Azure Monitor 경고를 사용하여 Azure 가상 머신 모니터링
이 문서는 Azure Monitor에서 가상 머신 및 해당 워크로드 모니터링 가이드의 일부입니다. Azure Monitor 경고는 모니터링 데이터의 흥미로운 데이터와 패턴을 사전에 알립니다. 가상 머신에 대해 미리 구성된 경고 규칙은 없지만 Azure Monitor 에이전트에서 수집한 데이터를 기준으로 고유한 경고 규칙을 만들 수 있습니다. 이 문서에서는 가상 머신과 관련된 경고 개념과 다른 Azure Monitor 고객이 사용하는 일반적인 경고 규칙을 설명합니다.
이 시나리오에서는 Azure 및 하이브리드 가상 머신 환경의 전체 모니터링을 구현하는 방법을 설명합니다.
첫 번째 Azure 가상 머신 모니터링을 시작하려면 Azure 가상 머신 모니터링을 참조하세요.
권장 경고 집합을 빠르게 사용하도록 설정하려면 Azure Virtual Machines에 대한 권장 경고 규칙 사용을 참조하세요.
중요
대부분의 경고 규칙에는 규칙 유형, 포함된 차원 수 및 실행 빈도에 따라 달라지는 비용이 있습니다. 경고 규칙을 만들기 전에 Azure Monitor 가격 책정의 경고 규칙 섹션을 참조하세요.
경고 규칙은 Azure Monitor에서 이미 수집된 데이터를 검사합니다. 경고 규칙을 만들기 전에 특정 시나리오에 대한 데이터가 수집되고 있는지 확인해야 합니다. 이 문서의 모든 경고 규칙을 포함하여 다양한 시나리오에 대한 데이터 수집 구성에 대한 지침은 Azure Monitor로 가상 머신 모니터링: 데이터 수집을 참조하세요.
Azure Monitor는 모든 Azure Virtual Machines에 대해 빠르게 사용하도록 설정할 수 있는 권장 경고 규칙 집합을 제공합니다. 이러한 규칙은 기본 모니터링을 위한 좋은 시작점입니다. 하지만 다음과 같은 이유로 대부분의 엔터프라이즈 구현에 대해 충분한 경고를 제공하지는 않습니다.
- 권장 경고는 Azure Virtual Machines에만 적용되며 하이브리드 컴퓨터에는 적용되지 않습니다.
- 권장 경고에는 게스트 메트릭이나 로그가 아닌 호스트 메트릭만 포함됩니다. 이러한 메트릭은 컴퓨터 자체의 상태를 모니터링하는 데 유용합니다. 하지만 컴퓨터에서 실행 중인 워크로드 및 애플리케이션에 대한 가시성이 최소화될 수 있습니다.
- 권장 경고는 과도한 수의 경고 규칙을 만드는 개별 컴퓨터와 연결됩니다. 각 컴퓨터에 대해 이 방법에 의존하는 대신 여러 컴퓨터에 대해 최소한의 경고 규칙을 사용하는 전략에 대해서는 경고 규칙 크기 조정을 참조하세요.
Azure Monitor에서 가장 일반적인 형식의 경고 규칙은 메트릭 경고 및 로그 검색 경고입니다. 특정 시나리오에 만드는 경고 규칙의 유형은 사용자가 경고하는 데이터의 위치에 따라 달라집니다.
메트릭과 로그 모두에서 특정 경고 시나리오의 데이터를 사용할 수 있는 경우가 있을 수 있습니다. 그렇다면 사용할 규칙 유형을 결정해야 합니다. 특정 데이터를 수집하는 방법에 유연성이 있을 수 있으며, 경고 규칙 유형을 판단하여 데이터 수집 방법에 대한 판단을 내릴 수도 있습니다.
메트릭 경고의 일반적인 용도는 다음과 같습니다.
- 특정 메트릭이 임계값을 초과하면 경고합니다. 예를 들어 컴퓨터의 CPU가 과하게 실행되는 경우를 들 수 있습니다.
메트릭 경고의 데이터 원본은 다음과 같습니다.
- 자동으로 수집되는 Azure 가상 머신의 호스트 메트릭입니다.
