適用対象: 2016 2019 Subscription Edition SharePoint in Microsoft 365
2016 2019 Subscription Edition SharePoint in Microsoft 365
重要
Microsoft 365 の SharePoint のクラウド ハイブリッド検索の内部コンポーネントである Search Content Service (SCS) は、2025 年 6 月 30 日から廃止されます。 それまでにクラウド ハイブリッド検索を引き続き使用するには、SharePoint Server ファームを SharePoint Server サブスクリプション エディション (SPSE) バージョン 25H1 以降のバージョンにアップグレードします。 このアップグレードを行わないと、SharePoint Server 2019/2016 以前のすべてのバージョンの SPSE では、この廃止後にハイブリッド フェデレーション検索を使用してオンプレミスと Microsoft 365 のコンテンツのみを個別に検索できます。
Microsoft 365 で SharePoint の クラウド ハイブリッド検索 を設定するには、慎重な計画が必要です。 この記事では、信頼性が高く、安全でスケーラブルなクラウド ハイブリッド検索ソリューションの設計に役立つ説明を示します。
ユーザーが求める検索エクスペリエンスについて
クラウド ハイブリッド検索の設定とオンプレミス コンテンツのフル クロールが完了すると、Office 365 の検索センターは Microsoft 365 インデックスから得られるハイブリッドの結果を自動的に表示します。
その他の種類の検索をユーザーが必要としているかどうか
バーティカル検索: バーティカル検索は、たとえばビデオのみを表示するように、検索結果を特定のコンテンツのセットに絞り込みます。 現在、SharePoint Server の検索センターで垂直検索を使用している場合は、Microsoft 365 の SharePoint の検索センターで再作成する必要があります。
サイト検索 - SharePoint Server のドキュメント ライブラリ内 の既存の検索 では、検索インデックスを Microsoft 365 に移動すると結果が返されなくなります。 検索は、ユーザーが検索インデックスと同じ環境にある検索センターを使用する場合に最も高速であるため、Microsoft 365 検索センターから検索するとエクスペリエンスが向上します。 SharePoint Server 2010 の既存のチーム サイトなど、オンプレミスの SharePoint サイトの Microsoft 365 検索インデックスの結果がユーザーに必要な場合は、SharePoint Server 2013 または SharePoint Server 2016 から検索を設定できます。 Microsoft 365 検索インデックスから結果を取得し、クエリフェデレーションの使用を計画する SharePoint Server 2013 または SharePoint Server 2016 でリモートの結果ソースを計画します。 Microsoft 365 の SharePoint はクエリを処理するため、ユーザーは Microsoft 365 の SharePoint でサポートされているクエリ構文を使用する必要があります。 詳細については、「 クラウド ハイブリッド検索を使用してオンプレミスの SharePoint で Microsoft 365 の結果を表示する」を参照してください。
電子情報開示: 電子情報開示は、SharePoint Server と Microsoft 365 の SharePoint で個別の設定が必要になることがあります。
クロスサイト発行: クロスサイト発行は、クラウド ハイブリッド検索では使用できません。
検索結果の表示方法について
プレビュー - ユーザーが Microsoft 365 の検索結果にカーソルを合わせると、コンテンツに関する情報とコンテンツのプレビューが表示されます。 オンプレミスから得られた検索結果のコンテンツに関する情報は自動的に表示されますが、このコンテンツのプレビューを表示するには設定が必要になります。 Office Web Apps Server ファームを計画し、Office Web Apps Server を使用するように SharePoint Server 2013 を構成します。 「 クラウド ハイブリッド検索を使用してオンプレミスの SharePoint で Microsoft 365 の結果を表示する」の方法について説明します。
