予期しない事態に備える方法 (インシデント発生前)
- 19 分
準備を確保し、インシデントの影響を最小限に抑えるには、このユニットで説明されているプロアクティブな推奨事項に従う必要があります。 これらのアクションは、インシデント通信プロセスを理解し、関連する情報を特定し、タイムリーな更新を受信するように通知を構成するのに役立ちます。 アプリケーションの回復性を評価し、推奨される対策を実装すると、より信頼性の高いワークロードが作成され、インシデントの潜在的な影響が軽減されます。 セキュリティのベスト プラクティスを確認して実装すると、環境が強化され、リスクが軽減されます。
常に最新の情報を入手し、影響を軽減し、投資を保護するには、次の 5 つのアクションをお勧めします。
アクション #1: Azure portal の Azure Service Health について十分に理解する
パブリック azure.status.microsoft ページには、 広範な停止についてのみ、一般的な状態情報が表示されます。
Azure Service Health では、特定のリソースに合わせてカスタマイズされた詳細が提供されます。 これは、計画メンテナンスや、リソースの可用性に影響を与える可能性のあるその他の変更を予測して準備するのに役立ちます。 サービス イベントに対処し、影響を受けるアプリケーションのビジネス継続性を維持するためのアクションを管理できます。 プラットフォームの脆弱性、セキュリティ インシデント、プライバシー侵害に関する重要な分析情報を Azure サービス レベルで提供します。これにより、Azure ワークロードを保護するための迅速なアクションが可能になります。
インシデントの準備を強化するために Azure Service Health で使用できる主な機能を次に示します。
[リソース正常性] ペイン (新しく表示されるようになったエクスペリエンス)
Azure Portal の [Service Health] ページにある Azure Resource Health は、Azure リソースに影響を与えるサービスの問題の診断と解決に役立ちます。 仮想マシン、Web アプリ、SQL データベースなどのリソースについて、さまざまな Azure サービスからのシグナルに基づいて正常性が評価されます。 リソースが異常と識別された場合、Resource Health は詳細な分析を実行して問題の原因を特定します。 また、インシデントに関連する問題を解決するための Microsoft のアクションに関する情報も提供され、問題に対処するために実行できる手順が提案されます。
[サービスに関する問題] ペイン (新しく表示されるようになったエクスペリエンス)
[サービスの問題] ウィンドウには、リソースに影響する可能性がある継続的なサービス インシデントが表示されます。 これにより、問題がいつ始まったかを追跡し、影響を受けるサービスとリージョンを特定できます。 最新の更新プログラムを確認して、インシデントを解決するための Azure の取り組みに関する分析情報を取得します。

[サービスの問題] ウィンドウの主な機能:
Real-Time 分析情報: サービスの問題ダッシュボードでは、サブスクリプションとテナントに影響を与える Azure サービス インシデントをリアルタイムで可視化できます。 テナント管理者の場合は、サブスクリプションとテナントに関連するアクティブなインシデントまたはアドバイザリを確認できます。
リソース影響評価: インシデントの詳細セクションの [影響を受けるリソース] タブには、確認済みまたは影響を受ける可能性のあるリソースが表示されます。 [リソースヘルス] ペインに直接アクセスするリソースを選択します。
リンクとダウンロード可能な説明: 問題管理システムで使用するために、問題へのリンクを取得できます。 PDF または CSV ファイルをダウンロードして、Azure portal にアクセスできない関係者と包括的な説明を共有します。 リソースに影響を与えた問題 (以前は根本原因分析 (RCA) と呼ばれる) については、インシデント レビュー後 (PIR) を要求できます。
[セキュリティ アドバイザリ] ウィンドウ
[セキュリティ アドバイザリ] ウィンドウでは、サブスクリプションとテナントの正常性に影響を与える緊急のセキュリティ関連の情報に重点を置いています。 プラットフォームの脆弱性、セキュリティ インシデント、プライバシー侵害に関する分析情報が提供されます。