- 게스트 운영 체제에서 Azure Monitor 에이전트가 수집한 메트릭
로그 검색 경고의 일반적인 용도:
- Windows 이벤트 로그 또는 syslog에서 특정 이벤트 또는 이벤트 패턴이 발견되면 경고합니다. 이러한 경고 규칙은 일반적으로 쿼리에서 반환된 테이블 행을 측정합니다.
- 여러 컴퓨터에서 숫자 데이터 계산을 기반으로 경고합니다. 이러한 경고 규칙은 일반적으로 쿼리 결과에서 숫자 열의 계산을 측정합니다.
로그 검색 경고의 데이터 원본:
- Log Analytics 작업 영역에서 수집된 모든 데이터입니다.
동일한 모니터링이 필요한 가상 머신이 많을 수 있으므로 각각에 대해 개별 경고 규칙을 만들 필요가 없습니다. 또한 규칙 형식에 따라 관리해야 하는 경고 규칙의 수를 제한하는 다양한 전략이 있는지 확인하려고 합니다. 이러한 각 전략은 경고 규칙의 대상 리소스에 대한 이해에 따라 달라집니다.
가상 머신은 여러 리소스 모니터링에 설명된 대로 여러 리소스 메트릭 경고 규칙을 지원합니다. 이를 통해 동일한 지역 내의 리소스 그룹 또는 구독에 있는 모든 가상 머신에 적용되는 단일 메트릭 경고 규칙을 만들 수 있습니다.
권장 경고로 시작하고 구독 또는 리소스 그룹을 대상 리소스로 사용하여 각각에 대해 해당 규칙을 만듭니다. 여러 지역에 컴퓨터가 있는 경우 각 지역에 대해 중복 규칙을 만들어야 합니다.
더 많은 메트릭 경고 규칙에 대한 요구 사항을 식별할 때 구독 또는 리소스 그룹을 대상 리소스로 사용하여 다음과 같은 전략을 수행합니다.
- 관리해야 하는 경고 규칙 수를 최소화합니다.
- 새 컴퓨터에 자동으로 적용되는지 확인합니다.
로그 검색 경고 규칙의 대상 리소스를 특정 컴퓨터로 설정하면 쿼리가 개별 경고를 제공하는 해당 컴퓨터와 연결된 데이터로 제한됩니다. 이러한 방식에는 각 컴퓨터에 대해 별도의 경고 규칙이 필요합니다.
로그 경고 규칙의 대상 리소스를 Log Analytics 작업 영역으로 설정하면 해당 작업 영역의 모든 데이터에 액세스할 수 있습니다. 이러한 이유로 단일 규칙으로 작업 그룹에 있는 모든 컴퓨터의 데이터에 대해 경고할 수 있습니다. 이러한 방식에서는 모든 컴퓨터에 대한 단일 경고를 만드는 옵션이 제공됩니다. 그런 다음 차원을 사용하여 각 컴퓨터에 대해 별도의 경고를 만들 수 있습니다.
예를 들어, 컴퓨터에서 Windows 이벤트 로그에 오류 이벤트가 만들어질 때 경고할 수 있습니다. 먼저 Azure Monitor 에이전트를 사용하여 데이터 수집에 설명된 대로 데이터 수집 규칙을 만들어 Log Analytics 작업 영역의 Event 테이블에 이러한 이벤트를 보내야 합니다. 그런 다음, 작업 영역을 대상 리소스로 사용하고 다음 이미지에 표시된 조건을 사용하여 이 테이블을 쿼리하는 경고 규칙을 만들 수 있습니다.
쿼리는 모든 컴퓨터의 모든 오류 메시지에 대한 레코드를 반환합니다. 차원으로 분할 옵션을 사용하고 _ResourceId를 지정하여 결과에 여러 컴퓨터가 반환되는 경우 각 컴퓨터에 대한 경고를 만들도록 규칙에 지시합니다.
