異なるクエリや値に同じ変換セットを適用する必要がある場合は、必要な回数再利用できるPower Queryカスタム関数を作成すると役に立つ可能性があります。 Power Queryカスタム関数は、入力値のセットから 1 つの出力値へのマッピングであり、ネイティブ M 関数と演算子から作成されます。
Power Query M 数式言語を使用して、独自のPower Queryカスタム関数を手動で作成することも、カスタム関数の作成と管理のプロセスを高速化、簡略化、および強化する機能をPower Queryユーザー インターフェイスで提供することもできます。
まず、UI でコードを使用してカスタム関数を作成基本的な手順について説明します。次に、インターフェイスを使用して、複雑なアクションを再利用可能な関数 にすることに重点を置きます。
重要
この記事では、Power Query ユーザー インターフェイスでアクセス可能な一般的な変換を使用して、Power Queryを使用してカスタム関数を作成する方法について説明します。 ここでは、カスタム関数を作成するための主要な概念と、この記事で参照されている特定の変換の詳細については、Power Queryドキュメントの他の記事へのリンクに焦点を当てています。
UI のコードからカスタム関数を作成する
手記
次の手順は、Power BI Desktop で実行するか、WindowsのExcelにあるPower Query エクスペリエンスを使用して実行できます。
コネクタ エクスペリエンスを使用して、データが収容されている場所に接続します。 データを選択したら、[データの変換] または [編集] ボタンを選択します。 これにより、Power Queryエクスペリエンスが実現します。
左側の クエリ ペインで空白の場所を右クリックします。
空のクエリを選択します。
新しい空のクエリ ウィンドウで、[ホーム] メニュー を選択し、[高度なエディタ] を開きます。
テンプレートをカスタム関数に置き換えます。 例えば次が挙げられます。
let HelloWorld = () => ("Hello World") in HelloWorld[完了] を選びます。
Power Query M 数式言語を使用したカスタム関数の開発の詳細については、次の記事を参照してください: M 関数Power Queryの理解。 以降のセクションでは、Power Query ユーザー インターフェイスを使用してコードを記述せずにカスタム関数を開発する方法と、クエリでカスタム関数を呼び出す方法について説明するチュートリアルがあります。
テーブル参照チュートリアルからカスタム関数を作成する
手記
次の例は、Power BI Desktop で見つかったデスクトップ エクスペリエンスを使用して作成され、WindowsのExcelで見つかったPower Query エクスペリエンスを使用して実行することもできます。
この例に従うには、次の ダウンロード リンクから、この記事で使用されているサンプル ファイルをダウンロードします。 わかりやすくするために、この記事ではフォルダー コネクタを使用します。 フォルダー コネクタの詳細については、「フォルダー に関するページを参照してください。 この例の目的は、すべてのファイルのすべてのデータを 1 つのテーブルに結合する前に、そのフォルダー内のすべてのファイルに適用できるカスタム関数を作成することです。
まず、フォルダー コネクタ エクスペリエンスを使用して、ファイルが配置されているフォルダーに移動し、[データ の変換] 選択するか、[の編集]選択します。 これらの手順を実行すると、Power Queryエクスペリエンスに取り組みます。 [コンテンツ] フィールドから任意の バイナリ 値を右クリックし、[新しいクエリとして追加] オプションを選択。 この例では、リストから最初のファイルを選択しました。それがファイル 4月 2019.csvになります。

このオプションでは、実質的にそのファイルに直接バイナリとしてナビゲーション ステップを含む新しいクエリが作成されます。この新しいクエリの名前は、選択したファイルのファイル パスです。 このクエリの名前をサンプル ファイル に変更します。

名前が ファイルパラメーター で、種類が バイナリである新しいパラメーター を作成します。 サンプルファイル クエリを 既定値 および 現在の値として使用します。