カスタムのセキュリティ トリミング: Microsoft 365 の SharePoint ではカスタムのセキュリティ トリミングがサポートされません。
必要な検索機能について
SharePoint Server で使い慣れている検索機能の一部は、クラウド ハイブリッド検索とは異なる方法で動作します。 この相違点について、ユーザーに通知することを計画します。
おすすめコンテンツ: おすすめコンテンツは SharePoint Server 2010 の機能です。 代わりに、Microsoft 365 の SharePoint でクエリ ルールを使用します。
カスタムの検索範囲: カスタムの検索範囲は SharePoint Server 2010 の機能です。 代わりに、Microsoft 365 の SharePoint で結果ソースを使用します。
検索結果の昇格/降格: 検索結果の昇格/降格は SharePoint Server 2010 の機能です。 代わりに、Microsoft 365 の SharePoint で結果ソースを使用します。
オンプレミス検索結果の削除 - SharePoint Server のサーバーの全体管理では、Search Service アプリケーションを選択し、[インデックスのリセット] オプションを使用して検索インデックスからすべての項目を削除できます。 クラウド Search Service アプリケーションにはこのオプションを使用しないでください。このオプションはクロール データベースからクロール履歴を削除しますが、SharePoint Server のクラウド Search Service アプリケーションとOffice 365の検索インデックスとの間に直接通信がないため、Microsoft 365 インデックスからオンプレミスのアイテムは削除されません。 これらのオンプレミスアイテムは、Microsoft 365 インデックスで孤立します。 Microsoft 365 検索インデックスからオンプレミスのすべてのメタデータを削除する場合は、すべてのオンプレミス コンテンツ ソースを削除します。 プロセスが完了した後に Microsoft 365 検索インデックスに残っているオンプレミスのアイテムは、孤立したアイテムです。
SharePoint Server で使い慣れている可能性のある検索機能の一部は、クラウド ハイブリッド検索では使用できません。 ユーザーに通知することを計画してください。
SharePoint Server 2013 または SharePoint Server 2016 ファーム上のマルチテナント - SharePoint Server 2013 または SharePoint Server 2016 ファームは、Microsoft 365 の SharePoint 内の 1 つのテナントにのみアタッチできるため、SharePoint はマルチテナント SharePoint Server 2013 または SharePoint Server 2016 ファームのテナント分離を保持できません。
カスタムのエンティティ抽出: カスタムのエンティティ抽出は、Microsoft 365 の SharePoint でサポートされていないため、クラウド ハイブリッド検索では利用できません。
コンテンツ エンリッチメント Web サービス: コンテンツ エンリッチメント Web サービスの呼び出しは、カスタムのエンティティ抽出が Microsoft 365 の SharePoint でサポートされていないため、クラウド ハイブリッド検索では使用できません。
シソーラス: シソーラスは、Microsoft 365 の SharePoint でサポートされていないため、クラウド ハイブリッド検索では使用できません。
SharePoint Server でクラウド ハイブリッド検索の検索アーキテクチャを計画する
クラウド ハイブリッド検索を設定する手順の 1 つは、SharePoint Server 2013 または SharePoint Server 2016 検索ファームにクラウド Search Service アプリケーション (クラウド SSA) を作成することです。 このクラウド SSA の作成時に、既定の検索アーキテクチャがクラウド SSA を実行するサーバーに作成されます。 各検索ファームが持てるクラウド SSA は 1 つのみですが、クラウド SSA と組み合わせれば複数の SSA を持つことができます。
