適用対象:![]() キャンバス アプリ
キャンバス アプリ![]() Copilot Studio
Copilot Studio![]() モデル駆動型アプリ
モデル駆動型アプリ![]() Power Platform CLI
Power Platform CLI![]() Dataverse 関数
Dataverse 関数![]() Power Pages
Power Pages
パターンに基づいてテキスト文字列の一致をテストまたは抽出します。
内容
IsMatch関数は、テキスト文字列が通常の文字、定義済みのパターン、または正規表現を構成できるパターンと一致するかどうかをテストします。 Match関数とMatchAll関数は、サブマッチを含め、一致した内容を返します。
IsMatchを使用して、ユーザーがテキスト入力コントロールに入力した内容を検証します。 たとえば、結果がデータ ソースに保存される前に、ユーザーが有効なメール アドレスを入力したかどうかを確認します。 エントリが条件と一致しない場合は、ユーザーにエントリの修正を求める他のコントロールを追加します。
Matchを使用して、パターンに一致する最初のテキスト文字列を抽出し、一致するすべてのテキスト文字列を抽出MatchAllします。 サブマッチを抽出して複雑な文字列を解析します。
Match は最初に見つかった一致の情報のレコードを返し、 MatchAll は見つかったすべての一致のレコードのテーブルを返します。 レコードまたはレコードには次のものが含まれます:
| Column | タイプ | 内容 |
|---|---|---|
| 名前付きサブマッチまたはサブマッチ | テキスト | 名前付きサブマッチにはそれぞれ独自の列があります。 (?< を使用して名前付きサブマッチを作成するname>...) を使用します。 名前付きサブマッチの名前が定義済みの列の 1 つと同じ場合、サブマッチが優先され、警告が生成されます。 この警告を回避するには、サブマッチの名前を変更します。 |
| フルマッチ | テキスト | 一致したすべてのテキスト文字列。 |
| スタートマッチ | 番号 | 入力テキスト文字列内での一致の開始位置。 文字列の最初の文字は 1 を返します。 |
| SubMatches( MatchOptions.NumberedSubMatches が使用されている場合のみ)。 | テキストの単一列テーブル (列 Value) | 正規表現に出現する順序の番号付きサブマッチのテーブル。 一般に、名前付きサブマッチは簡単に操作でき、推奨されます。 ForAll 関数または Index 関数を使用して、個々のサブ一致を操作します。 正規表現でサブマッチが定義されていない場合、このテーブルは存在しますが、空になります。 |
これらの関数はMatchOptions をサポートします。 既定:
- これらの関数は、大文字と小文字を区別する一致を実行します。 大文字と小文字を区別しない照合を実行するには MatchOptions.IgnoreCase を使用します。
- IsMatchはテキスト文字列全体 (Complete MatchOption) と一致し、テキスト文字列内の任意の場所 (MatchOption を含む) をMatchして検索MatchAll。 シナリオに応じて完了、含む、BeginsWith、または EndsWith を使用します。
IsMatch は、テキスト文字列がパターンと一致する場合は true 、一致しない場合は false を返します。 Match は、IsBlank 関数でテストできる一致が見つからない場合は空白を返します。 MatchAll IsEmpty 関数でテストできる一致が見つからない場合は、空のテーブルが返されます。
MatchAllを使用してテキスト文字列を分割する場合は、Split 関数を使用することを検討してください。これは、より簡単で高速です。
パターン
これらの関数を使用する鍵は、一致のパターンを記述することです。 パターンは、以下を組み合わせたテキスト文字列で記述します:
- "abc" や "123" などの通常文字。
- レター、MultipleDigits、電子メール などの事前定義済みのパターン。 ( Match 列挙型はこれらのパターンを定義します)。