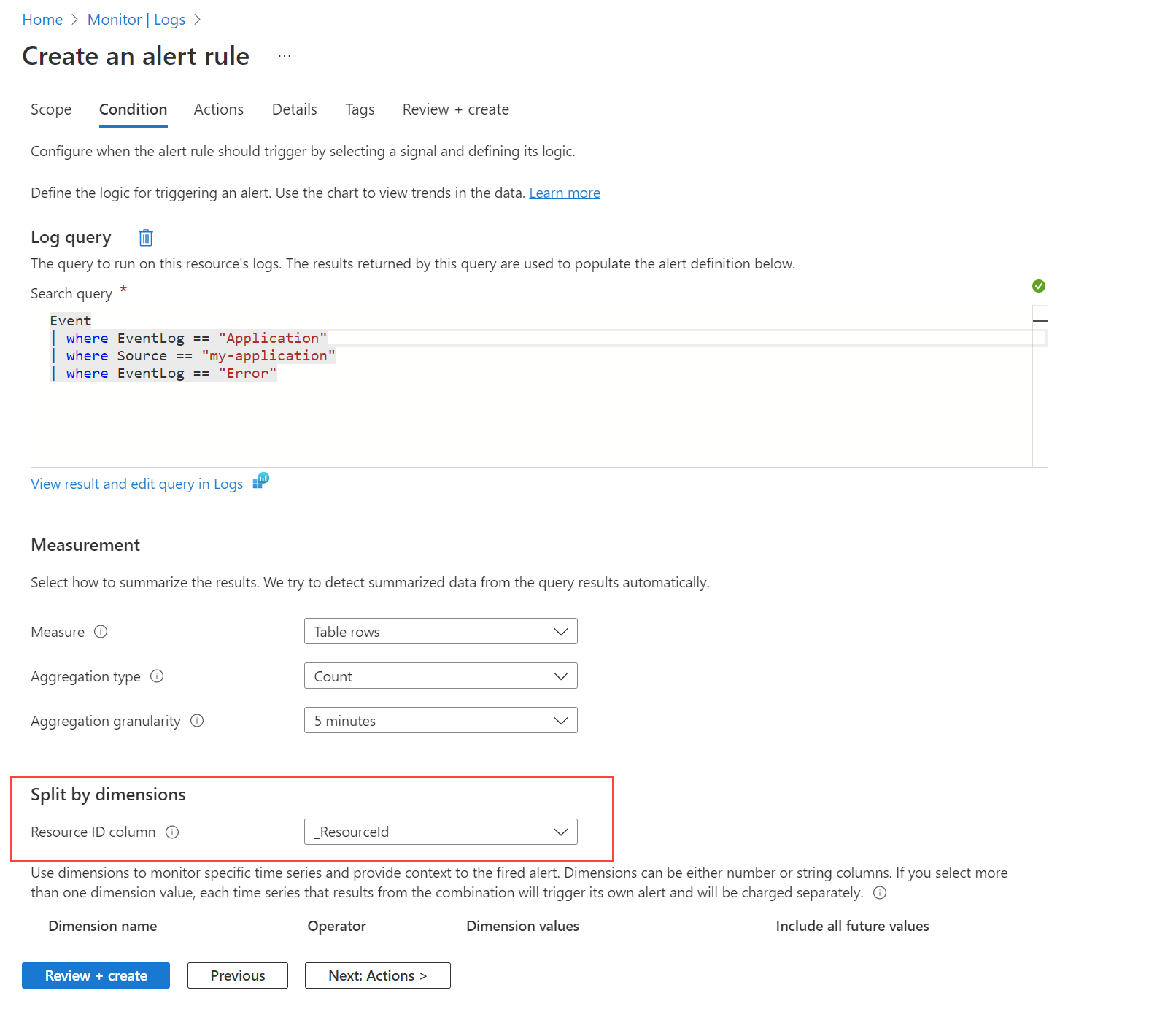
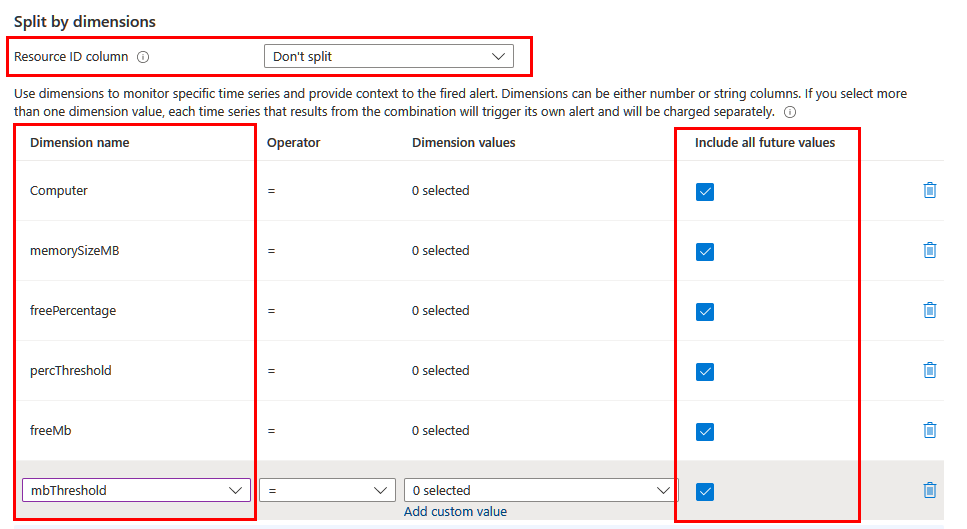
경고에 포함하려는 정보에 따라 다른 차원을 사용하여 분할해야 할 수도 있습니다. 이 경우 project 또는 extend 연산자를 사용하여 필요한 차원이 쿼리에 투영되었는지 확인합니다. 리소스 ID 열 필드를 분할 안 함으로 설정하고 의미 있는 모든 차원을 목록에 포함합니다. 쿼리에서 반환된 모든 값이 포함되도록 모든 향후 값 포함이 선택되었는지 확인합니다.
로그 검색 경고 규칙을 사용할 때의 또 다른 이점은 임계값을 결정하기 위해 쿼리에 복잡한 논리를 포함하는 기능입니다. 임계값을 하드 코딩하거나, 모든 리소스에 적용하거나, 일부 필드 또는 계산된 값에 따라 동적으로 계산할 수 있습니다. 임계값은 특정 조건에 따라서만 리소스에 적용됩니다. 예를 들어, 사용 가능한 메모리를 기반으로 경고를 만들 수 있지만 특정 양의 총 메모리가 있는 컴퓨터에 대해서만 경고를 만들 수 있습니다.
다음 섹션에서는 Azure Monitor의 가상 컴퓨터에 대한 일반적인 경고 규칙을 나열합니다. 메트릭 경고 및 로그 검색 경고에 대한 세부 정보가 각각 제공됩니다. 사용할 경고 형식에 대한 지침은 경고 형식을 참조하세요. Azure Monitor에서 경고 규칙을 만드는 프로세스에 익숙하지 않은 경우 새 경고 규칙을 만드는 지침을 참조하세요.