手記
Power Queryでパラメーターを作成および管理する方法を理解するには、パラメーターの使用に関する記事を参照することをお勧めします。
カスタム関数は、任意のパラメーター型を使用して作成できます。 パラメーターとしてバイナリを持つカスタム関数の要件はありません。
バイナリ パラメーターの種類は、バイナリに評価されるクエリがある場合、パラメーター ダイアログ [種類] ドロップダウン メニュー内にのみ表示されます。
パラメーターを指定せずにカスタム関数を作成できます。 これは、関数が呼び出されている環境から入力を推論できるシナリオでよく見られます。 たとえば、環境の現在の日付と時刻を受け取り、それらの値から特定のテキスト文字列を作成する関数です。
クエリ ペインで ファイル パラメーター を右クリックします。 [参照] オプションを選びます。
![ファイル パラメーターの [参照] オプションが選択されているスクリーンショット。](media/custom-function/reference-file-parameter.png)
新しく作成したクエリの名前を File Parameter (2) から Transform Sample fileに変更します。

この新しい 変換サンプル ファイル クエリを右クリックし、関数の作成 オプションを選択します。
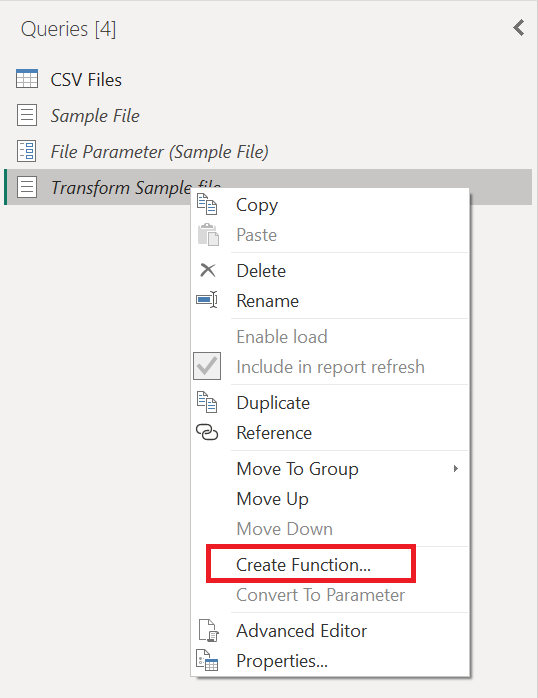
この操作により、Transform Sample ファイル クエリとリンクする新しい関数が効果的に作成されます。 変換サンプル ファイル クエリに加えた変更は、カスタム関数に自動的にレプリケートされます。 この新しい関数の作成時に、関数名として Transform ファイル を使用します。
![変換ファイルの [関数の作成] ウィンドウのスクリーンショット。](media/custom-function/transform-sample-file-function-window.png#lightbox)
関数を作成した後、関数の名前を使用して新しいグループが作成されます。 この新しいグループには、次のものが含まれます。
- 変換サンプルファイルのクエリ 内で参照されたすべてのパラメーターです。
- 変換サンプル ファイル クエリは、一般にサンプル クエリと呼ばれます。
- 新しく作成された関数 (この場合は Transform file)。

サンプル クエリへの変換の適用
新しい関数を作成したら、変換サンプル ファイル名前のクエリを選択します。 このクエリは、変換ファイル 関数にリンクされたので、このクエリに加えられた変更が関数に反映されます。 この接続は、関数にリンクされたサンプル クエリの概念と呼ばれます。
このクエリに対して行う必要がある最初の変換は、バイナリを解釈する変換です。 プレビュー ウィンドウからバイナリを右クリックし、CSV オプションを選択して、バイナリを CSV ファイルとして解釈できます。
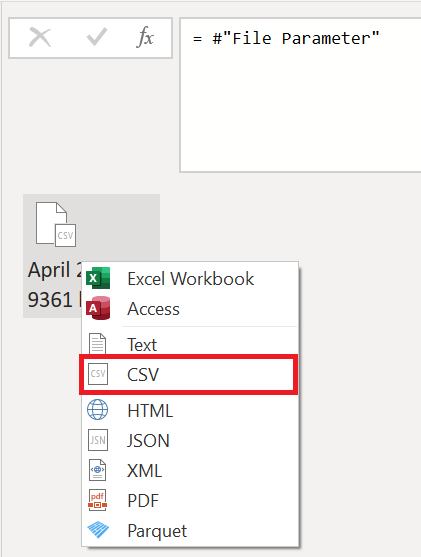
フォルダー内のすべての CSV ファイルの形式は同じです。 これらはすべて、先頭の上位 4 行にまたがるヘッダーを持っています。 次の図に示すように、列ヘッダーは行 5 にあり、データは行 6 から下方向に開始されます。

