Tutorial: Part 1 - Create resources for building a custom chat application with the prompt flow SDK
In this tutorial, you use the prompt flow SDK (and other libraries) to build, configure, evaluate, and deploy a chat app for your retail company called Contoso Trek. Your retail company specializes in outdoor camping gear and clothing. The chat app should answer questions about your products and services. For example, the chat app can answer questions such as "which tent is the most waterproof?" or "what is the best sleeping bag for cold weather?".
This tutorial is part one of a three-part tutorial. This part one shows how an administrator of an Azure subscription creates and configures the resources needed for parts two and three of the tutorial series. Parts two and three show how a developer uses the resources. In many organizations, the same person might take on both of these roles. In this part one, you learn how to:
- Create an Azure AI Studio hub
- Create a project
- Create an Azure AI Search index
- Configure access for the Azure AI Studio and Azure AI Search resources
If you've completed other tutorials or quickstarts, you might have already created some of the resources needed for this tutorial. If you have, feel free to skip those steps here.
This tutorial is part one of a three-part tutorial.
Prerequisites
- An Azure account with an active subscription. If you don't have one, create an account for free.
Important
You must have the necessary permissions to add role assignments in your Azure subscription. Granting permissions by role assignment is only allowed by the Owner of the specific Azure resources. You might need to ask your Azure subscription owner (who might be your IT admin) to complete this tutorial for you.
Azure AI Studio and Azure portal
In this tutorial, you use Azure resources to build the chat app. You'll use both Azure AI Studio and Azure portal to create and configure these resources.
- As an administrator, you use Azure portal to configure access to resources.
- As a developer, you use Azure AI Studio to group together those resources needed to build, evaluate, and deploy the chat app. You can also interact with your models and deployments in AI Studio.
Create an Azure AI Studio hub
To create a hub in Azure AI Studio, follow these steps:
Go to the Home page in Azure AI Studio and sign in with your Azure account.
Select All hubs from the left pane and then select + New hub.
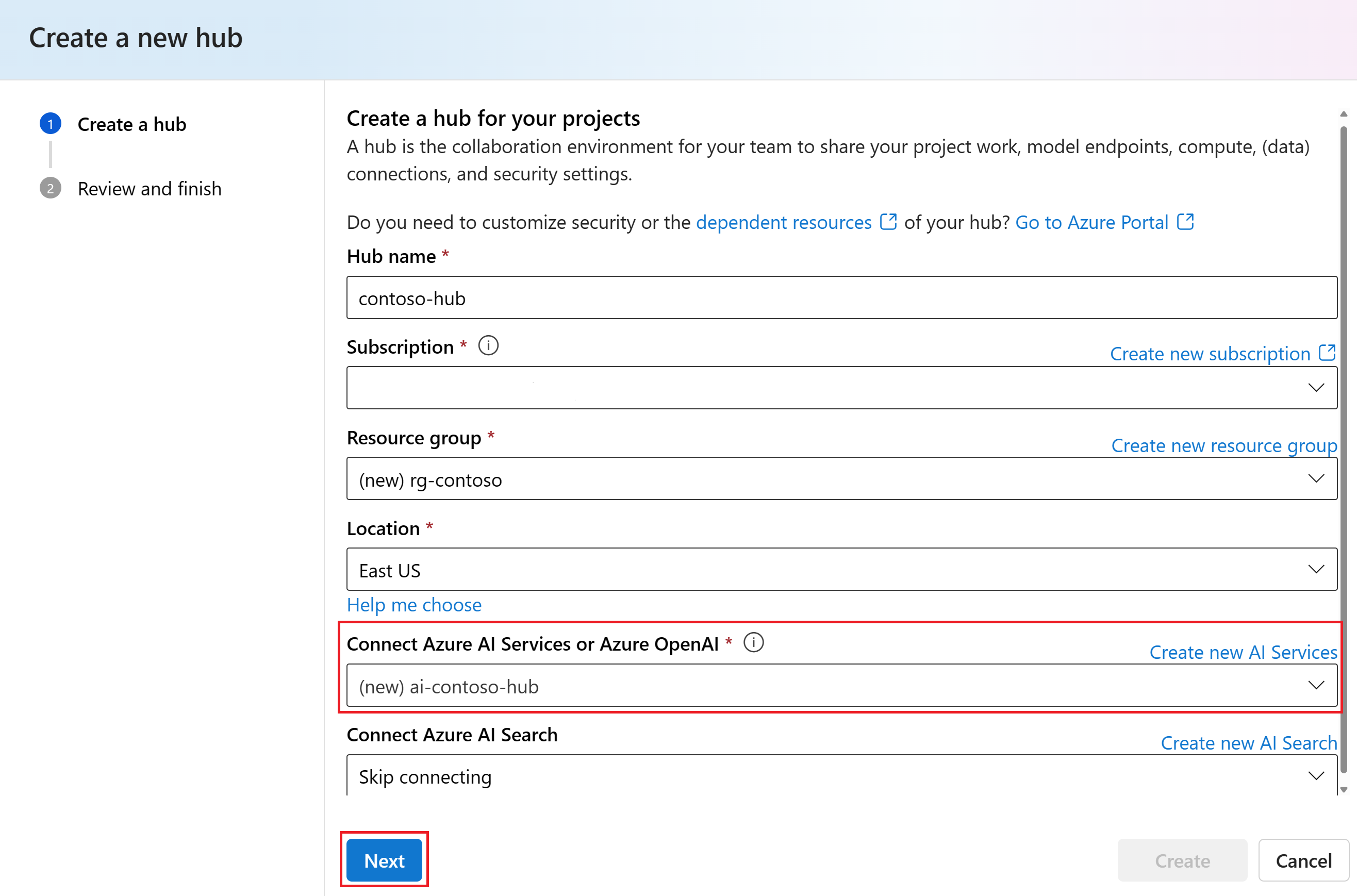
