Azure Data Factory 또는 Synapse 파이프라인을 사용하여 Azure Synapse Analytics에서 데이터 복사 및 변환
적용 대상: Azure Data Factory Azure Synapse Analytics
Azure Data Factory Azure Synapse Analytics
팁
기업용 올인원 분석 솔루션인 Microsoft Fabric의 Data Factory를 사용해 보세요. Microsoft Fabric은 데이터 이동부터 데이터 과학, 실시간 분석, 비즈니스 인텔리전스 및 보고에 이르기까지 모든 것을 다룹니다. 무료로 새 평가판을 시작하는 방법을 알아봅니다!
이 문서에서는 Azure Data Factory 또는 Synapse 파이프라인의 복사 작업을 사용하여 Azure Synapse Analytics 간에 데이터를 복사하고 Data Flow를 사용하여 Azure Data Lake Storage Gen2에서 데이터를 변환하는 방법을 설명합니다. Azure Data Factory에 대해 자세히 알아보려면 소개 문서를 참조하세요.
지원되는 기능
이 Azure Synapse Analytics 커넥터는 다음 기능에 대해 지원됩니다.
| 지원되는 기능 | IR | 관리형 프라이빗 엔드포인트 |
|---|---|---|
| 복사 작업(원본/싱크) | ① ② | ✓ |
| 매핑 데이터 흐름(원본/싱크) | ① | ✓ |
| 조회 작업 | ① ② | ✓ |
| GetMetadata 작업 | ① ② | ✓ |
| 스크립트 작업 | ① ② | ✓ |
| 저장 프로시저 작업 | ① ② | ✓ |
① Azure 통합 런타임 ② 자체 호스팅 통합 런타임
복사 작업의 경우 이 Azure Synapse Analytics 커넥터는 다음과 같은 기능을 지원합니다.
- 서비스 주체 또는 Azure 리소스에 대한 관리 ID를 통해 SQL 인증 및 Microsoft Entra 애플리케이션 토큰 인증을 사용하여 데이터를 복사합니다.
- 원본으로 SQL 쿼리 또는 저장 프로시저를 사용하여 데이터를 검색합니다. 또한 Azure Synapse Analytics 원본에서 병렬 복사를 선택할 수도 있습니다. 자세한 내용은 Azure Synapse Analytics의 병렬 복사 섹션을 참조하세요.
- 싱크로 COPY 문, PolyBase 또는 대량 삽입을 사용하여 데이터를 로드합니다. 더 나은 복사 성능을 위해 COPY 문 또는 PolyBase를 권장합니다. 커넥터는 원본 스키마를 기준으로 하지 않는 경우 DISTRIBUTION = ROUND_ROBIN을 사용하여 대상 테이블을 자동으로 만드는 것을 지원합니다.
Important
Azure Integration Runtime을 사용하여 데이터를 복사하는 경우, Azure 서비스가 논리 SQL Server에 액세스할 수 있도록 서버 수준 방화벽 규칙을 구성합니다. 자체 호스팅 통합 런타임을 사용하여 데이터를 복사하는 경우 적절한 IP 범위를 허용하도록 방화벽을 구성합니다. 이 범위에는 Azure Synapse Analytics에 연결하는 데 사용되는 머신 IP가 포함됩니다.
시작하기
팁
최상의 성능을 얻으려면 PolyBase 또는 COPY 문을 사용하여 Azure Synapse Analytics에 데이터를 로드합니다. PolyBase를 사용하여 Azure Synapse Analytics에 데이터 로드 및 COPY 문을 사용하여 Azure Synapse Analytics에 데이터 로드 섹션에 자세한 내용이 있습니다. 사용 사례가 있는 연습은 Azure Data Factory를 통해 Azure Synapse Analytics에 15분 이내 1TB 로드를 참조하세요.
파이프라인에 복사 작업을 수행하려면 다음 도구 또는 SDK 중 하나를 사용하면 됩니다.
UI를 사용하여 Azure Synapse Analytics 연결된 서비스 만들기
다음 단계를 사용하여 Azure Portal UI에서 Azure Synapse Analytics 연결된 서비스를 만듭니다.
Azure Data Factory 또는 Synapse 작업 영역에서 관리 탭으로 이동하여 연결된 서비스를 선택하고 새로 만들기를 클릭합니다.
Synapse를 검색하고 Azure Synapse Analytics 커넥터를 선택합니다.
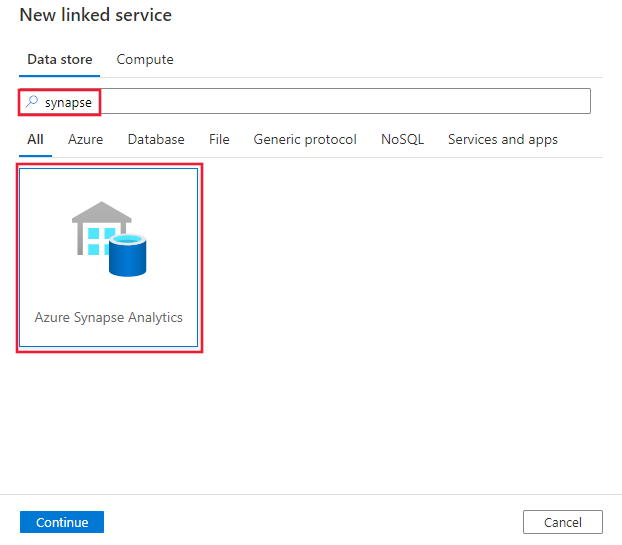
서비스 세부 정보를 구성하고, 연결을 테스트하고, 새로운 연결된 서비스를 만듭니다.
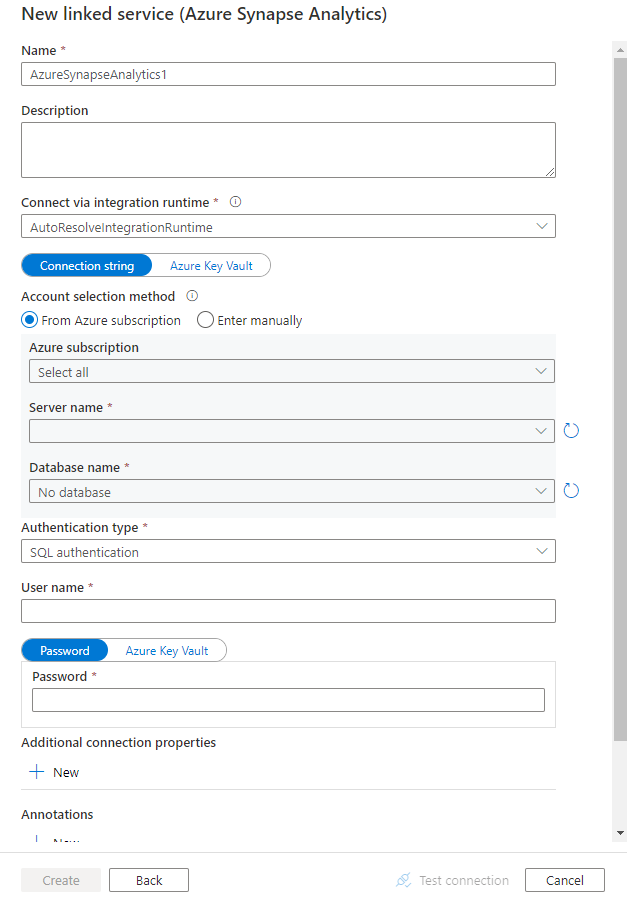
커넥터 구성 세부 정보
다음 섹션에서는 Azure Synapse Analytics 커넥터와 관련된 Data Factory 및 Synapse 파이프라인 엔터티를 정의하는 속성에 대해 자세히 설명합니다.
연결된 서비스 속성
이러한 일반 속성은 Azure Synapse Analytics 연결된 서비스에 대해 지원됩니다.
| 속성 | 설명 | 필수 |
|---|---|---|
| type | type 속성은 AzureSqlDW로 설정해야 합니다. | 예 |
| connectionString | connectionString 속성에 대해 Azure Synapse Analytics 인스턴스에 연결하는 데 필요한 정보를 지정합니다. 이 필드를 SecureString으로 표시하여 안전하게 저장합니다. 암호/서비스 주체 키를 Azure Key Vault에 넣고, SQL 인증인 경우 연결 문자열에서 password 구성을 끌어올 수도 있습니다. 자세한 내용은 표 아래의 JSON 예제 및 Azure Key Vault에 자격 증명 저장 문서를 참조하세요. |
예 |
| azureCloudType | 서비스 주체 인증의 경우 Microsoft Entra 애플리케이션이 등록된 Azure 클라우드 환경의 형식을 지정합니다. 허용되는 값은 AzurePublic, AzureChina, AzureUsGovernment 및 AzureGermany입니다. 기본적으로 데이터 팩터리 또는 Synapse 파이프라인의 클라우드 환경이 사용됩니다. |
아니요 |
| connectVia | 데이터 저장소에 연결하는 데 사용할 통합 런타임입니다. Azure Integration Runtime 또는 자체 호스팅 통합 런타임을 사용할 수 있습니다(데이터 저장소가 프라이빗 네트워크에 있는 경우). 지정하지 않으면 기본 Azure Integration Runtime을 사용합니다. | 아니요 |
다른 인증 형식의 경우 각각의 특정 속성, 필수 구성 요소 및 JSON 샘플에 대한 다음 섹션을 참조하세요.
팁
Azure Portal의 Azure Synapse에서 서버리스 SQL 풀에 대한 연결된 서비스를 만드는 경우:
- 계정 선택 방법에서 수동으로 입력을 선택합니다.
- 서버리스 엔드포인트의 정규화된 도메인 이름을 붙여넣습니다. 서버리스 SQL 엔드포인트 아래의 속성에서 Synapse 작업 영역에 대한 Azure Portal 개요 페이지에서 찾을 수 있습니다. 예:
myserver-ondemand.sql-azuresynapse.net. - 데이터베이스 이름의 경우 서버리스 SQL 풀에 데이터베이스 이름을 입력합니다.
팁
"UserErrorFailedToConnectToSqlServer" 오류 코드 및 "데이터베이스에 대한 세션 제한이 XXX이고 이에 도달했습니다."와 같은 메시지가 있는 오류가 발생하면 연결 문자열에 Pooling=false를 추가하고 다시 시도하세요.
