この記事には、Power Query のデータ ラングリング エクスペリエンスを最大限に活用するためのヒントとテクニックが含まれています。
適切なコネクタを選択する
Power Query には、膨大な数のデータ コネクタが用意されています。 これらのコネクタは、TXT、CSV、Excel ファイルなどのデータ ソースから、Microsoft SQL Server などのデータベース、Microsoft Dynamics 365 や Salesforce などの一般的な SaaS サービスまで多岐に及びます。 [データの 取得 ] ウィンドウにデータ ソースが表示されない場合は、常に ODBC または OLEDB コネクタを使用してデータ ソースに接続できます。
タスクに最適なコネクタを使用すると、最適なエクスペリエンスとパフォーマンスが得られます。 たとえば、SQL Server データベースに接続するときに ODBC コネクタの代わりに SQL Server コネクタを使用すると、 データの取得 エクスペリエンスが向上するだけでなく、SQL Server コネクタには、クエリ フォールディングなどのエクスペリエンスとパフォーマンスを向上させる機能も用意されています。 クエリ フォールディングの詳細については、 Power Query のクエリ評価とクエリ フォールディングの概要に関するページを参照してください。
各データ コネクタは、「 データの取得」で説明されている標準的なエクスペリエンスに従います。 この標準化されたエクスペリエンスには、 Data Preview というステージがあります。 この段階では、コネクタが許可する場合に、データ ソースから取得したいデータを選択するための使いやすいウィンドウと、そのデータの簡易プレビューが提供されます。 [ナビゲーター] ウィンドウを使用して、データ ソースから複数のデータ セットを選択することもできます。

注
Power Query で使用可能なコネクタの完全な一覧を表示するには、Power Query のコネクタに移動します。
早期にフィルター処理する
クエリの初期段階またはできるだけ早い段階でデータをフィルター処理することをお勧めします。 一部のコネクタでは、 Power Query でのクエリ評価とクエリ フォールディングの概要に関するページで説明されているように、クエリ フォールディングを使用してフィルターを利用します。 また、ケースに関連しないデータを除外することもベスト プラクティスです。 このフィルター処理を使用すると、データ プレビュー セクションに関連するデータのみを表示することで、目の前のタスクに集中できます。
列で見つかった値の個別の一覧を表示する自動フィルター メニューを使用して、保持または除外する値を選択できます。また、検索バーを使用して、列の値を見つけることもできます。
![列の値が強調されている Power Query の [自動フィルター] メニューのスクリーンショット。](media/best-practices-power-query/filter-values-auto-filter-menu.png)
型固有のフィルターを利用して、日付、datetime、または日付タイムゾーン列に対して過去にといったフィルターを適用することもできます。
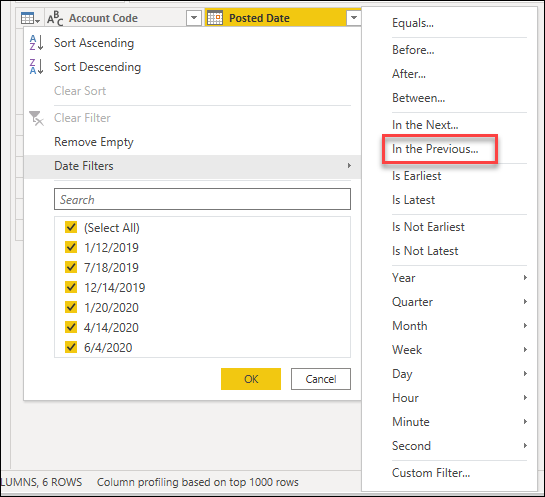
これらの種類固有のフィルターは、以前の x 秒、分、時間、日、週、月、四半期、または年数のデータを常に取得する動的フィルターを作成するのに役立ちます。
フィルター行のダイアログのスクリーンショットで、前の日付に基づくフィルターが表示されている。
注
列の値に基づいてデータをフィルター処理する方法の詳細については、「 値でフィルター処理する」を参照してください。
コストの高い操作を最後に実行する
特定の操作では、いかなる 結果を返すために完全なデータソースを読み取る必要があるため、Power Query エディターでのプレビューに遅延が発生します。 たとえば、並べ替えを実行すると、最初のいくつかの並べ替えられた行がソース データの末尾にある可能性があります。 そのため、結果を返すには、すべての行を読み取ってからソートを行う必要があります。