[セキュリティ アドバイザリ] ウィンドウの主な機能:
リアルタイムのセキュリティ分析情報: サブスクリプションとテナントに関連する Azure セキュリティ インシデントを即座に可視化します。
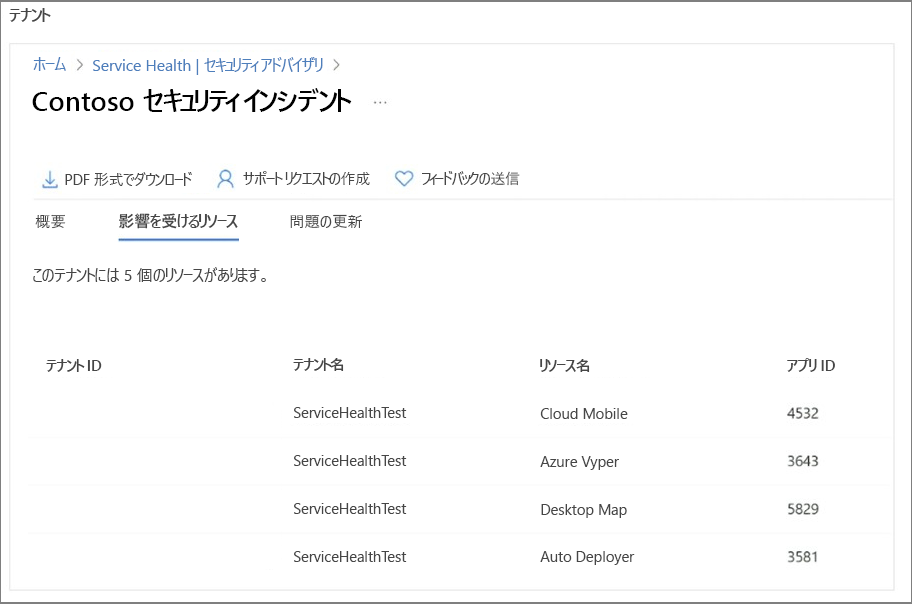
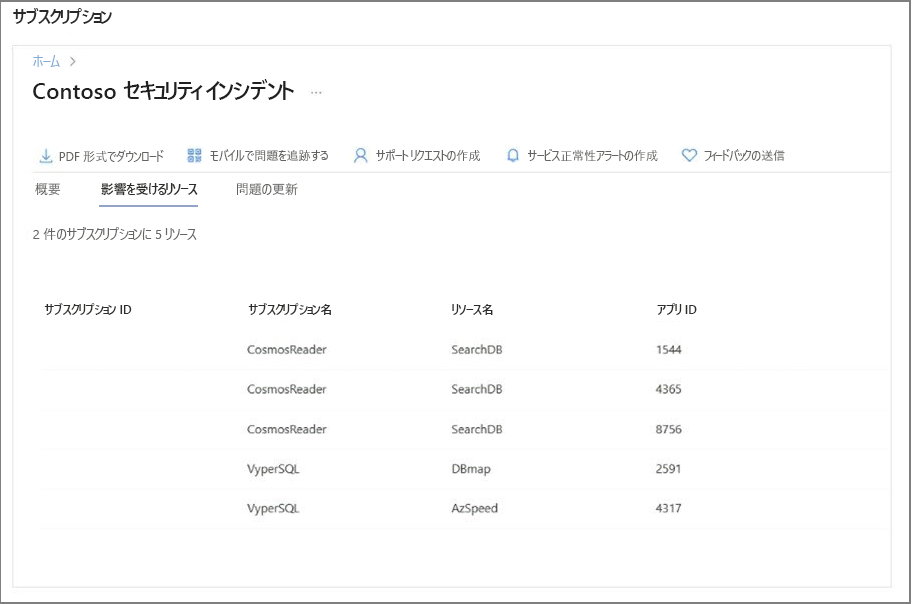
リソース影響評価: インシデントの詳細セクションの [影響を受けるリソース] タブには、インシデントが影響を受けたことが Azure によって確認されたリソースが強調表示されます。
以下のロールを認められたユーザーは、セキュリティの影響を受けたリソースの情報を確認できます。
サブスクリプション レベルのリソースの表示 テナント レベルのリソースの表示 サブスクリプションの所有者 セキュリティ管理者/セキュリティ閲覧者 サブスクリプション管理 グローバル管理者/テナント管理者 Service Health セキュリティ閲覧者 Azure Service Health プライバシー閲覧者 説明 PDF ドキュメントをダウンロードして、Azure portal に直接アクセスできない関係者と共有できます。
次の例は、サブスクリプションとテナントの両方のスコープから、影響を受けるリソースがあるセキュリティ インシデントを示しています。
Azure Service Health について理解することに加えて、Service Health アラートを設定することがもう 1 つの重要な手順です。 これらのアラートにより、タイムリーな通知が確実に行われます。 彼らは、ワークロードに影響を及ぼす可能性があるインシデントや重要な情報について、常に情報を提供します。 次のセクションでは、この問題について詳しく説明します。
アクション #2: Service Health アラートを設定して最新情報を常に入手する
サービス正常性アラート通知の構成は、事前対応型のインシデント管理に不可欠です。 これは最も重要な行動喚起です。 Service Health アラートを使用すると、電子メール、SMS、Webhook などのさまざまなチャネルを通じてタイムリーな通知を受信できます。 これらのアラートは、サービス インシデント、計画メンテナンス アクティビティ、セキュリティ インシデント、およびワークロードに影響を与える可能性があるその他の重要な情報に関する更新を提供します。
サービス正常性アラートは、Azure portal の [サービス正常性] ページの [アクティブなイベント] ウィンドウから構成したり、[サービス正常性] ウィンドウから正常性アラートを選択したり、Azure Resource Graph を使用して構成したりできます。
Azure Service Health 用の Azure Resource Graph サンプル クエリについては、こちらを参照してください。
Service Health は、リソースに影響する可能性があるさまざまな種類の正常性イベントを追跡します。 これらのイベントには、サービスの問題、計画メンテナンス、健康に関する勧告、およびセキュリティに関する勧告が含まれます。 サービス正常性アラートを構成する場合、これらのアラートを送信する方法と送信先を柔軟に選択できます。 サービス正常性通知のクラスと、影響を受けるサブスクリプション、サービス、リージョンに基づいてアラートをカスタマイズできます。
サービス正常性通知のクラス
| サービス正常性イベントの種類 | 説明 |
|---|---|
| サービスに関する問題 | 今すぐ影響を与える Azure サービスの問題。サービス インシデントとも呼ばれます。 |
| 定期的なメンテナンス | 将来のサービスの可用性に影響を与える可能性がある今後のメンテナンス。 |
| 正常性の勧告 | 注意を要する Azure サービスの変更。 たとえば、アクションを実行する必要がある場合、Azure の機能が非推奨になった場合、要件をアップグレードする場合、使用クォータを超えた場合などがあります。 |
| セキュリティ アドバイザリ | プラットフォームの脆弱性と、サブスクリプションとテナント レベルでのセキュリティとプライバシーの侵害 (セキュリティまたはプライバシー インシデントとも呼ばれます) に関するセキュリティ関連の通知。 |