SQL 인증
SQL 인증 인증 유형을 사용하려면 이전 섹션에서 설명한 일반 속성을 지정합니다.
SQL 인증을 사용하는 연결된 서비스 예제
{
"name": "AzureSqlDWLinkedService",
"properties": {
"type": "AzureSqlDW",
"typeProperties": {
"connectionString": "Server=tcp:<servername>.database.windows.net,1433;Database=<databasename>;User ID=<username>@<servername>;Password=<password>;Trusted_Connection=False;Encrypt=True;Connection Timeout=30"
},
"connectVia": {
"referenceName": "<name of Integration Runtime>",
"type": "IntegrationRuntimeReference"
}
}
}
Azure Key Vault의 암호:
{
"name": "AzureSqlDWLinkedService",
"properties": {
"type": "AzureSqlDW",
"typeProperties": {
"connectionString": "Server=tcp:<servername>.database.windows.net,1433;Database=<databasename>;User ID=<username>@<servername>;Trusted_Connection=False;Encrypt=True;Connection Timeout=30",
"password": {
"type": "AzureKeyVaultSecret",
"store": {
"referenceName": "<Azure Key Vault linked service name>",
"type": "LinkedServiceReference"
},
"secretName": "<secretName>"
}
},
"connectVia": {
"referenceName": "<name of Integration Runtime>",
"type": "IntegrationRuntimeReference"
}
}
}
서비스 주체 인증
서비스 주체 인증을 사용하려면 앞 섹션에서 설명한 일반 속성 외에 다음 속성을 지정합니다.
| 속성 | 설명 | 필수 |
|---|---|---|
| servicePrincipalId | 애플리케이션의 클라이언트 ID를 지정합니다. | 예 |
| servicePrincipalKey | 애플리케이션의 키를 지정합니다. 이 필드를 SecureString으로 표시하여 안전하게 저장하거나, Azure Key Vault에 저장된 비밀을 참조합니다. | 예 |
| 테넌트 | 애플리케이션이 있는 테넌트 정보(도메인 이름 또는 테넌트 ID)를 지정합니다. Azure Portal의 오른쪽 위 모서리에 마우스를 이동하여 검색할 수 있습니다. | 예 |
또한 아래 단계를 수행해야 합니다.
Azure Portal에서 Microsoft Entra 애플리케이션을 만듭니다. 애플리케이션 이름 및 연결된 서비스를 정의하는 다음 값을 적어 둡니다.
- 애플리케이션 ID
- 애플리케이션 키
- 테넌트 ID
아직 수행하지 않은 경우 Azure Portal에서 서버에 대해 Microsoft Entra 관리자를 프로비전합니다. Microsoft Entra 관리자는 Microsoft Entra 사용자 또는 Microsoft Entra 그룹일 수 있습니다. 관리 ID를 가진 그룹에 관리자 역할을 부여하는 경우 3단계 및 4단계를 건너뛰세요. 관리자는 데이터베이스에 대한 전체 액세스 권한을 가집니다.
서비스 주체에 대한 포함된 데이터베이스 사용자를 만듭니다. 최소한 ALTER ANY USER 권한이 있는 Microsoft Entra ID를 사용하여 SSMS 등의 도구를 통해 데이터를 복사하려는 데이터 웨어하우스에 연결합니다. 다음 T-SQL을 실행합니다.
CREATE USER [your_application_name] FROM EXTERNAL PROVIDER;일반적으로 SQL 사용자나 기타 사용자에 대해 수행하듯이 서비스 주체에 필요한 권한을 부여합니다. 다음 코드를 실행하거나 여기서 추가 옵션을 참조합니다. PolyBase를 사용하여 데이터를 로드하려는 경우 필요한 데이터베이스 권한을 알아보세요.
EXEC sp_addrolemember db_owner, [your application name];Azure Data Factory 또는 Synapse 작업 영역에서 Azure Synapse Analytics 연결된 서비스를 구성합니다.
서비스 주체 인증을 사용하는 연결된 서비스 예제
{
"name": "AzureSqlDWLinkedService",
"properties": {
"type": "AzureSqlDW",
"typeProperties": {
"connectionString": "Server=tcp:<servername>.database.windows.net,1433;Database=<databasename>;Connection Timeout=30",
"servicePrincipalId": "<service principal id>",
"servicePrincipalKey": {
"type": "SecureString",
"value": "<service principal key>"
},
"tenant": "<tenant info, e.g. microsoft.onmicrosoft.com>"
},
"connectVia": {
"referenceName": "<name of Integration Runtime>",
"type": "IntegrationRuntimeReference"
}
}
}
Azure 리소스 인증을 위한 시스템이 할당한 관리 ID
데이터 팩터리 또는 Synapse 작업 영역은 리소스를 나타내는 Azure 리소스의 시스템이 할당한 관리 ID와 연결할 수 있습니다. Azure Synapse Analytics 인증에 이 관리 ID를 사용할 수 있습니다. 지정된 리소스는 이 ID를 사용하여 데이터 웨어하우스의 데이터에 액세스하고 복사할 수 있습니다.
시스템이 할당한 관리 ID 인증을 사용하려면 이전 섹션에서 설명한 일반 속성을 지정하고 다음 단계를 수행합니다.
아직 수행하지 않은 경우 Azure Portal에서 서버에 대해 Microsoft Entra 관리자를 프로비전합니다. Microsoft Entra 관리자는 Microsoft Entra 사용자 또는 Microsoft Entra 그룹일 수 있습니다. 시스템이 할당한 관리 ID를 사용하는 그룹에 관리자 역할을 부여하는 경우 3단계 및 4단계를 건너뜁니다. 관리자는 데이터베이스에 대한 전체 액세스 권한을 가집니다.
시스템이 할당한 관리 ID에 대해 포함된 데이터베이스 사용자를 만듭니다. 최소한 ALTER ANY USER 권한이 있는 Microsoft Entra ID를 사용하여 SSMS 등의 도구를 통해 데이터를 복사하려는 데이터 웨어하우스에 연결합니다. 다음 T-SQL을 실행합니다.
CREATE USER [your_resource_name] FROM EXTERNAL PROVIDER;SQL 사용자 및 다른 사용자에 대해 일반적으로 수행하는 것처럼 시스템이 할당한 관리 ID에 필요한 권한을 부여합니다. 다음 코드를 실행하거나 여기서 추가 옵션을 참조합니다. PolyBase를 사용하여 데이터를 로드하려는 경우 필요한 데이터베이스 권한을 알아보세요.
EXEC sp_addrolemember db_owner, [your_resource_name];Azure Synapse Analytics 연결된 서비스를 구성합니다.
예제:
{
"name": "AzureSqlDWLinkedService",
"properties": {
"type": "AzureSqlDW",
"typeProperties": {
"connectionString": "Server=tcp:<servername>.database.windows.net,1433;Database=<databasename>;Connection Timeout=30"
},
"connectVia": {
"referenceName": "<name of Integration Runtime>",
"type": "IntegrationRuntimeReference"
}
}
}
사용자가 할당한 관리 ID 인증
데이터 팩터리 또는 Synapse 작업 영역은 리소스를 나타내는 Azure 리소스의 사용자가 할당한 관리 ID와 연결할 수 있습니다. Azure Synapse Analytics 인증에 이 관리 ID를 사용할 수 있습니다. 지정된 리소스는 이 ID를 사용하여 데이터 웨어하우스의 데이터에 액세스하고 복사할 수 있습니다.
사용자가 할당한 관리 ID를 사용하려면 앞 섹션에서 설명한 일반 속성 외에 다음 속성을 지정합니다.
| 속성 | 설명 | 필수 |
|---|---|---|
| credentials | 사용자가 할당한 관리 ID를 자격 증명 개체로 지정합니다. | 예 |
또한 아래 단계를 수행해야 합니다.
아직 수행하지 않은 경우 Azure Portal에서 서버에 대해 Microsoft Entra 관리자를 프로비전합니다. Microsoft Entra 관리자는 Microsoft Entra 사용자 또는 Microsoft Entra 그룹일 수 있습니다. 사용자가 할당한 관리 ID를 사용하는 그룹에 관리자 역할을 부여하는 경우 3단계를 건너뜁니다. 관리자는 데이터베이스에 대한 전체 액세스 권한을 가집니다.
사용자가 할당한 관리 ID에 대한 포함된 데이터베이스 사용자를 만듭니다. 최소한 ALTER ANY USER 권한이 있는 Microsoft Entra ID를 사용하여 SSMS 등의 도구를 통해 데이터를 복사하려는 데이터 웨어하우스에 연결합니다. 다음 T-SQL을 실행합니다.
CREATE USER [your_resource_name] FROM EXTERNAL PROVIDER;하나 이상의 사용자가 할당한 관리 ID를 만들고 SQL 사용자 및 다른 사용자에 대해 일반적으로 수행하는 것처럼 사용자가 할당한 관리 ID에 필요한 권한을 부여합니다. 다음 코드를 실행하거나 여기서 추가 옵션을 참조합니다. PolyBase를 사용하여 데이터를 로드하려는 경우 필요한 데이터베이스 권한을 알아보세요.
EXEC sp_addrolemember db_owner, [your_resource_name];하나 이상의 사용자가 할당한 관리 ID를 데이터 팩터리에 할당하고 각 사용자가 할당한 관리 ID에 대한 자격 증명을 만듭니다.
Azure Synapse Analytics 연결된 서비스를 구성합니다.
예제:
{
"name": "AzureSqlDWLinkedService",
"properties": {
"type": "AzureSqlDW",
"typeProperties": {
"connectionString": "Server=tcp:<servername>.database.windows.net,1433;Database=<databasename>;Connection Timeout=30",
"credential": {
"referenceName": "credential1",
"type": "CredentialReference"
}
},
"connectVia": {
"referenceName": "<name of Integration Runtime>",
"type": "IntegrationRuntimeReference"
}
}
}
데이터 세트 속성
데이터 세트 정의에 사용할 수 있는 섹션 및 속성의 전체 목록은 데이터 세트 문서를 참조하세요.