In the Create a new hub dialog, enter a name for your hub (such as contoso-hub) and select Next. Leave the default Connect Azure AI Services option selected. A new AI services connection is created for the hub.
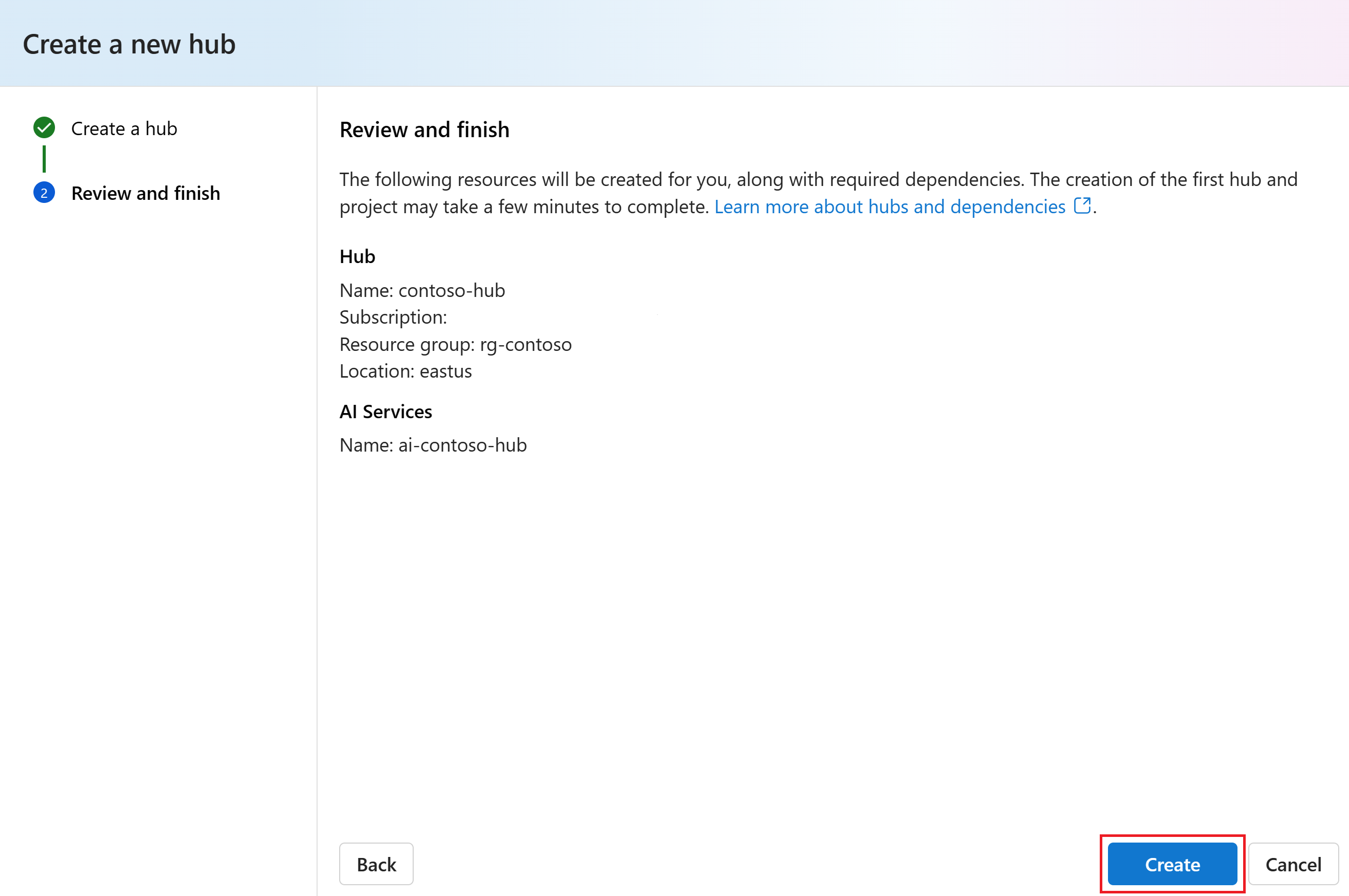
Review the information and select Create.
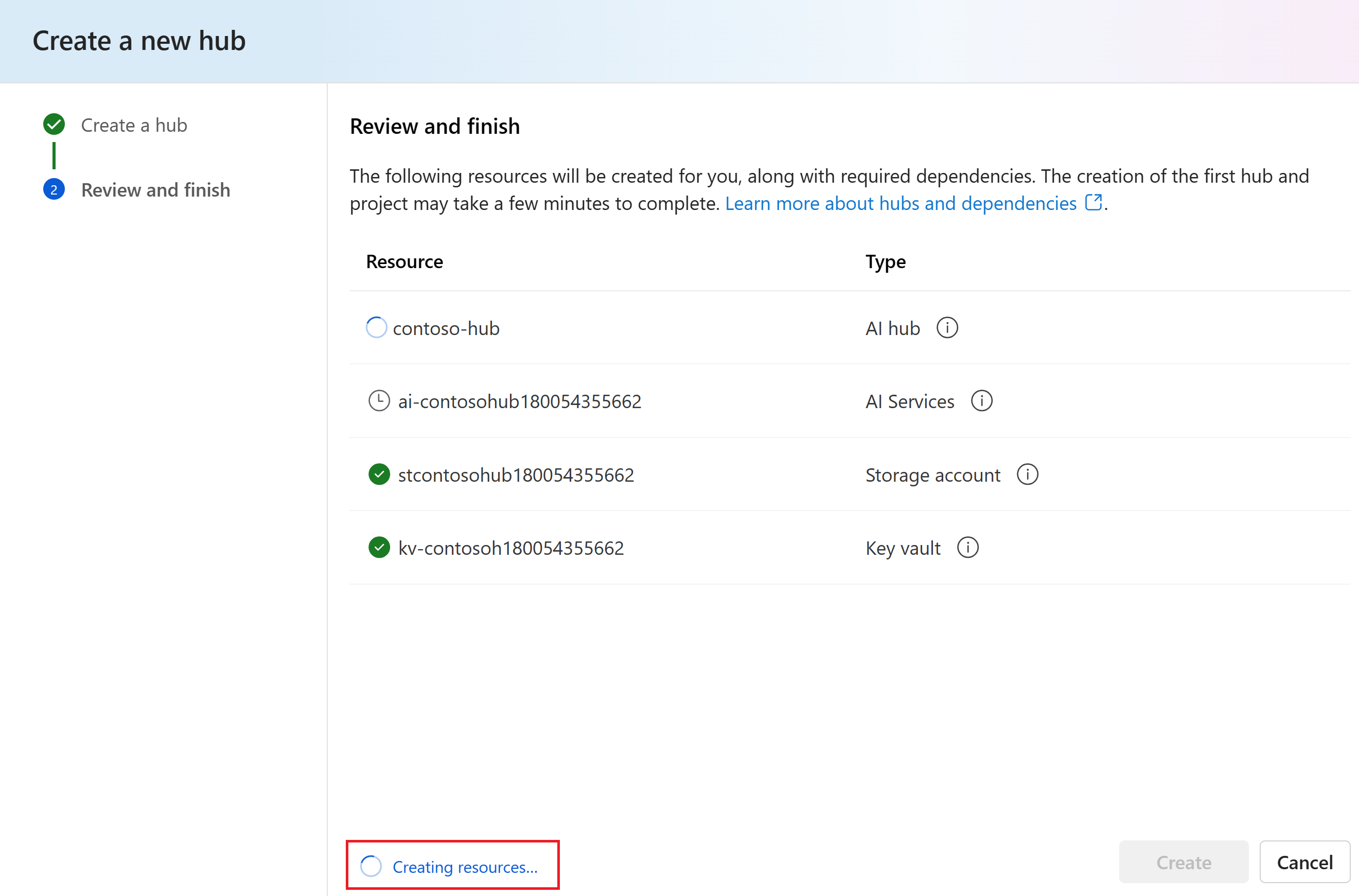
You can view the progress of the hub creation in the wizard.




Create a project
To create a project in Azure AI Studio, follow these steps:
- Go to the Home page of Azure AI Studio.
- Select + New project.
- Enter a name for the project.
- Select the hub you created in the previous step.
Once a project is created, you can access the playground, tools, and other assets in the left navigation panel.
Create an Azure AI Search index
The goal with this application is to ground the model responses in your custom data. The search index is used to retrieve relevant documents based on the user's question.
You need an Azure AI Search service and connection in order to create a search index.
Note
Creating an Azure AI Search service and subsequent search indexes has associated costs. You can see details about pricing and pricing tiers for the Azure AI Search service on the creation page, to confirm cost before creating the resource.
Create an Azure AI Search service
If you already have an Azure AI Search service, you can skip to the next section.
Otherwise, you can create an Azure AI Search service using the Azure portal.
- Create an Azure AI Search service in the Azure portal.
- Select your resource group and instance details. You can see details about pricing and pricing tiers on this page.
- Continue through the wizard and select Review + assign to create the resource.
- Confirm the details of your Azure AI Search service, including estimated cost.
- Select Create to create the Azure AI Search service.
Connect the Azure AI Search to your project
If you already have an Azure AI Search connection in your project, you can skip to configure access for the Azure AI Search service.
In the Azure AI Studio, check for an Azure AI Search connected resource.
- In AI Studio, go to your project and select Settings from the left pane.
- In the Connected resources section, look to see if you have a connection of type Azure AI Search.
- If you have an Azure AI Search connection, you can skip ahead to configure access for resources.
- Otherwise, select New connection and then Azure AI Search.
- Find your Azure AI Search service in the options and select Add connection.