その他の操作 (フィルターなど) では、結果を返す前にすべてのデータを読み取る必要はありません。 代わりに、"ストリーミング" と呼ばれる方法でデータを操作します。 データが "ストリーム" され、結果が途中で返されます。 Power Query エディターでは、このような操作は、プレビューを設定するのに十分な量のソース データを読み取るだけで済みます。
可能であれば、このようなストリーミング操作を最初に実行し、よりコストの高い操作を最後に実行します。 この順序で操作を実行すると、新しいステップをクエリに追加するたびにプレビューがレンダリングされるのを待つ時間を最小限に抑えることができます。
データのサブセットに対して一時的に作業する
Power Query エディターでクエリに新しいステップを追加するのが遅い場合は、最初に "最初の行を保持する" 操作を実行し、操作対象の行数を制限することを検討してください。 次に、必要なすべての手順を追加したら、[最初の行を保持] ステップを削除します。
適切なデータ型を使用する
Power Query の一部の機能は、選択した列のデータ型に依存します。 たとえば、日付列を選択すると、[列の追加] メニューの [日付と時刻] 列グループで使用できるオプションが使用できます。 ただし、列にデータ型が設定されていない場合、これらのオプションはグレー表示されます。
![[列の追加] メニューの種類固有のオプションを示す Power Query リボンのスクリーンショット。](media/best-practices-power-query/type-specific-filter-for-date.png#lightbox)
型固有のフィルターは特定のデータ型に固有であるため、同様の状況が発生します。 列に正しいデータ型が定義されていない場合、これらの型固有のフィルターは使用できません。
列の正しいデータ型を常に操作することが重要です。 データベースなどの構造化データ ソースを操作すると、データベース内のテーブル スキーマからデータ型情報が取得されます。 ただし、TXT や CSV ファイルなどの非構造化データ ソースの場合は、そのデータ ソースからの列に適切なデータ型を設定することが重要です。 既定では、Power Query では、非構造化データ ソースに対して自動データ型検出が提供されます。 この機能の詳細と、 それがデータ型でどのように役立つかを確認できます。
注
データ型の重要性とその使用方法の詳細については、「 データ型」を参照してください。
データを調査する
データの準備と新しい変換手順の追加を開始する前に、Power Query データ プロファイル ツール を有効にして、データに関する情報を簡単に検出することをお勧めします。

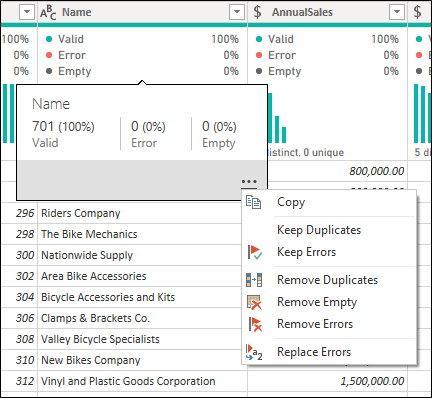
これらのデータ プロファイル ツールは、データの理解を深めるのに役立ちます。 このツールでは、次のような列ごとに情報を表示する小さな視覚化が提供されます。
- 列の品質 - 有効な値、エラー値、または空の値のカテゴリに該当する列の値の数を表す小さな横棒グラフと 3 つのインジケーターを提供します。
- 列の分布 - 各列の値の頻度と分布を示す、列の名前の下に一連のビジュアルを提供します。
- 列プロファイル - 列とその列に関連付けられている統計情報をより詳細に表示します。
データの準備に役立つこれらの機能を操作することもできます。
注
データ プロファイル ツールの詳細については、データ プロファイル ツールに関 するページを参照してください。
作業を文書化する
必要に応じて、手順、クエリ、またはグループの名前を変更するか、説明を追加してクエリを文書化することをお勧めします。
Power Query では、適用されたステップ ウィンドウにステップ名が自動的に作成されますが、ステップの名前を変更したり、いずれかのステップに説明を追加したりすることもできます。
注
適用されたステップ ペイン内にある使用可能なすべての機能とコンポーネントの詳細については、「適用されたステップの 使用」リストを参照してください。
モジュール方式のアプローチを採用する
必要になる可能性のあるすべての変換と計算を含む 1 つのクエリを作成することは完全に可能です。 ただし、クエリに多数のステップが含まれている場合は、クエリを複数のクエリに分割し、1 つのクエリで次のクエリを参照することをお勧めします。 このアプローチの目的は、変換フェーズを簡略化して小さな部分に分離し、理解しやすくすることです。
