HADR 구성 모범 사례(Azure VM의 SQL Server)
적용 대상:![]() Azure VM 기반 SQL Server
Azure VM 기반 SQL Server
Windows Server 장애 조치(Failover) 클러스터는 Azure VM(Virtual Machines)의 SQL Server를 사용한 HADR(고가용성 및 재해 복구)에 사용됩니다.
이 문서에서는 Azure VM에서 SQL Server와 함께 사용할 때 장애 조치(failover) 클러스터 인스턴스(FCI) 및 가용성 그룹 모두에 대한 클러스터 구성 모범 사례를 제공합니다.
자세한 내용은 이 시리즈의 다른 문서(검사 목록, VM 크기, 스토리지, 보안, HADR 구성, 기준선 수집)를 참조하세요.
검사 목록
이 문서의 나머지 부분에서 자세히 설명하는 HADR 모범 사례에 대한 간략한 개요를 보려면 다음 검사 목록을 검토합니다.
Always On 가용성 그룹 및 장애 조치(failover) 클러스터 인스턴스와 같은 HADR(고가용성 및 재해 복구) 기능은 기본 Windows Server 장애 조치(Failover) 클러스터 기술을 사용합니다. 클라우드 환경을 더 잘 지원하기 위해 HADR 설정을 수정하기 위한 모범 사례를 검토합니다.
Windows 클러스터의 경우 모범 사례를 고려합니다.
- 트래픽을 HADR 솔루션으로 라우팅하는 Azure Load Balancer 또는 DNN(분산 네트워크 이름)에 대한 종속성을 방지하기 위해 가능한 경우 SQL Server VM을 여러 서브넷에 배포합니다.
- 일시적인 네트워크 실패 또는 Azure 플랫폼 유지 관리로 인한 예기치 않은 중단을 방지하기 위해 덜 적극적인 매개 변수로 클러스터를 변경합니다. 자세히 알아보려면 하트비트 및 임계값 설정을 참조하세요. Windows Server 2012 이상에서는 다음 권장 값을 사용합니다.
- SameSubnetDelay: 1초
- SameSubnetThreshold: 하트비트 40개
- CrossSubnetDelay: 1초
- CrossSubnetThreshold: 40개 하트비트
- VM을 가용성 집합 또는 다른 가용성 영역에 배치합니다. 자세한 내용은 VM 가용성 설정을 참조하세요.
- 클러스터 노드당 단일 NIC를 사용합니다.
- 클러스터 쿼럼 투표를 구성하여 3개 이상의 홀수 투표를 사용합니다. DR 지역에 투표를 할당하지 마세요.
- 리소스 제약으로 인한 예기치 않은 재시작 또는 장애 조치(failover)를 방지하기 위해 리소스 제한을 신중하게 모니터링합니다.
- OS, 드라이버 및 SQL Server가 최신 빌드인지 확인합니다.
- Azure VM에서 SQL Server에 대한 성능을 최적화합니다. 자세히 알아보려면 이 문서의 다른 섹션을 검토합니다.
- 리소스 제한을 방지하기 위해 워크로드를 줄이거나 분산합니다.
- 제약을 방지하기 위해 제한이 더 높은 VM이나 디스크로 이동합니다.
SQL Server 가용성 그룹 또는 장애 조치(failover) 클러스터 인스턴스의 경우 다음 모범 사례를 고려합니다.
- 예기치 않은 오류가 자주 발생하는 경우 이 문서의 나머지 부분에서 설명하는 성능 모범 사례를 따릅니다.
- SQL Server VM 성능 최적화로 예기치 않은 장애 조치(failover)가 해결되지 않는 경우 가용성 그룹 또는 장애 조치(failover) 클러스터 인스턴스에 대한 모니터링 완화를 고려합니다. 하지만 문제의 근본 원인이 해결되지 않을 수 있고 오류 발생 가능성을 줄여 증상을 일시적으로 덮는 데 그칠 수 있습니다. 계속해서 근본 원인을 조사하고 해결해야 할 수 있습니다. Windows Server 2012 이상에서는 다음 권장 값을 사용합니다.
- 임대 시간 제한: 이 등식을 사용하여 최대 임대 시간 제한 값을 계산합니다.
Lease timeout < (2 * SameSubnetThreshold * SameSubnetDelay).
40초부터 시작합니다. 이전에 권장되었던 완화된SameSubnetThreshold및SameSubnetDelay값을 사용하는 경우 임대 시간 제한 값이 80초를 초과해서는 안 됩니다. - Max failures in a specified period(지정된 기간의 최대 실패 횟수) : 이 값을 6으로 설정합니다.
- 임대 시간 제한: 이 등식을 사용하여 최대 임대 시간 제한 값을 계산합니다.
- VNN(가상 네트워크 이름) 및 Azure Load Balancer를 사용하여 HADR 솔루션에 연결하는 경우 클러스터가 하나의 서브넷에만 걸쳐 있는 경우에도 연결 문자열에서
MultiSubnetFailover = true를 지정합니다.- 클라이언트에서
MultiSubnetFailover = True를 지원하지 않는 경우RegisterAllProvidersIP = 0및HostRecordTTL = 300을 설정하여 더 짧은 기간 동안 클라이언트 자격 증명을 캐시해야 할 수 있습니다. 하지만 이렇게 하면 DNS 서버에 추가 쿼리가 발생할 수 있습니다.
- 클라이언트에서
- DNN(분산형 네트워크 이름)을 사용하여 HADR 솔루션에 연결하려면 다음 사항을 고려합니다.