참고
여기에 제공된 로그 검색 경고에 대한 세부 정보는 클라이언트 운영 체제에 대한 공통 성능 카운터 집합을 제공하는 VM 인사이트를 사용하여 수집된 데이터를 사용합니다. 이 이름은 운영 체제 형식과 무관합니다.
가상 머신에 대한 가장 일반적인 모니터링 요구 사항 중 하나는 실행이 중지되면 경고를 만드는 것입니다. 가장 좋은 방법은 현재 공개 미리 보기에 있는 VM 가용성 메트릭을 사용하여 Azure Monitor에서 메트릭 경고 규칙을 만드는 것입니다. 이 메트릭에 대한 안내는 Azure 가상 머신에 대한 가용성 경고 규칙 만들기를 참조하세요.
경고 규칙은 하나의 활동 로그 신호로 제한됩니다. 따라서 모든 조건에 대해 하나의 경고 규칙을 만들어야 합니다. 예를 들어, "가상 머신 시작 또는 중지"에는 두 가지 경고 규칙이 필요합니다. 그러나 VM이 다시 시작될 때 경고를 받으려면 하나의 경고 규칙만 필요합니다.
스케일링 경고 규칙에 설명된 대로 구독 또는 리소스 그룹을 대상 리소스로 사용하여 가용성 경고 규칙을 만듭니다. 규칙은 경고 규칙 이후에 만드는 새 컴퓨터를 포함하여 여러 가상 머신에 적용됩니다.
에이전트 하트비트는 Azure Monitor 에이전트를 사용하여 하트비트를 보내기 때문에 컴퓨터를 사용할 수 없음 경고와 약간 다릅니다. 에이전트 하트비트는 컴퓨터가 실행 중이지만 에이전트가 응답하지 않는 경우 경고할 수 있습니다.