サービスに影響する問題がある場合は、通知を受ける必要があることを認識しています。 サービス正常性アラートを使用すると、これらのアラートを送信する 方法 と 送信先を 選択できます。 アラートは、サービス正常性通知のクラス、影響を受けるサブスクリプション、影響を受けるサービス、影響を受けるリージョンに基づいて構成できます。 アラートを設定して、電子メール、SMS メッセージ、ロジック アプリ、関数などをトリガーできます。
アラートがトリガーされたら、アクション グループを使用して実行するアクションを定義できます。 アクション グループは、アラートの送信方法と送信先を決定する通知設定のコレクションです。
使用可能な通知の種類の完全な一覧
| 通知のタイプ | 説明 | フィールド |
|---|---|---|
| 電子メールの Azure Resource Manager のロール | それぞれのロールに基づいて、サブスクリプション メンバーに電子メールを送信します。 通知メールは、Microsoft Entra ユーザー用に構成されたプライマリ メール アドレスにのみ送信されます。 メールは、選択されたロールの Microsoft Entra ユーザー メンバーにのみ送信され、Microsoft Entra グループやサービス プリンシパルには送信されません。 |
Microsoft Entra ユーザー用に構成されたプライマリ メール アドレスを入力します。 「電子メール」を参照してください。 |
| 電子メール | メール フィルター処理と、マルウェアおよびスパム防止サービスが適切に構成されていることを確認します。 電子メールは、次の電子メール アドレスから送信されます。 - azure-noreply@microsoft.com - azureemail-noreply@microsoft.com - alerts-noreply@mail.windowsazure.com |
通知を送信するメール アドレスを入力します。 |
| sms | SMS 通知では双方向通信がサポートされます。 SMS には、次の情報が含まれています。 - このアラートの送信先となったアクション グループの短い名前 - アラートのタイトル。 ユーザーは、次のことを行うために SMS に応答できます。 すべてのアクション グループまたは単一のアクション グループのすべての SMS アラートの登録解除。 - アラートへの再登録 - サポートの要求。 サポートされている SMS の返信の詳細については、「SMS の返信」を参照してください。 |
SMS 受信者の国番号と電話番号を入力します。 Azure portal で国/地域コードを選択できない場合、SMS は国/地域ではサポートされていません。 国/地域コードが利用できない場合は、アイデアを共有するで国/地域を追加するために投票できます。 国/地域がサポートされるまでの回避策として、お客様の国/地域をサポートするパートナー SMS プロバイダーに Webhook を呼び出すようにアクション グループを構成します。 |
| Azure アプリのプッシュ通知 | Azure mobile app に通知を送信します。 Azure mobile app へのプッシュ通知を有効にするための詳細については、Azure mobile app に関するページを参照してください。 | [Azure アカウントの電子メール] フィールドに、Azure mobile app を構成するときにアカウント ID として使用するメール アドレスを入力します。 |
| 音声 | 音声通知です。 | 通知の受信者の国番号と電話番号を入力します。 Azure portal で国/地域コードを選択できない場合、音声通知はご利用の国/地域ではサポートされていません。 国/地域コードが利用できない場合は、アイデアを共有するで国/地域を追加するために投票できます。 国/地域がサポートされるまでの回避策として、国/地域をサポートするパートナー音声通話プロバイダーに Webhook を呼び出すようにアクション グループを構成します。 |
トリガーできるアクションの完全な一覧
| アクションの種類 | 詳細 |
|---|---|
| 自動化手順書 | Automation Runbook ペイロードの制限の詳細については、「Automation の制限」を参照してください。 |