MultiSubnetFailover = True를 지원하는 클라이언트 드라이버를 사용해야 하고, 이 매개 변수가 연결 문자열에 있어야 합니다.- 가용성 그룹의 DNN 수신기에 연결할 때 연결 문자열에서 고유한 DNN 포트를 사용합니다.
- 기본 가용성 그룹에 대한 데이터베이스 미러링 연결 문자열을 사용하여 부하 분산 장치 또는 DNN에 대한 필요성을 무시합니다.
- 불일치 I/O가 발생하지 않도록 고가용성 솔루션 배포 전에 VHD의 섹터 크기를 확인합니다. 자세히 알아보려면 KB3009974를 참조하세요.
- SQL Server 데이터베이스 엔진, Always On 가용성 그룹 수신기 또는 장애 조치(failover) 클러스터 인스턴스 상태 프로브가 49,152~65,536(TCP/IP의 기본 동적 포트 범위) 사이의 포트를 사용하도록 구성된 경우 각 포트에 대한 제외를 추가합니다. 이렇게 하면 다른 시스템에 동적으로 동일한 포트가 할당되는 것을 방지할 수 있습니다. 다음 예에서는 포트 59999에 대한 제외를 만듭니다.
netsh int ipv4 add excludedportrange tcp startport=59999 numberofports=1 store=persistent
HADR 체크리스트를 다른 모범 사례와 비교하려면 포괄적인 성능 모범 사례 체크리스트를 참조하세요.
VM 가용성 설정
가동 중지 시간의 영향을 줄이려면 다음 VM 최대 가용성 설정을 고려합니다.
- 가장 짧은 대기 시간을 위해 근접 배치 그룹을 가속화된 네트워킹과 함께 사용합니다.
- 데이터 센터 수준 오류를 방지하기 위해 별도의 가용 영역에, 또는 동일한 데이터 센터 내에서 낮은 대기 시간 중복성을 위해 단일 가용성 집합에 가상 머신 클러스터 노드를 배치합니다.
- 가용성 집합의 VM에 대해 프리미엄 관리형 OS 및 데이터 디스크를 사용합니다.
- 각 애플리케이션 계층을 별도의 가용성 집합으로 구성합니다.
Quorum
2노드 클러스터는 Quorum 리소스 없이 작동하지 않지만 고객은 프로덕션 지원을 위해 Quorum 리소스를 사용해야 합니다. Quorum 리소스가 없는 클러스터는 클러스터 유효성 검사를 통과할 수 없습니다.
기술적으로 3노드 클러스터는 쿼럼 리소스 없이 단일 노드 손실(최대 2개 노드)에서 살아남을 수 있지만 클러스터가 두 노드로 줄어든 후 다른 노드 손실 또는 통신 오류가 있는 경우 클러스터형 리소스가 분할 브레인 시나리오를 방지하기 위해 오프라인으로 전환될 위험이 있습니다. Quorum 리소스를 구성하면 클러스터가 단 하나의 노드만 온라인 상태가 되어 온라인 상태를 지속할 수 있습니다.
디스크 감시는 가장 복원력이 높은 Quorum 옵션이지만 Azure VM 기반 SQL Server에서 디스크 감시를 사용하려면 고가용성 솔루션에 몇 가지 제한 사항을 적용하는 Azure 공유 디스크를 사용해야 합니다. 따라서 Azure 공유 디스크를 사용하여 장애 조치(failover) 클러스터 인스턴스를 구성하는 경우 디스크 감시를 사용하고, 그 외에는 가능한 경우 클라우드 감시를 사용합니다.
다음 표에서는 Azure VM에서 SQL Server에 사용할 수 있는 쿼럼 옵션을 보여줍니다.
| 클라우드 감시 | 디스크 감시 | 파일 공유 감시 | |
|---|---|---|---|
| 지원되는 OS | Windows Server 2016+ | 모두 | 모두 |
- 클라우드 감시는 여러 사이트, 여러 영역 및 여러 지역의 배포에 이상적입니다. 공유 스토리지 클러스터 솔루션을 사용하지 않는 경우 가능한 항상 클라우드 감시를 사용하세요.
- 디스크 감시는 가장 탄력적으로 사용되는 쿼럼 옵션으로, Azure 공유 디스크(또는 공유 SCSI, iSCSI 또는 파이버 채널 SAN과 같은 공유 디스크 솔루션)를 사용하는 모든 클러스터에서 선호됩니다. 클러스터 공유 볼륨을 디스크 감시로 사용할 수 없습니다.
- 파일 공유 감시는 디스크 감시 및 클라우드 감시를 사용할 수 없는 경우에 적합합니다.
시작하려면 클러스터 쿼럼 구성을 참조하세요.
쿼럼 투표
Windows Server 장애 조치(Failover) 클러스터에 참가하는 노드의 쿼럼 투표를 변경할 수 있습니다.
노드 투표 설정을 수정하는 경우 다음 지침을 따르세요.
