリサイクルします。
適切な正常性チェックを使用して、すべての重要なダウンストリーム依存関係を評価する必要があります。これは、全体的な正常性を確保するのに役立ちます。 応答しないワーカーを識別するには 、正常性チェック を有効にすることを強くお勧めします。
デプロイ
App Service プランごとのインスタンスの既定の制限を回避するには、App Serviceプランを 1 つのリージョン内の複数のスケール ユニットにデプロイします。 App Serviceプランを可用性ゾーン構成にデプロイして、ワーカー ノードがリージョン内のゾーン間で分散されるようにします。 サポート チケットを開いて、ワーカーの最大数を、通常のピーク負荷に対応するために必要なインスタンス数の 2 倍に増やすことを検討してください。
コンテナー レジストリ
コンテナー レジストリは、AKS などのコンテナー ランタイム環境にデプロイされるイメージをホストします。 ミッション クリティカルなワークロード用にコンテナー レジストリを慎重に構成する必要があります。 停止しても、特にスケーリング操作中に、イメージのプルに遅延が発生しないようにする必要があります。 次の考慮事項と推奨事項は、Azure Container Registryに焦点を当て、一元化およびフェデレーションデプロイ モデルに関連するトレードオフを調べます。
設計上の考慮事項
形式。 プッシュ操作とプル操作の両方に Docker で提供される形式と標準に依存するコンテナー レジストリの使用を検討してください。 これらのソリューションは互換性があり、ほとんど交換可能です。
デプロイ モデル。 コンテナー レジストリは、organization内の複数のアプリケーションによって使用される一元化されたサービスとしてデプロイできます。 または、特定のアプリケーション ワークロード用の専用コンポーネントとしてデプロイすることもできます。
パブリック レジストリ。 コンテナー イメージは、Azure と特定の仮想ネットワークの外部に存在するDocker Hubまたはその他のパブリック レジストリに格納されます。 これは必ずしも問題ではありませんが、サービスの可用性、調整、データ流出に関連するさまざまな問題につながる可能性があります。 一部のアプリケーション シナリオでは、エグレス トラフィックを制限したり、可用性を高めたり、潜在的な調整を回避したりするために、プライベート コンテナー レジストリ内のパブリック コンテナー イメージをレプリケートする必要があります。
設計の推奨事項
アプリケーション ワークロード専用のコンテナー レジストリ インスタンスを使用します。 組織の可用性と信頼性の要件がアプリケーションと完全に一致しない限り、一元化されたサービスへの依存関係を作成しないでください。
推奨される コア アーキテクチャ パターンでは、コンテナー レジストリは、長生きしているグローバル リソースです。 環境ごとに 1 つのグローバル コンテナー レジストリを使用することを検討してください。 たとえば、グローバル運用レジストリを使用します。
パブリック レジストリの SLA が、信頼性とセキュリティのターゲットと一致していることを確認します。 Docker Hubに依存するユース ケースでは、調整の制限に特に注意してください。
コンテナー イメージをホストするためのAzure Container Registryに優先順位を付けます。
Azure Container Registryの設計に関する考慮事項と推奨事項
このネイティブ サービスは、geo レプリケーション、Microsoft Entra認証、コンテナーの自動ビルド、Container Registry タスクによる修正プログラムの適用など、さまざまな機能を提供します。
[信頼性]
リージョンの依存関係を削除し、待機時間を最適化するために、すべてのデプロイ リージョンへの geo レプリケーションを構成します。 Container Registry では、複数の構成済みリージョンへの geo レプリケーション による高可用性がサポートされ、リージョンの停止に対する回復性が提供されます。 リージョンが使用できなくなった場合、他のリージョンは引き続きイメージ要求を処理します。 リージョンがオンラインに戻ると、Container Registry によって復旧され、変更がレプリケートされます。 この機能により、構成された各リージョン内のレジストリ コロケーションも提供され、ネットワークの待機時間とリージョン間のデータ転送コストが削減されます。
可用性ゾーンのサポートを提供する Azure リージョンでは、 Premium Container Registry レベルではゾーン冗長がサポート され、ゾーン障害に対する保護が提供されます。 Premium レベルでは、レジストリへの未承認のアクセスを防ぐために プライベート エンドポイント もサポートされており、信頼性の問題につながる可能性があります。
同じ Azure リージョン内で、使用しているコンピューティング リソースに近いホスト イメージ。
イメージのロック
画像は、たとえば手動エラーの結果として削除される可能性があります。 Container Registry では、 イメージ バージョンまたはリポジトリをロックして、 変更や削除を防ぐことができます。 以前にデプロイしたイメージ のバージョン が変更されると、同じバージョンのデプロイで、変更の前後に異なる結果が得られます。
Container Registry インスタンスを削除から保護する場合は、 リソース ロックを使用します。
タグ付けされた画像