Azure Synapse Analytics 데이터 세트에 대해 지원되는 속성은 다음과 같습니다.
| 속성 | 설명 | 필수 |
|---|---|---|
| type | 데이터 세트의 type 속성을 AzureSqlDWTable로 설정해야 합니다. | 예 |
| schema(스키마) | 스키마의 이름입니다. | 원본에는 아니요이고 싱크에는 예입니다 |
| table | 테이블/뷰의 이름입니다. | 원본에는 아니요이고 싱크에는 예입니다 |
| tableName | 스키마가 포함된 테이블/뷰의 이름입니다. 이 속성은 이전 버전과의 호환성을 위해 지원됩니다. 새 워크로드의 경우 schema 및 table을 사용합니다. |
원본에는 아니요이고 싱크에는 예입니다 |
데이터 세트 속성 예제
{
"name": "AzureSQLDWDataset",
"properties":
{
"type": "AzureSqlDWTable",
"linkedServiceName": {
"referenceName": "<Azure Synapse Analytics linked service name>",
"type": "LinkedServiceReference"
},
"schema": [ < physical schema, optional, retrievable during authoring > ],
"typeProperties": {
"schema": "<schema_name>",
"table": "<table_name>"
}
}
}
복사 활동 속성
작업 정의에 사용할 수 있는 섹션 및 속성의 전체 목록은 파이프라인 문서를 참조하세요. 이 섹션에서는 Azure Synapse Analytics 원본 및 싱크에서 지원하는 속성 목록을 제공합니다.
원본으로 Azure Synapse Analytics
팁
데이터 분할을 사용하여 Azure Synapse Analytics에서 데이터를 효율적으로 로드하려면 Azure Synapse Analytics의 병렬 복사에서 자세히 알아보세요.
Azure Synapse Analytics에서 데이터를 복사하려면 복사 작업 원본의 type 속성을 SqlDWSource로 설정합니다. 복사 작업 source 섹션에서 지원되는 속성은 다음과 같습니다.
| 속성 | 설명 | 필수 |
|---|---|---|
| type | 복사 작업 원본의 type 속성을 SqlDWSource로 설정해야 합니다. | 예 |
| SqlReaderQuery | 사용자 지정 SQL 쿼리를 사용하여 데이터를 읽습니다. 예: select * from MyTable |
아니요 |
| sqlReaderStoredProcedureName | 원본 테이블에서 데이터를 읽는 저장 프로시저의 이름입니다. 마지막 SQL 문은 저장 프로시저의 SELECT 문이어야 합니다. | 아니요 |
| storedProcedureParameters | 저장 프로시저에 대한 매개 변수입니다. 허용되는 값은 이름 또는 값 쌍입니다. 매개 변수의 이름 및 대소문자와, 저장 프로시저 매개변수의 이름 및 대소문자와 일치해야 합니다. |
아니요 |
| isolationLevel | SQL 원본에 대한 트랜잭션 잠금 동작을 지정합니다. 허용되는 ReadCommitted, ReadUncommitted, RepeatableRead, Serializable, Snapshot입니다. 지정하지 않으면 데이터베이스의 기본 격리 수준이 사용됩니다. 자세한 내용은 system.data.isolationlevel을 참조하세요. | 아니요 |
| partitionOptions | Azure Synapse Analytics에서 데이터를 로드하는 데 사용되는 데이터 분할 옵션을 지정합니다. 허용되는 값은 None(기본값), PhysicalPartitionsOfTable 및 DynamicRange입니다. 파티션 옵션을 사용하도록 설정하는 경우 (즉, None은 안 됨), Azure Synapse Analytics에서 데이터를 동시에 로드하는 병렬 처리 수준이 복사 작업에서 parallelCopies 설정에 의해 제어됩니다. |
아니요 |
| partitionSettings | 데이터 분할에 대한 설정 그룹을 지정합니다. 파티션 옵션이 None이 아닌 경우 적용됩니다. |
아니요 |
partitionSettings에서: |
||
| partitionColumnName | 병렬 복사를 위해 범위 분할에서 사용할 원본 열의 이름을 정수 또는 날짜/날짜/시간 형식(int, smallint, bigint, date, smalldatetime, datetime, datetime2 또는 datetimeoffset)으로 지정합니다. 지정하지 않으면 테이블의 인덱스 또는 기본 키가 자동으로 검색되어 파티션 열로 사용됩니다.파티션 옵션이 DynamicRange인 경우에 적용됩니다. 쿼리를 사용하여 원본 데이터를 검색하는 경우 WHERE 절에서 ?DfDynamicRangePartitionCondition 를 후크합니다. 예제는 SQL 데이터베이스에서 병렬 복사 섹션을 참조하세요. |
아니요 |
| partitionUpperBound | 파티션 범위 분할에 대한 파티션 열의 최댓값입니다. 이 값은 테이블의 행을 필터링하는 것이 아니라 파티션 진행 속도를 결정하는 데 사용됩니다. 테이블 또는 쿼리 결과의 모든 행이 분할되고 복사됩니다. 지정하지 않으면 복사 작업에서 값을 자동으로 검색합니다. 파티션 옵션이 DynamicRange인 경우에 적용됩니다. 예제는 SQL 데이터베이스에서 병렬 복사 섹션을 참조하세요. |
아니요 |
| partitionLowerBound | 파티션 범위 분할에 대한 파티션 열의 최솟값입니다. 이 값은 테이블의 행을 필터링하는 것이 아니라 파티션 진행 속도를 결정하는 데 사용됩니다. 테이블 또는 쿼리 결과의 모든 행이 분할되고 복사됩니다. 지정하지 않으면 복사 작업에서 값을 자동으로 검색합니다. 파티션 옵션이 DynamicRange인 경우에 적용됩니다. 예제는 SQL 데이터베이스에서 병렬 복사 섹션을 참조하세요. |
아니요 |
다음 사항에 유의하세요.
- 원본에서 저장 프로시저를 사용하여 데이터를 검색할 때 저장 프로시저가 다른 매개 변수 값이 전달되면 다른 스키마를 반환하도록 설계된 경우, UI에서 스키마를 가져오거나 자동 테이블을 만들어 SQL 데이터베이스로 데이터를 복사하면 예기치 않은 결과가 발생할 수 있습니다.
예: SQL 쿼리 사용
"activities":[
{
"name": "CopyFromAzureSQLDW",
"type": "Copy",
"inputs": [
{
"referenceName": "<Azure Synapse Analytics input dataset name>",
"type": "DatasetReference"
}
],
"outputs": [
{
"referenceName": "<output dataset name>",
"type": "DatasetReference"
}
],
"typeProperties": {
"source": {
"type": "SqlDWSource",
"sqlReaderQuery": "SELECT * FROM MyTable"
},
"sink": {
"type": "<sink type>"
}
}
}
]
예: 저장 프로시저 사용
"activities":[
{
"name": "CopyFromAzureSQLDW",
"type": "Copy",
"inputs": [
{
"referenceName": "<Azure Synapse Analytics input dataset name>",
"type": "DatasetReference"
}
],
"outputs": [
{
"referenceName": "<output dataset name>",
"type": "DatasetReference"
}
],
"typeProperties": {
"source": {
"type": "SqlDWSource",
"sqlReaderStoredProcedureName": "CopyTestSrcStoredProcedureWithParameters",
"storedProcedureParameters": {
"stringData": { "value": "str3" },
"identifier": { "value": "$$Text.Format('{0:yyyy}', <datetime parameter>)", "type": "Int"}
}
},
"sink": {
"type": "<sink type>"
}
}
}
]
샘플 저장 프로시저:
CREATE PROCEDURE CopyTestSrcStoredProcedureWithParameters
(
@stringData varchar(20),
@identifier int
)
AS
SET NOCOUNT ON;
BEGIN
select *
from dbo.UnitTestSrcTable
where dbo.UnitTestSrcTable.stringData != stringData
and dbo.UnitTestSrcTable.identifier != identifier
END
GO
싱크로서의 Azure Synapse Analytics
Azure Data Factory 및 Synapse 파이프라인은 Azure Synapse Analytics에 데이터를 로드하는 세 가지 방법을 지원합니다.
- COPY 문 사용
- PolyBase 사용
- 대량 삽입 사용
데이터를 로드하는 가장 빠르고 확장성 있는 방법은 COPY 문 또는 PolyBase을 통하는 것입니다.
데이터를 Azure Synapse Analytics에 복사하려면 복사 작업의 싱크 유형을 SqlDWSink로 설정합니다. 복사 작업 sink 섹션에서 지원되는 속성은 다음과 같습니다.