| Quorum 투표 지침 |
|---|
| 기본적으로 투표가 없는 각 노드에서 시작합니다. 각 노드에는 명시적 타당성을 갖춘 투표만 있어야 합니다. |
| 가용성 그룹의 주 복제본 또는 장애 조치(failover) 클러스터 인스턴스의 기본 설정 소유자를 호스트하는 클러스터 노드에 대한 투표를 사용하도록 설정합니다. |
| 자동 장애 조치(failover) 소유자에 투표를 사용하도록 설정합니다. 자동 장애 조치(failover)로 인해 주 복제본 또는 FCI를 호스팅할 수 있는 각 노드에는 투표가 있어야 합니다. |
| 가용성 그룹에 보조 복제본이 두 개 이상 있는 경우 자동 장애 조치(failover)가 있는 복제본에 대해서만 투표를 사용하도록 설정합니다. |
| 보조 재해 복구 사이트에 있는 노드에 대한 투표를 사용하지 않도록 설정합니다. 기본 사이트에 문제가 없는 경우 보조 사이트의 노드가 클러스터를 오프라인으로 전환하는 의사 결정에 영향을 주지 않아야 합니다. |
| 최소 3개의 쿼럼 투표를 포함하여 투표 수를 홀수로 합니다. 2노드 클러스터에서 필요한 경우 추가 투표를 위해 쿼럼 감시를 추가합니다. |
| 투표 할당 사후 장애 조치(failover)를 다시 평가합니다. 정상 상태의 쿼럼을 지원하지 않는 클러스터 구성에 대해서는 장애 조치(failover)를 수행할 필요가 없습니다. |
연결
가용성 그룹 수신기 또는 장애 조치(failover) 클러스터 인스턴스에 연결하는 온-프레미스 환경과 일치시키려면 SQL Server VM을 동일한 가상 네트워크 내의 여러 서브넷에 배포합니다. 여러 서브넷이 있으면 트래픽을 수신기로 라우팅하기 위해 Azure Load Balancer 또는 분산 네트워크 이름에 대한 추가 종속성이 필요하지 않습니다.
HADR 솔루션을 간소화하려면 가능한 경우 SQL Server VM을 여러 서브넷에 배포합니다. 자세한 내용은 다중 서브넷 AG 및 다중 서브넷 FCI를 참조하세요.
SQL Server VM이 단일 서브넷에 있는 경우 장애 조치(failover) 클러스터 인스턴스와 가용성 그룹 수신기 모두에 대해 VNN(가상 네트워크 이름) 및 Azure Load Balancer 또는 DNN(분산 네트워크 이름)을 구성할 수 있습니다.
분산 네트워크 이름은 사용 가능한 경우 권장되는 연결 옵션입니다.
- 더 이상 부하 분산 장치 리소스를 유지 관리하지 않아도 되므로 엔드투엔드 솔루션이 더욱 강력해집니다.
- 부하 분산 장치 프로브를 제거하면 장애 조치(failover) 기간이 최소화됩니다.
- DNN은 Azure VM의 SQL Server를 사용하여 장애 조치(failover) 클러스터 인스턴스 또는 가용성 그룹 수신기의 프로비저닝 및 관리를 간소화합니다.
다음 제한 사항을 고려하세요.
- 클라이언트 드라이버에서
MultiSubnetFailover=True매개 변수를 지원해야 합니다. - DNN 기능은 Windows Server 2016 이상에서 SQL Server 2016 SP3, SQL Server 2017 CU25 및 SQL Server 2019 CU8부터 사용할 수 있습니다.
자세히 알아보려면 Windows Server 장애 조치(Failover) 클러스터 개요를 참조하세요.
연결을 구성하려면 다음 문서를 참조하세요.
DNN을 사용하는 경우 대부분의 SQL Server 기능이 FCI 및 가용성 그룹에서 투명하게 작동하지만 특별 고려 사항이 필요할 수 있는 특정 기능이 있습니다. 자세한 내용은 FCI 및 DNN 상호 운용성과 AG 및 DNN 상호 운용성을 참조하세요.
팁
연결 문자열을 업데이트할 필요성 없이 향후 서브넷 확장을 지원하기 위해 단일 서브넷에 걸쳐 있는 HADR 솔루션의 경우에도 연결 문자열에서 MultiSubnetFailover 매개 변수를 true로 설정합니다.
하트비트와 임계값
클러스터 하트비트와 임계값 설정을 완화합니다. 기본 하트비트 및 임계값 클러스터 설정은 고도로 조정된 온-프레미스 네트워크에 맞춰 설계되며 클라우드 환경의 대기 시간 증가 가능성을 고려하지 않습니다. 하트비트 네트워크는 UDP 3343으로 유지 관리되며, 이는 TCP보다 안정성이 떨어지고 불완전한 대화가 발생하기 쉽습니다.
따라서 Azure VM 고가용성 솔루션에서 SQL Server에 대한 클러스터 노드를 실행할 때 클러스터 설정을 더 완화된 모니터링 상태로 변경하여 네트워크 대기 또는 장애, Azure 유지 관리 또는 리소스 병목 현상 발생으로 인한 일시적 장애를 방지합니다.
지연 및 임계값 설정은 총 상태 검색에 누적된 영향을 미칩니다. 예를 들어 2초마다 하트비트를 전송하도록 CrossSubnetDelay를 설정하고 CrossSubnetThreshold에서 복구 전 누락된 하트비트를 10개로 설정하면 복구 작업을 수행하기 전에 클러스터의 총 네트워크 허용 오차는 20초가 될 수 있습니다. 일반적으로 자주 하트비트를 계속해서 전송하되 임계값을 더 크게 하는 것이 좋습니다.
일시적인 문제에 대해 더 큰 허용 오차를 제공하면서 합당한 중단 도중 복구를 보장하려면 지연 및 임계값 설정을 아래 표에 자세히 설명된 권장값으로 완화합니다.
| 설정 | Windows Server 2012 이상 | Windows Server 2008 R2 |
|---|---|---|
| SameSubnetDelay | 1초 | 2초 |
| SameSubnetThreshold | 하트비트 40개 | 하트비트 10개(최대) |
| CrossSubnetDelay | 1초 | 2초 |
| CrossSubnetThreshold | 하트비트 40개 | 하트비트 20개(최대) |
PowerShell을 사용하여 클러스터 매개 변수 변경:
(get-cluster).SameSubnetThreshold = 40
(get-cluster).CrossSubnetThreshold = 40
PowerShell을 사용하여 변경 확인:
get-cluster | fl *subnet*
다음을 살펴보세요.