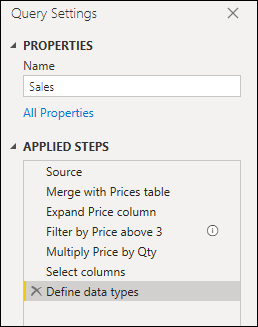
たとえば、次の図に示す 9 つの手順を含むクエリがあるとします。
このクエリは、[ Merge with Prices]\(価格とのマージ\) テーブル ステップで 2 つに分割できます。 こうすることで、マージの前に販売クエリに適用された手順を理解しやすくなります。 この操作を行うには、[ 価格とのマージ] テーブル ステップを右クリックし、[ 前へ抽出 ] オプションを選択します。
![[前のステップの抽出] が強調されている、適用されたステップのコンテキスト メニューのスクリーンショット。](media/best-practices-power-query/extract-previous.png)
その後、新しいクエリに名前を付けるダイアログが表示されます。 この手順では、クエリを効果的に 2 つのクエリに分割します。 1 つのクエリには、マージ前のすべてのクエリがあります。 もう 1 つのクエリでは、新しいクエリを参照する初めのステップと、「Merge with Prices テーブル」ステップ以下にある元のクエリの残りの手順が含まれています。
必要に応じてクエリ参照を利用することもできます。 ただし、多くの手順で一見すると難しくないレベルでクエリを維持することをお勧めします。
注
クエリの参照の詳細については、「クエリ の概要」ウィンドウを参照してください。
グループを作成する
作業を整理する優れた方法は、クエリ ウィンドウでグループを使用することです。
![Power Query でグループを操作する方法を示す [クエリ] ペインのコンテキスト メニューのスクリーンショット。](media/best-practices-power-query/queries-pane-move-to-group.png)
グループの唯一の目的は、クエリのフォルダーとして機能することで作業を整理し続けることです。 必要に応じて、グループ内にグループを作成できます。 グループ間でのクエリの移動は、ドラッグ アンド ドロップと同じくらい簡単です。
自分とケースにとって意味のあるわかりやすい名前をグループに付けてみてください。
注
クエリ ウィンドウ内にある使用可能なすべての機能とコンポーネントの詳細については、「クエリ ウィンドウについて」を参照 してください。
将来の検証クエリ
今後の更新中に問題が発生しないクエリを作成することが最優先事項です。 Power Query には、変更に対するクエリの回復性を高め、データ ソースの一部のコンポーネントが変更された場合でも更新できるようにする機能がいくつかあります。
クエリの実行内容と、そのスコープに関連すると考える構造、レイアウト、列名、データ型、およびその他のコンポーネントの観点から、クエリのスコープを定義することをお勧めします。
変更に対するクエリの回復性を高めるのに役立つ変換の例を次に示します。
クエリにデータを含む動的な行数が含まれているが、削除するフッターとして機能する固定数の行がある場合は、[ 下位行の削除 ] 機能を使用できます。
注
行の位置によるデータのフィルター処理の詳細については、「行の位置で テーブルをフィルター処理する」を参照してください。
クエリに動的な数の列があるが、データ セットから特定の列のみを選択する必要がある場合は、[ 列の選択 ] 機能を使用できます。
注
列の選択または削除の詳細については、「列の 選択または削除」を参照してください。
クエリに動的な列数があり、列のサブセットのみをピボット解除する必要がある場合は、 選択した列のみをピボット解除 機能を使用できます。
注
列のピボットを解除するオプションの詳細については、「列の ピボット解除」を参照してください。
クエリに列のデータ型を変更するステップがあるが、値が目的のデータ型に準拠しないためにエラーが発生するセルがある場合は、エラー値を生成した行を削除できます。
注
エラーの処理と対処の詳細については、「エラーの 処理」を参照してください。
パラメーターを使用する
動的で柔軟なクエリを作成することをお勧めします。 Power Query のパラメーターは、クエリをより動的かつ柔軟にするのに役立ちます。 パラメーターは、さまざまな方法で再利用できる値を簡単に格納および管理する方法として機能します。 ただし、次の 2 つのシナリオでより一般的に使用されます。