変換サンプル ファイル に適用する必要がある変換手順の次のセットは次のとおりです。
上位 4 行を削除します。このアクションは、ファイルのヘッダー セクションの一部と見なされる行を削除します。
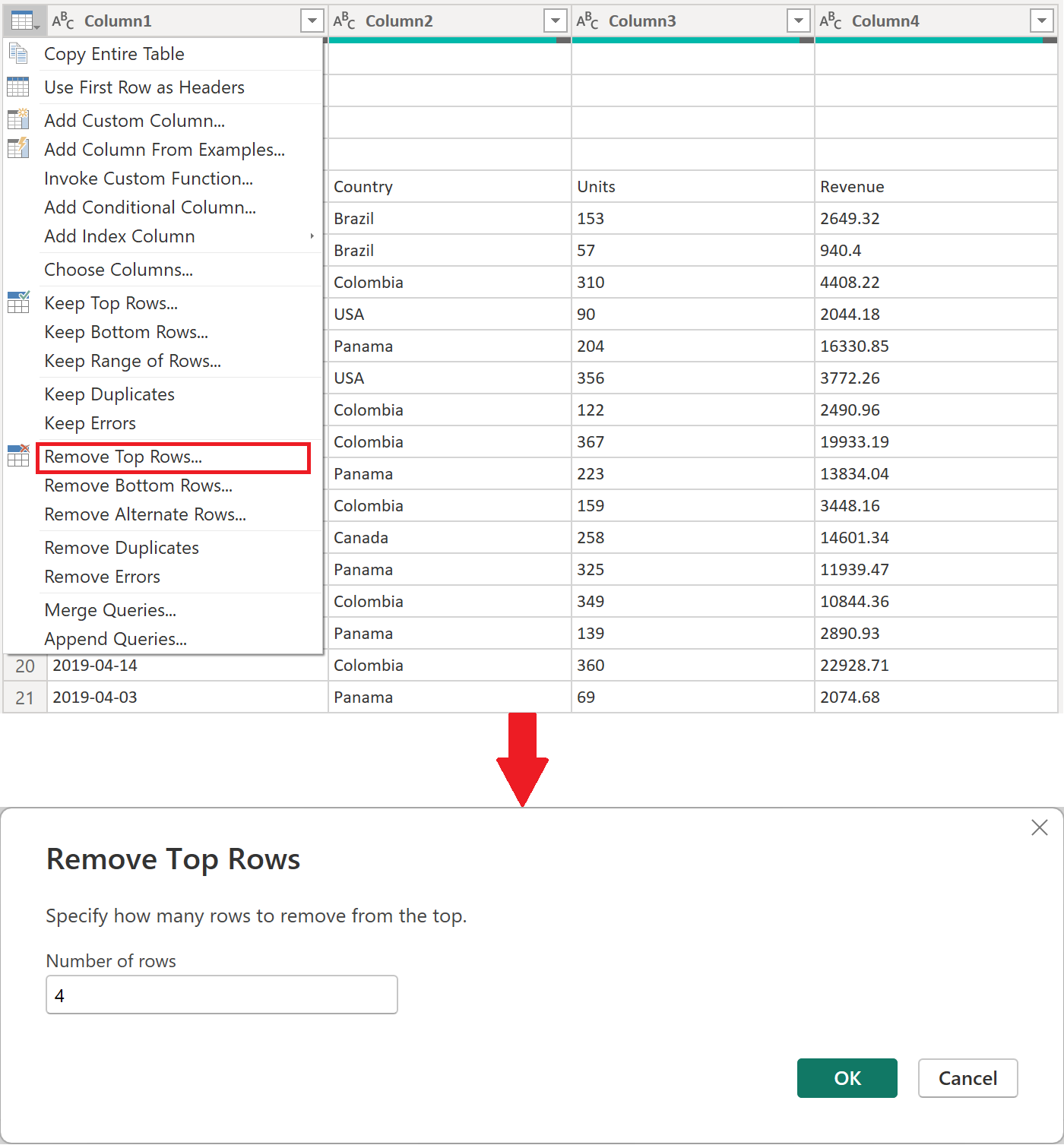
手記