- 이 변경은 즉시 적용되며 클러스터를 다시 시작하거나 리소스가 필요하지 않습니다.
- 동일한 서브넷 값은 서브넷 간 값보다 크지 않아야 합니다.
- SameSubnetThreshold <= CrossSubnetThreshold
- SameSubnetDelay <= CrossSubnetDelay
허용 가능한 가동 중지 시간과 애플리케이션, 비즈니스 요구 사항 및 환경에 따라 정정 작업이 수행될 때까지의 시간을 기준으로 완화된 값을 선택합니다. 기본 Windows Server 2019 값을 초과할 수 없는 경우 가능하면 최소한 이러한 값을 일치시켜야 합니다.
참조를 위해 다음 표에서는 기본값을 자세히 설명합니다.
| 설정 | Windows Server 2019 | Windows Server 2016 | Windows Server 2008 - 2012 R2 |
|---|---|---|---|
| SameSubnetDelay | 1초 | 1초 | 1초 |
| SameSubnetThreshold | 하트비트 20개 | 하트비트 10개 | 하트비트 5개 |
| CrossSubnetDelay | 1초 | 1초 | 1초 |
| CrossSubnetThreshold | 하트비트 20개 | 하트비트 10개 | 하트비트 5개 |
자세한 내용은 장애 조치(failover) 클러스터 네트워크 임계값 튜닝을 참조하세요.
완화된 모니터링
클러스터 하트비트 및 임곗값 설정을 권장 수준으로 튜닝하는 것이 허용 오차로는 부족하고 실제 중단이 아닌 일시적인 문제로 인해 장애 조치(failover)가 계속 표시되는 경우 AG 또는 FCI 모니터링을 더욱 완화적으로 구성할 수 있습니다. 일부 시나리오에서는 작업 수준이 지정된 경우 일정 기간 동안 모니터링을 일시적으로 완화하는 것이 유용할 수 있습니다. 예를 들어 데이터베이스 백업, 인덱스 유지 관리, DBCC CHECKDB 등과 같은 IO 집약적 워크로드를 수행하는 경우 모니터링을 완화할 수 있습니다. 작업이 완료되면 모니터링을 덜 완화된 값으로 설정합니다.
경고
이러한 설정을 변경하면 기본 문제를 덮을 수 있지만 실패 가능성을 제거하는 대신 임시 솔루션으로 사용해야 합니다. 계속해서 기본 문제를 조사 및 해결해야 합니다.
완화된 모니터링을 위해 기본값에서 다음 매개 변수를 늘리고 필요에 따라 조정합니다.
| 매개 변수 | 기본값 | 완화된 값 | Description |
|---|---|---|---|
| Healthcheck 제한 시간 | 30000 | 60000 | 주 복제본 또는 노드의 상태를 확인합니다. 클러스터 리소스 DLL sp_server_diagnostics는 상태 확인 제한 시간 임곗값의 1/3에 해당하는 간격으로 결과를 반환합니다. sp_server_diagnostics가 느리거나 정보를 반환하지 않는 경우 리소스 DLL은 리소스가 응답하지 않고 자동 장애 조치(failover)를 시작하기로 결정하기 전에 상태 확인 제한 시간 임곗값의 전체 간격 동안 대기합니다. |
| 오류 상태 수준 | 3 | 2 | 자동 장애 조치(failover)를 트리거하는 조건입니다. 가장 낮은 제한 수준 1에서 가장 높은 제한 수준 5까지의 다섯 가지 오류 상태 수준이 있습니다. |
Transact-SQL(T-SQL)을 사용하여 AG 및 FCI 모두에 대한 상태 검사 및 오류 조건을 수정합니다.
가용성 그룹:
ALTER AVAILABILITY GROUP AG1 SET (HEALTH_CHECK_TIMEOUT =60000);
ALTER AVAILABILITY GROUP AG1 SET (FAILURE_CONDITION_LEVEL = 2);
장애 조치(Failover) 클러스터 인스턴스:
ALTER SERVER CONFIGURATION SET FAILOVER CLUSTER PROPERTY HealthCheckTimeout = 60000;
ALTER SERVER CONFIGURATION SET FAILOVER CLUSTER PROPERTY FailureConditionLevel = 2;
가용성 그룹에 따라 다음 권장 매개 변수로 시작하고 필요에 따라 조정합니다.
| 매개 변수 | 기본값 | 완화된 값 | Description |
|---|---|---|---|
| 임대 시간 제한 | 20000 | 40,000 | 스플릿 브레인을 방지합니다. |
| 세션 제한 시간 | 10000 | 20000 | 복제본 간의 통신 문제를 검사합니다. 세션 제한 시간은 가용성 복제본이 연결이 실패한 것으로 간주되기 전에 연결된 복제본에서 ping 응답을 받기 위해 기다리는 최대 시간(초)을 제어하는 복제본 속성입니다. 기본적으로 복제본은 ping 응답을 받기 위해 10초 동안 기다립니다. 이 복제본 속성은 지정된 보조 복제본과 가용성 그룹의 주 복제본 사이의 연결에만 적용됩니다. |
| Max failures in specified period | 2 | 6 | 여러 노드 오류 내에서 클러스터된 리소스의 무한한 이동을 방지하는 데 사용됩니다. 값이 너무 낮으면 가용성 그룹이 오류 상태가 될 수 있습니다. 값이 너무 낮으면 AG가 오류 상태가 될 수 있으므로 값을 높여 성능 문제로 인한 짧은 중단을 방지해야 합니다. |
변경 전에 다음 사항을 고려합니다.