- "\d+\s+\d+" または "[a-z]+" などの正規表現コード。
文字列連結演算子 > を使用してこれらの要素を結合します。 たとえば、"abc" & Digit & "\s+" は有効なパターンであり、後ろに 0 から 9 までの数字と少なくとも 1 つの空白文字が付いた文字 "a"、"b"、"c" に一致します。
通常文字
最も単純なパターンは、正確に一致する通常の文字のシーケンスです。
たとえば、 IsMatch 関数で使用する場合、文字列 "Hello" は パターン "Hello" と 正確に一致します。 過不足がありません。 文字列 "hello!" は、末尾の感嘆符と文字 "h" の大文字と小文字が間違っているため、パターンと一致しません。 (この動作を変更する方法については、 Match オプション を参照してください)。
パターン言語では、 . ? * + ( ) [ ] ^ $ | \ 文字は特別な目的のために予約されています。 これらの文字を使用するには、文字の前に \ (円記号) を付けて文字を文字として取る必要があることを示すか、定義済みのパターンのいずれかを使用します。 たとえば、パターン "Hello?"を疑問符の前に円記号を付けて使用することで、文字列"Hello\\?"を照合できます。
事前定義済みパターン
事前定義済みのパターンは、文字セットの 1 つ、または一連の複数の文字を簡単に一致させる方法を提供します。 文字列連結演算子 & を使用して、独自のテキスト文字列をMatch列挙型のメンバーと結合します。
| Match 列挙型 | 内容 | 正規表現 |
|---|---|---|
| どれでも | 任意の文字と一致します。 | . |
| コンマ | コンマ ,と一致します。 |
, |
| 桁 | 1 桁の数と一致します ("0"~"9")。 | \d |
| 電子メール | "at" 記号 ("@") およびドット (".") が付いたドメイン名が含まれている電子メール アドレスと一致します | 注を参照してください |
| ハイフン | ハイフンと一致します。 |
-
注を参照してください |
| 左括弧 | 左かっこ (と一致します。 |
\( |
| 手紙 | 文字と一致します。 | \p{L} |
| 複数桁 | 1 桁以上の数と一致します。 | \d+ |
| 複数の文字 | 1 つ以上の文字と一致します。 | \p{L}+ |
| 複数の非スペース | 空白 (スペース、タブまたは改行) を追加しない 1 つ以上の文字と一致します。 | \S+ |
| 複数のスペース | 空白 (スペース、タブ、または改行) を追加する 1 つ以上の文字と一致します。 | \s+ |
| ノンスペース | 空白を追加しない 1 文字と一致します。 | \S |
| オプション数字 | 0、または 1 桁以上の数と一致します。 | \d* |
| オプション文字 | 0 または 1 文字以上と一致します。 | \p{L}* |
| オプションの非スペース | 空白文字を追加しない 0 または 1 文字以上と一致します。 | \S* |
| オプションスペース | 空白文字を追加する 0 または 1 文字以上と一致します。 | \s* |
| 期間 | ピリオドまたはドットの .に一致します。 |
\. |
| 右括弧 | 右かっこ )に一致します。 |
\) |
| 空間 | 空白を追加する 1 文字と一致します。 | \s |
| タブ | タブの文字と一致します。 | \t |
たとえば、パターン "A" と MultipleDigits は 、文字 "A" の後に 1 桁以上の数字が続く文字と一致します。
Power Apps では、Matchに別の定義が使用されます。電子メールとMatch。ハイフン。
Text( Match.Email )を評価して、ホストで使用されている正規表現を確認します。
正規表現
これらの関数で使用されるパターンは 、正規表現と呼ばれます。 Power Fx の正規表現の特定の方言は、 Power Fx の正規表現で詳しく説明されています。