하트비트라는 메트릭은 각 Log Analytics 작업 영역에 포함됩니다. 해당 작업 영역에 연결된 각 가상 머신은 1분 마다 하트비트 메트릭 값을 보냅니다. 컴퓨터가 메트릭에 있는 차원이기 때문에 모든 컴퓨터에서 하트비트를 보내지 못하면 경고를 발생 시킬 수 있습니다. 집계 형식을 계산을 위해 설정하고 평가 세분성과 일치하기 위해 임계값을 설정하세요.
로그 검색 경고는 하트비트 테이블을 사용합니다. 이 테이블은 각 컴퓨터에서 1분 마다 하트비트 레코드를 포함해야 합니다.
다음 쿼리와 함께 규칙을 사용합니다.
Heartbeat
| summarize TimeGenerated=max(TimeGenerated) by Computer, _ResourceId
| extend Duration = datetime_diff('minute',now(),TimeGenerated)
| summarize MinutesSinceLastHeartbeat = min(Duration) by Computer, bin(TimeGenerated,5m), _ResourceId
이 섹션에서는 CPU 경고에 대해 설명합니다.
| 대상 | 메트릭 |
|---|---|
| Host | 백분율 CPU(권장 경고에 포함됨) |
| Windows 게스트 | \Processor Information(_Total)% Processor Time |
| Linux 게스트 | cpu/usage_active |
CPU 사용률
InsightsMetrics
| where Origin == "vm.azm.ms"
| where Namespace == "Processor" and Name == "UtilizationPercentage"
| summarize CPUPercentageAverage = avg(Val) by bin(TimeGenerated, 15m), Computer, _ResourceId
이 섹션에서는 메모리 경고에 대해 설명합니다.
| 대상 | 메트릭 |
|---|---|
| Host | 사용 가능한 메모리 바이트(미리 보기)(권장 경고에 포함됨) |
| Windows 게스트 | \Memory% Committed Bytes in Use \Memory\Available Bytes |
| Linux 게스트 | 메모리/사용 가능 메모리/사용 가능 퍼센티지 |
참고
하나의 디스크에 경고를 지정해야 하는 경우 쿼리에 다음을 추가할 수 있습니다. | where parse_json(Tags).["vm.azm.ms/mountId"] == "C:"사용 가능한 메모리(MB)
InsightsMetrics
| where Origin == "vm.azm.ms"
| where Namespace == "Memory" and Name == "AvailableMB"
| summarize AvailableMemoryInMBAverage = avg(Val) by bin(TimeGenerated, 15m), Computer, _ResourceId
사용 가능한 메모리 퍼센티지(%)
InsightsMetrics
| where Origin == "vm.azm.ms"
| where Namespace == "Memory" and Name == "AvailableMB"
| extend TotalMemory = toreal(todynamic(Tags)["vm.azm.ms/memorySizeMB"]) | extend AvailableMemoryPercentage = (toreal(Val) / TotalMemory) * 100.0
| summarize AvailableMemoryInPercentageAverage = avg(AvailableMemoryPercentage) by bin(TimeGenerated, 15m), Computer, _ResourceId
이 섹션에서는 디스크 경고에 대해 설명합니다.