- 해당 기본값 아래로 제한 시간 값을 줄이지 않습니다.
Lease timeout < (2 * SameSubnetThreshold * SameSubnetDelay)등식을 사용하여 최대 임대 시간 초과 값을 계산합니다.
40초부터 시작합니다. 이전에 권장되었던 완화된SameSubnetThreshold및SameSubnetDelay값을 사용하는 경우 임대 시간 제한 값이 80초를 초과해서는 안 됩니다.- 동기-커밋 복제본의 경우 session-timeout을 높은 값으로 변경하면 HADR_sync_commit 대기가 증가할 수 있습니다.
임대 시간 제한
장애 조치(Failover) 클러스터 관리자를 사용하여 가용성 그룹에 대한 임대 시간 제한 설정을 수정합니다. 자세한 단계는 SQL Server 가용성 그룹 임대 상태 검사 설명서를 참조하세요.
세션 제한 시간
Transact-SQL(T-SQL)을 사용하여 가용성 그룹에 대한 세션 시간 초과를 수정합니다.
ALTER AVAILABILITY GROUP AG1
MODIFY REPLICA ON 'INSTANCE01' WITH (SESSION_TIMEOUT = 20);
Max failures in specified period
장애 조치(failover) 클러스터 관리자를 사용하여 Max failures in specified period 값을 수정합니다.
- 탐색 창에서 역할을 선택합니다.
- 역할에서 클러스터된 리소스를 마우스 오른쪽 단추로 클릭하고 속성을 선택합니다.
- 장애 조치(Failover) 탭을 선택하고 Max failures in specified period 값을 원하는 대로 늘립니다.
리소스 한계
VM 또는 디스크 한계로 인해 리소스 병목 현상이 발생하고 클러스터의 상태에 영향을 미치며 상태 검사를 방해할 수 있습니다. 리소스 한계 문제가 발생하는 경우 다음을 고려합니다.
- OS, 드라이버 및 SQL Server가 최신 빌드인지 확인합니다.
- Azure Virtual Machines의 SQL Server 성능 가이드라인에서 설명하는 것과 같이 Azure VM 환경에서 SQL Server 최적화
- 리소스 한계를 초과하지 않고 사용률을 줄이기 위해 워크로드를 줄이거나 분산
- 다음과 같은 경우 SQL Server 워크로드 조정
- 인덱스 추가/최적화
- 필요한 경우 및 가능한 경우 전체 검사를 통해 통계 업데이트
- 리소스 관리자(SQL Server 2014부터, 엔터프라이즈 전용)와 같은 기능을 사용하여 백업 또는 인덱스 유지 관리와 같은 특정 워크로드 동안 리소스 사용률을 제한합니다.
- 워크로드의 수요를 충족하거나 초과하도록 제한이 더 높은 VM 또는 디스크로 이동합니다.
네트워킹
트래픽을 HADR 솔루션으로 라우팅하는 Azure Load Balancer 또는 DNN(분산 네트워크 이름)에 대한 종속성을 방지하기 위해 가능한 경우 SQL Server VM을 여러 서브넷에 배포합니다.
서버당 단일 NIC(클러스터 노드)를 사용합니다. Azure 네트워킹에는 물리적 중복성이 있으므로 Azure 가상 머신 게스트 클러스터에서 추가 NIC가 필요하지 않습니다. 클러스터 유효성 검사 보고서는 노드가 단일 네트워크에서만 연결할 수 있다는 경고를 표시합니다. Azure 가상 머신 게스트 장애 조치(failover) 클러스터에서는 이 경고를 무시할 수 있습니다.
특정 VM에 대한 대역폭 제한은 NIC 간에 공유되며, 추가 NIC를 추가하더라도 Azure VM 기반 SQL Server에 대한 가용성 그룹 성능이 향상되지 않습니다. 따라서 두 번째 NIC를 추가할 필요가 없습니다.
Azure에서 RFC를 준수하지 않는 DHCP 서비스를 사용할 경우 특정 장애 조치 클러스터 구성을 만들 수 없게 됩니다. 이 오류는 클러스터 네트워크 이름에 중복 IP 주소(예: 클러스터 노드 중 하나와 IP 주소가 같음)가 할당되기 때문에 발생합니다. Windows 장애 조치 클러스터 기능에 따라 달라지는 가용성 그룹을 사용하는 경우 해당 문제가 발생합니다.
노드가 2개인 클러스터를 만들고 온라인 상태로 만드는 상황을 고려해 보십시오.
- 클러스터가 온라인 상태가 되면 다음 NODE1은 클러스터 네트워크 이름으로 동적 할당된 IP 주소를 요청합니다.
- DHCP 서비스는 요청이 NODE1 자체에서 나온다는 것을 인식하기 때문에 DHCP 서비스는 NODE1의 자체 IP 주소 이외에는 IP 주소를 제공하지 않습니다.
- Windows는 NODE1과 장애 조치 클러스터 네트워크 이름에 중복된 주소가 할당된 것으로 감지하므로, 기본 클러스터 그룹이 온라인 상태가 될 수 없습니다.
- 기본 클러스터 그룹은 NODE2로 이동합니다. NODE2는 NODE1의 IP 주소를 클러스터 IP 주소로 취급하여 기본 클러스터 그룹이 온라인 상태가 됩니다.
- NODE2가 NODE1에 연결을 시도하면 NODE1로 보내지는 패킷이 NODE1의 IP 주소 자체로 향하게 되므로 NODE2에서 출발 자체를 할 수 없습니다. 따라서 NODE2는 NODE1에 연결할 수 없고 쿼럼을 잃고 클러스터를 닫게 됩니다.