| Event Hubs | Event Hubs アクションは、通知を Event Hubs に発行します。 Event Hubs の詳細については、「Azure Event Hubs - ビッグ データ ストリーミング プラットフォームとイベント インジェスト サービス」を参照してください。 イベント受信者からアラート通知ストリームをサブスクライブできます。 |
| 関数 | 関数で既存の HTTP トリガー エンドポイントを呼び出します。 詳細については、Azure Functions に関するページを参照してください。 関数アクションを定義すると、関数の HTTP トリガーエンドポイントとアクセスキーがアクション定義に保存されます (https://azfunctionurl.azurewebsites.net/api/httptrigger?code=<access_key> など)。 関数のアクセス キーを変更する場合は、アクション グループで関数アクションを削除して再作成する必要があります。エンドポイントで HTTP POST メソッドがサポートされている必要があります。 関数は、ストレージ アカウントへのアクセス権を持っている必要があります。 アクセス権がない場合、キーを使用できず、関数の URI にアクセスできません。 ストレージ アカウントへのアクセスの復元についてはこちらを参照してください。 |
| IT サービスマネジメント (ITSM) | ITSM アクションには ITSM 接続が必要です。 ITSM 接続の作成方法については、「 ITSM 統合」 を参照してください。 |
| ロジック アプリ | Azure Logic Apps を使用して、統合用のワークフローを構築およびカスタマイズしたり、アラート通知をカスタマイズしたりできます。 |
| セキュリティで保護された Webhook | セキュリティで保護された Webhook アクションを使用する場合、Microsoft Entra ID を使用して、アクション グループとエンドポイント (保護された Web API) 間の接続をセキュリティで保護する必要があります。 セキュリティで保護された Webhook の認証の構成に関するセクションを参照してください。 セキュリティで保護された Webhook では、基本認証はサポートされていません。 基本認証を使用している場合は、Webhook アクションを使用します。 |
| ウェブフック | Webhook アクションを使用する場合、ターゲット Webhook エンドポイントは、さまざまなアラート ソースが出力する、さまざまな JSON ペイロードを処理できる必要があります。 Webhook アクションを介してセキュリティ証明書を渡すことはできません。 基本認証を使用するには、URI で資格情報を渡す必要があります。 Webhook エンドポイントが特定のスキーマ (Microsoft Teams スキーマなど) を必要とする場合は、Logic Apps アクションの種類を使用して、ターゲット Webhook の想定に合わせてアラート スキーマを操作する必要があります。 Webhook アクションの再試行に使用される規則の詳細については、「Webhook」を参照してください。 |
ほとんどのサービス インシデントは、いくつかのサブスクリプションに影響するため、これらのインシデントは status.azure.comなどの場所には表示されません。 サービス正常性アラートは、ポータルから構成できます。 作成を自動化する場合は、PowerShell または ARM テンプレートを使用して構成できます。
Service Health アラートとアクション グループを効果的に構成すると、タイムリーな通知受け取り、適切なアクションを実行して、Azure リソースに対するインシデントの影響を軽減できます。
注
何を監視するか、何に対してどのアラートを設定する必要があるかについて役立つ情報が必要な場合は、 Azure Monitor ベースライン アラート ソリューション以上の情報を確認する必要はありません。 Azure 環境でポリシーとイニシアティブを使用して、プラットフォーム アラートとサービス正常性アラートのベースラインを実装するための包括的なガイダンスとコードを提供します。 自動デプロイまたは手動デプロイのオプションが用意されています。