クラウド ハイブリッド検索の検索アーキテクチャは、トポロジを形成する検索コンポーネントとデータベース、およびトポロジをホストするサーバーで構成されます。 目的のトポロジに応じたクロール コンポーネントの数、検索コンポーネントとデータベースをホストするサーバー、および各サーバーに要求されるハードウェアを計画する必要があります。
作業の開始前に、「クラウド ハイブリッド検索の検索トポロジについて」を確認して、クラウド ハイブリッド検索の検索アーキテクチャに含まれる検索コンポーネントについて理解しておいてください。
手順 1: Microsoft 365 にインデックスを作成できるオンプレミス コンテンツの量について
Microsoft 365 の SharePoint でテナントが持つプールされたストレージ領域の 1 TB ごとに、Office 365の検索インデックスに 100 万個のオンプレミス コンテンツのインデックスを作成できます。 クォータを増やすために、2,000 万アイテムのしきい値に達するまで、さらに多くの領域を購入できます。 2,000 万を超えるオンプレミス コンテンツのインデックスを作成する必要がある場合は、このしきい値を増やすMicrosoft サポートにお問い合わせください。
手順 2: クラウド検索アーキテクチャに必要になるサイズについて
クラウド ハイブリッド検索の場合は、クラウド SSA の作成時に得られる既定の検索アーキテクチャの使用をお勧めします。
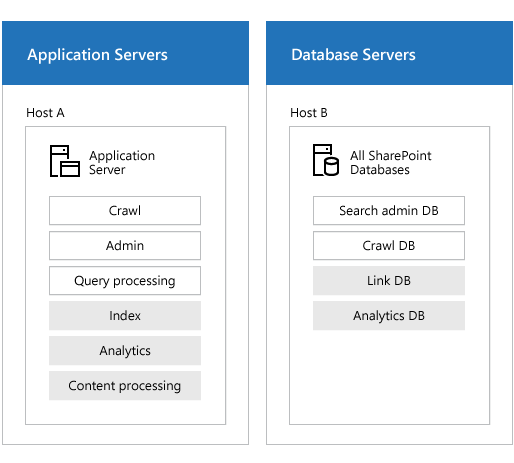
灰色のコンポーネントはクラウド ハイブリッド検索では非アクティブになりますが、示されているとおりにサーバーに配置されている必要があります。 非アクティブなコンポーネントについては、「クラウド ハイブリッド検索の検索トポロジについて」を参照してください。
オンプレミス専用のエンタープライズ検索と同様に、検索アーキテクチャは拡大縮小できます。 メイン違いは、クラウド ハイブリッド検索の場合、クロール コンポーネントのスケーリングにのみ関連する点です。 クロールの調整が必要な場合は、「Redesign enterprise search topology for specific performance requirements in SharePoint 2016」のクロールに関するガイダンスに従ってください (クロールのガイダンスは、クラウド ハイブリッド検索にも当てはまります)。 オンプレミスのコンテンツを高いレートでクロールすると、システムが Microsoft 365 検索インデックスへのフィードを調整して Microsoft 365 organizationを保護する可能性があることに注意してください。 検索アーキテクチャに最大 2 つのクロール コンポーネントがある場合は、十分に容認できるクロール レートが得られます。
手順 3: クラウド検索アーキテクチャに関して注意が必要なハードウェア要件について
クラウド ハイブリッド検索用のサーバーを物理的に実行するか仮想的に実行するかを選択する
仮想マシンを使用する検索アーキテクチャが推奨されますが、物理マシンを使用することもできます。 詳細については、「サーバーを物理的に実行するか仮想的に実行するかを選択する」を参照してください。
クラウド ハイブリッド検索用のホスト サーバーのハードウェア リソースを選択する
この表には、それぞれのアプリケーション サーバーまたはデータベース サーバーに必要なハードウェア リソースの最小量を示します。
| サーバー | 稼働するホスト | ストレージ | RAM | プロセッサ1 |
|---|---|---|---|---|
| アプリケーション サーバー |
A |
100 GB |
16 GB |
1.8 GHz 4x CPU コア |
| データベース サーバー |
B |
100 GB |
16 GB |
1.8 GHz 4x CPU コア |
1 ここで指定しているのは、CPU スレッドの数ではなく、CPU コアの数です。
追加事項は次のとおりです。