| 속성 | 설명 | 필수 |
|---|---|---|
| type | 복사 작업 싱크의 type 속성은 SqlDWSink로 설정해야 합니다. | 예 |
| allowPolyBase | PolyBase를 사용하여 Azure Synapse Analytics에 데이터를 로드할지 여부를 나타냅니다. allowCopyCommand 및 allowPolyBase 모두 true일 수 없습니다. 제약 조건 및 세부 정보는 PolyBase를 사용하여 Azure Synapse Analytics로 데이터 로드 섹션을 참조하세요. 허용되는 값은 True 및 False(기본값)입니다. |
아니요. PolyBase를 사용하는 경우 적용합니다. |
| polyBaseSettings | allowPolybase 속성이 true로 설정된 경우 지정될 수 있는 속성의 그룹입니다. |
아니요. PolyBase를 사용하는 경우 적용합니다. |
| allowCopyCommand | COPY 문을 사용하여 Azure Synapse Analytics로 데이터를 로드할지 여부를 나타냅니다. allowCopyCommand 및 allowPolyBase 모두 true일 수 없습니다. 제약 조건 및 세부 정보는 COPY 문을 사용하여 Azure Synapse Analytics로 데이터 로드 섹션을 참조하세요. 허용되는 값은 True 및 False(기본값)입니다. |
아니요. COPY를 사용하는 경우 적용합니다. |
| copyCommandSettings | allowCopyCommand 속성이 TRUE로 설정된 경우 지정될 수 있는 속성의 그룹입니다. |
아니요. COPY를 사용하는 경우 적용합니다. |
| writeBatchSize | 일괄 처리당 SQL 테이블에 삽입할 행 수입니다. 허용되는 값은 정수(행 수)입니다. 기본적으로 서비스는 행 크기에 따라 적절한 일괄 처리 크기를 동적으로 결정합니다. |
아니요. 대량 삽입을 사용하는 경우 적용합니다. |
| writeBatchTimeout | 삽입, upsert 및 저장 프로시저 작업이 시간 초과되기 전에 완료될 때까지 기다리는 시간입니다. 허용되는 값은 timespan입니다. 예를 들어 30분인 경우 "00:30:00"입니다. 값을 지정하지 않으면 시간 제한은 기본적으로 "00:30:00"으로 설정됩니다. |
아니요. 대량 삽입을 사용하는 경우 적용합니다. |
| preCopyScript | 각 실행에서 Azure Synapse Analytics에 데이터를 쓰기 전에 실행할 복사 작업에 대한 SQL 쿼리를 지정합니다. 이 속성을 사용하여 미리 로드된 데이터를 정리합니다. | 아니요 |
| tableOption | 원본 스키마를 기반으로 싱크 테이블이 존재하지 않는 경우 자동으로 만들지 여부를 지정합니다. 허용되는 값은 none(기본값) 또는 autoCreate입니다. |
아니요 |
| disableMetricsCollection | 이 서비스는 복사 성능 최적화 및 권장 사항을 위해 Azure Synapse Analytics DWU와 같은 메트릭을 수집하여 추가 마스터 DB 액세스를 도입합니다. 이 동작에 관심이 있는 경우 true를 지정하여 해제합니다. |
아니요(기본값: false) |
| maxConcurrentConnections | 작업 실행 중 데이터 저장소에 설정된 동시 연결의 상한입니다. 동시 연결을 제한하려는 경우에만 값을 지정합니다. | 아님 |
| WriteBehavior | 데이터를 Azure SQL Database에 로드하기 위한 복사 작업의 쓰기 동작을 지정합니다. 허용되는 값은 Insert 및 Upsert입니다. 기본적으로 서비스는 삽입을 사용하여 데이터를 로드합니다. |
아니요 |
| upsertSettings | 쓰기 동작에 대한 설정 그룹을 지정합니다. WriteBehavior 옵션이 Upsert인 경우 적용합니다. |
아니요 |
upsertSettings에서: |
||
| 키 | 고유한 행 식별을 위한 열 이름을 지정합니다. 단일 키 또는 일련의 키를 사용할 수 있습니다. 지정하지 않으면 기본 키가 사용됩니다. | 아니요 |
| interimSchemaName | 중간 테이블을 만들기 위한 중간 스키마를 지정합니다. 참고: 사용자는 테이블을 만들고 삭제할 수 있는 권한이 있어야 합니다. 기본적으로 중간 테이블은 싱크 테이블과 동일한 스키마를 공유합니다. | 아니요 |
예제 1: Azure Synapse Analytics 싱크
"sink": {
"type": "SqlDWSink",
"allowPolyBase": true,
"polyBaseSettings":
{
"rejectType": "percentage",
"rejectValue": 10.0,
"rejectSampleValue": 100,
"useTypeDefault": true
}
}
예제 2: 데이터 Upsert
"sink": {
"type": "SqlDWSink",
"writeBehavior": "Upsert",
"upsertSettings": {
"keys": [
"<column name>"
],
"interimSchemaName": "<interim schema name>"
},
}
Azure Synapse Analytics에서 병렬 복사
복사 작업의 Azure Synapse Analytics 커넥터는 데이터를 병렬로 복사하는 기본 제공 데이터 분할을 제공합니다. 복사 작업의 원본 탭에서 데이터 분할 옵션을 찾을 수 있습니다.
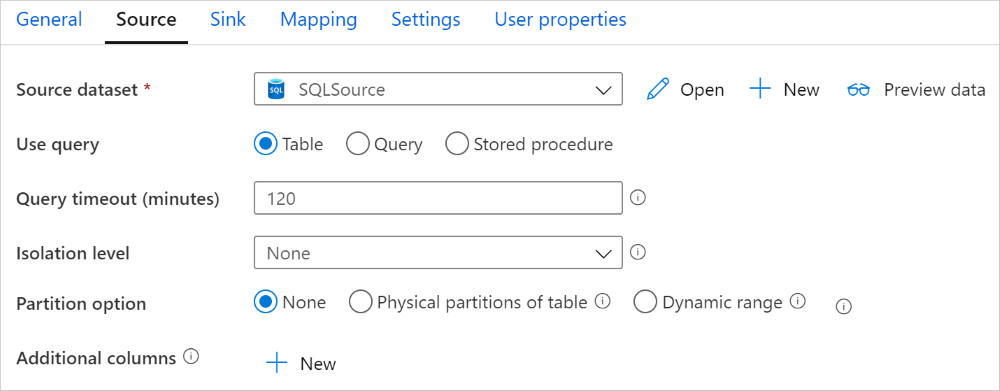
분할된 복사본을 사용하도록 설정하면 복사 작업이 Azure Synapse Analytics 원본에 대해 병렬 쿼리를 실행하여 파티션별로 데이터를 로드합니다. 병렬 수준은 복사 작업의 parallelCopies 설정에 의해 제어됩니다. 예를 들어 parallelCopies를 4로 설정하는 경우, 이 서비스는 지정된 파티션 옵션과 설정에 따라 4개의 쿼리를 동시에 생성하고 실행하며, 각 쿼리는 Azure Synapse Analytics에서 데이터의 일부를 검색합니다.
특히 Azure Synapse Analytics에서 대량의 데이터를 로드하는 경우 특별히 데이터 분할로 병렬 복사를 사용하도록 설정하는 것이 좋습니다. 다양한 시나리오에 대해 권장되는 구성은 다음과 같습니다. 파일 기반 데이터 저장소에 데이터를 복사할 때 여러 파일로 폴더에 쓰는 것이 좋습니다(폴더 이름만 지정). 이 경우 단일 파일에 쓰는 것보다 성능이 좋습니다.
| 시나리오 | 제안된 설정 |
|---|---|
| 실제 파티션이 있는 대형 테이블에서 전체 로드 | 파티션 옵션: 테이블의 실제 파티션 실행하는 동안 서비스에서 실제 파티션을 자동으로 검색하여 데이터를 파티션별로 복사합니다. 실제 파티션이 테이블에 있는지 확인하려면 이 쿼리를 참조할 수 있습니다. |
| 실제 파티션이 없지만 데이터 분할에 대한 정수 또는 날짜/시간 열이 있는 대형 테이블에서 전체 로드를 수행합니다. | 파티션 옵션: 동적 범위 파티션입니다. 파티션 열(선택 사항): 데이터를 분할하는 데 사용되는 열을 지정합니다. 지정하지 않으면 인덱스 또는 기본 키 열이 사용됩니다. 파티션 상한 및 파티션 하한(선택 사항): 파티션 진행 속도를 결정할지 여부를 지정합니다. 이는 테이블의 행을 필터링하기 위한 것이 아니며, 테이블의 모든 행을 분할하고 복사합니다. 지정하지 않으면 복사 작업에서 자동으로 값을 검색합니다. 예를 들어, “ID” 파티션 열의 값 범위가 1~100이고, 하한을 20으로 설정하고, 상한을 80으로 설정하고, 병렬 복사를 4로 설정하면 서비스에서 4개의 파티션별로(각각 ID 범위: <=20, [21, 50], [51, 80] 및 >=81) 데이터를 검색합니다. |
| 실제 파티션이 없지만 데이터 분할에 대한 정수, 날짜 또는 날짜/시간 열이 있는 사용자 지정 쿼리를 사용하여 많은 양의 데이터를 로드합니다. | 파티션 옵션: 동적 범위 파티션입니다. 쿼리: SELECT * FROM <TableName> WHERE ?DfDynamicRangePartitionCondition AND <your_additional_where_clause>.파티션 열: 데이터를 분할하는 데 사용되는 열을 지정합니다. 파티션 상한 및 파티션 하한(선택 사항): 파티션 진행 속도를 결정할지 여부를 지정합니다. 이는 테이블의 행을 필터링하기 위한 것이 아니며, 쿼리 결과의 모든 행을 분할하고 복사합니다. 지정하지 않으면 복사 작업에서 값을 자동으로 검색합니다. 예를 들어 "ID" 파티션 열의 값 범위가 1~100이고 하한을 20으로 설정하고 상한을 80으로 설정하고 병렬 복사를 4로 설정하면 서비스에서 4개의 파티션별로(각각 ID 범위: <=20, [21, 50], [51, 80] 및 >=81) 데이터를 검색합니다. 다양한 시나리오에 대한 추가 샘플 쿼리는 다음과 같습니다. 1. 전체 테이블 쿼리: SELECT * FROM <TableName> WHERE ?DfDynamicRangePartitionCondition2. 열을 선택하고 where 절 필터를 추가하여 테이블 쿼리: SELECT <column_list> FROM <TableName> WHERE ?DfDynamicRangePartitionCondition AND <your_additional_where_clause>3. 하위 쿼리를 사용하여 쿼리: SELECT <column_list> FROM (<your_sub_query>) AS T WHERE ?DfDynamicRangePartitionCondition AND <your_additional_where_clause>4. 하위 쿼리에서 파티션을 사용하여 쿼리: SELECT <column_list> FROM (SELECT <your_sub_query_column_list> FROM <TableName> WHERE ?DfDynamicRangePartitionCondition) AS T |
파티션 옵션을 사용하여 데이터를 로드하는 모범 사례:
- 데이터 기울이기를 방지하려면 고유한 열(예: 기본 키 또는 고유 키)을 분할 열로 선택합니다.
- 테이블에 기본 제공 파티션이 있는 경우 "테이블의 실제 파티션" 파티션 옵션을 사용하여 성능을 향상시킵니다.
- Azure Integration Runtime을 사용하여 데이터를 복사하는 경우 더 많은 컴퓨팅 리소스를 활용할 수 있도록 더 큰 “DIU(데이터 통합 단위)”(>4)를 설정할 수 있습니다. 여기서 적용 가능한 시나리오를 확인합니다.
- "복사 병렬 처리 수준"은 파티션 수를 제어합니다. 이 수를 너무 크게 설정하면 성능이 저하되는 경우가 있습니다. 이 수를 (DIU 또는 자체 호스팅 IR 노드 수) * (2~4)로 설정하는 것이 좋습니다.
- Azure Synapse Analytics는 한 번에 최대 32개의 쿼리를 실행할 수 있으므로 "복사 병렬성 정도"를 너무 크게 설정하면 Synapse 제한 문제가 발생할 수 있습니다.