このソリューションには、すべての種類のサービス正常性イベント (サービスに関する問題、計画メンテナンス、正常性の勧告、セキュリティ アドバイザリ) に関するアラート、アクション グループ、さまざまな種類の Azure リソースに関する警告処理ルールを自動的に作成するための事前定義済みポリシーが含まれています。 これは、Azure ランディング ゾーン (ALZ) の設計環境の監視に重点を置いていますが、現在 ALZ アーキテクチャのブラウンフィールドに対応していないブラウンフィールドのお客様向けのガイダンスも提供します。
アクション #3: リソース固有の問題を通知する Resource Health アラートまたは Scheduled Events を検討する
サービス正常性アラートを設定したら、リソース正常性アラートの採用も検討してください。 Azure Resource Health アラートを導入すると、リソースの正常性状態が変化したときに、その理由に関係なく、準リアルタイムで通知を受け取ることができます。
"サービス正常性" アラートと "リソース正常性" アラートには主な違いがあります。 前者は、Microsoft によって調査中の既知のプラットフォームの問題の間にトリガーされます。 たとえば、継続的な停止またはサービス インシデントがあります。 後者は、基になる原因に関係なく、特定のリソースが異常と見なされたときにトリガーされます。
リソース正常性アラートは、Azure portal の [サービス正常性] ページの [Resource Health] ウィンドウから構成できます。

Azure Resource Manager テンプレートおよび Azure PowerShell を使用して、リソース正常性アラートをプログラムで作成することもできます。 リソース正常性アラートをプログラムで作成すると、アラートを一括で作成およびカスタマイズできます。
影響を回避するための仮想マシンのスケジュール化されたイベント
スケジュールされたイベント は、もう 1 つの優れたツールです。 前に説明したアラートの種類はどちらもユーザーまたはシステムに通知しますが、スケジュールされたイベントはリソース自体に通知します。 このアプローチにより、仮想マシンのメンテナンスまたは自動サービス復旧イベントの 1 つに備える時間をアプリケーションに提供できます。 これにより、間近に迫ったメンテナンス イベント (たとえば、今後の再起動) に関するシグナルが提供されます。これにより、アプリケーションはそれを認識し、中断を制限するアクションを実行できます。 アプリケーションがプールから削除されたり、性能がゆっくり低下したりする可能性があります。 スケジュール化されたイベントは、Windows と Linux の両方で、PaaS や IaaS を含むすべての種類の Azure Virtual Machine で利用できます。
注
リソース正常性アラートとスケジュール化されたイベントはどちらも役に立つツールですが、最も重要な行動要請はサービス正常性アラートを構成することです。 この機能は、リソースで何が起こっているか、私たちがどのように対応しているか、そして問題が解決する時期を確実に理解するために重要です。
アクション #4: 投資のセキュリティを強化して環境を保護する
運用可能なセキュリティに関するベスト プラクティスに関する記事を確認し、それらを実装して、Azure 内のデータ、アプリケーション、その他の資産を確実に保護します。 これらのベスト プラクティスは、Azure プラットフォームの現在の機能と機能を使用するユーザーの集合的な知識と経験から派生しています。 この記事は、進化するオプションやテクノロジを反映するために定期的に更新されています。
出発点として、実装に関する次の主要な推奨事項を検討します。
すべてのユーザーに対して 2 段階認証を要求します。 この要件には、アカウントが侵害された場合に大きな影響を与える可能性がある管理者や組織内の他のユーザーが含まれます。 たとえば、財務責任者です。 この露出に関する懸念を軽減するには、多要素認証を適用します。
テナントで リスク ポリシーを 構成して有効にします。 "誰か" が環境内にある場合は 、アラート が表示されます。 この方法では、匿名 IP アドレスの使用、通常とは限らない移動、未知のサインイン プロパティなど、危険なイベントに対するアラートが作成されます。 さらに、多要素認証やパスワードのリセットなどの修復作業がトリガーされ、お客様のセキュリティが確保されます。