各ホスト サーバーに、Windows Server オペレーティング システムの基本インストールと SharePoint Server プログラム ファイル用の十分なディスク領域があることを確認します。 また、ホスト サーバーでは、ログ記録、デバッグ、メモリ ダンプの作成などの診断用、日々の操作用、およびページ ファイル用の空きハードディスク領域も必要です。 通常、Windows Server オペレーティング システムと SharePoint Server プログラム ファイルには、80 GB のディスク領域で十分です。
データベース サーバーごとに SQL ログ スペース用のストレージを追加します。 データベースを頻繁にバックアップするようにデーベース サーバーを設定していない場合は、SQL ログ スペースに大量のストレージが使用されます。 SQL データベースを計画する方法の詳細については、「ストレージおよび SQL Server の容量計画と構成 (SharePoint Server)」を参照してください。
クラウド ハイブリッド検索のストレージ パフォーマンスを計画する
検索コンポーネントおよびストレージのオペレーティング システムからデータをどのように分散するかによって、検索パフォーマンスに影響が出ます。 以下のようにすることをお勧めします。
Windows Server オペレーティング システム ファイル、SharePoint Server プログラム ファイル、および診断ログは、通常のパフォーマンスの 3 つの別個のストレージ ボリュームまたはパーティションに分割します。
検索コンポーネントのデータは、高パフォーマンスの別個のストレージ ボリュームまたはパーティションに保存します。
ヒント
SharePoint Server をホストにインストールするときに、検索コンポーネント データのカスタムの場所を設定できます。 ホスト上の検索コンポーネントは、データを保存する必要がある場合、この場所に保存します。 この場所を後で変更するには、そのホストに SharePoint Server を再インストールする必要があります。
所有しているストレージが、検索コンポーネントおよびデータベースからのトラフィックを十分に処理できる高速なものであることを確認します。 クロール データベースは、クラウド ハイブリッド検索の検索アーキテクチャで IOPS 要件がある唯一のコンポーネントです。 クロール データベースには中程度から高程度の IOPS が必要になり、I/O にかかる通常の負荷は 1 DPS (1 秒あたりのドキュメント) クロール レートあたり 10 IOPS になります。
クラウド ハイブリッド検索の検索トポロジについて
クラウド SSA の検索トポロジは、SharePoint Server 2013 または SharePoint Server 2016 の標準 SSA の検索トポロジと同じ種類の検索コンポーネントとデータベースで構成されます。 ただし、いくつかの相違点があります。
クラウド ハイブリッド検索の未使用の検索コンポーネントとデータベース - クラウド ハイブリッド検索では、コンテンツを処理し、インデックスを格納し、分析を処理するのは Microsoft 365 です。 クラウド SSA は、独自のコンテンツ処理コンポーネント、インデックス コンポーネント、分析処理コンポーネント、リンク データベース、または分析データベースを使用しません。 これらのコンポーネントとデータベースはアイドル状態になります。
クラウド ハイブリッド検索の検索コンポーネントとデータベースの間の対話処理: 標準 SSA の検索トポロジと比較すると、クラウド SSA の検索トポロジには、検索コンポーネントとデータベースの対話処理に次に示す違いがあります。
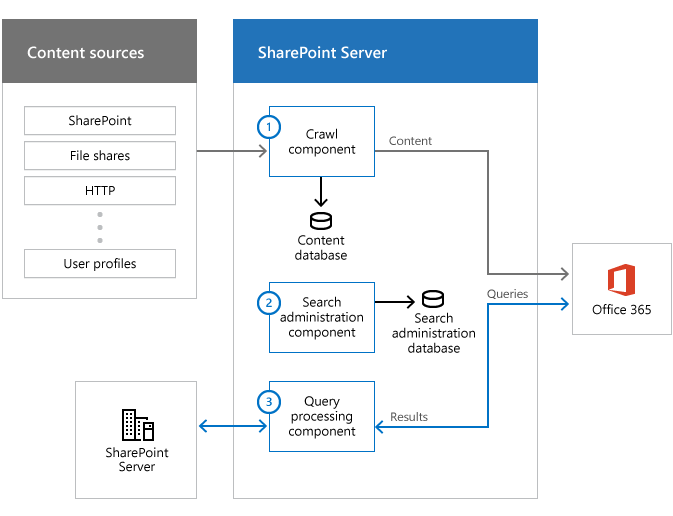
クロール コンポーネントは、オンプレミスのファームからコンテンツを取得して、そのコンテンツを Office 365 の検索インデックスに送信します。 コネクタを使用してコンテンツ ソースと対話し、クロール データベースを使用して、クロールするアイテムに関する一時的な情報と履歴情報の両方を、通常のクロール コンポーネントと同様に格納します。
検索管理コンポーネントは、標準 SSA の場合と同様に、検索に不可欠なシステム プロセスを実行します。