예제: 실제 파티션이 있는 대형 테이블에서 전체 로드
"source": {
"type": "SqlDWSource",
"partitionOption": "PhysicalPartitionsOfTable"
}
예: 동적 범위 파티션이 있는 쿼리
"source": {
"type": "SqlDWSource",
"query": "SELECT * FROM <TableName> WHERE ?DfDynamicRangePartitionCondition AND <your_additional_where_clause>",
"partitionOption": "DynamicRange",
"partitionSettings": {
"partitionColumnName": "<partition_column_name>",
"partitionUpperBound": "<upper_value_of_partition_column (optional) to decide the partition stride, not as data filter>",
"partitionLowerBound": "<lower_value_of_partition_column (optional) to decide the partition stride, not as data filter>"
}
}
실제 파티션을 확인하기 위한 샘플 쿼리
SELECT DISTINCT s.name AS SchemaName, t.name AS TableName, c.name AS ColumnName, CASE WHEN c.name IS NULL THEN 'no' ELSE 'yes' END AS HasPartition
FROM sys.tables AS t
LEFT JOIN sys.objects AS o ON t.object_id = o.object_id
LEFT JOIN sys.schemas AS s ON o.schema_id = s.schema_id
LEFT JOIN sys.indexes AS i ON t.object_id = i.object_id
LEFT JOIN sys.index_columns AS ic ON ic.partition_ordinal > 0 AND ic.index_id = i.index_id AND ic.object_id = t.object_id
LEFT JOIN sys.columns AS c ON c.object_id = ic.object_id AND c.column_id = ic.column_id
LEFT JOIN sys.types AS y ON c.system_type_id = y.system_type_id
WHERE s.name='[your schema]' AND t.name = '[your table name]'
테이블에 물리적 파티션이 있는 경우 "HasPartition"이 "예"로 표시됩니다.
COPY 문을 사용하여 Azure Synapse Analytics에 데이터 로드
COPY 문을 사용하는 것은 처리량이 높은 Azure Synapse Analytics로 데이터를 로드하는 간단하고 유연한 방법입니다. 자세한 내용을 보려면 COPY 문을 사용하여 데이터 대량 로드를 확인합니다.
- 원본 데이터가 Azure Blob 또는 Azure Data Lake Storage Gen2이고 형식이 COPY 문과 호환인 경우 복사 작업을 사용하여 COPY 문을 직접 호출하여 Azure Synapse Analytics가 원본에서 데이터를 가져오도록 합니다. 자세한 내용은 COPY 문을 사용하여 직접 복사를 참조하세요.
- 원본 데이터 저장소와 형식이 COPY 문에서 원래 지원되지 않는 경우, 대신 COPY 문을 사용한 준비된 복사 기능을 사용합니다. 준비된 복사 기능을 사용할 경우, 처리량도 향상됩니다. 자동으로 데이터를 COPY 문 호환 형식으로 변환하고 Azure Blob Storage에 데이터를 저장한 다음 COPY 문을 호출하여 데이터를 Azure Synapse Analytics에 로드합니다.
팁
Azure Integration Runtime과 함께 COPY 문을 사용할 때 효과적인 DIU(데이터 통합 단위)는 항상 2입니다. DIU 조정은 스토리지에서 데이터를 로드하는 것이 Azure Synapse 엔진에 의해 구동되므로 성능에 영향을 주지 않습니다.
COPY 문을 사용하여 직접 복사
Azure Synapse Analytics COPY 문은 Azure Blob, Azure Data Lake Storage Gen1 및 Azure Data Lake Storage Gen2를 직접 지원합니다. 원본 데이터가 이 섹션에 설명된 조건을 충족하는 경우, COPY 문을 사용하여 원본 데이터 저장소에서 Azure Synapse Analytics로 직접 복사합니다. 그렇지 않은 경우, COPY 문을 사용한 준비된 복사를 사용합니다. 이 서비스는 설정을 확인하고 조건이 충족되지 않으면 복사 작업 실행에 실패합니다.
원본 연결된 서비스 및 형식은 다음과 같은 유형 및 인증 방법을 사용합니다.
지원되는 원본 데이터 저장소 형식 지원되는 형식 지원되는 원본 인증 유형 Azure Blob 구분된 텍스트 계정 키 인증, 공유 액세스 서명 인증, 서비스 주체 인증, 시스템이 할당한 관리 ID 인증 Parquet 계정 키 인증, 공유 액세스 서명 인증 ORC 계정 키 인증, 공유 액세스 서명 인증 Azure Data Lake Storage Gen2 구분된 텍스트
Parquet
ORC계정 키 인증, 서비스 주체 인증, 시스템이 할당한 관리 ID 인증 Important
- 스토리지에 연결된 서비스에 관리 ID 인증을 사용하는 경우 각각 Azure Blob 및 Azure Data Lake Storage Gen2에 필요한 구성을 알아봅니다.
- Azure Storage가 VNet 서비스 엔드포인트로 구성된 경우 스토리지 계정에 "신뢰할 수 있는 Microsoft 서비스 허용"이 사용하도록 설정된 관리 ID 인증을 사용해야 합니다. Azure Storage에서 VNet 서비스 엔드포인트 사용의 영향을 참조하세요.
형식 설정에는 다음이 포함됩니다.
- Parquet의 경우:
compression은 압축 없음, Snappy 또는GZip일 수 있습니다. - ORC의 경우:
compression은 압축 안 함,zlib또는 Snappy일 수 있습니다. - 구분 된 텍스트의 경우:
rowDelimiter는 단일 문자 또는 "\r\n"으로 명시적으로 설정됩니다. 기본값은 지원되지 않습니다.nullValue는 기본값으로 남아 있거나 빈 문자열("")로 설정됩니다.encodingName는 기본값으로 남아 있거나 utf-8 또는 utf-16으로 설정됩니다.escapeChar는quoteChar와 동일해야 하며 비어 있지 않습니다.skipLineCount는 기본값으로 남아 있거나 0으로 설정됩니다.compression는 압축 안 함 또는GZip일 수 있습니다.
- Parquet의 경우:
원본이 폴더인 경우 복사 작업의
recursive를 true로 설정해야 하며wildcardFilename는*또는*.*이어야 합니다.wildcardFolderPath,wildcardFilename(*또는*.*이외),modifiedDateTimeStart,modifiedDateTimeEnd,prefix,enablePartitionDiscovery및additionalColumns는 지정되지 않습니다.
복사 작업의 allowCopyCommand에서 다음 COPY 문 설정이 지원됩니다.
| 속성 | 설명 | 필수 |
|---|---|---|
| defaultValues | Azure Synapse Analytics의 각 대상 열에 대한 기본값을 지정합니다. 속성의 기본값은 데이터 웨어하우스의 기본 제약 조건 집합을 덮어쓰고 ID 열에는 기본값을 사용할 수 없습니다. | 아니요 |
| additionalOptions | COPY 문의 "With" 절에서 직접 Azure Synapse Analytics COPY 문에 전달되는 추가 옵션입니다. COPY 문 요구 사항에 맞게 조정하는 데 필요한 값을 따옴표로 묶습니다. | 아니요 |
"activities":[
{
"name": "CopyFromAzureBlobToSQLDataWarehouseViaCOPY",
"type": "Copy",
"inputs": [
{
"referenceName": "ParquetDataset",
"type": "DatasetReference"
}
],
"outputs": [
{
"referenceName": "AzureSQLDWDataset",
"type": "DatasetReference"
}
],
"typeProperties": {
"source": {
"type": "ParquetSource",
"storeSettings":{
"type": "AzureBlobStorageReadSettings",
"recursive": true
}
},
"sink": {
"type": "SqlDWSink",
"allowCopyCommand": true,
"copyCommandSettings": {
"defaultValues": [
{
"columnName": "col_string",
"defaultValue": "DefaultStringValue"
}
],
"additionalOptions": {
"MAXERRORS": "10000",
"DATEFORMAT": "'ymd'"
}
}
},
"enableSkipIncompatibleRow": true
}
}
]
COPY 문을 사용한 준비된 복사
원본 데이터가 COPY 문과 기본적으로 호환되지 않는 경우 중간 준비 Azure Blob 또는 Azure Data Lake Storage Gen2(Azure Premium Storage일 수 없음)를 통해 데이터 복사를 사용하도록 설정합니다. 이 경우, 이 서비스는 COPY 문의 데이터 형식 요구 사항을 충족하도록 데이터를 자동으로 변환합니다. 그런 다음, COPY 문을 호출하여 Azure Synapse Analytics에 데이터를 로드합니다. 마지막으로 스토리지에서 임시 데이터를 정리합니다. 스테이징을 통한 데이터 복사에 대한 자세한 내용은 스테이징된 복사본을 참조하세요.
이 기능을 사용하려면 Azure Storage 계정을 중간 스토리지로 참조하는 계정 키 또는 시스템 관리 ID 인증으로 Azure Blob Storage에 연결된 서비스 또는 Azure Data Lake Storage Gen2에 연결된 서비스를 만듭니다.
Important
- 스테이징하는 연결된 서비스에 관리 ID 인증을 사용하는 경우 Azure Blob 및 Azure Data Lake Storage Gen2 각각에 필요한 구성을 알아봅니다. 또한 스테이징 Azure Blob Storage 또는 Azure Data Lake Storage Gen2 계정에서 Azure Synapse Analytics 작업 영역 관리 ID에 권한을 부여해야 합니다. 이 권한을 부여하는 방법을 알아보려면 작업 영역 관리 ID에 대한 권한 부여를 참조하세요.
- 스테이징 Azure Storage가 VNet 서비스 엔드포인트로 구성된 경우 스토리지 계정에 "신뢰할 수 있는 Microsoft 서비스 허용"이 사용하도록 설정된 관리 ID 인증을 사용해야 합니다. Azure Storage에서 VNet 서비스 엔드포인트 사용의 영향을 참조하세요.
Important
스테이징하는 Azure Storage가 관리형 프라이빗 엔드포인트로 구성되고 스토리지 방화벽이 사용하도록 설정된 경우 관리 ID 인증을 사용하고 Synapse SQL Server에 스토리지 Blob 데이터 판독기 권한을 부여하여 COPY 문 로드 중에 스테이징된 파일에 액세스할 수 있도록 해야 합니다.