タグ付けされた Container Registry イメージは既定で変更可能です。つまり、レジストリにプッシュされた複数のイメージで同じタグを使用できます。 運用環境のシナリオでは、アプリケーションのアップタイムに影響を与える可能性のある予期しない動作が発生する可能性があります。
ID 管理とアクセス管理
Microsoft Entra統合認証を使用して、アクセス キーに依存するのではなく、イメージをプッシュおよびプルします。 セキュリティを強化するには、管理者アクセス キーの使用を完全に無効にします。
サーバーレス コンピューティング
サーバーレス コンピューティングは、必要に応じてリソースを提供し、インフラストラクチャを管理する必要がなくなります。 クラウド プロバイダーは、デプロイされたアプリケーション コードの実行に必要なリソースを自動的にプロビジョニング、スケーリング、管理します。 Azure には、いくつかのサーバーレス コンピューティング プラットフォームが用意されています。
Azure Functions。 Azure Functionsを使用すると、アプリケーション ロジックは、HTTP 要求やキュー メッセージなどのイベントに応答して実行される個別のコード ブロック (関数) として実装されます。 各関数は、需要を満たすために必要に応じてスケーリングされます。
Azure Logic Apps。 Logic Apps は、さまざまなアプリ、データ ソース、サービス、システムを統合する自動化されたワークフローの作成と実行に最適です。 Azure Functionsと同様に、Logic Apps では、イベント ドリブン処理に組み込みのトリガーが使用されます。 ただし、アプリケーション コードをデプロイする代わりに、条件付きやループなどのコード ブロックをサポートするグラフィカル ユーザー インターフェイスを使用してロジック アプリを作成できます。
Azure API Management。 API Managementを使用すると、従量課金レベルを使用して、拡張セキュリティ API の発行、変換、保守、監視を行うことができます。
Power Apps と Power Automate。 これらのツールは、ユーザー インターフェイスの接続を介して構成可能なシンプルなワークフロー ロジックと統合を備えた、ローコードまたはコードなしの開発エクスペリエンスを提供します。
ミッション クリティカルなアプリケーションでは、サーバーレス テクノロジによって開発と運用が簡素化され、シンプルなビジネス ユース ケースに役立ちます。 ただし、このシンプルさは、スケーラビリティ、信頼性、パフォーマンスの点で柔軟性が犠牲になり、ほとんどのミッション クリティカルなアプリケーション シナリオでは実現できません。
次のセクションでは、重要でないワークフロー シナリオの代替プラットフォームとしてAzure Functionsと Logic Apps を使用するための設計上の考慮事項と推奨事項について説明します。
Azure Functionsの設計に関する考慮事項と推奨事項
ミッション クリティカルなワークロードには、重要なシステム フローと非クリティカルなシステム フローがあります。 Azure Functionsは、重要なシステム フローと同じ厳格なビジネス要件を持たないフローに対して実行可能な選択肢です。 関数は、可能な限り高速に実行される個別の操作を実行するため、有効期間の短いプロセスを持つイベント ドリブン フローに適しています。
アプリケーションの信頼性レベルに適したAzure Functionsホスティング オプションを選択します。 Premium プランでは、コンピューティング インスタンス のサイズを構成できるため、お勧めします。 専用プランは、サーバーレスの最小オプションです。 自動スケーリングが提供されますが、これらのスケール操作は他のプランの操作よりも遅くなります。 Premium プランを使用して、信頼性とパフォーマンスを最大化することをお勧めします。
セキュリティに関する考慮事項がいくつかあります。 HTTP トリガーを使用して外部エンドポイントを公開する場合は、Web アプリケーション ファイアウォール (WAF) を使用して、一般的な外部攻撃ベクトルから HTTP エンドポイントの保護レベルを提供します。
プライベート仮想ネットワークへのアクセスを制限するには、プライベート エンドポイントを使用することをお勧めします。 また、悪意のある管理者シナリオなど、データ流出リスクを軽減することもできます。
Azure Functions コードでコード スキャン ツールを使用し、それらのツールを CI/CD パイプラインと統合する必要があります。
Azure Logic Apps の設計に関する考慮事項と推奨事項
Azure Functionsと同様に、Logic Apps では、イベント ドリブン処理に組み込みのトリガーが使用されます。 ただし、アプリケーション コードをデプロイする代わりに、条件付き、ループ、その他のコンストラクトなどのブロックをサポートするグラフィカル ユーザー インターフェイスを使用してロジック アプリを作成できます。
複数の デプロイ モード を使用できます。 シングルテナントのデプロイを確実に行い、ノイズの多い近隣シナリオを軽減するには、Standard モードをお勧めします。 このモードでは、コンテナー化されたシングルテナント Logic Apps ランタイムが使用されます。これは、Azure Functionsに基づいています。 このモードでは、ロジック アプリに複数のステートフル ワークフローとステートレス ワークフローを含めることができます。 構成の制限に注意する必要があります。
IaaS による制約付き移行