- NODE1은 NODE2로 패킷을 보낼 수 있지만, NODE2는 응답할 수 없습니다. NODE1도 쿼럼을 잃고 클러스터를 닫습니다.
클러스터 네트워크 이름을 온라인 상태로 만들고 IP 주소를 Azure Load Balancer에 추가하기 위해 사용되지 않는 고정 IP 주소를 클러스터 네트워크 이름에 할당하면 이 시나리오를 방지할 수 있습니다.
SQL Server 데이터베이스 엔진, Always On 가용성 그룹 수신기, 장애 조치(failover) 클러스터 인스턴스 상태 프로브, 데이터베이스 미러링 엔드포인트, 클러스터 코어 IP 리소스 또는 다른 SQL 리소스가 49,152~65,536(TCP/IP의 기본 동적 포트 범위) 사이의 포트를 사용하도록 구성된 경우 각 포트에 대한 제외를 추가합니다. 이렇게 하면 다른 시스템 프로세스에 동적으로 동일한 포트가 할당되는 것을 방지할 수 있습니다. 다음 예에서는 포트 59999에 대한 제외를 만듭니다.
netsh int ipv4 add excludedportrange tcp startport=59999 numberofports=1 store=persistent
포트가 사용되지 않을 때 포트 제외를 구성하는 것이 중요합니다. 그렇지 않으면 "프로세스는 다른 프로세스에서 사용 중이므로 파일에 액세스할 수 없습니다."와 같은 메시지를 나타내며 명령이 실패합니다.
제외가 올바르게 구성되었는지 확인하려면 netsh int ipv4 show excludedportrange tcp 명령을 사용합니다.
AG 역할 IP 프로브 포트에 대해 이 제외를 설정하면 상태가 10048인 이벤트 ID: 1069와 같은 이벤트를 방지해야 합니다. 이 이벤트는 다음 메시지를 나타내며 Windows 장애 조치 클러스터 이벤트에서 볼 수 있습니다.
Cluster resource '<IP name in AG role>' of type 'IP Address' in cluster role '<AG Name>' failed.
An Event ID: 1069 with status 10048 can be identified from cluster logs with events like:
Resource IP Address 10.0.1.0 called SetResourceStatusEx: checkpoint 5. Old state OnlinePending, new state OnlinePending, AppSpErrorCode 0, Flags 0, nores=false
IP Address <IP Address 10.0.1.0>: IpaOnlineThread: **Listening on probe port 59999** failed with status **10048**
Status [**10048**](/windows/win32/winsock/windows-sockets-error-codes-2) refers to: **This error occurs** if an application attempts to bind a socket to an **IP address/port that has already been used** for an existing socket.
이 오류는 프로브 포트로 정의된 동일한 포트를 사용하는 내부 프로세스로 인해 발생할 수 있습니다. 프로브 포트는 Azure Load Balancer에서 백 엔드 풀 인스턴스의 상태를 확인하는 데 사용됩니다.
상태 프로브가 백 엔드 인스턴스에서 응답을 얻지 못하면 상태 프로브가 다시 성공할 때까지 새 연결이 해당 백 엔드 인스턴스로 전송되지 않습니다.
알려진 문제
일반적으로 알려진 문제와 오류에 대한 해결 방법을 검토합니다.
리소스 경합(특히 IO)으로 인해 장애 조치(failover) 발생
VM에 대한 I/O 또는 CPU 용량이 소진되면 가용성 그룹이 장애 조치(failover)될 수 있습니다. 장애 조치(failover) 직전에 발생하는 경합을 식별하는 것이 자동 장애 조치(failover)의 원인을 식별하는 가장 신뢰할 수 있는 방법입니다. Azure 가상 머신를 모니터링하여 스토리지 IO 사용률 메트릭을 살펴보고 VM 또는 디스크 수준 대기 시간을 파악합니다.
다음 단계에 따라 Azure VM 전체 IO 소모 이벤트를 검토하세요.
SQL 가상 머신이 아닌 Azure Portal에서 가상 머신으로 이동합니다.
모니터링에서 메트릭을 선택하여 메트릭 페이지를 엽니다.
로컬 시간을 선택하여 관심 있는 시간 범위와 표준 시간대(VM 로컬 또는 UTC/GMT)를 지정합니다.
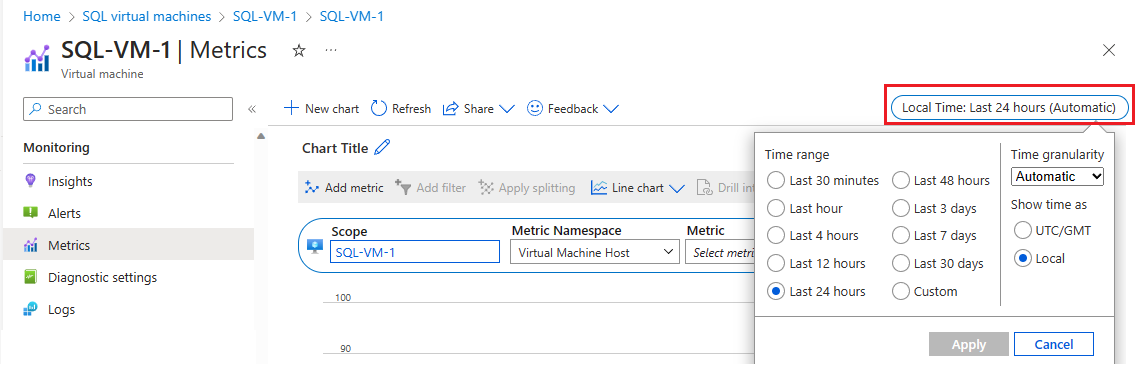
메트릭 추가를 선택해서 다음 두 메트릭을 추가하여 그래프를 봅니다.