正規表現は強力であり、さまざまな目的に対応します。 また、句読点のランダムなシーケンスのように見えることもあります。 この記事では、正規表現のすべての側面について説明するわけではありませんが、豊富な情報、チュートリアル、ツールをオンラインで利用できます。
正規表現は長い歴史があり、多くのプログラミング言語で使用できます。 すべてのプログラミング言語には正規表現の独自の方言があり、標準はほとんどありません。 同じ正規表現がすべての Power Fx 実装で同じ結果を得られるように努めています。 互換性は、大きな違いがある JavaScript と .NET 上で Power Fx が実行されるため、簡単には実現できません。 さまざまなプラットフォームでの実行に対応するために、Power Fx 正規表現は、業界全体で広くサポートされている機能のサブセットに限定されています。
その結果、他の環境で動作する可能性のある正規表現の一部がブロックされたり、Power Fx で調整が必要になる場合があります。 作成時間エラーは、サポートされていない機能が発生すると報告されます。 これは、正規表現とオプションが動的ではなくオーサリング時間定数である必要がある理由の 1 つです (たとえば、変数で指定されます)。
注
Power Apps では、以前のバージョンの Power Fx 正規表現が使用され、制限が少なくなりますが、機能も少なくなります。 MatchOptions.DotAll と MatchOptions.FreeSpacing は使用できません。また、Matchの定義も使用できません。電子メールとMatch。ハイフンは異なります。 Unicode サロゲート ペアは 1 文字として扱われません。 MatchOptions.NumberedSubMatches が既定値です。 ここで説明する正規表現のバージョンは、"Power Fx V1.0 互換性" スイッチの下で、すぐに Power Apps で使用できるようになります。
数値の解析の複雑さを増す正規表現の基本的な要素を次に示します。
| 特徴 | Example | 内容 |
|---|---|---|
| Predfined 文字クラス | \d |
この正規表現は、 1など、1 つの数値と一致します。 文字クラスは一連の文字と一致し、\dは0に9標準の数字と一致し、Unicode 文字カテゴリ "Nd" で定義されている数字にも一致します。
\wを持つ文字と数字の文字クラスと、\sの改行を含むスペースがあります。 大文字の逆文字クラスもあります。 \D は、 \d が一致しないものすべてに一致します。 |
| 1 つ以上 | \d+ |
この正規表現は、 123などの 1 つ以上の数値と一致します。 要素の後の + が、最後の要素の "1 つ以上" と表示されます。 |
| 0 または 1 | \+?\d |
この正規表現は、省略可能な + 記号の後に 1 つ以上の数値 ( +123 や 123など) と一致します。 要素の後の ? が "これは省略可能であり、0 回または 1 回発生する可能性があります" と表示されます。
+の前に円記号があり、"1 つ以上" の使用法ではなくリテラル文字として区別されます。 |
| グループ化と代替 | (-|\+)?\d+ |
この正規表現は、 + 記号または -のいずれかと一致し、必要に応じて、 -123、 +123、 123などの一連の数値と一致します。 ここでは、よく一緒に使用される 2 つの概念を紹介します。 まず、 ? が作用するために、要素のセットとしてグループ化するかっこがあります。 次に、"this or that" という | があります。 |
| カスタム文字クラス | (-|\+)?\d+[eE][\-\+]?\d+ |
この正規表現は、2 つの文字クラスを持つミックスに指数を追加し、 +123e-12一致します。 文字クラスは、よりコンパクトな形式で "これらの 1 つに一致する" | 代替に似ています。
+と同様に、-は正規表現文字クラスで特別な意味を持つので、エスケープする必要があります。 |
| 0 以上 | (-|\+)?\d+\.?\d*[eE][\-\+]?\d+ |