クラウド ハイブリッド検索はこのために最適化されているため、Microsoft 365 からのすべての検索を実行することをお勧めします。 ただし、SharePoint Server でサイト検索を設定して、Office 365の検索インデックスから検索結果を取得できます。 Microsoft 365 インデックスのクエリを実行するようにオンプレミスのサイト コレクションで検索を設定した場合、このクエリ処理コンポーネントは、検索ボックスから Microsoft 365 インデックスにクエリを渡し、結果を Microsoft 365 インデックスから検索ボックスに渡します。
オンプレミス コンテンツのクロールの管理方法を決定する
コンテンツ ソースの効果的な使用、クロールのスケジュール設定、クロール ルールなど、クロールの管理方法によってクロールのパフォーマンスと検索の鮮度に影響を与えることができます。 オンプレミス検索のみのクロールを管理するためのガイダンスは、クラウド ハイブリッド検索にも適用されます。 「SharePoint Server でのクロールのベスト プラクティス」を参照してください。
Active Directory の同期方法を決定する
オンプレミス コンテンツがクロール、解析および暗号化されるときに、アイテムごとのアクセス制御リスト (ACL) もクロールされます。 Microsoft 365 検索インデックスは、ACL とアイテムを一緒に格納するため、システムはオンプレミス ユーザーを Microsoft 365 の同じユーザーとして認識できる必要があります。 オンプレミス ネットワーク (Windows Server Active Directory) と Microsoft 365 organization (Microsoft Entra ID) の間で Active Directory 同期を設定すると、システムは ACL をマップして適切なユーザーに変換し、ユーザーは Microsoft 365 インデックスからセキュリティトリミングされた検索結果を取得します。
Active Directory の同期方式は 2 つあります。
ディレクトリ同期とパスワード同期
ディレクトリ同期とシングル サインオン (SSO)
SSO の構成を選択する場合は、SSO のバックアップとしてパスワード同期も構成することができます。ただし、この 2 つ (パスワード同期または SSO) のうちどちらか一方は必ず構成する必要があります。 詳細と、 Microsoft 365 とオンプレミス環境の統合で 2 つの方法を構成する方法について説明します。
ユーザーが Domain Users セキュリティ グループのメンバーになっているとクラウド ハイブリッド検索でハイブリッドの結果を取得できない理由
一部の組織は、Windows Server Active Directory (AD) の既定のセキュリティ グループの 1 つ (たとえば、Domain Users セキュリティ グループ) を使用して、オンプレミス コンテンツへのアクセス権を割り当てます。
Microsoft Entra Connect 同期ツールは、既定で一部のオブジェクトを同期から除外します。 属性 IsCriticalSecurityObject が true のセキュリティ グループは、このツールで除外される 1 つのオブジェクトのセットであり、これに該当するセキュリティ グループの一例として Domain Users が挙げられます。 そのため、ドメイン ユーザーのメンバーのアクセス権は、Microsoft Entra IDでは使用できません。 ユーザーがオンプレミスコンテンツにアクセスできる場合でも、そのコンテンツを検索しても検索結果は取得されません。
代わりに、IsCriticalSecurityObject=true を持たないグループ (Everyone グループ、Authenticated Users グループ、カスタム グループなど) を使用して、アクセス権を割り当てます。 オブジェクトを除外する条件の一覧と、予期しない同期結果の詳細については、「 Azure Active Directory 同期ツールを使用するときに 1 つ以上のオブジェクトが同期されない」を参照してください。
組織に機密性の高いオンプレミス コンテンツがあるかどうか
一部の組織には、規制、法律、または地政学的制約のために機密性が高いと見なされるオンプレミスコンテンツがあります。 場合によっては、機密性の高いオンプレミス コンテンツのメタデータを Microsoft 365 検索インデックスに追加することは禁止されています。 その他のケースでは、機密性の高いオンプレミス コンテンツのメタデータを Microsoft 365 検索インデックスに追加できますが、機密コンテンツから検索結果を開くことができるユーザーの数は限られています。