- VM 캐시된 대역폭 사용률
- VM 캐시되지 않은 대역폭 소비한 백분율
Azure VM HostEvents로 인해 장애 조치(failover) 발생
Azure VM HostEvent로 인해 가용성 그룹이 장애 조치(failover)될 수 있습니다. Azure VM HostEvent가 장애 조치(failover)를 일으켰다고 생각되는 경우 Azure Monitor 활동 로그와 Azure VM Resource Health 개요를 확인할 수 있습니다.
Azure Monitor 활동 로그는 구독 수준 이벤트에 대한 인사이트를 제공하는 Azure의 플랫폼 로그입니다. 활동 로그에는 리소스가 수정되거나 가상 머신이 시작되는 시기와 같은 정보가 포함됩니다. Azure Portal에서 활동 로그를 보거나 PowerShell 및 Azure CLI를 사용하여 항목을 검색할 수 있습니다.
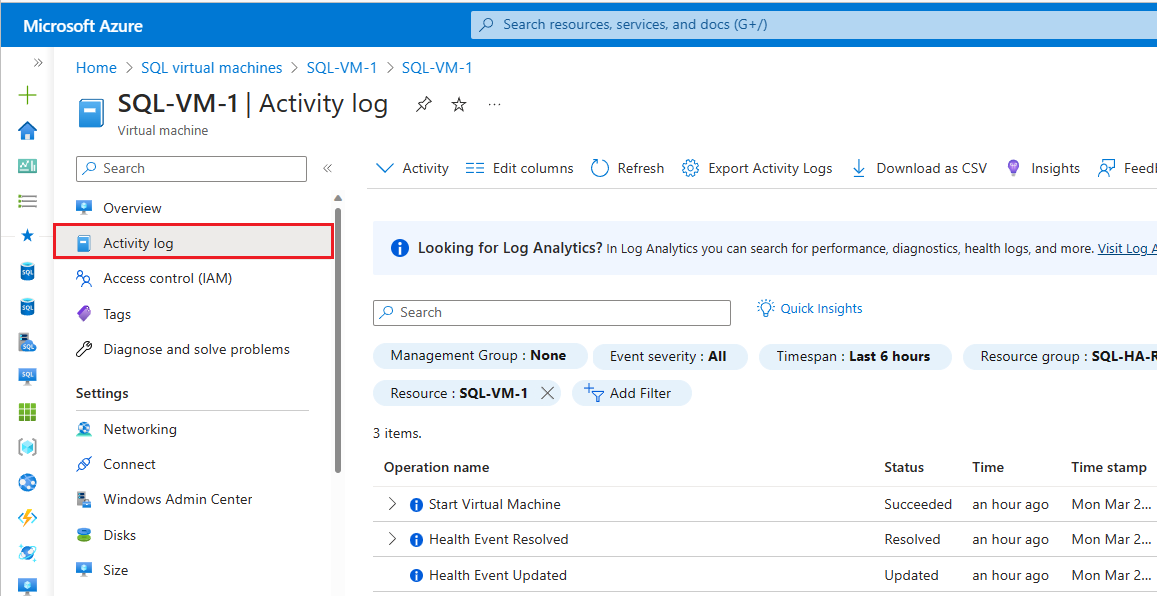
Azure Monitor 활동 로그를 확인하려면 다음 단계를 수행합니다.
Azure Portal에서 가상 머신으로 이동합니다.
가상 머신 창에서 활동 로그를 선택합니다.
시간 범위를 선택하고 가용성 그룹이 장애 조치(failover)된 기간을 선택합니다. 적용을 선택합니다.
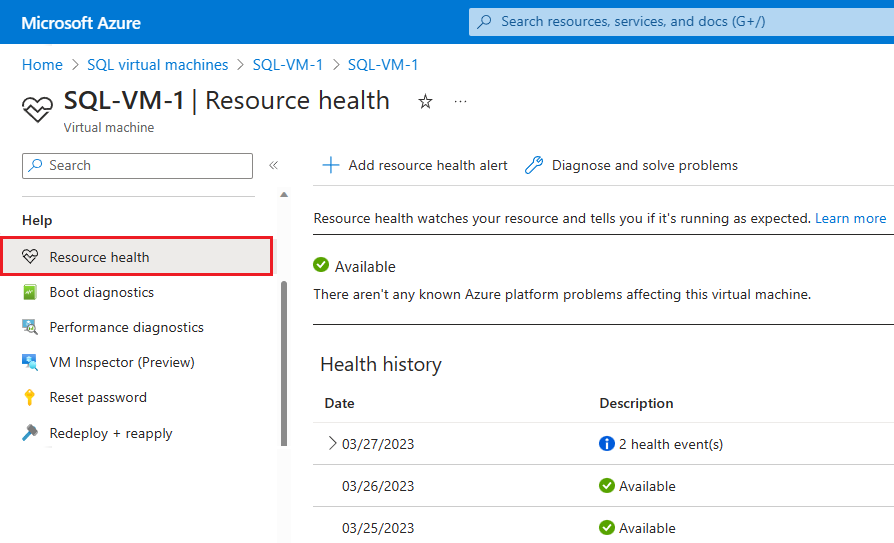
Azure에 플랫폼에서 시작된 사용 불가의 근본 원인에 대한 추가 정보가 있는 경우 해당 정보는 최초 사용 불가 후 최대 72시간까지 Azure VM - Resource Health 개요요 페이지에 게시될 수 있습니다. 이 정보는 현재 가상 머신에만 사용할 수 있습니다.
