이 자습서에서는 Visual Studio Code Databricks 확장을 설정한 다음, Azure Databricks 클러스터에서 Python 실행하고 원격 작업 영역에서 Azure Databricks 작업으로 실행하는 방법에 대해 설명합니다. Visual Studio Code용 Databricks 확장을 참조하세요.
요구 사항
이 자습서에서는 다음이 필요합니다.
- Visual Studio Code 대한 Databricks 확장을 설치했습니다. Visual Studio Code 용 Databricks 확장 설치를 참조하세요.
- 사용할 원격 Azure Databricks 클러스터가 있습니다. 클러스터의 이름을 기록해 둡다. 사용 가능한 클러스터를 보려면 Azure Databricks 작업 영역 사이드바에서 Compute 클릭합니다. 컴퓨팅을 참조하세요.
1단계: 새 Databricks 프로젝트 만들기
이 단계에서는 새 Databricks 프로젝트를 만들고 원격 Azure Databricks 작업 영역과의 연결을 구성합니다.
- Visual Studio Code 시작하고 > 폴더 열기를 클릭하고 로컬 개발 머신에서 빈 폴더를 엽니다.
- 사이드바에서 Databricks 로고 아이콘을 클릭합니다. 그러면 Databricks 확장이 열립니다.
- 구성 보기에서 구성 만들기클릭합니다.
-
Databricks 작업 영역을 구성하는 명령 팔레트가 열립니다.
Databricks 호스트에 대해, 작업 영역별 URL을입력하거나 선택하십시오(예:
https://adb-1234567890123456.7.azuredatabricks.net). - 프로젝트에 대한 인증 프로필을 선택합니다. Visual Studio Code용 Databricks 확장에 대한 권한 부여 설정을 참조하십시오.
2단계: Databricks 확장에 클러스터 정보 추가 및 클러스터 시작
구성 보기가 이미 열려 있는 상태에서 클러스터 선택하거나 기어(클러스터구성) 아이콘을 클릭합니다.

명령 팔레트이전에 만든 클러스터의 이름을 선택합니다.
아직 시작되지 않은 경우 재생 아이콘(클러스터 시작)을 클릭합니다.
3단계: Python 코드 만들기 및 실행
로컬 Python 코드 파일을 만듭니다. 사이드바에서 폴더(Explorer) 아이콘을 클릭합니다.
주 메뉴에서 파일 > 새 파일을 클릭하고 Python 파일을 선택합니다. 파일 이름을 demo.py 프로젝트의 루트에 저장합니다.
파일에 다음 코드를 추가한 다음 저장합니다. 이 코드는 기본 PySpark DataFrame의 내용을 만들고 표시합니다.
from pyspark.sql import SparkSession from pyspark.sql.types import * spark = SparkSession.builder.getOrCreate() schema = StructType([ StructField('CustomerID', IntegerType(), False), StructField('FirstName', StringType(), False), StructField('LastName', StringType(), False) ]) data = [ [ 1000, 'Mathijs', 'Oosterhout-Rijntjes' ], [ 1001, 'Joost', 'van Brunswijk' ], [ 1002, 'Stan', 'Bokenkamp' ] ] customers = spark.createDataFrame(data, schema) customers.show()# +----------+---------+-------------------+ # |CustomerID|FirstName| LastName| # +----------+---------+-------------------+ # | 1000| Mathijs|Oosterhout-Rijntjes| # | 1001| Joost| van Brunswijk| # | 1002| Stan| Bokenkamp| # +----------+---------+-------------------+편집기 탭 목록 옆에 있는 Databricks
실행 아이콘을 클릭한 다음 파일업로드 및 실행 클릭합니다. 출력이 디버그 콘솔 보기에 나타납니다. 
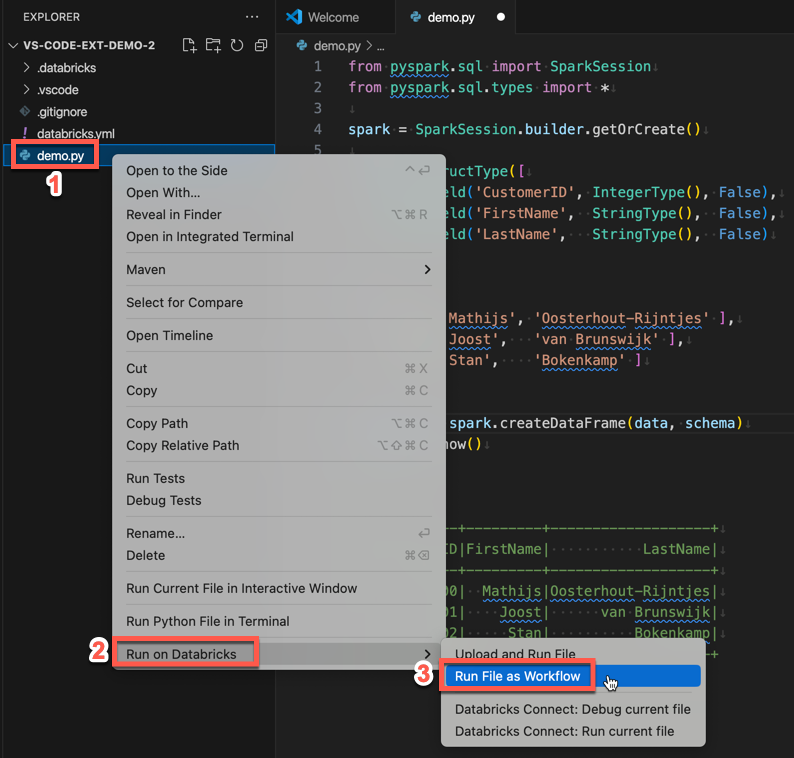
탐색기 보기에서 파일을 마우스 오른쪽 버튼으로 클릭한 후,
demo.py, >을 클릭합니다.
4단계: 작업으로 코드 실행
demo.py을 작업으로 실행하려면 편집기 탭 목록 옆에 있는 Databricks 실행 아이콘을 클릭한 후, 파일을 워크플로로 실행을 클릭합니다. 출력은 demo.py 파일 편집기 옆에 있는 별도의 출력 탭에 나타납니다.
![]()
또는 demo.py 파일을 탐색기 패널에서 마우스 오른쪽 버튼으로 클릭한 다음 Databricks에서 실행>워크플로로 파일 실행을 선택합니다.
다음 단계
이제 Visual Studio Code Databricks 확장을 사용하여 로컬 Python 파일을 업로드하고 원격으로 실행했으므로 다음을 수행할 수도 있습니다.
- 확장 UI를 사용하여 선언적 자동화 번들 리소스 및 변수를 탐색합니다. 선언적 자동화 번들 확장 기능을 참조하세요.
- Databricks Connect를 사용하여 Python 코드를 실행하거나 디버그합니다. Visual Studio Code용 Databricks 확장에서 Databricks Connect를 사용하여 디버그 코드를 참조하세요.
- 파일 또는 Notebook을 Azure Databricks 작업으로 실행합니다. Azure Databricks에서 Visual Studio Code용 Databricks 확장을 사용하여 클러스터, 파일 또는 노트북을 작업으로 실행하는 방법을 참조하십시오.
- 를 사용하여 테스트를 실행합니다
pytest. Visual Studio Code 용 Databricks 확장에서 Python 테스트 실행하기 부분을 참조하십시오.