| 대상 | 메트릭 |
|---|---|
| Windows 게스트 | \Logical Disk(_Total)% Free Space \Logical Disk(_Total)\Free Megabytes |
| Linux 게스트 | 디스크/사용 가능 공간 디스크/사용 가능 공간 퍼센티지 |
사용된 논리 디스크-각 컴퓨터의 모든 디스크
InsightsMetrics
| where Origin == "vm.azm.ms"
| where Namespace == "LogicalDisk" and Name == "FreeSpacePercentage"
| summarize LogicalDiskSpacePercentageFreeAverage = avg(Val) by bin(TimeGenerated, 15m), Computer, _ResourceId
논리 디스크 사용-개별 디스크
InsightsMetrics
| where Origin == "vm.azm.ms"
| where Namespace == "LogicalDisk" and Name == "FreeSpacePercentage"
| extend Disk=tostring(todynamic(Tags)["vm.azm.ms/mountId"])
| summarize LogicalDiskSpacePercentageFreeAverage = avg(Val) by bin(TimeGenerated, 15m), Computer, _ResourceId, Disk
논리 디스크 IOPS
InsightsMetrics
| where Origin == "vm.azm.ms"
| where Namespace == "LogicalDisk" and Name == "TransfersPerSecond"
| extend Disk=tostring(todynamic(Tags)["vm.azm.ms/mountId"])
| summarize DiskIOPSAverage = avg(Val) by bin(TimeGenerated, 15m), Computer, _ResourceId, Disk
논리 디스크 데이터 속도
InsightsMetrics
| where Origin == "vm.azm.ms"
| where Namespace == "LogicalDisk" and Name == "BytesPerSecond"
| extend Disk=tostring(todynamic(Tags)["vm.azm.ms/mountId"])
| summarize DiskBytesPerSecondAverage = avg(Val) by bin(TimeGenerated, 15m), Computer, _ResourceId, Disk
| 대상 | 메트릭 |
|---|---|
| Host | 총 네트워크 입력, 총 네트워크 출력(권장 경고에 포함됨) |
| Windows 게스트 | \Network Interface\Bytes Sent/sec \Logical Disk(_Total)\Free Megabytes |
| Linux 게스트 | 디스크/사용 가능 공간 디스크/사용 가능 공간 퍼센티지 |
네트워크 인터페이스 수신된 바이트 -모든 인터페이스
InsightsMetrics
| where Origin == "vm.azm.ms"
| where Namespace == "Network" and Name == "ReadBytesPerSecond"
| summarize BytesReceivedAverage = avg(Val) by bin(TimeGenerated, 15m), Computer, _ResourceId
네트워크 인터페이스 수신된 바이트-개별 인터페이스
InsightsMetrics
| where Origin == "vm.azm.ms"
| where Namespace == "Network" and Name == "ReadBytesPerSecond"
| extend NetworkInterface=tostring(todynamic(Tags)["vm.azm.ms/networkDeviceId"])
| summarize BytesReceievedAverage = avg(Val) by bin(TimeGenerated, 15m), Computer, _ResourceId, NetworkInterface
네트워크 인터페이스 전송된 바이트-모든 인터페이스
InsightsMetrics
| where Origin == "vm.azm.ms"
| where Namespace == "Network" and Name == "WriteBytesPerSecond"
| summarize BytesSentAverage = avg(Val) by bin(TimeGenerated, 15m), Computer, _ResourceId
네트워크 인터페이스 전송된 바이트-개별 인터페이스
InsightsMetrics
| where Origin == "vm.azm.ms"
| where Namespace == "Network" and Name == "WriteBytesPerSecond"
| extend NetworkInterface=tostring(todynamic(Tags)["vm.azm.ms/networkDeviceId"])
| summarize BytesSentAverage = avg(Val) by bin(TimeGenerated, 15m), Computer, _ResourceId, NetworkInterface
다음 샘플에서는 특정 Windows 이벤트가 만들어질 때 경고를 만듭니다. 메트릭 측정 경고 규칙을 사용하여 각 컴퓨터에 대해 별도의 경고를 만듭니다.
특정 Windows 이벤트에 대한 경고 규칙을 만듭니다. 다음 예제에서는 응용 프로그램 로그의 이벤트를 보여 줍니다. 0의 임계값과 0보다 큰 연속 위반을 지정합니다.
Event | where EventLog == "Application" | where EventID == 123 | summarize NumberOfEvents = count() by Computer, bin(TimeGenerated, 15m)특정 심각도의 Syslog 이벤트에 대한 경고 규칙을 만듭니다. 다음 예제에서는 오류 권한 부여 이벤트를 보여 줍니다. 0의 임계값과 0보다 큰 연속 위반을 지정합니다.
Syslog | where Facility == "auth" | where SeverityLevel == "err" | summarize NumberOfEvents = count() by Computer, bin(TimeGenerated, 15m)
카운터의 최댓값에 대한 경고를 만듭니다.
Perf | where CounterName == "My Counter" | summarize AggregatedValue = max(CounterValue) by Computer카운터의 평균 값에 대한 경고를 만듭니다.
Perf | where CounterName == "My Counter" | summarize AggregatedValue = avg(CounterValue) by Computer