"activities":[
{
"name": "CopyFromSQLServerToSQLDataWarehouseViaCOPYstatement",
"type": "Copy",
"inputs": [
{
"referenceName": "SQLServerDataset",
"type": "DatasetReference"
}
],
"outputs": [
{
"referenceName": "AzureSQLDWDataset",
"type": "DatasetReference"
}
],
"typeProperties": {
"source": {
"type": "SqlSource",
},
"sink": {
"type": "SqlDWSink",
"allowCopyCommand": true
},
"stagingSettings": {
"linkedServiceName": {
"referenceName": "MyStagingStorage",
"type": "LinkedServiceReference"
}
}
}
}
]
PolyBase를 사용하여 Azure Synapse Analytics에 데이터 로드
PolyBase를 사용하면 높은 처리량으로 대량 데이터를 Azure Synapse Analytics에 효율적으로 로드할 수 있습니다. 기본 BULKINSERT 메커니즘 대신 PolyBase를 사용하면 처리량이 훨씬 증가합니다.
- 원본 데이터가 Azure Blob, Azure Data Lake Storage Gen1 또는 Azure Data Lake Storage Gen2이고 형식이 PolyBase와 호환인 경우 복사 작업을 사용하여 PolyBase를 직접 호출하여 Azure Synapse Analytics가 원본에서 데이터를 가져오도록 합니다. 자세한 내용은 PolyBase를 사용하여 직접 복사를 참조하세요.
- 원본 데이터 저장소와 형식이 PolyBase에서 원래 지원되지 않는 경우, 대신 PolyBase를 사용한 준비된 복사 기능을 사용합니다. 준비된 복사 기능을 사용할 경우, 처리량도 향상됩니다. 자동으로 데이터를 PolyBase 호환 형식으로 변환하고 Azure Blob Storage에 데이터를 저장한 다음 PolyBase를 호출하여 데이터를 Azure Synapse Analytics에 로드합니다.
팁
PolyBase 사용에 대한 모범 사례에 대해 자세히 알아봅니다. Azure Integration Runtime과 함께 PolyBase를 사용하는 경우 직접 또는 스테이징된 스토리지에서 Synapse까지의 효과적인 DIU(데이터 통합 단위)는 항상 2입니다. DIU 조정은 스토리지에서 데이터를 로드하는 것이 Synapse 엔진에 의해 구동되므로 성능에 영향을 주지 않습니다.
복사 작업의 polyBaseSettings에서 다음 PolyBase 설정이 지원됩니다.
| 속성 | 설명 | 필수 |
|---|---|---|
| rejectValue | 쿼리가 실패하기 전에 거부될 수 있는 행의 수 또는 백분율을 지정합니다. CREATE EXTERNAL TABLE(Transact-SQL)의 인수 섹션에서 PolyBase의 거부 옵션에 대해 자세히 알아봅니다. 허용되는 값은 0(기본값), 1, 2 등입니다. |
아니요 |
| rejectType | rejectValue 옵션이 리터럴 값인지 또는 백분율인지를 지정합니다. 허용되는 값은 Value(기본값) 및 Percentage입니다. |
아니요 |
| rejectSampleValue | PolyBase가 거부된 행의 백분율을 다시 계산하기 전에 검색할 행 수를 결정합니다. 허용되는 값은 1, 2 등입니다. |
rejectType이 percentage인 경우 예 |
| useTypeDefault | PolyBase가 텍스트 파일에서 데이터를 검색할 경우 구분된 텍스트 파일에서 누락된 값을 처리하는 방법을 지정합니다. 외부 파일 서식 만들기(Transact-SQL)를 사용하여 파이프라인을 만드는 데 사용할 수 있는 샘플 JSON 정의를 제공합니다. 허용되는 값은 True 및 False(기본값)입니다. |
아니요 |
PolyBase를 사용한 직접 복사
Azure Synapse Analytics PolyBase는 Azure Blob, Azure Data Lake Storage Gen1 및 Azure Data Lake Storage Gen2를 직접 지원합니다. 원본 데이터가 이 섹션에 설명된 조건을 충족하는 경우, PolyBase를 사용하여 원본 데이터 저장소에서 Azure Synapse Analytics로 직접 복사합니다. 조건을 충족하지 않는 경우, PolyBase를 사용한 준비된 복사를 사용합니다.
팁
Azure Synapse Analytics로 데이터를 효율적으로 복사하려면 Azure Data Factory를 통해 Azure Synapse Analytics와 함께 Data Lake Store를 사용할 때 데이터에서 통찰력을 더욱 쉽고 편리하게 찾을 수 있음에서 자세히 알아보세요.
조건을 충족하지 않는 경우, 이 서비스는 설정을 확인한 후 데이터 이동을 위해 BULKINSERT 메커니즘으로 자동으로 대체됩니다.
원본 연결된 서비스는 다음과 같은 유형 및 인증 방법을 사용합니다.
지원되는 원본 데이터 저장소 형식 지원되는 원본 인증 유형 Azure Blob 계정 키 인증, 시스템이 할당한 관리 ID 인증 Azure Data Lake Storage Gen1 서비스 주체 인증 Azure Data Lake Storage Gen2 계정 키 인증, 시스템이 할당한 관리 ID 인증 Important
- 스토리지에 연결된 서비스에 관리 ID 인증을 사용하는 경우 각각 Azure Blob 및 Azure Data Lake Storage Gen2에 필요한 구성을 알아봅니다.
- Azure Storage가 VNet 서비스 엔드포인트로 구성된 경우 스토리지 계정에 "신뢰할 수 있는 Microsoft 서비스 허용"이 사용하도록 설정된 관리 ID 인증을 사용해야 합니다. Azure Storage에서 VNet 서비스 엔드포인트 사용의 영향을 참조하세요.
원본 데이터 형식은 다음 구성과 함께 Parquet, ORC 또는 구분된 텍스트입니다.
- 폴더 경로는 와일드 카드 필터를 포함하지 않습니다.
- 파일 이름이 비어 있거나 단일 파일을 가리킵니다. 복사 작업에서 와일드 카드 파일 이름을 지정하는 경우
*또는*.*만 가능합니다. rowDelimiter는 기본값, \n, \r\n 또는 \r입니다.nullValue는 기본값으로 남아 있거나 빈 문자열("")로 설정되며,treatEmptyAsNull는 기본값으로 남아 있거나 true로 설정됩니다.encodingName는 기본값으로 남아 있거나 utf-8로 설정됩니다.quoteChar,escapeChar및skipLineCount는 지정되지 않습니다. PolyBase 지원은firstRowAsHeader로 구성될 수 있는 헤더 행을 건너뜁니다.compression는 압축 안 함,GZip또는 Deflate일 수 있습니다.
원본이 폴더인 경우 복사 작업의
recursive을 true로 설정해야 합니다.wildcardFolderPath,wildcardFilename,modifiedDateTimeStart,modifiedDateTimeEnd,prefix,enablePartitionDiscovery및additionalColumns는 지정되지 않습니다.
참고 항목
원본이 폴더인 경우 PolyBase는 폴더와 모든 하위 폴더에서 파일을 검색하며, 여기 - LOCATION 인수에 설명된 대로 파일 이름이 밑줄(_) 또는 마침표(.)로 시작하는 파일에서 데이터를 검색하지 않습니다.
"activities":[
{
"name": "CopyFromAzureBlobToSQLDataWarehouseViaPolyBase",
"type": "Copy",
"inputs": [
{
"referenceName": "ParquetDataset",
"type": "DatasetReference"
}
],
"outputs": [
{
"referenceName": "AzureSQLDWDataset",
"type": "DatasetReference"
}
],
"typeProperties": {
"source": {
"type": "ParquetSource",
"storeSettings":{
"type": "AzureBlobStorageReadSettings",
"recursive": true
}
},
"sink": {
"type": "SqlDWSink",
"allowPolyBase": true
}
}
}
]
PolyBase를 사용한 준비된 복사
원본 데이터가 PolyBase와 기본적으로 호환되지 않는 경우 중간 준비 Azure Blob 또는 Azure Data Lake Storage Gen2(Azure Premium Storage일 수 없음)를 통해 데이터 복사를 사용하도록 설정합니다. 이 경우, Azure Data Factory는 COPY 문의 데이터 형식 요구 사항을 충족하도록 데이터를 자동으로 변환합니다. 그런 다음 PolyBase를 호출하여 Azure Synapse Analytics에 데이터를 로드합니다. 마지막으로 스토리지에서 임시 데이터를 정리합니다. 스테이징을 통한 데이터 복사에 대한 자세한 내용은 스테이징된 복사본을 참조하세요.
이 기능을 사용하려면 Azure Storage 계정을 중간 스토리지로 참조하는 계정 키 또는 관리 ID 인증으로 Azure Blob Storage에 연결된 서비스 또는 Azure Data Lake Storage Gen2에 연결된 서비스를 만듭니다.
Important
- 스테이징하는 연결된 서비스에 관리 ID 인증을 사용하는 경우 Azure Blob 및 Azure Data Lake Storage Gen2 각각에 필요한 구성을 알아봅니다. 또한 스테이징 Azure Blob Storage 또는 Azure Data Lake Storage Gen2 계정에서 Azure Synapse Analytics 작업 영역 관리 ID에 권한을 부여해야 합니다. 이 권한을 부여하는 방법을 알아보려면 작업 영역 관리 ID에 대한 권한 부여를 참조하세요.
- 스테이징 Azure Storage가 VNet 서비스 엔드포인트로 구성된 경우 스토리지 계정에 "신뢰할 수 있는 Microsoft 서비스 허용"이 사용하도록 설정된 관리 ID 인증을 사용해야 합니다. Azure Storage에서 VNet 서비스 엔드포인트 사용의 영향을 참조하세요.
Important
스테이징하는 Azure Storage가 관리형 프라이빗 엔드포인트로 구성되고 스토리지 방화벽이 사용하도록 설정된 경우 관리 ID 인증을 사용하고 Synapse SQL Server에 스토리지 Blob 데이터 판독기 권한을 부여하여 PolyBase 로드 중에 스테이징된 파일에 액세스할 수 있도록 해야 합니다.
"activities":[
{
"name": "CopyFromSQLServerToSQLDataWarehouseViaPolyBase",
"type": "Copy",
"inputs": [
{
"referenceName": "SQLServerDataset",
"type": "DatasetReference"
}
],
"outputs": [
{
"referenceName": "AzureSQLDWDataset",
"type": "DatasetReference"
}
],
"typeProperties": {
"source": {
"type": "SqlSource",
},
"sink": {
"type": "SqlDWSink",
"allowPolyBase": true
},
"enableStaging": true,
"stagingSettings": {
"linkedServiceName": {
"referenceName": "MyStagingStorage",
"type": "LinkedServiceReference"
}
}
}
}
]
PolyBase를 사용하는 모범 사례
다음 섹션에서는 Azure Synapse Analytics에 대한 모범 사례에 설명된 사례 이외의 모범 사례를 제공합니다.