ステップ引数: ユーザー インターフェイスから駆動される複数の変換の引数としてパラメーターを使用できます。
![変換引数の [パラメーターの選択] オプションが設定されている [行のフィルター] ダイアログのスクリーンショット。](media/best-practices-power-query/parameters-step-argument-sample-parameter-select-parameter.png)
カスタム関数引数: クエリから新しい関数を作成し、カスタム関数の引数としてパラメーターを参照できます。
![[クエリ] コンテキスト メニューの [関数の作成] オプションが強調され、[関数の作成] ダイアログのスクリーンショット。](media/best-practices-power-query/parameters-create-function.png)
パラメーターを作成して使用する主な利点は次のとおりです。
[ パラメーターの管理 ] ウィンドウを使用して、すべてのパラメーターの一元化されたビュー。
![[パラメーターの管理] ドロップダウン メニューのスクリーンショット。[新しいパラメーター] が強調され、[パラメーターの管理] ダイアログが強調されています。](media/best-practices-power-query/parameters-manage-parameters.png)
複数のステップまたはクエリでのパラメーターの再利用性。
カスタム関数の作成を簡単かつ簡単にします。
データ コネクタの引数の一部でパラメーターを使用することもできます。 たとえば、SQL Server データベースに接続するときに、サーバー名のパラメーターを作成できます。 その後、SQL Server データベース ダイアログ内でそのパラメーターを使用できます。
![サーバー名のパラメーターが設定された [SQL Server データベース] ダイアログのスクリーンショット。](media/best-practices-power-query/sql-server-parameter.png)
サーバーの場所を変更する場合は、サーバー名のパラメーターを更新するだけで、クエリが更新されます。
注
パラメーターの作成と使用の詳細については、「パラメーターの使用」を 参照してください。
再利用可能な関数を作成する
異なるクエリや値に同じ一連の変換を適用する必要がある場合があります。 この場合、必要な回数再利用できる Power Query カスタム関数を作成すると役に立つ可能性があります。 Power Query カスタム関数は、入力値のセットから 1 つの出力値へのマッピングであり、ネイティブ M 関数と演算子から作成されます。
たとえば、同じ変換セットを必要とする複数のクエリまたは値があるとします。 後で任意のクエリまたは値に対して呼び出すことができるカスタム関数を作成できます。 このカスタム関数は時間を節約し、一元的な場所で変換のセットを管理するのに役立ちます。これはいつでも変更できます。
Power Query カスタム関数は、既存のクエリとパラメーターから作成できます。 たとえば、複数のコードをテキスト文字列として持ち、それらの値をデコードする関数を作成するクエリがあるとします。
最初に、例として機能する値を持つパラメーターを指定します。
![サンプル パラメーター コード値が入力された [パラメーターの管理] ダイアログのスクリーンショット。](media/best-practices-power-query/sample-parameter-code.png)
そのパラメーターから、必要な変換を適用する新しいクエリを作成します。 この場合、PTY-CM1090-LAX コードを複数のコンポーネントに分割します。
- Origin = PTY
- 目的地 = LAX
- 航空会社 = CM
- FlightID = 1090

その後、クエリを右クリックして [関数の作成] を選択すると、そのクエリを 関数に変換できます。 最後に、任意のクエリまたは値にカスタム関数を呼び出すことができます。

さらにいくつかの変換が行われると、目的の出力に達し、カスタム関数からこのような変換のロジックを適用したことがわかります。

注
Power Query でカスタム関数を作成して使用する方法の詳細については、 カスタム関数に関する記事を参照してください。