この正規表現は、 -123.456e-89 や -123.E+32など、数値の整数部分の後に 10 進数を追加します。 小数点の後の \d には、小数点の後の 10 進数に対して "0 回以上" と表示される * 量指定子があります。 . |
| グループのキャプチャ | (?<number>(-|\+)?\d+\.?\d*)[eE](?<exponent>[\-\+]?\d+) |
最後に、 number と exponentのキャプチャ グループを追加します。 正規表現は文字列全体と一致できるだけでなく、数式で使用する部分を抽出することもできます。この場合、 e (または E) の前の部分と後の部分を抽出することもできます。 |
これらの例では、正規表現でできることの少しの味しか与えられません。 ID 番号、メール アドレス、電話番号、日付と時刻を検証し、あらゆる種類のテキスト ファイルから情報を抽出するために一般的に使用されます。 Power Fx で正規表現を読み、実験し、Web を使用して詳細を確認して、体験を続けます。
Match のオプション
これらの関数の動作を変更するには、文字列連結演算子 (> を使用して結合する 1 つ以上のオプション) を指定します。
| MatchOptions 列挙型 | 内容 | 正規表現への影響 |
|---|---|---|
| MatchOptions.BeginsWith | パターンはテキストの先頭から一致する必要があります。 | 正規表現の先頭に ^ を追加します。 |
| マッチオプション.完了 | Power Apps での IsMatch の既定値。 このパターンは、最初から最後まで、テキストの文字列全体と一致します。 | 正規表現の開始位置に ^、末尾に $ を追加します。 |
| マッチオプション.Contains | MatchとMatchAllの既定値、および Power Apps の外部でのIsMatch。 パターンは、テキストのどこかに表示する必要がありますが、先頭または末尾である必要はありません。 | 正規表現を変更しません。 |
| MatchOptions.DotAll | 改行文字を含むすべての文字に一致するように、 . (ドット) 演算子の動作を変更します。 Power Apps では使用できません。 |
正規表現を変更しません。 このオプションは、正規表現の標準の "s" 修飾子に相当します。 |
| マッチオプション.EndsWith | パターンはテキストの文字列の末尾と一致する必要があります。 | 正規表現の末尾に $ を追加します。 |
| MatchOptions.FreeSpacing | 正規表現では、改行を含む空白文字は無視されます。
#で始まる行末コメントは無視されます。 Power Apps では使用できません。 |
正規表現の構文を変更するだけです。 このオプションは、正規表現の標準の "x" 修飾子に相当します。 |
| マッチオプション.大文字と小文字を区別しない | 大文字と小文字を同じものとして扱います。 既定では、一致は大文字と小文字を区別します。 | 正規表現を変更しません。 このオプションは、正規表現の標準の「i」修飾子と同等です。 |
| マッチオプション.複数行 |
^と$の動作を、aline の末尾に一致するように変更します。 |
正規表現を変更しません。 このオプションは、正規表現の標準の「m」修飾子と同等です。 |
| MatchOptions.NumberedSubMatches | 名前付きキャプチャは、理解と保守が容易であるため、優先されます。 不要なキャプチャが保持されないため、パフォーマンスも向上します。 ただし、古い正規表現の場合、かっこの各セットは、結果の SubMatches テーブルに含まれる番号付きキャプチャとして扱います。 Power Apps の既定値。 | 正規表現を変更しません。 名前付きキャプチャが無効になり、 \1 スタイルのバック参照が有効になります。 |
MatchAllの使用は、正規表現に標準の "g" 修飾子を使用する場合と同じです。
構文
IsMatch( Text, Pattern [, Options ] )
- テキスト – 必須。 テストするテキスト文字列。