필수 데이터베이스 권한
PolyBase를 사용하려면 Azure Synapse Analytics에 데이터를 로드하는 사용자에게 대상 데이터베이스에 대한 "CONTROL" 권한이 있어야 합니다. 한 가지 방법은 해당 사용자를 db_owner 역할의 구성원으로 추가하는 것입니다. Azure Synapse Analytics 개요에서 수행 방법을 알아봅니다.
행 크기 및 데이터 형식 한도
PolyBase는 1MB보다 작은 행으로 제한됩니다. VARCHR(MAX), NVARCHAR(MAX) 또는 VARBINARY(MAX)에 로드하는 데 사용할 수 없습니다. 자세한 내용은 Azure Synapse Analytics 서비스 용량 제한을 참조하세요.
원본 데이터에 1MB보다 큰 행이 있는 경우, 원본 테이블을 여러 개의 작은 테이블로 수직 분할하는 것이 좋습니다. 각 행의 최대 크기가 한도를 초과하지 않는지 확인합니다. 더 작은 테이블은 PolyBase를 사용하여 로드하고 Azure Synapse Analytics에 병합할 수 있습니다.
또는 이러한 광범위한 열이 포함된 데이터의 경우 "PolyBase 허용" 설정을 해제하여 비 PolyBase를 사용하고 데이터를 로드할 수 있습니다.
Azure Synapse Analytics 리소스 클래스
가능한 최상의 처리량을 얻으려면 PolyBase를 통해 Azure Synapse Analytics에 데이터를 로드하는 사용자에게 더 큰 리소스 클래스를 할당합니다.
PolyBase 문제 해결
Decimal 열에 로드
원본 데이터가 텍스트 형식이나 기타 PolyBase 호환 저장소(준비된 복사 및 PolyBase 사용)에 있고 Azure Synapse Analytics Decimal 열에 로드할 빈 값을 포함하는 경우 다음 오류가 발생할 수 있습니다.
ErrorCode=FailedDbOperation, ......HadoopSqlException: Error converting data type VARCHAR to DECIMAL.....Detailed Message=Empty string can't be converted to DECIMAL.....
이 솔루션은 복사 작업 싱크 -> PolyBase 설정에서 “형식 기본값 사용” 옵션(false로 설정)을 선택 취소하는 것입니다. "USE_TYPE_DEFAULT"는 PolyBase 네이티브 구성으로, PolyBase가 텍스트 파일에서 데이터를 검색할 경우 구분된 텍스트 파일에서 누락된 값을 처리하는 방법을 지정합니다.
Azure Synapse Analytics에서 tableName 속성 확인
다음 표에서는 JSON 데이터 세트의 tableName 속성을 지정하는 방법에 대한 예를 제공합니다. 스키마 및 테이블 이름의 여러 조합을 보여 줍니다.
| DB 스키마 | 테이블 이름 | tableName JSON 속성 |
|---|---|---|
| dbo | MyTable | MyTable 또는 dbo.MyTable 또는 [dbo].[MyTable] |
| dbo1 | MyTable | dbo1.MyTable 또는 [dbo1].[MyTable] |
| dbo | My.Table | [My.Table] 또는 [dbo].[My.Table] |
| dbo1 | My.Table | [dbo1].[My.Table] |
다음 오류가 표시되는 경우, tableName 속성에 대해 지정한 값이 문제일 수 있습니다. tableName JSON 속성의 값을 지정하는 올바른 방법은 앞의 표를 참조하세요.
Type=System.Data.SqlClient.SqlException,Message=Invalid object name 'stg.Account_test'.,Source=.Net SqlClient Data Provider
기본값이 있는 열
현재, PolyBase 기능은 대상 테이블과 동일한 열 수만 허용합니다. 예를 들어, 네 개의 열이 있고 그 중 한 열이 기본값으로 정의된 테이블이 있다고 가정합니다. 이 경우, 입력 데이터에 네 개의 열이 있어야 합니다. 3열 입력 데이터 세트를 제공하면 다음 메시지와 비슷한 오류가 발생합니다.
All columns of the table must be specified in the INSERT BULK statement.
NULL 값은 특별한 형태의 기본값입니다. 열이 Null을 허용하는 경우, 해당 열에 대한 Blob의 입력 데이터가 비어 있을 수 있습니다. 그러나 입력 데이터 세트에서는 누락할 수 없습니다. PolyBase는 Azure Synapse Analytics에서 누락된 값에 대해 NULL을 삽입합니다.
외부 파일 액세스 실패
다음 오류가 발생하면 관리 ID 인증을 사용하고 있고 Azure Synapse 작업 영역의 관리 ID에 대한 Storage Blob 데이터 판독기 권한을 부여했는지 확인합니다.
Job failed due to reason: at Sink '[SinkName]': shaded.msdataflow.com.microsoft.sqlserver.jdbc.SQLServerException: External file access failed due to internal error: 'Error occurred while accessing HDFS: Java exception raised on call to HdfsBridge_IsDirExist. Java exception message:\r\nHdfsBridge::isDirExist
자세한 내용은 작업 영역 생성 후 관리 ID에 권한 부여를 참조하세요.
매핑 데이터 흐름 속성
매핑 데이터 흐름에서 데이터를 변환하는 경우 Azure Synapse Analytics에서 테이블에 대한 읽기 및 쓰기를 수행할 수 있습니다. 자세한 내용은 매핑 데이터 흐름에서 원본 변환 및 싱크 변환을 참조하세요.
원본 변환
Azure Synapse Analytics에 특정한 설정은 원본 변환의 원본 옵션 탭에서 사용할 수 있습니다.
입력 원본을 테이블에 표시할지 선택하거나(Select * from <table-name>와 동일) 사용자 지정 SQL 쿼리를 입력합니다.
스테이징 사용 Azure Synapse Analytics 원본이 있는 프로덕션 워크로드에서 이 옵션을 사용하는 것이 좋습니다. 파이프라인에서 Azure Synapse Analytics 원본을 사용하여 데이터 흐름 작업을 실행하면 스테이징 위치 스토리지 계정을 입력하라는 메시지가 표시되며 이를 스테이징된 데이터 로드에 사용할 수 있습니다. Azure Synapse Analytics에서 데이터를 로드하는 가장 빠른 메커니즘입니다.
- 스토리지에 연결된 서비스에 관리 ID 인증을 사용하는 경우 각각 Azure Blob 및 Azure Data Lake Storage Gen2에 필요한 구성을 알아봅니다.
- Azure Storage가 VNet 서비스 엔드포인트로 구성된 경우 스토리지 계정에 "신뢰할 수 있는 Microsoft 서비스 허용"이 사용하도록 설정된 관리 ID 인증을 사용해야 합니다. Azure Storage에서 VNet 서비스 엔드포인트 사용의 영향을 참조하세요.
- Azure Synapse 서버리스 SQL 풀을 원본으로 사용하는 경우 스테이징 사용이 지원되지 않습니다.
쿼리: 입력 필드에서 쿼리를 선택하는 경우에는 원본에 대한 SQL 쿼리를 입력합니다. 이렇게 설정하면 데이터 세트에서 선택한 모든 테이블이 재정의됩니다. Order By 절은 여기서 지원되지 않지만 전체 SELECT FROM 문을 설정할 수 있습니다. 사용자 정의 테이블 함수를 사용할 수도 있습니다. select * from udfGetData()는 테이블을 반환하는 SQL의 UDF입니다. 이 쿼리는 데이터 흐름에서 사용할 수 있는 원본 테이블을 생성합니다. 쿼리를 사용하는 것은 테스트 또는 조회를 위해 행을 줄이는 좋은 방법이기도 합니다.
SQL 예제: Select * from MyTable where customerId > 1000 and customerId < 2000
일괄 처리 크기: 일괄 처리 크기를 입력하여 대량 데이터를 읽기로 청크합니다. 데이터 흐름에서 이 설정을 사용하여 Spark 열 형식 캐싱을 설정합니다. 이 필드는 비어 있는 경우 Spark 기본값을 사용하는 옵션 필드입니다.
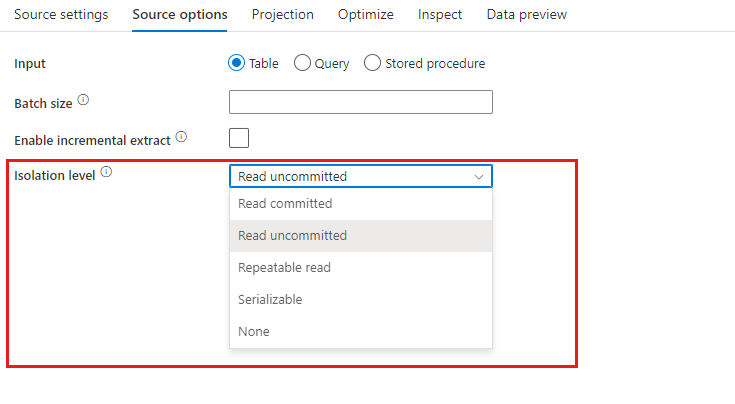
격리 수준: 매핑 데이터 흐름에서 SQL 원본의 기본값은 커밋되지 않은 읽기입니다. 여기에서 격리 수준을 다음 값 중 하나로 변경할 수 있습니다.
- 커밋된 읽기
- 커밋되지 않은 읽기
- 반복 가능한 읽기
- 직렬화 가능
- 없음(격리 수준 무시)
싱크 변환
Azure Synapse Analytics에 특정한 설정은 싱크 변환의 설정 탭에서 사용할 수 있습니다.
