Azure HDInsight は、組織が大量のデータを処理するのに役立つビッグ データ分析用のマネージド クラウドベースのサービスです。 このチュートリアルでは、Azure HDInsight クラスターから Jupyter ノートブックを使用して OneLake に接続する方法について説明します。
Azure HDInsight の使用
HDInsight クラスターから Jupyter ノートブックを使用して OneLake に接続するには、次の操作を行います。
HDInsight (HDI) Apache Spark クラスターを作成します。 「HDInsight のクラスターを設定する」の手順に従います。
クラスター情報を指定するときは、後でクラスターにアクセスする際に必要となるため、クラスター ログインの [ユーザー名] と [パスワード] を覚えておいてください。
ユーザー割り当てマネージド ID (UAMI) を作成します。Azure HDInsight - UAMI 用に作成し、[ストレージ] 画面で ID として選択します。
![[ストレージ] 画面でユーザー割り当てマネージド ID を入力する場所を示すスクリーンショット。](media/onelake-azure-hdinsight/create-hdinsight-cluster-storage.png)
この UAMI に、項目を含む Fabric ワークスペースへのアクセス権を付与します。 最適なロールの決定については、「ワークスペースロール」を参照してください。
レイクハウスに移動し、ワークスペースとレイクハウスの名前を見つけます。 これらのファイルは、レイクハウスの URL またはファイルの [プロパティ] ウィンドウで確認できます。
Azure portal でクラスターを探し、ノートブックを選択します。
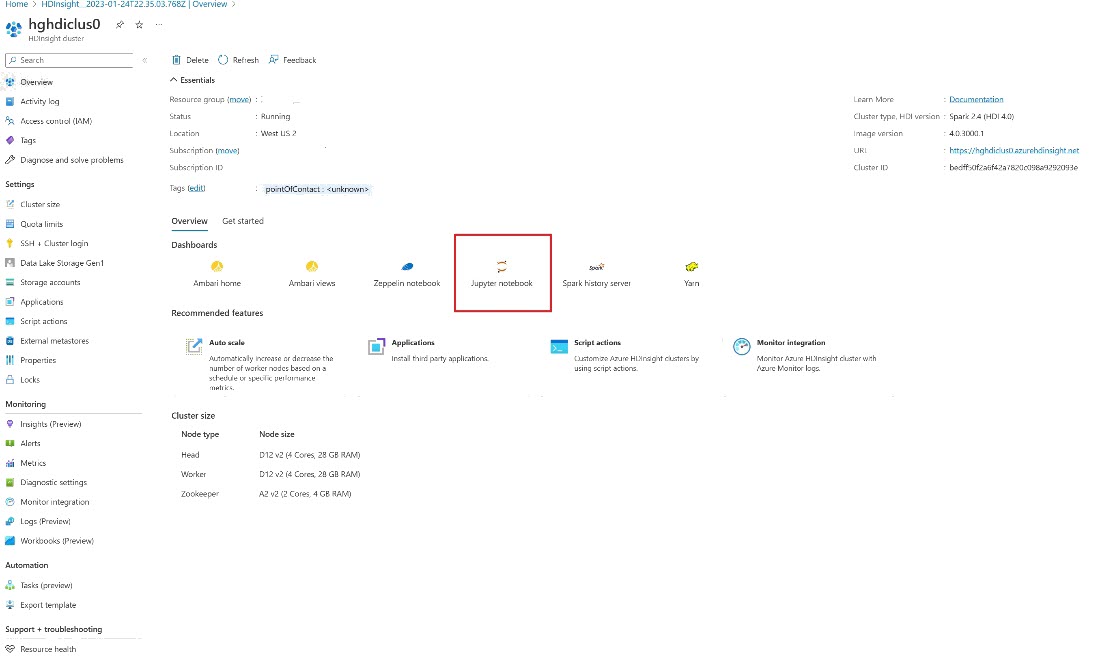
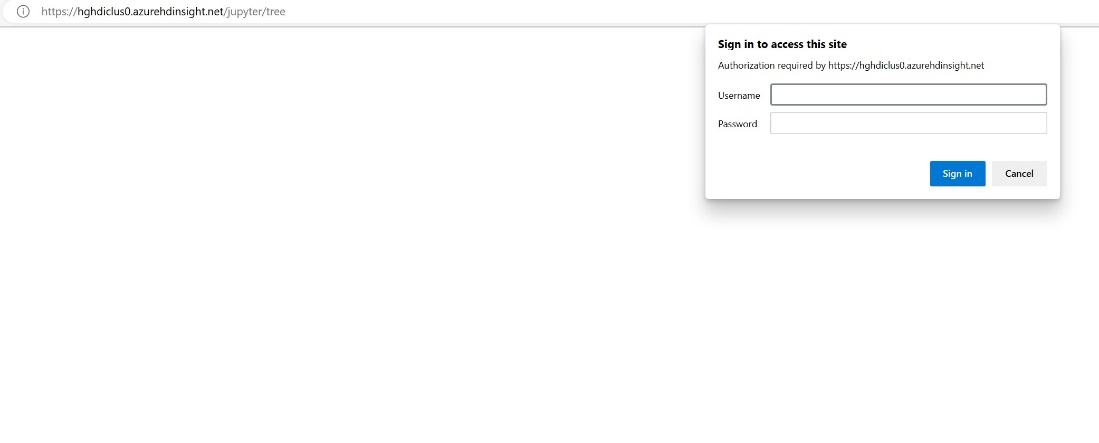
クラスターの作成時に指定した資格情報を入力します。
新しい Apache Spark ノートブックを作成します。
ワークスペースとレイクハウスの名前をノートブックにコピーし、レイクハウスの OneLake URL を作成します。 これで、このファイル パスから任意のファイルを読み取ることができます。
fp = 'abfss://' + 'Workspace Name' + '@onelake.dfs.fabric.microsoft.com/' + 'Lakehouse Name' + '/Files/' df = spark.read.format("csv").option("header", "true").load(fp + "test1.csv") df.show()レイクハウスにデータを書き込もう。
writecsvdf = df.write.format("csv").save(fp + "out.csv")レイクハウスにチェックするか、新しく読み込まれたファイルを読み取って、データが正常に書き込まれたことをテストします。
![[ストレージ] 画面でユーザー割り当てマネージド ID を入力する場所を示すスクリーンショット。](media/onelake-azure-hdinsight/create-hdinsight-cluster-storage.png#lightbox)



HDI Spark クラスターの Jupyter ノートブックを使用して、OneLake でデータの読み取りと書き込みを行えるようになりました。