- パターン – 必須。 テキスト文字列としてテストするパターン。 Match列挙型が定義または正規表現を提供する定義済みのパターンを連結します。 パターン は、変数、データ ソース、またはアプリの実行時に変更されるその他の動的参照を含まない定数数式である必要があります。 式は "Match" として表す必要があることに注意してください。PredefinedPattern" (例: Match)。電子メール
- オプション – オプション。 MatchOptions 列挙値を組み合わせたテキスト文字列。 既定では MatchOptions.Complete が使用されます。 オプション は、変数、データ ソース、またはアプリの実行時に変更されるその他の動的参照を含まない定数数式である必要があります。
Match( Text, Pattern [, Options ] )
- テキスト – 必須。 一致するテキスト文字列。
- パターン – 必須。 テキスト文字列として一致するパターン。 Match列挙型が定義する定義済みのパターンを連結するか、正規表現を指定します。 パターン は、アプリの実行時に変化する変数、データ ソース、その他の動的参照を含まない定数式である必要があります。
- オプション – オプション。 MatchOptions 列挙値を組み合わせたテキスト文字列。 既定では、MatchOptions.Complete が使用されます。 オプション は、変数、データ ソース、またはアプリの実行時に変更されるその他の動的参照を含まない定数数式である必要があります。
MatchAll( Text, Pattern [, Options ] )
- テキスト – 必須。 一致するテキスト文字列。
- パターン – 必須。 テキスト文字列として一致するパターン。 Match列挙型が定義または正規表現を提供する定義済みのパターンを連結します。 パターン は、変数、データ ソース、またはアプリの実行時に変更されるその他の動的参照を含まない定数数式である必要があります。
- オプション – オプション。 MatchOptions 列挙値を組み合わせたテキスト文字列。 既定では、MatchOptions.Complete が使用されます。 オプション は、変数、データ ソース、またはアプリの実行時に変更されるその他の動的参照を含まない定数数式である必要があります。
IsMatch 例
通常文字
アプリに TextInput1 という名前のテキスト入力コントロールがある場合を想像してください。 ユーザーはこのコントロールに値を入力して、データベースに格納します。
ユーザーは、TextInput1 に「Hello world」と入力します。
| 計算式 | 内容 | 結果 |
|---|---|---|
IsMatch( TextInput1.Text, "Hello world" ) |
ユーザーの入力が文字列「Hello World」に正確に一致するかどうかをテストします。 | 真実 |
IsMatch( TextInput1.Text, "Good bye" ) |
ユーザーの入力が文字列「Good bye」に完全に一致するかどうかをテストします。 | 間違い |
IsMatch( TextInput1.Text, "hello", Contains ) |
ユーザーの入力に単語「hello」 (大文字と小文字の区別) が含まれているかどうかをテストします。 | 間違い |
IsMatch( TextInput1.Text, "hello", Contains & IgnoreCase ) |
ユーザーの入力に単語「hello」 (大文字と小文字を区別しない) が含まれているかどうかをテストします。 | 真実 |
事前定義済みパターン
| 計算式 | 内容 | 結果 |
|---|---|---|
IsMatch( "123-45-7890", Match.Digit & Match.Digit & Match.Digit & Match.Digit & Match.Digit & Match.Digit & Match.Digit & Match.Digit & Match.Digit & Match.Digit & Match.Digit ) |
米国の社会保障番号と一致します | 真実 |
IsMatch( "joan@contoso.com", Match.Email ) |