- Continue through the wizard to create the connection. For more information about adding connections, see this how-to guide.
Configure access for resources
This section shows how to configure the various access controls needed for the resources you created in the previous sections.
We recommend using Microsoft Entra ID instead of using API keys. In order to use this authentication, you need to set the right access controls and assign the right roles for your services.
Configure access for Azure AI Services
Start in the project to find the AI Services resource:
- In AI Studio, go to your project and select Settings from the left pane.
- Select Connected resources.
- Select the AI Services or Azure OpenAI name in the connected resources list to open the resource details page. Then select the resource name again in the Connection Details page, which opens the resource in the Azure portal.
Specify the access control in the Azure portal:
- From the left page in the Azure portal, select Access control (IAM) > + Add > Add role assignment.
- Search for the role Cognitive Services OpenAI User and then select it. Then select Next.
- Select User, group, or service principal. Then select Select members.
- In the Select members pane that opens, search for the name of the user that you want to add the role assignment for. Select the user and then select Select.
- Continue through the wizard and select Review + assign to add the role assignment.
Configure access for Azure AI Search
Now go back to AI Studio Settings > Connected Resources. This time select the Azure AI Search name in the connected resources list to open the resource details page. Then select the resource name again in the Connection Details page, which opens the resource in the Azure portal.
To enable role-based access control for your Azure AI Search service, follow these steps:
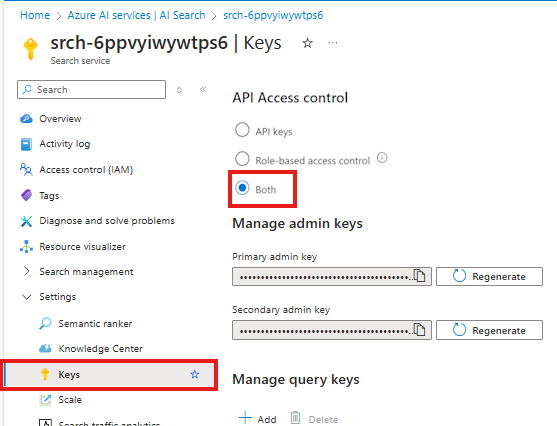
On your Azure AI Search service in the Azure portal, select Settings > Keys from the left pane.
Select Both to ensure that API keys and role-based access control are both enabled for your Azure AI Search service.
Warning
You can use role-based access control locally because you run az login later in this tutorial series. But when you deploy your app in part 3 of the tutorial, the deployment is authenticated using API keys from your Azure AI Search service. Support for Microsoft Entra ID authentication of the deployment is coming soon. For now, you need to enable both keys and endpoints.
Next grant your user identity (or the identity of the developer who will complete parts two and three) the Search Index Data Contributor and Search Service Contributor roles on the Azure AI Search service. These roles enable you to call the Azure AI Search service the associated user identity.
Still in the Azure portal for the Azure AI Search service, assign the Search Index Data Contributor role to your Azure AI Search service. (These are the same steps you did previously for the Azure OpenAI service.)
- From the left page in the Azure portal, select Access control (IAM) > + Add > Add role assignment.
- Search for the Search Index Data Contributor role and then select it. Then select Next.
- Select User, group, or service principal. Then select Select members.
- In the Select members pane that opens, search for the name of the user that you want to add the role assignment for. Select the user and then select Select.
- Continue through the wizard and select Review + assign to add the role assignment.
Repeat these steps to also add the Search Service Contributor role to the Azure AI Search service.
You're now ready to hand off the project to a developer to build the chat application. The developer will use the prompt flow SDK to build, configure, evaluate, and deploy the chat app for your retail company called Contoso Trek.
Clean up resources
To avoid incurring unnecessary Azure costs, you should delete the resources you created in this tutorial if they're no longer needed. To manage resources, you can use the Azure portal.
But don't delete them yet, if you want to build a chat app in the next part of this tutorial series.