行を削除する方法、または行の位置でテーブルをフィルター処理する方法の詳細については、「行の位置 でテーブルをフィルター処理する」を参照してください。
ヘッダーを最上段に昇格—作成しているテーブルのヘッダーがテーブルの最初の行に配置されました。 次の図に示すように、昇格させることができます。
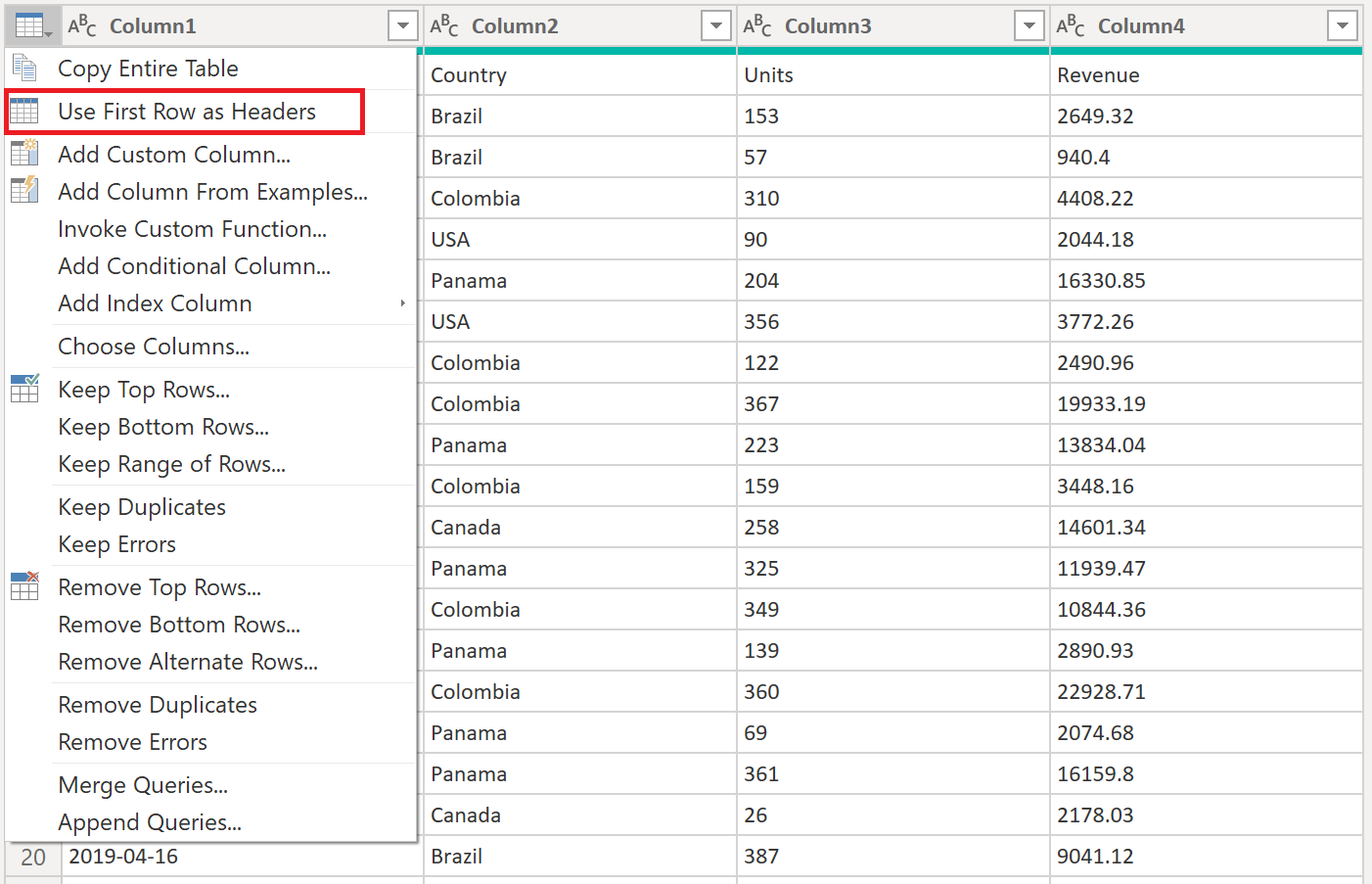