電子メール アドレスと一致します | 真実 |
IsMatch( "123.456", Match.MultipleDigits & Match.Period & Match.OptionalDigits ) |
一連の数字、ピリオド、0 以上の数字と一致します。 | 真実 |
IsMatch( "123", Match.MultipleDigits & Match.Period & Match.OptionalDigits ) |
一連の数字、ピリオド、0 以上の数字と一致します。 一致するテキストにピリオドが表示されないため、このパターンは一致されません。 | 間違い |
正規表現
| 計算式 | 内容 | 結果 |
|---|---|---|
IsMatch( "986", "\d+" ) |
0 以上の整数と一致します。 | 真実 |
IsMatch( "1.02", "\d+(\.\d\d)?" ) |
正の通貨金額と一致します。 入力に小数点が含まれる場合、入力には小数点の後ろに 2 つの数値が含まれている必要があります。 たとえば、3.00 は有効ですが、3.1 は無効です。 | 真実 |
IsMatch( "-4.95", "(-)?\d+(\.\d\d)?" ) |
正または負の通貨金額と一致します。 入力に小数点が含まれる場合、入力には小数点の後ろに 2 つの数値が含まれている必要があります。 | 真実 |
IsMatch( "111-11-1111", "\d{3}-\d{2}-\d{4}" ) |
米国の社会保障番号と一致します。 形式、型、および指定された入力フィールドの長さを検証します。 一致する文字列には、3 つの数値とそれに続くダッシュ、2 つの数値とそれに続くダッシュ、4 つの数値を含む必要があります。 | 真実 |
IsMatch( "111-111-111", "\d{3}-\d{2}-\d{4}" ) |
前の例と同じですが、入力内のハイフンの 1 つが所定の位置外にあります。 | 間違い |
IsMatch( "AStrongPasswordNot", "(?!^[0-9]\*$)(?!^[a-zA-Z]\*$)([a-zA-Z0-9]{8,10})" ) |
8 文字、9 文字、または 10 文字、少なくとも 1 桁の数字、および少なくとも 1 つの英字を含む必要がある強力なパスワードを検証します。 文字列に特殊文字を含めることはできません。 | 間違い |
Match と MatchAll の例
| 計算式 | 内容 | 結果 |
|---|---|---|
Match( "Bob Jones <bob.jones@contoso.com>", "<(?<email>" & Match.Email & ")>") |
連絡先情報の電子メール部分のみを抽出します。 | { 電子メール: "bob.jones@contoso.com"、 FullMatch: "<bob.jones@contoso.com>"、 StartMatch: 11 } |
Match( "Bob Jones <InvalidEmailAddress>", "<(?<email>" & Match.Email & ")>" |
連絡先情報の電子メール部分のみを抽出します。 有効な住所が見つからない (@ 記号がない) ため、関数はblankに返します。 | 空白 |
Match( Language(), "(<language>\w{2})(?:-(?<script>\w{4}))?(?:-(?<region>\w{2}))?" ) |
言語、スクリプト、および地域の Language 関数が返す言語タグの一部を抽出します。 これらの結果は米国を反映しています; その他の例については、Language 関数ドキュメント を参照してください。 (?: 別のサブマッチを作成しない文字グループの演算子。 | { language: "en", script: blank, region: "US", FullMatch: "en-US"、 StartMatch: 1 } |
Match( "PT2H1M39S", "PT(?:(?<hours>\d+)H)?(?:(?<minutes>\d+)M)?(?:(?<seconds>\d+)S)?" ) |