環境内に '誰' がいるかを認識し、準備するための事前対策として、ディレクトリとの間のサブスクリプションの移動を制御します。 この方法により、組織は、使用されているサブスクリプションを完全に可視化でき、不明なディレクトリに移動する可能性のあるサブスクリプションの移動を防ぐことができます。
すべてのグローバル管理者とサブスクリプション管理者の資格情報を定期的にローテーションして、潜在的なセキュリティ侵害、侵害されたアカウント、または特権アクセス許可の不正使用から保護します。 資格情報を定期的にローテーションすると、環境にセキュリティレイヤーが追加され、データとリソースの整合性と機密性を維持するのに役立ちます。
テナント内のすべてのグローバル管理者ユーザーの電子メールと電話番号を確認し、定期的に更新します。
アクション #5: 潜在的な影響を回避するか、最小限に抑えるために、主要な Azure ワークロードの回復性を高める
ワークロードの信頼性を確保するには、Microsoft Azure Well-Architected レビューを通じて、Microsoft Azure Well-Architected Framework (WAF) の教義を使用してワークロードを評価することが重要です。 WAF には、カオス エンジニアリング手法の採用など、回復性テストに関する推奨事項も用意されています。
アプリケーションは、 可用性 と 回復性の両方を確保するためにテストを受ける必要があります。 可用性とは、アプリケーションが大幅なダウンタイムなしで動作する期間を指します。 回復性は、アプリケーションが障害から回復できる速度を測定します。
WAF の作業を補完するために、次の推奨事項を実装し、提供されているツールを使用して、アプリケーションの回復性を確認して構築することを検討してください。
Azure Advisor ページの下にある Azure portal の統合信頼性 ブック を使用して、アプリケーションの信頼性の状態を評価し、潜在的なリスクを特定し、改善を計画して実装します。
ワークロードとリソースを複数のリージョンに展開して、事業継続とディザスター リカバリー (BCDR) を強化します。 最適なリージョン間デプロイ オプションについては、 Azure リージョン ペアの包括的な一覧を参照してください。
ワークロードおよびリソースのデプロイを Availability Zones 全体に分散して、リージョン内の可用性を最大化します。
高度な分離を必要とするビジネス クリティカルなワークロードには、Azure で分離された仮想マシン サイズを使用することを検討してください。 これらのサイズにより、仮想マシンが特定の種類のハードウェア専用となり、独立して動作することが保証されます。 詳細については、「 Azure での仮想マシンの分離」を参照してください。
メンテナンス構成を使用して、Azure 仮想マシンの更新プログラムをより適切に制御および管理することを検討してください。 この機能を使用すると、更新プログラムをスケジュールおよび管理できます。これにより、メンテナンス アクティビティ中のダウンタイムを許容できない機密性の高いワークロードの中断を最小限に抑えることができます。
リージョン間またはリージョン内の冗長性を実装して、冗長性を強化します。 ガイダンスについては、 高可用性ゾーン冗長 Web アプリケーションの例を参照してください。
Azure Chaos Studio を使用して、アプリケーションの回復性を強化します。 このツールを使用すると、Azure アプリケーションに制御された障害を意図的に導入できます。 このツールを使用すると、回復性を評価し、ネットワーク待機時間、ストレージの停止、期限切れのシークレット、データセンターの障害など、さまざまな中断にどのように対応するかを確認できます。
Azure ポータルの [Azure Advisor] ページで利用できる サービス廃止ワークブック を使用します。 この統合ツールは、重要なワークロードに影響を与える可能性のあるサービス提供終了について常に情報を得るのに役立ちます。これにより、必要な移行を効果的に計画して実行できます。
注
Premier/Unified サポート契約を結んでいるお客様は、カスタマー サクセス チームを使用して、Well-Architected Framework 評価 (WAF) を戦略化して実装できます。