既存のオンプレミスデプロイを持つ多くのアプリケーションでは、仮想化テクノロジと冗長ハードウェアを使用して、ミッション クリティカルなレベルの信頼性を提供しています。 モダン化は、多くの場合、ミッション クリティカルなワークロードに推奨されるクラウドネイティブ ベースライン (North Star) アーキテクチャ パターンとの完全な整合を妨げるビジネス上の制約によって妨げられます。 そのため、多くのアプリケーションでは段階的なアプローチが採用されており、仮想化と Azure Virtual Machinesをプライマリ アプリケーション ホスティング モデルとして使用する初期クラウド デプロイがあります。 特定のシナリオでは、IaaS 仮想マシンの使用が必要になる場合があります。
- 使用可能な PaaS サービスでは、必要なパフォーマンスや制御レベルは提供されません。
- ワークロードには、オペレーティング システムへのアクセス、特定のドライバー、またはネットワークとシステムの構成が必要です。
- ワークロードでは、コンテナーでの実行はサポートされていません。
- サードパーティのワークロードに対するベンダーのサポートはありません。
このセクションでは、Azure Virtual Machinesおよび関連サービスを使用して、アプリケーション プラットフォームの信頼性を最大限に高める最適な方法について説明します。 これは、クラウドネイティブおよび IaaS 移行シナリオを転置するミッション クリティカルな設計手法の重要な側面を強調しています。
設計上の考慮事項
IaaS 仮想マシンを使用する運用コストは、仮想マシンとオペレーティング システムの管理要件により、PaaS サービスを使用するコストよりも大幅に高くなります。 仮想マシンを管理するには、ソフトウェア パッケージと更新プログラムを頻繁にロールアウトする必要があります。
Azure には、仮想マシンの可用性を向上させる機能が用意されています。
- 可用性セット は、障害ドメインと更新ドメイン間で仮想マシンを分散することで、ネットワーク、ディスク、および電源障害から保護するのに役立ちます。
- 可用性ゾーン は、リージョン内の物理的に分離されたデータセンターに VM を分散することで、さらに高いレベルの信頼性を実現するのに役立ちます。
- Virtual Machine Scale Setsは、グループ内の仮想マシンの数を自動的にスケーリングするための機能を提供します。 また、インスタンスの正常性を監視し、 異常なインスタンスを自動的に修復するための機能も提供します。
設計の推奨事項
重要
運用の複雑さとコストを削減するために、可能な場合は PaaS サービスとコンテナーを使用します。 IaaS 仮想マシンは、必要な場合にのみ使用します。
有効なリソース使用率を確保するための適切なサイズの VM SKU サイズ。
データセンター レベルのフォールト トレランスを実現するために 、可用性ゾーン 間に 3 つ以上の仮想マシンをデプロイします。
- 市販の商用ソフトウェアを展開する場合は、ソフトウェアベンダーに相談し、ソフトウェアを運用環境に展開する前に適切にテストしてください。
複数の可用性ゾーンにデプロイできないワークロードの場合は、3 つ以上の VM を含む 可用性セット を使用します。
- 可用性ゾーンがワークロード要件を満たしていない場合 (待機時間の短いワークロードなど) に対してのみ、可用性セットを検討してください。
スケーラビリティとゾーン冗長性のために、Virtual Machine Scale Setsの使用に優先順位を付けます。 この点は、負荷が異なるワークロードでは特に重要です。 たとえば、アクティブなユーザーまたは 1 秒あたりの要求の数がさまざまな負荷である場合です。
個々の仮想マシンに直接アクセスしないでください。 可能な場合は、その前にロード バランサーを使用します。
リージョンの停止から保護するには、複数の Azure リージョンにアプリケーション仮想マシンをデプロイします。
- アクティブなデプロイ リージョン間でトラフィックを最適にルーティングする方法の詳細については、 ネットワークと接続の設計領域 を参照してください。
マルチリージョンのアクティブ/アクティブデプロイをサポートしていないワークロードの場合は、リージョンフェールオーバーにホット/ウォーム スタンバイ仮想マシンを使用してアクティブ/パッシブデプロイを実装することを検討してください。
維持する必要があるカスタム イメージではなく、Azure Marketplaceの標準イメージを使用します。
自動プロセスを実装して、仮想マシンに対する変更をデプロイしてロールアウトし、手動による介入を回避します。 詳細については、「運用手順の設計」領域の「IaaS に関する考慮事項」を参照してください。
カオス実験を実装して、仮想マシン コンポーネントにアプリケーション 障害を挿入し、障害の軽減策を観察します。 詳細については、「 継続的な検証とテスト」を参照してください。
仮想マシンを監視し、診断ログとメトリックが 統合データ シンクに取り込まれるようにします。
ミッション クリティカルなアプリケーション シナリオのセキュリティ プラクティス (該当する場合) と、Azure の IaaS ワークロードのセキュリティのベスト プラクティスを実装します。
次のステップ
データ プラットフォームに関する考慮事項を確認します。
フィードバック
以下は間もなく提供いたします。2024 年を通じて、コンテンツのフィードバック メカニズムとして GitHub の issue を段階的に廃止し、新しいフィードバック システムに置き換えます。 詳細については、「https://aka.ms/ContentUserFeedback」を参照してください。
フィードバックの送信と表示