列ヘッダーを昇格した後、Power Query既定では、各列のデータ型を自動的に検出する新しい Changed Type ステップが自動的に追加されます。 あなたの変換サンプルファイルクエリは、次の画像のようになります。
手記
ヘッダーを昇格および降格させる方法の詳細については、「列ヘッダーのレベル上げ/下げ」を参照してください。

注意
変換ファイル 関数は、変換サンプル ファイル クエリで実行された手順に依存します。 ただし、Transform file 関数のコードを手動で変更しようとすると、次のような警告が表示されます: The definition of the function 'Transform file' is updated whenever query 'Transform Sample file' is updated. However, updates will stop if you directly modify function 'Transform file'.
カスタム関数を新しい列として呼び出す
カスタム関数が作成され、すべての変換手順が組み込まれたので、元のクエリに戻り、フォルダーからファイルの一覧を取得できます (この例では CSV ファイル)。 リボンの [列の追加] タブで、[全般] グループから [カスタム関数の呼び出し] を選択します。 カスタム関数 を呼び出すウィンドウで、新しい列名として 出力テーブル を入力する。 関数クエリドロップダウン リストから、関数の名前である Transform ファイルを選択します。 ドロップダウン メニューから関数を選択すると、関数のパラメーターが表示され、この関数の引数として使用するテーブルの列を選択できます。 ファイル パラメーターに渡す値/引数として、Content 列を選択します。
![[カスタム関数の呼び出し] ダイアログ セットの設定が強調された [カスタム関数の呼び出し] ボタンのスクリーンショット。](media/custom-function/custom-invoke-custom-function.png#lightbox)
[OK] を選択した後、「出力テーブル 」という名前の新しい列が作成されます。 次の図に示すように、この列のセルには [テーブル] 値が含まれています。 わかりやすくするために、名前 と 出力テーブルを除き、このテーブルからすべての列を削除します。
![カスタム関数が呼び出され、[名前] 列と [出力テーブル] 列のみが残っているスクリーンショット。](media/custom-function/custom-invoked-custom-function.png#lightbox)
手記
テーブルの列を選択または削除する方法の詳細については、「列の選択または削除」参照してください。
関数の引数として Content 列の値を使用して、テーブルのすべての行に関数が適用されました。 データが目的の図形に変換されたので、[展開] アイコンを選択して 出力テーブル 列を展開できます。 展開された列にはプレフィックスを使用しないでください。
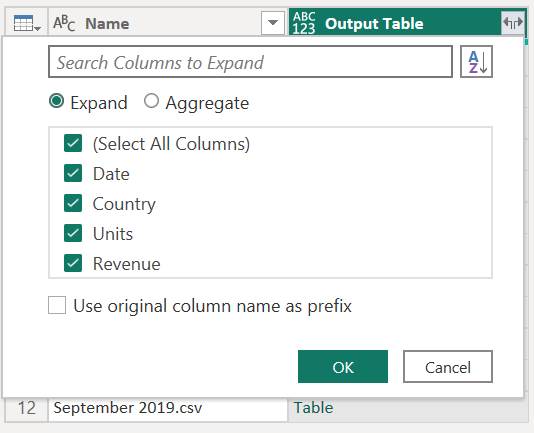
フォルダー内のすべてのファイルのデータがあることを確認するには、[名] または [日付] 列 値を確認します。 この場合、各ファイルには特定の年の 1 か月分のデータのみが含まれるため、日付 列の値を確認できます。 複数のファイルが表示される場合は、複数のファイルのデータを 1 つのテーブルに正常に結合したことを意味します。

手記
これまでに読んだことは、基本的にファイルの結合 体験中に発生するのと同じプロセスですが、手動で行っています。
また、Combine ファイルの概要と CSV ファイルの結合に関する記事を読んで、Power Queryでのファイルの結合エクスペリエンスとカスタム関数が果たす役割をさらに理解することをお勧めします。
既存のカスタム関数に新しいパラメーターを追加する
現在構築したものの上に新しい要件があるとします。 新しい要件では、ファイルを結合する前に、ファイル内のデータをフィルター処理して、Country がパナマ 等しい行のみを取得する必要があります。
この要件を満たすために、テキスト データ型で Market という新しいパラメーターを作成します。 [現在の値] に「Panama」と入力します。