ここでは、このような制約に適合するようにハイブリッド検索をセットアップする 2 つの方法の例を示します。
機密性の高いオンプレミス コンテンツから得られるメタデータが Microsoft 365 インデックスに含まれることを許容する場合
クラウド ハイブリッド検索を設定し、機密性の高いコンテンツへのアクセス権を慎重に計画して、適切なユーザーのみが検索結果を選択するときに機密性の高いコンテンツにアクセスできるようにします。
機密性の高いオンプレミス コンテンツから得られるメタデータが Microsoft 365 インデックスに含まれることを許容しない場合
ハイブリッド フェデレーション検索と組み合わせてクラウド ハイブリッド検索を設定します。
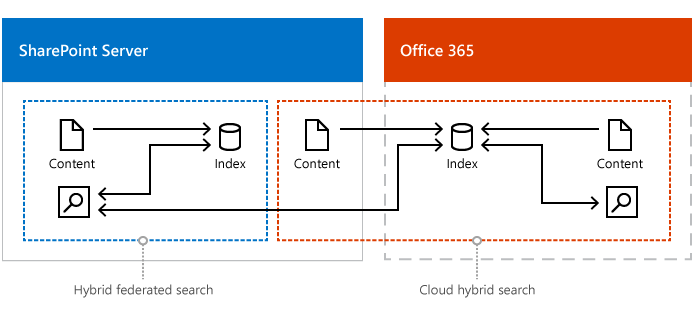
機密コンテンツを除くすべてのオンプレミス コンテンツをカバーする SharePoint Server のクラウド Search Service アプリケーション (クラウド SSA) のコンテンツ ソースを計画します。 クロールされるコンテンツのメタデータは、Office 365 の検索インデックスに追加されます。
SharePoint Server でエンタープライズ検索を計画して、機密性の高いオンプレミス コンテンツをクロールする方法については、「 SharePoint Server での検索の計画」を参照してください。 機密コンテンツをカバーする SSA のコンテンツ ソースを計画します。 クロールされた機密性の高いコンテンツのメタデータが SharePoint Server の検索インデックスに追加されます。
ユーザーがオンプレミスの SharePoint サイトの Microsoft 365 検索インデックスからの結果を必要としている場合は、SharePoint Server の検索インデックスと Office 365 の検索インデックスから得られる検索結果を表示する SharePoint Server からのハイブリッド フェデレーション検索を計画します。詳細については「SharePoint Server のハイブリッド フェデレーション検索を計画する」を参照してください。
ユーザーに公開する前にクラウド ハイブリッド検索の検証を計画する
クラウド SSA を作成して設定し、フル クロールを完了すると、Microsoft 365 Search Center にオンプレミスとオンラインの両方の検索結果が表示されます。 新しい検索エクスペリエンスの検証と調整は、元の検索エクスペリエンスを変更しないようにして、別の検索センターで実行することをお勧めします。
Office 365の検索センターに Microsoft 365 コンテンツのみを表示するように制限するカスタム結果ソースを計画します。 次に、ハイブリッド検索結果の表示方法を検証および調整できる環境を示します。
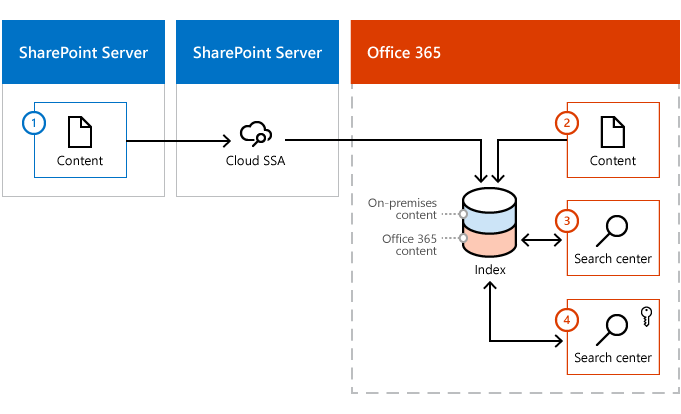
オンプレミス コンテンツ。 クロール中に、このコンテンツのメタデータが Microsoft 365 検索インデックスに追加されます。
Microsoft 365 コンテンツ。 クロール中に、このコンテンツのメタデータが Microsoft 365 検索インデックスに追加されます。
既定 (または既存の) Microsoft 365 Search Center。 この検索センターのカスタム結果ソースを作成すると、検索結果が Microsoft 365 コンテンツのみを表示するように制限されます。
新しい Microsoft 365 検索センター。ここでは、ハイブリッド検索結果の表示方法を検証して調整します。 この検索センターでは、既定の結果ソースが使用され、オンプレミスと Microsoft 365 の両方のコンテンツからの検索結果が表示されます。 このサイトには、テスト担当者と管理者のみがアクセスできるようにアクセス権を設定します。
注:
チューニング中は元の検索エクスペリエンスを変更せずにおくことができますが、元の Office Delve エクスペリエンスを変更せずに保持することはできません。 オンプレミス コンテンツから得られたメタデータが Office 365 検索インデックスに存在する場合、このコンテンツが Delve に表示されます。