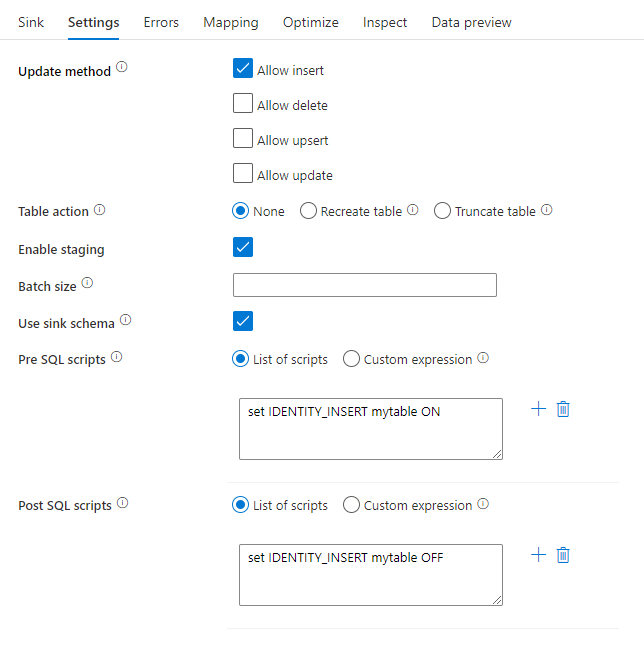
업데이트 메서드: 데이터베이스 대상에서 허용되는 작업을 결정합니다. 기본값은 삽입만 허용하는 것입니다. 행을 업데이트, upsert 또는 삭제하려면 해당 작업을 위해 행에 태그를 지정하는 데 행 변경 변환이 필요합니다. 업데이트, upsert 및 삭제의 경우 변경할 행을 결정하기 위해 키 열을 설정해야 합니다.
테이블 작업: 쓰기 전에 대상 테이블에서 모든 행을 다시 만들지 또는 제거할지 여부를 결정합니다.
- None: 테이블에 대한 작업이 수행되지 않습니다.
- Recreate: 테이블이 삭제되고 다시 생성됩니다. 동적으로 새 테이블을 만드는 경우 필요합니다.
- Truncate: 대상 테이블의 모든 행이 제거됩니다.
스테이징 사용: 이렇게 하면 복사 명령을 사용하여 Azure Synapse Analytics SQL 풀에 로드할 수 있으며 대부분의 Synapse 싱크에 권장됩니다. 스테이징 스토리지는 데이터 흐름 실행 작업에서 구성됩니다.
- 스토리지에 연결된 서비스에 관리 ID 인증을 사용하는 경우 각각 Azure Blob 및 Azure Data Lake Storage Gen2에 필요한 구성을 알아봅니다.
- Azure Storage가 VNet 서비스 엔드포인트로 구성된 경우 스토리지 계정에 "신뢰할 수 있는 Microsoft 서비스 허용"이 사용하도록 설정된 관리 ID 인증을 사용해야 합니다. Azure Storage에서 VNet 서비스 엔드포인트 사용의 영향을 참조하세요.
일괄 처리 크기: 각 버킷에 작성되는 행 수를 제어합니다. 일괄 처리 크기가 클수록 압축 및 메모리 최적화가 향상되지만 데이터를 캐시할 때 메모리 부족 예외가 발생할 위험이 있습니다.
싱크 스키마 사용: 기본적으로 임시 테이블은 싱크 스키마 아래에 스테이징으로 만들어집니다. 또는 싱크 스키마 사용 옵션을 선택 취소하고 대신 사용자 DB 스키마 선택에서 Data Factory가 업스트림 데이터를 로드하는 준비 테이블을 만들고 완료 시 자동으로 정리할 스키마 이름을 지정할 수 있습니다. 데이터베이스에 대한 테이블 만들기 권한과 스키마에 대한 변경 권한이 있는지 확인합니다.

사전 및 사후 SQL 스크립트: 데이터를 싱크 데이터베이스에 기록하기 전(사전 처리)과 후(사후 처리)에 실행할 여러 줄 SQL 스크립트를 입력합니다.
팁
- 여러 명령이 있는 단일 일괄 처리 스크립트는 여러 일괄 처리로 분할하는 것이 좋습니다.
- 단순 업데이트 횟수를 반환하는 DDL(데이터 정의 언어) 및 DML(데이터 조작 언어) 문만 일괄 처리의 일부로 실행할 수 있습니다. 일괄 처리 작업 수행의 자세한 정보
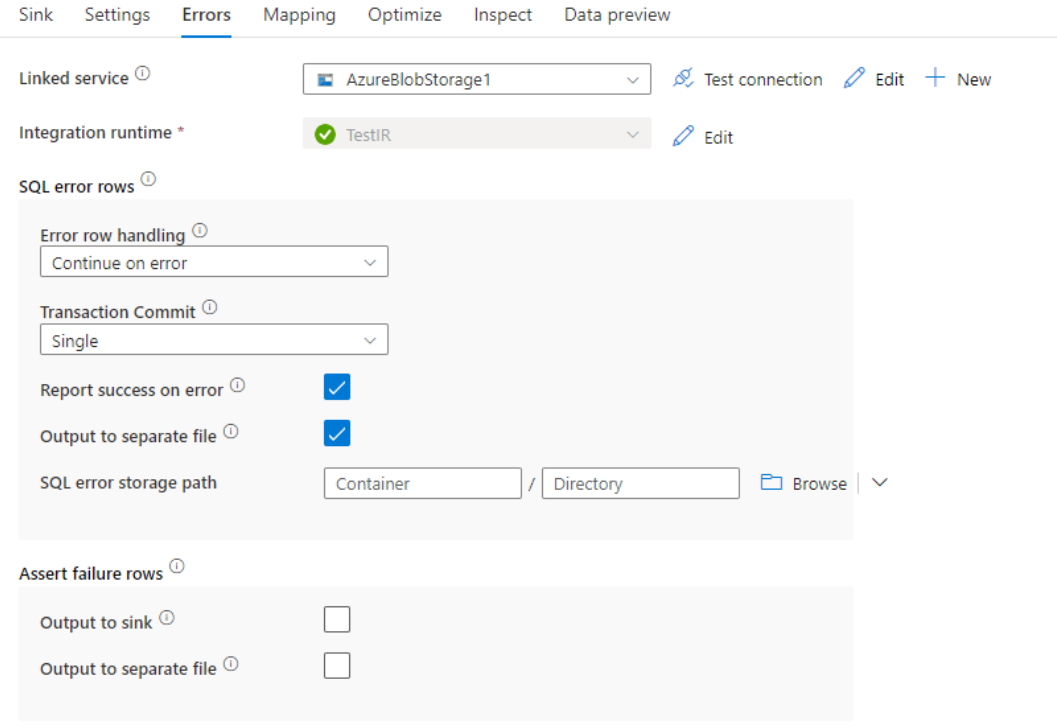
오류 행 처리
Azure Synapse Analytics에 쓸 때 대상에서 설정된 제약 조건으로 인해 특정 데이터 행이 실패할 수 있습니다. 일반적인 오류는 다음과 같습니다.
- 테이블에서 문자열이나 이진 데이터는 잘립니다.
- 열에 NULL 값을 삽입할 수 없습니다.
- 값을 데이터 형식으로 변환하지 못했습니다.
기본적으로 첫 번째 오류가 발생할 때 데이터 흐름 실행이 실패합니다. 개별 행에 오류가 있는 경우에도 데이터 흐름이 완료될 수 있도록 오류 발생 시 계속을 선택할 수 있습니다. 서비스는 이러한 오류 행을 처리하는 다양한 옵션을 제공합니다.
트랜잭션 커밋: 데이터를 단일 트랜잭션으로 쓸지 또는 일괄로 쓸지를 선택합니다. 단일 트랜잭션은 더 나은 성능을 제공하며 트랜잭션이 완료될 때까지 기록된 데이터가 다른 사용자에게 표시되지 않습니다. 일괄 처리 트랜잭션은 성능이 저하되지만 큰 데이터 세트에 대해 작동할 수 있습니다.
거부된 데이터 출력: 사용하도록 설정된 경우 선택한 Azure Blob Storage 또는 선택한 Azure Data Lake Storage Gen2 계정의 csv 파일에 오류 행을 출력할 수 있습니다. 이렇게 하면 세 개의 추가 열, 즉 INSERT 또는 UPDATE와 같은 SQL 작업, 데이터 흐름 오류 코드 및 오류 메시지를 포함하는 오류 행이 기록됩니다.
오류 발생 시 성공 보고: 사용하도록 설정된 경우 오류 행이 있는 경우에도 데이터 흐름이 성공으로 표시됩니다.
조회 작업 속성
속성에 대한 자세한 내용을 보려면 조회 작업을 확인하세요.
GetMetadata 작업 속성
속성에 대한 자세한 내용을 보려면 GetMetadata 작업을 확인하세요.
Azure Synapse Analytics에 대한 데이터 형식 매핑
Azure Synapse Analytics에서/로 데이터를 복사하는 경우, Azure Synapse Analytics 데이터 형식에서 Azure Data Factory 중간 데이터 형식으로 다음 매핑이 사용됩니다. Synapse 파이프라인은 Azure Synapse 내에서 Azure Data Factory도 구현하므로 이러한 매핑은 Synapse 파이프라인을 사용하여 Azure Synapse Analytics 간에 데이터를 복사하는 경우에도 사용됩니다. 복사 작업에서 원본 스키마 및 데이터 형식을 싱크에 매핑하는 방법에 대한 자세한 내용은 스키마 및 데이터 형식 매핑을 참조하세요.
팁
Azure Synapse Analytics 지원 데이터 형식 및 지원되지 않는 데이터 형식에 대한 해결 방법에 관한 자세한 내용은 Azure Synapse Analytics의 테이블 데이터 형식 문서를 참조하세요.
| Azure Synapse Analytics 데이터 형식 | Data Factory 중간 데이터 형식 |
|---|---|
| bigint | Int64 |
| binary | Byte[] |
| bit | 부울 |
| char | String, Char[] |
| date | DateTime |
| DateTime | DateTime |
| datetime2 | DateTime |
| Datetimeoffset | DateTimeOffset |
| 소수 | Decimal |
| FILESTREAM 특성(varbinary(max)) | Byte[] |
| Float | Double |
| 이미지 | Byte[] |
| int | Int32 |
| money | Decimal |
| nchar | String, Char[] |
| numeric | Decimal |
| nvarchar | String, Char[] |
| real | Single |
| rowversion | Byte[] |
| smalldatetime | DateTime |
| smallint | Int16 |
| smallmoney | Decimal |
| time | TimeSpan |
| tinyint | Byte |
| uniqueidentifier | GUID |
| varbinary | Byte[] |
| varchar | String, Char[] |
관련 콘텐츠
복사 작업에서 원본 및 싱크로 지원되는 데이터 저장소 목록은 지원되는 데이터 저장소 및 형식을 참조하세요.