新しいパラメーターを使用して、「変換サンプル ファイル」クエリ を選択し、マーケット パラメーターの値を用いて、カントリー フィールドをフィルタリングします。

手記
値で列をフィルター処理する方法の詳細については、列 の値によるフィルター処理に関するページを参照してください。
この新しいステップをクエリに適用すると、Transform file 関数が自動的に更新され、Transform Sample file で使用される 2 つのパラメーターに基づく 2 つのパラメーターが必要になります。

ただし、CSV ファイルのクエリの横には警告記号が表示されます。 関数が更新されたので、2 つのパラメーターが必要です。 そのため、関数を呼び出すステップでは、呼び出されたカスタム関数の ステップの間に関数 変換ファイル 関数に渡された引数のいずれかが 1 つだけであるため、エラー値が発生します。

エラーを修正するには、[適用された手順] で 呼び出されたカスタム関数 をダブルクリックして、[カスタム関数の呼び出し] ウィンドウを開きます。 Market パラメーターに、値 パナマを手動で入力します。

適用ステップ内の 展開された出力テーブル に戻ることができます。 クエリを確認して、Country が パナマ と等しい行のみが最終結果セットに表示されるように CSV ファイル クエリで確認してください。

再利用可能なロジックからカスタム関数を作成する
同じ変換セットを必要とする複数のクエリまたは値がある場合は、再利用可能なロジックとして機能するカスタム関数を作成できます。 後で、このカスタム関数は、選択したクエリまたは値に対して呼び出すことができます。 このカスタム関数を使用すると、時間を節約し、一元的な場所で変換のセットを管理するのに役立ちます。いつでも変更できます。
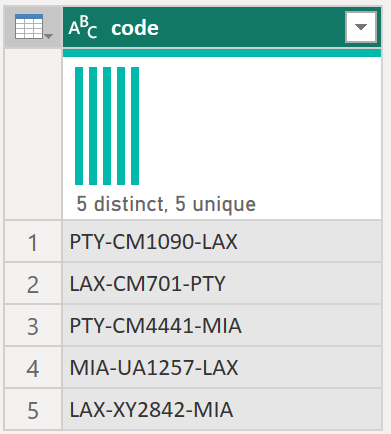
たとえば、テキスト文字列として複数のコードを含むクエリがあり、次のサンプル テーブルのように、これらの値をデコードする関数を作成するとします。
| コード |
|---|
| PTY-CM1090-LAX |
| LAX-CM701-PTY |
| PTY-CM4441-MIA |
| MIA-UA1257-LAX |
| LAX-XY2842-MIA |
最初に、例として機能する値を持つパラメーターを指定します。 この場合、値は PTY-CM1090-LAXです。
![サンプル パラメーター コード値が入力された [パラメーターの管理] ダイアログのスクリーンショット。](media/custom-function/sample-parameter-code.png#lightbox)
そのパラメーターから、必要な変換を適用する新しいクエリを作成します。 この場合、PTY-CM1090-LAX コードを複数のコンポーネントに分割します。
- Origin = PTY
- 目的地 = LAX
- 航空会社 = CM
- FlightID = 1090

次の M コードは、その一連の変換を示しています。
let
Source = code,
SplitValues = Text.Split( Source, "-"),
CreateRow = [Origin= SplitValues{0}, Destination= SplitValues{2}, Airline=Text.Start( SplitValues{1},2), FlightID= Text.End( SplitValues{1}, Text.Length( SplitValues{1} ) - 2) ],
RowToTable = Table.FromRecords( { CreateRow } ),
#"Changed Type" = Table.TransformColumnTypes(RowToTable,{{"Origin", type text}, {"Destination", type text}, {"Airline", type text}, {"FlightID", type text}})
in
#"Changed Type"
手記
Power Query M 数式言語の詳細については、「Power Query M 数式言語に関するページを参照してください。
その後、クエリを右クリックし、[関数の作成] を選択して、そのクエリを関数変換できます。 最後に、次の図に示すように、任意のクエリまたは値にカスタム関数を呼び出すことができます。

さらにいくつかの変換が行われると、目的の出力に達し、カスタム関数からこのような変換のロジックを適用したことがわかります。