ISO 8601 期間値から時間、分、秒を抽出します。 抽出された数値はテキスト文字列のままです; 算術演算が実行される前に数値に変換するのにValue 関数を使用します。 | { hours: "2", 分: "1", seconds: "39", FullMatch: "PT2H1M39S", StartMatch: 1 } |
最後の例の詳細をより細かく見てみましょう。 Time 関数を使用してこの文字列を日付/時刻値に変換する場合は、名前付きサブマッチを個別に渡す必要があります。 これを行うには、Matchが返すレコードで With 関数を使用します。
With(
Match( "PT2H1M39S", "PT(?:(?<hours>\d+)H)?(?:(?<minutes>\d+)M)?(?:(?<seconds>\d+)S)?" ),
Time( Value( hours ), Value( minutes ), Value( seconds ) )
)
これらの例では、Button コントロールを追加し、OnSelect プロパティをこの計算式に設定し、ボタンを選択します:
Set( pangram, "The quick brown fox jumps over the lazy dog." )
| 計算式 | 内容 | 結果 |
|---|---|---|
Match( pangram, "THE", IgnoreCase ) |
パングラム変数に含まれるテキスト文字列で「THE」に一致するものをすべて検索します。 文字列には 2 つの一致が含まれていますが、MatchAllではなくMatchを使用しているため、最初の文字列のみが返されます。 | { FullMatch: "The", StartMatch: 32 } |
MatchAll( pangram, "the" ) |
パングラム変数に含まれるテキスト文字列で「THE」に一致するものをすべて検索します。 テストでは大文字と小文字が区別されるため、「the」の 2 番目のインスタンスのみが見つかりました。 |

|
MatchAll( pangram, "the", IgnoreCase ) |
パングラム変数に含まれるテキスト文字列で「THE」に一致するものをすべて検索します。 この場合、テストでは大文字と小文字が区別されないため、単語の両方のインスタンスが見つかりました。 |

|
MatchAll( pangram, "\b\wo\w\b" ) |
中央に "o" がある 3 文字の単語をすべて検索します。 "brown" は 3 文字の単語ではないため除外されるため、"\b" (単語の境界) に一致しません。 |

|
Match( pangram, "\b\wo\w\b\s\*(?<between>\w.+\w)\s\*\b\wo\w\b" ) |
「fox」と「dog」の間のすべての文字に一致します。 | { between:"jumpsoverthelazy"、 FullMatch: "fox jumps over the lazy dog"、 StartMatch: 17 } |
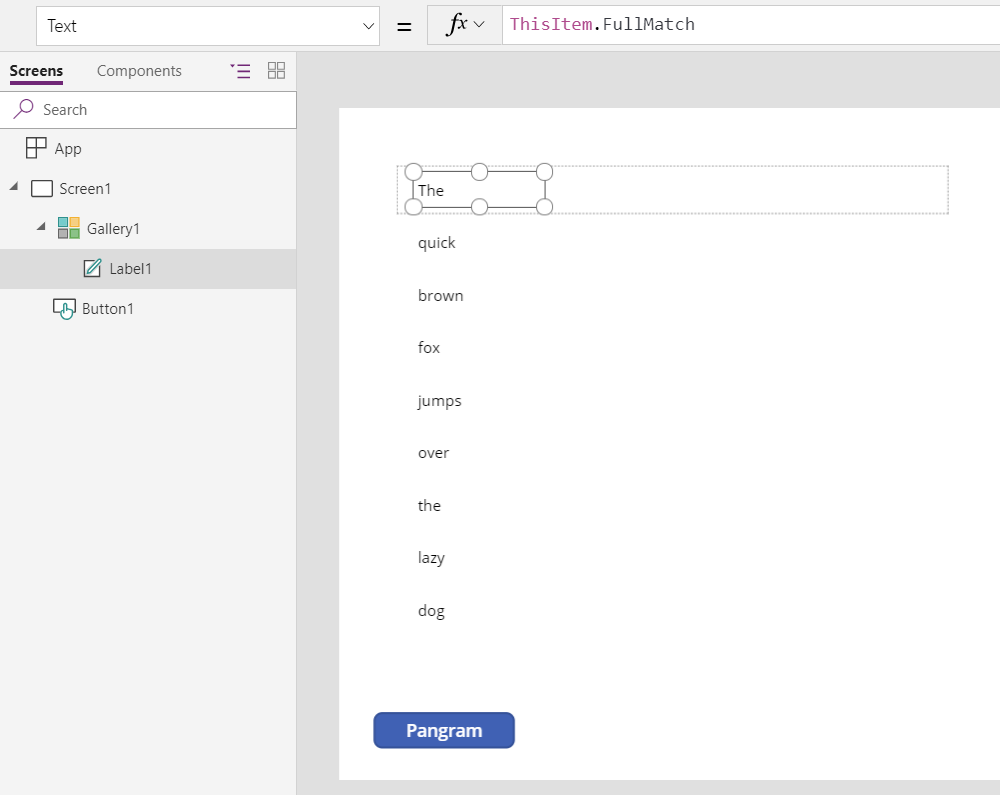
ギャラリーで MatchAll の結果を表示するには:
空の画面で、空の垂直 ギャラリー コントロールを挿入します。
ギャラリーの Items プロパティを MatchAll( pangram, "\w+" ) または MatchAll( pangram, MultipleLetters ) に設定します。
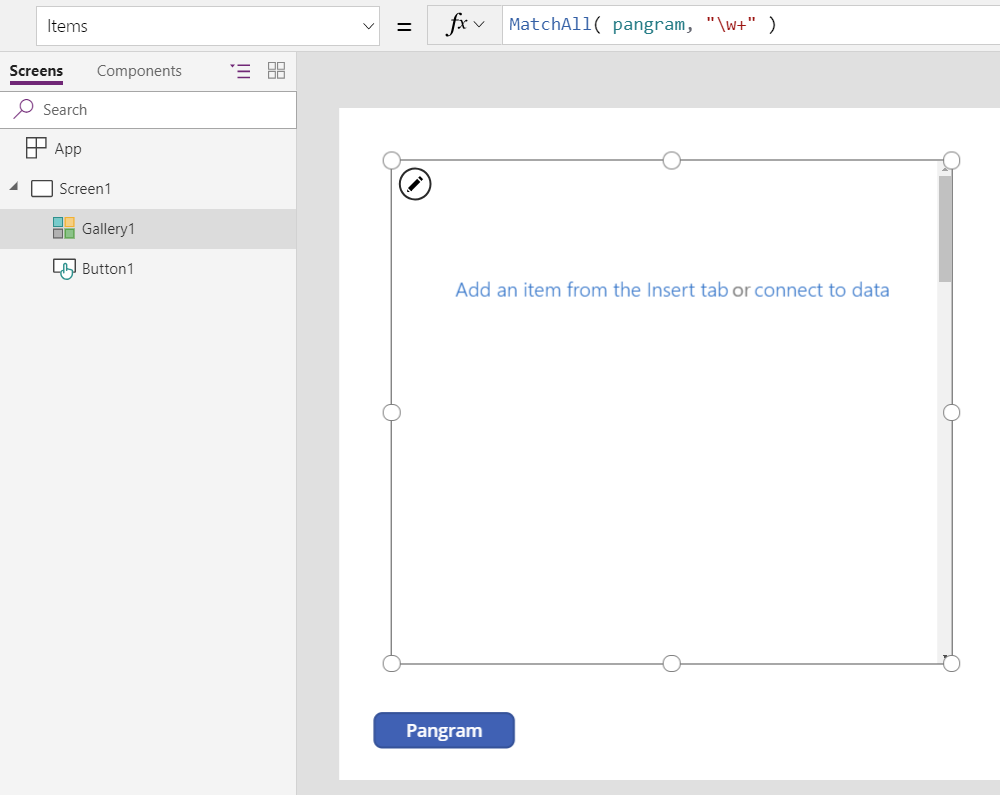
ギャラリーのテンプレートを選択するため、ギャラリー コントロールの中央にある「挿入タブからアイテムを追加」を選択します。
Label コントロールをギャリーのテンプレートに追加します。
ラベルの Text プロパティを ThisItem.FullMatch に設定します。
ギャラリーは、サンプル テキストの各単語が設定されます。 1 つの画面ですべての単語を表示するには、ギャラリーのテンプレートとラベル コントロールのサイズを変更します。