- Azure Portal에서 가상 머신으로 이동합니다.
- 상태 창에서 Resource Health를 선택합니다.
이 페이지의 상태 이벤트를 기반으로 경고를 구성할 수도 있습니다.
멤버 자격에서 제거된 클러스터 노드
Windows 클러스터 하트비트 및 임계값 설정이 환경에 비해 너무 적극적인 경우 시스템 이벤트 로그에 다음 메시지가 자주 표시될 수 있습니다.
Error 1135
Cluster node 'Node1' was removed from the active failover cluster membership.
The Cluster service on this node may have stopped. This could also be due to the node having
lost communication with other active nodes in the failover cluster. Run the Validate a
Configuration Wizard to check your network configuration. If the condition persists, check
for hardware or software errors related to the network adapters on this node. Also check for
failures in any other network components to which the node is connected such as hubs, switches, or bridges.
자세한 내용은 이벤트 ID 1135 클러스터 문제 해결을 참조하세요.
임대 만료/임대가 더 이상 유효하지 않음
모니터링이 환경에 비해 너무 적극적인 경우 가용성 그룹 또는 FCI 재시작, 오류 또는 장애 조치(failover)가 자주 발생할 수 있습니다. 추가로 가용성 그룹의 경우 SQL Server 오류 로그에 다음 메시지가 표시될 수 있습니다.
Error 19407: The lease between availability group 'PRODAG' and the Windows Server Failover Cluster has expired.
A connectivity issue occurred between the instance of SQL Server and the Windows Server Failover Cluster.
To determine whether the availability group is failing over correctly, check the corresponding availability group
resource in the Windows Server Failover Cluster
Error 19419: The renewal of the lease between availability group '%.*ls' and the Windows Server Failover Cluster
failed because the existing lease is no longer valid.
연결 제한 시간
가용성 그룹 환경에 세션 시간 초과가 너무 적극적인 경우 다음과 같은 메시지가 자주 표시될 수 있습니다.
Error 35201: A connection timeout has occurred while attempting to establish a connection to availability
replica 'replicaname' with ID [availability_group_id]. Either a networking or firewall issue exists,
or the endpoint address provided for the replica is not the database mirroring endpoint of the host server instance.
Error 35206
A connection timeout has occurred on a previously established connection to availability
replica 'replicaname' with ID [availability_group_id]. Either a networking or a firewall issue
exists, or the availability replica has transitioned to the resolving role.
그룹이 장애 조치(failover)되지 않음
Maximum Failures in the Specified Period 값이 너무 낮고 일시적인 문제로 인해 간헐적으로 오류가 발생하는 경우 가용성 그룹이 오류 상태가 될 수 있습니다. 더 많은 일시적 오류를 허용하려면 이 값을 늘려야 합니다.
Not failing over group <Resource name>, failoverCount 3, failoverThresholdSetting <Number>, computedFailoverThreshold 2.
이벤트 1196 - 네트워크 이름 리소스가 연결된 DNS 이름을 등록하지 못했습니다.
- 각 클러스터 노드의 NIC 설정을 확인하여 외부 DNS 레코드가 없는지 확인합니다.
- 클러스터에 대한 A 레코드가 내부 DNS 서버에 있는지 확인합니다. A 레코드가 없는 경우 DNS 서버에서 클러스터 액세스 제어 개체에 대한 새 A 레코드를 수동으로 만들고 인증된 사용자가 동일한 소유자 이름으로 DNS 레코드를 업데이트하도록 허용을 선택합니다.
- IP 리소스가 있는 리소스 "클러스터 이름"을 오프라인으로 전환하고 수정합니다.
이벤트 157 - 디스크가 갑자기 제거되었습니다.
이러한 상황은 AG 환경에 대해 스토리지 공간 속성 AutomaticClusteringEnabled가 True로 설정된 경우 발생할 수 있습니다. False으로 변경합니다. 또한 스토리지 옵션이 있는 유효성 검사 보고서를 실행하면 디스크 다시 설정 또는 예상치 못한 제거 이벤트가 트리거될 수 있습니다. 스토리지 시스템 제한은 예기치 않은 디스크 제거 이벤트를 트리거할 수도 있습니다.
이벤트 1206- 클러스터 네트워크 이름 리소스를 온라인 상태로 전환할 수 없습니다.
리소스에 연결된 컴퓨터 개체를 도메인에서 업데이트할 수 없습니다. 도메인에 대한 적절한 권한이 있는지 확인합니다.
Windows 클러스터링 오류
통신을 위해 열린 클러스터 서비스 포트가 없는 경우 Windows 장애 조치(failover) 클러스터 또는 해당 연결을 설정하는 동안 문제가 발생할 수 있습니다.
Windows Server 2019를 사용 중이고 Windows 클러스터 IP가 표시되지 않는 경우는 SQL Server 2019에서만 지원되는 분산 네트워크 이름을 구성한 것입니다. 이전 버전의 SQL Server가 있는 경우 네트워크 이름을 사용하여 클러스터를 제거하고 다시 만들 수 있습니다.
여기에서 기타 Windows 장애 조치(failover) 클러스터링 이벤트 오류 및 해결 방법을 검토하세요.
다음 단계
자세한 내용은 다음을 참조하세요.
피드백
출시 예정: 2024년 내내 콘텐츠에 대한 피드백 메커니즘으로 GitHub 문제를 단계적으로 폐지하고 이를 새로운 피드백 시스템으로 바꿀 예정입니다. 자세한 내용은 다음을 참조하세요. https://aka.ms/ContentUserFeedback
다음에 대한 사용자 의견 제출 및 보기